Dataikuを活用した第3回金融データ活用チャレンジの取り組み
目次
はじめに
普段、Dataikuを使ってデータ分析をしています。今回Dataikuを使ってRAG構築コンペにチャレンジしたのでその内容を紹介します。
第3回金融データ活用チャレンジとは?
第3回金融データ活用チャレンジは、FDUA主催のRAG構築コンペです。環境面で多くの支援が受けられるということで、RAG構築の勉強も兼ねてチャレンジしてみました。
なぜDataikuを使用したのか?
Dataikuはデータ収集から加工、可視化、ML、LLM、アプリケーション開発まで一元的に行える強力なプラットフォームです。普段から業務でも使用していてGUI操作で誰でもRAG構築ができるという点が魅力でDataikuを使用させていただきました。
使用した環境について
- Dataiku環境:クラウド版と無料インストール版があり、無料インストール版を個人のMacにインストールして使用しました
- LLM API:日本マイクロソフト社より提供されたAOAIのGPT-4o-miniと個人のOpenAIアカウントのGPT-4o-miniを使用しました(GPT-4oも使いましたがリクエスト制限で使い勝手が悪かったのでやめました)
- Embedding API:上記同様のアカウントからtext-embedding-3-largeを使用しました
- Python環境:Dataiku上で使用するPython環境はPython 3.10をローカルにインストールしDataikuのCode Envで選択し使用しました(設定方法は後続の手引書を参照)
最終結果について
最終的な評価結果は負の値になってしまい撃沈しましたが、RAG構築の知見は得られたので大変満足しています!

全体フロー
Dataikuを使うとRAG構築の流れをフローで表すことができ、どこで何をやっているかが一目でわかるので便利です。
今回はデータ→テキスト抽出→ベクトル化→QA→データ後処理という単位で分割しフローを作成しました。

基本的な流れはDataiku kimuraさんの手引書をそのまま使わせていただき、ところどころアレンジを加えています。
テキスト抽出
上記の手引書では、DataikuのOCRプラグインを使ってPDFファイルからテキストを抽出していますが、Dataiku無料インストール版ではOCRプラグインのインストール時にエラーが出たため、Pythonのライブラリを使ってテキスト抽出をしています。また今回対象のドキュメントがプレゼン資料形式で図表が多く使われていたためスライド一枚一枚を画像として保存し、画像をテキスト化するアプローチを試しました。
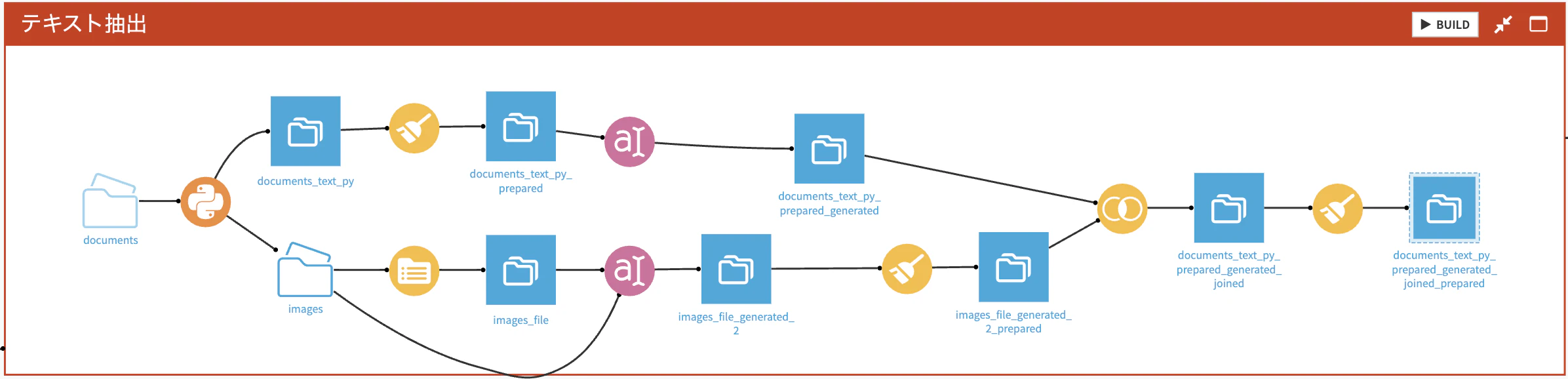
Pythonでのテキスト抽出と画像保存
テキスト抽出にはpdfplumberライブラリを使い、PDFから1ページずつテキストを抽出し、Dataikuのデータセットとして保存しています。画像保存にはpdf2imageライブラリを使ってPDF1ページずつを画像として保存しDataikuのマネージドフォルダに保存しています。
pdf2imageライブラリの使用には別途popplerのインストールが必要なためMac上にインストールしています。
brew install poppler
DataikuではGUIのVisualレシピの他にPythonやRコードを書いてフローに組み込むコードレシピがあり自由度高くフローを作ることができます。
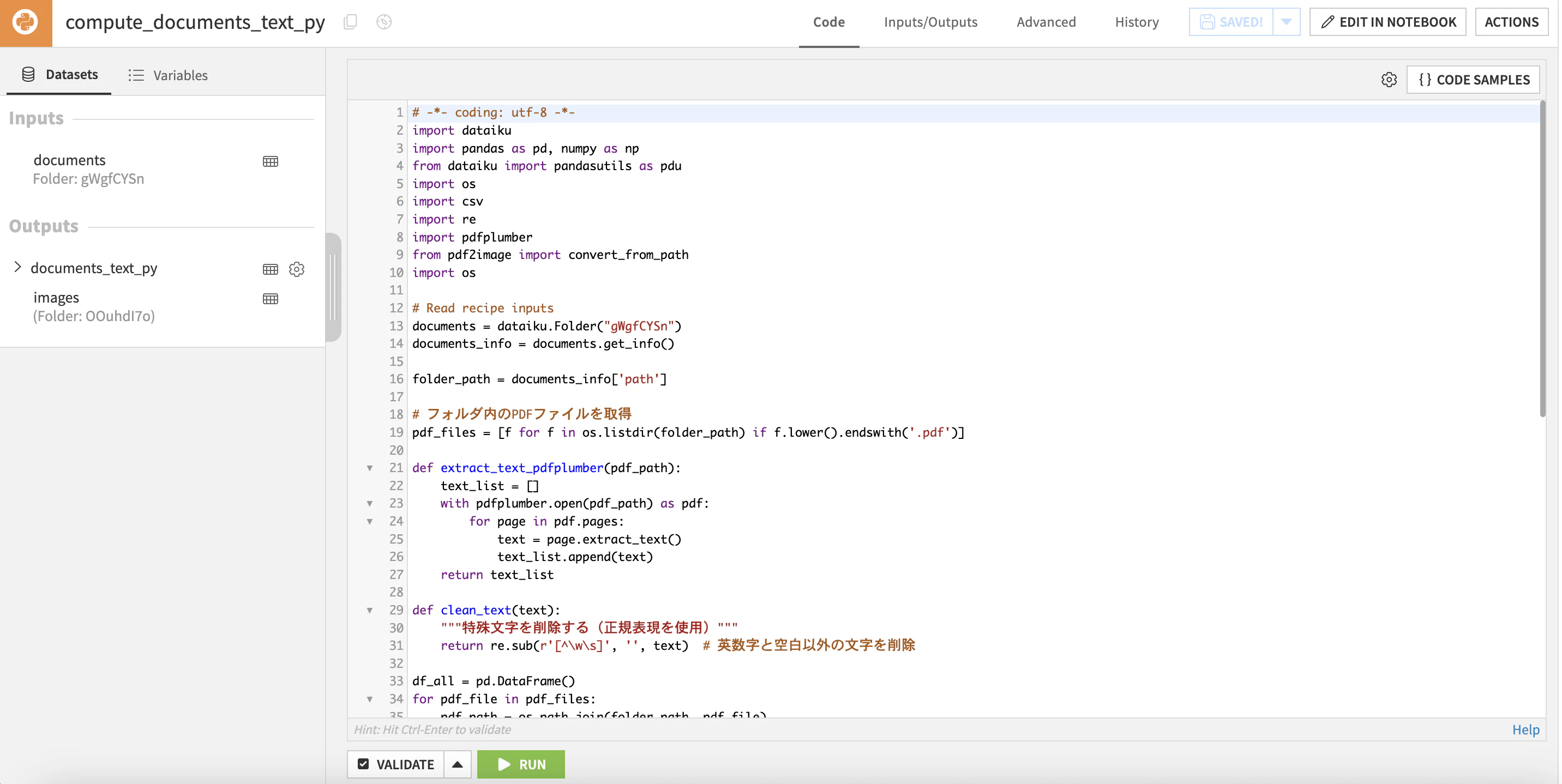
Pythonコード
# Pythonのサンプルコード
# -*- coding: utf-8 -*-
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
import os
import csv
import re
import pdfplumber
from pdf2image import convert_from_path
import os
# Read recipe inputs
documents = dataiku.Folder("gWgfCYSn")
documents_info = documents.get_info()
folder_path = documents_info['path']
# フォルダ内のPDFファイルを取得
pdf_files = [f for f in os.listdir(folder_path) if f.lower().endswith('.pdf')]
def extract_text_pdfplumber(pdf_path):
text_list = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
text = page.extract_text()
text_list.append(text)
return text_list
def clean_text(text):
"""特殊文字を削除する(正規表現を使用)"""
return re.sub(r'[^\w\s]', '', text) # 英数字と空白以外の文字を削除
df_all = pd.DataFrame()
for pdf_file in pdf_files:
pdf_path = os.path.join(folder_path, pdf_file)
text_list = extract_text_pdfplumber(pdf_path)
df = pd.DataFrame({'text':text_list, 'document':pdf_file})
df_all = pd.concat([df_all, df])
df_all = df_all.reset_index()
df_all['text'] = df_all['text'].apply(clean_text)
# Write recipe outputs
documents_text_py = dataiku.Dataset("documents_text_py")
documents_text_py.write_with_schema(df_all)
# DPI(解像度)を設定(300以上にすると高解像度)
dpi = 300
# M1/M2 Mac(Homebrewの場合)
poppler_path = "/opt/homebrew/bin"
output_folder = dataiku.Folder("OOuhdI7o")
# df_image_all = pd.DataFrame()
for pdf_file in pdf_files:
pdf_path = os.path.join(folder_path, pdf_file)
# PDFを画像に変換
images = convert_from_path(pdf_path, dpi=dpi, poppler_path=poppler_path)
# 画像を Dataiku マネージドフォルダに保存
for i, image in enumerate(images):
img_filename = f"{os.path.splitext(pdf_file)[0]}_page_{i+1}.png"
with output_folder.get_writer(img_filename) as writer:
image.save(writer, format="PNG")
画像のテキスト化
PDFを画像として保存したものをLLMを用いてテキスト化しました。フローは下記記事を参考にさせていただいてます。
画像をテキスト化するフローの流れ
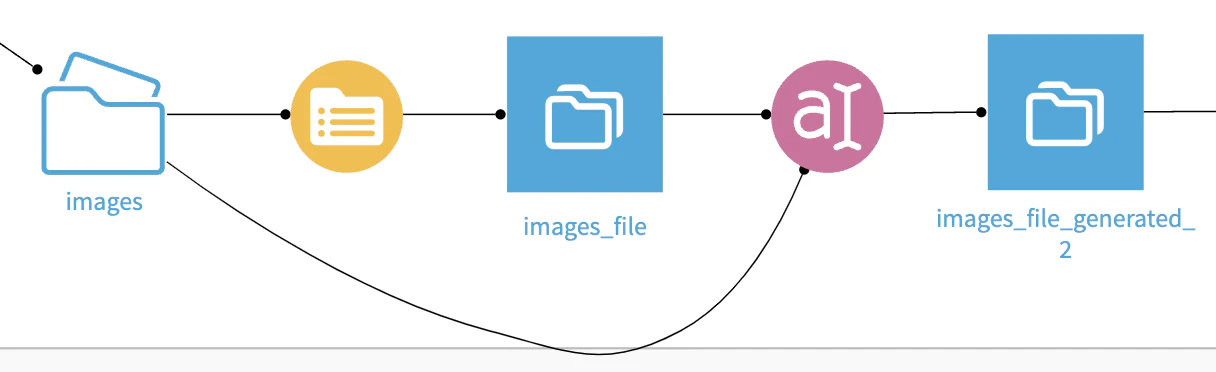
マネージドフォルダを選択してコンテンツリストレシピを選択します。実行すると画像のpath一覧のデータセットを作成します。
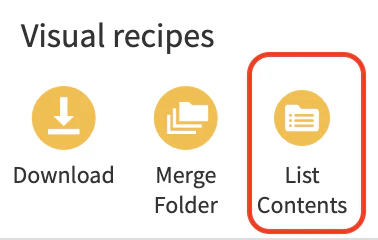
path一覧のデータセットを選択し、プロンプトレシピを作成します。

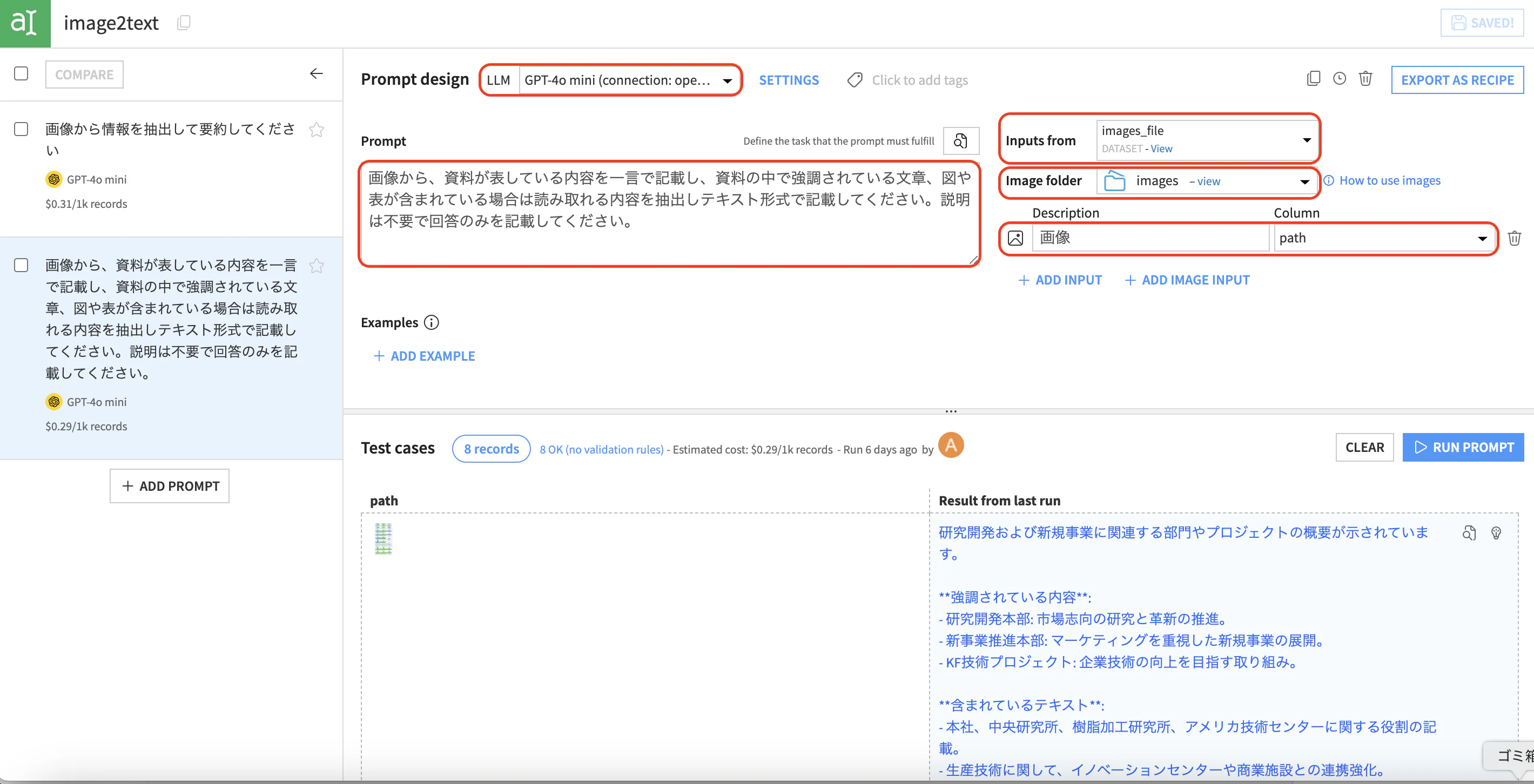
プロンプトスタジオに移動し、マルチモーダルが扱えるLLMを指定します。Inputs fromに画像のpath一覧のデータセットが入った状態で、ADD IMAGE INPUTを選択し、Image folderに画像が入ったマネージドフォルダとpath列を指定します。最後にプロンプトで画像に対するテキスト化の指示を与えます。
今回は画像(スライド)の内容を一言で表すことや強調された文章、数値を読み取りテキスト化するような指示を与えました。
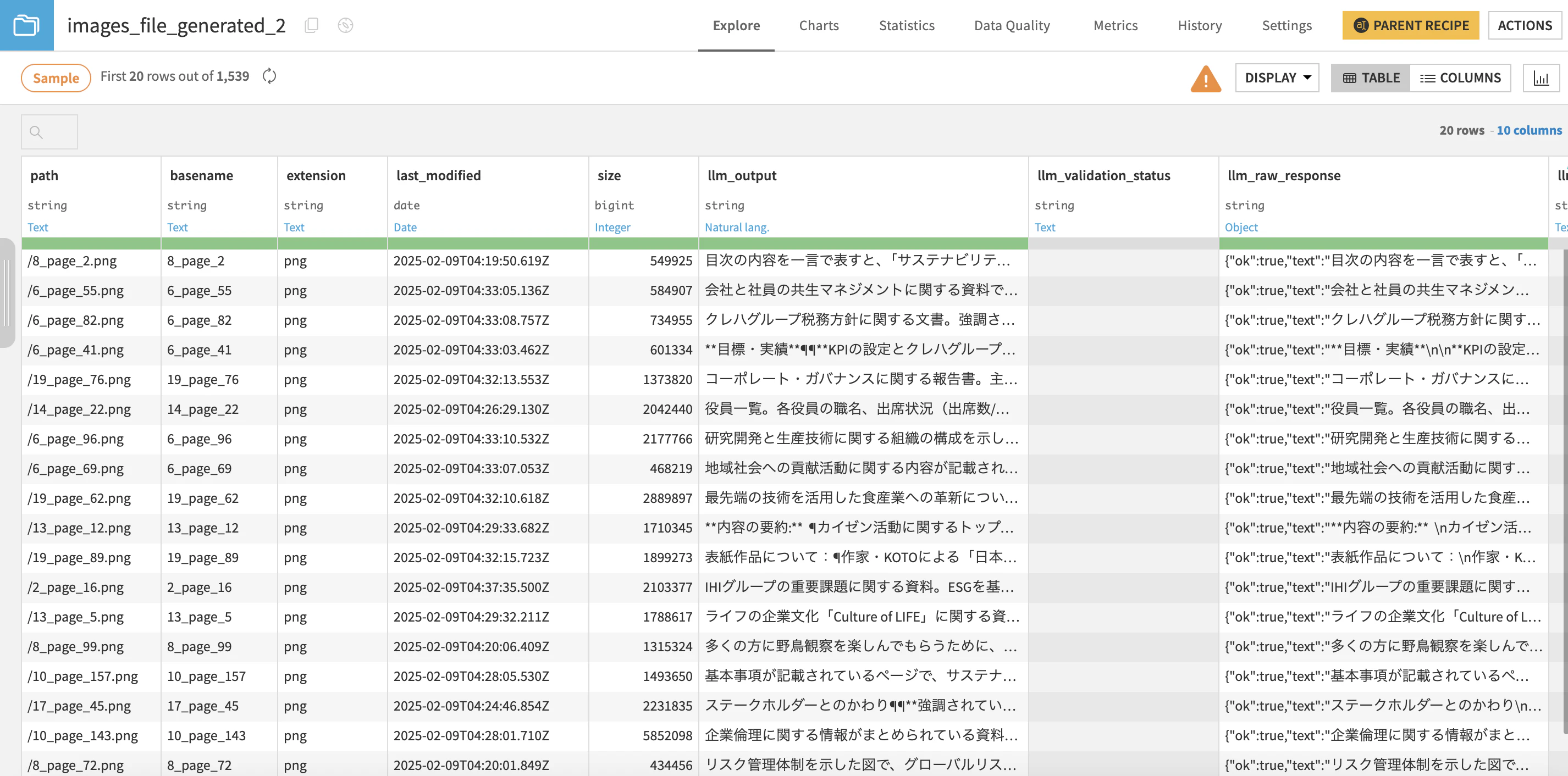
1539枚(ページ)の画像をでテキスト化するのに個人のOpenAIアカウントのGPT-4o-miniを使用して5$ほどかかりました。処理時間も20~30分ほどかかりました。
出力されたデータセットを確認すると画像をテキスト化したアウトプットが生成されています。
RAGに投入するテキストの作成
最後にRAGに投入するテキストを作成します。今回は以下3つのテキストを足し合わせて一つのテキストにしました。
- pythonでテキスト抽出した本文(ヘッダー等の冗長なテキストは削除したもの)
- 1の文章をLLMで要約した文章
- 画像をテキスト化した文章
またMetadataとして資料の企業名、ページ番号、Page番号、画像path、PDF名を列として残しておきます。
ベクトル化
テキスト抽出したデータセットをベクトル化していきます。
データセットを選択した状態でEmbedレシピを選択し、手引書通りに設定していきます。
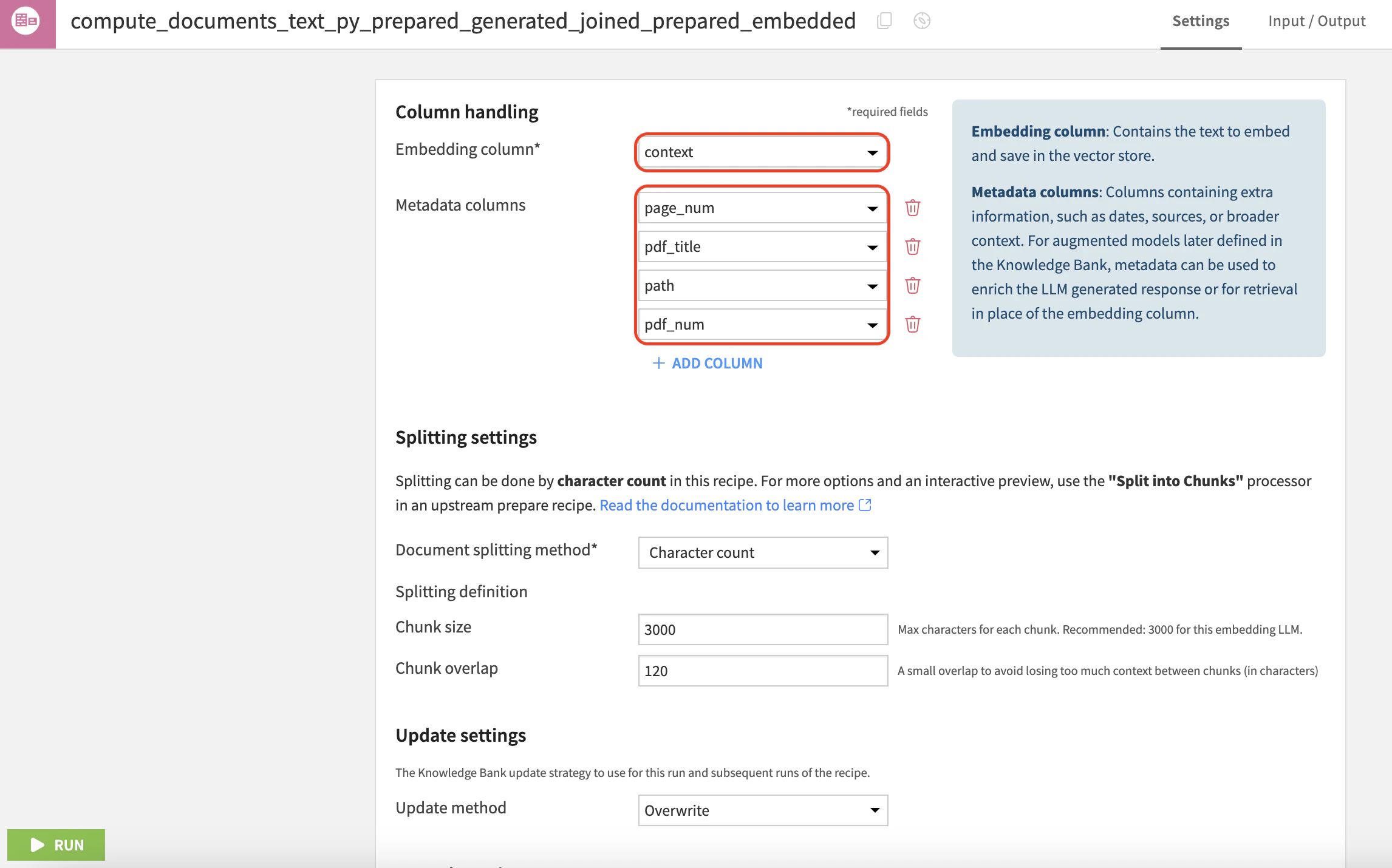
Embeddingモデルはtext-embedding-3-largeを使用し、ベクトルストアはデフォルトのChromaDBを使用しています。

Embeddingするテキストに作成したテキストを指定し、Metadataとしてページ番号、資料の企業名、画像path、PDF名を指定しました。
質問回答
作成したベクトルDBを用いて、テストデータに対する回答を生成します。
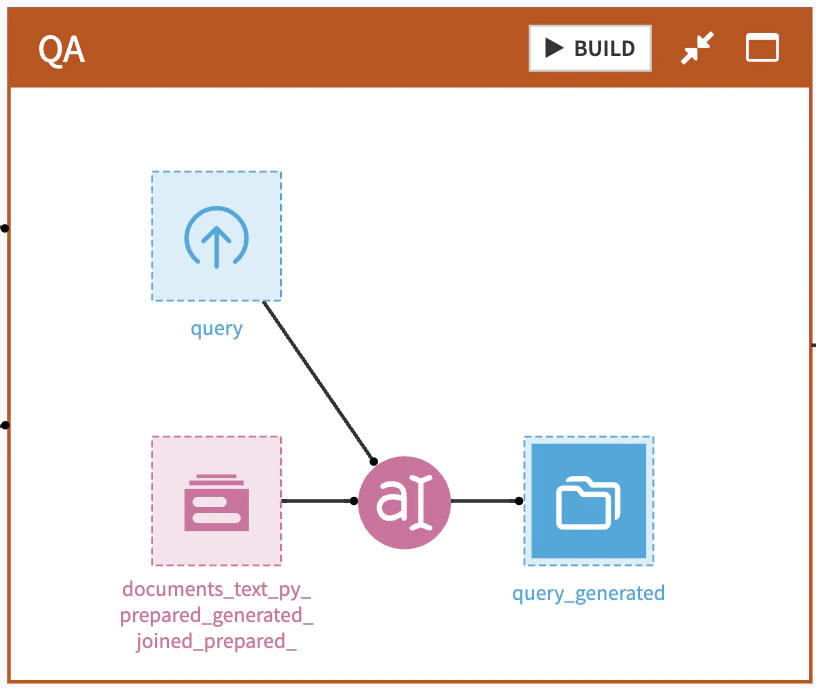
テストデータに対してプロンプトレシピを作成しプロンプトスタジオを開きます。
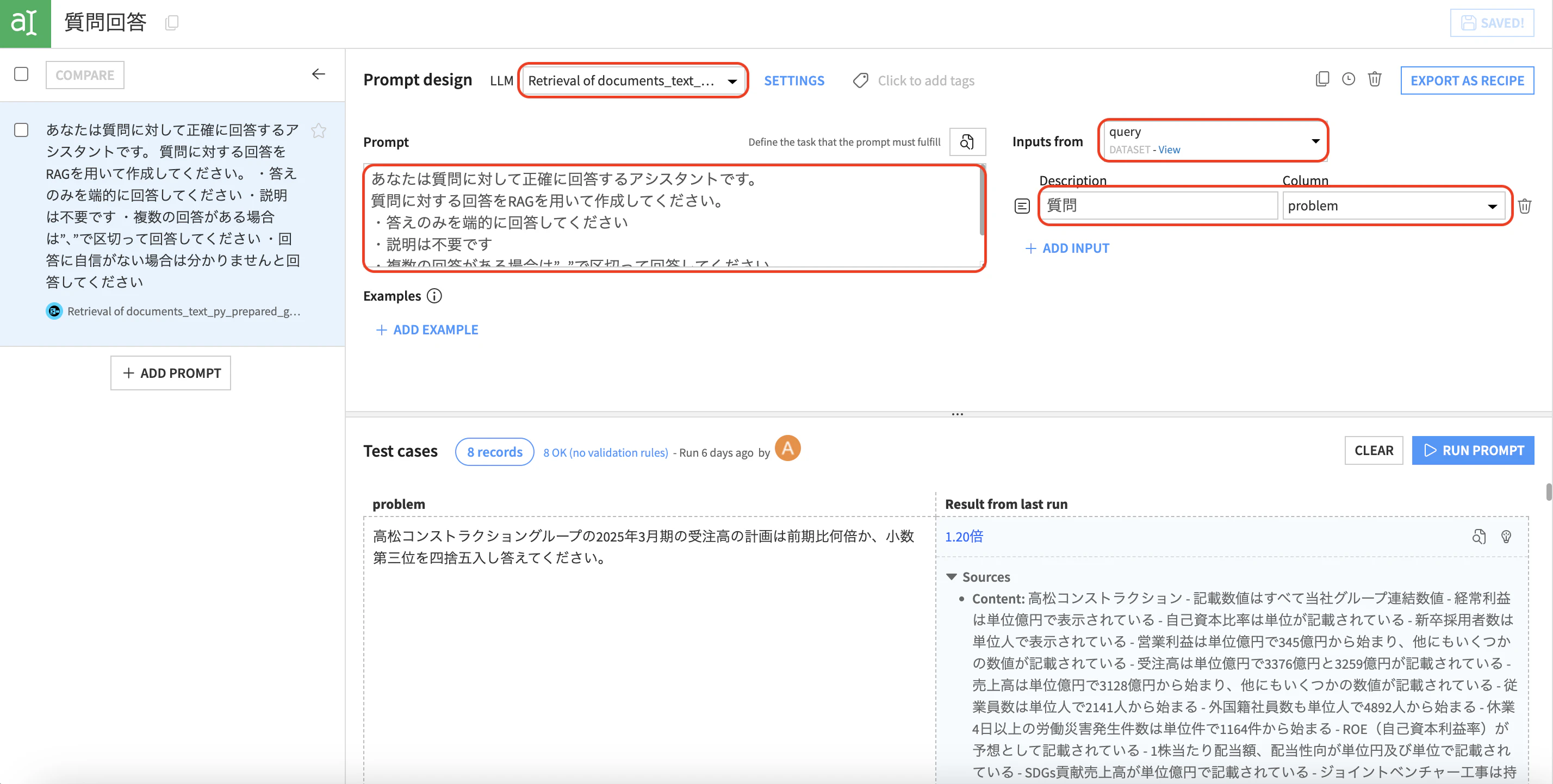
LLMに作成したベクトルDBを指定し、ADD INPUTでテストデータの質問列を指定します。
プロンプトに回答の作成指示を与え実行します。今回は以下プロンプトで回答を作成しました。
あなたは質問に対して正確に回答するアシスタントです。
質問に対する回答をRAGを用いて作成してください。
・答えのみを端的に回答してください
・説明は不要です
・複数の回答がある場合は”、”で区切って回答してください
・回答に自信がない場合は分かりませんと回答してください
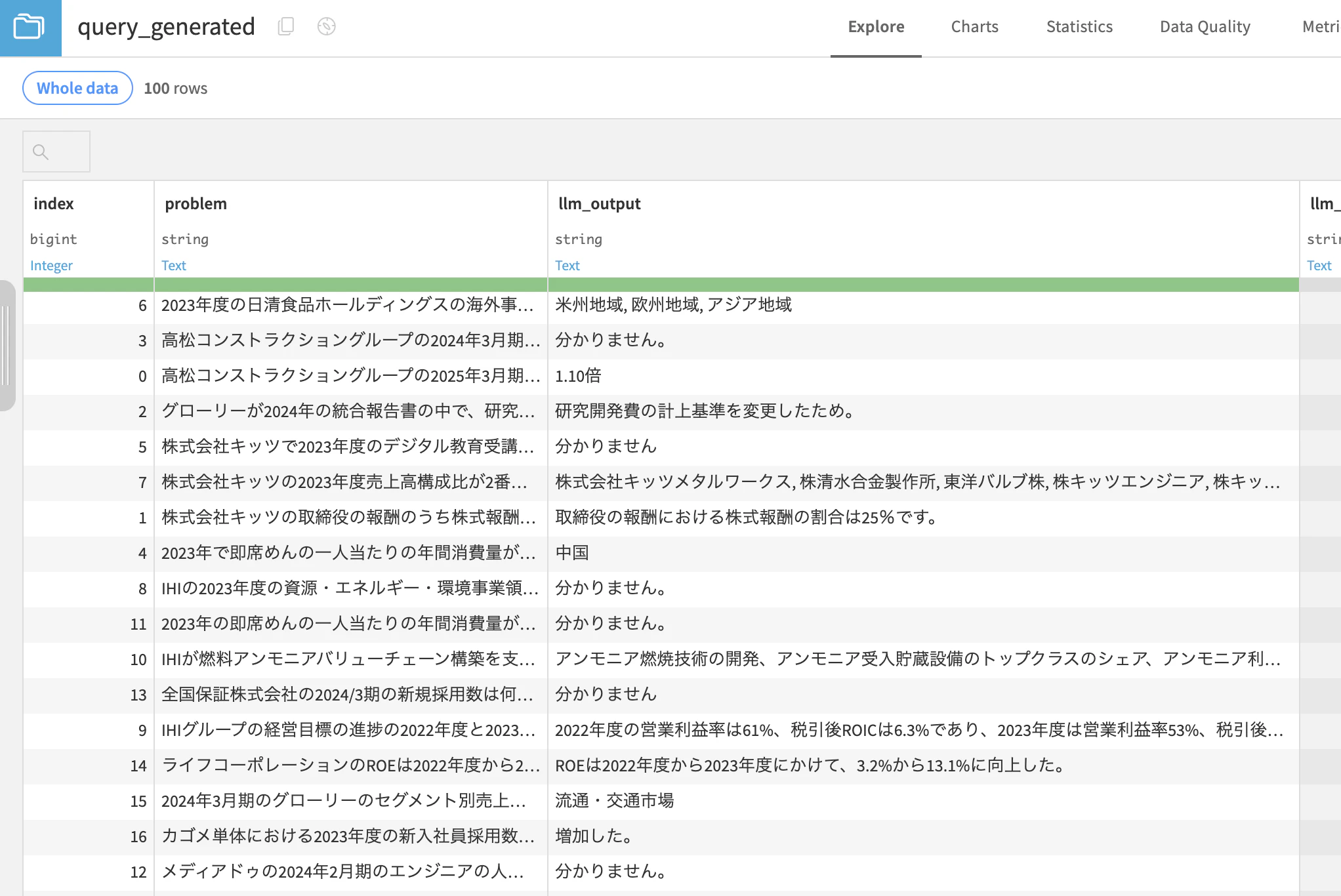
実行するとそれらしい回答が生成されています。
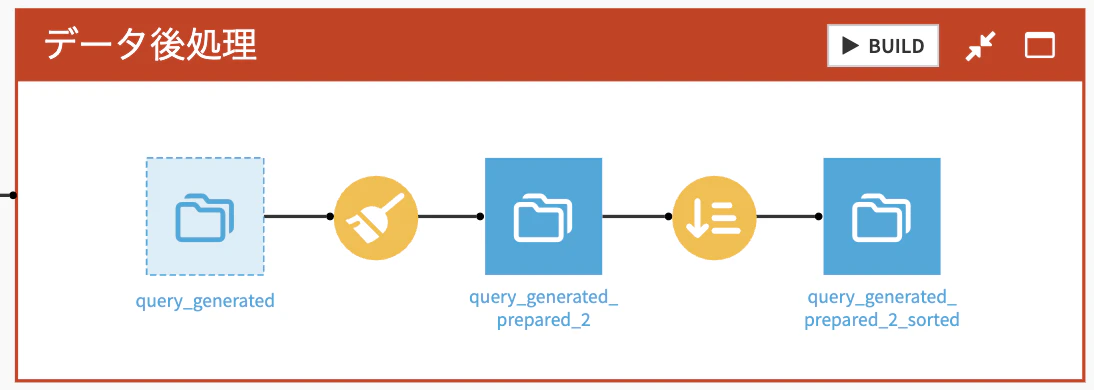
データ後処理
さいごにサブミッション用にデータを整形していきます。
準備レシピで不要な列を削除し、並べ替えレシピで問題順にソートして完成です。
あとは手動でExportしてコンペサイトに投稿します。
さいごに
コンペの感想
スコアが全然伸びなかったことに悔いが残りますが、学びの多いコンペで大変満足しています。プロンプトや図表の読み取りに改善ポイントがありそうです。他の参加者の解法もチェックして勉強したいと思います。
Dataikuを活用した感想
DataikuはGUIベースでデータ操作からRAG構築まで行えて効率的に作業を進めることができました。また細かいところはPythonも組み込めるので非常に強力なツールだと感じました。今後も活用していきたいと思います。