はじめに
先日行われたFDUA主催の「第3回金融データ活用チャレンジ」に参加しました。
職場の若手3人(RAG初心者)で手を組み、コンペに取り組みながらRAGのお勉強ができればと思い、team_maguroとして参加させていただきました。
せっかくなので、コンペに挑戦する中で苦労したこと、工夫したこと、心残りなこと、など残したいと思います。
同コンペに参加された方、これからRAGを構築する方など、どなたかのお役に立てば幸いです。
コンペの概要
コンペの詳しい内容は割愛しますが、ざっくりいうと「19個の企業パンフレット(pdf)に記載されている情報を見れば回答できる問題を100問作ったからRAGで答えてみろ!」というものです。
各問題が『正解:1点、惜しい:0.5点、回答なし(わかりません):0点、誤答:-1点』で採点され、100問の平均が最終的な点数となります(-1.00~1.00点)。
結果
最終得点が0.51点で、結果は94位でした。(厳しい…!)
可もなく不可もない結果ですが、RAG初心者集団で挑んだにしてはよくやったのではないかと思います。
ブロンズという称号をいただきました。ラッキー。

最終提出したモデルの紹介
0.51点を獲得したモデルを紹介させていただきます。
モデルの説明
モデルの外観は以下の通りになります。
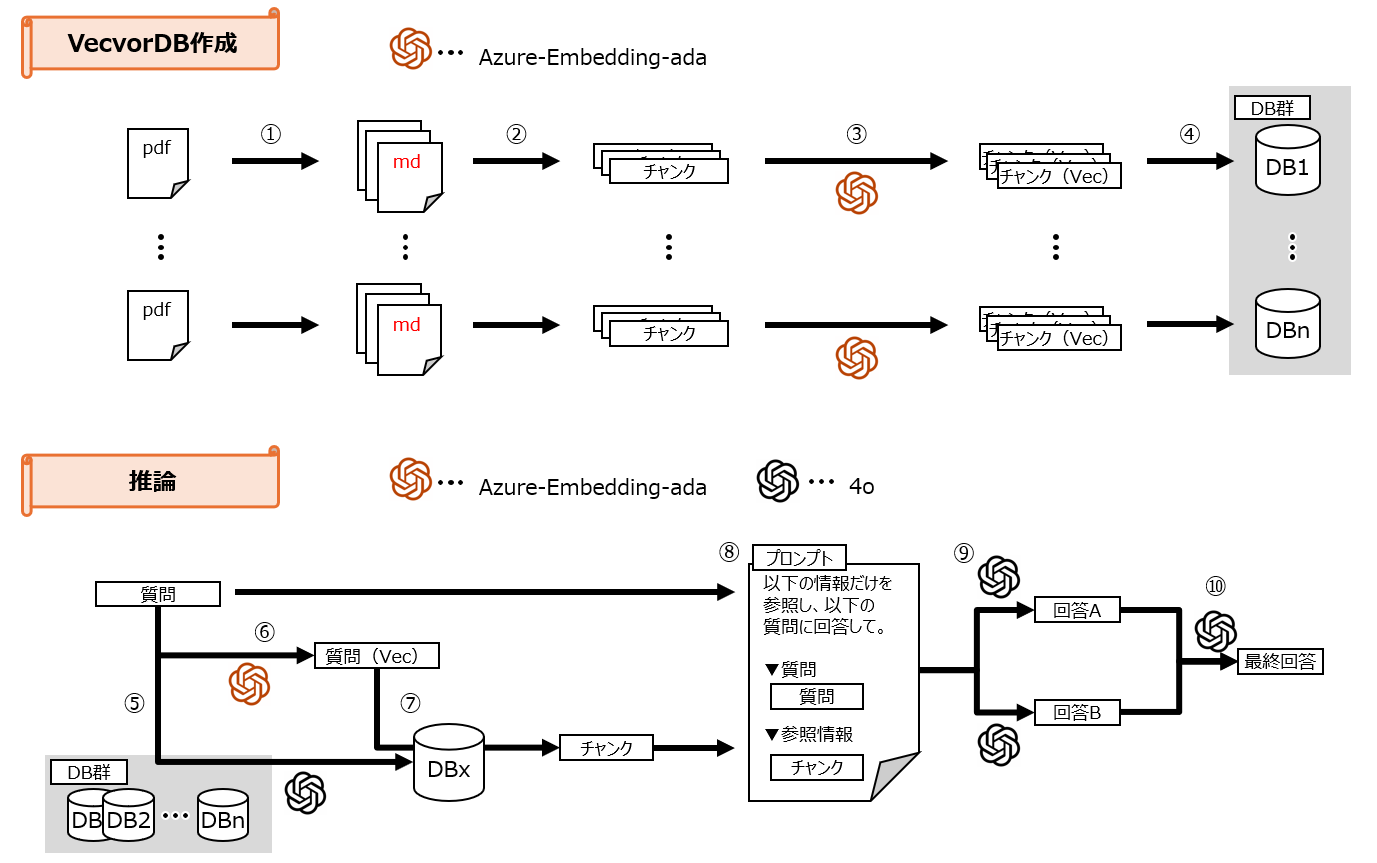
① pdfからmdへ
今回はyomitokuというライブラリを利用しました。
yomitokuは、日本語文書に特化した文書画像解析エンジンで、OCR(光学文字認識)でpdfの内容をmarkdown形式に変換してくれるライブラリです。
今回は、企業のパンフレットに記載された情報の読み取りが題材であり、pdfには図表もふんだんに盛り込まれていたので、光学文字認識に頼ろうと判断しました。
yomitokuについて、詳しく知りたい方は以下をご参照ください。
特長 | MLism
② テキストのチャンク分割
md形式のファイルをチャンク分割します。
- チャンクサイズ:20000
- オーバーラップ:500
初回に決め打ちで20000-500にしましたが、ここにはもっと試行錯誤の余地があったかもしれません。
③ チャンクのベクトル化
分割したチャンクを「Azure-Embedding-ada」によりベクトル化します。
今回のコンペ用にMicroSoft様がAPIキーを提供してくださっていたので、ありがたく利用させていただきました。
④ ベクトルのDB保存
ベクトル化されたデータはDB(と呼んでいるだけで実際はただのローカルのファイル)に保存します。
企業のパンフレットごとにDBを作成したので、19個のDBが作成されます。
⑤ 参照するDBの決定
企業のパンフレットから読み取ることができる質問を生成AI(GPT-4o)に渡して、どの企業のことを説明しているかを回答してもらいます。
この後、ベクトル検索するDBを決定するためのステップです。
※質問文を渡してあげるだけでも、9割くらいの精度で正しいDBの選択が可能です。
※企業名が記載されていない質問文も混ざっており、そういったものにはうまく対応できていなかったです。
⑥ 質問文のベクトル化
質問文を「Azure-Embedding-ada」によりベクトル化します。
今回のコンペ用にMicroSoft様がAPIキーを提供してくださっていたので、ありがたく利用させていただきました。
⑦ ⑤で選択したDBからチャンクを取得
⑤で選択したDBを⑥でベクトル化したもので検索し、チャンクを取得します。
top_K=5で設定しました。
⑧ プロンプト作成
質問文と⑦で取得したチャンクをつかってプロンプトを作成します。
作成したプロンプトはおおむね図に記載されたようなものです。
⑨ プロンプトから回答を2つ生成
⑧で作成したプロンプトをつかって、GPT-4oに2回回答させます。
temperatureは0.5に設定しました。
⑩ 2つの回答を照合し、最終的な回答を決定
2つの回答をインプットに、最終回答をアウトプットします。
最終回答の決定は以下のルールに従います。
- 2つの回答が同じであれば、その回答を最終回答とする。
- 2つの回答が異なる場合は、「わかりません」を最終回答とする。
工夫点
0.51点に寄与したと思われる工夫点が3点ほどあるので説明します。
その1:yomitokuの採用
コンペ開始と同時に、pdfの読み取りで思いっきり躓きました。
pyPDFやpdfminerなどpythonのpdf読み取りライブラリをいろいろ試してみましたが、図表の読み取り以前にそもそも文字化けに悩まされるなど先が思いやられる展開でしたが、そんな中見つけたのがyomitokuでした。
yomitokuはpdfの内容をOCRで変換するため、図表の読み取りに強いだけでなく、pdfを生成AIとの相性が良いmarkdown形式に変換してくれる点が非常に優秀だと感じました。
しかも、md形式のまま分割したチャンクをインプットにgptに推論させると、表の読み取り問題も難なく回答してくれるんです。感動しました。
その2:gpt-4oの採用
初めはMicrosoft様から提供されていたgpt-4ominiを使って推論させたところ、0.3前後のスコアを記録しましたが、内容を見ると取り出すチャンクは間違ってなさそうなのに回答にたどり着けていないように感じたので、より賢いモデルgpt-4oに頼ることにしました。
プログラム上はgpt-4ominiからgpt-4oに変えただけなのですが、得点は0.3→0.65に一気に大躍進(0.65は中間スコアです)。
使うモデルって重要なんですね。一長一短かとは思いますが、自分のやりたいこととモデルの得意不得意を照らし合わせて、適切にモデルを選択するって大事なんだって感じた経験でした。
その3:2つの回答をマージさせる作戦を採用
通常のRAGでは⑧で作成したプロンプトで回答させて終わりかと思いますが、今回は「GPT-4oに2回回答させ、それらをマージして最終回答とする」流れを採用しました。
この作戦に至った経緯を説明します。
まずは今回のコンペのルールのおさらいです。
- 今回のコンペのルールでは、誤答は-1点であり、ハルシネーションによる減点が大きい。
- 一方で、「わかりません」という回答すれば0点に抑えられる。
- そのため、誤答するくらいなら「わかりません」と回答させるほうがマシ。
初めに思いついたのは、プロンプトに『わからない場合は「わからない」とだけ回答してください。』と記載することでした。
が、試してみると、取り出すチャンクが適切でも大半の問題に「わかりません」と回答するようになってしまい、まったくスコアが伸びない結果となりました。
なんでもいいから回答はさせたいんだよなぁ。。。と思い、辿り着いたのが、不正解でもいいからとりあえず回答させる&2つの回答をマージさせる作戦です。
"とりあえず"で答えさせた回答で得点がマイナスにならないように、2つの答えが相違している場合は「わかりません」と回答させることでリスクヘッジしました。
さらに、2人が同じ誤答をして-1点となるのを避けるため、temperatureを0.5に設定することで、2人が異なる間違え方をすることを狙いました。
これにより、「gptがある程度答えを絞れている場合は2回とも同じ回答を得られるだろう(→1点獲得)」「gptが答えを絞り切れていない場合は2回とも違う回答が得られるだろう(→±0点)」と期待しました。
実際、この作戦を採用することにより、LLMが回答を出力する回数は増え、最終回答における「わかりません」の割合も減り、得点もアップしました。
そのほかに試したこと
このモデルを作成した後もいろいろと試してはみたのですが、どれも得点アップにはつながりませんでした。
試したことは以下に記載します。
-
chain of thoughtの導入
取り出すチャンクはあっているのに推論過程で間違って失点するパターンが散見されたので、推論のプロンプトに推論過程も出力させてみました。が、結果はあまり変わらず。
推論能力の高いモデルに変えないとダメなのかな、、、という感想を持ちました。 -
チャンクサイズの変更
私が作成したモデルでは1回も回答できていなかった問題を、チームメイトが簡単に回答できていたことから、二人のモデルの違いであるチャンクサイズに着目して「チャンクサイズ:10000、オーバーラップ:500」のチャンクもモデルに組み込んでみました。
検証データを使って試したところ、わずかに得点アップしたような気もしましたが、本番データでは点数を超えられず、、という結果でした。 -
3人多様性の導入
2人に回答させてそれらの答えをマージするモデルを採用していましたが、2人がベストなの??という疑問がわき、お試しで3人多数決も試してみました(2人以上が同じ答えならその答えを採用。それ以外は「わかりません」。)。
結果はあまり変わらず、何人で回答させるのがベストなのかを机上で考えようとしてみましたが、どのような問題設定にすればよいかがわからず挫折。
時間があれば試したかったこと
-
ほかのモデルの採用
今回のコンペ用に提供されていたLlamaやqwen、推論に強いgpt-o1、o3、deepseekなど、いろいろと試してみたかったです。 -
GraphRAGと、ベクトルRAG以外のアプローチ
RAGの勉強にもなったと思うので、時間があればいろいろ調べながら手を出してみたかったです。 -
データのクレンジング
yomitokuにおんぶにだっこでデータのクレンジングには全く手を出せなかったです。私の勝手な推測ですが、上位数%の方々はこのあたりに力を入れられたのではないかなと思います。
感想
参加する前は「聞いたことあるなぁ」くらいの距離感だったRAGが、実践を通して身近なものに感じられるようになりました。
とはいえ、RAGを使いこなし上位にランクインされている方々の足元にも及ばない結果に終わってしまったので、まだまだ精進が必要だと感じています。
本当にいい刺激になりました。ありがとうございました!
番外編:gpt-4o vs deepseek R1
コンペの開催中に突如発表され話題となったdeepseek。
せっかくなので、deepseekにも同じ問題を解かせてみて実力を測ってみます!
比較方法
- 今回は検証用に与えられた問題を上から20問ピックアップ。
- それらの問題をgpt-4oとdeepseek R1に解かせます。
- 使用するモデル以外はすべて条件をそろえています(チャンク、top_K、プロンプトなどすべて同じ)。
- 単なるモデルの比較がしたいだけなので、2つの回答をマージするアプローチは取らず、それぞれのモデルに1回だけ回答させます。
- ちなみに、deepseek R1は日立社からコンペ用に提供されたものではなく、個人でのAPI利用になります。
(おそらくリクエストのトークン数が大きいことが原因で、日立社提供のモデルからはレスポンスが返ってこなかったので断念。。。)
結果
推論時間の比較
20問を解き終わるのにかかった時間は以下の通りで、わずかにdeepseekの方が早いという結果でした。
deepseekは推論に時間がかかるイメージでしたが、案外早いんですね。
(inputトークンは、約40000トークン/問です。)
| 所要時間 | |
|---|---|
| GPT-4o | 20分02秒 |
| deepseek R1 | 18分32秒 |
推論精度の比較
大差はつかず、わずかにdeepseek R1が優位な結果となりました。
| 正解 | 不正解 | 無回答 | 得点 | |
|---|---|---|---|---|
| GPT-4o | 10 | 2 | 8 | 0.40 |
| deepseek R1 | 12 | 2 | 6 | 0.50 |
回答内容の比較
以下の4問は、gpt-4oとdeepseek R1が異なる回答を出力した問題です。
(緑:正解、赤:不正解、白:無回答)
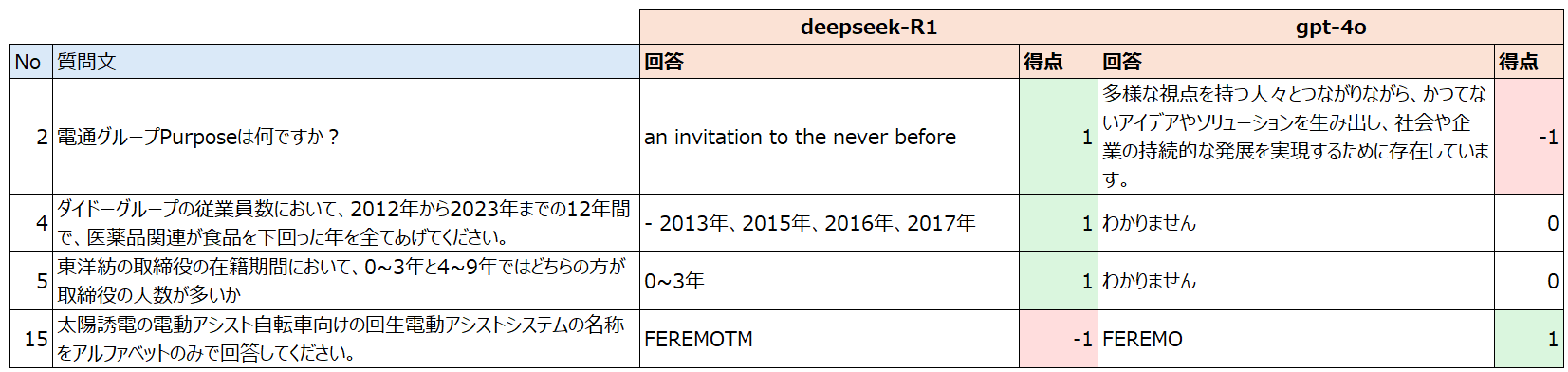
deepseek R1 > gpt-4o となった3問について
- No2は単純な読み取り問題です。コンペ期間中はgpt-4oも正解していた気がするのですが、なんで間違えたんだろ、、、ちょっと謎です。
- No4とNo5をdeepseekが正解したのはかなり驚きでした。というのも、これらの問題は、pdfに記載された情報をただ回答する問題ではなく、記載された情報を集計して回答する問題で、コンペ期間中にgpt-4oでは正解に辿り着けなかったものだったからです(chain of thoughtを試してみたけどそれでもだめだった...)。
deepseekの推論能力の高さを思い知った気がします。さすが...!
deepseek R1 < gpt-4o となった1問について
- No15は、パンフレットに記載された FEREMO™ という表記に騙されずにFEREMOと回答できるか、がカギとなる問題です。
- yomitokuのOCRで「FEREMOTM\(フェリモ\)」というテキストデータに変換されてしまっているので、deepseekのように「FEREMOTM」と答えるのが自然な気もしますが、TMを商標マークだと察して「FEREMO」と答えたgpt-4oは賢いですね。
- (若干横道にそれますが)「アメリカと中国におけるTMマークの扱いの違い」についてgeminiに聞いてみると、中国ではアメリカほど一般的ではないという回答が返ってきました。この情報がどこまで信ぴょう性のあるものかわかりませんが、LLMの学習データに依存している可能性は無きにしも非ずだなと思いました。

番外編まとめ
以下のような結果となりました。
- 推論時間: deepseek R1がわずかに早い
- 推論精度: deepseek R1の方が正答率が高い
- その他
- 推論系の問題はdeepseekのほうが強い。
- deepseekの学習データはおそらく中国のデータが主なため、中国で一般的ではない用語・表現の扱いには弱い(?) ←あくまで推測です。
「deepseek圧勝!」みたいな結果に見えなくもないですが、gpt-4oの公開日は2024年5月13日なので「半年前のモデルなんだ」という温かい目で見てあげてください。
deepseek R1の発表時は「gpt-o1に匹敵する!」という謳い文句だったのでgpt-o1と比較するのが筋なんでしょうが、お金と時間の都合上見送りです。また別の機会にやることにします(どこかで別の人がもうやってると思います)。
いろいろ学びが得られていい経験になりました。ここまでよんでいたdありがとうございました。