はじめに
昨年に引き続きとても楽しいコンペ第3回 金融データ活用チャレンジを企画いただき関係者の皆様に深く感謝します.
また無料でLLMを提供いただいた企業の皆様にも御礼申し上げます.
振り返り
コンペの概要
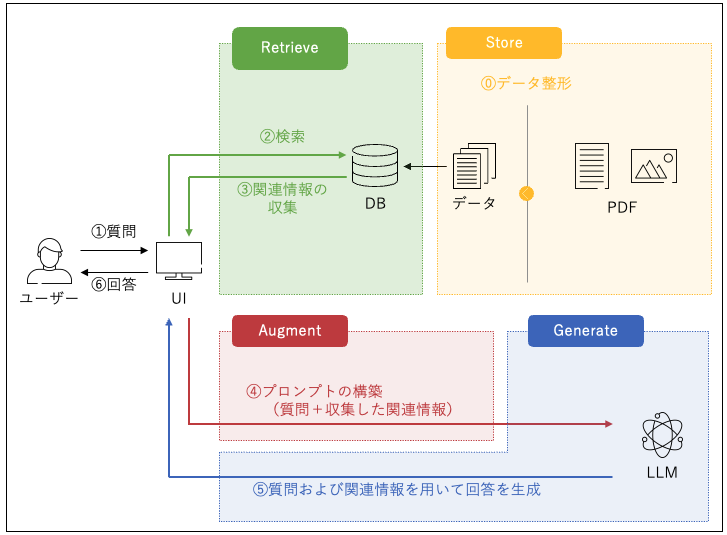
今回のコンペは「企業のESGレポートや統合報告書に関連する質問に対して自動的かつ正確に回答できるRAGシステムの構築」がテーマとなりました.
詳細は第3回 金融データ活用チャレンジをご確認ください.
自分のスコアは?
自分 == 64歳の現役サラリーマン(プログラマ) としては望外な結果に大満足です.

今回の取組み
自分はさっくり以下のステップでコンペに取組みました.
- PDFファイルのテキスト化と検索用VectorDBの構築
- 質問に回答するLLMの実行
2.1. 質問の答えを知っていそうなPDFデータを検索用VectorDBを利用して収集
2.2. プロンプトを構築しLLMにQueryを実行
2.3. 受信した回答の自動整形
Azure OpenAIの活用
マイクロソフト様から無償提供された2つのLLMモデル
今回のコンペではマイクロソフト様から2つの高性能LLMモデルを無償提供いただきました.
| APIの種類 | 提供モデル | 自分ならこう使う |
|---|---|---|
| Chat Completions API | Azure OpenAI GPT-4omini | 質問への回答生成 |
| Embedding API | text-embedding-3-large | 検索用VectorDBの構築および質問のVector化 |
ただし使用にあたっては「Generate」以外の用途では使ってはならないというルールがありましたので今回記述するのは Azure OpenAIがもし仮に自由に使えた場合、こんなにすごいことができる という感想を書き連ねていきます.
コンペで実際に利用したモデル(主に前処理)はGemini2.0-Flushでしたが無償提供されたAzure OpenAIも思う存分触らせていただき機能、性能ともにすごいと思いましたのでそのポテンシャルの大きさをご紹介したいと思います.
活用その1:PDFファイルのテキスト化
PDFのテキスト化は markitdown などなど様々なツールが存在します.
それらのツールとは別にPDFの表データやグラフデータを上手にテキスト化するためにわざわざpngやjpegなどの画像に変換した後でテキスト化するという手法もあります.
Azure OpenAI GPT-4ominiは画像データを読み取ってmarkdown形式でテキスト化することができます.
一例ですが以下のPythonコードで画像をテキスト化できます.
import os
import base64
import numpy as np
from openai import AzureOpenAI
with open(image_file, 'rb') as f:
img = f.read()
content = [
{
'role' : 'system',
'content' : [
{'type':'text', 'text':'あなたは画像から文字を読み取りmarkdownに変換して出力します'},
{'type':'text', 'text':'わからないときは # unknown と出力します'},
]
},
{
'role' : 'user',
'content' : [
{ 'type': "image_url", 'image_url': {'url':'data:image/jpeg;base64,'+
base64.b64encode(img).decode('ascii') }},
]
}
]
client = AzureOpenAI(
api_key=AZURE_OPENAI_API_KEY,
api_version=API_VERSION,
azure_endpoint=AZURE_OPENAI_ENDPOINT)
completion_resp = client.chat.completions.create(
model=DEPLOYMENT_ID_FOR_CHAT_COMPLETION,
temperature=0,
seed=42,
messages=content
)
活用その2:検索用VectorDBの構築
今回提供されたtext-embedding-3-largeを使うと最大8Kトークンのテキストを3,072次元のベクトルに変換してくれます.
PDFの各ページを最大8Kトークン以下のテキストにしてこれをベクトル化してストレージ(メモリが潤沢にあればメモリでもOK)に格納します.
自分が検索用VectorDBと勝手によんでいるのはこのストレージ内のベクトルデータのことです.
テキストのベクトル化はきわめて簡単で以下のPythonコードで実現できます.
client = AzureOpenAI(
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version=API_VERSION
)
response = client.embeddings.create(
input=text,
model=DEPLOYMENT_ID_FOR_EMBEDDING
)
text_vector = response.data[0].embedding
embeddingで入力8Kトークンという容量や3,072次元という出力は以下のモデルと比較しても大規模できわめて使い勝手が非常に良いと感じました.
| model | 出力次元数 |
|---|---|
| voyage-3-large | 2,048 |
| text-embedding-004 | 768 |
このベクトルをどうやって文書検索に使うのかについてはChatGPT - LLMシステム開発大全に詳しく説明があります.
今回のチャレンジでは自分は2つのテキスト(ベクトル)の類似性の計算にコサイン類似度を使う方法を採用しました.
この手法は今回のコンペのためにマイクロソフト様が開催してくれたハンズオンから学んだものです.
たまに話のベクトルがあうとかあわないとかいう表現を耳にしますが,話の向きがピッタリ重なりあえばコサインの最大値1となり話が90度合わない場合は0になるというイメージです.
若干数学的な説明をしますと長さ1のベクトルa,bの内積(aとbの間の角度のコサイン)がコサイン類似度となります.
ストレージに蓄積したPDFごとの各ページのベクトルと質問のベクトルを片っ端から突合してコサイン類似度を計算しコサイン類似度の高いドキュメントが質問の答えを知っている可能性が高いのでは?という期待にtext-embedding-3-largeは見事に答えてくれるとおもいます.
今回のコンペではPDFをLLMで要約したベクトルと質問のベクトルのコサイン類似度を計算して回答を知ってそうなPDF==コサイン類似度が大きいPDF を最初に特定してからページ単位のベクトル突合をおこない答えを知っているであろうページ候補10ページを特定してプロンプトを構築しました.
embeddingモデルは提供されたtext-embedding-3-largeを使いたかったのですがコンペのルールを考慮してvoyage-3-largeを利用したテキスト検索を構築しています.
活用その3: 受信した回答の自動整形
作戦その1
「XX工業の純資産において、2022年度と2023年度ではどちらが大きいでしょうか?」という質問があったとします.
このときLLMが返す「XX工業の純資産は2022年度は純資産120億、2023年度は純資産140億なので2023年度が大きい.」という冗長な回答をもっとシンプルにできないか?というときに比較的うまくいきそうなのが以下のアプローチです.
system_prompt = """
あなたは日本語の質問文を解析し質問文が以下のいずれかの条件を満たす場合はtrue, 満たさない場合はfalseを判定するAIです.
質問に対する回答はおこないません.
- 質問文に選択肢が含まれておりその中から回答を選択する.
- 択一の条件が提示され、条件に該当し選ばれた候補を要求する.
- JSON形式でkeyとして"judge"を指定しそのvalueに判定結果を記載して出力すること.
- 質問文に選択肢が含まれている場合、JSON形式でkeyとして"selection"を指定しそのvalueに選択肢をすべて質問文から抽出して出力すること.
"""
するとこんな感じのJSONを返してくれます.
{'judge': True, 'selection': ['2022年度', '2023年度']}
回答は'2022年度'または'2023年度'に限定されるはずなのでLLMの冗長な回答を評価してどちらかを2者択一の回答に採用するという戦略です.
類似の応用として「XX誘電のコンデンサの2023年度の売上高は何億円ですか?」という質問に対して
system_prompt = """
あなたは日本語の質問文を解析し数値による回答を要求しているか否かを判定するAIです.
質問に対する回答は行いません.
判定結果および判定理由の出力は以下のルールに従うこと
- 判定結果は回答が数値を要求している場合はtrue,数値以外の回答を要求している場合はfalse,不明な場合はunknownと出力する.
- JSON形式でkeyとして"judge"を指定しそのvalueに判定結果を記載して出力すること.
- 数値を要求している場合、JSON形式でkeyとして"unit"を指定しそのvalueに数値の単位を質問文から抽出して出力すること.
"""
するとこんな感じのJSONを返してくれます.
{'judge': True, 'unit': '億円'}
この結果を受けてこの質問には「億円」で終わる数値を回答すればいいのかな?とわかります.
今回はGemini2.0-Flashを使いましたが Azure OpenAI GPT-4ominiを使えばこれらのことはたぶんできただろうと思います.
作戦その2
ひとことでいうと「ガス抜きプロンプト作戦」です.
高度なLLMは丁寧な説明を付け加えることが多く「シンプルに回答して」みたいなリクエストがきかないときがあります.
そこで丁寧な説明をさせないのではなく最終結論をキー"conclusion", 詳細な説明、推論の過程、根拠、出典をキー"reason"に出力してもらうという作戦を使いました.
回答イメージはこんな感じです.
"conclusion":1.20
"reason":"2024年3月期の受注高は3,259億円で、2025年3月期の計画受注高は3,900億円です。受注高の計画は前期比でどれだけ増加するかを計算するために、次の式を使用します: (2025年3月期計画受注高) / (2024年3月期受注高) = 3,900億円 / 3,259億円 = 1.196。小数第三位を四捨五入すると1.20になります。"
作戦その3
ひとことでいうと「強制わかりませんアンサンブル」です.
LLMは「わからないことはわかりませんと回答してください」とお願いしてもなかなか「わかりません」とは回答してくれません.
今回のコンペではIncorrect(不正解)のペナルティが大きいので回答に自信がないときは「わかりません」と答えてほしいものです.
50問の質問に対してPerfect(正解)が40個,Incorrect(不正解)が10個だとすると (40 - 10) / 50 = 0.6がスコアになります.
50問の質問に対してPerfect(正解)が40個,Missing(わかりません)が10個だとすると (40 - 0) / 50 = 0.8がスコアになります.
どうやったら「わかりません」を導き出せるか無理やり考えたのが「強制わかりませんアンサンブル」です.
Azure OpenAI GPT-4ominiの場合はseedパラメータに乱数シードを設定することができます.
completion_resp = client.chat.completions.create(
model=DEPLOYMENT_ID_FOR_CHAT_COMPLETION,
temperature=0,
seed=SEED,
messages=content
)
異なる乱数を10個くらい用意して同じ質問を乱数を変えて10回くらいLLMを実行すると明らかに回答がばらつく質問があります.
回答がばらついた質問に対しては証言の信ぴょう性に疑問ありと判断し無理やり「わかりません」に変更して回答を作成しました.
Azure OpenAIの感想
- 機能が豊富で高性能
- 個人的には8Kトークンまで扱えるtext-embedding-3-largeが気に入りました
- Azure OpenAI GPT-4ominiは最終回答だけでなくテキストの前処理にも十分活用が可能
- PythonによるAPI実装がシンプルで使い勝手がよい
- 今回のコンペのようにフリーで使える機会があればぜひ申請して使ってみてレポート報告したいと思います
以上.