Databricksのサンプルデータを用いて、Databricksにおけるデータ操作を体感します。
こちらで使用しているノートブックはこちらとなります。こちらのノートブックをインポートして使うこともできます。
Databricksにおけるデータの格納場所
Databricksをデプロイする際にS3の設定を行なっており、Databricksで使用するデータはこちらのS3バケットに格納されます。DatabricksからS3のデータにアクセスする際には、Databricksファイルシステム(DBFS) 経由でアクセスすることになります。DBFSを利用することで、S3のURLなどを意識することなしに、フォルダー、ファイルの概念でファイルを操作することができます。

DBFSのアクセス権に関する重要な情報
DBFSルートを除き、DBFSにマウントされたオブジェクトストレージのオブジェクトに対してすべてのユーザーが読み書きのアクセス権を持ちます。
しかし、インスタンスプロファイルを用いてマウントが作成されている場合、IAMロールが許可するユーザーのみがアクセス権を持ち、当該インスタンスプロファイルを使用するように設定されたクラスターのみがアクセスすることができます。このため、インスタンスプロファイルを用いて作成されたマウントにはDBFS CLIでアクセスすることはできません。
インスタンスプロファイルを用いたS3バケットのマウントに関しては、DBFSを通じたS3バケットへのアクセスをご覧ください。
参考資料
データ操作用ノートブックを作成する
注意
画面が日本語になっていない場合は、こちらを参考にしてください。
- Databricksワークスペースにログインします。
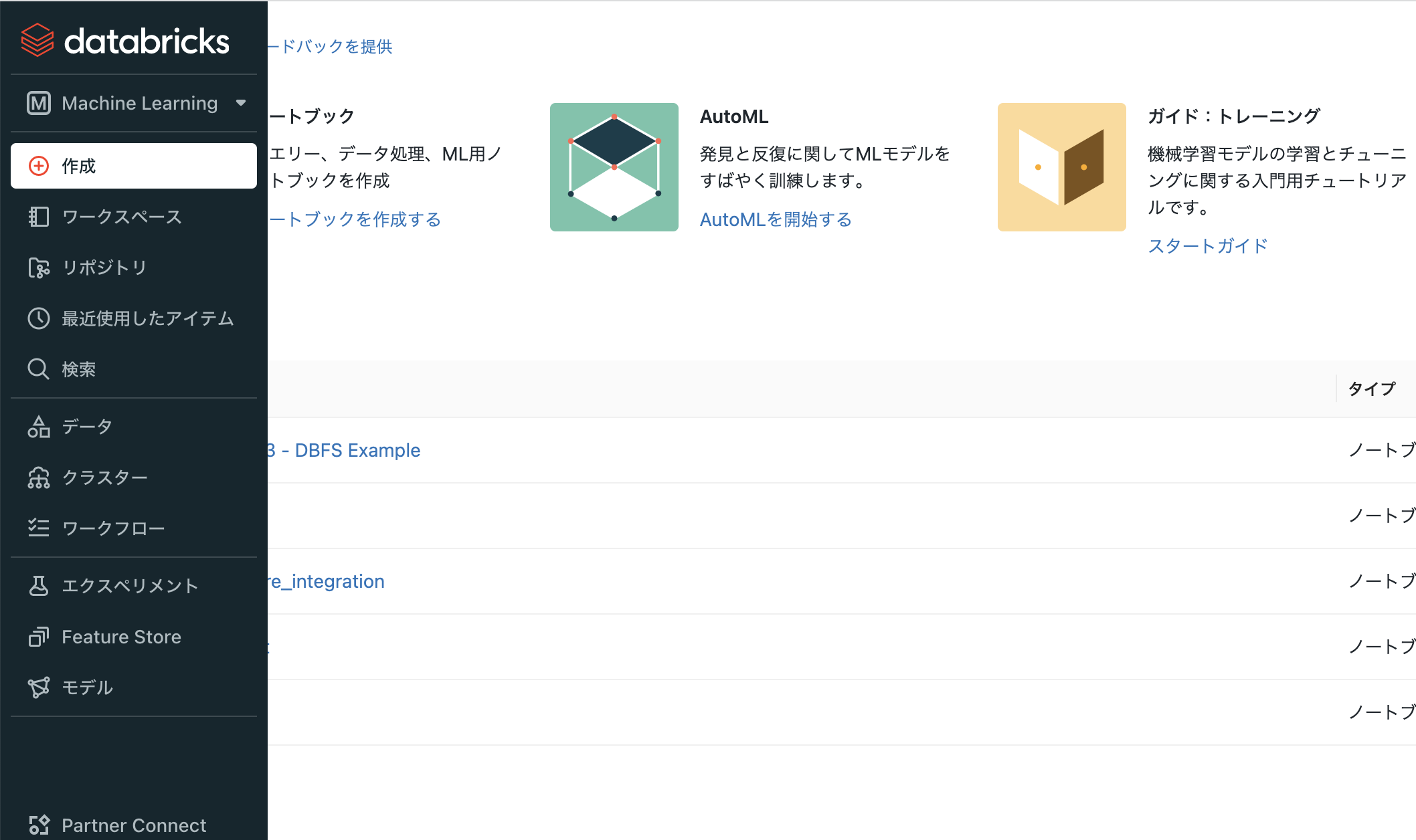
- サイドメニューの作成をクリックします。
-
ノートブックを選択します。
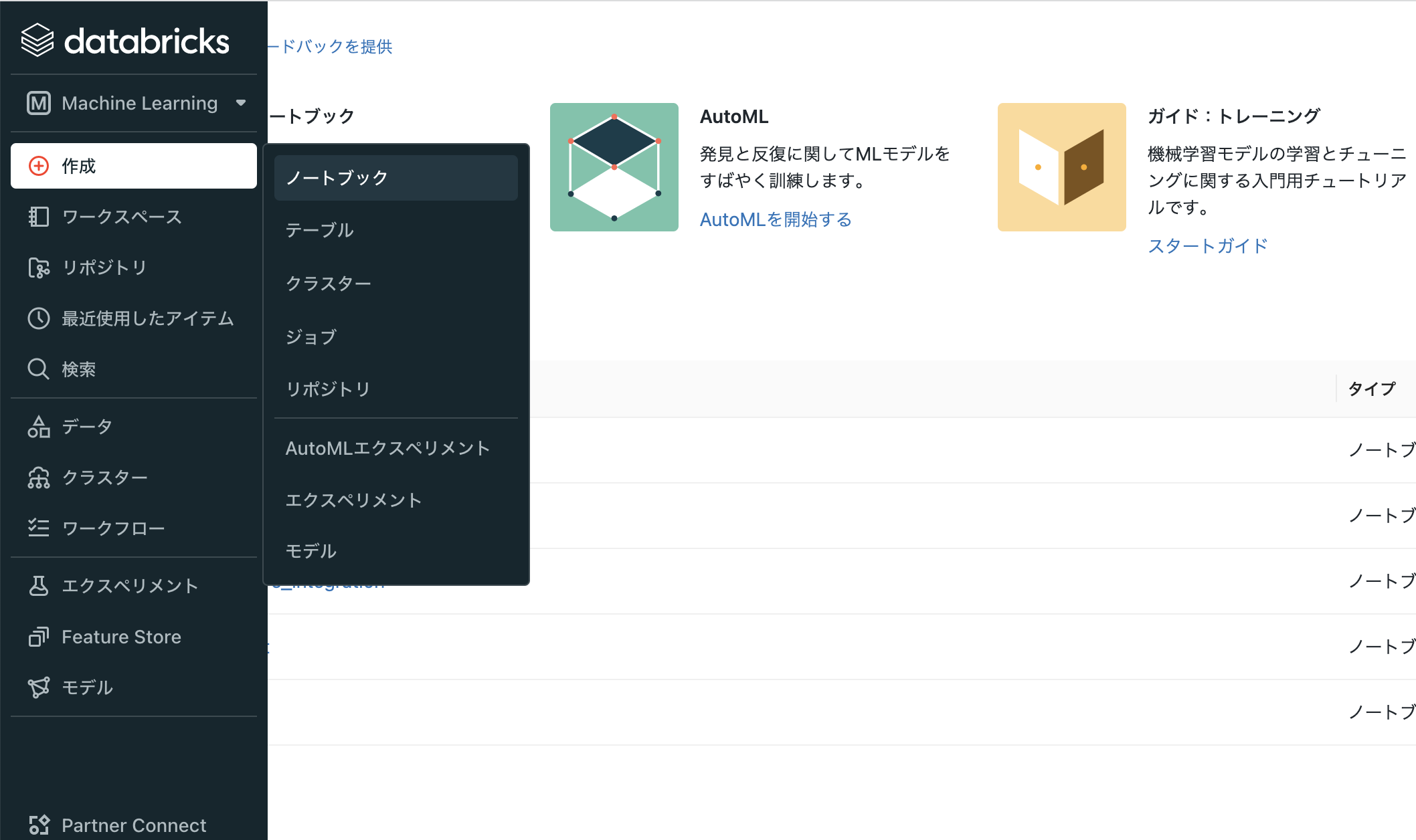
- ノートブック名を入力し、デフォルト言語はPythonとし、クラスターでは稼働中のクラスターを選択します。なお、後からクラスターを起動することも可能です。
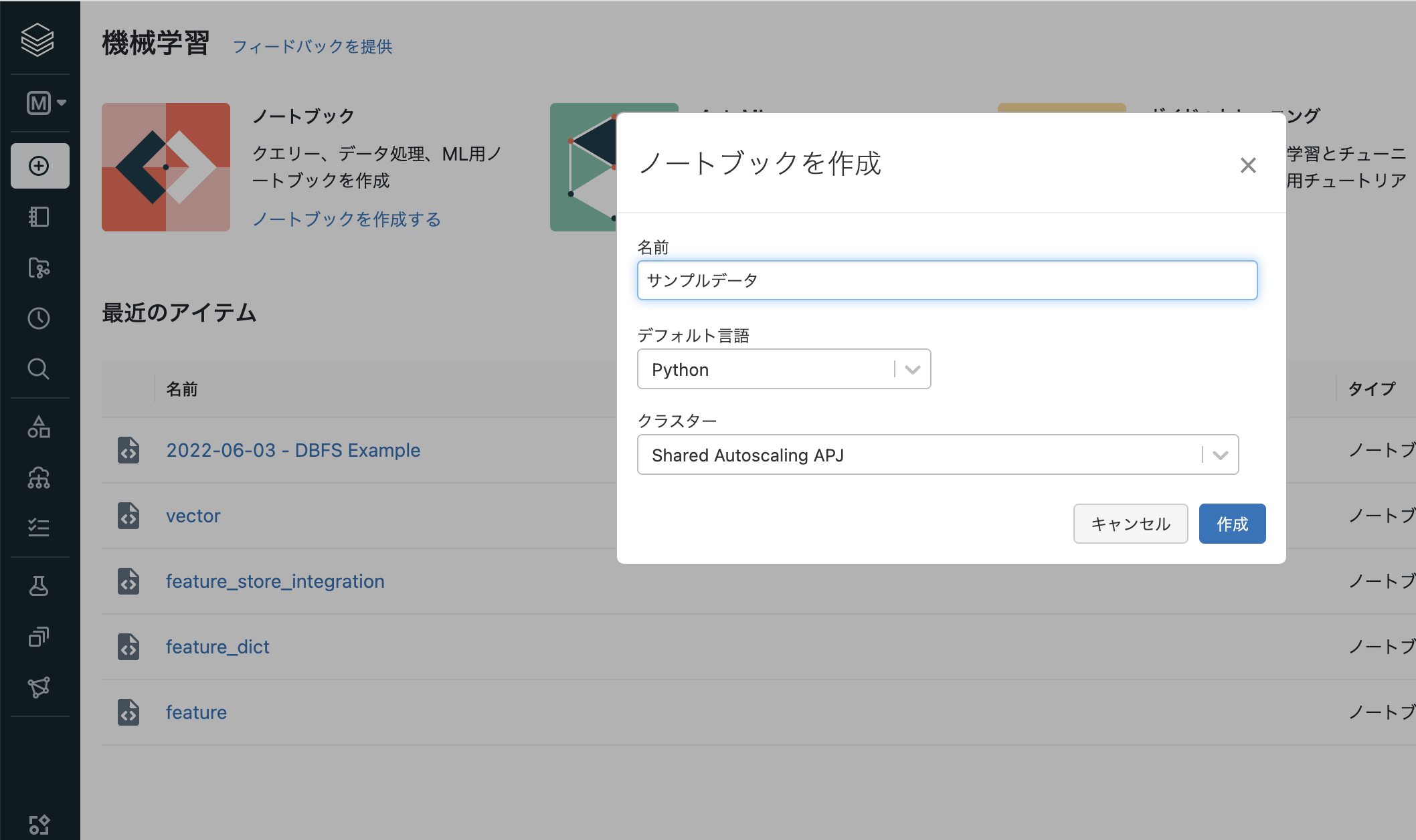
- ホームフォルダにノートブックが作成されます。
ノートブックからサンプルデータにアクセスする
アクセスしたいデータに合わせて、ノートブックに処理を記述していきます。ここではCOVID-19の感染者数のデータにアクセスします。
ノートブックがクラスターにアタッチされていない場合は、稼働しているクラスターにノートブックをアタッチします。ノートブック左上のドロップダウンリストからグリーンのインジケータが表示されているクラスターを選択します。
ノートブックの最初のセルに以下の内容を貼り付けます。以下の%fsはDBFSを操作する際に指定するマジックコマンドとなります。マジックコマンドの詳細に関してはこちらを参照ください。
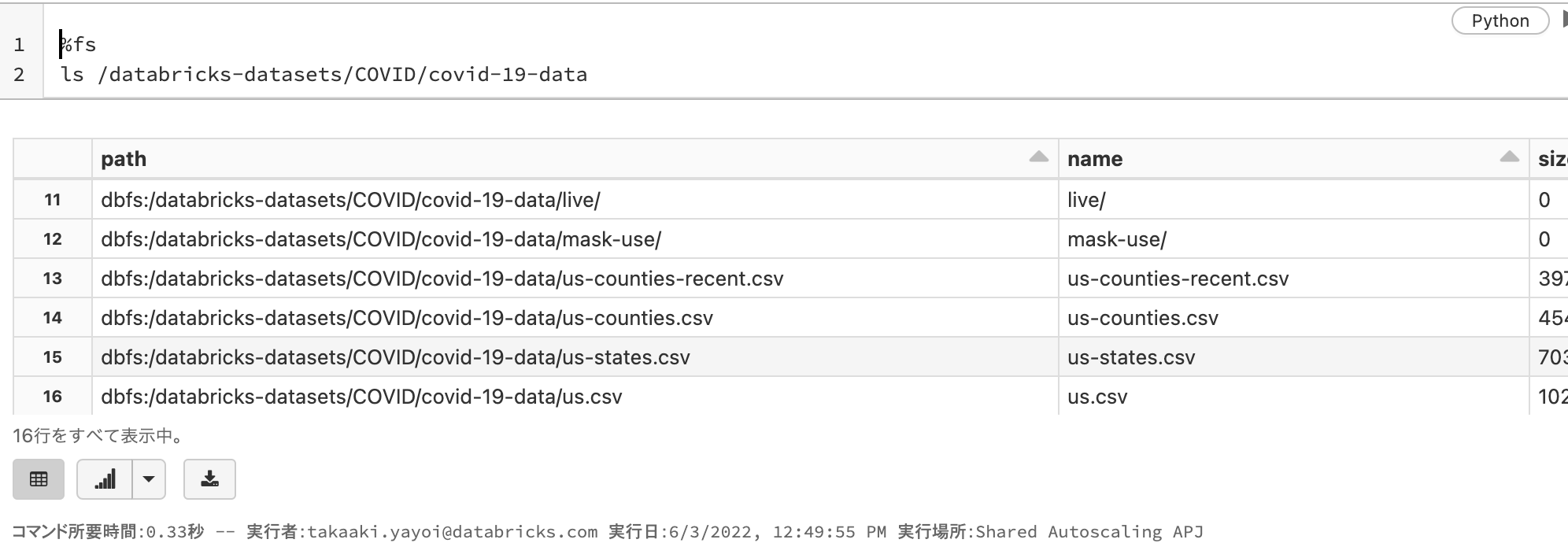
このセルを実行することで、DBFSのパス/databricks-datasets/COVID/covid-19-dataのファイル一覧を表示します。
%fs
ls /databricks-datasets/COVID/covid-19-data
ノートブックにセルを追加して、/databricks-datasets/COVID/covid-19-data/us-states.csvの中身を確認するコマンドを実行します。セルを追加するには、セルの下部にカーソルを持っていくことで表示される + ボタンをクリックします。

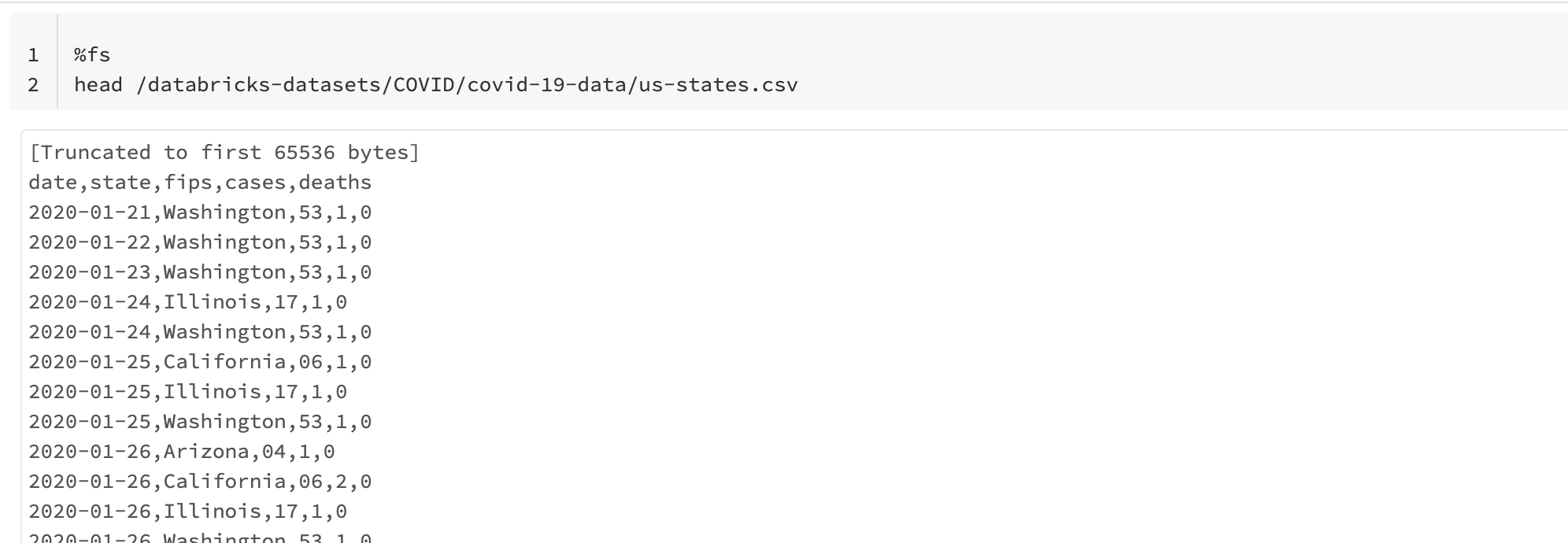
%fs
head /databricks-datasets/COVID/covid-19-data/us-states.csv
こちらを実行することで、CSVファイルの中身を確認することができます。
さらにセルを追加し、以下の内容を記述します。
# ファイルの格納場所とタイプ
file_location = "dbfs:/databricks-datasets/COVID/covid-19-data/us-states.csv"
file_type = "csv"
# CSVのオプション
infer_schema = "false" # スキーマの推定は行わない
first_row_is_header = "true" # 先頭行はヘッダー
delimiter = "," # 区切り文字
# CSVファイルのオプションが適用されます。他のファイルタイプの場合、これらは無視されます。
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
# 読み込んだデータフレームを表示します
display(df)
こちらを実行することで、サンプルデータをデータフレームに読み込むことができます。
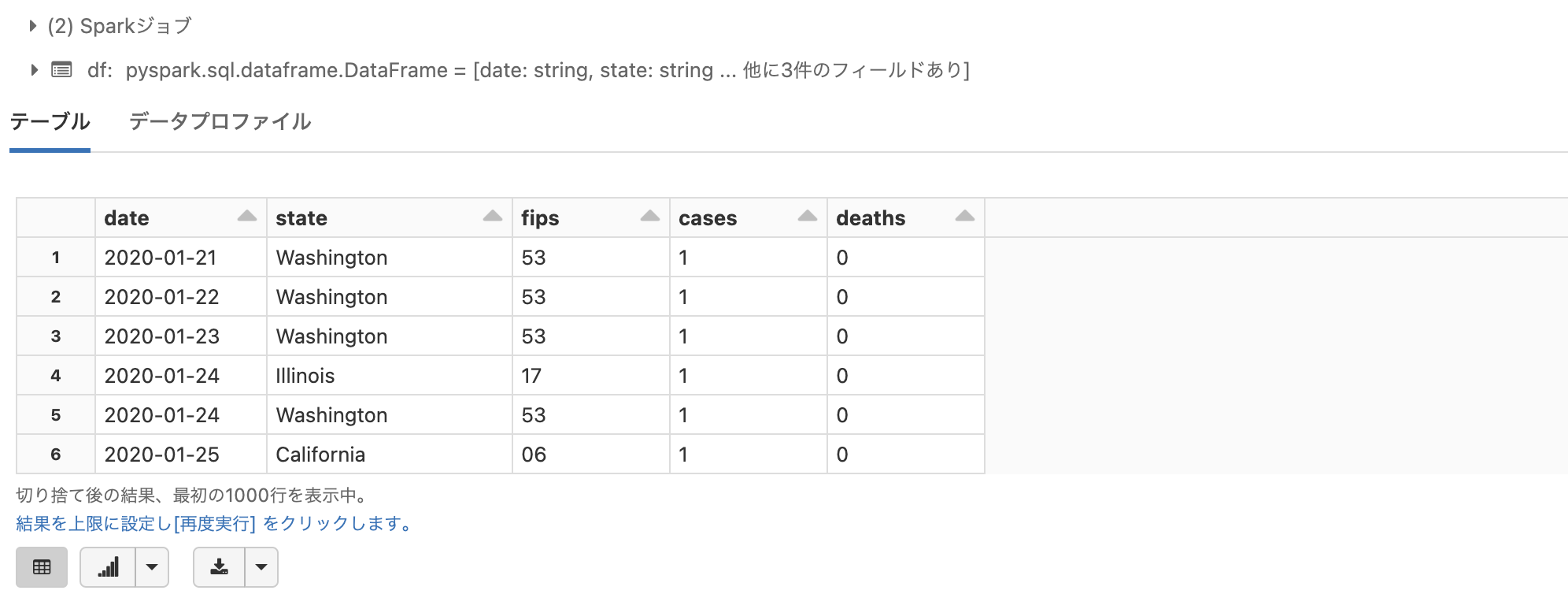
displayを用いてデータフレームを表示すると、結果の並び替えや結果からグラフを表示することも可能です。表示結果の下に表示される表とグラフマークのボタンで表示を切り替えることができます。
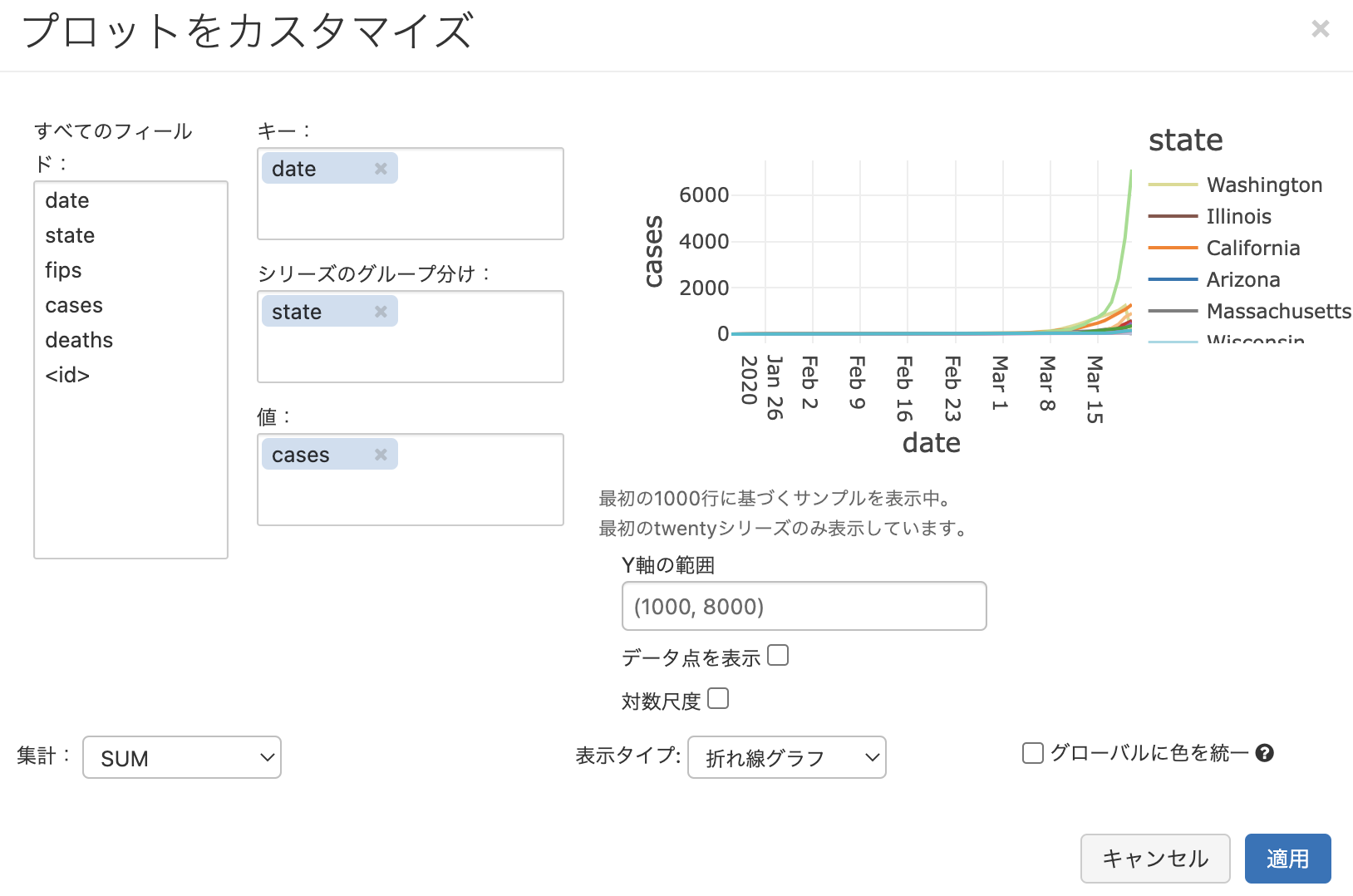
グラフボタンを押した後に表示されるプロットオプションで、以下のように設定をしてみます。
- キー:
date - シリーズのグループ分け:
state - 値:
cases - 表示タイプ: 折れ線グラフ
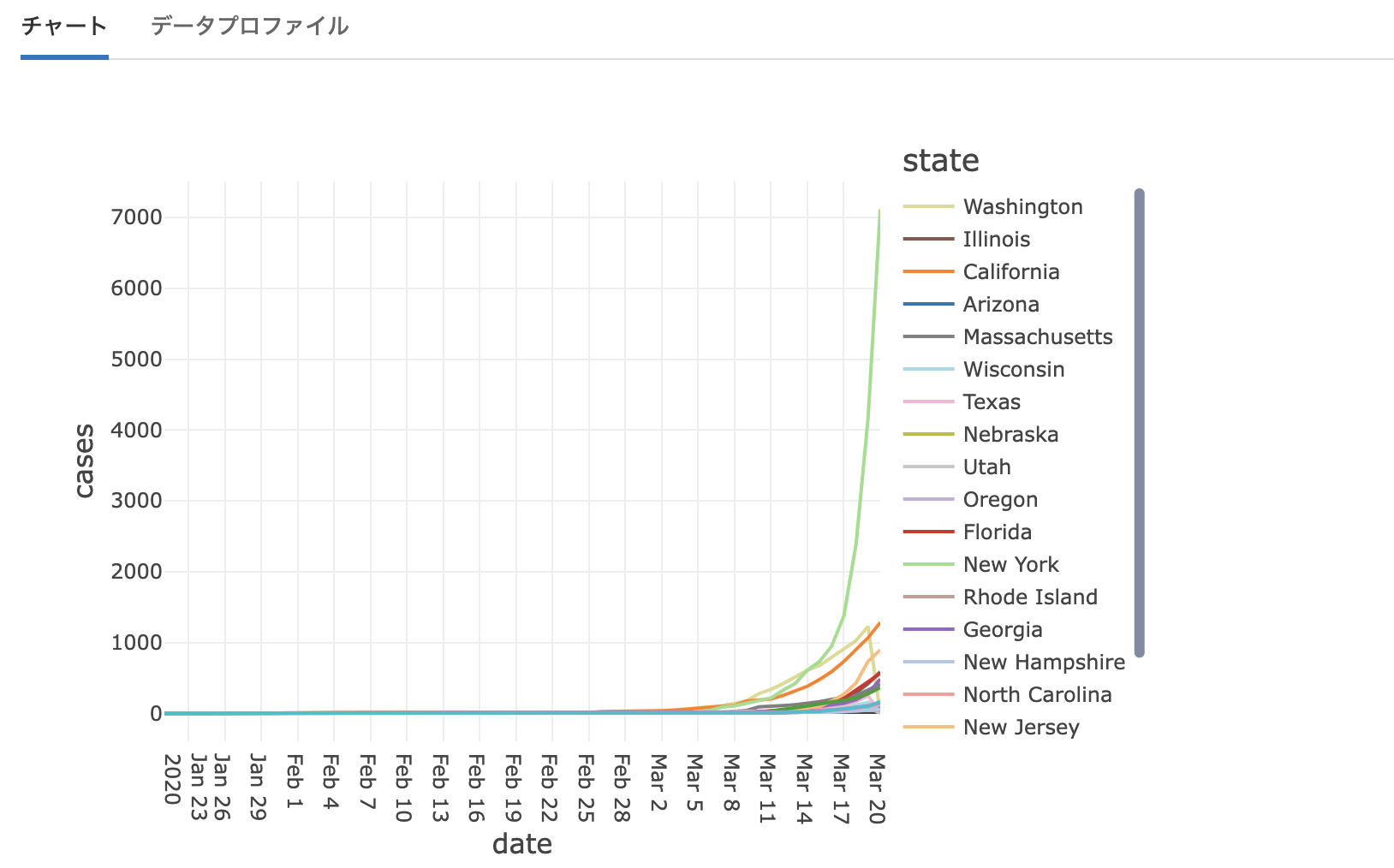
これで、州ごとの感染者数の時系列変化を示す折れ線グラフを表示することができます。表形式に戻すには表マークのボタンを押します。この可視化機能を活用することで、クイックにデータの傾向を把握することができます。他のプロットオプションも試してみてください。
一時ビューの作成
SQLをメインで使用してデータの操作を行いたい場合には、createOrReplaceTempViewを用いてデータフレームを一時ビューに登録するのが便利です。
# ビューの作成
temp_table_name = "usstates"
df.createOrReplaceTempView(temp_table_name)
一時ビューとして登録することで、SQLセルからさまざまな操作を行えるようになります。
%sql
/* 作成した一時ビューをSQLセルでクエリーします */
select * from `usstates`
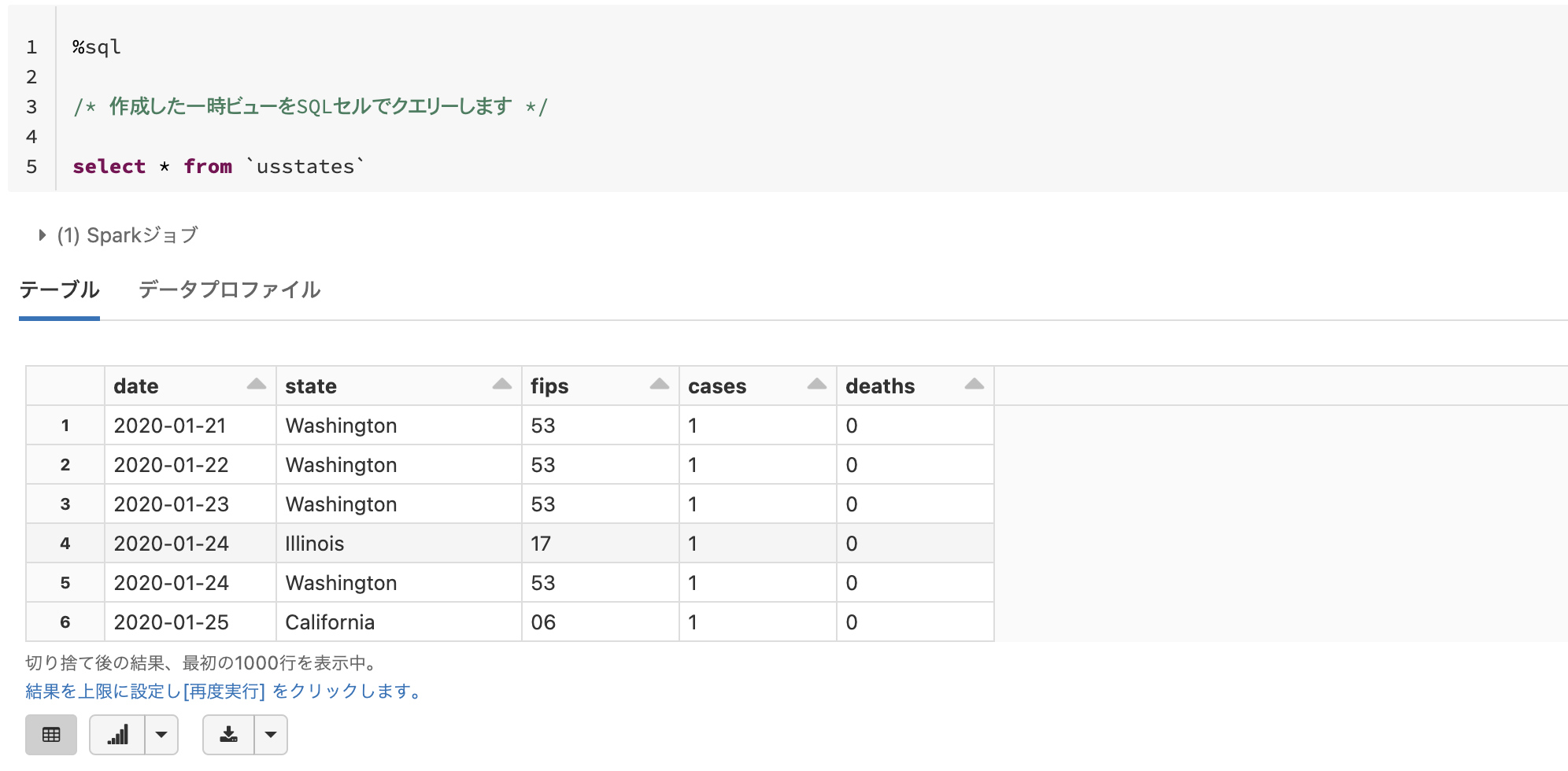
この一時ビューは上のコマンドを実行したノートブックからのみアクセスすることができます。また、クラスターが停止すると削除されます。
テーブルの永続化
他のユーザーもテーブルにクエリーできるようにするには、上のデータフレームからテーブルを作成することもできます。データベースにテーブルとして保存することで、テーブルは永続化され、クラスターを再起動してもデータにアクセスでき、他のユーザーのノートブックからもアクセスできるようになります。
# 他のテーブルと重複しない名前を指定します
permanent_table_name = "taka_usstates"
df.write.format("parquet").saveAsTable(permanent_table_name)
このようにすることでテーブルが永続化され、永続化されたテーブルはサイドメニューのデータから確認することができます。
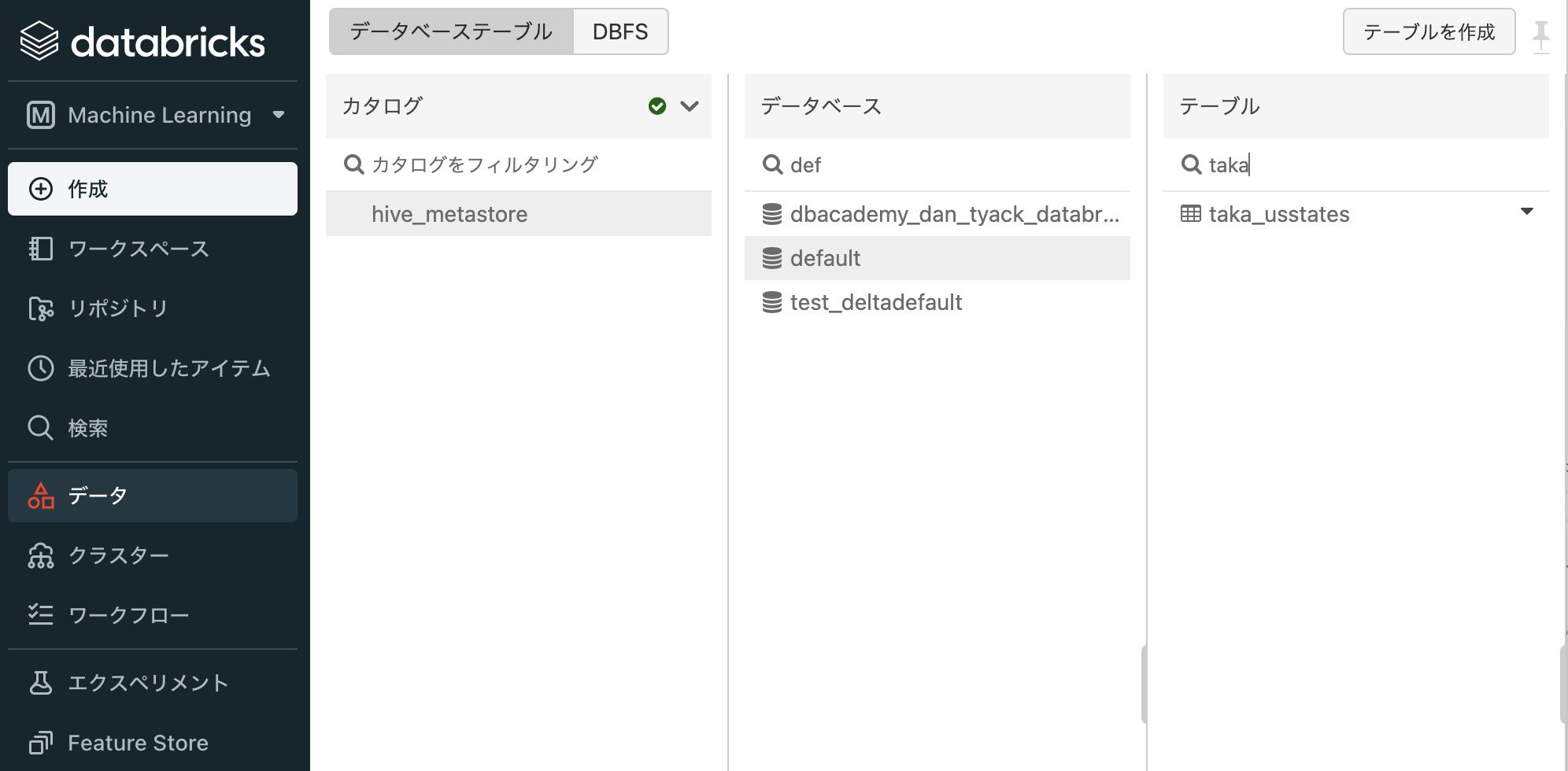
注意
上の例では、データベースを明示的に指定しないので、デフォルトのデータベースdefaultの中にテーブルが作成されます。必要に応じて別のデータベースを作成し、その中にテーブルを保存してください。詳細はDatabricksにおけるデータベースおよびテーブルをご覧ください。
クリーンアップ
永続化したテーブルを削除するにはDROP TABLEを実行します。
%sql
-- クリーンアップ
DROP TABLE taka_usstates;
この他にも/databricks-datasetsの下には、以下のように数多くのサンプルデータがありますので、色々試してみてください!
-
/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv: ダイアモンドデータセット -
/databricks-datasets/flights/departuredelays.csv: フライトデータセット -
/databricks-datasets/bikeSharing/data-001/day.csv: バイクシェアリングデータセット
ファイルの詳細はディレクトリ配下のREADME.mdなどで確認することができます。
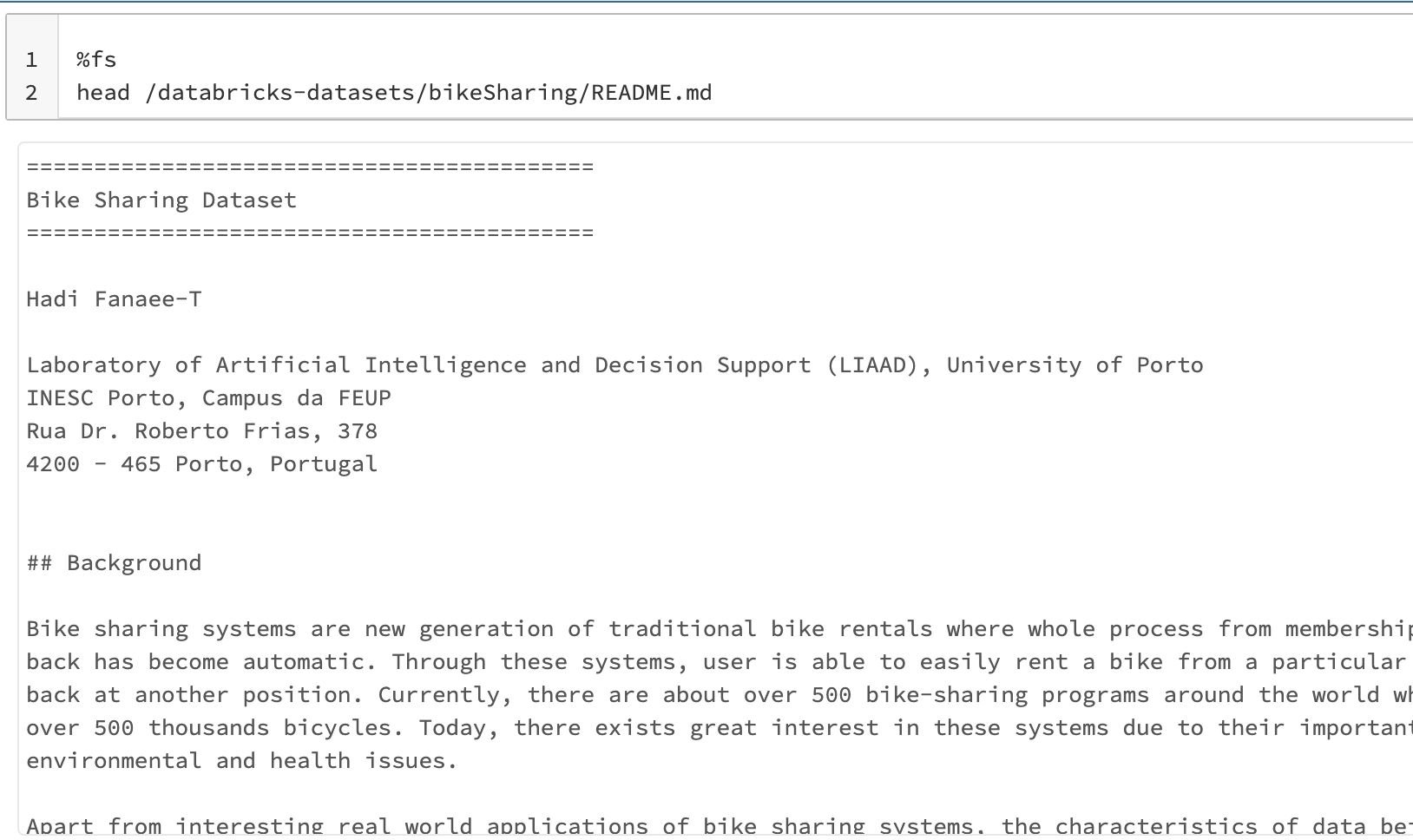
%fs
head /databricks-datasets/bikeSharing/README.md