DatabricksにおけるファイルシステムであるDBFS(Databricksファイルシステム)には最初からサンプルデータが格納されており、これらは/databricks-datasetsのパスに存在します。
本記事では、2022/6/9時点(日々更新されます)で格納されているサンプルデータセットを説明します。データを読み込むサンプルコード、データの中身のスクリーンショットをカバーしています。
以下のコマンドをまとめたノートブックはこちらです。
まず、/databricks-datasetsの中のフォルダを表示するには、ノートブックで以下のコマンドを実行します。
Python
%fs
ls /databricks-datasets/
| パス | 名前 | 説明 | データタイプ |
|---|---|---|---|
| dbfs:/databricks-datasets/COVID/ | COVID/ | COVID-19関連のデータ。定期的に更新される。 | 構造化データ、テキストなど |
| dbfs:/databricks-datasets/README.md | README.md | /databricks-dataset自体の説明 | テキスト |
| dbfs:/databricks-datasets/Rdatasets/ | Rdatasets/ | 元々はRで配布されているデータセット | 構造化データなど |
| dbfs:/databricks-datasets/SPARK_README.md | SPARK_README.md | SparkのReadme | テキスト |
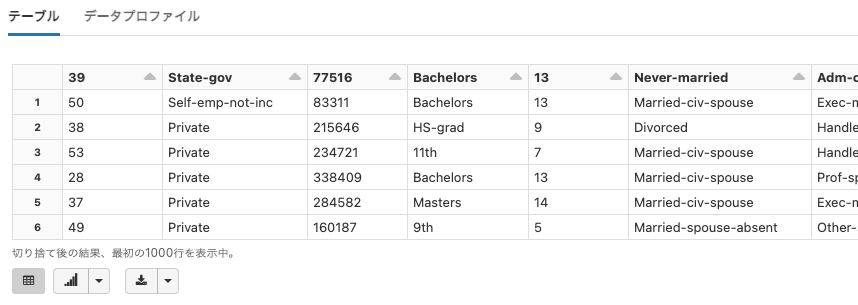
| dbfs:/databricks-datasets/adult/ | adult/ | "Census Income"データセット。国勢調査のデータに基づいて年収を予測するモデルを構築する際に使用される。 | 構造化データ |
| dbfs:/databricks-datasets/airlines/ | airlines/ | アメリカの国内線の発着時刻のデータ | 構造化データ |
| dbfs:/databricks-datasets/amazon/ | amazon/ | Amazonレビューのデータセット | 構造化データ、テキストなど |
| dbfs:/databricks-datasets/asa/ | asa/ | Flight Performance Datasets 1997-2008 | 構造化データ |
| dbfs:/databricks-datasets/atlas_higgs/ | atlas_higgs/ | Dataset from the ATLAS Higgs Boson Machine Learning Challenge 2014 http://opendata.cern.ch/record/328 | 構造化データ |
| dbfs:/databricks-datasets/bikeSharing/ | bikeSharing/ | Bike Sharing Dataset: バイクシェアリングの実績および気候 | 構造化データ |
| dbfs:/databricks-datasets/cctvVideos/ | cctvVideos/ | カメラから取得した動画、静止画 | 動画、画像 |
| dbfs:/databricks-datasets/credit-card-fraud/ | credit-card-fraud/ | クレジットカードトランザクションデータ | 構造化データ |
| dbfs:/databricks-datasets/cs100/ | cs100/ | 英語テキスト、ログデータなど | テキスト、準構造化データ |
| dbfs:/databricks-datasets/cs110x/ | cs110x/ | 映画のレビュー | テキスト |
| dbfs:/databricks-datasets/cs190/ | cs190/ | millionsong.txt, neuro.txt https://github.com/theofpa/datascience/tree/master/spark/data/cs190 | 構造化データ |
| dbfs:/databricks-datasets/data.gov/ | data.gov/ | Data.govデータセット | 構造化データ |
| dbfs:/databricks-datasets/definitive-guide/ | definitive-guide/ | Spark Definitive Guideで使用されているデータセット | さまざま |
| dbfs:/databricks-datasets/delta-sharing/ | delta-sharing/ | Delta Sharingサンプルデータセット | 構造化データ |
| dbfs:/databricks-datasets/flights/ | flights/ | On-Time Performanceデータセット | 構造化データ |
| dbfs:/databricks-datasets/flower_photos/ | flower_photos/ | 花の画像 | 画像 |
| dbfs:/databricks-datasets/flowers/ | flowers/ | 花のデータを格納しているDeltaテーブル | 構造化データ、画像 |
| dbfs:/databricks-datasets/genomics/ | genomics/ | ゲノムデータ | 準構造化データ |
| dbfs:/databricks-datasets/hail/ | hail/ | hail用データ。サンプル、人口グループ、属性とVCF | 構造化データ |
| dbfs:/databricks-datasets/identifying-campaign-effectiveness/ | identifying-campaign-effectiveness/ | SafeGraph FootTraffic Dataset | 構造化データ |
| dbfs:/databricks-datasets/iot/ | iot/ | IoTセンサーデータ | 構造化データ |
| dbfs:/databricks-datasets/iot-stream/ | iot-stream/ | IOT Device Data(合成) | 構造化データ |
| dbfs:/databricks-datasets/learning-spark/ | learning-spark/ | 書籍Learning Sparkで使用されているデータセット | さまざま |
| dbfs:/databricks-datasets/learning-spark-v2/ | learning-spark-v2/ | MnM Datasetなど | さまざま |
| dbfs:/databricks-datasets/lending-club-loan-stats/ | lending-club-loan-stats/ | 融資データ | 構造化データ |
| dbfs:/databricks-datasets/med-images/ | med-images/ | 病理画像 Camelyon16 Grand Challenge | 画像 |
| dbfs:/databricks-datasets/media/ | media/ | OpenRTB BidStream Sample Dataset | 構造化データ |
| dbfs:/databricks-datasets/mnist-digits/ | mnist-digits/ | MNIST handwritten digits dataset 手書き数字データ | 画像 |
| dbfs:/databricks-datasets/news20.binary/ | news20.binary/ | 20 Newsgroups Dataset 2値分類 | 構造化データ |
| dbfs:/databricks-datasets/nyctaxi/ | nyctaxi/ | NYC Taxi Dataset タクシー乗降記録 | 構造化データ |
| dbfs:/databricks-datasets/nyctaxi-with-zipcodes/ | nyctaxi-with-zipcodes/ | NYC Taxi with Zipcodes Dataset | 構造化データ |
| dbfs:/databricks-datasets/online_retail/ | online_retail/ | オンラインストアの注文データ | 構造化データ |
| dbfs:/databricks-datasets/overlap-join/ | overlap-join/ | 不明 | 構造化データ |
| dbfs:/databricks-datasets/power-plant/ | power-plant/ | Combined Cycle Power Plant Data Set 電力プラントのデータ | 構造化データ |
| dbfs:/databricks-datasets/retail-org/ | retail-org/ | Synthetic Retail Dataset 合成小売データ | 構造化データ |
| dbfs:/databricks-datasets/rwe/ | rwe/ | Simulated Patient Data シミュレートした患者データ | 構造化データ |
| dbfs:/databricks-datasets/sai-summit-2019-sf/ | sai-summit-2019-sf/ | Fire Calls-For-Service 消防署への電話記録 | 構造化データ |
| dbfs:/databricks-datasets/sample_logs/ | sample_logs/ | Webサーバーログのサンプル | 準構造化データ |
| dbfs:/databricks-datasets/samples/ | samples/ | サンプルデータ | さまざま |
| dbfs:/databricks-datasets/sfo_customer_survey/ | sfo_customer_survey/ | 2013 SFO Customer Survey Data Set + Dictionary | 構造化データ |
| dbfs:/databricks-datasets/sms_spam_collection/ | sms_spam_collection/ | SMS Spam Collection | テキスト |
| dbfs:/databricks-datasets/songs/ | songs/ | Sample of Million Song Dataset | 構造化データ |
| dbfs:/databricks-datasets/structured-streaming/ | structured-streaming/ | 構造化ストリーミングのサンプルデータ | 構造化データ |
| dbfs:/databricks-datasets/timeseries/ | timeseries/ | Fire Department Calls for Service | 構造化データ |
| dbfs:/databricks-datasets/tpch/ | tpch/ | TPC-H Data | 構造化データ |
| dbfs:/databricks-datasets/warmup/ | warmup/ | TCP-DS Data | 構造化データ |
| dbfs:/databricks-datasets/weather/ | weather/ | Seattle Temperature Recordings Data Set | 構造化データ |
| dbfs:/databricks-datasets/wiki/ | wiki/ | Wikipediaデータ | テキスト |
| dbfs:/databricks-datasets/wikipedia-datasets/ | wikipedia-datasets/ | Wikipediaデータ | テキスト、構造化データ |
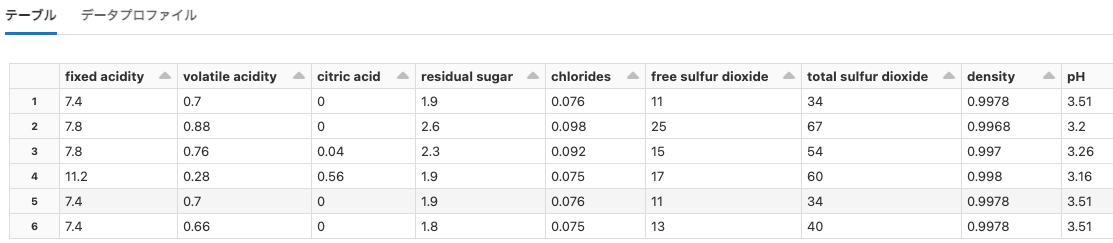
| dbfs:/databricks-datasets/wine-quality/ | wine-quality/ | Wine Quality Data Set | 構造化データ |
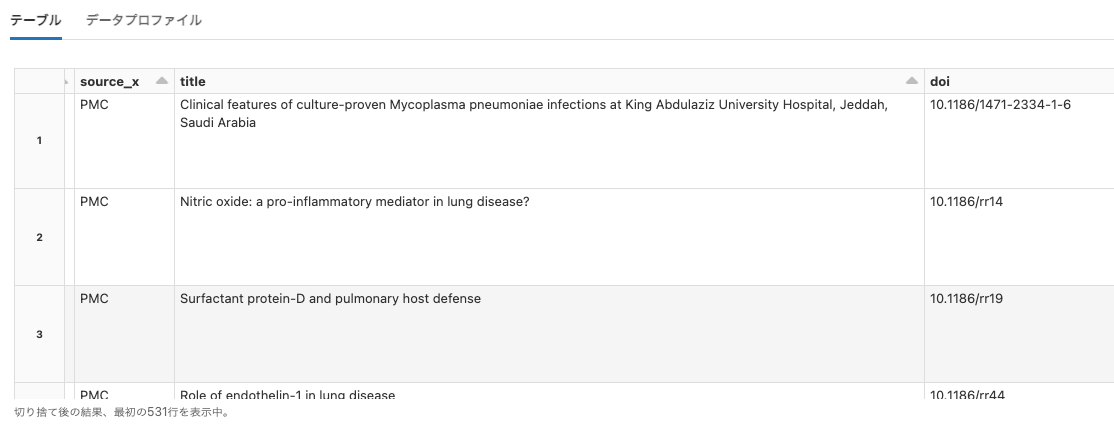
COVID
Python
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/COVID/CORD-19/2021-03-28/metadata.csv")
display(df)
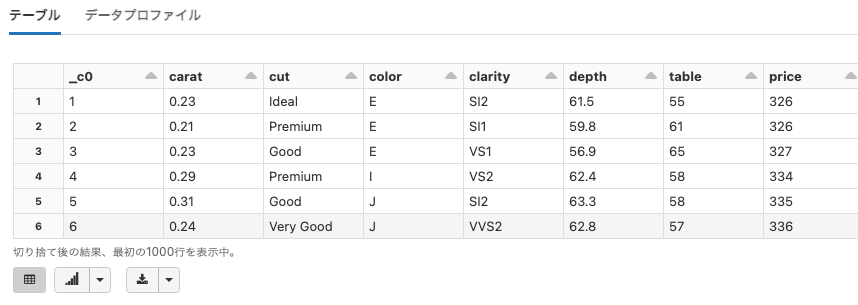
RDatasets
Python
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(df)
adult
Python
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/adult/adult.data")
display(df)
airlines
Python
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/airlines/part-00000")
display(df)
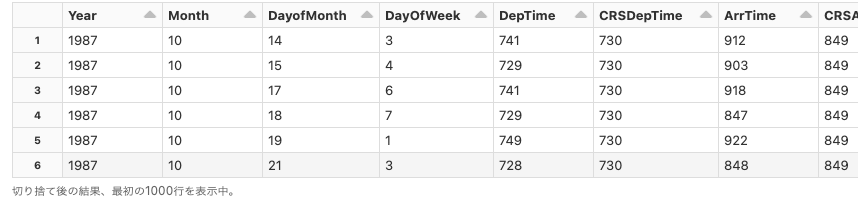
amazon
Python
df = spark.read.format("parquet").option("header", True).load("dbfs:/databricks-datasets/amazon/data20K/")
display(df)
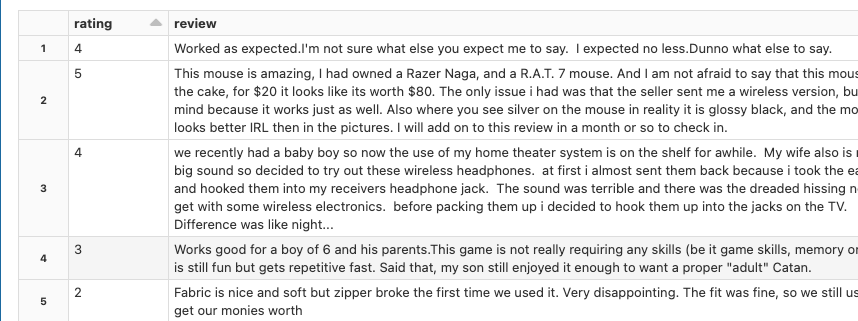
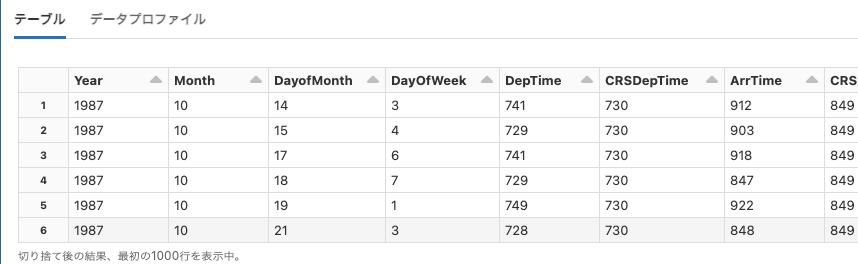
asa
Python
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/asa/airlines/1987.csv")
display(df)
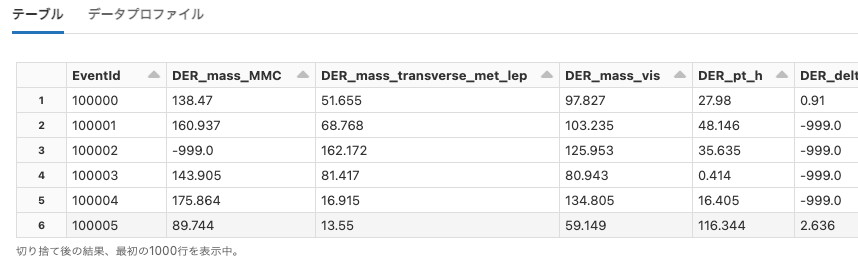
atlas_higgs
Python
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/atlas_higgs/atlas_higgs.csv")
display(df)
bikeSharing
Python
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/bikeSharing/data-001/day.csv")
display(df)
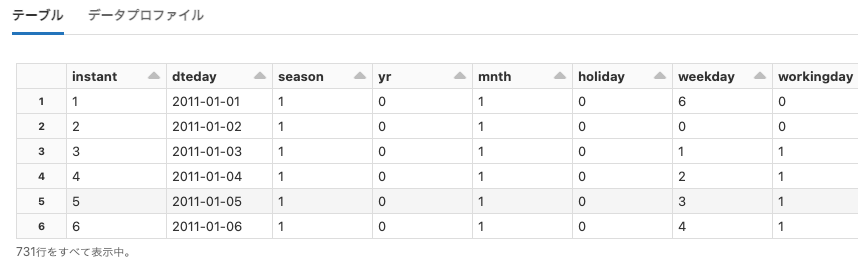
cctvVideos
Python
df = spark.read.format("image").load("dbfs:/databricks-datasets/cctvVideos/train_images/")
display(df)
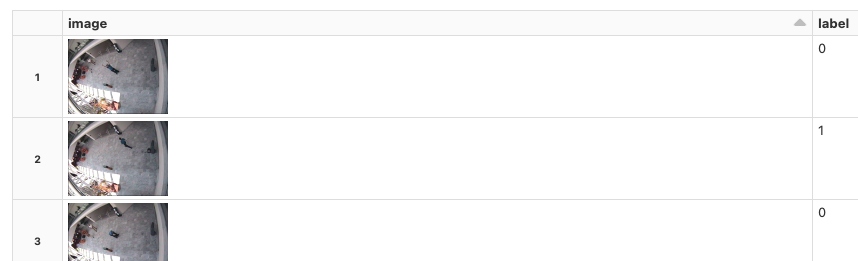
credit-card-fraud
Python
df = spark.read.format("parquet").option("header", True).load("dbfs:/databricks-datasets/credit-card-fraud/data/")
display(df)
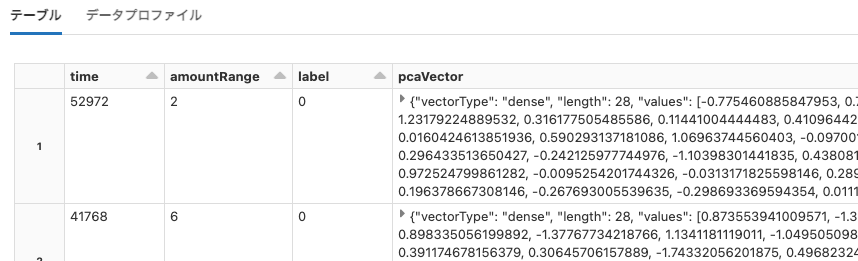
cs100
Python
print(dbutils.fs.head("dbfs:/databricks-datasets/cs100/lab2/data-001/apache.access.log.PROJECT"))
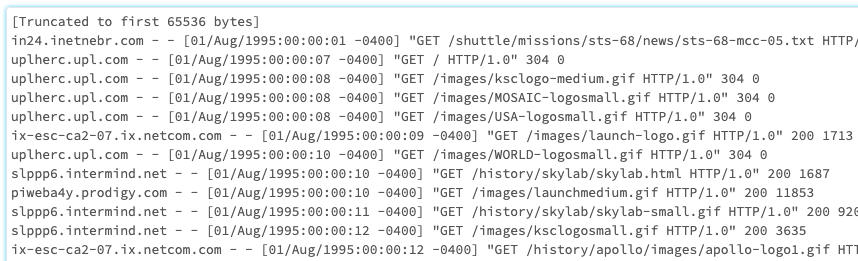
cs110x
Python
df = spark.read.option("header", False).option("delimiter", "::").csv("dbfs:/databricks-datasets/cs110x/ml-1m/data-001/movies.dat")
display(df)
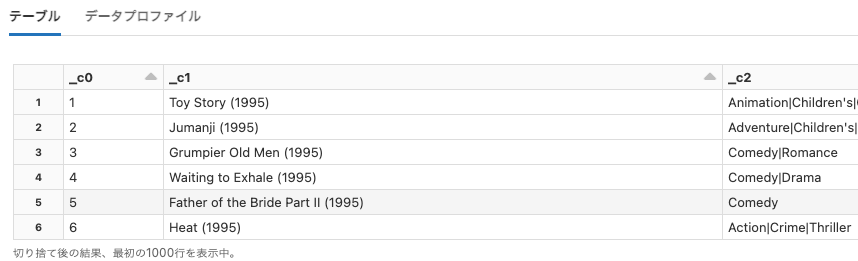
cs190
Python
df = spark.read.option("header", False).csv("dbfs:/databricks-datasets/cs190/data-001/millionsong.txt")
display(df)
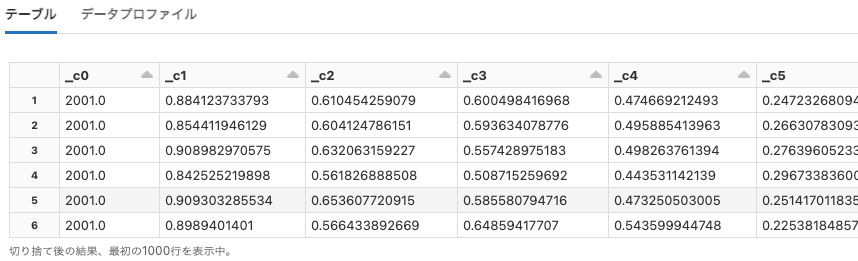
data.gov
Python
df = spark.read.option("header", True).csv("dbfs:/databricks-datasets/data.gov/irs_zip_code_data/data-001/2013_soi_zipcode_agi.csv")
display(df)
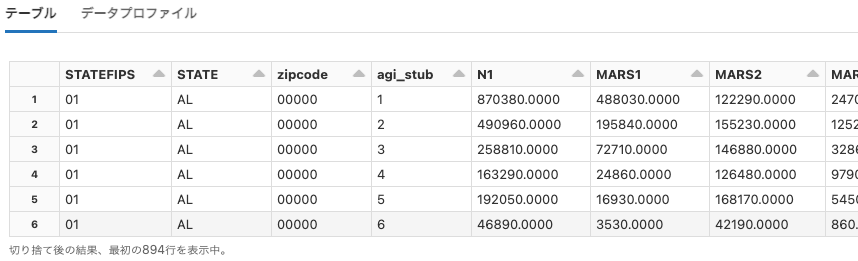
definitive-guide
Python
df = spark.read.format("json").load("dbfs:/databricks-datasets/definitive-guide/data/activity-data/")
display(df)
delta-sharing
Python
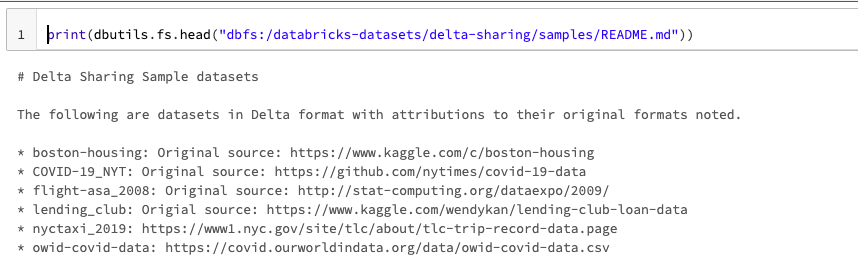
print(dbutils.fs.head("dbfs:/databricks-datasets/delta-sharing/samples/README.md"))
flights
Python
df = spark.read.format("csv").option("header", True).load("dbfs:/databricks-datasets/flights/departuredelays.csv")
display(df)
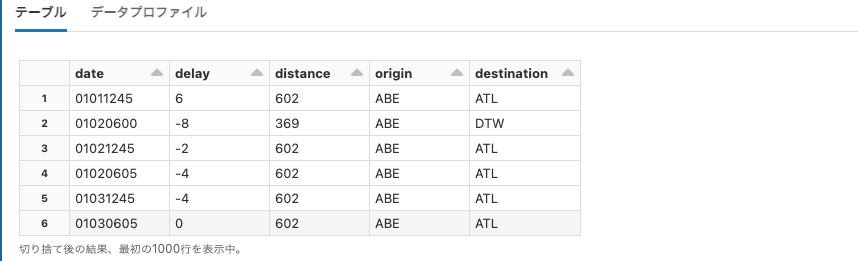
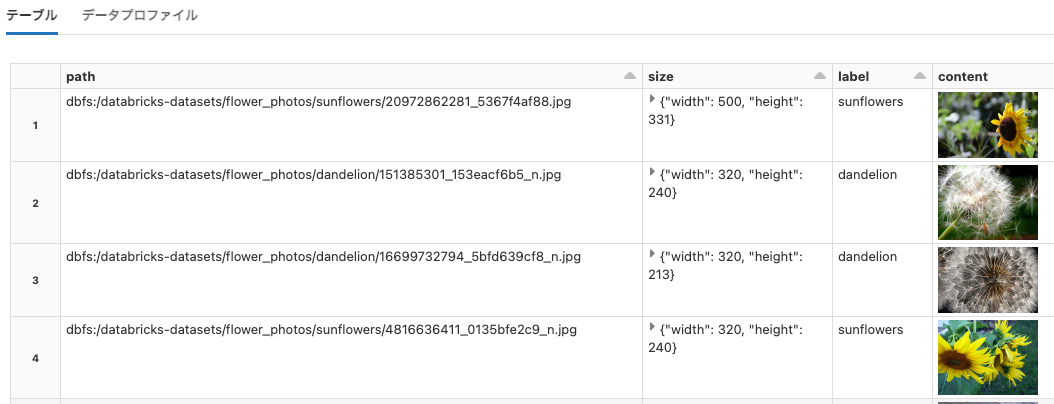
flower_photos
Python
df = spark.read.format("image").load("dbfs:/databricks-datasets/flower_photos/daisy/")
display(df)
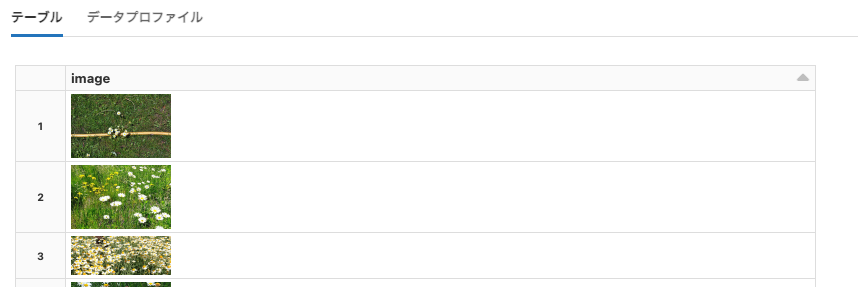
flowers
Python
df = spark.read.format("delta").load("dbfs:/databricks-datasets/flowers/delta/")
display(df)
genomics
Python
df = spark.read.format("parquet").load("dbfs:/databricks-datasets/genomics/1000G/dbgenomics.data/")
display(df)
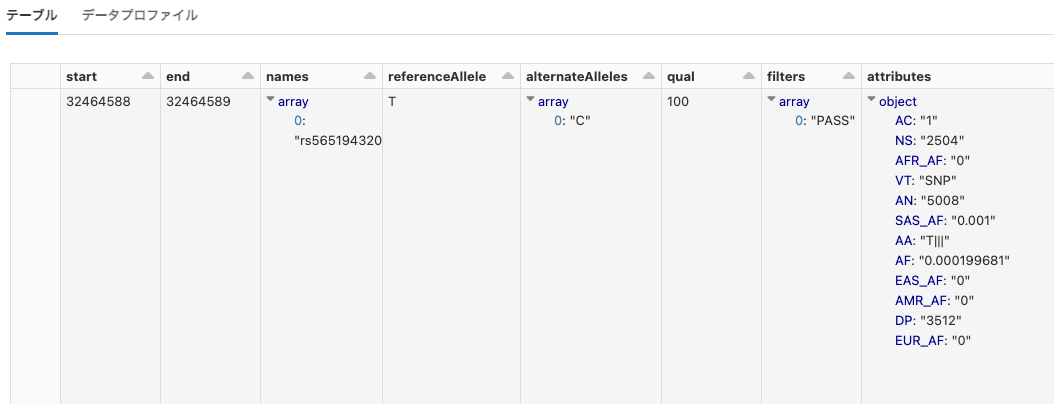
hail
Python
print(dbutils.fs.head("dbfs:/databricks-datasets/hail/data-001/1kg_annotations.txt"))
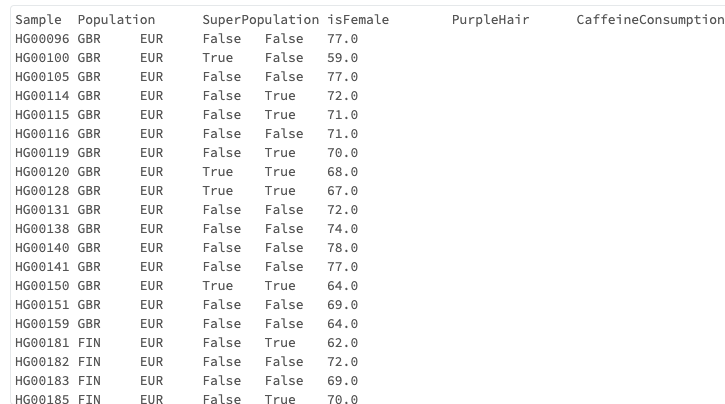
identifying-campaign-effectiveness
Python
df = spark.read.format("csv").option("header", True).load("dbfs:/databricks-datasets/identifying-campaign-effectiveness/subway_foot_traffic/foot_traffic.csv")
display(df)

iot
Python
df = spark.read.format("json").load("dbfs:/databricks-datasets/iot/iot_devices.json")
display(df)
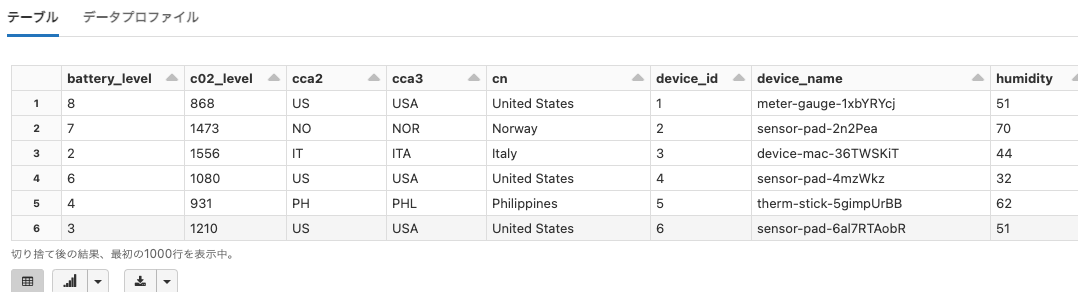
learning-spark
Python
df = spark.read.format("csv").load("dbfs:/databricks-datasets/learning-spark/data-001/favourite_animals.csv")
display(df)
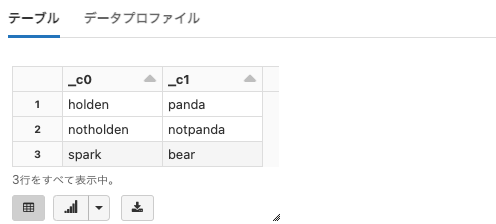
learning-spark-v2
Python
df = spark.read.format("csv").option("header", True).load("dbfs:/databricks-datasets/learning-spark-v2/mnm_dataset.csv")
display(df)
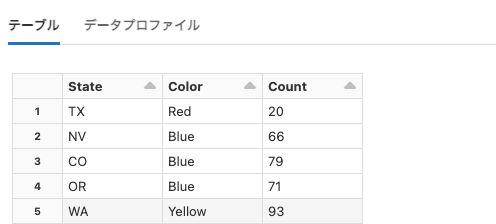
lending-club-loan-stats
Python
df = spark.read.format("csv").option("header", True).load("dbfs:/databricks-datasets/lending-club-loan-stats/LoanStats_2018Q2.csv")
display(df)

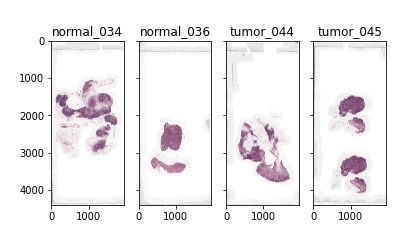
med-images
Python
%pip install openslide-python
Python
WSI_TIF_PATH = "/databricks-datasets/med-images/camelyon16/"
import numpy as np
import openslide
import matplotlib.pyplot as plt
f, axarr = plt.subplots(1,4,sharey=True)
i=0
for pid in ["normal_034","normal_036","tumor_044", "tumor_045"]:
path = '/dbfs/%s/%s.tif' %(WSI_TIF_PATH,pid)
slide = openslide.OpenSlide(path)
axarr[i].imshow(slide.get_thumbnail(np.array(slide.dimensions)//50))
axarr[i].set_title(pid)
i+=1
display()
media
Python
print(dbutils.fs.head("dbfs:/databricks-datasets/media/rtb/raw_incoming_bid_stream/bidRequestSample.txt"))

mnist-digits
Python
print(dbutils.fs.head("dbfs:/databricks-datasets/mnist-digits/README.md"))
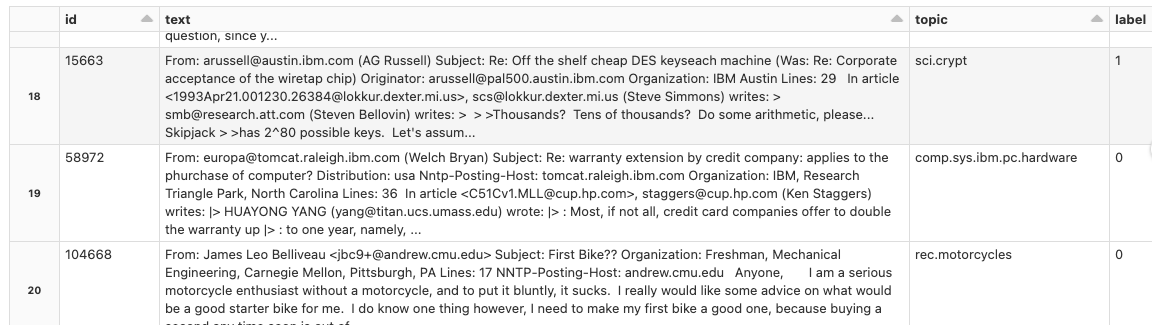
news20.binary
Python
df = spark.read.format("parquet").load("dbfs:/databricks-datasets/news20.binary/data-001/training/")
display(df)
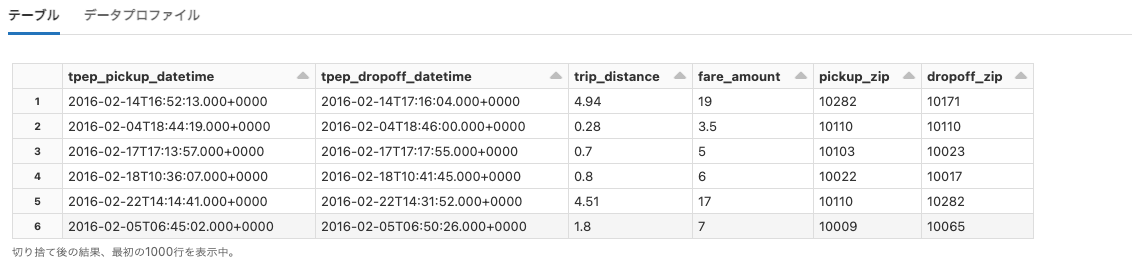
nyctaxi
Python
df = spark.read.format("json").load("dbfs:/databricks-datasets/nyctaxi/sample/json/")
display(df)
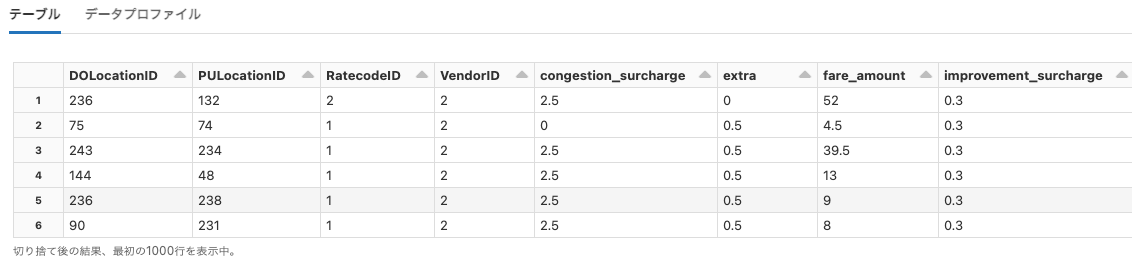
nyctaxi-with-zipcodes
Python
df = spark.read.format("delta").load("dbfs:/databricks-datasets/nyctaxi-with-zipcodes/subsampled/")
display(df)
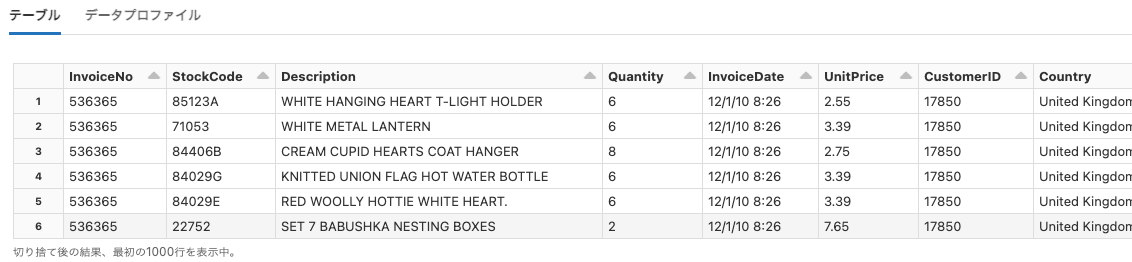
online_retail
Python
df = spark.read.format("csv").option("header", True).load("dbfs:/databricks-datasets/online_retail/data-001/data.csv")
display(df)
overlap-join
Python
print(dbutils.fs.head("dbfs:/databricks-datasets/overlap-join"))

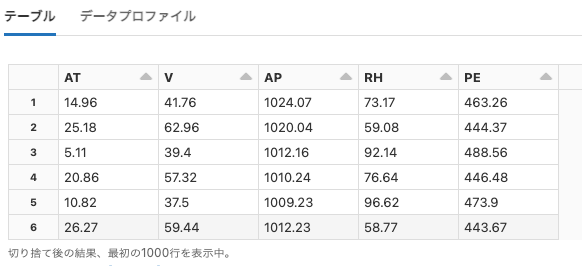
power-plant
Python
df = spark.read.format("csv").option("header", True).option("delimiter", "\t").load("dbfs:/databricks-datasets/power-plant/data/Sheet1.tsv")
display(df)
retail-org
Python
df = spark.read.format("parquet").load("dbfs:/databricks-datasets/retail-org/active_promotions/active_promotions.parquet")
display(df)
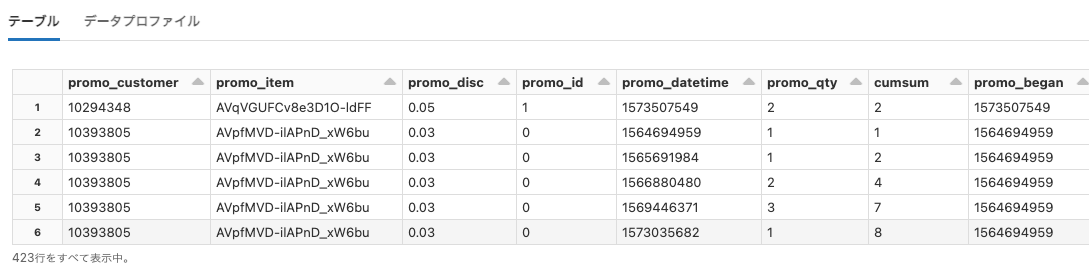
rwe
Python
df = spark.read.format("csv").option("header", True).option("delimiter", ",").load("dbfs:/databricks-datasets/rwe/ehr/csv/allergies.csv")
display(df)
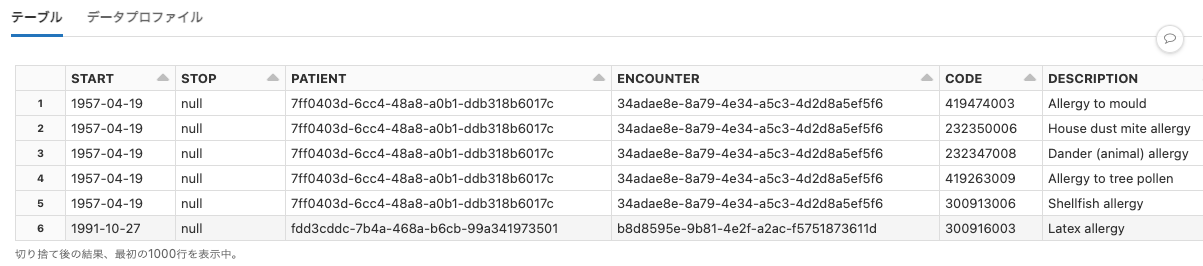
sai-summit-2019-sf
Python
df = spark.read.format("csv").option("header", True).option("delimiter", ",").load("dbfs:/databricks-datasets/sai-summit-2019-sf/fire-calls.csv")
display(df)
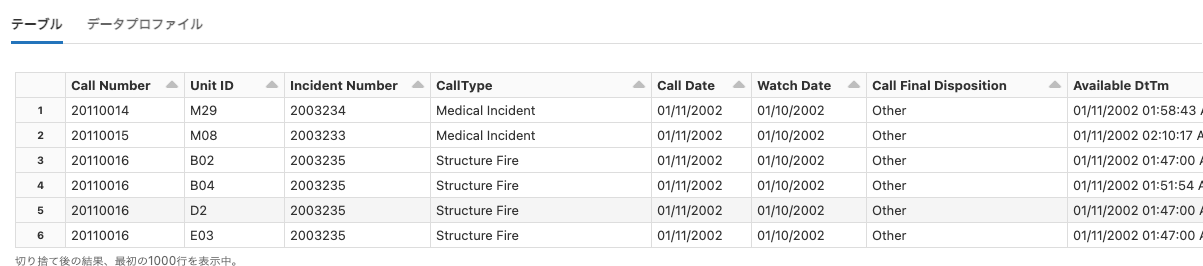
sample_logs
Python
df = spark.read.format("csv").load("/databricks-datasets/sample_logs/")
display(df)
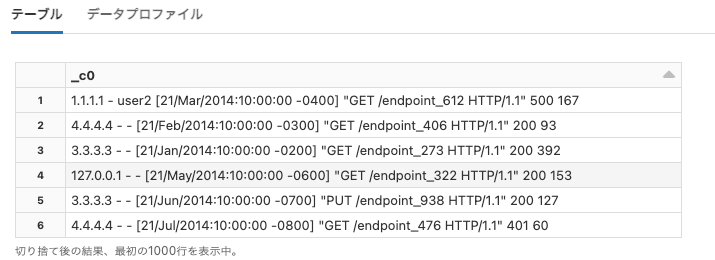
samples
Python
print(dbutils.fs.head("dbfs:/databricks-datasets/samples/data/mllib/gmm_data.txt"))
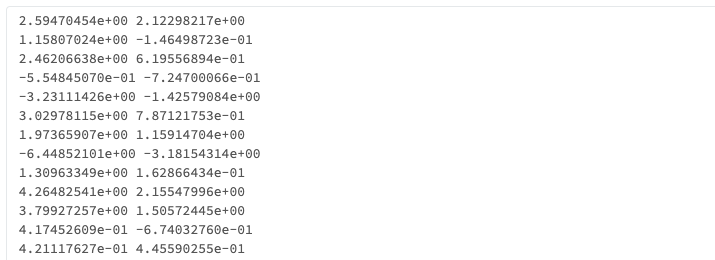
sfo_customer_survey
Python
df = spark.read.format("csv").option("header", True).load("dbfs:/databricks-datasets/sfo_customer_survey/2013_SFO_Customer_Survey.csv")
display(df)
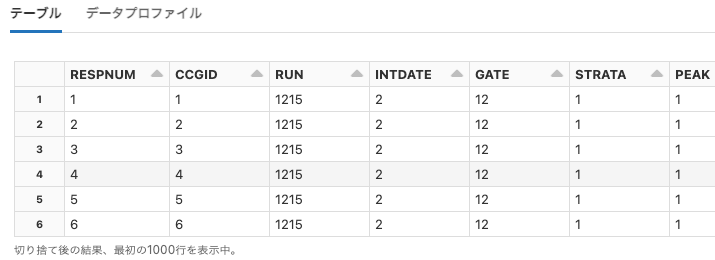
sms_spam_collection
Python
df = spark.read.format("csv").option("header", False).load("dbfs:/databricks-datasets/sms_spam_collection/data-001/smsData.csv")
display(df)
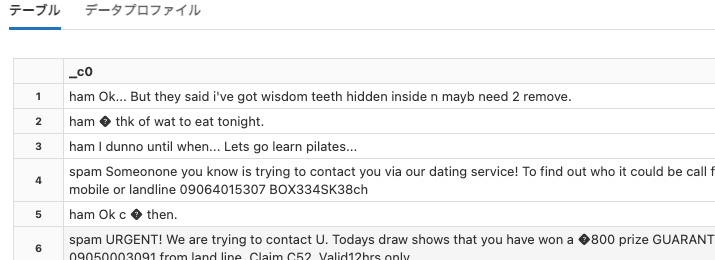
songs
Python
df = spark.read.format("csv").option("header", False).option("delimiter", "\t").load("dbfs:/databricks-datasets/songs/data-001/part-00000")
display(df)
structured-streaming
Python
df = spark.read.format("json").load("dbfs:/databricks-datasets/structured-streaming/events/file-0.json")
display(df)
timeseries
Python
df = spark.read.format("csv").option("header", True).option("delimiter", ",").load("dbfs:/databricks-datasets/timeseries/Fires/Fire_Department_Calls_for_Service.csv")
display(df)

tpch
Python
print(dbutils.fs.head("dbfs:/databricks-datasets/tpch/README.md"))

warmup
Python
%fs
ls dbfs:/databricks-datasets/warmup/
weather
Python
df = spark.read.format("csv").option("header", True).option("delimiter", ",").load("dbfs:/databricks-datasets/weather/high_temps")
display(df)
wiki
Python
df = spark.read.format("csv").load("dbfs:/databricks-datasets/wiki/")
display(df)
wikipedia-datasets
Python
df = spark.read.format("json").load("dbfs:/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/")
display(df)
wine-quality
Python
df = spark.read.format("csv").option("header", True).option("delimiter", ";").load("dbfs:/databricks-datasets/wine-quality/winequality-red.csv")
display(df)