Databricksに入社してから約2年になりますが、最初の壁となったのはDatabricksでファイルを読み書きする際にパスをどう指定すればいいのだろうでした。
以下のような記事を書いてくる中で腹落ちはしましたが、Databricksを初めて触る方には敷居が高いと感じています。
- Databricksファイルシステム(DBFS)
- Databricksにおけるファイルシステム
- DatabricksのFileStore
- Databricksを使い始めたときに感じる疑問 + ベストプラクティス
そこでここでは、絵や実例を駆使して可能な限り分かりやすくファイルシステムを説明してみたいと思います。これでも分かりにくい場合には私の修行がまだ足りないので精進します。
Databricksクイックスタートガイドのコンテンツです。
注意
この記事のスコープにはUnity Catalogを含めていません。Unity Catalog(UC)ではファイルシステムにさらに新たなコンセプトを導入しているので、別途UCもスコープに含めた記事を書く予定です。
なぜ難しいと感じるのか?
改めて何が難しいのかを振り返ってみました。大きく2つあるのではないかと思います。
- ファイルシステムが2種類(Databricksファイルシステム / ドライバーノードのローカルファイルシステム)あることがわかりにくい
- 使っているAPIに応じてパスの書き方を変える必要があることがわかりにくい
本書では、背景を含めて可能な限りわかりやすく説明していきます。
なぜ、Databricksには2種類のファイルシステムがあるのか?
これは単にDatabricksとSparkのアーキテクチャによるところが大きいと思います。以下にDatabricksのアーキテクチャ図を示します。

Databricksファイルシステム
まず、上の図にあるようにDatabricksでファイルの永続化に使用する①のDBFS(Databricksファイルシステム)が存在します。これは、お客さまのクラウドアカウントに構築されるデータプレーン上のオブジェクトストレージ(S3やADLS)を用いて構成される、仮想的なファイルシステムです。
DatabricksファイルシステムはDatabricksワークスペースにマウントされる分散ファイルシステムであり、Databricksクラスターから利用することができます。DBFSは、ネイティブクラウドストレージAPIの呼び出しにマッピングされる最適化FUSE(Filesystem in Userspace)インタフェースを提供するスケーラブルなオブジェクトストレージ上にある抽象化レイヤーです。
Sparkクラスターのドライバーノードのローカルストレージ
そして、Databricksで計算資源を利用する際は、お客さまクラウドアカウント上に構築されるデータプレーン上にDatabricksクラスター(Apache Sparkクラスター)を構成し、これにノートブックをアタッチして処理を実行します。クラスターの実態はAWSであればEC2、AzureであればVMになります。当然これらにはローカルのストレージがアタッチされています。これが上の図の②の部分です。
また、Sparkクラスターはドライバーノードとワーカーノードから構成されていますが、ユーザーは通常ドライバーノードにSparkジョブを投入して結果を受け取るというように、ドライバーノードとやり取りを行います。
これは、Databricksでも同様です。ノートブックをDatabricksにアタッチして処理を実行する際はドライバーノードとやり取りを行い、Sparkの並列分散処理はドライバーノードからワーカーノードに指示を行うことで実行され、結果がドライバーノードに戻され、その結果がノートブックに表示されます。
この処理の過程で②のローカルストレージにファイルを保存することが可能です。
2つのファイルシステムの違い
ここまでで2つのファイルシステムと言っていますが、ファイルの永続化に使えるのは①のDBFSだけです。クラスターのドライバーノードのローカルストレージは揮発性であり、クラスターを停止すると全てが失われます。このことを理解しておかないと、せっかく準備したデータがなくなってしまった!ということになりかねません。
ですので、計算処理過程での中間ファイルなどはローカルストレージに保存し、処理結果のファイルの永続化はDBFSで行うということを意識することが重要となります。
もう一つ重要な違いとして、DBFSはオブジェクトストレージで動作しているので、ランダムアクセスはサポートされていません。DBFSにおいてランダムアクセスが発生するような書き込み(例:zip)を行おうとするとエラーになります。この場合、こちらで説明している様にローカルファイルシステム上でzipファイルを作成してから、DBFSにコピーしてください。
| DBFS | ドライバーノードのローカルストレージ | |
|---|---|---|
| 永続化 | YES | NO |
| ランダムアクセス | NO | YES |
| 容量制限 | なし | あり1 |
| アクセス制御 | あり2 | なし |
なぜ、使っているAPIに応じてパスの記述方法を変えなくてはいけないのか?
上述した通りアクセスする先が違うので、そのことをDatabricksに教えてあげないといけないためです。
ただ、ここで物事をややこしくしているのがコマンドのデフォルトの挙動です。Databricksではファイルを操作する際に使用するAPIが複数存在しています。これらのそれぞれでデフォルトでDBFSにアクセスするのか、ローカルファイルシステムにアクセスするのかが違います。これは、それぞれのAPIの用途からすると自然な話ではあるのですが、初めて操作する際には詰まりやすいポイントだと思います。
大きく分けて、分散ファイルシステム向けコマンドとローカルファイルシステム向けコマンドに分けて考えるといいかと思います。名前の通り、それぞれのファイルシステムがデフォルトになります。
| コマンド(API) | デフォルトのファイルシステム | |
|---|---|---|
| 分散ファイルシステム向けコマンド |
|
分散ファイルシステム(DBFS) |
| ローカルファイルシステム向けコマンド |
|
ドライバーノードのローカルファイルシステム |
そして、Databricksでは上述のコマンドのいずれにおいても、DBFS、ローカルファイルシステムにアクセスすることができるのですが、明示的に指示をしない場合、デフォルトのファイルシステムにアクセスします。
指示する方法は以下の通りです。
- 分散ファイルシステム向けコマンドでローカルファイルシステムにアクセスする場合: パスの先頭に
file:/を追加 - ローカルファイルシステム向けコマンドでDBFSにアクセスする場合: パスの先頭に
/dbfsを追加
ティップス
上の分散ファイルシステム向けコマンドで指定しているfile:/はいわゆるURLにおけるスキームであるのですが、DBFSのスキームdbfs:/も存在しています。分散ファイルシステム向けコマンドでdbfs:/を指定することは必須ではないのですが、プログラムの意図を明確にするために、パスの先頭にdbfs:/を記述することをお勧めします。
実践してみる
マジックコマンド%fs
マジックコマンド%fsはDBFSにアクセスするために使用できるコマンドです。クイックにファイルシステムを操作できます。このコマンドのデフォルトファイルシステムはDBFSです。以下のコマンドはDBFSの/tmpを一覧します。一覧されているpathのスキームがdbfs:/になっていることに注意してください。
%fs ls /tmp
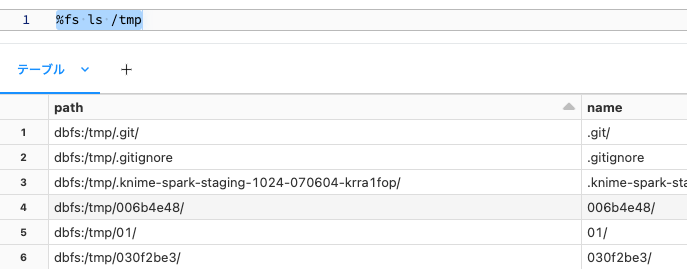
DBFSのスキームはdbfs:/なので、以下のコマンドでも同じ結果となります。
%fs ls dbfs:/tmp
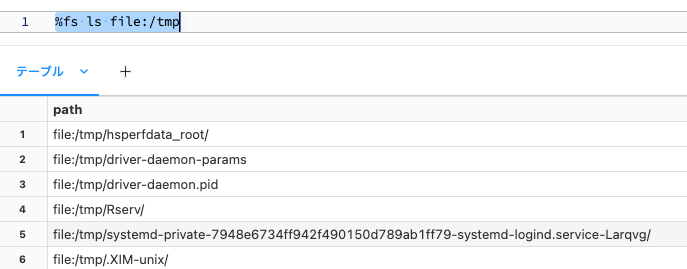
一方、ローカルファイルシステムのスキームfile:/を指定すると、クラスターのドライバーノードのローカルファイルシステムを参照することができます。
%fs ls file:/tmp
マジックコマンド%sh
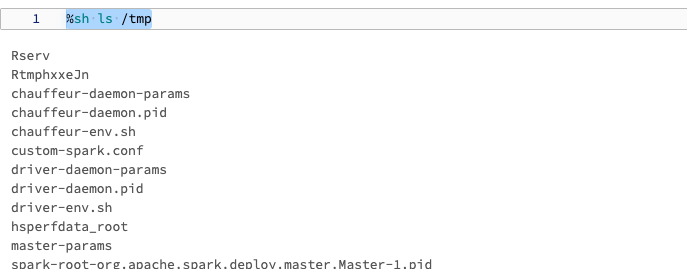
マジックコマンド%shは、クラスターのドライバーノードでシェルスクリプトを実行できるコマンドです。このコマンドはドライバーノードローカルで動作することを前提としているので、このコマンドのデフォルトファイルシステムはローカルファイルシステムです。
%sh ls /tmp
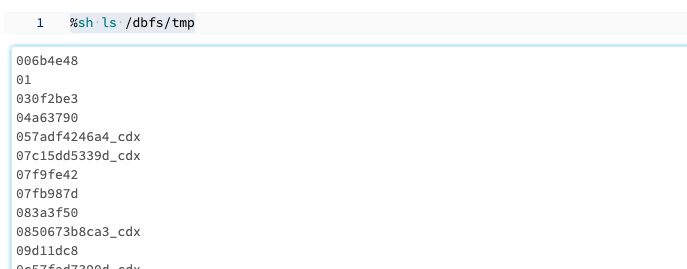
一方、パスの先頭に/dbfsを追加すると、クラスターのドライバーノードのローカルファイルシステムを参照することができます。
%sh ls /dbfs/tmp
なお、%shはwgetなどでデータをクイックにクラスター上に持ってきたい時に使うと便利です。
%sh
wget https://sajpstorage.blob.core.windows.net/yayoi/train.csv
dbutils.fsユーティリティ
dbutils.fsユーティリティはマジックコマンド%fsと同様に、DBFSを操作するためのコマンドを提供しています。Pythonなどのプログラミング言語から呼び出すことができます。このコマンドのデフォルトファイルシステムはDBFSです。
display(dbutils.fs.ls("/tmp"))
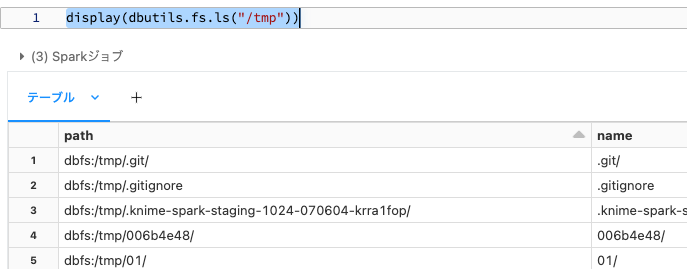
ローカルファイルシステムを参照することも可能です。
display(dbutils.fs.ls("file:/tmp"))
さらには、ローカルファイルシステムとDBFS間でデータをコピーすることもできます。一時的にドライバーノードに保存しておいたファイルを永続化する際にdbutils.fs.cpはよく使います。
dbutils.fs.cp("file:/databricks/driver/train.csv", "dbfs:/tmp/")
ティップス
%shを使う際のデフォルトのカレントパスはfile:/databricks/driver/です。なので、上のwgetで取得したファイルはfile:/databricks/driver/train.csvに保存されています。
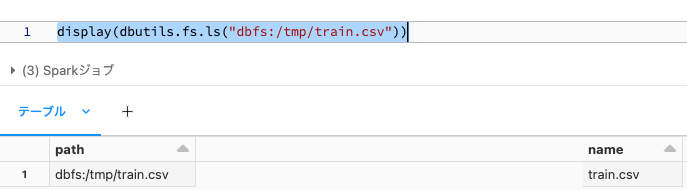
display(dbutils.fs.ls("dbfs:/tmp/train.csv"))
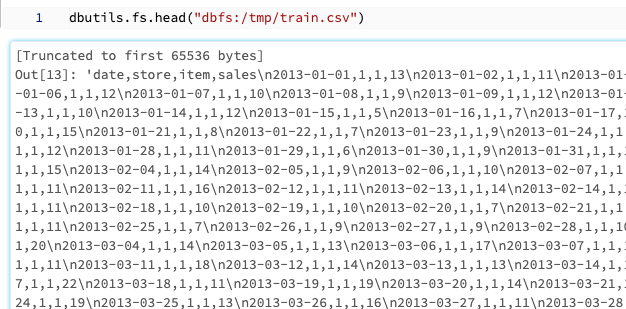
dbutils.fs.headでファイルの中身を確認することもできます。
dbutils.fs.head("dbfs:/tmp/train.csv")
dbutils.fs.rmで削除もできます。
dbutils.fs.rm("dbfs:/tmp/train.csv")

Spark API
PySparkなどSparkのAPIは、分散ファイルシステムを前提としているのでデフォルトファイルシステムはDBFSです。
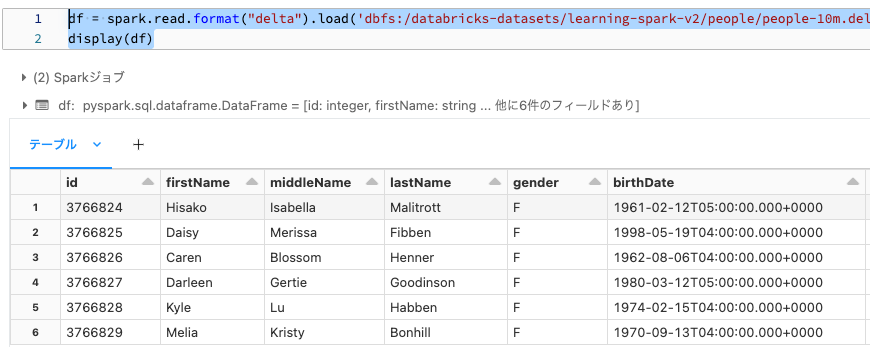
df = spark.read.format("delta").load('dbfs:/databricks-datasets/learning-spark-v2/people/people-10m.delta')
display(df)
ティップス
dbfs:/databricks-datasetsには色々なサンプルデータが格納されています。
なお、Sparkではローカルファイルシステムでのファイルの読み書きはサポートされていないので、DBFSにあるファイルを操作する様にしてください。
pandas API
pandasはローカルファイルシステムを前提としているのでデフォルトファイルシステムはドライバーノードのローカルファイルシステムです。
import pandas as pd
df = pd.read_csv("/databricks/driver/train.csv")
display(df)
file:をパスの先頭に追加した以下のセルでも同じ結果が得られます。
import pandas as pd
df = pd.read_csv("file:/databricks/driver/train.csv")
display(df)
DBFSのファイルを読み込むには、パスの先頭に/dbfsを追加します。
import pandas as pd
df = pd.read_csv("/dbfs/databricks-datasets/wine-quality/winequality-red.csv", sep=";")
display(df)
まとめ
ここまで説明してきたコンセプトは、最初はとっつきにくいところがあると思いますが、慣れると非常に生産性高く作業できる様になります。大事なのは、クラスターは揮発性の計算資源・ストレージ資源であること、どのファイルシステムを操作しているのかを常に意識することです。私はよく以下の様なフローを実行しています。
-
[ローカルファイルシステム]
wgetを使ってサンプルデータのzipをドライバーノードにダウンロード -
[ローカルファイルシステム] ドライバーノードで
unzip -
[ローカルファイルシステム -> DBFS]
dbutils.fs.cpでDBFSにファイルをコピー -
[DBFS]
spark.readでファイルをSparkデータフレームにロード - [DBFS] 処理結果をDBFSに永続化
Databricks 無料トライアル
-
EBSの拡張はサポートしています。 ↩
-
インスタンスプロファイルやIAMクレディンシャルパススルーなどを使用します。よりきめ細かいアクセス制御に関しては、Unity Catalogの使用を検討してください。 ↩