本書では、Databricksを使い始めた段階で迷いやすいポイント、それに対するベストプラクティスをまとめています。随時更新していきます。
Databricksクイックスタートガイドのコンテンツです。
ファイルはどのように管理されているのか?
以下のDatabricksのアーキテクチャ図の赤枠で囲われている2つの領域にデータが保存されます。(1)Databricksファイルシステム(DBFS)と(2)クラスターのローカルファイルシステムです。

Databricksで取り扱うデータファイルは、AWS S3などのオブジェクトストレージで永続化されます。これらのファイルに対しては、Databricksファイルシステム(DBFS)を介してアクセスすることになります。
Databricksファイルシステム(DBFS)は、Databricksワークスペースにマウントされる分散ファイルシステムであり、Databricksクラスターで利用することができます。DBFSはオブジェクトストレージの抽象化レイヤーとして動作し、以下のメリットを提供します。
- 認証情報なしにデータにシームレスにアクセスできるように、オブジェクトストレージ(S3/Azure Blob Storage)などをマウントすることができます。
- ストレージURLではなく、ディレクトリとファイルの文法を用いてオブジェクトストレージを操作することができます。
- ファイルをオブジェクトストレージに永続化するので、クラスターを停止してもデータを失うことはありません。
どのようにファイルパスを指定すればいいのか?
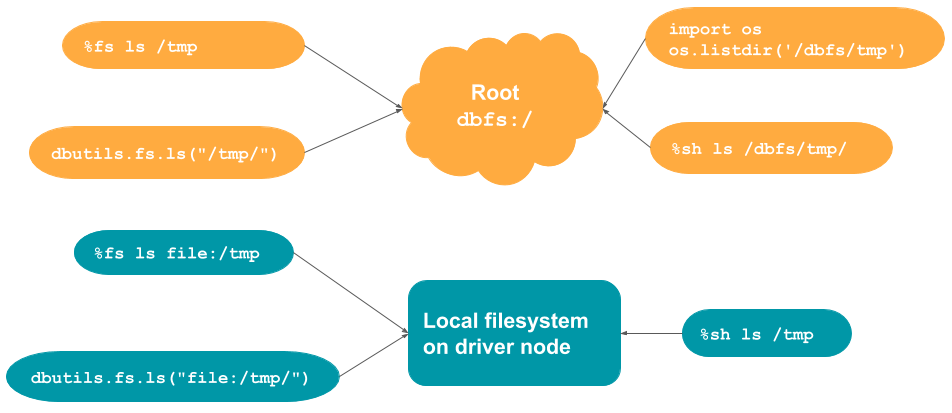
アクセス手段ごとにデフォルトで読みにいくアクセス先が異なるため、パスを指定するには以下の2点に注意する必要があります。デフォルトの挙動を変更するには、以下の表に従ってパスにプレフィクスを追加してください。
- アクセス手段(API/マジックコマンド)
- アクセス先(DBFS/ローカルストレージ)
| アクセス手段 | デフォルトのアクセス先 | DBFSへのアクセス | ローカルストレージへのアクセス |
|---|---|---|---|
%fs |
DBFS | パスにfile:/を追加 |
|
%sh |
ローカルストレージ | パスに/dbfsを追加 |
|
dbutils.fs |
DBFS | パスにfile:/を追加 |
|
os.<command> |
ローカルストレージ | パスに/dbfsを追加 |
|
| Spark API | DBFS | パスにfile:/を追加 |
|
| pandas API | ローカルストレージ | パスに/dbfsを追加 |
ベストプラクティス
- DBFSのファイルパスを指定する際には、デフォルトの挙動でDBFSを参照するAPIであっても、明示的にプレフィクス
dbfs:を追加するようにしてください。コードの可読性が向上します。DBFSにおいてdbfs:/と/は同じ意味となります。
df = spark.read.json('dbfs:/FileStore/people.json')
df.show()
# PythonのファイルシステムAPIを用いてファイルをDBFSに書き込む
with open("/dbfs/tmp/test_dbfs.txt", 'w') as f:
f.write("Apache Sparkは素晴らしい!\n")
f.write("End of example!")
# ファイルの読み込み
with open("/dbfs/tmp/test_dbfs.txt", "r") as f_read:
for line in f_read:
print(line)
DBFSとクラスターのローカルストレージはどう使い分ければいいのか?
ベストプラクティス
-
クラスターを停止すると、クラスターのローカルストレージ上のファイルは失われるので、一時的なファイルの保存場所として使用します。例としては、
wgetで取得したファイルの保存、Tensorflowのログの保存などに使用します。 -
一方、クラスターを停止した後でも利用するファイル、例えばデータセットなどはDBFSに保存します。
-
DBFSではランダムの書き込みをサポートしていません。この場合、ランダム書き込みを必要とするオペレーションはローカルストレージ上で実行し、結果ファイルをDBFSにコピーします。
Pythonimport xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') # ローカルストレージに出力 worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/dbfs/tmp/excel.xlsx') # DBFSにコピー
データベース・テーブルはどのように管理されているのか?
Databricksのデータベースはテーブルの集合体です。Databricksのテーブルは構造化データの集合体となります。Databricksテーブルに対して、Apache Sparkのデータフレームでサポートされているあらゆる操作、フィルター、キャッシュを行うことができます。Spark API、Spark SQLを用いてテーブルに対してクエリーを実行することができます。
テーブルには2種類あります:グローバルテーブルとローカルテーブルです。グローバルテーブルは全てのクラスターからアクセスすることができます。DatabricksはグローバルテーブルをDatabricksが管理するHiveメタストア、あるいは外部のHiveメタストアに登録します。ローカルテーブルはHiveメタストアに登録されず、他のクラスターからはアクセスできません。これは一時ビューとも呼ばれます。
また、Databricksのテーブルは、スキーマを格納するメタデータ情報とデータ本体から構成されています。テーブルを作成する際には、これらメタデータとデータ本体をどのように管理するのか(後述するマネージド/アンマネージドテーブル)を事前に検討する必要があります。
どのようにデータベース・テーブルを作成すればいいのか?
注意
本セクションの内容はUnity Catalogを使用した場合には当てはまりません。
Databricksにおけるデータベース・テーブルを作成する際には、「どこに」作成するのかを検討する必要があります。明示的に場所を指定せずにデータベース・テーブルを作成した場合、データベース・テーブルはDBFSの/user/hive/warehouseに格納され、Databricksによって管理されます。この場合のテーブルをマネージドテーブルと呼びます。一方で明示的に場所を指定すると、データベース・テーブルは指定された場所に作成されます。この場合のテーブルはDatabricksによって管理されていないことからアンマネージドテーブルと呼びます。
以下にそれぞれの作成方法をまとめます。
| タイプ | 作成方法 |
|---|---|
| (マネージド)データベース | LOCATIONを指定せずにCREATE SCHEMAを実行 |
| (アンマネージド)データベース | LOCATIONを指定してCREATE SCHEMAを実行 |
(アンマネージド)データベースでは、データベースの格納場所をユーザーが制御することができます。
| タイプ | 作成方法 |
|---|---|
| マネージドテーブル | OPTIONにPATHを指定せずにCREATE TABLEを実行 |
| アンマネージドテーブル | OPTIONにPATHを指定してCREATE TABLEを実行 |
- マネージドテーブルはメタデータ、データ本体の両方をDatabricksが管理するので、エンドユーザーはデータ本体の場所を意識する必要はありません。SQLの
DROP TABLEを実行すればメタデータ、データ本体の両方が削除されます。 - アンマネージドテーブルでは、Databricksがデータ本体を管理しないため、SQLの
DROP TABLEを実行してもメタデータのみしか削除されないため、明示的にデータ本体を削除する必要があります。一方で、データ本体の格納場所に対して、特定のユーザーにしかアクセスを許可しないと言ったセキュリティ保護を講じることが可能となります。
ベストプラクティス
- POCのようなライトなユースケースにおいては、(マネージド)データベース + マネージドテーブルを使ってください。テーブルに対するSQLの操作で全てが完結します。
- プロダクション段階で、データ本体に対するセキュリティ保護が必要な場合には、(アンマネージド)データベース + マネージドテーブルを使ってください。セキュリティ保護がなされた場所に作成された(アンマネージド)データベースの配下にマネージドテーブルが作成されます。
- さらに、データ本体の場所も制御したい場合には、(アンマネージド)データベース + アンマネージドテーブルを使用してください。
サンプルデータはないのか?
DBFSの/databricks-datasets配下にパブリックなサンプルデータが格納されています。
サンプルノートブックはないのか?
マニュアルの要所要所でサンプルノートブックが添付されています。
日本語化したものをこちらで公開しています。