Access S3 buckets using IAM credential passthrough with Databricks SCIM | Databricks on AWS [2021/12/3時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
プレビュー
本機能はパブリックプレビューです。
IAMクレディンシャルパススルーを用いることで、Databricksへのログインで使用しているアイデンティティを用いて、DatabricksクラスターからS3バケットへの認証を自動で行うことができます。IAMクレディンシャルパススルーをお使いのクラスターで有効化すると、そのクラスターで実行するコマンドはあなたのアイデンティティを用いてS3にデータを読み書きすることができます。IAMクレディンシャルパススルーには、インスタンスプロファイルを用いたS3バケットへのセキュアなアクセスに比べて以下の2つのメリットがあります。
- IAMクレディンシャルパススルーを用いることで、常にデータのセキュリティを保持しながらも、異なるデータアクセスポリシーを持つ複数のユーザーがS3のデータにアクセスする1つのクラスター共有することができます。インスタンスプロファイルは1つのIAMロールとしか関連づけることができません。このため、このロールとロールに割り当てられているデータアクセスポリシーを、Databricksクラスター上の全てのユーザーが共有することになります。
- IAMクレディンシャルパススルーはアイデンティティとユーザーを関連づけます。これによって、CloudTrailによるS3オブジェクトのロギングが可能となります。S3への全てのアクセスは、CloudTrailログ上でARNを通じて直接ユーザーに紐づけられます。
要件
- プレミアムプラン(あるいは2020/3/3以前にOperational Security packageを購買したお客様)
- 以下にアクセスできるAWS管理者
- DatabricksデプロイメントのAWSアカウントのIAMロール、ポリシー
- S3バケットのAWSアカウント
- インスタンスプロファイルを設定できるDatabricks管理者へのアクセス
メタインスタンスプロファイルのセットアップ
IAMクレディンシャルパススルーを使用するには最初に、ユーザーに割り当てるIAMロールに委任される、少なくとも一つのメタインスタンスプロファイルをセットアップする必要があります。
IAMロールは、AWS内でアイデンティティが何ができて何ができないかを規定するポリシーを持つAWSのアイデンティティです。インスタンスプロファイルは、EC2インスタンスが起動する際に、EC2インスタンスにロールの情報を引き渡す際に使用されるIAMロールのコンテナです。インスタンスプロファイルを用いることで、ノートブックにAWSのキーを埋め込むことなしに、Databricksクラスターからデータにアクセスできるようになります。
インスタンスプロファイルはクラスターに対するロールの設定を非常にシンプルにしますが、インスタンスプロファイルは1つのみのIAMロールとしか紐づけることができません。このため、このロールとロールに割り当てられているデータアクセスポリシーを、Databricksクラスター上の全てのユーザーが共有することになります。しかし、IAMロールは、他のIAMロールの委任を受けることや、自身で直接データにアクセスすることができます。異なるロールの委任を受けるために1つのロールに対するクレディンシャルを使用することをロールチェーニングと呼びます。
IAMクレディンシャルパススルーを用いることで、管理者はインスタンスプロファイルが使用するIAMロールと、ユーザーがデータにアクセスするロールを分割することができます。Databricksでは、このインスタンスロールをメタIAMロールと呼び、データにアクセスするロールをデータIAMロールと呼びます。インスタンスプロファイル同様に、メタインスタンスプロファイルはメタIAMロールのコンテナとなります。
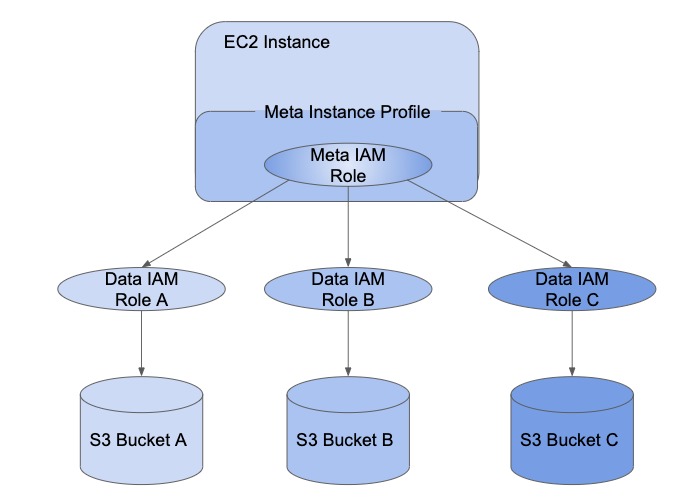
SCIM APIを用いて、ユーザーはデータIAMロールへのアクセスを許可されます。ロールをアイデンティティプロバイダーとマッピングしている場合には、これらのロールはDatabricks SCIM APIに同期されます。クレディンシャルパススルーとメタインスタンスプロファイルが設定されたクラスターを使用する際、あなたがアクセスできるデータIAMロールからのみ委任を受けることができます。これによって、データをセキュアに保ちつも、異なるデータアクセスポリシーを持つ複数のユーザーが1つのDatabricksクラスターを共有することができます。
このセクションでは、IAMクレディンシャルパススルーの有効化に必要なメタインスタンスプロファイルのセットアップ方法を説明します。
ステップ1: IAMクレディンシャルパススルーのロールの設定
データIAMロールの作成
既存のデータIAMロールあるいは、オプションとしてS3バケットにアクセスできるデータIAMロールを、ステップ1 S3バケットにアクセスするためのインスタンスプロファイルを作成する、ステップ2 接続先S3バケットのパケットポリシーを作成するに従って作成します。
メタIAMロールの設定
データIAMロールの委任を受けるメタIAMロールを設定します。
- AWSコンソールでIAMサービスに移動します。
- サイドバーのRolesをクリックします。
-
Create roleをクリックします。
- Select type of trusted entityではAWSサービスを選択します。
- EC2サービスをクリックします。
- Next Permissionsをクリックします。
-
Create Policyをクリックします。新規ウィンドウが開きます。
- JSONタブをクリックします。
- 以下のポリシーをコピーし、
<account-id>はお使いのAWSアカウントID、<data-iam-role>には上のセクションで設定したデータIAMロールの名前に設定します。JSON{ "Version": "2012-10-17", "Statement": [ { "Sid": "AssumeDataRoles", "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": [ "arn:aws:iam::<account-id>:role/<data-iam-role>" ] } ] } - Review Policyをクリックします。
- Nameフィールドにはポリシーの名前を入力しCreate policyをクリックします。
- ロールウィンドウに戻り画面を更新します。
- ポリシー名を検索し、ポリシー名の隣のチェックボックスを選択します。
- Next TagsとNext Reviewをクリックします。
- ロール名のフィールドにはメタIAMロールの名前を入力します。
- Create roleをクリックします。
- ロールサマリーでは、Instance Profile ARNをコピーしておきます。
メタIAMロールを信頼するようにデータIAMロールを設定
メタIAMロールがデータIAMロールの委任を受けられるようにするために、データロールによってメタロールが信頼されるようにしなくてはなりません。
- AWSコンソールでIAMサービスに移動します。
- サイドバーのRolesをクリックします。
- 以前のステップで作成したデータロールを検索し、クリックしてロールの詳細ページに移動します。
- Trust relationshipsタブをクリックし、設定されていない場合には以下の文を追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<account-id>:role/<meta-iam-role>"
},
"Action": "sts:AssumeRole"
}
]
}
ステップ2: Databricks上でメタインスタンスプロファイルを設定
このセクションでは、Databricksどのようにメタインスタンスプロファイルを設定するのかを説明します。
Databricksデプロイメントで使用するIAMロールの特定
- アカウントコンソールに移動します。
- AWS Accountタブをクリックします。
- Role ARNの最後にあるロール名をメモしておきます。ここでは
testco-roleとなります。

Databricksデプロイメントで使用するIAMロールのポリシーの修正
- AWSコンソールでIAMサービスに移動します。
- サイドバーのRolesをクリックします。
- 以前のセクションでメモしたロールを編集します。
- ロールにアタッチされているポリシーをクリックします。
- DatabricksのSparkクラスターのEC2インスタンスが、メタIAMロールの設定で作成したメタインスタンスプロファイルを使用できようにポリシーを修正します。サンプルについては、ステップ4 S3 IAMロールをEC2ポリシーに追加するをご覧ください。
- Review policy、Save Changesをクリックします。
Databricksにメタインスタンスプロファイルを追加
- Adminコンソールに移動します。
- Instance Profilesタブを選択します。
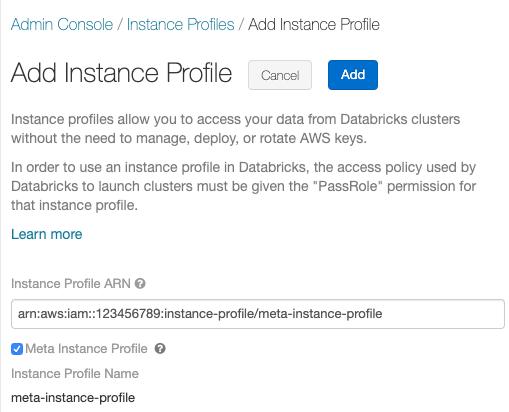
- Add Instance Profileをクリックします。ダイアログが表示されます。
- メタIAMロールの設定のメタIAMロールに対応するインスタンスプロファイルARNを貼り付けます。
-
Meta Instance Profileチェックボックスをチェックし、Addをクリックします。
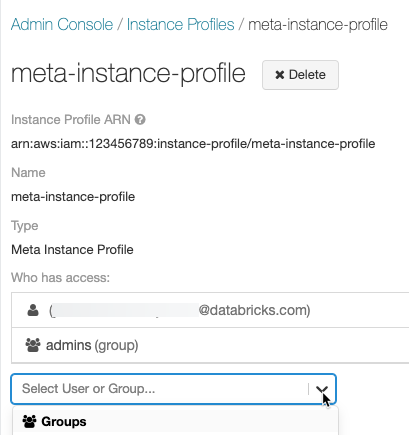
- オプションで、このメタインスタンスプロファイルでクラスターを起動できるユーザーを指定します。
ステップ3: DatabricksユーザーにIAMロールのアクセス権をアタッチ
IAMロールに対するユーザーのマッピングを管理する方法は2つあります。
- Databricks内でSCIM Users APIかSCIM Groups APIを使用する。
- アイデンティティプロバイダーで管理する。これにより、データアクセスを集中管理し、SAML 2.0アイデンティティ統合を通じてDatabricksクラスターに対して直接これらの権限を引き渡すことができます。
お使いのワークスペースでどちらのマッピング手段が適しているのかを決断するには、以下の表を参照ください。
| 要件 | SCIM | アイデンティティプロバイダー |
|---|---|---|
| Databricksへのシングルサインオン | No | Yes |
| AWSアイデンティティプロバイダーの設定 | No | Yes |
| メタインスタンスプロファイルの設定 | Yes | Yes |
| Databricks管理者 | Yes | Yes |
| AWS管理者 | Yes | Yes |
| アイデンティティプロバイダー管理者 | No | Yes |
メタインスタンスプロファイルが設定されたクラスターを起動する際、クラスターはあなたのアイデンティティをパススルーし、あなたがアクセスできるデータIAMロールからのみの委任を受けます。管理者は、ロールに対するアクセス権を設定するには、SCIM APIを使ってデータIAMロールに対するユーザーのアクセス権を許可する必要があります。
注意
お使いのアイデンティティプロバイダーでロールのマッピングを管理している場合、これらのロールはSCIMでマッピングされた全てのロールを上書きするので、ユーザートロールを直接マッピングするべきではありません。Step 6: Optionally configure Databricks to synchronize role mappings from SAML to SCIMをご覧ください。
IAMクレディンシャルパススルークラスターの起動
クレディンシャルパススルーが設定されたクラスターの起動プロセスは、クラスターモードによって異なります。
ハイコンカレンシークラスターでクレディンシャルパススルーを有効化
ハイコンカレンシークラスターは複数ユーザーで共有することができます。パススルーが設定されている場合、PythonとSQLのみがサポートされます。
- クラスターを作成する際、Cluster ModeをHigh Concurrencyに設定します。
- Databricksランタイムバージョン6.1以降を選択します。
-
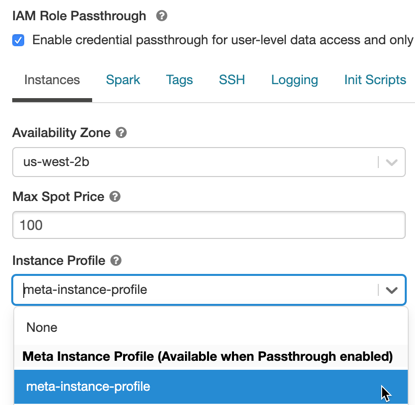
Advanced Optionsを展開し、Enable credential passthrough for user-level data access and only allow Python and SQL commandsを選択します。

-
Instancesタブをクリックします。Instance Profileドロップダウンから、Databricksにメタインスタンスプロファイルを追加で作成したメタインスタンスプロファイルを選択します。
スタンダードクラスターでIAMクレディンシャルパススルーを有効化
スタンダードクラスターでのクレディンシャルパススルーは、Databricksランタイム6.0以降でサポートされており、単一のユーザーに限定されます。スタンダードクラスターでは、Python、SQL、Scala、Rがサポートされています。Databricksランタイム10.1以降ではsparklyrもサポートされます。
クラスター作成時にユーザーを割り当てる必要がありますが、クラスターに対してCan Manage権限を持つユーザーであれば、いつでも元のユーザーから別のユーザーに切り替えることができます。
重要!
クラスターに割り当てられるユーザーは、クラスターでコマンドを実行できるように少なくともCan Attach To権限を持っている必要があります。管理者とクラスターの作成者はCan Manage権限を持っていますが、割り当てられたクラスターユーザー出ない場合は、クラスターでコマンドを実行することはできません。
- クラスターを作成する際、Cluster ModeをStandardに設定します。
- Databricksランタイムバージョン6.1以降を選択します。
-
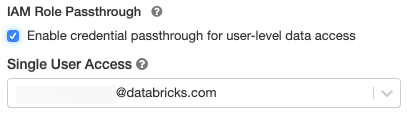
Advanced Optionsを展開し、Enable credential passthrough for user-level data accessを選択します。
-
Single User Accessドロップダウンからユーザー名を選択します。
-
Instancesタブをクリックします。Instance Profileドロップダウンから、Databricksにメタインスタンスプロファイルを追加で作成したメタインスタンスプロファイルを選択します。
IAMクレディンシャルパススルーを用いたS3へのアクセス
ロールの委任を受けることでクレディンシャルパススルーを用いるか、直接S3にアクセスするか、S3バケットをマウントし、マウントを通じてデータにアクセするためにロールを用いることで、S3にアクセスすることができます。
クレディンシャルパススルーを用いたS3へのデータの読み書き
S3に対してデータの読み書きを行います。
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
spark.read.csv("s3a://prod-foobar/sampledata.csv")
spark.range(1000).write.mode("overwrite").save("s3a://prod-foobar/sampledata.parquet")
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
# SparkR
library(SparkR)
sparkR.session()
read.df("s3a://prod-foobar/sampledata.csv", source = "csv")
write.df(as.DataFrame(data.frame(1:1000)), path="s3a://prod-foobar/sampledata.parquet", source = "parquet", mode = "overwrite")
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("s3a://prod-foobar/sampledata.csv")
sc %>% sdf_len(1000) %>% spark_write_parquet("s3a://prod-foobar/sampledata.parquet", mode = "overwrite")
ロールを指定してdbutilsを使用します。
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
dbutils.fs.ls("s3a://bucketA/")
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
dbutils.fs.ls("s3a://bucketA/")
他のdbutils.credentialsメソッドについては、Credentials utility (dbutils.credentials)を参照ください。
IAMクレディンシャルパススルーを用いたDBFSへのS3バケットのマウント
異なるバケットやプレフィックスが異なるロールを必要とするようなより高度なシナリオにおいては、特定のバケットパスにアクセスする際に使用するロールを指定するためにDatabricksバケットマウントを使うのが便利です。
IAMクレディンシャルパススルーが設定されたクラスターを用いてデータをマウントすると、マウントポイントに対するすべての読み書き処理はマウントポイントに対して認証を受けるためにあなたの認証情報を使用します。このマウントポイントは他のユーザーも参照できますが、以下のユーザーのみが読み書きを行うことができます。
- IAMデータロールを通じて背後のS3ストレージアカウントへのアクセス権を持っている。
- IAMクレディンシャルパススルーが有効化されているクラスターを使用している。
dbutils.fs.mount(
"s3a://<s3-bucket>/data/confidential",
"/mnt/confidential-data",
extra_configs = {
"fs.s3a.credentialsType": "Custom",
"fs.s3a.credentialsType.customClass": "com.databricks.backend.daemon.driver.aws.AwsCredentialContextTokenProvider",
"fs.s3a.stsAssumeRole.arn": "arn:aws:iam::xxxxxxxx:role/<confidential-data-role>"
})
IAMクレディンシャルパススルーを用いたジョブによるS3データへのアクセス
ジョブでクレディンシャルパススルーを用いてS3にアクセスするためには、新規あるいは既存クラスターを選択する際に、IAMクレディンシャルパススルークラスターを起動するようにクラスターを設定します。
クラスターはジョブのオーナーに対して許可されたロールのみから委任を受けるので、許可されたロールがアクセスできるS3のデータにアクセスできるようになります。
IAMクレディンシャルパススルーを用いたJDBC、ODBCクライアントによるS3データへのアクセス
JDBC、ODBCクライアントを用いてIAMクレディンシャルパススルーによるS3データへのアクセスを行うには、IAMクレディンシャルパススルークラスターを起動するようにクラスターを設定し、クライアントからこのクラスターに接続します。クラスターは接続ユーザーに対して許可されたロールのみから委任を受けるので、許可されたロールがアクセスできるS3のデータにアクセスできるようになります。
SQLクエリーでロールを指定するには、以下を実行します。
SET spark.databricks.credentials.assumed.role=arn:aws:iam::XXXX:role/<data-iam-role>;
-- Access the bucket which <my-role> has permission to access
SELECT count(*) from csv.`s3://my-bucket/test.csv`;
既知の制限
IAMクレディンシャルパススルーでは以下の機能はサポートされていません。
-
$fs(代わりにdbutils.fsを使ってください) - テーブルアクセスコントロール
- SparkContext (
sc) と SparkSession (spark)オブジェクトに対する以下のメソッド- すでに推奨されないメソッド
- 非管理者ユーザーがScalaコードを呼び出せる
addFile()やaddJar()のようなメソッド - S3以外のファイルシステムにアクセスする全てのメソッド
- 古いHadoop API(
hadoopFile()とhadoopRDD()) - Streaming API。これはストリームが稼働中にパススルーされたクレディンシャルが期限切れになる場合があるためです。
- クラスターのインスタンスプロファイルのダウンロード権限を必要とするクラスターライブラリ。DBFSパスを使うライブラリのみがサポートされています。
- Databricksランタイム7.3LTS以降でのみ利用できるHigh Concurrency上のDatabricks Connect
- MLflow