Databricks Connect | Databricks on AWS [2021/11/10時点]の翻訳です。
Databricksクイックスタートガイドのコンテンツです。
Databricks Connectを用いることで、お使いのIDE(Eclipse、IntelliJ、PyCharm、RStudio、Visual Studio Code)、ノートブックサーバー(Jupyter Notebook、Zeppelin)、他のカスタムアプリケーションからDatabricksクラスターに接続できます。
本書では、Databricks Connectがどのように動作するのか、Databricks Connectのセットアップ方法のウォークスルー、Databricks Connectを利用している際の問題への対処法、Databricks ConnectとDatabricks notebookでの処理実行の違いを説明します。
概要
Databricks Connectは、Databricksランタイムのクライアントライブラリです。これによって、ローカルのSparkセッションの代わりに、Spark APIを用いてジョブを記述し、リモートのDatabricksクラスター上で処理を実行することができます。
例えば、Databricks Connectを用いて、spark.read.parquet(...).groupBy(...).agg(...).show()のデータフレームコマンドを実行した場合、ジョブ実行に対するパーシングと実行計画はお使いのローカルマシン上で実行されます。そして、クラスターで処理を行うために、Databricksで稼働しているSparkサーバーにジョブの論理表現が送信されます。
Databricks Connectを使用することで、以下のことが可能となります。
- あらゆるPython、Java、Scala、RアプリケーションからSparkの大規模処理を実行できます。どこでも
import pyspark、import org.apache.spark、require(SparkR)を実行でき、IDEのプラグインやSparkサブミットスクリプトを利用することなしに、お使いのアプリケーションから直接Sparkジョブを実行することができます。 - リモートのクラスターを利用しつつも、お使いのIDEでコードをデバッグすることができます。
- ライブラリを開発する際に迅速にイテレーションできます。クラスターにおける個々のクライアントセッションは分離されているので、Databricks ConnectにおけるPythonやJavaライブラリの依存関係を変更した後にクラスターを再起動する必要がありません。
- 作業状態を失うことなしにアイドル状態のクラスターをシャットダウンできます。クライアントアプリケーションはクラスターと分離されているので、通常はノートブックで定義されたすべての変数、RDD、データフレームオブジェクトが失われてしまう、クラスターの再起動、アップグレードの影響を受けません。
要件
-
以下のDatabricksランタイムバージョンがサポートしています。
- Databricks Runtime 9.1 ML、Databricks Runtime 9.1
- Databricks Runtime 7.3 LTS ML、Databricks Runtime 7.3 LTS
- Databricks Runtime 6.4 ML、Databricks Runtime 6.4
- Databricks Runtime 5.5 LTS ML、Databricks Runtime 5.5 LTS
-
お使いのPythonクライアントのマイナーバージョンは、DatabricksクラスターのPythonのマイナーバージョンと一致する必要があります。以下のテーブルでは、それぞれのDatabricksランタイムのPythonバージョンを示しています。
| Databricksランタイムバージョン | Pythonバージョン |
|:--|:--|
|9.1 ML, 9.1 | 3.8 |
|7.3 LTS ML, 7.3 LTS | 3.7 |
|6.4 ML, 6.4 | 3.7 |
|5.5 LTS ML |3.6 |
|5.5 LTS | 3.5 |例えば、お使いのローカル環境でCondaを使用しており、クラスターがPython 3.5で動作するのであれば、同じバージョンで環境を構築する必要があります。例えば、
Bash
conda create --name dbconnect python=3.7
conda
- Databricks Connectのメジャー、マイナーバージョンは常にDatabricksランタイムバージョンと一致する必要があります。Databricksランタイムバージョンと一致する最新のDatabricks Connectの最新パッケージを使用することをお勧めします。例えば、Databricks Runtime 7.3 LTSクラスターを使用している場合には、`databricks-connect==7.3.*`パッケージをお使いください。
>**注意**
利用可能なDatabricks Connectリリースとメンテナンスのアップデートに関しては、[Databricks Connect release notes](https://docs.databricks.com/release-notes/dbconnect/index.html)を参照ください。
- Java Runtime Environment (JRE) 8が必要です。クライアントはOpenJDK 8 JREでテストされています。クライアントはJava 11をサポートしていません。
>**訳者注**
[Java SE Development Kit 8 \- Downloads](https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html)で動作確認しました。
>**注意**
Windowsで、Databricks Connectが`winutils.exe`を見つけられないというエラーに遭遇した場合には、[Windowsでwinutils.exeが見つからない](#windowsにおいてwinutilsexeが見つからない)を参照ください。
# クライアントのセットアップ
## ステップ1:クライアントのインストール
1. PySparkをアンインストールします。これは`databricks-connect`がPySparkと競合するためです。詳細に関しては、[PySparkインストールの競合](#pysparkインストールの競合)を参照してください。
```bash:Bash
pip uninstall pyspark
```
1. Databricks Connectクライアントをインストールします。
```bash:Bash
pip install -U "databricks-connect==7.3.*" # or X.Y.* to match your cluster version.
```
>**注意**
最新のパッケージがインストールされていることを確実にするために、`databricks-connect=X.Y`の代わりに`databricks-connect==X.Y.*`を常に指定するようにしてください。
## ステップ2:接続プロパティの設定
1. 以下の設定プロパティを確認します。
- Databricksの[ワークスペースURL](https://docs.databricks.com/workspace/workspace-details.html#workspace-url)
- Databricksの[パーソナルアクセストークン](https://docs.databricks.com/dev-tools/api/latest/authentication.html#token-management)
- 作成したクラスターのID。URLからクラスターIDを取得できます。以下の例では、クラスターIDは`0304-201045-xxxxxxxx`となります。
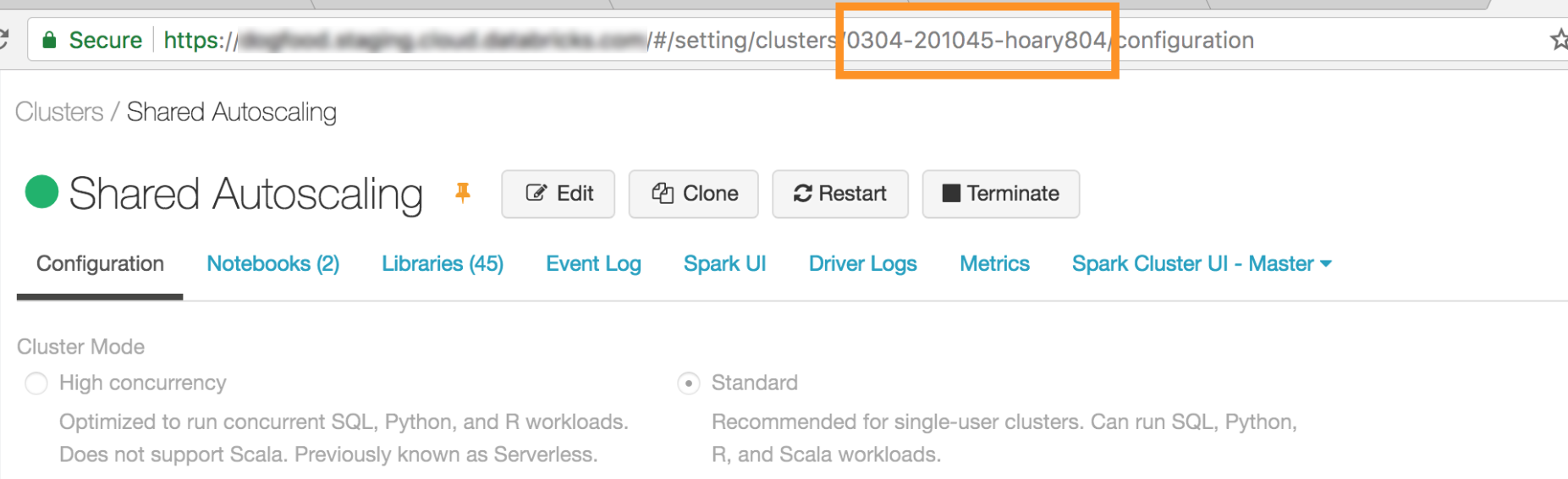
- Databricks Connectが接続するポート。`15001`に設定します。
1. 接続設定を行います。CLI、SQL設定、環境変数を利用できます。設定方法の優先度が高い順から低い順に、SQL設定キー、CLI、環境変数となります。
- CLI
- `databricks-connect`を実行します。
```bash:Bash
databricks-connect configure
```
ライセンスが表示されます。
```
Copyright (2018) Databricks, Inc.
This library (the "Software") may not be used except in connection with the
Licensee's use of the Databricks Platform Services pursuant to an Agreement
...
```
- ライセンスを承諾し、設定値を指定します。**Databricks Host**と**Databricks Token**に対しては、ステップ1で取得したワークスペースURLとパーソナルアクセストークンを指定します。
```
Do you accept the above agreement? [y/N] y
Set new config values (leave input empty to accept default):
Databricks Host [no current value, must start with https://]: <databricks-url>
Databricks Token [no current value]: <databricks-token>
Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id>
Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id>
Port [15001]: <port>
```
- SQL設定あるいは環境変数。以下のテーブルでは、ステップ1で取得した接続プロパティに対応するSQL設定キーと環境変数を示しています。SQL設定キーを指定するには、`sql("set config=value")`を使用します。例えば、`sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh")`。
| パラメーター | SQL設定キー | 環境変数 |
|:--|:--|:--|
|Databricksのホスト | spark.databricks.service.address | DATABRICKS_ADDRESS |
|Databricksのトークン | spark.databricks.service.token | DATABRICKS_API_TOKEN |
|クラスターID |spark.databricks.service.clusterId | DATABRICKS_CLUSTER_ID |
|組織ID | spark.databricks.service.orgId | DATABRICKS_ORG_ID |
|ポート | spark.databricks.service.port | DATABRICKS_PORT |
>**重要!**
トークンをSQL設定に記述することはお勧めしません。
1. Databricksへの接続テストを行います。
```bash:Bash
databricks-connect test
```
設定したクラスターが稼働していない場合には、このテストはクラスターを起動し、指定された自動停止時間まで稼働し続けます。出力は以下のようになります。
- PySpark is installed at /.../3.5.6/lib/python3.5/site-packages/pyspark
- Checking java version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode) - Testing scala command
18/12/10 16:38:44 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/12/10 16:38:50 WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set.
18/12/10 16:39:53 WARN SparkServiceRPCClient: Now tracking server state for 5abb7c7e-df8e-4290-947c-c9a38601024e, invalidating prev state
18/12/10 16:39:59 WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms
Welcome to
____ __
/ / ___ / /
\ / _ / _ `/ __/ '/
// .__/_,// //_\ version 2.4.0-SNAPSHOT
//
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_152)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.range(100).reduce(_ + _)
Spark context Web UI available at https://10.8.5.214:4040
Spark context available as 'sc' (master = local[*], app id = local-1544488730553).
Spark session available as 'spark'.
View job details at /?o=0#/setting/clusters//sparkUi
View job details at ?o=0#/setting/clusters//sparkUi
res0: Long = 4950
scala> :quit
- Testing python command
18/12/10 16:40:16 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/12/10 16:40:17 WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set.
18/12/10 16:40:28 WARN SparkServiceRPCClient: Now tracking server state for 5abb7c7e-df8e-4290-947c-c9a38601024e, invalidating prev state
View job details at /?o=0#/setting/clusters//sparkUi
# IDEあるいはノートブックサーバーのセットアップ
このセクションでは、Databricks Connectクライアントを使うために、お使いのIDEやノートブックサーバーをどのように設定するのかを説明します。
このセクションでは以下のツールを説明します。
- [Jupyter notebook](#jupyter-notebook)
- [PyCharm](#pycharm)
- [SparkRおよびRStudio Desktop](#sparkrおよびrstudio-desktop)
- [sparklyrおよびRStudio Desktop](#sparklyrおよびrstudio-desktop)
- [IntelliJ (Scala、Java)](#intellij-scalajava)
- [Eclipse](#eclipse)
- [Visual Studio Code](#visual-studio-code)
- [SBT](#sbt)
## Jupyter notebook
>**注意**
始める前に、[要件に合致](#要件)しているか確認の上、Databricks Connectの[クライアントをセットアップ](#クライアントのセットアップ)してください。
Databricks Connectの設定スクリプトは、お使いのプロジェクト設定に自動でパッケージを追加します。Pythonカーネルで始めるには、以下を実行します。
```python:Python
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
SQLクエリーを実行し、可視化するマジックコマンド%sqlを有効にするには、以下のスニペットを実行します。
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
PyCharm
注意
始める前に、要件に合致しているか確認の上、Databricks Connectのクライアントをセットアップしてください。
Databricks Connectの設定スクリプトは、お使いのプロジェクト設定に自動でパッケージを追加します。
Python3のクラスター
- PyCharmプロジェクトを作成する際に、Existing Interpreterを選択します。ドロップダウンメニューから、作成したConda環境を選択します(要件を参照ください)。

- Run > Edit Configurationsに移動します。
- 環境変数として
PYSPARK_PYTHON=python3を追加します。

SparkRおよびRStudio Desktop
注意
始める前に、要件に合致しているか確認の上、Databricks Connectのクライアントをセットアップしてください。
-
お使いのローカルマシン上にオープンソースのSparkをダウンロードし解凍します。お使いのDatabircksクラスターと同じバージョン(Hadoop 2.7)を選択します。
-
databricks-connect get-jar-dirを実行します。このコマンドは/usr/local/lib/python3.5/dist-packages/pyspark/jarsのようなパスを返します。JARディレクトリのファイルパスの一つ上位のディレクトリのファイルパスをコピーします。例えば、SPARK_HOMEディレクトリである、/usr/local/lib/python3.5/dist-packages/pysparkとなります。 -
お使いのRスクリプトに追加することで、SparkライブラリパスとSparkホームを設定します。ステップ1でオープンソースSparkを解凍したディレクトリを
<spark-lib-path>に設定します。ステップ2で取得したディレクトリを<spark-home-path>に設定します。R# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>") -
Sparkセッションを初期化し、SparkRコマンドを実行します。
RsparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyrおよびRStudio Desktop
プレビュー
この機能はパブリックプレビューです。
注意
始める前に、要件に合致しているか確認の上、Databricks Connectのクライアントをセットアップしてください。
Databricks Connectを用いてローカルで開発したsparklyr依存のコードをコピーし、最低限のコード変更のみで、Databricksノートブック、あるいはDatabricksワークスペース上にホストされたRStudioサーバーで実行することができます。
要件
- sparklyr 1.2以降
- Databricks Runtime 6.4以降およびマッチするDatabricks Connect。
インストール、設定、sparklyrの利用
-
RStudioデスクトップで、CRANあるいはGitHubから最新のマスターバージョンからsparklyr 1.2以降をインストールします。
R# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr") -
Databricks ConnectがインストールされたPython環境をアクティベートし、
<spark-home-path>を取得するためにターミナルで以下のコマンドを実行します。Bashdatabricks-connect get-spark-home -
スパークセッションを初期化し、sparklyrコマンドを実行します。
Rlibrary(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% count
1. 接続をクローズします。
```r:R
spark_disconnect(sc)
```
### リソース
詳細に関しては、sparklyrのGitHubの[README](https://github.com/sparklyr/sparklyr#connecting-through-databricks-connect)を参照ください。コードサンプルは[sparklyr](https://docs.databricks.com/spark/latest/sparkr/sparklyr.html)を参照ください。
### sparklyrとRStudioデスクトップの制限
以下の機能はサポートされていません。
- sparklyrストリーミングAPI
- sparklyr ML API
- broom API
- csv_fileのシリアライゼーションモード
- spark submit
## IntelliJ (Scala、Java)
> **注意**
始める前に、[要件に合致](#要件)しているか確認の上、Databricks Connectの[クライアントをセットアップ](#クライアントのセットアップ)してください。
1. `databricks-connect get-jar-dir`を実行します。
1. コマンドで返却されるディレクトリへの依存関係を指定します。**File > Project Structure > Modules > Dependencies > ‘+’ sign > JARs or Directories**に移動します。
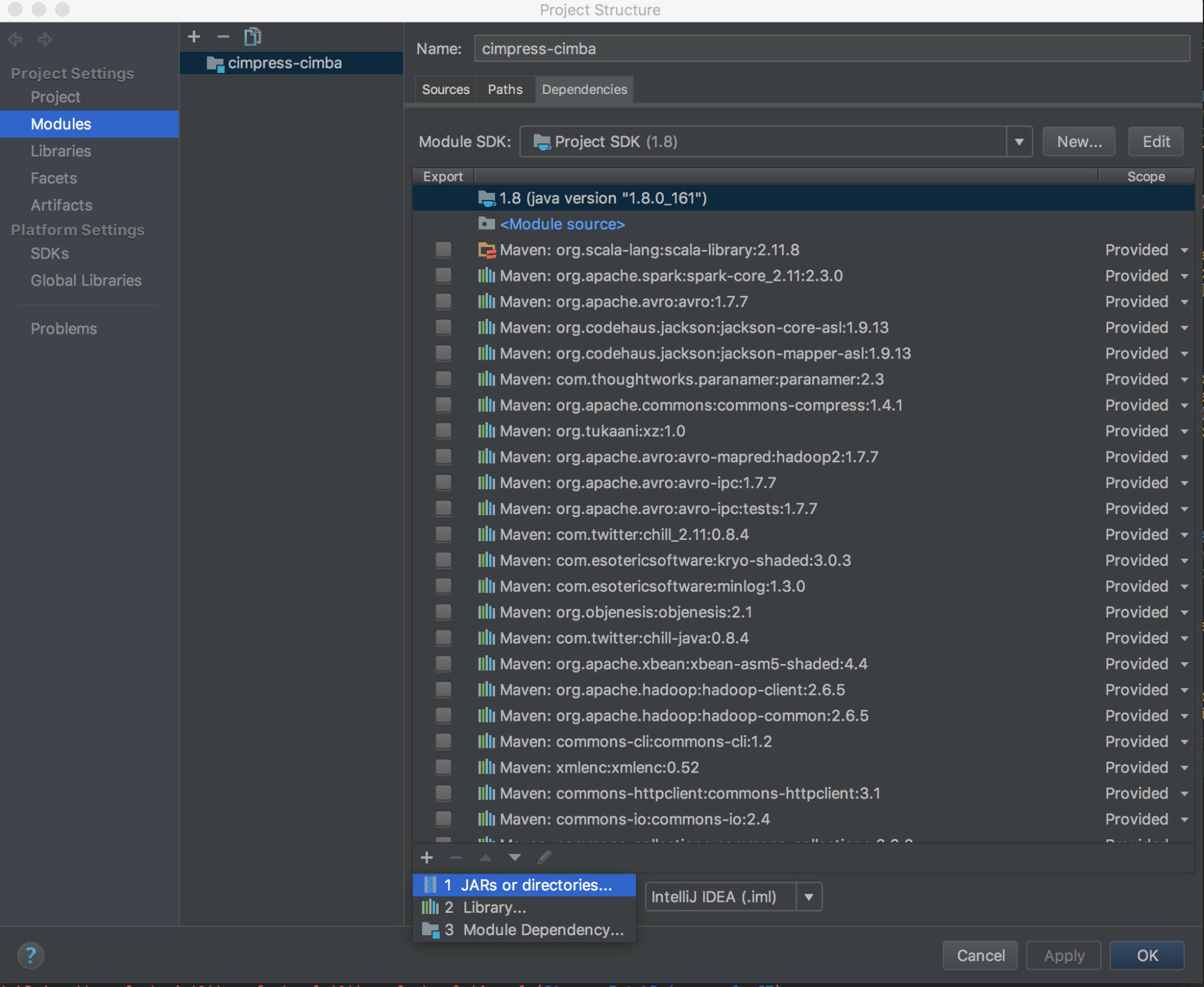
競合を回避をするためには、お使いのクラスパスから他のSparkインストレーションを削除することを強くお勧めします。これが不可能な場合、追加したJARがクラスパスの先頭にあることを確認してください。特に、これらはインストールされた他のSparkのバージョン先頭にある必要があります(さもないと、これら他のSparkバージョンを使用しローカルで実行するか、`ClassDefNotFoundError`をスローすることになります)。
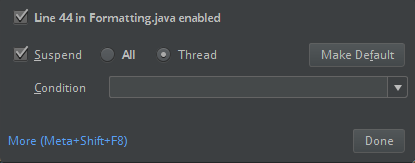
1. IntelliJのブレイクアウトオプションの設定をチェックしてください。デフォルトは**All**であり、デバッグのためにブレークポイントを設定した場合には、ネットワークのタイムアウトが発生するかもしれません。バックグラウンドのネットワークスレッドの停止を回避するために、**Thread**に設定してください。
## Eclipse
> **注意**
始める前に、[要件に合致](#要件)しているか確認の上、Databricks Connectの[クライアントをセットアップ](#クライアントのセットアップ)してください。
1. `databricks-connect get-jar-dir`を実行します。
1. コマンドで返却されるディレクトリへの依存関係を指定します。**Project menu > Properties > Java Build Path > Libraries > Add External Jars**に移動します。
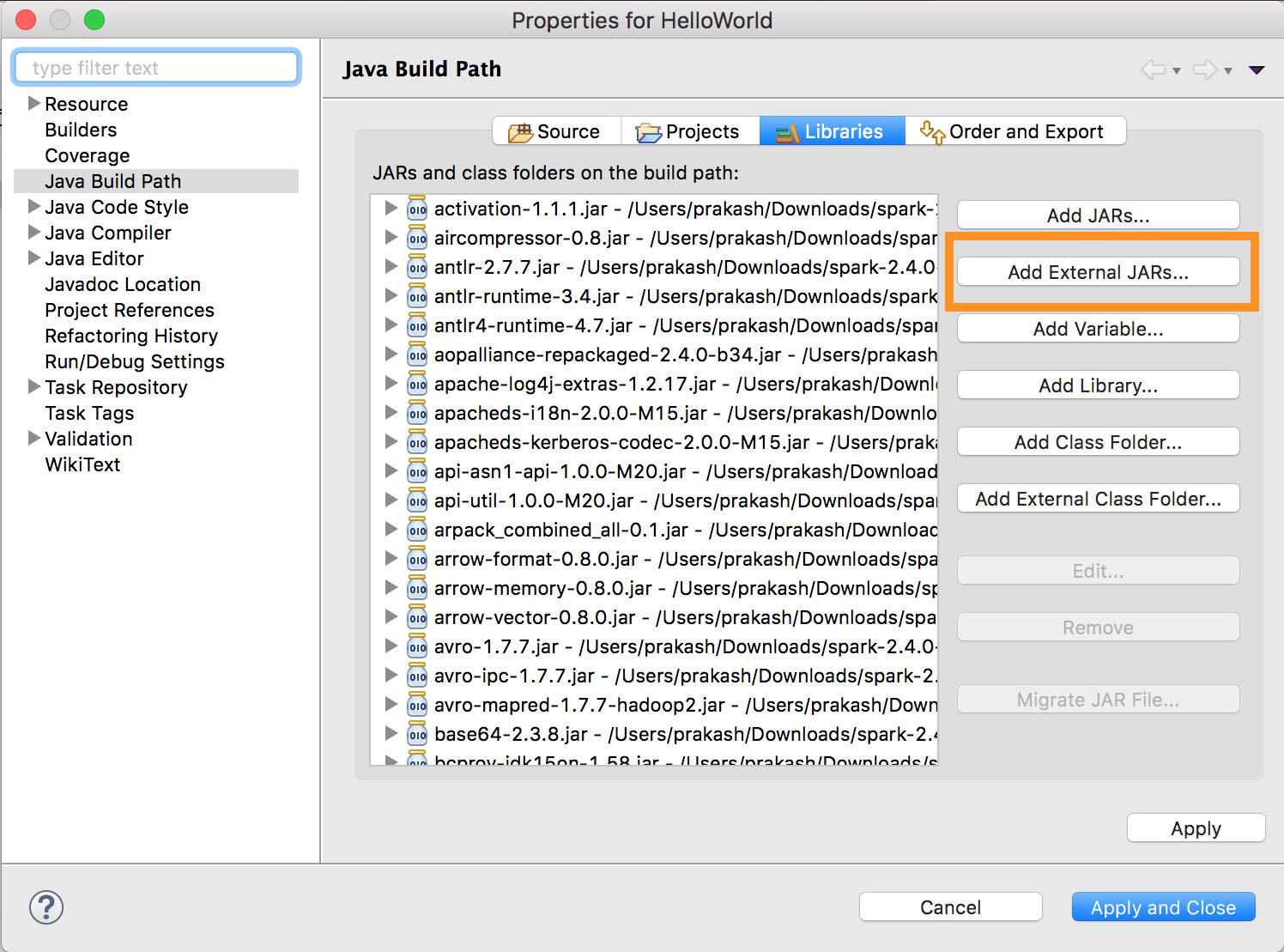
競合を回避をするためには、お使いのクラスパスから他のSparkインストレーションを削除することを強くお勧めします。これが不可能な場合、追加したJARがクラスパスの先頭にあることを確認してください。特に、これらはインストールされた他のSparkのバージョン先頭にある必要があります(さもないと、これら他のSparkバージョンを使用しローカルで実行するか、`ClassDefNotFoundError`をスローすることになります)。
## Visual Studio Code
> **注意**
始める前に、[要件に合致](#要件)しているか確認の上、Databricks Connectの[クライアントをセットアップ](#クライアントのセットアップ)してください。
1. [Python拡張](https://marketplace.visualstudio.com/items?itemName=ms-python.python)がインストールされていることを確認してください。
1. コマンドパレットを開きます(MacOSなら**Command+Shift+P**、Windows/Linuxなら**Ctrl+Shift+P**)。
1. Pythonインタプリタを選択します。**Code > Preferences > Settings**に移動し、**python settings**を選択します。
1. `databricks-connect get-jar-dir`を実行します。
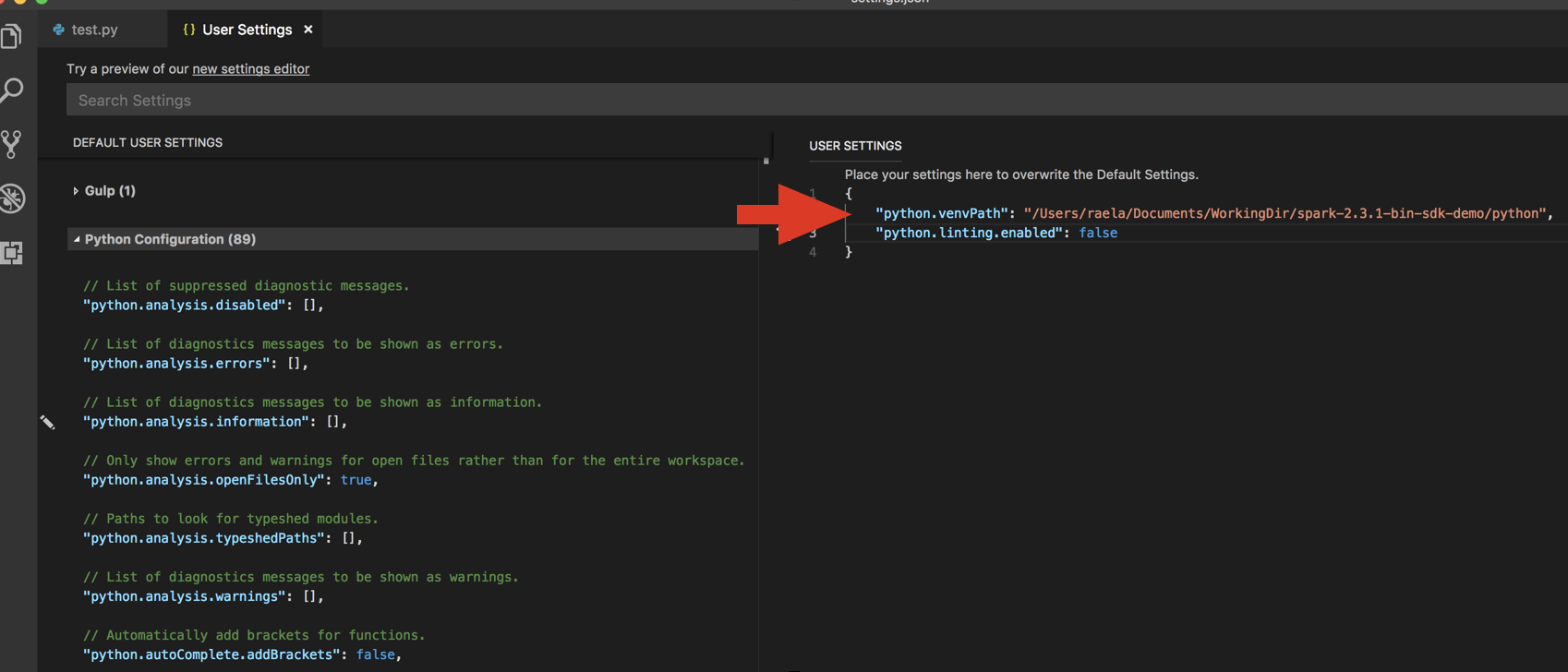
1. コマンドから返却されるディレクトリを`python.venvPath`配下のUser SettingsのJSONに追加します。これはPython設定に追加される必要があります。
1. Linterを無効化します。**edit json settings**の右側の...をクリックします。変更された設定は以下の通りとなります。
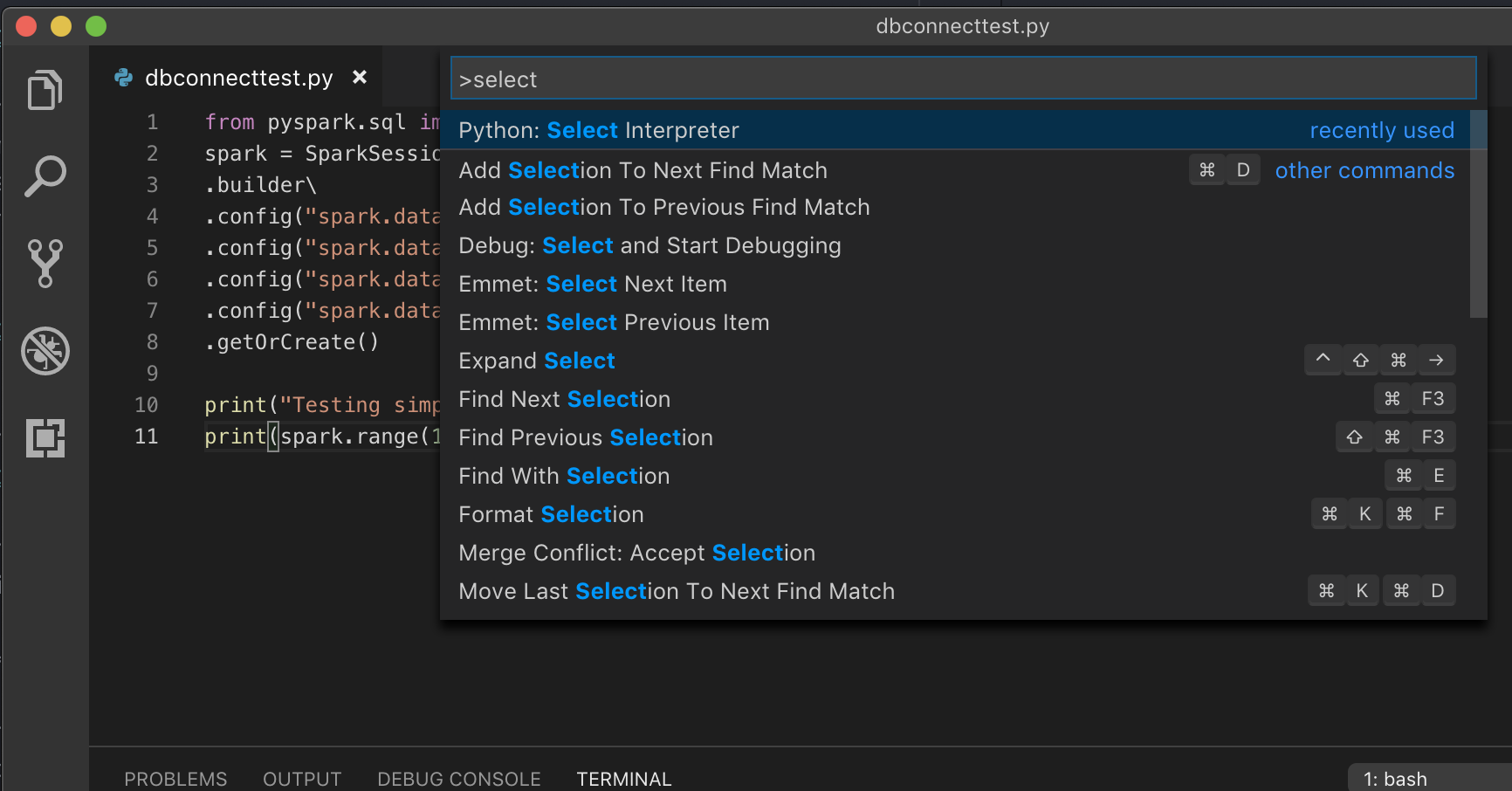
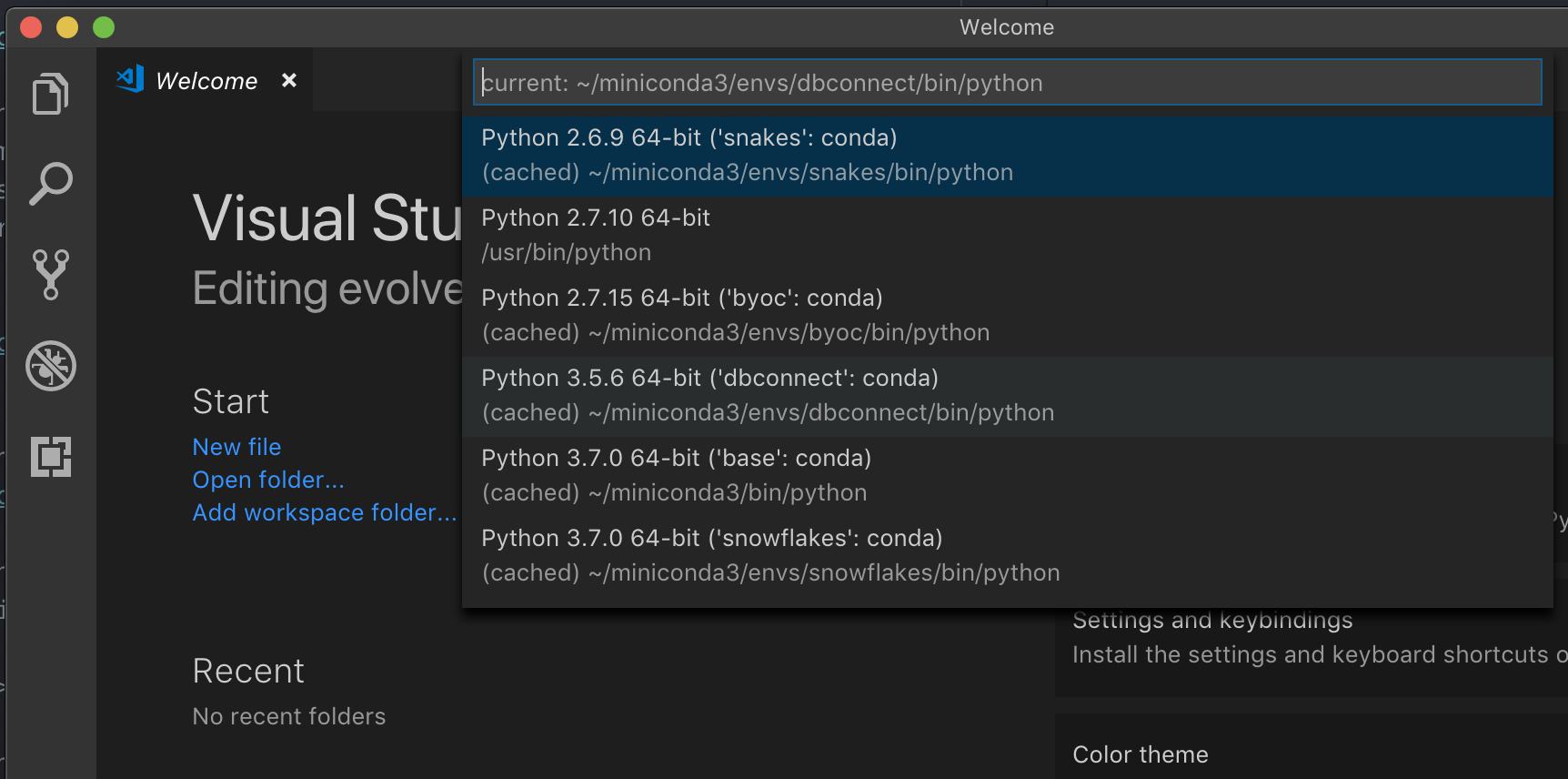
1. VS CodeでPythonを開発する際に推奨している、仮想環境で実行をしている場合には、コマンドパレットで、`select python interpreter`とタイプし、お使いのクラスターPythonバージョンに*マッチする*環境を指定します。
例えば、クラスターがPython 3.5の場合には、お使いのローカル環境はPython 3.5である必要があります。
## SBT
> **注意**
始める前に、[要件に合致](#要件)しているか確認の上、Databricks Connectの[クライアントをセットアップ](#クライアントのセットアップ)してください。
SBTを使うためには、通常のSpark依存ライブラリではなく、Databricks ConnectのJARを指定するように`build.sbt`を設定する必要があります。以下のビルドファイルサンプルにあるように、`unmanagedBase`ディレクティブを用いて設定を行います。こちらのサンプルでは、Scalaアプリケーションが`com.example.Test`メインオブジェクトを有していることを想定しています。
### `build.sbt`
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by databricks-connect get-jar-dir
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
# IDEでの実行例
```java:Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS demo_temps_table");
temps.write().saveAsTable("demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE demo_temps_table");
}
}
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS demo_temps_table')
temps.write.saveAsTable('demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE demo_temps_table')
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS demo_temps_table")
temps.write.saveAsTable("demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE demo_temps_table")
}
}
依存関係への対応
通常、メインクラスやPythonファイルは他のJARやファイルへの依存関係を有します。sparkContext.addJar("path-to-the-jar")やsparkContext.addPyFile("path-to-the-file")を呼び出すことで、このようなJARやフィルに対する依存関係を追加することができます。また、addPyFile()インタフェースで、Eggファイルやzipファイルを追加することもできます。IDEでコードを実行する際は常に、クラスター上に依存するJARやファイルがインストールされます。
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
# sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.parquet("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
DBUtilsへのアクセス
Databricksユーティリティモジュールであるdbutils.fsやdbutils.secretsを使用することができます。サポートされているコマンドは、dbutils.fs.cp、dbutils.fs.head、dbutils.fs.ls、dbutils.fs.mkdirs、dbutils.fs.mv、dbutils.fs.put、dbutils.fs.rm、dbutils.secrets.get、dbutils.secrets.getBytes、dbutils.secrets.list、dbutils.secrets.listScopesとなります。Credentials utility (dbutils.credentials)やSecrets utility (dbutils.secrets)を参照いただくか、dbutils.fs.help()やdbutils.secrets.help()を実行してください。
Python
pip install six
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Databricksランタイム7.3 LTS以降を使用しており、ローカルと同じような手順でDatabricksクラスターのDBUtilsモジュールにアクセスするには、以下のget_dbutils()を使用してください。
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
あるいは、以下のget_dbutils()を使用してください。
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
ローカル、リモートファイルシステム間でのファイルコピー
クライアントとリモートファイルシステム間でファイルをコピーするために、dbutils.fsを使用できます。file:/スキームはクライアントのローカルファイルシステムを参照します。
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
転送できるファイル最大サイズは250MBです。
dbutils.secrets.getの有効化
セキュリティ上の制約から、デフォルトではdbutils.secrets.getの呼び出しは無効化されています。お使いのワークスペースでこの機能を有効化するにはDatabricksのサポートに問い合わせください。
Hadoopファイルシステムへのアクセス
標準的なHadoopファイルシステムインタフェースを用いて、DBFSに直接アクセスすることができます。
> import org.apache.hadoop.fs._
// get new DBFS connection
> val dbfs = FileSystem.get(spark.sparkContext.hadoopConfiguration)
dbfs: org.apache.hadoop.fs.FileSystem = com.databricks.backend.daemon.data.client.DBFS@2d036335
// list files
> dbfs.listStatus(new Path("dbfs:/"))
res1: Array[org.apache.hadoop.fs.FileStatus] = Array(FileStatus{path=dbfs:/$; isDirectory=true; ...})
// open file
> val stream = dbfs.open(new Path("dbfs:/path/to/your_file"))
stream: org.apache.hadoop.fs.FSDataInputStream = org.apache.hadoop.fs.FSDataInputStream@7aa4ef24
// get file contents as string
> import org.apache.commons.io._
> println(new String(IOUtils.toByteArray(stream)))
Hadoopの設定
SQL、データフレームの操作に適用されるspark.conf.setAPIを用いて、クライアント上にHadoop設定を行うことができます。sparkContextに設定されたHadoop設定は、ノートブックを使用しているクラスターに設定される必要があります。これは、sparkContext上の設定は、ユーザーのセッションではなく、クラスター全体適用されるためです。
トラブルシューティング
接続に関する問題を確認するには、databricks-connect testを実行します。このセクションでは、遭遇するであろう一般的な問題と解決法を説明します。
Pythonバージョンのミスマッチ
ローカルで使用しているPythonのバージョンが、クラスターのバージョンとマイナーバージョンまで一致していることを確認してください。(例えば、3.5.1と3.5.2はOKですが、3.6はNGです)
ローカルに複数のPythonバージョンがある場合には、Databricks Connectが、PYSPARK_PYTHONで指定されたもの(例えば、PYSPARK_PYTHON=python3)を使用していることを確認してください。
サーバーが有効化されていない
お使いのクラスターでspark.databricks.service.server.enabled trueが指定され、Sparkサーバーが有効化されていることを確認してください。有効化されている場合、ドライバーログに以下のような出力が確認できます。
18/10/25 21:39:18 INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
18/10/25 21:39:21 INFO SparkContext: Loading Spark Service RPC Server
18/10/25 21:39:21 INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
18/10/25 21:39:21 INFO Server: jetty-9.3.20.v20170531
18/10/25 21:39:21 INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
18/10/25 21:39:21 INFO Server: Started @5879ms
PySparkインストールの競合
databricks-connectパッケージはPySparkと競合します。両方をインストールすると、PythonでSparkコンテキストを初期化する際にエラーが発生します。これは「stream corrupted」や「class not found」エラーとなりえます。Python環境にPySparkをインストールしている場合には、databricks-connectをインストールする前にアンインストールしてください。PySparkをアンインストールした後は、Databricks Connectを完全に再インストールしたことを確認んしてください。
pip uninstall pyspark
pip uninstall databricks-connect
pip install -U "databricks-connect==5.5.*" # or X.Y.* to match your cluster version.
SPARK_HOMEの競合
お使いのマシンで以前Sparkを使ったことがある場合には、IDEはDatabricks ConnectのSparkではなく、以前のバージョンのSparkを使うように設定されているかもしれません。これは、「stream corrupted」や「class not found」といったエラーを引き起こします。SPARK_HOMEの値をチェックすることで、お使いのSparkのバージョンを確認できます。
System.out.println(System.getenv("SPARK_HOME"));
import os
print(os.environ['SPARK_HOME'])
println(sys.env.get("SPARK_HOME"))
解決方法
SPARK_HOMEがクライアントと異なるバージョンのSparkを示している場合には、SPARK_HOMEをアンセットし、再度トライする必要があります。
お使いのIDEの環境変数設定、.bashrc、.zshrc、.bash_profileファイル、他に環境変数が設定されているところを確認してください。古い状態を廃棄するためにIEDを再起動する必要があるかもしれません、そして、問題が継続する場合には新規プロジェクトを作成する必要があるかもしれません。
SPARK_HOMEに新たな値を指定する必要はありません。アンセットするだけで十分です。
バイナリーのPATHエントリーの競合あるいは欠如
spark-shellのようなコマンドがDatabricks Connectによるものではなく、別にインストールされたバイナリーで実行されるようにPATHが設定されている可能性があります。この場合、databricks-connect testは失敗します。Databricks Connectのバイナリーの優先度が高いことを確認するか、以前インストールされたものを削除してください。
spark-shellのようなコマンドを実行できない場合、pip installによってPATHが自動的に設定されておらず、手動でPATHにbinディレクトリを追加する必要があるかもしれません。sっとアップされていなかったとしても、IDEからDatabricks Connectを利用できる可能性はありますが、databricks-connect testコマンドは失敗します。
クラスターにおけるシリアライゼーション設定の競合
databricks-connect testコマンドを実行した際に「stream corrupted」エラーに装具数する場合は、クラスターのシリアライゼーション設定に互換性がない可能性があります。例えば、spark.io.compression.codecの設定が問題を引き起こす場合があります。この問題を解決するためには、クラスター設定からこれらの設定を削除するか、Databricks Connectクライアントにも同じ設定を行います。
Windowsにおいてwinutils.exeが見つからない
WindowsでDatabricks Connectを使用している際に、以下のエラーに遭遇するかもしれません。
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
WindowsにおけるHadoopパスの設定の指示に従ってください。
Windowsにおいて、ファイル名、ディレクトリ名、ボリュームラベルの文法が誤っている
WindowsでDatabricks Connectを使用している際に、以下のエラーに遭遇するかもしれません。
The filename, directory name, or volume label syntax is incorrect.
Java、Databricks Connectがパスに空白を含むディレクトリにインストールされています。パスに空白を含まないディレクトリにインストールするか、ショートネームフォームを用いてパスを設定することで回避します。
制限
以下のDatabricks、サードパーティのプラットフォームの機能はサポートされていません。
- 構造化ストリーミング
- リモートクラスターにおいて、Sparkジョブの一部ではない任意のコードの実行
- Deltaテーブル操作のためのScala、Python、RのネイティブAPI(例えば、
DeltaTable.forPath)はサポートされていません。しかし、Delta Lakeに対するオペレーションのためのSQL API(spark.sql(...))や、Deltaテーブルに対するSpark API(例えば、spark.read.load)はサポートされています。 - Apache Zeppelin 0.7.x以下
- テーブルアクセスコントロールがあるクラスターへの接続
- プロセス分類が有効化された(
spark.databricks.pyspark.enableProcessIsolationがtrueに設定されている)
クラスターへの接続 - Deltaの
CLONESQLコマンド - グローバル一時ビュー
- Koalas
- 以下のDatabricksユーティリティ
- AWS Glueカタログ
- IAMクレディンシャルパススルーはDatabricksランタイム6.4以降が動作しているスタンダードクラスターでのみサポートされます。