初版: 2018/10/5
著者: 伊藤 雅博, 株式会社日立製作所
はじめに
この投稿ではオープンソースカンファレンス2017.Enterpriseで発表した「めざせ!Kafkaマスター ~Apache Kafkaで最高の性能を出すには~」の検証時に調査した内容を紹介します(全8回の予定)。本投稿の内容は2017年6月にリリースされたKafka 0.11.0 時点のものです。
第2回目となる今回は、KafkaのコンポーネントであるBroker、Producer、Consumerについて、処理の流れとパラメータ設定を紹介します。
投稿一覧:
- Apache Kafkaの概要とアーキテクチャ
- Apache KafkaのProducer/Broker/Consumerのしくみと設定一覧 (本投稿)
- Apache Kafkaの推奨構成と性能の見積もり方法
- Apache Kafkaの性能検証(1): 検証環境とパラメータチューニングの内容
- Apache Kafkaの性能検証(2): Producerのチューニング結果
- Apache Kafkaの性能検証(3): Brokerのチューニング結果
- Apache Kafkaの性能検証(4): Producerの再チューニングおよびConsumerのチューニング結果
- Apache Kafkaの性能検証(5): システム全体のレイテンシについて
Producer
ProducerはメッセージをTopicに書き込むためのクライアントライブラリです。ユーザアプリケーションはProducerを使用して、Brokerクラスタ上に構成されたTopicの各Partitionにメッセージを書き込みます。
Producerのしくみ
Producerは定期的にいずれかのBrokerからメタデータを取得することで、各Brokerのホスト名、接続先ポート、各Topic PartitionのLeader Replicaの場所など把握します。Producerはこの情報を元に、どのメッセージをどのBrokerに送信するかを決定します。
Producerがメタデータを取得後に、実際にメッセージを送信するときの処理の流れを以下に示します。
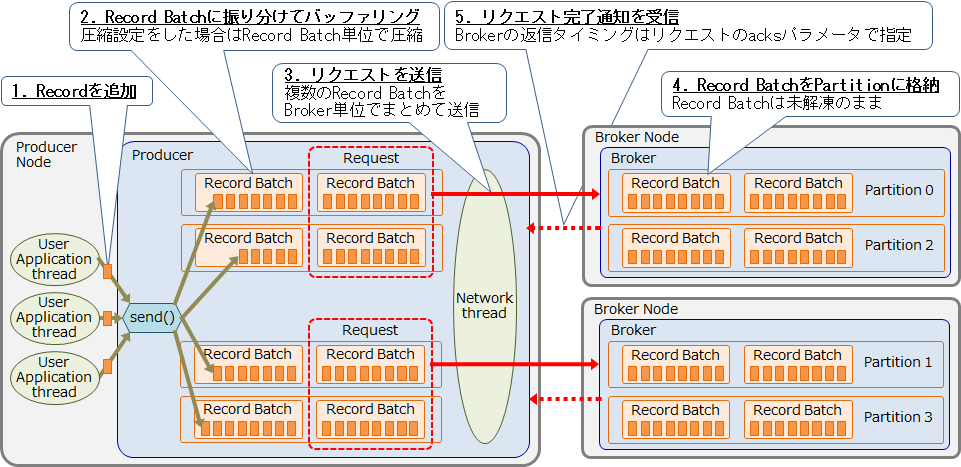
Producerの各処理の詳細を以下に示します。
1. 送信するRecordを追加
Kafkaのメッセージはキーバリュー形式であり、Recordと呼ばれます。ユーザアプリケーションはProducerのSend APIを通じて送信したいRecordを追加します。ProducerのSend APIはスレッドセーフであるため、1つのProducerインスタンスを複数のユーザスレッドで共有することが推奨されています(参考)。これにより、複数のユーザアプリケーションから追加された、複数TopicのデータをまとめてBrokerに送信することができ、処理のオーバーヘッドを減らすことができます。
2. Record Batchに振り分けてバッファリング
登録されたRecordは、Partition単位で存在するRecord Batchに振り分けてバッファリングします。Recordはキーバリュー形式であるため、特定のキーに対応するRecordを、特定のPartition(のRecord Batch)に集めることも可能です。これにより、例えば特定のユーザIDを持つRecordを、そのPartitionを担当する1つのConsumerがまとめて処理することができます。
また、リクエストの並列送信数(後述の max.in.flight.requests.per.connection)を1に設定することで、Partition内でRecordの順序を保証することができます。これにより特定のユーザIDを持つRecordの時系列を維持することができます。もしRecordを圧縮する場合はRecord Batch 単位で圧縮されます。ここまでの処理はSend APIを呼び出したユーザアプリケーションのスレッドで実行されます。
3. リクエストを送信
Record BatchはProducerのネットワークスレッドがBroker単位でまとめて送信します(これをProduce リクエストと呼ぶ)。複数TopicのRecord Batchを1回のリクエストでまとめて送信することで、通信のオーバーヘッドを削減しています。リクエストは下記のいずれかのタイミングで送信されます。
- リクエストの全Record Batchが上限サイズ(後述の batch.size)に達したとき
- リクエストが上限サイズ(後述の max.request.size)に達したとき
- ネットワークスレッドのデータ蓄積待機時間(後述の linger.ms)が経過したとき
4. Record BatchをPartitionに格納
Brokerは受信したProduce リクエストに含まれる各Record Batchを、対応するPartitionに格納します。Record BatchはBrokerでは解凍されず、Broker間の複製やConsumerへの送信もRecord Batch単位で行われます。このように、Kafkaは大量のRecordをRecord Batch単位で扱うことで、処理のオーバーヘッドを減らしてスループットを高めています。
5. リクエスト完了通知を受信
BrokerはProduceリクエストを処理した後、Producerにリクエスト完了通知を返信します。この返信は、Producerがリクエストのacksパラメータで指定した、以下のいずれかのタイミングで行われます。これによりProducerは、レスポンスの待ち時間と、データ送信の確実性およびデータ耐久性のトレードオフを選択できます。
| acksの設定 | 返信タイミング |
|---|---|
| 0 | 即時(Producerはレスポンスの返信を待たずにデータを送信し続ける) |
| 1 | Leader Replicaへの書き込み完了時 |
| all | Topicの最小ISR数まで複製完了時(コミット完了時)。 例えば最小ISR数が2の場合、Leader Replica と1個以上のFollower Replicaに複製されたことを確認した時点でレスポンスを返す |
Producerの主なパラメータ
Producerの主要なパラメータを以下に示します。全パラメータの詳細は公式ドキュメントを参照してください。
-
bootstrap.servers
- デフォルト値:なし
- 説明:Brokerの接続先リスト。いずれかのBrokerにアクセスして初期接続を確立する。
-
send.buffer.bytes
- デフォルト値:128 KB
- 説明:TCP送信ソケットバッファのサイズ。-1に設定するとOSのデフォルト値が使用される。
-
receive.buffer.bytes
- デフォルト値:32 KB
- 説明:TCP受信ソケットバッファのサイズ。-1に設定するとOSのデフォルト値が使用される。
-
batch.size
- デフォルト値:16 KB
- 説明:1 Record Batchの最大サイズ。Record Batchがこのサイズに達するとリクエストが送信される。
-
max.request.size
- デフォルト値:1 MB
- 説明:1 リクエストの最大サイズ。リクエストがこのサイズに達するとリクエストが送信される。
-
linger.ms
- デフォルト値:0 ms
- 説明:ネットワークスレッドが送信前にデータ蓄積を待つ時間。Record Batchサイズやリクエストサイズが上限に達していなくても、この時間が経過したら送信される。ネットワークスレッドはユーザスレッドから独立したシングルスレッドであり、各Brokerに対して順番にリクエストを送信する。ネットワークスレッドがあるRecord Batch群をリクエストとして送信している間にも、ユーザスレッドは別のRecord BatchにRecordを追加し続ける。そのためRecord Batchがデータ蓄積を待つ時間は、 linger.ms + ネットワークスレッドが別のリクエスト群を送信処理している時間、となる。よってこのパラメータを0msに設定しても、追加したRecord(のRecord Batch)が即時送信されるわけではないことに注意。
-
buffer.memory
- デフォルト値:32 MB
- 説明:ProducerがRecord Batchのバッファリングに使用できるメモリ量。この値を増やすとバッファリングできるRecord数が増え、送信待ちRecord数が増加した際にも対応できるようになる。Producerはこの他にデータ圧縮や送信処理に別途メモリを使用する。
-
acks
- デフォルト値:1
- 説明:Producerからの送信リクエストにBrokerが書き込み完了通知(ack)を返すタイミング。
- 設定値:0 (即時)、1(Leader Replicaへの書き込み完了時)、all(Topicの最小ISR数まで複製完了時)
-
retries
- デフォルト値:0
- 説明:リクエストの送信失敗時にリトライする回数。acks=1またはallの場合のみ有効。
-
max.in.flight.requests.per.connection
- デフォルト値:5
- 説明:各Brokerとのコネクション内で並列送信できるリクエスト(送信済みだがackが返ってきていないリクエスト)の上限数。2以上に設定した場合、送信失敗時のリトライによってメッセージの順序が変わる可能性がある(次のリクエストが成功した後に、前のリクエストを再試行する可能性がある)。そのため、送信処理したRecordの順序を保証したい場合は1に設定すること。
-
compression.type
- デフォルト値:none (圧縮なし)
- 説明:ProducerはRecord Batch単位でデータを圧縮する。Record Batchサイズが大きいほど圧縮のスループットは高くなる。
- 設定値:none, gzip, snappy, z4
-
max.block.ms
- デフォルト値:60秒
- 説明:ProducerへのRecord登録(send()メソッド呼出)時にバッファリングするメモリが足りない場合や、Brokerからのメタデータ取得(partitionsFor()メソッド呼出)における、処理の最大ブロック時間。この時間ブロックされても処理が完了しなかった場合は例外がスローされる。
Broker
Brokerは複数台のマシンでクラスタを組み、Topicという分散メッセージキューを構成します。
Brokerのしくみ
BrokerはProducerやConsumerおよび他のBrokerから、様々な種類のリクエストを受け付けます。ここではTopicにメッセージを書き込むProduce リクエストと、Topicからメッセージを読み出すFetchリクエストを受信した際の動作について説明します。Produce/Fetchリクエストを受信した際の、Brokerの処理の流れを以下に示します。
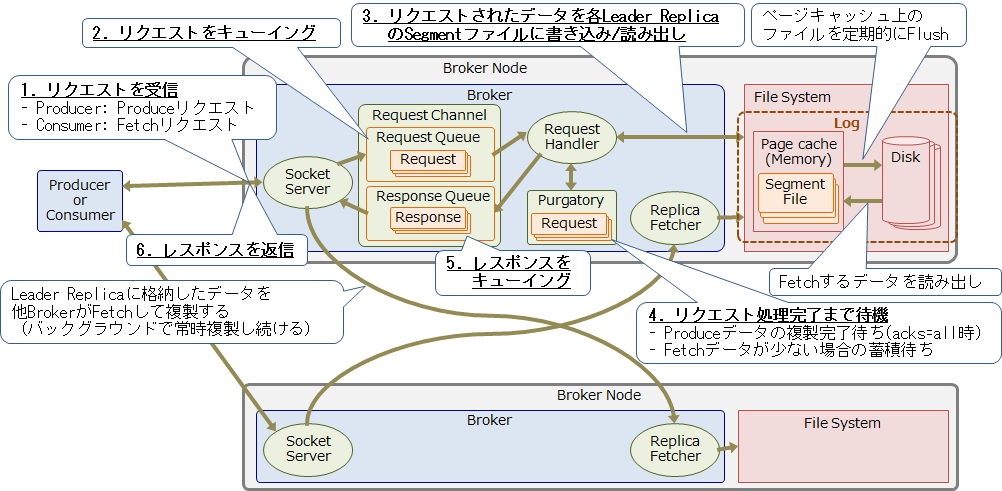
Brokerの各処理の詳細を以下に示します。
1. リクエストを受信
ProducerからはTopicにメッセージを書き込むProduceリクエストを、ConsumerからはTopicからメッセージを読み出すFetchリクエストを受信します。
2. リクエストをキューイング
Socket Serverは受信したリクエストをRequest Channelのリクエストキューに格納します。Request Channelは、リクエスト/レスポンスの送受信を行うSocket Serverと、リクエストの処理を行うRequest Handler間で、リクエスト/レスポンスを受け渡すためのキューです。このキューを使用することで、Socket ServerとRequest Handlerのスレッドがブロックされることを防ぎます。
3. リクエストされたデータを各Leader ReplicaのSegmentファイルに書き込み/読み出し
Request Handlerがリクエストキューからリクエストを取り出して処理します。Produceリクエストの場合はまずデータをローカルにあるLeader ReplicaのSegmentファイルに書き込みます。Acks=1の場合はこの時点でackをレスポンスとしてProducerに返信します(5.へ進む)。Fetchリクエストの場合は、ローカルにあるLeader Replicaからデータを読み出します。もし対象のデータが読み出せた場合は、この時点でレスポンスとしてConsumerに返信します(5.へ進む)
4. リクエスト処理完了まで待機
Produceリクエストがacks=allの場合、データが他のBrokerに複製されるのを待つ必要があります。またFetch対象のデータがReplicaに存在しなかった場合は、対象のデータが蓄積するまでレスポンスの前に一定時間待機します。このときRequest Handerスレッドがブロックされることを防ぐため、リクエストを一旦Purgatoryという場所に格納します。各BrokerのReplica Fetcherスレッドは、他のBrokerのLeader Replicaにあるデータを自身が持つFollower Replicaへ複製するため、定期的にFetchリクエストを送信します。Leader Replicaに格納したデータが最小ISR数まで複製されたことが確認できたら、PurgatoryにあるProduce リクエストは完了したとみなされます。
5. レスポンスをキューイング
リクエストの処理が完了したら、その結果をレスポンスとしてRequest Channelのレスポンスキューに格納します。
6. レスポンスを返信
Socket Serverがレスポンスキューからレスポンスを取り出して、Producer/Consumer/(他のBrokerの)Replica Fetcherに返信します。
Brokerの主なパラメータ
Brokerの主要なパラメータを以下に示します。全パラメータの詳細は公式ドキュメントを参照してください。
Log設定
KafkaではTopicに書き込んだデータの実体をLogと呼びます。Logの保存とフラッシュに関する主要なパラメータを以下に示します。
-
log.dirs
- デフォルト値:なし
- 説明:Logディレクトリのリスト。Brokerの各ディスク上に作成したディレクトリを指定する。
-
log.retention.hours
- デフォルト値:168時間(7日間)
- 説明:Log保存期間(時単位)。log.retention.minutes または log.retention.ms の設定が優先される。
-
log.retention.minutes
- デフォルト値:なし
- 説明:Log保存期間(分単位)。log.retention.ms の設定が優先される。
-
log.retention.ms
- デフォルト値:なし
- 説明:Log保存期間(ミリ秒単位)。
-
log.retention.bytes
- デフォルト値:なし
- 説明:Logの最大保存サイズ。Logがこのサイズに達したら、Log保存期間に関わらず古いものから削除される。
-
log.segment.bytes
- デフォルト値:1 GB
- 説明:Segmentファイルの最大サイズ
-
log.roll.hours
- デフォルト値:168時間 (7日間)
- 説明:Segmentファイルのロールアウト間隔(時単位)。この時間が経過すると、現在使用しているSegmentファイルのサイズが最大値(log.segment.bytes)に達していなくても、そのファイルを閉じて新しいSegmentファイルを作成する。log.roll.ms の設定が優先される。
-
log.roll.ms
- デフォルト値:なし
- 説明:Segmentファイルのロールアウト間隔(ミリ秒単位)。
-
log.cleaner.threads
- デフォルト値:1
- 説明:Log圧縮に使用するスレッド数。
-
background.threads
- デフォルト値:10
- 説明:ファイル削除などバックグラウンドで実行する様々なタスク用のスレッド数。
-
num.recovery.threads.per.data.dir
- デフォルト値:1
- 説明:起動時のLog復旧と、シャットダウン時のフラッシュに使用する、データディレクトリあたりのスレッド数
-
log.flush.interval.messages
- デフォルト値:Long.maxvalue
- 説明:Logのディスクへの強制フラッシュ間隔(Partition単位のメッセージ数)。デフォルトではLong型の最大値が設定されており、Kafkaは明示的なフラッシュを行わず、代わりにOSのバックグラウンドフラッシュ機能に任せている。
-
log.flush.interval.ms
- デフォルト値:なし
- 説明:Logのディスクへの強制フラッシュ間隔(ミリ秒)。設定されていない場合、log.flush.scheduler.interval.ms の値が使用される。
-
log.flush.scheduler.interval.ms
- デフォルト値:Long.maxvalue
- 説明:Logをディスクにフラッシュする必要があるかどうかを確認する間隔(ミリ秒)。デフォルトではLong型の最大値が設定されており、Kafkaは明示的なフラッシュを行わず、代わりにOSのバックグラウンドフラッシュ機能に任せている。
Topic設定
Topic設定に関する主要なパラメータを以下に示します。
-
num.partitions
- デフォルト値:2
- 説明:TopicのPartition数。Topic単位でも個別に指定可能。
-
default.replication.factor
- デフォルト値:1
- 説明:Replicaの複製数(Replication Factor)。PartitionのLeader ReplicaとFollower Replicaの合計数。min.insync.replicasより大きくすること。Topic単位でも個別に指定可能。
-
min.insync.replicas
- デフォルト値:1
- 説明:In Sync Replica (ISR) の最小数。Replicaがこの個数まで同期していないPartition(のLeader Replica)は書き込みを受け付けなくなる。また、Recordはこの個数まで複製された時点でコミットされたものとみなされる。Topic単位でも個別に指定可能。
-
offsets.topic.num.partitions
- デフォルト値:50
- 説明:Consumer offset保存用TopicのPartition数。ConsumerはRecordをどこまで読みだしたのかを示すOffsetを、このTopicに格納して永続化する(詳細は後述)
-
offsets.topic.replication.factor
- デフォルト値:1
- 説明:Consumer offset保存用TopicのPartitionレプリカ数。min.insync.replicasより大きくすること。
リクエスト受付・処理
Socket Server のリクエストの受信/返信、Request Channelにおけるリクエストのキューイング、およびRequest Handlerのリクエスト処理に関するパラメータを以下に示します。
-
num.network.threads
- デフォルト値:3
- 説明:Socket Serverがリクエストの受信とレスポンスの送信に使用するスレッド数。
-
message.max.bytes
- デフォルト値:976 KB
- 説明:Socket Serverが受け付ける最大Record Batchサイズ。
-
socket.request.max.bytes
- デフォルト値:100 MB
- 説明:Socket Serverが受け付ける最大リクエストサイズ。
-
socket.receive.buffer.bytes
- デフォルト値:100 KB
- 説明:Socket Server のTCP受信ソケットバッファサイズ。-1に設定するとOSのデフォルト値が使用される。
-
socket.send.buffer.bytes
- デフォルト値:100 KB
- 説明:Socket Server のTCP送信ソケットバッファサイズ。-1に設定するとOSのデフォルト値が使用される。
-
queued.max.requests
- デフォルト値:500
- 説明:Request Channelのリクエストキューのサイズ。リクエストがこの数までキューに詰まれると、Socket Serverは新規リクエストの受付を停止する。
-
num.io.threads
- デフォルト値:8
- 説明:Request Handlerのリクエスト処理用スレッド数。この処理はディスクI / Oを含む。
Replica複製
Replicaの複製に関するパラメータを以下に示します。
-
num.replica.fetchers
- デフォルト値:1
- 説明:Replica Fetcher用スレッド数。このスレッドがLeader Replica を持つBrokerにFetchリクエストを送信して、取得したRecordをローカルのFollower Replicaに書き込む。
-
replica.socket.receive.buffer.bytes
- デフォルト値:64 KB
- 説明:Replica FetcherのTCP受信ソケットバッファのサイズ。-1に設定するとOSのデフォルト値が使用される。
-
replica.lag.time.max.ms
- デフォルト値:10秒
- 説明:Replica複製の滞留・遅延の判定時間。下記の状態がこの判定時間以上続いたFollower Replicaは、同期していないとみなされてISRから除外される。
- Leader Replicaに対してFetchリクエストを送信していない
- Replicaの最新Offsetまで取得が追い付いていない
クラスタ管理
クラスタの管理に関するパラメータを以下に示します。なお、ZooKeeprとの接続が途切れたBrokerは、再接続されるまでクラスタから除外されます。
-
broker.id
- デフォルト値:0
- 説明:クラスタ内でBrokerを一意に識別するID。0から始まる数値を使用する。
-
zookeeper.connect
- デフォルト値:なし
- 説明:ZooKeeperのホスト名のリスト
-
zookeeper.connection.timeout.ms
- デフォルト値:なし
- 説明:Zookeeperコネクションのタイムアウト。BrokerがZooKeeperとの接続を確立する際の最大待機時間。設定されていない場合は、zookeeper.session.timeout.ms の値が使用される。
-
zookeeper.session.timeout.ms
- デフォルト値:6秒
- 説明:Zookeeperセッションのタイムアウト。この期間内にBrokerからZooKeeperへのハートビートがない場合、ZooKeeperはそのBrokerが消えたと判断し、Brokerの情報をZooKeeper上から削除したうえで他のBrokerに通知する。
Consumer
ConsumerはメッセージをTopicから読み出すためのクライアントライブラリです。ユーザアプリケーションはConsumerを使用して、Brokerクラスタ上に構成されたTopicの各Partitionからメッセージを読み出します。
Consumerのしくみ
ConsumerもProducerと同様に、定期的にいずれかのBrokerからメタデータを取得することで、各Brokerのホスト名、接続先ポート、各Topic PartitionのLeader Replicaの場所など把握します。Consumerはこの情報を元に、どのBrokerからRecordを取得するのか決定します。
Consumerがメタデータを取得後に、実際にメッセージを取得するときの処理の流れを以下に示します。
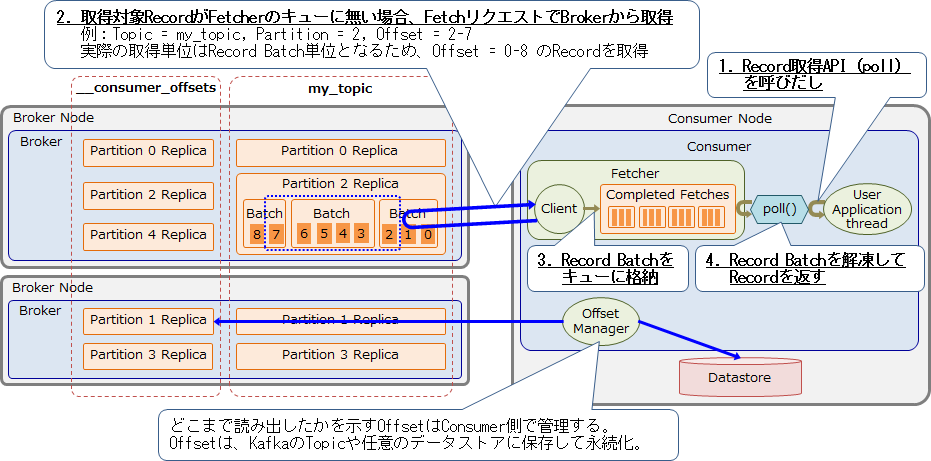
ユーザアプリケーションはRecordを取得するためにConsumerの Poll APIを呼び出します。Consumer内部のキューに取得対象のRecordがなかった場合は、BrokerにFetchリクエストを投げてRecordを取得します。Fetchリクエストでは取得対象のTopic、partitionのリスト、各Partitionで取得したいOffset(Record番号)の範囲、の3つを指定します。ただし、実際の取得単位はRecord Batch単位となります。Brokerから取得したRecord BatchはConsumer内部のキューに格納されます。このキューからRecord Batch を取り出して解凍し、pollを呼び出したユーザアプリケーションにRecordを返します。
ConsumerがRecordをどこまで読みだしたのかを示すOffsetはConsumer側で管理し、Broker側では排他制御を行いません。そのためConsumer数が増加しても、Broker側の負担は少なく済みます。Consumerはアプリケーションの再起動時に、自身のOffsetから再開できるようOffsetを永続化する必要があります。そのため、Consumerは自身のOffsetをKafka上のOffset用Topicや、任意のデータストアに保存します。
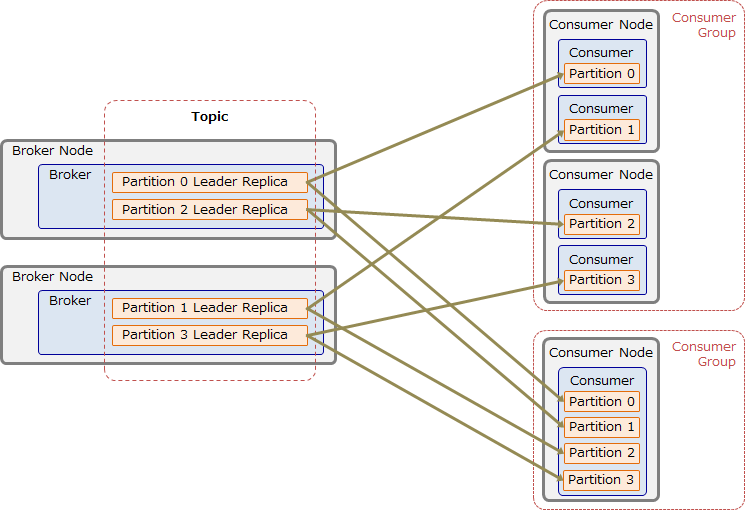
Consumer Groupについて
ユーザアプリケーションは、1つ以上のConsumerでConsumer Groupを構成することで、1TopicのデータをGroup内のConsumerで分散読み出しできます。以下の図に示す通り、Topicの各パーティションは、Consumerグループ内の特定の1 Consumerのみが読み出します。これにより、Topicのメッセージを並列かつ(Consumer Group内では)重複なしに読み出すことができます。このようにデータを分散読み出しできるため、KafkaはHadoop/Spark/Stormなどの並列分散処理フレームワークと相性が良いです。また、Topicのデータは読み出されてもすぐには削除されないため、同じTopicのデータを複数のConsumer Groupから読み出すことができます。
Consumerの主なパラメータ
Consumerの主要なパラメータを以下に示します。全パラメータの詳細は公式ドキュメントを参照してください。
-
bootstrap.servers
- デフォルト値:なし
- 説明:Brokerの接続先リスト。いずれかのBrokerにアクセスして初期接続を確立する。
-
group.id
- デフォルト値:なし
- 説明:Consumer Group名
-
fetch.min.bytes
- デフォルト値:1byte
- 説明:Fetchリクエストで取得する最小データサイズ。
-
fetch.max.bytes
- デフォルト値:1MB
- 説明:Fetch リクエストで取得する1Partitionあたりの最大データ量。
-
max.partition.fetch.bytes
- デフォルト値:50MB
- 説明:Fetch リクエストで取得する最大データ量。
-
fetch.max.wait.ms
- デフォルト値:500ms
- 説明:FetchリクエストがPurgatoryで待機する最大時間。Fetch リクエストで取得するデータ量がfetch.min.bytesに満たない場合、FetchリクエストはBrokerにデータが蓄積するまでPurgatoryで待機する。この値は replica.lag.time.max.ms より小さくする。
-
max.poll.records
- デフォルト値:500
- 説明:1回のpoll() 呼出で取得する最大レコード数。
-
receive.buffer.bytes
- デフォルト値:64KB
- 説明:TCP受信ソケットバッファのサイズ。-1に設定するとOSのデフォルト値が使用される。
-
enable.auto.commit
- デフォルト値:True
- 説明:OffsetをバックグラウンドでKafkaに自動コミットするか否か。
-
auto.commit.interval.ms
- デフォルト値:5秒
- 説明:OffsetをKafkaに自動コミットする頻度(ミリ秒単位)。
おわりに
本投稿ではKafkaのProducer、Broker、Consumerのしくみと設定一覧について紹介しました。次回の投稿ではKafkaの推奨構成と性能の見積もり方法について紹介します。