初版: 2018/11/9
著者: 伊藤 雅博, 株式会社日立製作所
はじめに
この投稿ではオープンソースカンファレンス2017.Enterpriseで発表した「めざせ!Kafkaマスター ~Apache Kafkaで最高の性能を出すには~」の検証時に調査した内容を紹介します(全8回の予定)。本投稿の内容は2017年6月にリリースされたKafka 0.11.0 時点のものです。
第7回目となる今回は、Producerの再チューニング結果とConsumerのチューニング結果を紹介します。第6回の投稿ではBrokerのチューニングを行いましたが、最終的にはスループットが大幅に低下してしまいました。そこで今回は、Brokerのチューニングをした状態で改めてProducerのチューニングを行ってみます。その後Consumerのチューニングを行い、Producerの送信からConsumerの受信までを通した全体のスループットを最適化します。
投稿一覧:
- Apache Kafkaの概要とアーキテクチャ
- Apache KafkaのProducer/Broker/Consumerのしくみと設定一覧
- Apache Kafkaの推奨構成と性能の見積もり方法
- Apache Kafkaの性能検証(1): 検証環境とパラメータチューニングの内容
- Apache Kafkaの性能検証(2): Producerのチューニング結果
- Apache Kafkaの性能検証(3): Brokerのチューニング結果
- Apache Kafkaの性能検証(4): Producerの再チューニングおよびConsumerのチューニング結果 (本投稿)
- Apache Kafkaの性能検証(5): システム全体のレイテンシについて
Producerの再チューニング
前回の検証で、acks を 1 から all に変更した際にスループットが大幅に低下することが分かりました。これは、acks が 1 の時と all の時では適切な Record Batch サイズや Producer数などが異なるためと考えられます。そこで今回は、前回までのパラメータ最適化をした状態で acks=all に設定し、改めて Producerのチューニングを行います。
batch.size のチューニング
最初に、Producer用ノード2台かつProducer 3個で batch.size を再チューニングした結果を以下に示します。
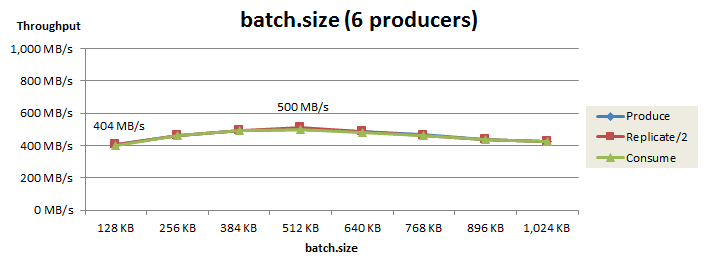
このパラメータを128KBから512KBに増やすことで、Produceスループットは 404 MB/s から 500 MB/s まで向上しました。
Producer数のチューニング
次に、Producer数の再チューニング結果を以下に示します。Producerノードは2台で合計80コア1を持ち、各Producerがユーザスレッドとネットワークスレッドで合計2コアを使用するため、本検証では最大40 Producerまで増やして測定を行いました。
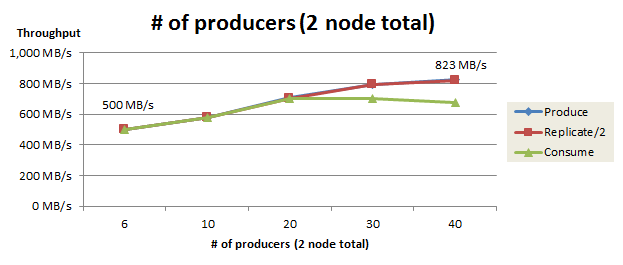
Producer数を6個(1Producerノードあたり3個)から40個(1Producerノードあたり20個)まで増やすと、Produceスループットは 500 MB/s から 823 MB/s まで向上しました。Producerノードをさらに増やしてProducer数を増やせば、Produceスループットはさらに向上する可能性があります。
num.network.threads のチューニング
最後に、Broker側のネットワークスレッド数(num.network.threads)の再チューニング結果を以下に示します。
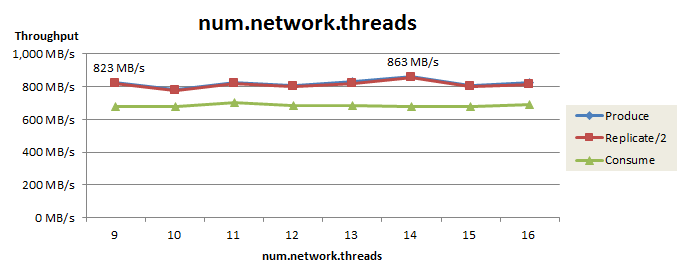
ネットワークスレッド数を増やしてもProduceスループットはほぼ横ばいでしたが、14個まで増やすとスループットが 823 MB/s から 863 MB/s まで若干向上しました。
Producerの再チューニング結果まとめ
Producerの再チューニング結果を以下にまとめました。
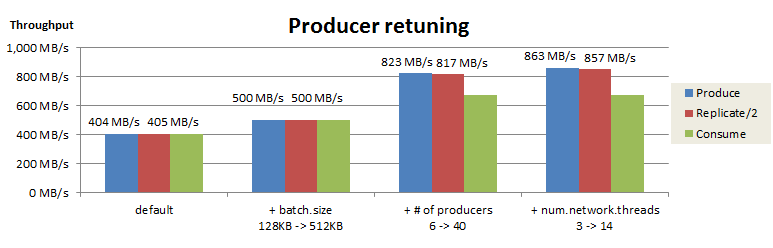
これらのチューニングにより、acks=all の状態でProduceスループットが 404 MB/s から 863 MB/s まで向上しました。この結果から、acksが1とallの場合で適切な batch.size や Producer数が異なることを確認できました。
Consumerのチューニング
今までのチューニングを行った状態で、最後にConsumer の取得性能をチューニングすることで、Producerの送信からConsumerの受信まで含めたシステム全体のスループットを最適化します。Consumerまで含めたここまでのチューニング範囲を以下の図に赤色で示します。Consumerのチューニングを行うことで、Producer、Broker、Consumerの3コンポーネントすべてのチューニングが完了します。
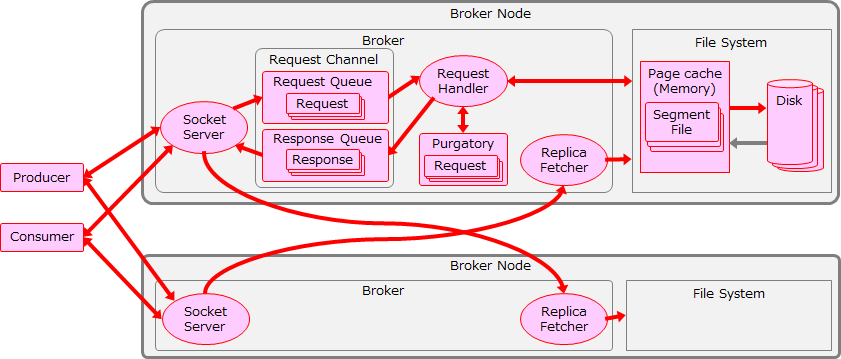
fetch.max.bytes のチューニング
最初に、Consumerが1回のFetchリクエストで取得する最大サイズ(fetch.max.bytes)を変更した結果を以下に示します。このパラメータには大きな値(1,000 MB)を設定して、次にチューニングするPartition単位の最大取得サイズ(max.partition.fetch.bytes)で1回あたりの取得サイズを調整することにします。
この変更により、Consumeスループットは 676 MB/s から 688 MB/s まで若干向上しました。
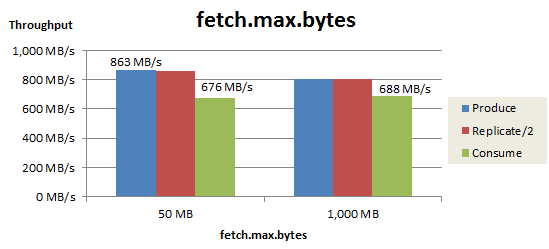
max.partition.fetch.bytes のチューニング
次に、1回のFetchリクエストにおけるPartition単位の最大取得サイズ(max.partition.fetch.bytes)をチューニングした結果を以下に示します。
このパラメータを 1 MBから 7 MBまで増やすことで、Consumeスループットは 688 MB/s から 763 MB/s まで向上しました。
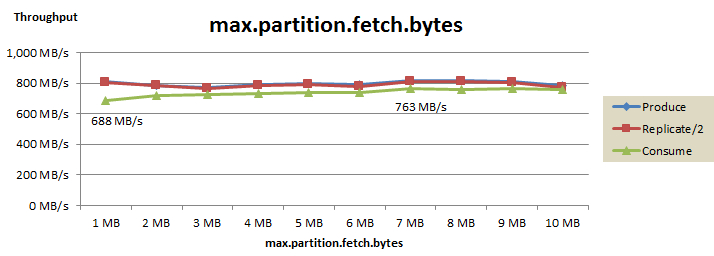
Consumer数 のチューニング
最後に、Consumer数のチューニング結果を以下に示します。
Consumer数を増やしてもConsumeスループットはほぼ横ばいでしたが、4から6に増やすことで、スループットは763 MB/s から 803 MB/s まで若干向上しました。Consumerの処理はProducerと比べてオーバーヘッドが少ないため、Consumer数は6個で十分なのだと思います。
Consumerのチューニング結果まとめ
Consumerの取得性能のチューニング結果を以下にまとめました。
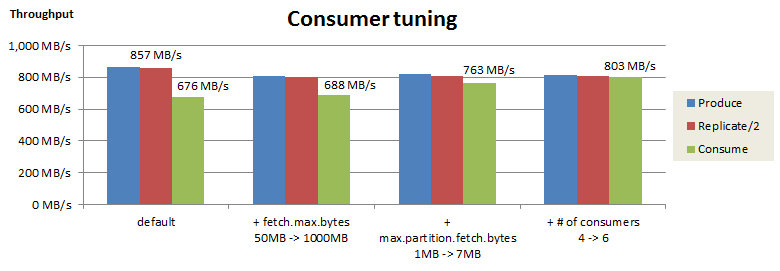
これらのチューニングにより、Consumeスループットは 676 MB/s から 803 MB/s まで向上しました。またProduce/ReplicateスループットもConsumeスループットとほぼ釣り合っており、システム全体を通して 803 MB/s のスループットを出せることが確認できました。
システム全体のスループットの評価
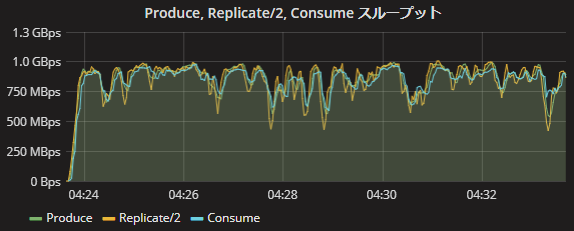
今回の検証でProducer、Broker、Consumerのチューニングが完了し、Producerの送信からConsumerの受信までを通した全体のスループットを最適化しました。これまでのチューニングにより、同期レプリケーション(acks=all、Replication Factor=3、min.insync.replicas=2)で平均 803MB/sのスループットを達成しました。
これはネットワーク帯域の理論値(1,170 MB/s)の約70%です。この時のProduce、Replicate、Consumeスループットの推移を以下に示します。スループットの平均は803MB/sですが、スループットは時間とともに上下しており、最大で1,000 MB/s(理論値の約85%)程度の帯域を使用していることが分かります。
チューニングのポイント
これまでのチューニングで大きな効果があったパラメータを以下に示します。
-
Producer の batch.size
- KafkaはRecord Batch単位でデータを処理するため、Record Batchサイズを増やすことで、処理のオーバーヘッドが減りスループットが向上します。また、acks=allではackの返信に時間がかかるため、リクエスト頻度を増やすよりRecord Batchサイズを増やして1回のリクエストサイズを大きくした方が良いと考えられます。
-
Producer の個数
- Producer数を増やすことで送信データ量が増えるほか、Brokerとのコネクション数(並列処理数)が増えるため、スループットが向上します。
-
Broker の num.replica.fetchers
- Replica fetcher数を増やすことで、レプリケーションのスループットが大幅に向上しました。ただし、Replica fetcherに対するPartition割り当ての偏りを回避するため、Replica Fetcher 数をBroker数の倍数にしないことを推奨します。
-
Consumer の replica.fetch.response.max.bytes、max.partition.fetch.bytes、Consumer Group内のConsumer数
- ConsumerのFetchサイズとConsumer数を増やすことでスループットが向上しました。Consumerの処理はProducerと比べてオーバーヘッドが少ないため、Producerと比べて少ない個数でも十分なスループットを出すことができます。
おわりに
これまでの検証では、データ処理のスループットに着目してチューニングを行いました。一般的に、スループットが増加するとレイテンシも増加しますが、これまで検証で行ったチューニングはレイテンシを考慮しませんでした。そこで次回はレイテンシの測定結果について紹介します。
第8回:Apache Kafkaの性能検証(5): システム全体のレイテンシについて