初版: 2018/11/1
著者: 伊藤 雅博, 株式会社日立製作所
はじめに
この投稿ではオープンソースカンファレンス2017.Enterpriseで発表した「めざせ!Kafkaマスター ~Apache Kafkaで最高の性能を出すには~」の検証時に調査した内容を紹介します(全8回の予定)。本投稿の内容は2017年6月にリリースされたKafka 0.11.0 時点のものです。
第6回目となる今回はBrokerのチューニング結果を紹介します。第5回の投稿では、Producer-Broker間の通信スループットを最適化しました。この最適化をした状態で、今回はBrokerのLogフラッシュ性能と、Broker間のレプリケーション性能をそれぞれチューニングして、スループットを最適化していきます。
投稿一覧:
- Apache Kafkaの概要とアーキテクチャ
- Apache KafkaのProducer/Broker/Consumerのしくみと設定一覧
- Apache Kafkaの推奨構成と性能の見積もり方法
- Apache Kafkaの性能検証(1): 検証環境とパラメータチューニングの内容
- Apache Kafkaの性能検証(2): Producerのチューニング結果
- [Apache Kafkaの性能検証(3): Brokerのチューニング結果 (本投稿)
- Apache Kafkaの性能検証(4): Producerの再チューニングおよびConsumerのチューニング結果
- Apache Kafkaの性能検証(5): システム全体のレイテンシについて
BrokerのLogフラッシュ性能のチューニング
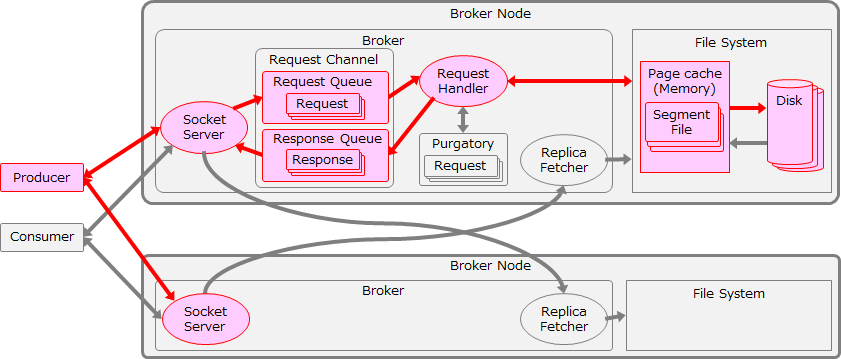
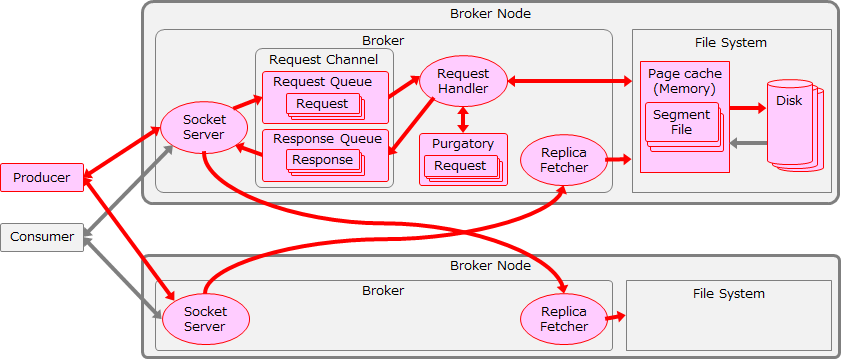
まずはBrokerのLogフラッシュまで含めたスループットを最適化します。ここまでのチューニング範囲を以下の図に赤色で示します。
acks を1に変更
第5回の投稿では、BrokerのLogフラッシュとレプリケーションの影響を排除するために、acks=0でチューニングを行いました。今回の検証ではBrokerのLogフラッシュをまで含めた性能を検証するために、acksを1に設定します。acksを0から1に変更した際の、スループットの変化を以下に示します。
なお、本検証ではReplication factor=3で測定を行っており、Produceしたデータの2倍の量をBroker間で複製するため、ReplicateスループットはProduce/Consumeスループットと比較しやすいように半分の値を表示しています。
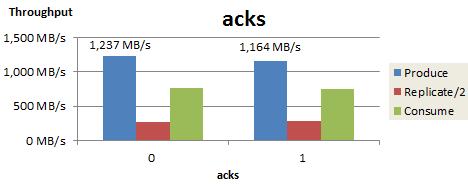
acksを1に変更するとProduceスループットが若干低下しましたが、依然として理論値である1,170MB/s1に近いスループットを保っていることが確認できます。
log.flush.scheduler.interval.ms のチューニング
Logフラッシュ間隔(log.flush.scheduler.interval.ms)をチューニングした際の、スループットの推移を以下に示します。図の一番左はデフォルト設定(Long型最大値)であり、Kafkaは明示的なフラッシュを行わずOSのバックグラウンドフラッシュ機能に任せている状態です。
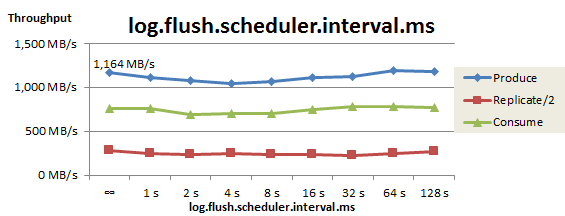
フラッシュ間隔を変更してもProduceスループットはほぼ横ばいでした。この測定により、フラッシュ間隔はデフォルト設定で問題ないことが確認できましたした。
num.io.threads のチューニング
最後に、リクエストを処理するRequest Handlerのスレッド数(num.io.threads)をチューニングした結果を以下に示します。
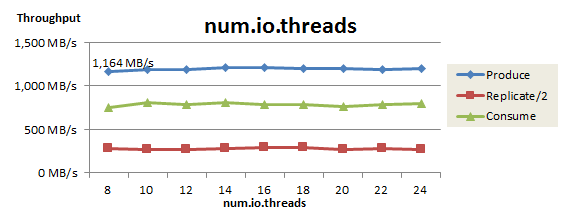
スレッド数を変更してもProduceスループットはほぼ横ばいでした。この測定により、Request Handlerのスレッド数はデフォルトの8個で問題ないことが確認できました。
Logフラッシュ性能のチューニング結果まとめ
BrokerのLogフラッシュ性能のチューニング結果を以下にまとめました。
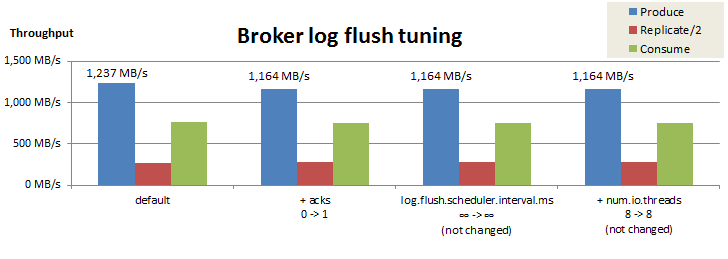
今回の検証では、Logフラッシュ性能のチューニングは不要でした。これは、ディスクI/O性能の理論値がネットワークI/O性能より高く、ディスクI/Oがボトルネックにならないためと考えられます1。結果として、Producerの送信スループットはacks=1で1,164 MB/sとなり、依然として理論値(1,170MB/s)に近いスループットを保っています。
Broker間のレプリケーション性能のチューニング
次にBroker間のレプリケーションまで含めたスループットを最適化します。この検証ではチューニングによるReplicateスループットの推移を確認するため、最初はacks=1でチューニングを行います。そしてReplicateスループットがProduceスループットと釣り合うまで向上した後、acks=allに設定して測定を行います。ここまでのチューニング範囲を以下の図に赤色で示します。
replica.fetch.response.max.bytes のチューニング
最初に、Replica fetcherが1回のFetchリクエストで取得する最大サイズ(replica.fetch.response.max.bytes)を変更した結果を以下に示します。このパラメータには大きな値(100MB)を設定して、次にチューニングするPartition単位の最大取得サイズ(replica.fetch.max.bytes)で取得サイズを調整することにします。
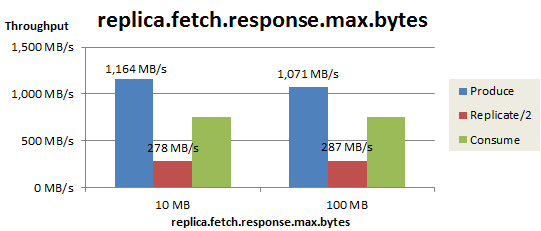
この変更により、Replicateスループットは278 MB/sから287 MB/sまで若干向上しました。
replica.fetch.max.bytes のチューニング
次に、Replica fetcherが1回のFetchリクエストで取得するPartition単位の最大サイズ(replica.fetch.max.bytes)をチューニングした結果を以下に示します。
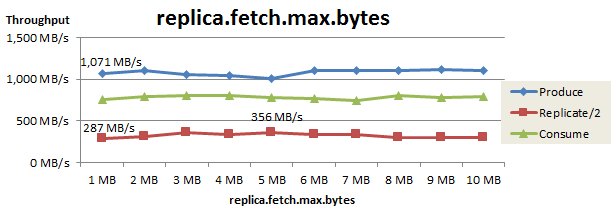
このパラメータを1MBから5MBに増やすことで、Replicateスループットは287MB/sから356MB/sまで向上しました。
num.replica.fetchers と num.network.threads のチューニング
Replica fetcherのスレッド数(num.replica.fetchers)を増やすと、Brokerに対するコネクション数が増えるため、BrokerのSocket Serverにも負荷がかかります。そこで、Replica fetcherスレッド数とSocket Serverのネットワークスレッド数(num.network.threads)を同時にチューニングしました。このチューニングによるReplicateスループットの推移を以下に示します。
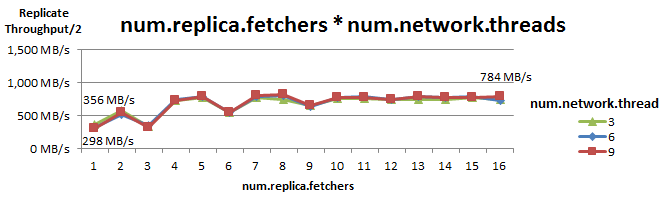
num.replica.fetchers のチューニングは効果が大きく、num.network.threads の影響は小さいことが確認できました。num.replica.fetchers の増加に応じてスループットは向上していきますが、num.replica.fetchers が3の倍数の時はスループットが落ちる傾向がありました。この理由は後ほど説明します。
測定の結果、num.network.threads=9 で num.replica.fetchers を1から16に増やした時、Replicateスループットは356MB/sから784MB/sまで向上しました。num.network.threads=9 におけるProduce/Replicate/Consumeスループットの推移を以下に示します。
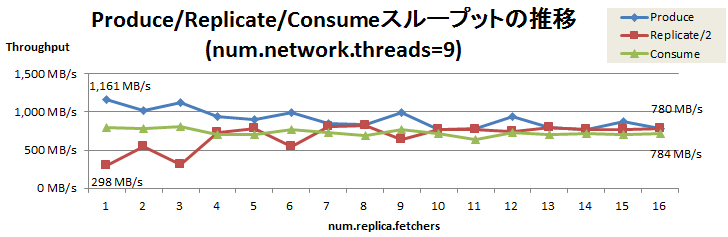
num.replica.fetchersの増加に応じてProduceスループットが低下し、Replicateスループットは向上しました。そして num.replica.fetchers=16 のとき、Replicateスループット(784 MB/s)とProduceスループット(780MB/s)がほぼ釣り合うことが確認できました。
acks をallに変更
最後にacks を1からallに変更した際のスループットを以下に示します。本検証ではmin.insync.replicas=2で測定しているため1、acks=allに設定することで、データがLeader Replicaと1個以上のFollower Replicaに複製されたことを確認した時点で、Producerにレスポンスを返すようになります。
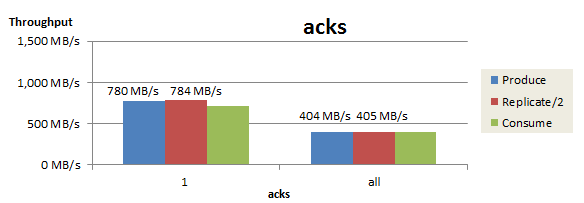
acks=1の時点でProduceとReplicateのスループットがほぼ釣り合っていたにも関わらず、acks=allに設定するとスループットは大幅に低下してしまいました。
レプリケーション性能のチューニング結果まとめ
Broker間のレプリケーション性能のチューニング結果を以下にまとめました。
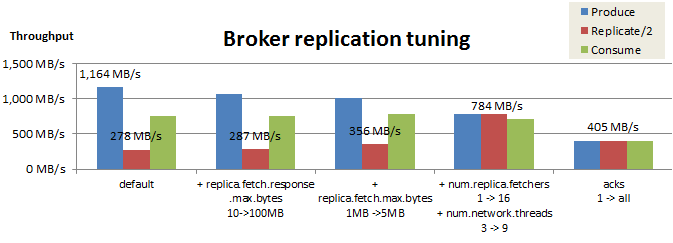
今回の検証では、acks=1でReplicateスループットを784MB/sまで改善できましたが、acks=allに変更するとスループットは405MB/sまで大幅に低下してしまいました。
Replica fetcherに対するPartition割り当ての偏り
今回の検証ではnum.replica.fetchers が3の倍数のときレプリケーション性能が低下しました。これはReplica fetcherに対するPartition割り当ての偏りが原因です。
例として、3台のBrokerに6個のPartition(のLeader Replica)を割り当てるとします。Topicの新規作成時、Partition 0のLeader ReplicaがいずれかのBrokerに割り当てられ、Partition 1以降はBroker IDの順に割り当てられます(AdminUtils.scala および PartitionStateMachine.scala を参照)。例えば Partition 0 (のLeader Replica)が Broker1 に割り当てられた場合、以下のような対応関係になります。
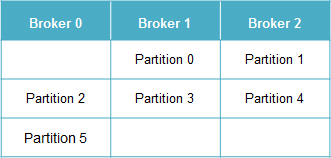
もし各Brokerが3個のReplica fetcherスレッドを持つ場合、各Replica fetcherはどのPartitionを担当するでしょうか?まずReplica fetcher 0がいずれかのPartitionに割り当てられ、Replica fetcher 1以降はPartition IDの順に繰り返し割り当てられます(AbstractFetcherManager.scalaを参照)。例えば Replica fetcher 0 がPartition 1 に割り当てられた場合、以下のような対応関係になります。
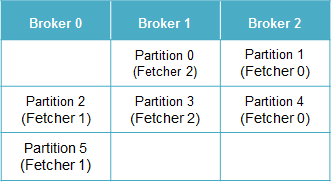
上記の通り、このアルゴリズムではReplica Fetcher 数がBroker数の倍数だと、各Replica Fetcherに同一BrokerのPartitionを割り当てます。そのため、1個のReplica Fetcherは自BrokerのPartitionのみを担当することになり、全く使用されなくなります(Replica Fetcherは他BrokerにあるPartitionのデータを取得するため)。これによりレプリケーション性能が低下します。
なお、Topicが複数ある場合はReplica fetcherの割り当てが分散するため、この偏りは緩和されます。
おわりに
今回はBrokerのチューニング結果を紹介しましたが、acks=allに設定するとスループットが大幅に低下してしまいました。これは、acksが1の時とallの時では適切なRecord BatchサイズやProducer数などが異なるためと考えられます。そこで次回は、acks=allにした状態で改めてProducerのチューニングを行ってみます。その後Consumerのチューニングを行い、システム全体のスループットを最適化した結果を紹介します。
第7回:Apache Kafkaの性能検証(4): Producerの再チューニングおよびConsumerのチューニング結果