初版: 2018/9/28
著者: 伊藤 雅博, 株式会社日立製作所
はじめに
この投稿ではオープンソースカンファレンス2017.Enterpriseで発表した「めざせ!Kafkaマスター ~Apache Kafkaで最高の性能を出すには~」の検証時に調査した内容を紹介します(全8回の予定)。本投稿の内容は2017年6月にリリースされたKafka 0.11.0 時点のものです。
第1回目となる今回は、Apache Kafkaの概要とアーキテクチャについて紹介します。
投稿一覧:
- Apache Kafkaの概要とアーキテクチャ (本投稿)
- Apache KafkaのProducer/Broker/Consumerのしくみと設定一覧
- Apache Kafkaの推奨構成と性能の見積もり方法
- Apache Kafkaの性能検証(1): 検証環境とパラメータチューニングの内容
- Apache Kafkaの性能検証(2): Producerのチューニング結果
- Apache Kafkaの性能検証(3): Brokerのチューニング結果
- Apache Kafkaの性能検証(4): Producerの再チューニングおよびConsumerのチューニング結果
- Apache Kafkaの性能検証(5): システム全体のレイテンシについて
Apache Kafkaとは
Apache Kafka(以降、Kafka)はスケーラビリティに優れた分散メッセージキューです。メッセージキューとは、システム間のデータの受け渡しを仲介し、データを一時的に保持(キューイング)するミドルウェアです。メッセージキューを導入することには、以下のような利点があります。
- メッセージキューを介してシステム間の通信を行うことで、システム間の接続経路を簡略化し、システムを疎結合に保つ
- システム間の通信を非同期化することで、データ流量の急激な増加によるシステムの負荷上昇を抑制する
Kafkaは処理性能を重視したメッセージキューであり、複数台のマシンでクラスタを構成して分散処理を行うことで、高いスループットを発揮します。後からクラスタにマシンを追加することで、処理性能とデータ保持容量をスケールアウトすることもできます。また、Kafkaはクラスタ内でデータを複製するため、一部のマシンに障害が発生してもデータを失うことなく処理を継続できます。
Kafkaのユースケース
Kafkaは主に以下の2種類のユースケースで使用されています。
データハブの構築
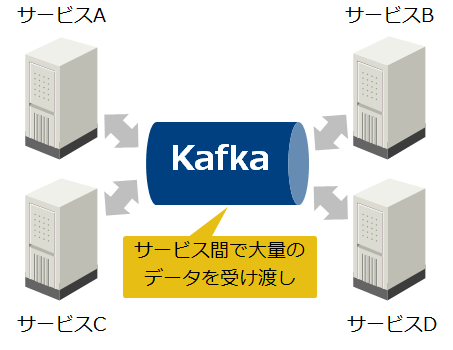
複雑なシステムをサービス単位で分割して疎結合に保つことで、迅速な機能追加や不良修正が可能なマイクロサービスが多くの企業で導入されています。しかし、多数のサービス間で直接データを受け渡そうとすると接続経路が複雑になります。またデータ流量の急激な増加により、サービスの負荷が急増することもあります。Kafkaはこのようなサービス間で、大量のデータを受け渡すためのハブとして活用されています。
ストリーミングアプリケーションの構築
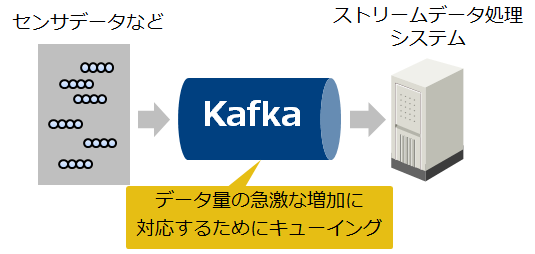
Webサービスやネットワークに接続されたデバイスは、大量のデータをリアルタイムに生成します。このようなデータをリアルタイムに処理するストリーミングアプリケーションにおいて、データ量の急激な増加に対応するためのキューとしてKafkaが活用されています。
システム構成
Kafkaの全体アーキテクチャを以下に示します。
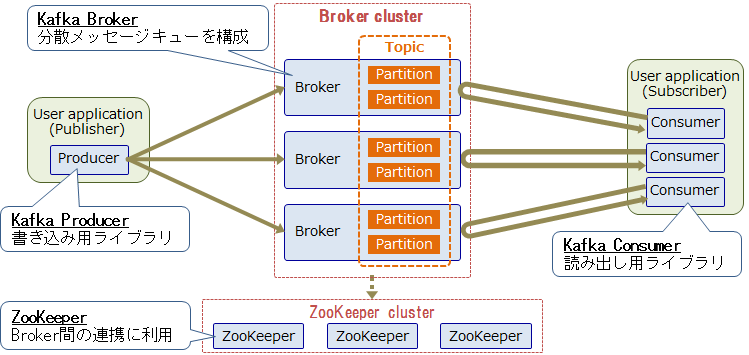
Kafkaは複数のBrokerでクラスタを構成し、このクラスタ上にTopicと呼ばれる分散キューを構成します。Kafkaのメッセージはキーバリュー形式であり、Recordと呼びます。1つのTopicは、複数のBrokerに分散配置されたPartitionで構成されており、このPartition単位でRecordの書き込み/読み込みを行うことで、1つのTopicに対する並列書き込み/読み出しを実現します。Broker同士はクラスタコーディネータであるZooKeeperを使用して連携し、Brokerの1つがリーダーとなりBrokerクラスタを管理します。
KafkaはPub/Subメッセージングモデルを採用しています。また、Kafkaは書き込み/読み出し性能を重視しており、Topicに対する書き込み/読み出しには、MQTTなどの標準プロトコルではなく、独自プロトコルを使用します。書き込み側のアプリケーション(Publisher)はProducerと呼ばれる書き込み用ライブラリを通じて、BrokerのTopicにRecordを書き込みます。読み出し側のアプリケーション(Subscriber)はConsumerと呼ばれる読み出し用ライブラリを通じて、Recordを取り出します。Kafka本体に含まれているProducer/ConsumerライブラリはJava製ですが、他にもサードパーティからPythonやC++など様々な言語製のライブラリが提供されており、様々なアプリケーションや機器に組み込むことができます。
Topicに書き込んだデータはBrokerのディスクに保存され、読み出されてもすぐには削除されません。そのため、同じTopicのデータを複数のアプリケーションから読み出すことができます。一定期間が経過したRecordや、Partitionの最大容量を超えた分のRecordは自動的に削除されます。また、Partition 内のRecordはBroker間で複製されるため、一部のBrokerノードに障害が発生してもRecordが失われにくい仕組みになっています。
データ管理
Kafkaの論理/物理データ構造とその管理方法について説明します。
論理データ構造とデータ複製
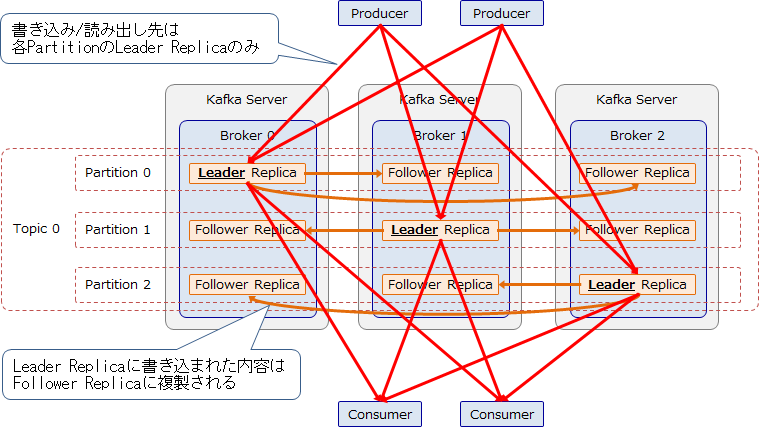
Topic、Partition、Replica
1つのTopicは複数のPartitionで構成されており、各PartitionはBroker間で複製された複数のReplicaで構成されます。各Partitionには1個のLeader Replicaと0個以上のFollower Replicaが存在し、Leader Replicaに書き込まれたRecordはFollower Replicaに複製されます。
この複製方法はLeader/Follower型と呼ばれ、Replicaの複製数(1個のLeaderと0個以上のFollowerの合計数)をReplication Factorと呼びます。各Leader ReplicaはBrokerに均等に割り当てられ、Partitionへの書き込み/読み出しはLeader Replicaにのみ行います。Brokerノードの障害などでLeader Replicaが使用できなくなった際は、いずれかのFollower ReplicaがLeader Replicaに昇格します。
TopicのPartition数とReplication FactorはTopicの作成時に指定します。Brokerノード3台で1 Topic、3 Partition、Replication Factor = 3の場合の、データ構造の例を以下に示します。
In Sync Replica(ISR)
Brokerやネットワークの問題により、LeaderからFollowerへの複製が遅延または停止して、LeaderとFollowerの内容が同期しなくなることがあります。Kafkaのデフォルトの設定では、複製が追い付いていない状態が10秒間続いたFollowerは同期していないとみなされます。Brokerは常に「同期しているFollowerのリスト」を追跡しており、同期しているReplicaをIn Sync Replica(ISR)と呼びます。
ISRの最小数はTopicごとに設定することが可能で、現在のISR 数はPartitionごとに追跡されます。あるPartitionのISR数が最小数を下回ると、そのPartition(のLeader Replica)はProducerから書き込み出来なくなります。ISR数が最小数まで回復すると、そのPartitionは再びProducerから書き込み出来るようになります。ISRの最小数まで書き込まれたRecordはコミットされたものとみなされ、ConsumerはコミットされたRecordのみを取得できます。
物理データ構造とデータ保存方法
Log、Segment
BrokerはTopicに書き込まれたRecordをファイルに保存することで永続化します。BrokerはReplica ごとにデータディレクトリを作成して、Recordは各ディレクトリ内のSegmentというファイルに書き込みます。このSegmentファイルの集合を、KafkaではLogと呼んでいます。
通常、Brokerノードは複数台のディスクを搭載しており、各ディスクに対してラウンドロビン方式でReplicaのデータディレクトリを割り当てます。そのため、最低でもディスク台数分のReplicaがないとディスクを使い切れません(Replica数 = 全TopicのPartition数 * Replication Factor)。また、Partition間のデータのバランスが悪いと、ディスク間に負荷の不均衡が発生してしまいます。
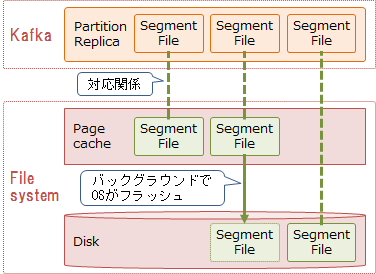
Segmentファイルのフラッシュ
Segmentファイルはファイルシステムが管理しています。Linuxでは、ファイルシステムに書き込まれたデータは、ディスクに書き出されるまでメモリ上のページキャッシュに保持されます。デフォルト設定では、KafkaはOSに対してディスクへの書き込み指示は行わず、OSがバックグラウンドでページキャッシュ上のデータを定期的にディスクへフラッシュするのに任せます。なお、フラッシュ後もメモリに余裕があれば、データはページキャッシュ上に残り続けるため、高速に読み出すことができます。
Brokerの設定により、一定期間または一定量のデータが書き込まれた際に、データを強制的にフラッシュすることも可能です。ただし、KafkaはBrokerノードが故障した際は別のBrokerノードのReplicaからデータを回復するため、ディスクへのデータ同期を必要とはしていません(他のノードのページキャッシュ上に複製されていればよいという考え方)。そのため、デフォルトのフラッシュ設定を使用することを推奨します。
Kafkaのツール
Kafkaに付属する主なツールについて、その概要を簡単に説明します。詳細についてはリンク先の公式ドキュメントを参照してください。
Kafka Connectを使用することで、DBなどの外部システムとKafka間でデータを書き込み/読み出しするコネクタを定義できます。Offsetの永続化など、Kafkaと外部システムを接続する際に必要な処理を簡素化してくれます。
Kafka Streamsは、Kafkaに格納されたデータを処理および分析するためのクライアントライブラリです。ウィンドウ処理などが可能であり、Spark StreamingやFlinkなどの並列分散処理フレームワークに相当します。
Miller MakerはKafkaクラスタ間のミラーリングを行います。複数のデータセンタにクラスタを用意することで、データセンタ間でのバックアップが可能となります。Miller Makerの実体は一方のクラスタからConsumeしたRecordを他方のクラスタにProduceするクライアントアプリケーションであり、ミラーリングは非同期に行われます。そのため、フォールトトレランス機能としての使用は意図されていません。
Kafkaの機能
Kafkaの主な機能について、その概要を簡単に説明します。詳細についてはリンク先の公式ドキュメントを参照してください。
KafkaはSSL/SASLを用いた接続認証、通信データの暗号化、クライアントによる読み取り/書き込み操作の認証などを提供しています 。
Quotasによりクライアントが使用するBrokerリソース(ネットワーク帯域幅およびネットワーク・ディスクI/OスレッドのCPU要求レート)を制御できます 。
Logコンパクションを使用することで、各キーの最新Recordのみを保持できます(一定期間が過ぎたRecordを削除するのではなく、同じキーの最新Record以外を削除する)。この保存ポリシーはTopicごとに設定可能です。
KafkaはJMX (Java Management Extensions) により性能情報などのメトリックを公開しています。JDK付属のjconsoleや、JMXに対応した監視ソフトウェアを使用することで、これらのメトリックを収集できます。
Recordの重複排除、トランザクション、エンドツーエンドのExactly-once保障
Kafka 0.11では以下の機能が追加されました。
- Producerは送信したRecordがコミットされたことを示す応答を、Brokerから受信できなかった場合にRecordを再送するため、Logに同じRecordが書き込まれる可能性があります。Kafka 0.11では、Producerによって送信されるシーケンス番号を使用することで、この重複を排除する機能が追加されました。
- Kafka 0.11では、Producer/Consumerは複数のTopicにまたがるトランザクション機能が追加されました。トランザクションを使用することで、あるTopicから読み出したRecordを変換処理して別のTopicに書き込む、といった一連の処理をアトミックに実行できます。
- Kafkaはデフォルト設定において、At least once(データが重複する可能性があるが、欠損はしない)のRecord配信を保障しています。Kafka 0.11では、Recordの重複排除やトランザクションなどの設定を行い、Kafka StreamsとKafka Connectを組み合わせることで、エンドツーエンドのExactly-onceのRecord配信(ProducerのRecord送信から、変換処理、外部DBへの出力までをRecordの欠損や重複なしに実行)が可能になりました。
おわりに
本投稿ではApache Kafkaの概要とアーキテクチャについて紹介しました。次回の投稿ではKafkaのコンポーネントであるBroker、Producer、Consumerについて、詳細な処理の流れとパラメータ設定を紹介します。