初版: 2018/10/26
著者: 伊藤 雅博, 株式会社日立製作所
はじめに
この投稿ではオープンソースカンファレンス2017.Enterpriseで発表した「めざせ!Kafkaマスター ~Apache Kafkaで最高の性能を出すには~」の検証時に調査した内容を紹介します(全8回の予定)。本投稿の内容は2017年6月にリリースされたKafka 0.11.0 時点のものです。
第5回目となる今回は、Producer-Broker間の送信スループットをチューニングした際の性能測定結果を紹介します。
投稿一覧:
- Apache Kafkaの概要とアーキテクチャ
- Apache KafkaのProducer/Broker/Consumerのしくみと設定一覧
- Apache Kafkaの推奨構成と性能の見積もり方法
- Apache Kafkaの性能検証(1): 検証環境とパラメータチューニングの内容
- Apache Kafkaの性能検証(2): Producerのチューニング結果 (本投稿)
- Apache Kafkaの性能検証(3): Brokerのチューニング結果
- Apache Kafkaの性能検証(4): Producerの再チューニングおよびConsumerのチューニング結果
- Apache Kafkaの性能検証(5): システム全体のレイテンシについて
Producer-Broker間の性能チューニング
チューニングの範囲
前回の投稿で説明した通り、まずはProducerの送信性能からチューニングを行い、Producer-Broker間の通信スループットを最適化します。ここでは理論上の最大スループットである1,170MB/sをめざします。この検証ではBroker側のLogフラッシュやレプリケーションの影響を排除するため、acks=0でチューニングと測定を実施しました。この検証におけるチューニング範囲を以下の図に赤色で示します。
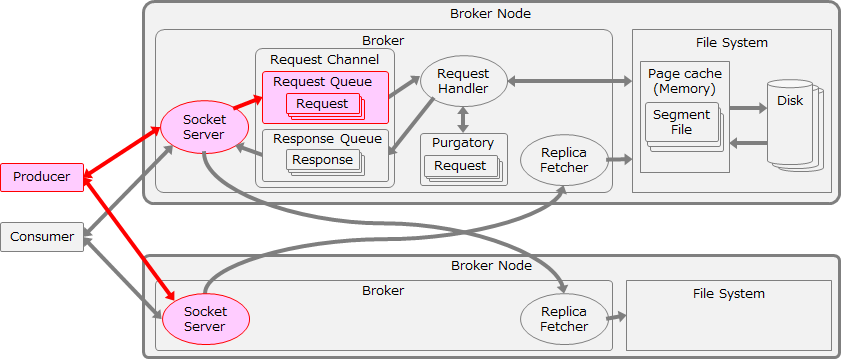
batch.size と linger.ms のチューニング
Producerが送信するBatchのサイズは、Batchの最大サイズ(batch.size)とBatchの蓄積を待つ時間(linger.ms)によって決まるため、この2つを同時にチューニングしました。Producer用ノード1台かつProducer 1個で測定した際の、Produceスループットを以下に示します。
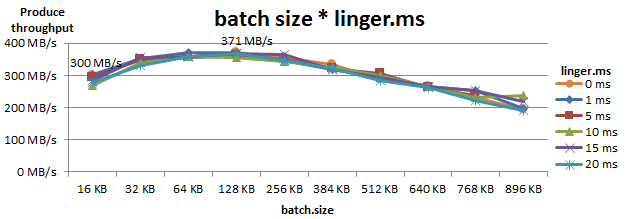
以上の結果から、batch.sizeのチューニングは効果が大きいが、linger.msの影響は小さいことが分かりました。この測定ではbatch.size=128KB、linger.ms=1msのとき、Produceスループットが300MB/sから371MB/sまで向上しました。
Producer数 のチューニング
次に、Producer用ノードを2台に増やし、Producer数を2の倍数で増やして測定を行いました。Producer数を増やした時のProduce、Replicate、Consumeスループットの推移を以下に示します。本検証ではReplication factor=3で測定したため、Produceしたデータの2倍の量をBroker間で複製します。そのためReplicateスループットは最大でProduceスループットの2倍となります。そこで、グラフ上ではProduce/Consumeスループットと比較しやすいように半分の値(Replicate/2)を示します。
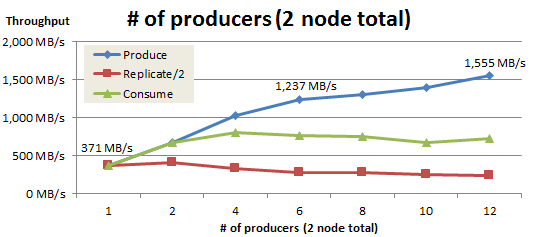
Producer数を6個(1Producerノードあたり3個)まで増やすと、Produceスループットは理論値である1,170MB/sを超えました。これはBroker側のReplicateスループットが遅延しており、その分のネットワーク帯域を使用できるためです。Producer数が1のときはProduce、Replicate、Consumeのスループットが一致していましたが、Producer数の増加に合わせてProduce とReplicate、Consumeのスループットは乖離していくことが確認できました。
この測定により、Producerは6個あれば1,170MB/sを超えるProduceスループットが得られると分かりました。
compression.type のチューニング
次に、ProducerでRecord Batchを圧縮した際のProduceスループットを以下に示します。このスループットは圧縮後のbyteレートであるため、圧縮率により送信したRecord数は変化します。
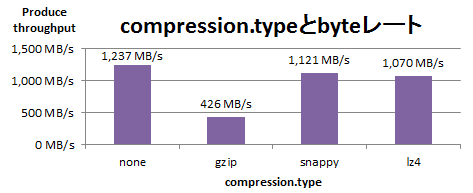
実際に最大化したいのは圧縮後のbyteレートではなく、送信Record数のレートです。これを以下に示します。
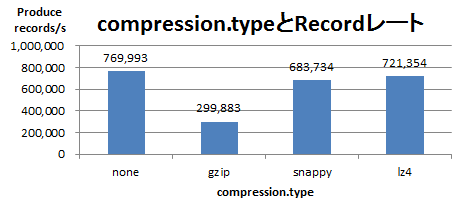
以上の結果から、gzipは圧縮率が高い分byteレートは低く、snappyとlz4は圧縮率が低い分byteレートは高い傾向にあることが確認できました。ただし、Record数のレートを比べると、圧縮なし(none)の場合が最も高スループットでした。
Broker の num.network.threads のチューニング
最後に、Recordを受信するBroker側の、Socket Serverのネットワークスレッド数(num.network.threads)をチューニングしました。この測定結果を以下に示します。
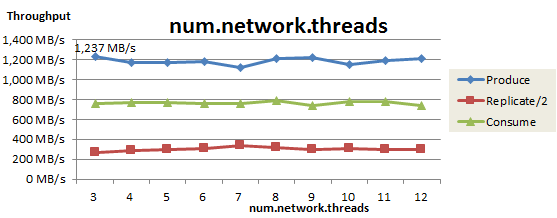
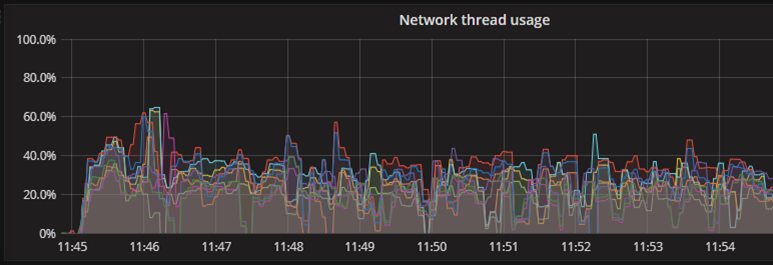
ネットワークスレッド数を増やしてもProduceスループットはほぼ横ばいでした。num.network.threads=3のときの、ネットワークスレッドごとのCPU使用率を以下に示します(Broker3台なので合計9スレッド)。このときCPU使用率は40%程度で推移しており、ボトルネックにはなっていません。この測定により、ネットワークスレッド数は3個で問題ないことが確認できました。
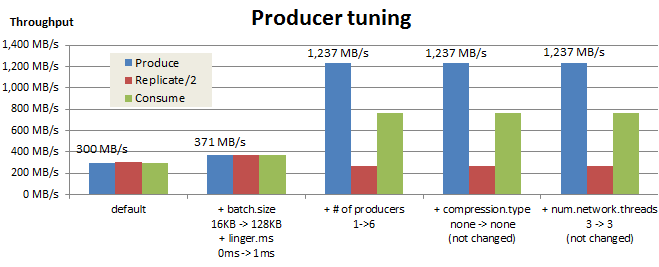
チューニング結果のまとめ
今回のチューニング結果を以下にまとめました。これらのチューニングにより、Producerの送信スループットは300 MB/sから1,237 MB/sまで向上しました。ただし、ReplicateおよびConsumeスループットは目標性能に届いていないため、BrokerとConsumerについてもチューニングも必要となります。
おわりに
今回はProducer-Broker間の通信スループットをチューニングした結果を紹介しました。次回は、Brokerのチューニング結果を紹介します。