初版: 2018/10/19
著者: 伊藤 雅博, 株式会社日立製作所
はじめに
この投稿ではオープンソースカンファレンス2017.Enterpriseで発表した「めざせ!Kafkaマスター ~Apache Kafkaで最高の性能を出すには~」の検証時に調査した内容を紹介します(全8回の予定)。本投稿の内容は2017年6月にリリースされたKafka 0.11.0 時点のものです。
第4回目となる今回からは、実際にKafkaの性能検証を行った際の測定結果を紹介していきます。今回はまず、検証環境のシステム構成と検証方法について紹介します。
投稿一覧:
- Apache Kafkaの概要とアーキテクチャ
- Apache KafkaのProducer/Broker/Consumerのしくみと設定一覧
- Apache Kafkaの推奨構成と性能の見積もり方法
- Apache Kafkaの性能検証(1): 検証環境とパラメータチューニングの内容 (本投稿)
- Apache Kafkaの性能検証(2): Producerのチューニング結果
- Apache Kafkaの性能検証(3): Brokerのチューニング結果
- Apache Kafkaの性能検証(4): Producerの再チューニングおよびConsumerのチューニング結果
- Apache Kafkaの性能検証(5): システム全体のレイテンシについて
検証の目的
Kafkaは非同期レプリケーションであれば、ディスク/ネットワーク性能の上限に近いスループットを出すことができます。一方、同期レプリケーション時の性能については情報があまりありません。一般的に、本番環境ではデータを保護するための同期レプリケーションが求められます。そこで、同期レプリケーション時のスループットを測定するために、性能検証を実施しました。
前回の投稿で説明した通り、Producerが送信したデータをConsumer Groupがすぐに読み出すストリームデータ処理システムでは、処理性能が最も低い箇所がボトルネックとなります。そのためKafkaで高いスループットを出すには、Producer-Broker間通信、Broker-Broker間通信、BrokerのディスクI/O、Broker-Consumer間通信の全てにおいて高いスループットを出す必要があります。
本検証では、データ処理のスループットに着目してチューニングを行いました。一般的に、スループットが増加するとレイテンシも増加しますが、本検証で行うチューニングはレイテンシについては考慮していません。なお、レイテンシの測定結果については今後の投稿で紹介します。
検証内容
検証システムの全体像を以下に示します。本検証では、Producerノードで生成した検証用データ(1KBのRecord)を、複数のProducerがBrokerへ600秒間送信し続けます。同時に、1つのConsumer GroupがBrokerからデータを取得し続けます。このシステムにおける、Consumerの600秒間の平均受信スループットを最大化するために、Producer、Broker、Consumerのパラメータチューニングを行いました。
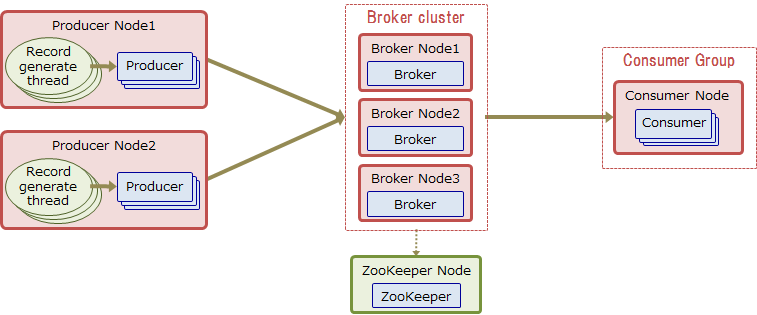
今回は同期レプリケーション時の性能を測定するため、Replica複製数=3、最小ISR数=2、acks=allに設定しました。
Brokerの合計ディスク台数は24台のため、全ディスクを使い切って性能を出すためには最低でも24個のReplicaが必要となります。今回は1個のTopicを使用して性能検証を行うため、このTopicのPartition数は 24ディスク ÷ 3Replication = 8個 以上にする必要があります。
ただし、全てのPartitionに均等にデータが読み書きされるとは限らず、Partitionごとに偏りが出る場合もあります。そのため、今回は1ディスクあたり6個のReplicaを割り当てることにして、Partitions数を 24ディスク × 6Replica ÷ 3Replication = 48個 に設定しました。
| コンポーネント | パラメータ名 | デフォルト値 | 設定値 |
|---|---|---|---|
| Broker | num.partitions | 2 | 48 |
| Broker | default.replication.factor | 1 | 3 |
| Broker | min.insync.replicas | 1 | 2 |
| Producer | acks | 1 | all |
検証環境
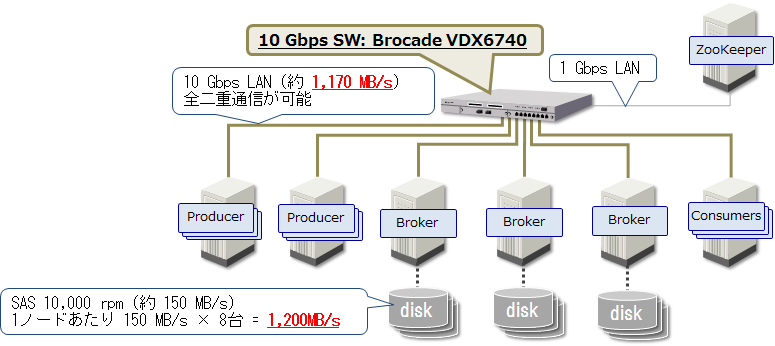
Producer用ノード2台、Broker用ノード3台、Consumer用ノード1台には、以下に示すスペックの物理マシンを使用しました。また、ソフトウェアのパラメータ設定については、前回の投稿で説明した推奨設定を使用しました。
| 項目 | 設定 |
|---|---|
| サーバ種別 | HA8000/TS20AN |
| CPUコア数 | 20コア40スレッド |
| メモリ容量 | 384 GB |
| ディスク | 1,200GB (SAS 10,000 rpm) を10台。 OS用に2台でRAID1、Brokerは8台をJBODでLogディレクトリに割り当て。 検証前に測定したディスクのシーケンシャルアクセス速度は約150MB/s。 |
| OS | RHEL 6.7 |
| JDK | JDK 1.8.0.121 |
| ファイルシステム | EXT4(マウントオプション:defaults,noatime) |
| Kafkaバージョン | Kafka 0.11.0 |
今回は性能検証であるため、ZooKeeperは1台のみで冗長化はしていません。ZooKeeper用ノードのスペックを以下に示します。
| 項目 | 設定 |
|---|---|
| サーバ種別 | 仮想マシン |
| CPUコア数 | 4スレッド |
| メモリ容量 | 16 GB |
| ディスク | 80GBを1台 |
| OS | RHEL 6.7 |
| JDK | JDK 1.8.0.121 |
| ZooKeeperバージョン | ZooKeeper 3.4.10 |
検証システムのネットワーク構成を以下に示します。Producer、Broker、Consumerノード間は10 Gbps回線で接続し、ZooKeeperは1 Gbps回線で接続しました。検証前にiperfコマンドでノード間のスループットを測定し、Producer、Broker、Consumerノード間で同時に約1,170MB/sのスループットが出ることを確認しました。
理論上の最大スループット
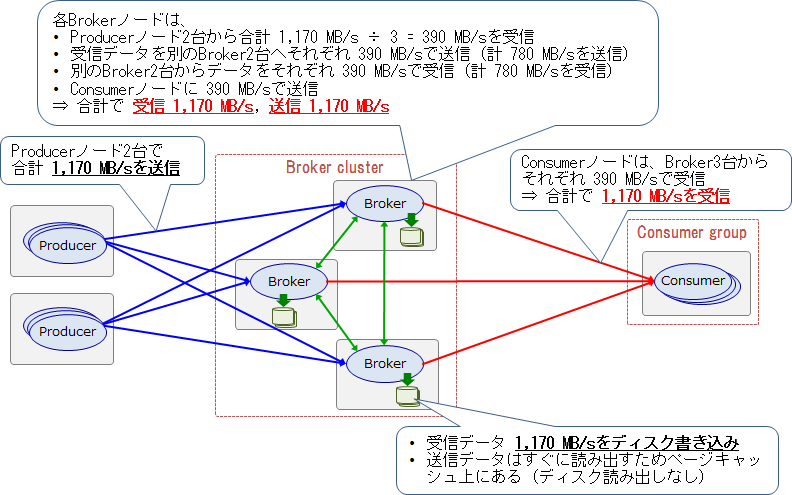
上記の検証環境における、理論上の最大スループットを以下に示します。検証ではこの最大スループットをめざして、Producer、Broker、Consumerのパラメータチューニングを行いました。
今回の検証では、Producerが送信したデータをConsumer Groupがすぐに読み出すストリームデータ処理システムを想定します。このシステムでは、レプリケーションやConsumer Groupによる読み出しの遅延が発生しない限り、データはすべてページキャッシュ上にあります。そのため、ここではディスク読み出しは発生しないと仮定しています。
このシステムでは、Producerノード2台が合計1,170 MB/sでデータを送信すると、Brokerの送受信とConsumerの受信ネットワーク帯域が、理論上の最大スループットである1,170 MB/sに達します。これらの個所がボトルネックとなるため、Producerノードがこれ以上のスループットでデータを送信しても、システム全体のスループットは向上しません。よって、システム全体の理論上の最大スループットは 1,170 MB/sとなります。
パラメータチューニング
チューニングの順序
KafkaはProducer、Broker、Consumerの3コンポーネントに分かれていますが、ストリーム処理ではシステム全体を通した性能が重要であり、どれかがボトルネックとなってはいけません。しかし3コンポーネントの全パラメータの組み合わせを調べることは難しいため、本検証では以下の4つの範囲に分けて順番にチューニングを行いました。
1. Producerの送信性能
システム全体で十分な量のデータ(理論値である1,170MB/s)を流すため、最初にProducer-Broker間の通信スループットを最適化しました。この検証ではBroker側のLogフラッシュやレプリケーションの影響を排除するため acks=0 でチューニングを実施しました。
2. BrokerのLogフラッシュ性能
BrokerのLogフラッシュ(ディスクI/O)まで含めたスループットを最適化しました。この検証ではレプリケーションの影響を排除するため、acks=1で測定を実施しました。
3. Broker間のレプリケーション性能
Broker間のレプリケーションまで含めたスループットを最適化しました。この検証ではProduce/Replicateスループットの変化を見るため、まずはacks=1でチューニングを行い、最後にacks=allに変更しました。
4. Consumerの取得性能
acks=allでチューニングを行い、Consumerの取得まで含めたシステム全体のスループットを最適化しました。
チューニング対象のパラメータ
本検証でチューニングしたパラメータを以下に示します。各パラメータの詳細は第2回の投稿を参照してください。
| コンポーネント | パラメータ名 | デフォルト値 | 検証範囲 |
|---|---|---|---|
| Producer | batch.size | 16KB | 16-1,024KB |
| Producer | linger.ms | 0ms | 0-20ms |
| Producer | compression.type | none | none, gzip, snappy, z4 |
| Broker | num.network.threads | 3 | 3-16 |
| Broker | log.flush.scheduler.interval.ms | Long.MAX_VALUE | 1-128秒 |
| Broker | num.io.threads | 8 | 8-24 |
| Broker | replica.fetch.response.max.bytes | 10MB | 10MB, 100MB |
| Broker | num.replica.fetchers | 1 | 1-16 |
| Consumer | fetch.max.bytes | 50MB | 50MB, 1,000MB |
| Consumer | max.partition.fetch.bytes | 1MB | 1-10MB |
| Consumer | Consumer数 | なし | 4-20個 |
固定したパラメータ
本検証で固定したパラメータを以下に示します。今回の性能検証はスループットを最大化することが目的であるため、上限値を定義するパラメータに対しては、その制限を受けないように大きな値を設定しました。本番環境では適切な上限値を設定する必要があります。各パラメータの詳細は第2回の投稿を参照してください。
| コンポーネント | パラメータ名 | デフォルト値 | 設定値 |
|---|---|---|---|
| Producer | buffer.memory | 32MB | 1GB |
| Producer | max.request.size | 1MB | Int.MAX_VALUE |
| Producer | max.in.flight.requests.per.connection | 5 | Int.MAX_VALUE |
| Producer | max.block.ms | 60秒 | Long.MAX_VALUE |
| Producer | retries | 0 | Int.MAX_VALUE |
| Producer | request.timeout.ms | 30秒 | Int.MAX_VALUE |
| Broker | queued.max.requests | 500 | 5,000 |
| ZooKeeper | zookeeper.connection.timeout.ms | 6秒 | 60秒 |
| ZooKeeper | zookeeper.session.timeout.ms | 6秒 | 60秒 |
性能メトリクスの収集方法
Kafkaは性能情報などのメトリクスをJMXで公開しています。今回の性能検証では、スループットなどのメトリクスの監視にPrometheus、メトリクスの収集にJMX Exporterを使用しました。
スループットに関するメトリクスを以下に示します。なお、これらのスループットはProducer、Broker、Consumerが送受信したRecordサイズであり、メタデータ取得などのスループットは含みません。これらのメトリクスの他にも、スレッドごとのCPU使用率など様々なメトリクスを監視して、パラメータチューニングに役立てました。
| メトリクス | 説明 |
|---|---|
| kafka.producer.producer-topic-metrics.byte-rate | ProducerがProduceリクエストで送信した秒間Recordサイズ (以降、Produceスループットと呼ぶ) |
| kafka.server.replica-fetcher-metrics.incoming-byte-rate | BrokerのReplica fetcherがFetchリクエストで取得した秒間Recordサイズ (以降、Replicateスループットと呼ぶ) |
| kafka.consumer.consumer-fetch-manager-metrics.bytes-consumed-ratee | ConsumerがFetchリクエストで取得した秒間Recordサイズ (以降、Consumeスループットと呼ぶ) |
測定手順
1回の測定手順を以下に示します。この手順を、パラメータを変えて繰り返し実行しました。
- Topicを削除して再作成
- 全ノードのページキャッシュをクリア
- Brokerを再起動(Brokerのパラメータ変更を適用)
- ProducerとConsumerを起動して処理を実行(ProducerとConsumerのパラメータ変更を適用)。Producer が1KBのRecordをBrokerに送信し続け、Consumerはそれを取得し続ける
- 600秒経過した時点で、Prometheusが収集したメトリクスからスループットの平均値などを計算
- ProducerとConsumerを停止
おわりに
本投稿では検証環境のシステム構成と検証方法について紹介しました。次回は、実際にProducerをチューニングして性能測定を行った結果を紹介します。