初版: 2018/10/12
著者: 伊藤 雅博, 株式会社日立製作所
はじめに
この投稿ではオープンソースカンファレンス2017.Enterpriseで発表した「めざせ!Kafkaマスター ~Apache Kafkaで最高の性能を出すには~」の検証時に調査した内容を紹介します(全8回の予定)。本投稿の内容は2017年6月にリリースされたKafka 0.11.0 時点のものです。
第3回目となる今回は、Kafkaの推奨システム構成とネットワーク・ディスク性能の見積もり方法について紹介します。
投稿一覧:
- Apache Kafkaの概要とアーキテクチャ
- Apache KafkaのProducer/Broker/Consumerのしくみと設定一覧
- Apache Kafkaの推奨構成と性能の見積もり方法 (本投稿)
- Apache Kafkaの性能検証(1): 検証環境とパラメータチューニングの内容
- Apache Kafkaの性能検証(2): Producerのチューニング結果
- Apache Kafkaの性能検証(3): Brokerのチューニング結果
- Apache Kafkaの性能検証(4): Producerの再チューニングおよびConsumerのチューニング結果
- Apache Kafkaの性能検証(5): システム全体のレイテンシについて
ハードウェア構成
Broker用ノードとZooKeeper用ノードの推奨ハードウェアスペックについて説明します。なお、ProducerとConsumerは送受信用のライブラリであり、必要なスペックはライブラリを使用するユーザアプリケーションに依存するため、ここでは説明しません。
Broker
Broker用ノードの推奨ハードウェアスペックを以下に示します。
-
台数:4台以上
- データの耐久性を考慮するとReplicaを最低3個は確保したい。Brokerノードが4台以上あれば、1台が故障しても、そのBroker上のReplicaは別のBroker上に再構築されるため、3個のReplicaを維持できる。
-
CPUコア数:20コア以上
- Brokerでは多くのスレッドが実行される。特にリクエスト送受信(デフォルト設定で3スレッド)、リクエスト処理(デフォルト設定で8スレッド)、複製処理(デフォルト設定で1スレッド)は比較的使用率が高い。その他にもバックグラウンド処理用のスレッドが複数存在する。そのため20コア以上を推奨する。
-
メモリ容量:24GB+キャッシュしたいデータ量
- Kafkaでは書き込んだメッセージをすぐに読み出すことが多いため、ページキャッシュを活用することで高速なデータ読み出しが可能となる。例えば1,000MB/秒で書き込まれる直近60秒間のデータをキャッシュしたい場合、必要なメモリ量は1,000MB * 60秒 ≒ 60GBと見積もることができる。これにBrokerに割り当てたJavaヒープメモリ(6-16GB程度)と、OS動作用に残しておくメモリ(4-8GB程度)を合計したものが、必要なメモリ容量となる。
-
ディスク台数:10台以上
- Kafkaではメッセージをディスクに保存するため、ディスク台数が多いほどBrokerの書き込み/読み出しスループットが向上する。OS用に2台でRAID1構成、残りをJBOD(または1台のRAID0)でKafka用に割り当てる。Kafka用のディスクはSASなどのシーケンシャルアクセス性能が高いものがよい。
-
ディスク容量:保存したいデータ量に依存
- Kafkaはデータを指定した期間ディスクに保存するため、それに合わせた容量が必要となる。例えば1日1TBのデータを受信し、3個に複製する場合、1日当たり3TBのディスク容量を消費する。このとき過去7日間のデータを保存しておく場合は21TBの容量が必要となる。これに加えてメタデータなどのファイル用に最低10%以上の容量が必要となる。
-
ネットワーク回線:10Gbps回線
- 必要な回線速度はデータの流量に依存するが、最低でも10 Gbps回線の使用を推奨する。さらに帯域が必要な場合は、複数NICによるボンディングや、40Gbps回線の使用を検討するとよい。
ZooKeeper
ZooKeeper用ノードの推奨ハードウェアスペックを以下に示します。
-
台数:3台以上(奇数台)
- 3台構成だと1台の故障に耐えられ、5台構成だと2台までの故障に耐えられる。
-
CPUコア数:2コア以上
- OSとZooKeeperの処理用にそれぞれ1コアずつあるとよい。
-
メモリ容量:8GB以上
- ZooKeeperに3-5GB程度のJavaヒープを割り当て、OS用に4GB程度のメモリを残しておく。
-
ディスク台数:4台以上
- ディスクの用途は以下の3種類に分けられる。
- OS用:2台でRAID1構成のディスクを割り当てる
- トランザクションログ用:トランザクションログは同期的に書き込まれるため、他の用途とは独立したディスク(2台でRAID1構成)を割り当てる
- スナップショット用:スナップショットはディスクに非同期で書き込まれるためOS用のディスクと共有でもよい
- ディスクの用途は以下の3種類に分けられる。
-
ネットワーク回線:1Gbps以上
- ZooKeeperとの通信データ量は小さいため、高速な回線で接続する必要はない。
ソフトウェアのパラメータ設定
OSの設定
KafkaではOSにLinuxまたはSolarisが使用可能です。ここではRHEL 6 を使用する場合のパラメータ設定を以下に示します。
-
スワップ頻度(vm.swappiness):1
- ディスクをメモリとして使うスワップ領域の設定です。0-100の範囲で設定し、数値が高いほど積極的にスワップを利用します。メモリ上のページを頻繁にディスクへスワップすると、SegmentファイルのディスクI/Oに影響し、ページキャッシュに割り当てられるメモリも減少します。そのためスワップ頻度を低く抑えることを推奨します。
-
ファイルディスクリプタ数:100,000
- Brokerは大量のファイルとネットワークコネクションをオープンします。そのため、ファイルディスクリプタ数は1Brokerプロセスあたり100,000個から始めることを推奨します。なお、最小必要数は以下のように計算できます。
- 最小必要数= 1Brokerの接続数 + (Partition数)*(Partitionサイズ / Segmentサイズ)
- Brokerは大量のファイルとネットワークコネクションをオープンします。そのため、ファイルディスクリプタ数は1Brokerプロセスあたり100,000個から始めることを推奨します。なお、最小必要数は以下のように計算できます。
-
ソケットバッファの最大値
- Kafka側でソケットバッファのサイズを指定しても、OS側の制限によりこの最大値を超えることはできません。特にデータセンタ間で通信を行う場合はRTTが長くなるため、ソケットバッファを大きくする必要があります。
ファイルシステムの設定
Linuxではファイルシステムとして一般的にEXT4またはXFSが使用されます。BrokerのディスクI/O性能を高めるために、いくつかのマウントオプションを使用することを推奨します。オプションの詳細は公式ドキュメントを参照してください。
XFS/EXT4共通のマウントオプションを以下に示します。XFSはオートチューニングが行われているため、これ以外のデフォルト設定を変更する必要はありません。
- noatime
- ファイルのatime(最終アクセス時刻)属性の更新を無効にする。これにより、ファイル読み込み時に発生する書き込み処理を抑制できる。Kafkaはatime属性に依存しないため、無効にしても問題ない。
EXT4を使用する場合は、パフォーマンスを最大限に引き出すため、必要に応じて公式ドキュメントに記載されたオプションを追加してください。
JVMの設定
BrokerはScala言語で記述されておりJVM上で動作するため、実行するにはJDKをインストールする必要があります。ProducerおよびConsumerについても、JavaまたはScalaクライアントを使用する場合は、同様にJDKが必要となります。セキュリティ上の観点から、JDK 1.8の最新リリース版を使用することを推奨します。
なお、Kafkaの公開元であるLinkedInでは以下のJavaオプションを使用しています。
-Xmx6g
-Xms6g
-XX:MetaspaceSize = 96m
-XX:+UseG1GC
-XX:MaxGCPauseMillis = 20
-XX:InitiatingHeapOccupancyPercent = 35
-XX:G1HeapRegionSize = 16M
-XX:MinMetaspaceFreeRatio = 50
-XX:MaxMetaspaceFreeRatio = 80
理論上の最大スループットの見積もり
ストリームデータ処理システムでは、処理性能が最も低い箇所がボトルネックとなり、システム全体の処理性能が決まります。Kafkaでボトルネックになりやすい箇所は、ノード間のネットワークI/Oと、BrokerのLogの読み書きによるディスクI/Oです。そのため、想定するデータ流量に対して、ネットワークI/O性能とディスクI/O性能が十分かどうかの見積もりが重要となります。
ここでは、ディスク性能とネットワーク性能から、理論上の最大スループットを見積もる方法を説明します。**なお、これはあくまで理論上の最大性能であり、実際には様々なオーバーヘッドがあります。**実際の性能については次回以降の性能測定で説明しますが、レプリケーションが非同期であれば、理論値に近いスループットを出すことも可能です。しかし同期レプリケーションを行う場合のスループットは、理論値の60-70%程度になります。
システム全体のデータの流れ
必要となるネットワークI/O性能とディスクI/O性能を見積もるため、まずシステム全体のデータ流れを説明します。今回は以下のシステム構成例における理論上の最大スループットを見積もります。なお、ここではZooKeeperとの通信量については考慮しません。
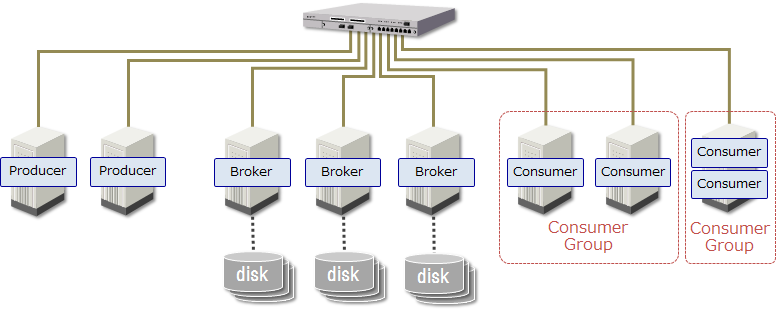
上記のシステム構成におけるデータの流れを以下に示します。ここでは、Producerが送信したデータをConsumer Groupがすぐに読み出すストリームデータ処理システムを想定しています。このシステムにおける最大スループットは、最もスループットが低い箇所(ボトルネック)によって決まります。そのため、以下のデータの流れでは「全Producerの合計データ送信量」と「1 Consumer Groupあたりのデータ受信量」が釣り合う最大スループットが、システム全体の最大スループットとなります。
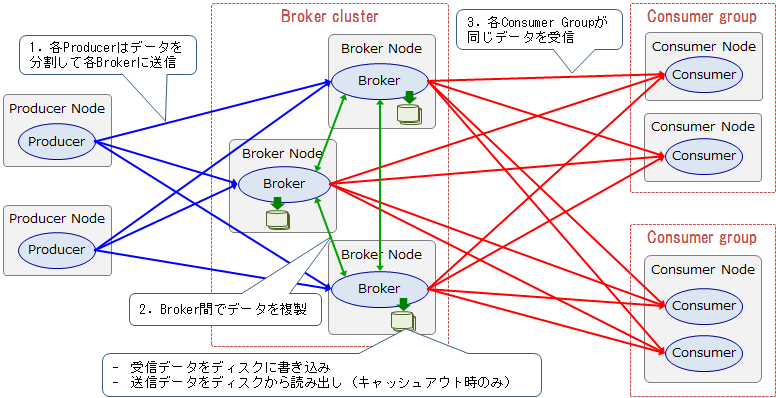
上記のデータの流れを詳しく見ていきます。
1. ProducerからBrokerへのデータ送信
各Producerノードは、送信するデータを1/3ずつに分けて3台のBrokerノードに送信します。各Brokerは受信したデータをローカルのディスクに書き込みます。
2. Broker間のレプリケーション
例えばReplication Factorが3の場合、各Brokerノードはデータを複製するため、受信したデータを別の2台へ送信し、別の2台からデータを受信します。よって送信・受信するデータ量は共にProducerから受信したデータ量の2倍となります。また、各Brokerは受信データをディスクに書き込み、送信データはキャッシュになければディスクから読み出す必要があります。
3. BrokerからConsumerへのデータ送信
BrokerノードはConsumerからのFetch要求に応じて、Consumerノードへデータを送信します。2個のConsumer Groupがそれぞれ同じデータを取得するため、送信するデータ量は Producerから受信したデータ量の2倍となります。また、各Brokerは送信データがキャッシュになければディスクから読み出す必要があります。
以上のデータの流れから、KafkaではレプリケーションによるBrokerのデータ入出力量が多くなることが分かります。そのためボトルネックとなりやすいのは、Brokerに接続されたネットワーク回線の帯域と、Brokerに搭載されたディスクのシーケンシャルアクセス性能です。
Brokerノードのディスク・ネットワークI/O性能の見積もり
Producerが送信するデータ量から、Brokerノードに必要なネットワークI/OスループットおよびディスクI/Oスループットを求める方法を以下に示します。
ネットワークI/Oスループット
一般的にネットワーク回線は全二重であるため、送信スループットと受信スループットを独立に考える必要があります。Brokerノード1台当たりの受信スループットと送信スループットを以下に示します。
1Brokerの受信スループット
= Producerからの受信スループット + 他のBrokerからの受信スループット
= Producerからの受信スループット + Producerからの受信スループット * (Replication Factor - 1)
= Producerからの受信スループット * Replication Factor
= Producerの合計送信スループット / Brokerノード数 * Replication Factor
1Brokerの送信スループット
= 他のBrokerへの送信スループット + Consumer Groupへの送信スループット
= Producerからの受信スループット * (Replication Factor - 1) + Producerからの受信スループット * Consumer Group数
= Producerからの受信スループット * (Replication Factor + Consumer Group数 - 1)
= Producerの合計送信スループット / Brokerノード数 * (Replication Factor + Consumer Group数 - 1)
ディスクI/Oスループット
一般的にディスクは書き込みと読み出しを並列に実行できないため、ディスクI/Oスループットは書き込みと読み出しを合計して考える必要があります。Brokerノード1台当たりの書き込みスループットと読み出しスループットを以下に示します。
ディスク書き込みスループット
Brokerノード1台あたりの合計ディスク書き込みスループットを以下に示します。
1Brokerの書き込みスループット
= 1Brokerの受信スループット
= Producerの合計送信スループット / Brokerノード数 * Replication Factor
ディスク読み出しスループット
Brokerノード1台あたりの合計ディスク読み出しスループットを以下に示します。これは、他Brokerへの複製対象データ(以下、複製データ)と、Consumer Groupの読み出し対象データ(以下、Consumeデータとする)が、Brokerノードのページキャッシュに乗っているか否かで、以下の4パターンに分類できます。
1. 複製データとConsumeデータが共にキャッシュにある場合
Broker間の複製が遅延しておらず、かつBrokerに書き込んだデータをConsumer Groupがすぐに読み出す場合は、データがすべてキャッシュに乗っているためディスク読み出しは発生しません。
1Brokerの読み出しスループット = 0
2. 複製データがキャッシュにない場合
Broker間の複製が遅延して、複製対象のデータがキャッシュから追い出されてしまった場合は、そのデータをディスクから読み出す必要があります。
1Brokerの読み出しスループット
= 他のBrokerへの送信スループット
= Producerからの受信スループット * (Replication Factor - 1)
= Producerの合計送信スループット / Brokerノード数 * (Replication Factor - 1)
3. Consumeデータがキャッシュにない場合
Consumer Groupによる読み出しが遅延して、読み出し対象のデータがキャッシュから追い出されてしまった場合は、そのデータをディスクから読み出す必要があります。
1Brokerの読み出しスループット
= Consumer Groupへの送信スループット
= Producerからの受信スループット * Consumer Group数
= Producerの合計送信スループット / Brokerノード数 * Consumer Group数
4. 複製データとConsumeデータが共にキャッシュにない場合
Broker間の複製とConsumer Groupによる読み出しが遅延して、対象のデータがキャッシュから追い出されてしまった場合は、それらのデータをディスクから読み出す必要があります。
1Brokerの読み出しスループット
= 1Brokerの送信スループット
= Producerの合計送信スループット / Brokerノード数 * (Replication Factor + Consumer Group数 - 1)
以上の見積もりから、Brokerはデータをキャッシュするためのメモリ容量も重要であることが分かります。一般的に、KafkaではBrokerに書き込んだメッセージをすぐに読み出すことが多いため、ページキャッシュを活用すればディスク読み出しが不要となり、高速なデータ読み出しが可能です。
しかし、Broker間のデータ複製やConsumer Groupによるデータ読み出しが遅延すると、ページキャッシュにないデータをディスクから読み出す必要があります。もしディスク性能が低い場合はそこがボトルネックとなり、システム全体のスループットが一気に低下してしまう可能性があります。
おわりに
本投稿ではKafkaのネットワーク・ディスク性能の見積もり方法と、推奨システム構成について紹介しました。次回からは、実際にKafkaの性能検証を行った際の測定結果を紹介していきます。