この記事は、Elixir Advent Calendar 2022 4の12日目です
昨日は、@zacky1972 さんで「Elixirと宇宙の話でもしますか〜Elixirと宇宙利用の関係」でした
piacere です、ご覧いただいてありがとございます ![]()
この2年間で、Elixirの機械学習環境が凄まじく発展し、プロダクションに実戦投入しても問題無いフェーズに入ったので、「Eixirで機械学習に初挑戦」をテーマにシリーズコラムをお届けします
入門者向けに「機械学習とは何か?」や、機械学習の中で出てくる数々のキーワード解説もしていきますので、AI・MLの知識が無いWeb開発者/IoT開発者の方や、PythonでAI・MLを学んだけどイマイチ入らなかった方、Elixir経験者だけどNx/Axon/Livebook等の新テクノロジーに追いつけていない方にも、スッと入りやすい内容としてまとめていこうと思います
今回は、前回作ったカンタンな機械学習の実装コードの解説を行いつつ、「学習データの可視化」と、「学習過程のアニメーション化」を行います
最終的に、下記のようなアニメーションを見れるので、辿り着けるよう頑張ってください
なお、アニメーション実装は、LiveView JP#12で @GeekMasahiro さん登壇でご披露いただいたものを参考にさせていただきました … この場を借りて感謝申し上げます ![]()
それと、本コラムに対し、更に分かりやすい解説を @RyoWakabayashi さんが書いてくれていますので、本コラムを読んでいて難しいなぁ…と感じた方は、コチラをご参考に理解を深めてください
 Elixir Advent Calendar 総勢16本、熱い冬ヽ(=´▽`=)ノ
Elixir Advent Calendar 総勢16本、熱い冬ヽ(=´▽`=)ノ
例年に無い盛り上がりを見せています … 応援/購読よろしくお願いします ![]()
https://qiita.com/advent-calendar/2022/elixir
本シリーズの目次
①:基礎知識とLivebook+Nx+Axonによる機械学習入門
|> ②:機械学習コードの解説と「学習データの可視化」「学習過程のアニメ化」
|> ③:「予測」の可視化と「精度」の変化要因、「学習過程グラフ」の読み方
|> ④:データ処理に強いElixirでKaggle挑戦(前編)…「データ前処理」基礎編
|> ⑤:データ処理に強いElixirでKaggle挑戦(後編)…「統計」と「EDA」でKaggleに挑む
|> ⑥:いま、Elixir AI・MLで何が出来る? → Elixirのメリット→2023年に攻略する領域
本コラムの検証環境
本コラムは、以下環境で検証しています(恐らくUbuntu実機やMacでも動きます)
- Windows 10 + WSL2 + Ubuntu 22.04 ※最新版のインストール手順はコチラ
- Elixir 1.14.2 ※最新版のインストール手順はコチラ
- Livebook 0.8.0
OR予測で行うことの構成と流れ
前回、作ったコードは、下記のような構成と流れで作られています
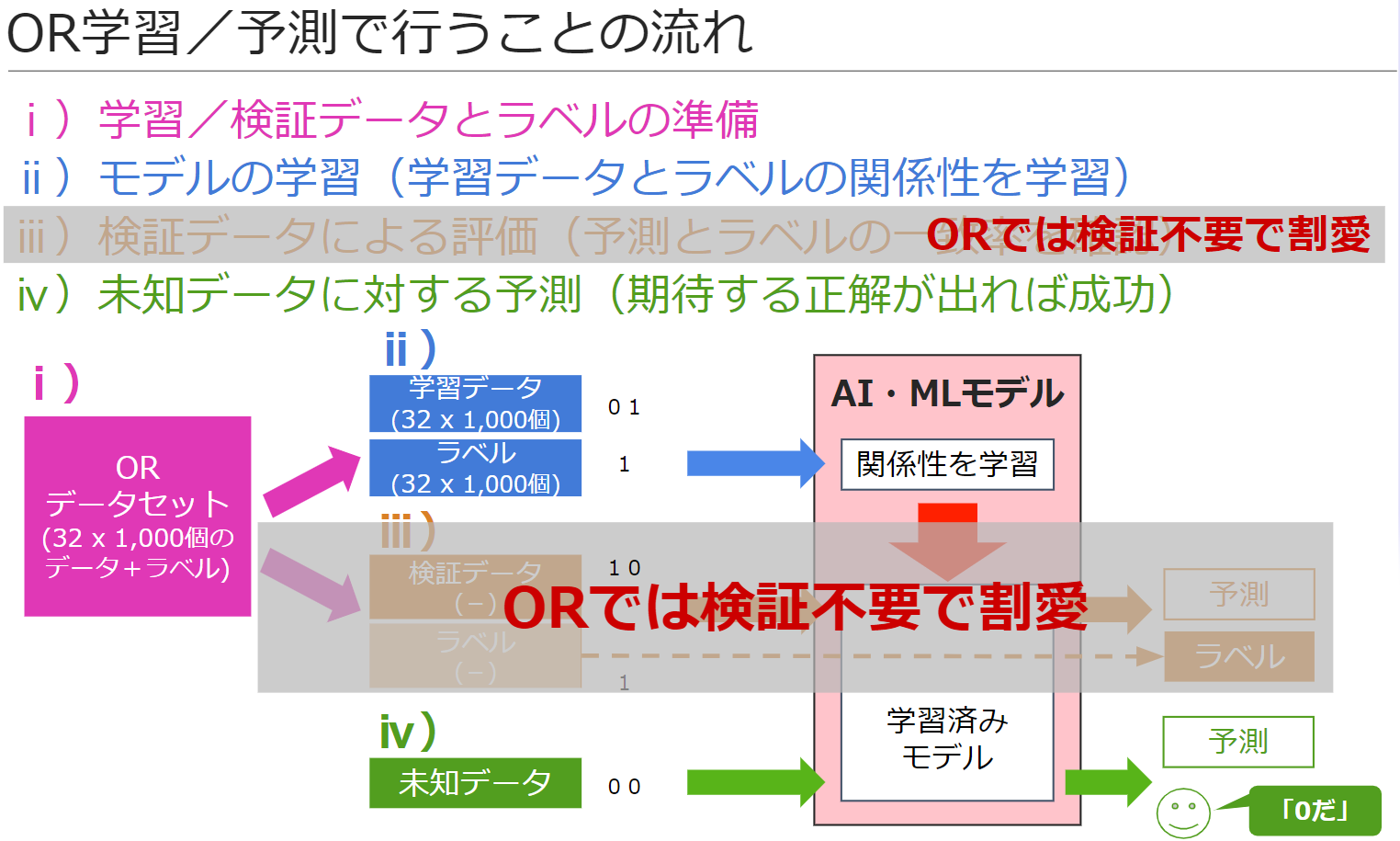
各ステップで行うことは、下記の通りです
ⅰ)学習/検証データとラベルの準備
学習や検証の元となる学習/検証データと、そのデータが入力されたときに期待する正解である「ラベル」を準備します
学習/検証データ自体が存在しない場合は、自前でデータを作成し、紐付くラベルも人が作成します
学習/検証データは存在するけど、ラベルが存在しない場合は、紐付くラベルのみ人が作成します
なお今回のORは、検証が不要なほどカンタンな例のため、今回、検証データ/ラベルの作成は割愛しています
ⅱ)モデルの学習(学習データとラベルの関係性を学習)
ⅰ)で作った学習データを入力したとき、そのラベルが出力となるよう、モデルに「学習」をさせます
ⅲ)検証データによる評価(予測とラベルの一致率を確認)
ⅰ)で作った検証データを学習済みモデルに入力した結果が、いかにラベルと一致するかを評価します
なお今回のORは、検証が不要なほどカンタンな例のため、今回、この手順自体を割愛しています
ⅳ)未知データに対する予測(期待する正解が出れば成功)
ⅲ)で精度が充分な状態になったら、学習データには存在しないデータで、期待するデータが出力(予測、識別)されることを確認します
このタスクは、開発した学習済みモデルを本番運用に回した後も必要となります
具体的には、精度を定期的にチェックし、そこで期待する精度が出ないケースを捕捉し、期待以下が頻出する場合は、モデルを見直したり、精度が出ないケースをサポート対象外とする等のアクションが必要です
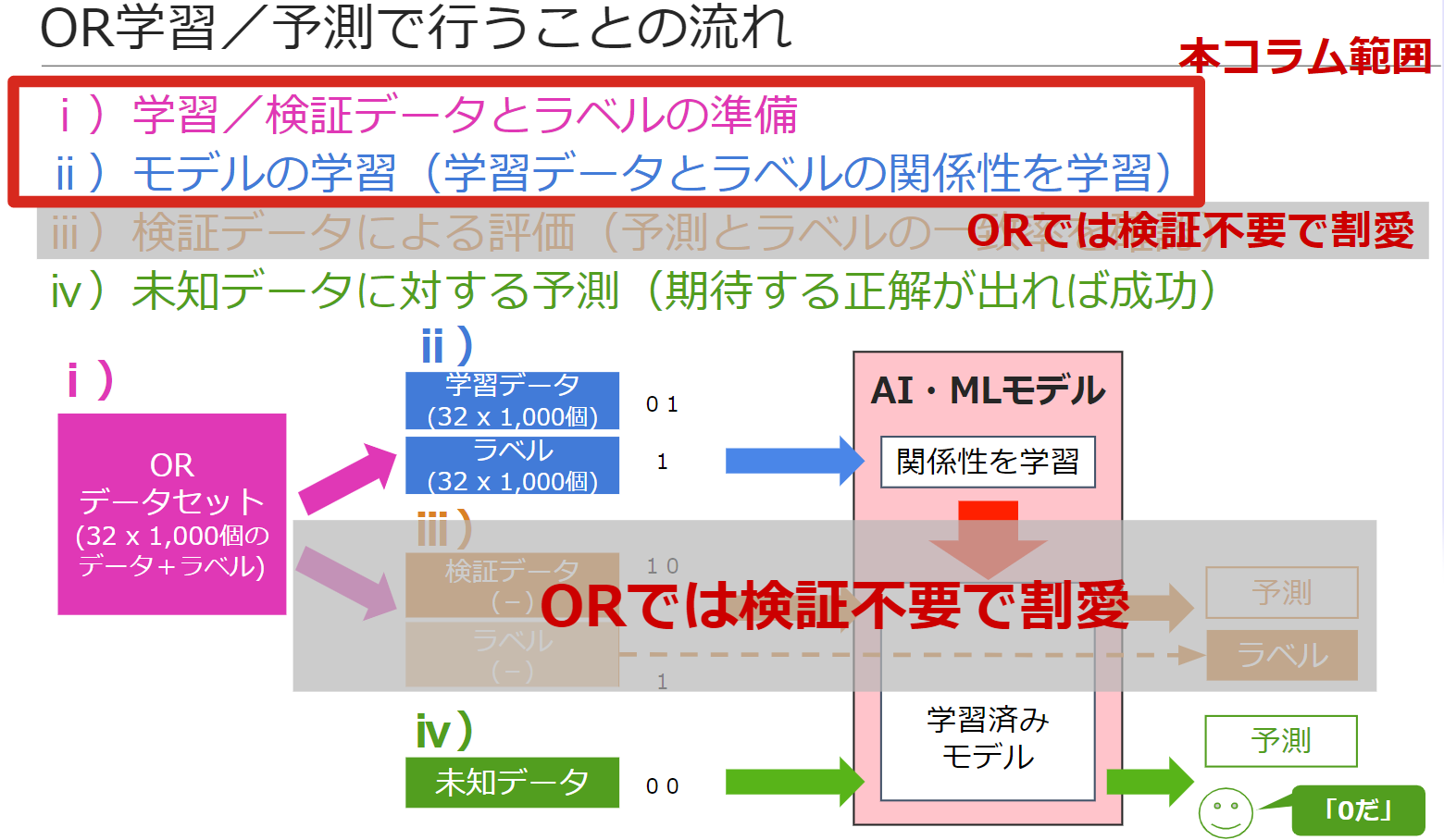
本コラムで解説するコード範囲
今回、解説するコードの範囲は、「ⅰ)学習/検証データとラベルの準備」と「ⅱ)モデルの学習(学習データとラベルの関係性を学習)」になります
各コードについて解説
構成と流れを踏まえた上で、各コードについて解説していきます
ライブラリのロード
Livebook最上部の「Notebook dependencies and setup」で、下記を実行し、必要ライブラリをロードしてください
Mix.install([
{:nx, "~> 0.4"},
{:axon, "~> 0.3"},
{:exla, "~> 0.4"},
{:table_rex, "~> 3.1"}
])
ⅰ)学習/検証データの準備
下記コードを解説します
train_datas = Stream.repeatedly(fn ->
input1 = Nx.tensor(for _ <- 1..32, do: [Enum.random(0..1)])
input2 = Nx.tensor(for _ <- 1..32, do: [Enum.random(0..1)])
label = Nx.logical_or(input1, input2)
{%{"input1" => input1, "input2" => input2}, label}
end)
|> Enum.take(1000)
ⅰ-1.学習データ1セットの生成
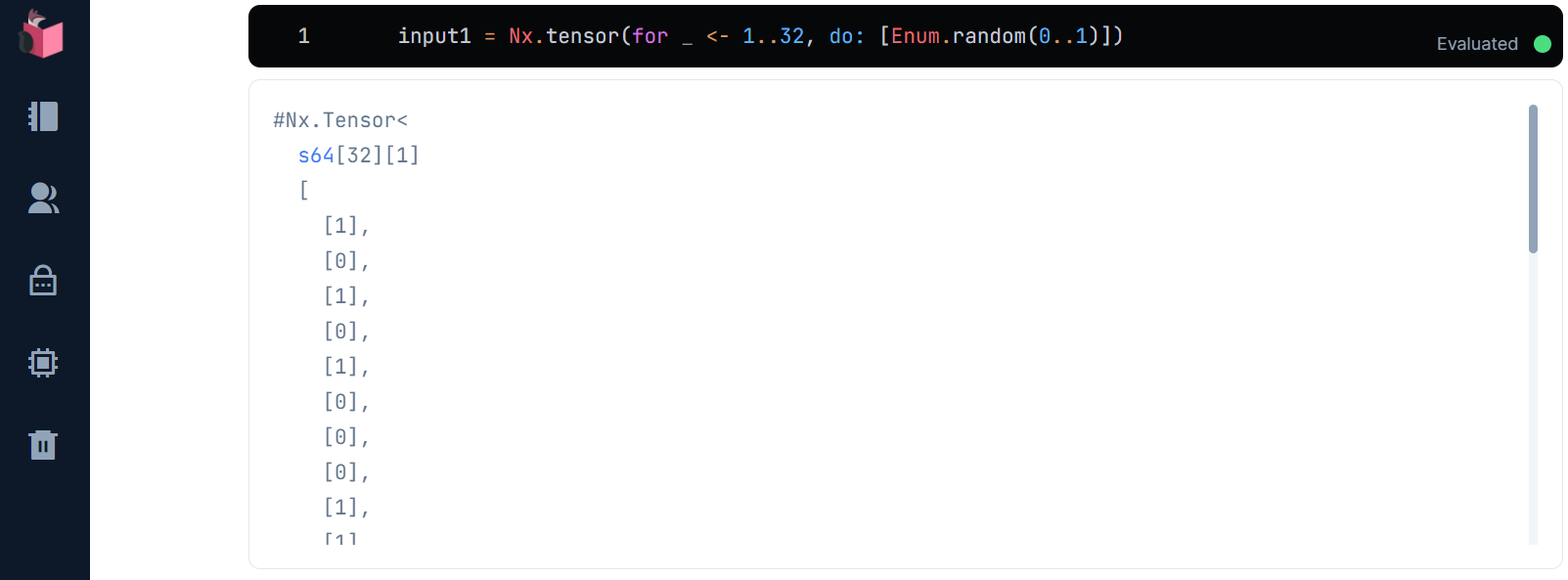
ORの1つ目の学習データは、0か1いずれかのランダムな値を32個、1次元の行列に包まれた1次元行列、つまり2次元の行列として並べます
input1 = Nx.tensor(for _ <- 1..32, do: [Enum.random(0..1)])
0か1いずれかのランダムな値が32個、1次元の行列に包まれた1次元行列として並ぶ様子は下記の通りです
ORの2つ目の学習データも、同じ手順で生成します
input2 = Nx.tensor(for _ <- 1..32, do: [Enum.random(0..1)])
ⅰ-2.学習データ1セットの可視化
ここで、どんなデータを生成したかを可視化してみます
まず、下記コードで学習データをグラフ描画可能な形式にします
input1 = for _ <- 1..32, do: [Enum.random(0..1)]
input2 = for _ <- 1..32, do: [Enum.random(0..1)]
datas =
Enum.zip([List.flatten(input1), List.flatten(input2)])
|> Enum.map(fn {input1, input2} -> %{input1: input1, input2: input2} end)
グラフ描画可能な形式は、下記結果に出てるように、リストの中に、マップでキー/値がある形式です
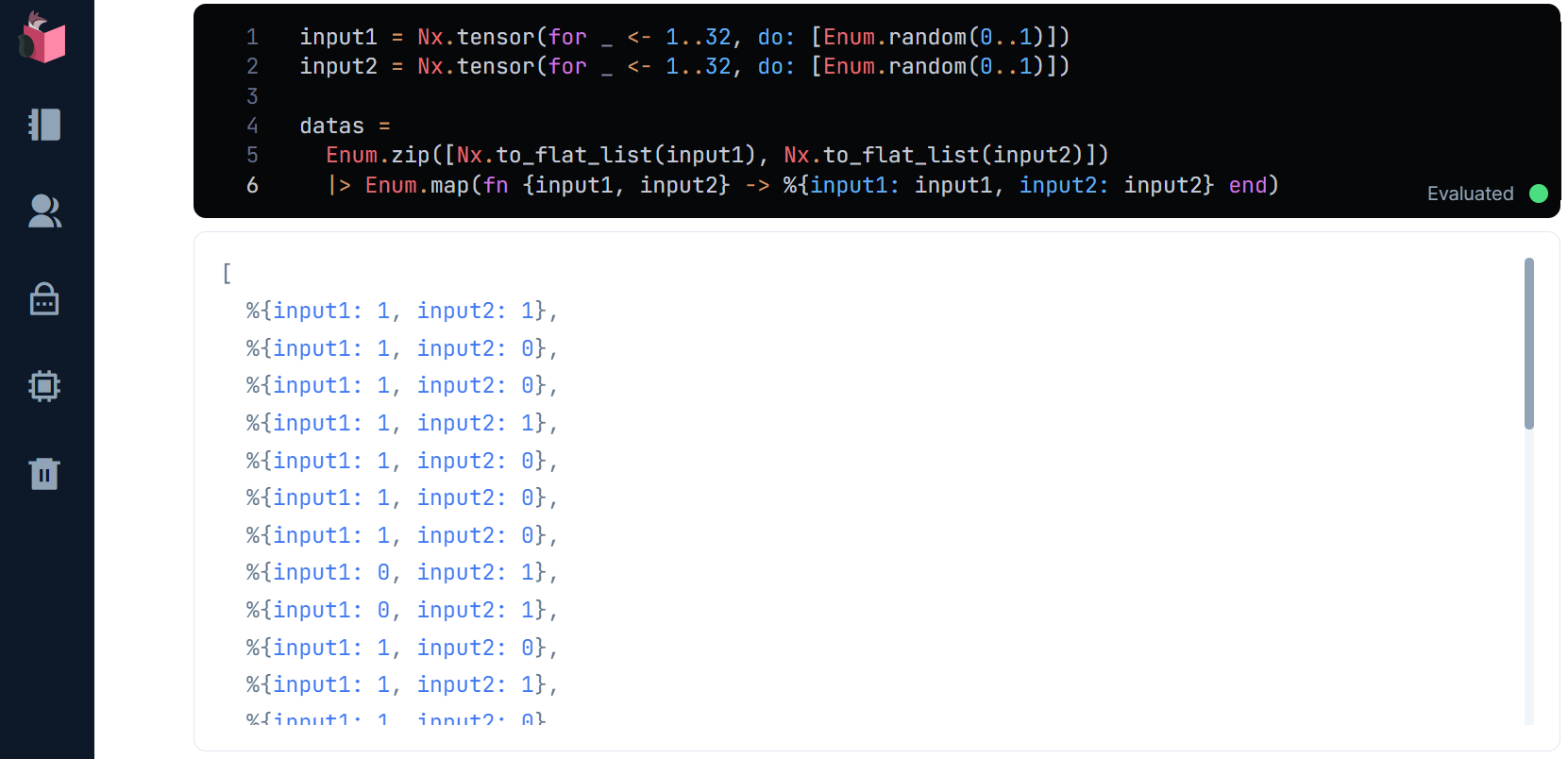
グラフ描画可能なデータができたので、グラフ表示パーツを下図のように、「Smart」Cellの「Chart」で追加します
すると、下記モーダルが出るので、「Add and restart」ボタンをクリックしてください
これにより、最上部「Notebook dependencies and setup」にライブラリ「kino_vega_lite」が追加され(気になる方は確認してみてください)、下記のグラフ描画セルが追加されます
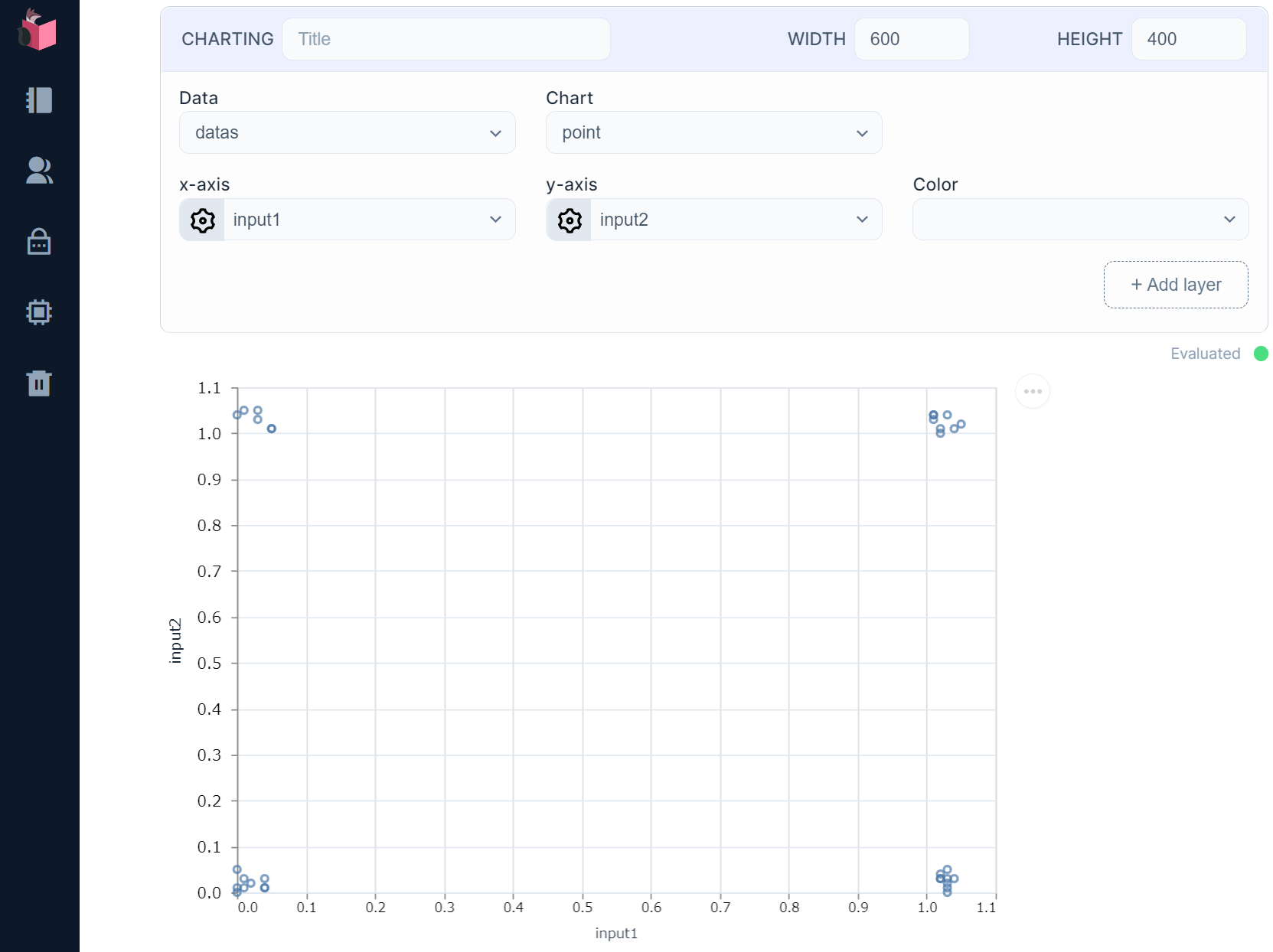
Dataには、デフォルトでdatasが勝手に設定済みなので、「WIDTH」に600、「HEIGHT」に400を入力して、実行すると、下図のように、入力1と入力2が4点のグラフとして表示されます
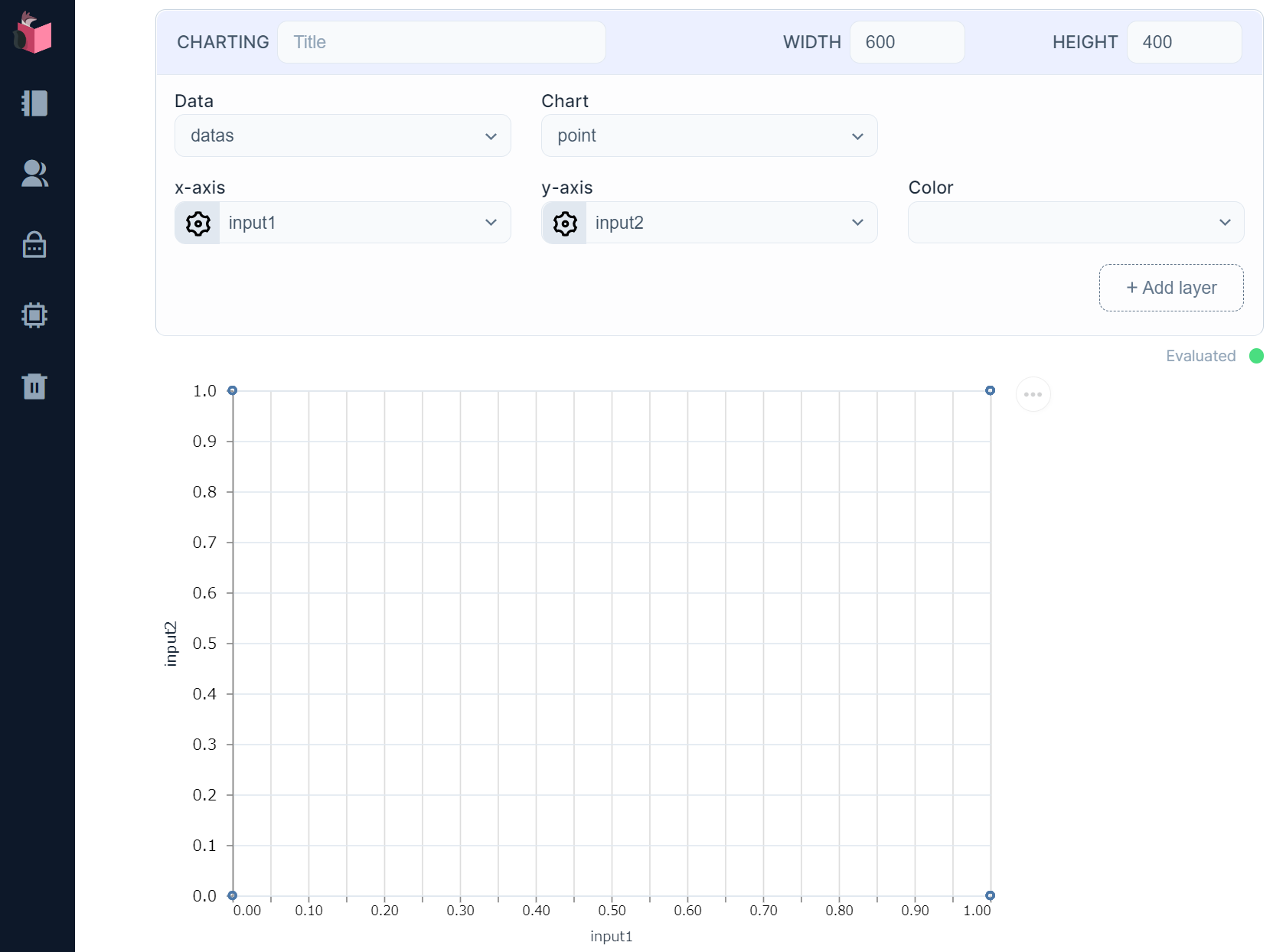
ただ、このままだと、4点が全て重なっていて、どれだけ生成されたかが分かりにくいので、各値を適度に揺らしてみます
input1 = Nx.tensor(for _ <- 1..32, do: [Enum.random(0..1) + Enum.random(0..5) / 100])
input2 = Nx.tensor(for _ <- 1..32, do: [Enum.random(0..1) + Enum.random(0..5) / 100])
datas =
Enum.zip([Nx.to_flat_list(input1), Nx.to_flat_list(input2)])
|> Enum.map(fn {input1, input2} -> %{input1: input1, input2: input2} end)
これでデータ数が確認できます … 32個のデータが出ています
なお、「Smart」Cellはコード化することができ、鉛筆アイコンをクリックすると、下記のように確認が出てきて、「Convert」ボタンをクリックするとコード化できます
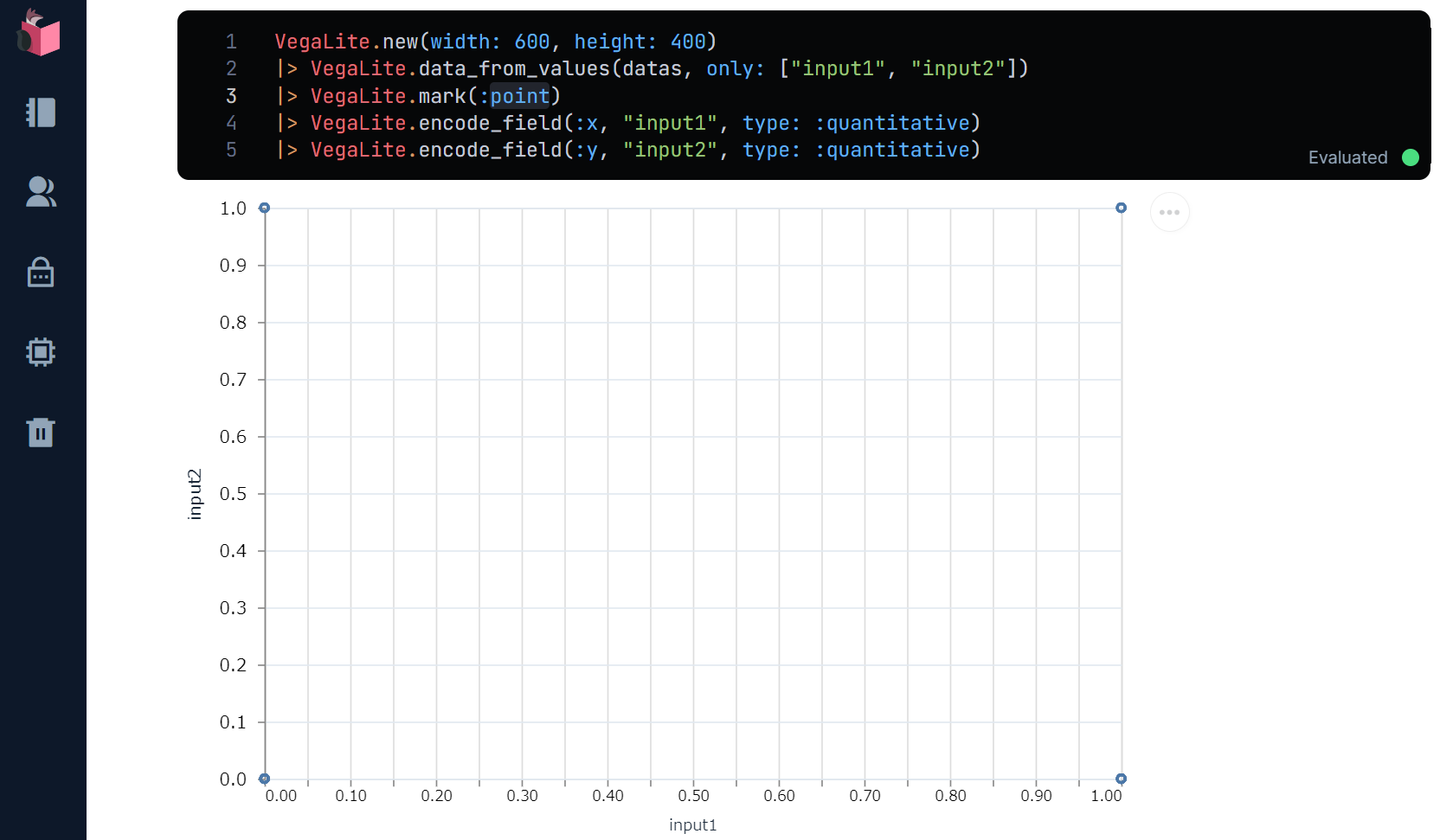
下記のような、VegaLiteを使ったコードが自動生成されていることが確認できます(datasやWIDTH等のUI上で指定したパラメータ指定などもコード化されます)
ⅰ-3.ラベルの付与
上記2つの学習データに対するラベルは、デジタルなOR演算を機械的に行うことで生成します
label = Nx.logical_or(input1, input2)
なお通常は、このような機械的なラベル生成はできないため、人が学習/検証データを見て、ラベルを付与していきます
ⅰ-3.学習データとラベルをセットに
上記2つの学習データと、上記ラベルをセットにしたタプルを作成します
"input1"に32個の0/1ランダムの学習データ、"input2"に32個のinput1と異なる0/1ランダムの学習データ、そのマップに対して32個のラベルというセットになります
{%{"input1" => input1, "input2" => input2}, label}
ⅰ-4.上記学習データ+ラベル1セットを1,000件分、生成する
Stream.repeatedlyで上記学習データ+ラベル1セットを無限に生成し、Enum.takeで先頭1,000件のみを実在化させます
train_datas = Stream.repeatedly(fn ->
(上記で説明済みのコード)
end)
|> Enum.take(1000)
なお、分かりやすさのために1,000件のみとしていますが、コレを実施しなくても、この後の「学習」側で長さを制御することも可能です(良く分からなければ読み飛ばしてください)
ⅱ)モデルの構築/学習
モデルを構築し、そのモデルを学習データで学習させます
require Axon
input1 = Axon.input("input1", shape: {nil, 1})
input2 = Axon.input("input2", shape: {nil, 1})
model = Axon.concatenate(input1, input2)
|> Axon.dense(8, activation: :relu)
|> Axon.dense(1, activation: :sigmoid)
trained_state = model
|> Axon.Loop.trainer(:binary_cross_entropy, :sgd)
|> Axon.Loop.run(train_datas, %{}, epochs: 5, iterations: 1000, compiler: EXLA)
ⅱ-1.Axonでモデル構築
Axonは、ニューラルネットワークの構築をカンタンにできます
下記コードでモデルが構築され、modelに設定されますが、実行結果を見ながら内訳を解説していきます
require Axon
input1 = Axon.input("input1", shape: {nil, 1})
input2 = Axon.input("input2", shape: {nil, 1})
model = Axon.concatenate(input1, input2)
|> Axon.dense(8, activation: :relu)
|> Axon.dense(1, activation: :sigmoid)
構築されたモデルが、下記結果で表示されます
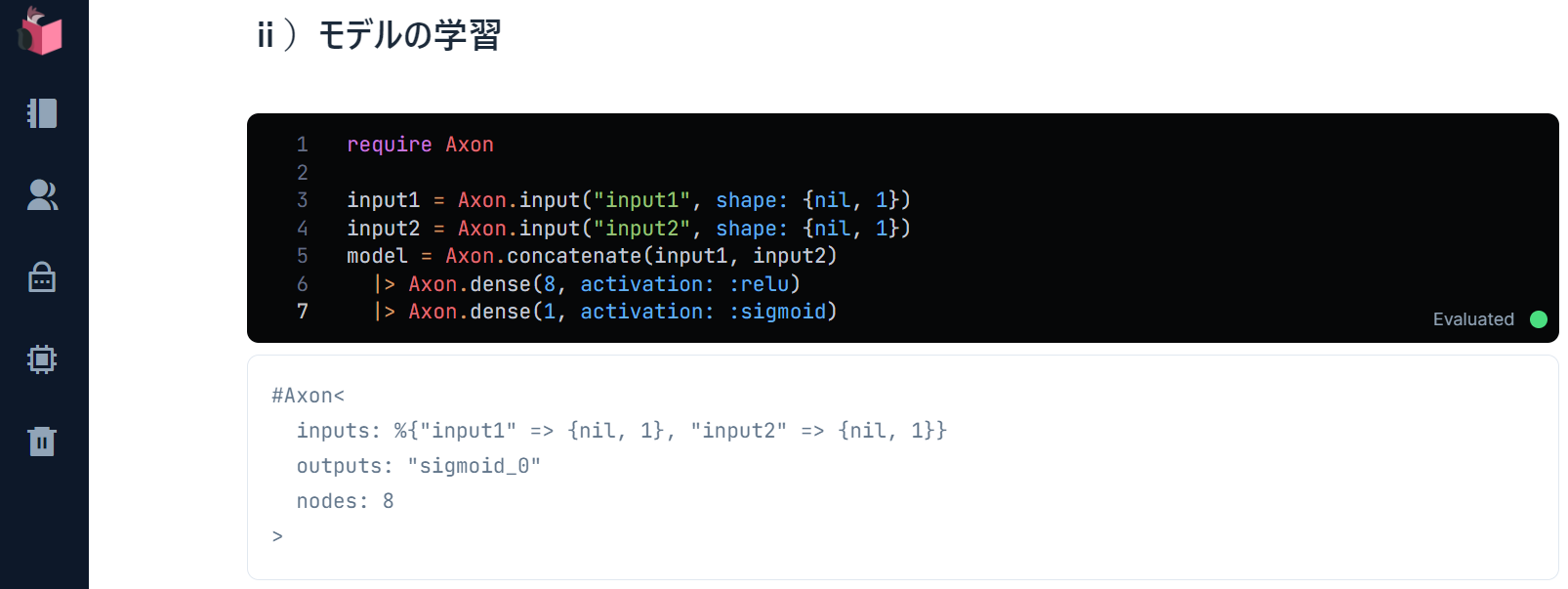
inputs:は、このモデルの「入力層」で、学習(もしくは予測)で入力されるデータの形が定義されています
このモデルには、前述したinput1とinput2の2つの2次元行列が入力される想定です
outputs:は、このモデルの「出力層」で、予測結果がシグモイド関数で設定されています
シグモイド関数は、二値分類、つまり0/1を分類するための関数で、今回のOR予測に向いています(他に、他クラス分類や、回帰(≒連続する数値の予測)のための関数もあります)
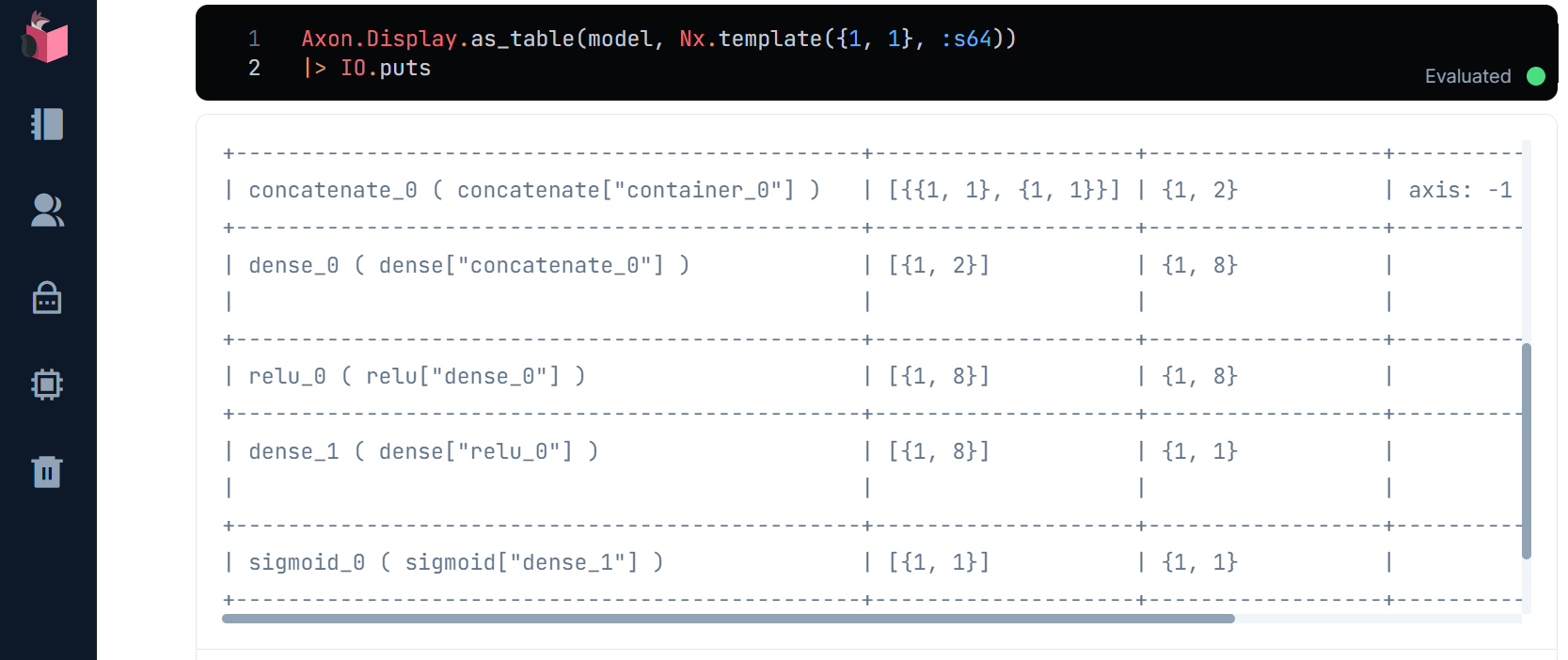
このように、モデルの入出力は、上記で表示できますが、その間にある「中間層」は表示されないため、これを下記コードで表示してみます
Axon.Display.as_table(model, Nx.template({1, 1}, :s64))
|> IO.puts
dense_0 ( dense["concatenate_0"] ) とrelu_0 ( relu["dense_0"] ) が、「中間層」であるAxon.dense(8, activation: :relu)に該当し、やっていることは学習データに対して、「ReLU」という「活性化関数」を設定しています
「活性化関数」は、入力されたデータを、次の層に通過させるか、それとも非活性(≒入力が無かったことにする)とするかを決定しますが、「学習」とは、この通過/非活性の度合い(「重み」と呼ばれます)を調整することを指します
ⅱ-2.モデルの学習
AxonのLoopモジュールにある学習機能を使って、モデルの学習を行います
下記コードでモデルが学習され、trained_stateには学習結果状態がされますが、実行結果を見ながら内訳を解説していきます
trained_state = model
|> Axon.Loop.trainer(:binary_cross_entropy, :sgd)
|> Axon.Loop.metric(:accuracy, "Accuracy")
|> Axon.Loop.run(train_datas, %{}, epochs: 5, iterations: 1000, compiler: EXLA)
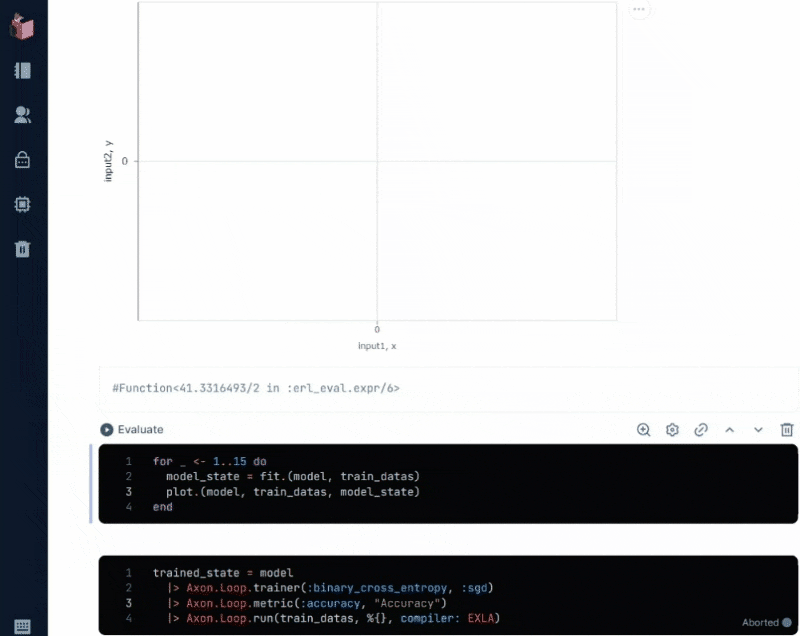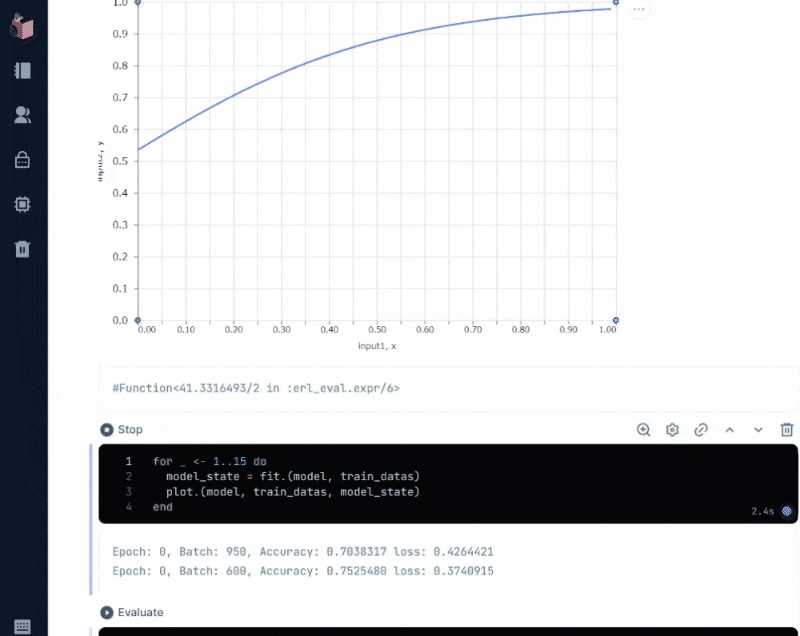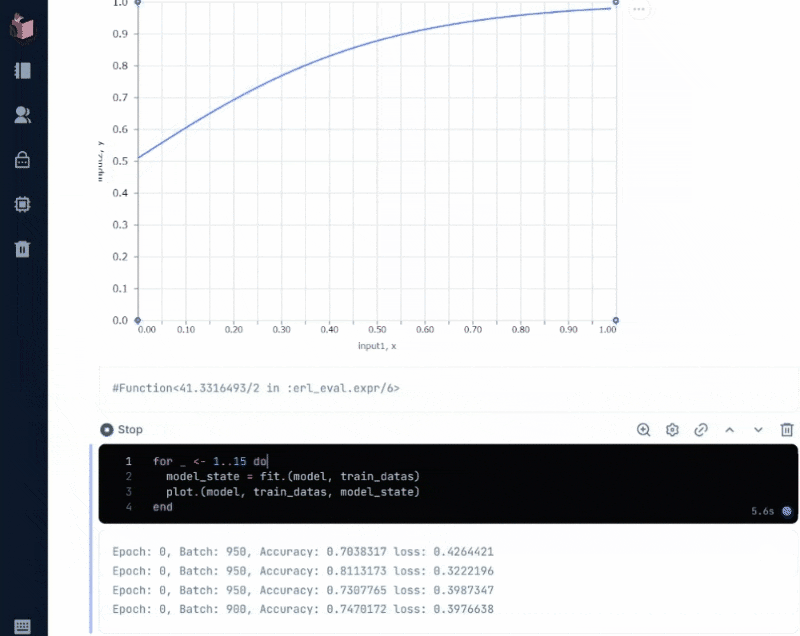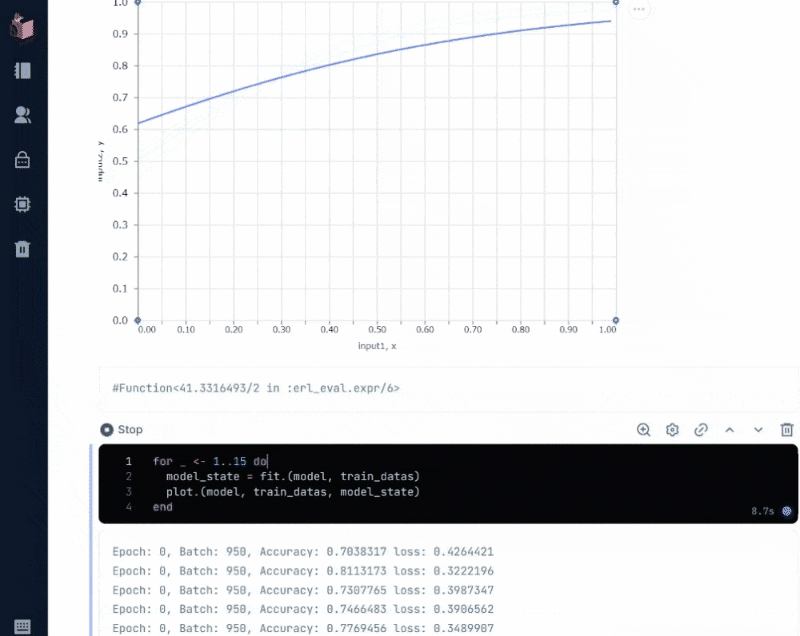
実行すると、下図のように、「正解率(Accuracy)」と「損失率(loss)」が変化しながら、学習回数(epochs)が積み重なる様がアニメーションされます
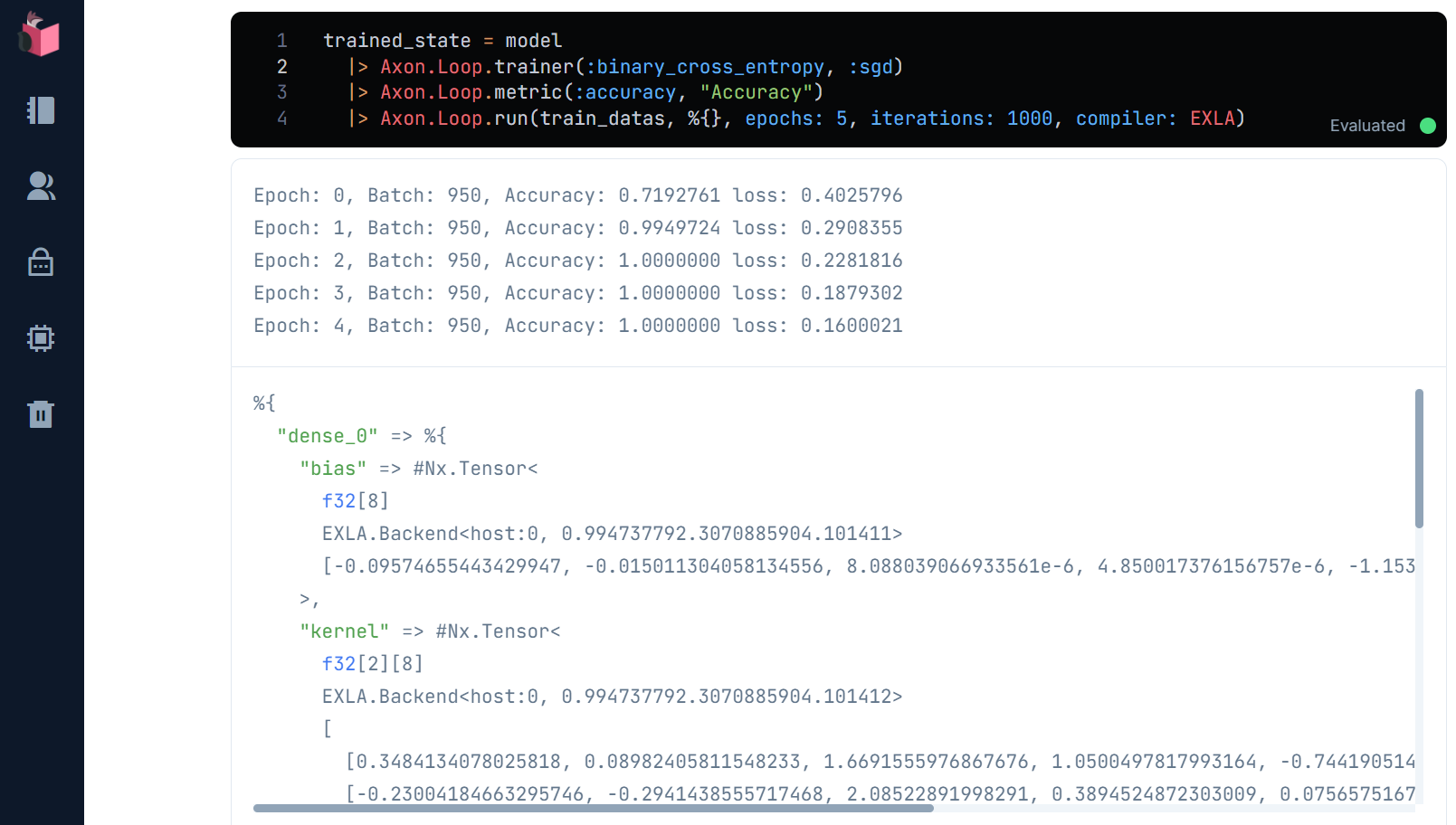
「正解率(Accuracy)」は、Axon.loop.metricで設定されており、モデルの予測とラベルがどの程度、合っているかを示します
「損失率(loss)」は、Axon.Loop.trainerで設定される「損失関数」によって計算されますが、ここでは二値分類のための「バイナリクロスエントロピー」によって計算されています
「バイナリクロスエントロピー」は、結果が「1」である確率を求める関数で、それが「0.5」以上なら「1」、「0.5」未満なら「0」とみなすことで二値分類を判定できます
Axon.Loop.trainerで設定される、もう1つのパラメータは、「最適化アルゴリズム」と呼ばれるもので、上述した「重み」を調整する量をコントロールする関数です
ここでは、ランダムに取り出した学習データの一群から学習を進めることで、学習速度を向上させる「SGD(stochastic gradient descent:確率的勾配降下法)」というものを使っていますが、その詳細や、他のアルゴリズムの紹介は、別の機会に紹介しますので、現時点では「イイ感じに重みを調整してくれる」位の理解でOKです
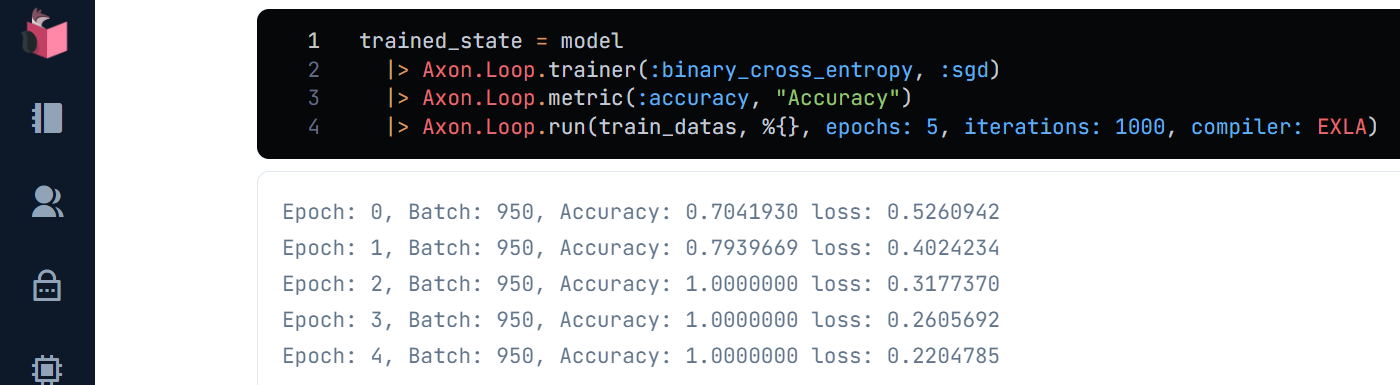
なお、SGDはランダムに学習データを取得するため、実行のたびに、「正解率」と「損失率」の変動が違ってきます(上記の「学習」画面と見比べてください)
最後に、学習回数である「エポック数(epochs)」は、通常であれば10回くらい必要ですが、OR予測は簡単なタスクなので、5回で充分です
ⅱ-3.学習過程のアニメーション化
上記で「Smart」Cellをコード化した際と同様、VegaLiteを使って、モデル学習をグラフ化することで可視化し、学習過程を逐一確認できるよう、アニメーション表示させます
なお、ここのコードはアニメーション表示のために若干分かりにくい部分があるので、VegaLiteに慣れていない方はいったん動かすだけでも構いません … それでも、機械学習がどのように動いているかを視覚で直感的に理解しやすくなります
最初のステップは、「学習」を可視化向けに関数化します(これは「無名関数」という書き方です)
なお、OR予測はあまりにカンタンなため、2~3回で学習完了してしまうため、ここでは毎回、1度のみ学習させた結果を可視化することとしています
fit = fn model, datas ->
model
|> Axon.Loop.trainer(:binary_cross_entropy, :sgd)
|> Axon.Loop.metric(:accuracy, "Accuracy")
|> Axon.Loop.run(datas, %{}, compiler: EXLA)
end
次のステップは、VegaLite.layersにて、「学習データ2つ(input1、input2)」と「学習データによる分類(x、y)」の2系統のレイヤーをグラフ化します
また、plotで、「学習データ2つ(input1、input2)」と「学習データによる分類(x、y)」をグラフに流し込む処理を関数化します
graph = VegaLite.new(width: 600, height: 400)
|> VegaLite.layers([
VegaLite.new
|> VegaLite.mark(:point, tooltip: true)
|> VegaLite.encode_field(:x, "input1", type: :quantitative)
|> VegaLite.encode_field(:y, "input2", type: :quantitative),
VegaLite.new
|> VegaLite.mark(:line)
|> VegaLite.encode_field(:x, "x", type: :quantitative)
|> VegaLite.encode_field(:y, "y", type: :quantitative)
])
|> Kino.VegaLite.new
|> Kino.render
plot = fn model, datas, trained_state ->
input1 = datas |> Enum.map(& elem(&1, 0)["input1"] |> Nx.to_flat_list) |> List.flatten
input2 = datas |> Enum.map(& elem(&1, 0)["input2"] |> Nx.to_flat_list) |> List.flatten
x = (for i <- 0..99, do: i / 100)
|> Nx.tensor
|> Nx.new_axis(0)
|> Nx.transpose
y = Axon.predict(model, trained_state, %{"input1" => x, "input2" => x})
points =
Enum.zip([input1, input2, Nx.to_flat_list(x), Nx.to_flat_list(y)])
|> Enum.map(fn {input1, input2, x, y} -> %{input1: input1, input2: input2, x: x, y: y} end)
Kino.VegaLite.clear(graph)
Kino.VegaLite.push_many(graph, points)
end
ここまで準備できた後、「学習」と「グラフ化」を呼び出すことで、アニメーション表示できます
for _ <- 1..15 do
trained_state = fit.(model, train_datas)
plot.(model, train_datas, trained_state)
end
実際に動く様は、以下の通りで、これがまさに出力層に設定した「シグモイド関数」の形をしています
このグラフの読み方については、次回、予測の詳細と併せて解説したいと思います
今回内容が難しいと感じた方へ
下記コミュニティのイベントで本シリーズ内容の解説やハンズオンをしていますので、ご利用ください
今回コラムをマスターすると…
下記Elixirディープラーニングのコラムを読みこなすことができると思います … 基本的な構造は同じだからです
Elixirでディープラーニング①:手書き文字識別(MNIST)をLivebook+Axonで
|> ElixirのみでディープラーニングOnnx編:Livebook+AxonOnnxでResnet画像識別
終わり
今回は、OR予測の「教師あり学習」の構成と流れを説明した後、実装したコードの各パートを解説しつつ、学習データと学習の可視化を行いました
機械学習が、どういったデータから、どのように学習しているかが可視化されたことで、直感的に理解できる部分が増えたかと思います
次回は、予測について、学習の精度やグラフの意味と絡めて、その詳細を学んでいきます
主催/運営しているElixirコミュニティ紹介
4. LiveView JP : A place to mob-program in LiveView, LiveBook+Nx+Axon, and elixir-desktop
5. Neos.ex : A place to connecting Elixir and NeosVR to create a new world
Elixir生誕10周年を一緒にお祝いしませんか?
12/21(水)19:30~21:00、「過去LTいただいた方々への感謝祭」をテーマに、リモート忘年会を開催
「Elixir生誕10周年」に対するコメントや、今/昔のElixirの進化を聞けるチャンスですので、お見逃し無くッ
※カンパイスタートの会ですので、お酒 or ソフトドリンク、お菓子 or ご飯をお忘れなく
※Zoom接続できれば、本人でも、2Dアバター/3D(VR)アバターでも、お好きな姿でご参加OK
日々アップデートされる、Elixir生誕10周年をお祝いするコラム群についての解説もあります(本コラムも、「第3弾「Elixir/Livebook+NxでPythonっぽくAI・ML」に追加しています)
明日は、@the_haigo さんで「Phoenix 1.7とElixirDesktopでスマホアプリを作る セットアップ編」です