この記事は、Elixir Advent Calendar 2022 6の18日目です
昨日は、@t-yamanashi さんで「Elixirでテスト用の画像を量産しよう」でした
piacere です、ご覧いただいてありがとございます ![]()
この2年間で、Elixirの機械学習環境が凄まじく発展し、プロダクションに実戦投入しても問題無いフェーズに入ったので、「Eixirで機械学習に初挑戦」をテーマにシリーズコラムをお届けします(今回、ページ数が多いですが、画面キャプチャ多めなだけなので、内容は読みやすいと思います)
入門者向けに「機械学習とは何か?」や、機械学習の中で出てくる数々のキーワード解説もしていきますので、AI・MLの知識が無いWeb開発者/IoT開発者の方や、PythonでAI・MLを学んだけどイマイチ入らなかった方、Elixir経験者だけどNx/Axon/Livebook等の新テクノロジーに追いつけていない方にも、スッと入りやすい内容としてまとめていこうと思います
前回までは、機械学習の基礎と可視化、それを叶えるコードの解説をしてきましたが、より実践的な講義内容として、Kaggleのデータを題材とした「データ前処理」を行い、その中で「素の状態でもデータ処理に強いElixir※」を体感してもらおうと思います
今回、実際にKaggleへの提出(submit)まで行っています
※Python pandasライクなElixirデータ処理フレームワーク「Explorer」を使う方法も今ならありますが、2021年までExplorerは未存在で、一方、Python ML向けの「データ前処理」をElixirで作るのに特に難儀したことも無かったので、実はElixir標準だけでも問題無かったりしますw ![]()
 Elixir Advent Calendar 総勢16本、熱い冬ヽ(=´▽`=)ノ
Elixir Advent Calendar 総勢16本、熱い冬ヽ(=´▽`=)ノ
例年に無い盛り上がりを見せています … 応援/購読よろしくお願いします ![]()
https://qiita.com/advent-calendar/2022/elixir
本シリーズの目次
①:基礎知識とLivebook+Nx+Axonによる機械学習入門
|> ②:機械学習コードの解説と「学習データの可視化」「学習過程のアニメ化」
|> ③:「予測」の可視化と「精度」の変化要因、「学習過程グラフ」の読み方
|> ④:データ処理に強いElixirでKaggle挑戦(前編)…「データ前処理」基礎編
|> ⑤:データ処理に強いElixirでKaggle挑戦(後編)…「統計」と「EDA」でKaggleに挑む
|> ⑥:いま、Elixir AI・MLで何が出来る? → Elixirのメリット→2023年に攻略する領域
本コラムの検証環境
本コラムは、以下環境で検証しています(恐らくUbuntu実機やMacでも動きます)
- Windows 10 + WSL2 + Ubuntu 22.04 ※最新版のインストール手順はコチラ
- Elixir 1.14.2 ※最新版のインストール手順はコチラ
- Livebook 0.8.0
Kaggleのデータで「データ前処理」の基礎を学ぶ
「Kaggle」は、世界中1,000万人のデータサイエンティストとAI・MLエンジニアがコンペティションで数百万円~3億円(!)の賞金を争うプラットフォームです(英語が苦手な方は、ブラウザのGoogle翻訳をOnにして進んでください)
Kaggleコンペは、下記7種類のカテゴリがあります
- Getting Started:練習コンペ(メダル無、ランキングにも反映されない)
- Playground:小額の賞金や景品が獲得できる入門向けコンペ
- Featured:賞金やメダルが獲得できる一般的なコンペ
- Research:賞金やメダルが獲得できる実験的で実践的なコンペ
- Community:フェローKagglerによって作成されたコンペ
- Analytics:データ解析のコンペ
- Simulations:ゲームAIを作成しスコアを競うコンペ(強化学習向き)
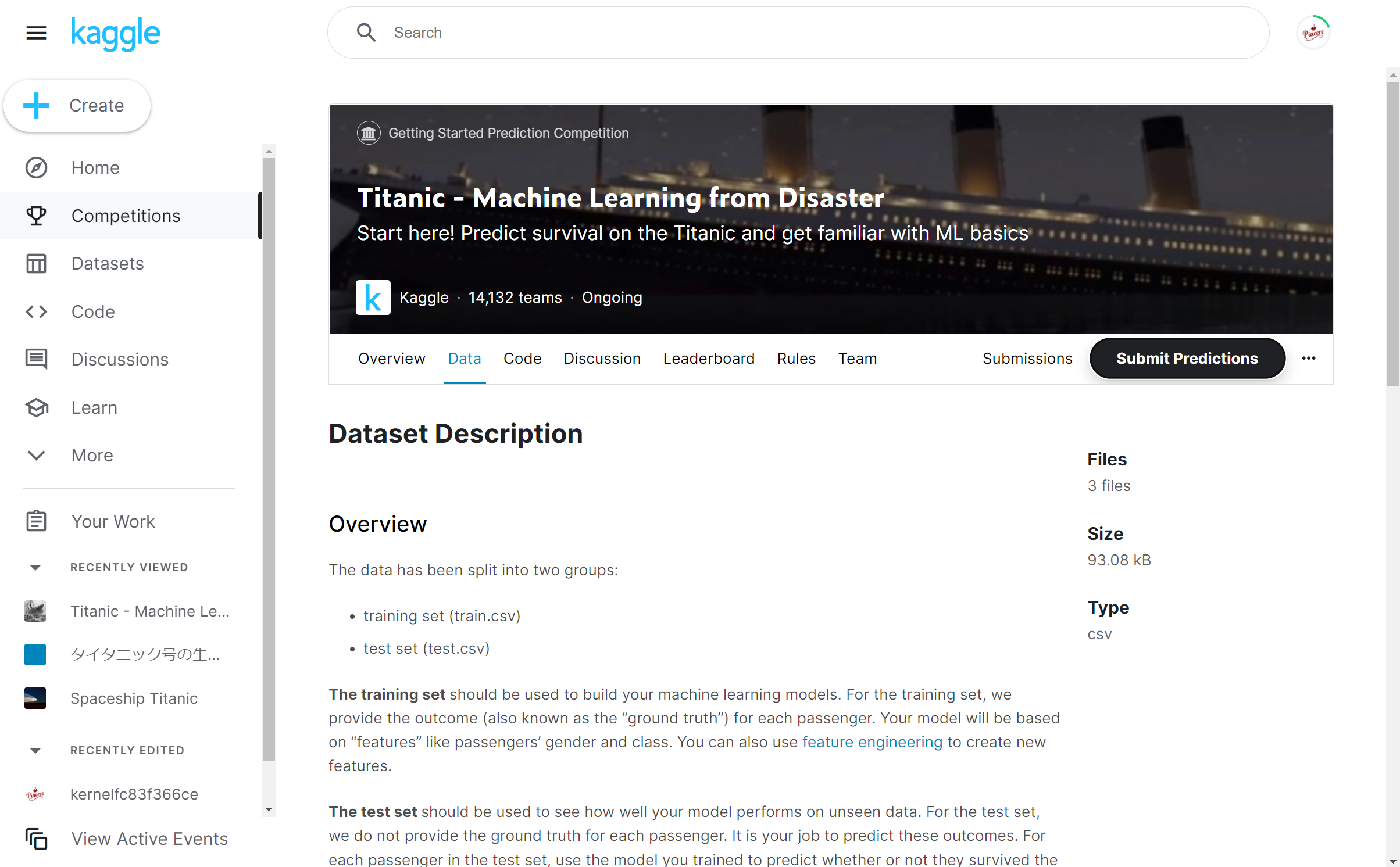
入門者にオススメなのは、もちろん「Getting Started」です
このカテゴリのコンペを見つけるには、Kaggleにログイン後、「Competitions」メニューで開く画面の「Filters」をクリックします(なお、Kaggleのユーザ登録は予め済ませておいてください)

「Getting Started」を選択して、検索すれば、このカテゴリのコンペが絞り込めます

その中から、下図のような面白そうなコンペ(ぜひDescription読んでください、Google翻訳でもOK)で学んでいってはどうかな?…と一瞬、思いかけましたが…
https://www.kaggle.com/competitions/spaceship-titanic/

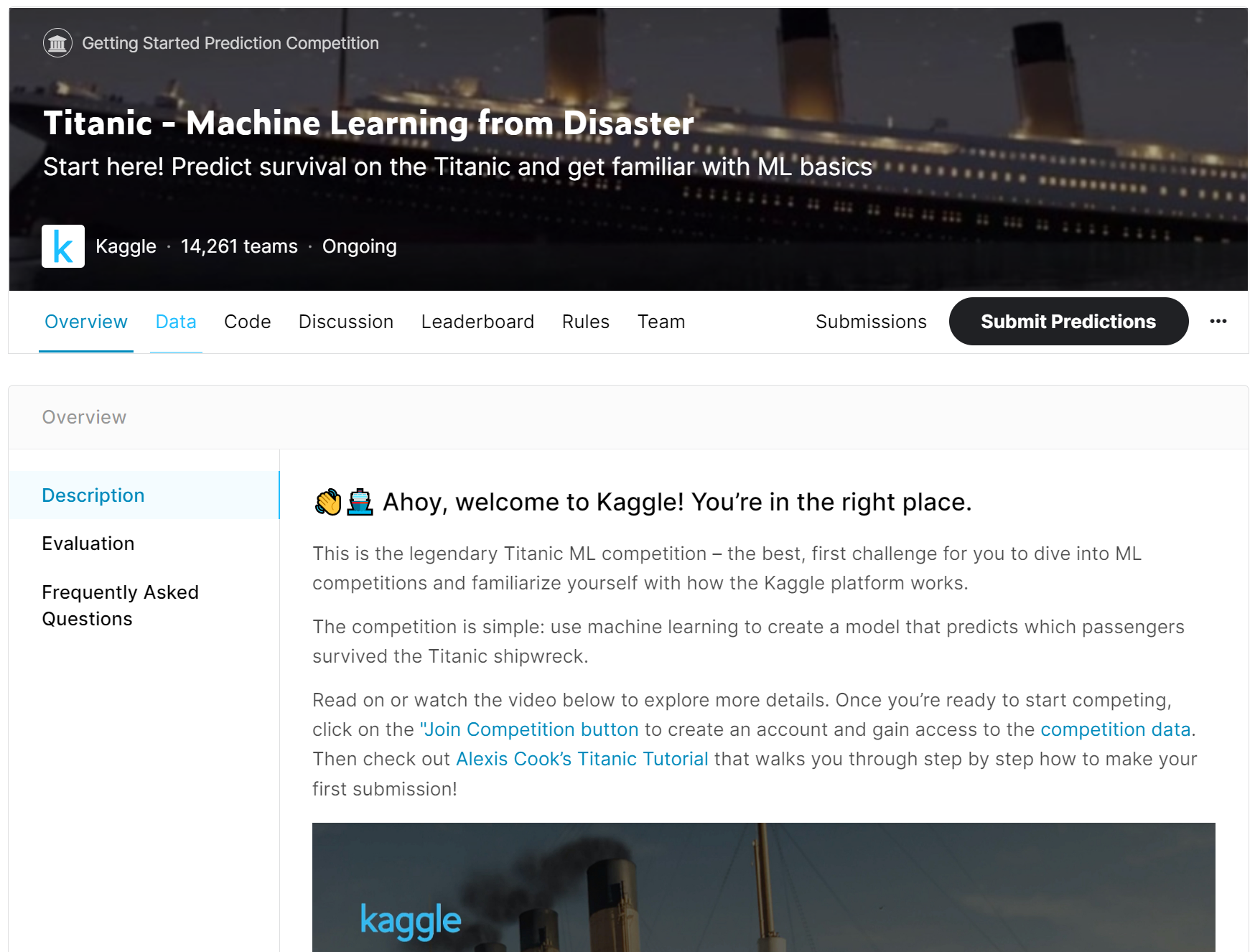
そもそも、この講座は入門向け講義なので、Kaggleをご存知の方であれば誰でも知っており、攻略コラムも巷に煽れているから補講や自学もしやすい「タイタニック問題」を扱うことに改めました ![]()
https://www.kaggle.com/competitions/titanic
今回の流れ
今回の流れは下図で、題材がKaggleに変わっても、これまで学んできたものと同じく、慣れ親しんだものです

本講義回の最終的なコード
下記のコードでタイタニック問題の予測が実現できるので、Kaggleからデータをダウンロード後(この後、やり方は解説します)、Livebookに打ち込んで、動かしてみてください(なお予測結果は、実際にKaggleコンペへの提出(submit)もできます)
Mix.install([
{:csv, "~> 3.0"},
{:exla, "~> 0.4"},
{:axon, "~> 0.3"}
])
defmodule Pre do
def count_missings(datas) do
datas
|> Enum.flat_map(fn map -> Map.filter(map, & elem(&1, 1) == "") |> Map.keys end)
|> Enum.reject(& &1 == [])
|> Enum.frequencies
end
def separate(datas, id, label) do
{
datas |> Enum.map(& Map.get(&1, id)),
if Map.has_key?(List.first(datas), label) do
datas |> Enum.map(& [[String.to_float("#{Map.get(&1, label)}.0")]] |> Nx.tensor)
else
nil
end,
datas |> Enum.map(& Map.drop(&1, [id, label]))
}
end
def drop(datas, keys) do
datas
|> Enum.map(& Map.drop(&1, keys))
end
def empty_replace(datas, replaces_map) do
replaces_map
|> Enum.reduce(datas, fn {key, replace}, acc ->
acc
|> Enum.map(& Map.put(&1, key, String.replace(Map.get(&1, key), ~r/^$/, replace)))
end)
end
def make_dummies(datas, key) do
datas
|> Enum.map(& Map.get(&1, key))
|> Enum.uniq
|> Enum.with_index(& {&1, String.to_float("#{&2}.0")})
|> Enum.into(%{})
end
def to_dummies(datas, train_maps, keys) do
keys
|> Enum.reduce(datas, fn key, acc ->
acc
|> Enum.map(& Map.put(&1, key, make_dummies(train_maps, key)[Map.get(&1, key)]))
end)
end
def integer_string_to_float(datas, keys) do
keys
|> Enum.reduce(datas, fn key, acc ->
acc
|> Enum.map(& Map.put(&1, key, Map.get(&1, key)
|> String.replace(~r/^(?!.*\.).*$/, "\\0\.0")
|> String.to_float))
end)
end
def map_to_tensor(datas) do
datas
|> Enum.map(& [Map.values(&1)] |> Nx.tensor)
end
def for_dummies(datas) do
datas
|> drop([:cabin, :name, :ticket])
|> empty_replace(%{embarked: "S", age: "0", fare: "0"})
end
def process(datas, train_datas) do
for_dummies_train_data = for_dummies(train_datas)
datas
|> for_dummies
|> to_dummies(for_dummies_train_data, [:embarked, :sex])
|> integer_string_to_float([:age, :fare, :parch, :pclass, :sibsp])
|> map_to_tensor
end
def header_and_csv_datas(path) do
[hd | tl] = File.stream!(path)
|> CSV.decode!
|> Enum.to_list
header = hd
|> Enum.map(& &1 |> String.downcase |> String.to_atom)
{header, tl}
end
def csv_file_to_datas(path) do
{header, datas} = header_and_csv_datas(path)
datas
|> Enum.map(& List.zip([header, &1]) |> Enum.into(%{}))
|> Pre.separate(:passengerid, :survived)
end
end
{train_csv_ids, train_csv_labels, train_csv_maps} = Pre.csv_file_to_datas("train.csv")
train_datas = Enum.zip(Pre.process(train_csv_maps, train_csv_maps), train_csv_labels)
model =
Axon.input("input", shape: {nil, 7})
|> Axon.dense(48, activation: :tanh)
|> Axon.dropout(rate: 0.2)
|> Axon.dense(48, activation: :tanh)
|> Axon.dense(1, activation: :sigmoid)
trained_state =
model
|> Axon.Loop.trainer(:mean_squared_error, Axon.Optimizers.adam(0.0005))
|> Axon.Loop.metric(:accuracy, "Accuracy")
|> Axon.Loop.run(train_datas, %{}, epochs: 20, compiler: EXLA)
(紙面ボリュームの都合で割愛)
{test_csv_ids, _, test_csv_maps} = Pre.csv_file_to_datas("test.csv")
result = Pre.process(test_csv_maps, train_csv_maps)
|> Enum.map(& Axon.predict(model, trained_state, &1)
|> Nx.to_flat_list |> List.first |> round)
|> then(& Enum.zip(test_csv_ids, &1))
|> Enum.map(fn {k, v} -> [k, Integer.to_string(v)] end)
|> then(& [["PassengerId", "Survived"] | &1])
result
|> CSV.encode
|> Enum.to_list
|> then(& File.write("result.csv", &1))
今回は、「ⅰ)学習データの準備」と、その中にある「データ前処理」に集中した解説を行い、それ以外は次回以降の中で解説したいと思います
ⅰ)学習/検証データとラベルの準備
OR学習/予測では、デジタルなOR演算だったため、ランダムな学習データと、演算によるラベルを扱いましたが、今回からは、よりリアルなシチュエーションとして、学習データに人がラベル付けしたものを扱います
ⅰ-1.生データの収集
「タイタニック問題」のページに飛んだら、「Data」をクリックします

少しスクロールすると、下図のような部分が出てくるので、「Download All」ボタンでtitanic.zipというファイルがダウンロードされます
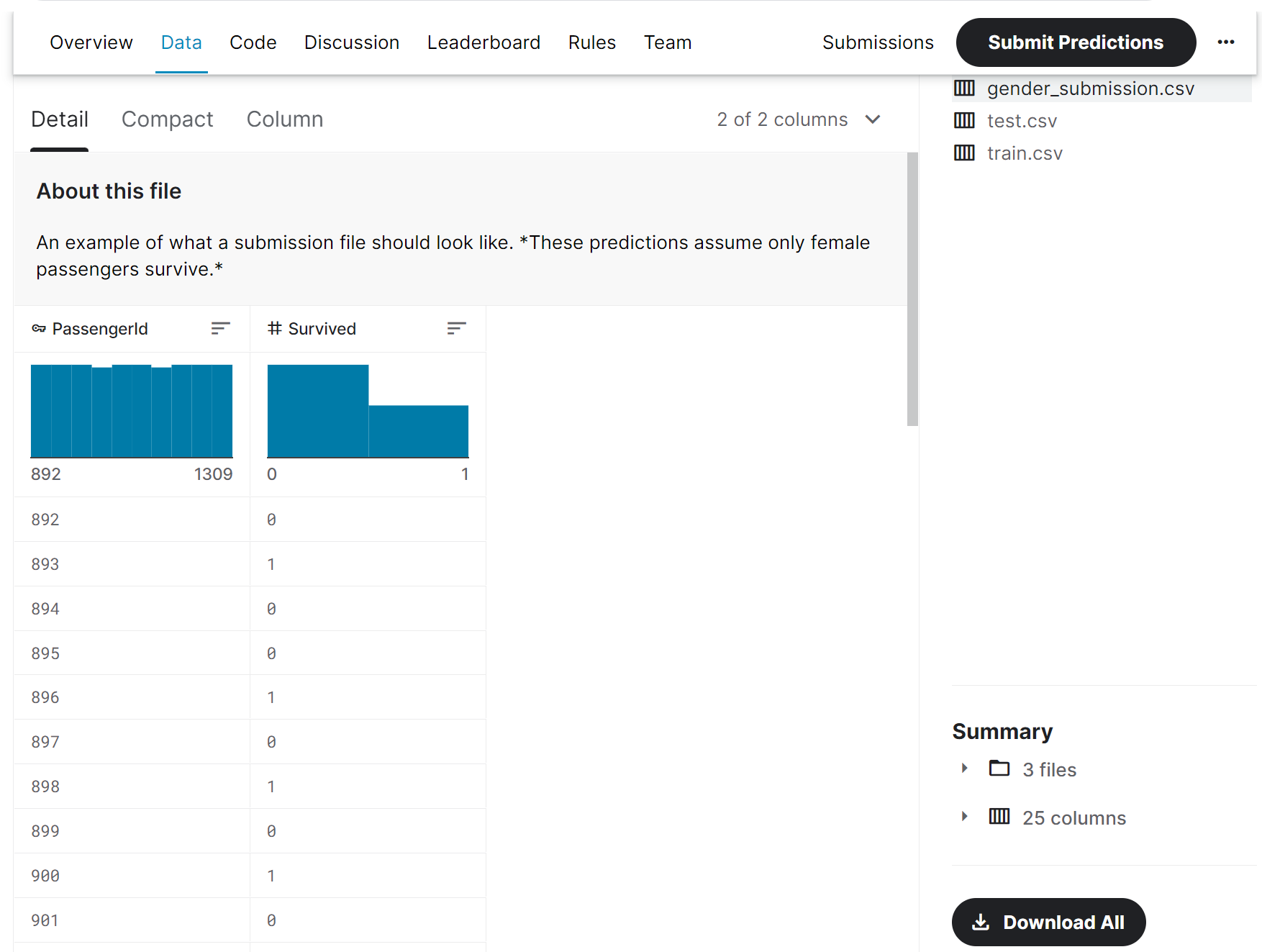
titanic.zipを解凍すると、以下3つのCSVファイルが入っています

中に入っているCSVファイルの各列の意味は、このページ中段に下記の通り、記載されています

survivedがラベルで、タイタニックの各乗客が、生存していれば「1」、生存が確認できない場合は「0」を示します
あと、この表には出ていませんが、passenger_idという、各データ毎の通番もあります
残りは全て学習データで、各乗客の特徴を示します(詳細は「データ前処理」内で解説します)
ⅰ-2.生データをLivebookにロード
まず、Livebookからアクセス可能な場所に、train.csvとtest.csvを置きます
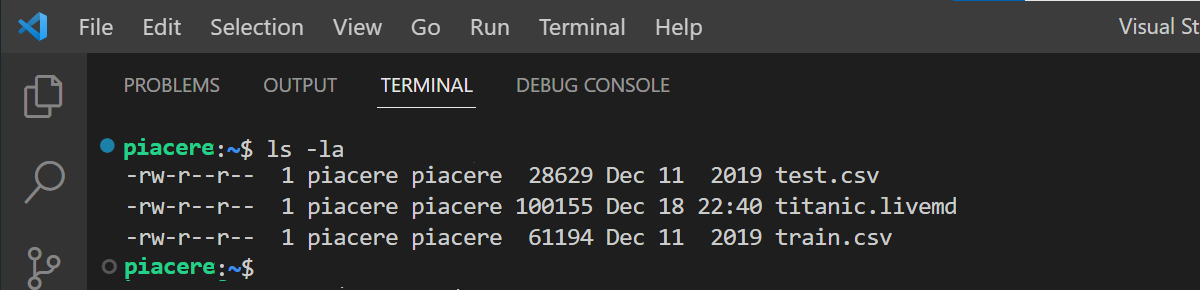
次に、Livebook最上部の「Notebook dependencies and setup」で、下記を実行し、ライブラリ群をロードしてください
Mix.install([
{:csv, "~> 3.0"},
{:exla, "~> 0.4"},
{:axon, "~> 0.3"}
])
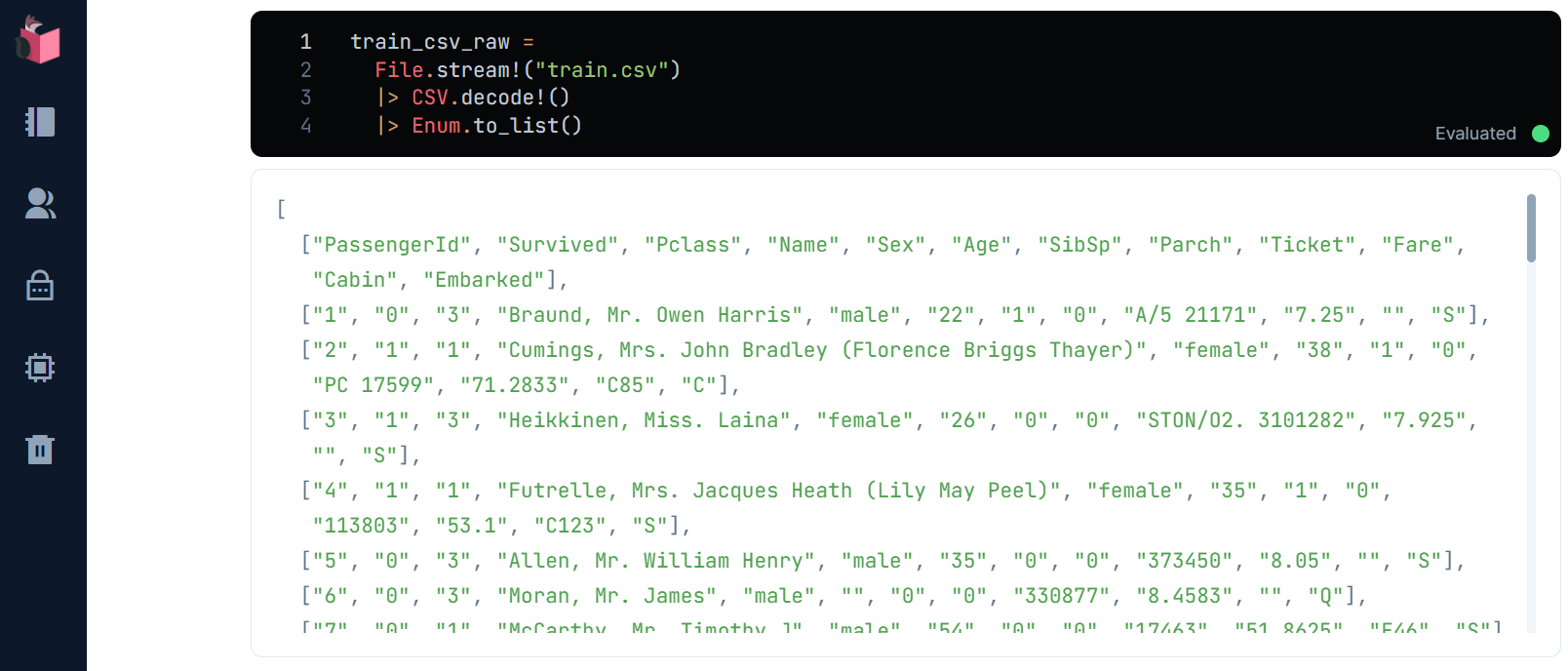
それから、ライブラリ「CSV」でtrain.csvをロードします
train_csv_raw =
File.stream!("train.csv")
|> CSV.decode!
|> Enum.to_list
ロードすると、リスト内リストとしてロードされます
ⅰ-3.データ操作しやすくするためにマップ群に変換
リスト内リストのままだと、ヘッダーの列名で値にアクセスするのが不便なので、ヘッダーの列名をキーとするマップ群に変換します
まず、ヘッダーをhdで取り出し、小文字化し、アトム化します
train_csv_header =
train_csv_raw
|> hd
|> Enum.map(& 1 |> String.downcase |> String.to_atom)
下記のように、ヘッダーを小文字化/アトム化されたリストにします

ヘッダー列名をキーとするマップ群は、ヘッダー以降のデータ群をtlで取り出し、ヘッダーと各データをList.zipでキーワードリスト化し、Enum.intoでマップ化することで作成します
train_csv_maps =
train_csv_raw
|> tl
|> Enum.map(& List.zip([train_csv_header, &1]) |> Enum.into(%{}))
これで各データをマップとして扱えるので、アクセスしやすくなります

ⅰ-4.学習のための最低限の「データ前処理」
まず大前提として、機械学習では、文字列や空白のような数値データ以外を入力として使うことはできないので、空白無の数値データのみに変換する必要があり、これを「データ前処理」で行います(これは、学習データとラベルの両方に必要です)
また、以下2つも「データ前処理」で行います
- データの中には、ラベルと相関性が無い、いわゆる「特徴と言えないデータ」が存在し得るので、その列の削除
- ID/ラベル/学習データはモデル学習の際に別データとする必要があるため、分離
なお、本講義回では、学習のための最低限の「データ前処理」のみ行い、精度向上のための工夫は次回に預けます
①空白値の確認
まず、IDやラベルも含め、空白値をピックアップし、集計します
train_csv_all_maps
|> Enum.flat_map(fn map -> Map.filter(map, & elem(&1, 1) == "") |> Map.keys end)
|> Enum.reject(& &1 == [])
|> Enum.frequencies
以下の列に空白値があるようです

これらのうち、欠損値の補完が必要か、それとも列自体が不要かをこの後、判断します
なお、「データ前処理」は、学習データだけで無く、検証データや未知データに対しても同じ処理を行う必要があるため、count_missingsで関数化しておきます
defmodule Pre do
def count_missings(datas) do
datas
|> Enum.flat_map(fn map -> Map.filter(map, &(elem(&1, 1) == "")) |> Map.keys end)
|> Enum.reject(&(&1 == []))
|> Enum.frequencies
end
end
下記のように呼び出します
train_csv_maps
|> Pre.count_missings
②ID/ラベル/学習データを分離
ID/ラベル/学習データの分離は、それぞれの列をマップから抜き出すseparateという関数で行います
うち、ラベルについては、この段階で行列化しておきますが、以下2つの操作が必要です
-
Nx.tensorでの行列化できる値は小数だが、ラベルは整数文字列なので、整数の後ろに「.0」を付加し、String.to_floatすることで小数化 - モデルに入力できるよう、「2次元行列のリスト」に変換する必要があるが、ラベル群は単なるリストのため、2次元行列で包むために、2重リスト
[[~]]で囲んだ上で、Nx.tensorに渡す
defmodule Pre do
def count_missings(datas) do
…
def separate(datas, id, label) do
{
datas |> Enum.map(& Map.get(&1, id)),
datas |> Enum.map(& [[String.to_float("#{Map.get(&1, label)}.0")]] |> Nx.tensor),
datas |> Enum.map(& Map.drop(&1, [id, label]))
}
end
end
{trains_csv_ids, train_csv_labels, train_csv_maps} =
train_csv_all_maps
|> Pre.separate(:passengerid, :survived)
ID/ラベル/学習データに分離され、ラベルは「2次元行列のリスト」に変換されたことが確認できます

③特徴とならない列の削除
タイタニック問題で「特徴と言えないデータ」に該当すると思われるのは以下です
- cabin:部屋番号
- 部屋番号は、生存率にとても高い相関性を持っているはずですが、Cabinは891件中、687件と大量のデータが欠損しているため、使い物にならないと判断し、削除
- name:乗客名
- 乗客名は、全員が異なり、生存率にも無関係と思われる
- 名字が同じで、チケット番号が近い or 部屋が近い等であれば、家族乗船の可能性があり、家族全員がボートに乗れるまで待ったとき生存率が低くなる、といった仮説は考えられるが、いったん削除
- ticket:チケット番号
- チケット番号そのものは、生存率に無関係と思われる
- 近い番号の方が、生存率の高い/低い部屋番号にまとまって配置されたという可能性は考えられるが、憶測の域を出ないので、いったん削除
これら列の削除をdropという関数で行います
defmodule Pre do
def count_missings(datas) do
…
def drop(datas, keys) do
datas
|> Enum.map(& Map.drop(&1, keys))
end
end
train_csv_dropped_maps = train_csv_maps
|> Pre.drop([:cabin, :name, :ticket])
cabinなどの列が削除されているのが確認できます

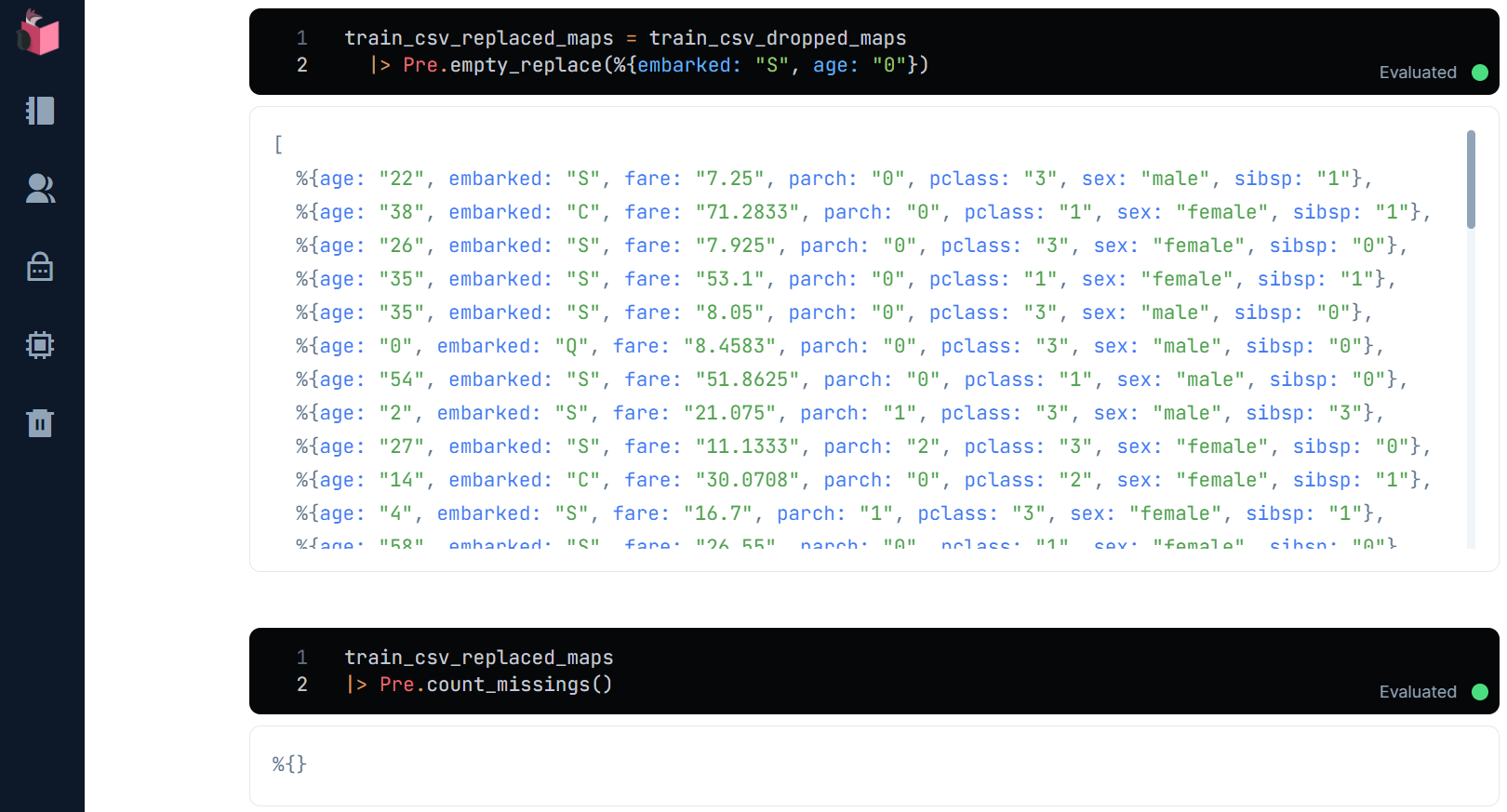
④欠損値の補完
欠損値のうち、cabinは列ごと削除されたので、残るageとemberkedが補完対象で、これをempty_replaceという関数で行います
defmodule Pre do
def count_missings(datas) do
…
def empty_replace(datas, replaces_map) do
replaces_map
|> Enum.reduce(datas, fn {key, replace}, acc ->
acc
|> Enum.map(& Map.put(&1, key, String.replace(Map.get(&1, key), ~r/^$/, replace)))
end)
end
end
ここではいったん、ageは「0」、emberkedは「S」で補完します(本来、どのような値で補完するかは精度に影響を与えますが、これは次回に)
train_csv_replaced_maps = train_csv_dropped_maps
|> Pre.empty_replace(%{embarked: "S", age: "0"})
欠損値が無くなったことを確認できました
⑤カテゴリ値(種別文字列)を数値に変換
sexは、「make」と「female」の2種類の文字列で男女を分類していますが、このような種別を表す文字列の数値化は、「male」を「0」、「female」を「1」のように、通番の数値に置換することで実現できます
このような種別を表す文字列を「カテゴリ値」と呼びます
また、通番数値はダミーの値であることから「ダミー変数」と呼ばれることもあります(Pythonのpandasではget_dummiesという関数でこの置換を行います)
こうした置換自体を「ワンホットエンコーディング」と呼ぶこともあります
さて蘊蓄はこのくらいにして、置換用コードを書いてみましょう
まずは、指定列をカテゴリ値とみなし、ダミー値を振ったマップを生成するmake_dummiesという関数を追加します
指定されたキーのみを抽出し、ユニーク化した後、Enum.with_indexでインデックスを振り出し、Enum.intoでマップ化することで実装します
このとき、Enum.with_indexで振り出すインデックスは、整数がデフォルトなので、separeteでラベルに行ったのと同じ方法で小数化します
defmodule Pre do
def count_missings(datas) do
…
def make_dummies(datas, key) do
datas
|> Enum.map(& Map.get(&1, key))
|> Enum.uniq
|> Enum.with_index(& {&1, String.to_float("#{&2}.0")})
|> Enum.into(%{})
end
カテゴリ値であるsexとemberkedのダミー値入りマップを生成してみます
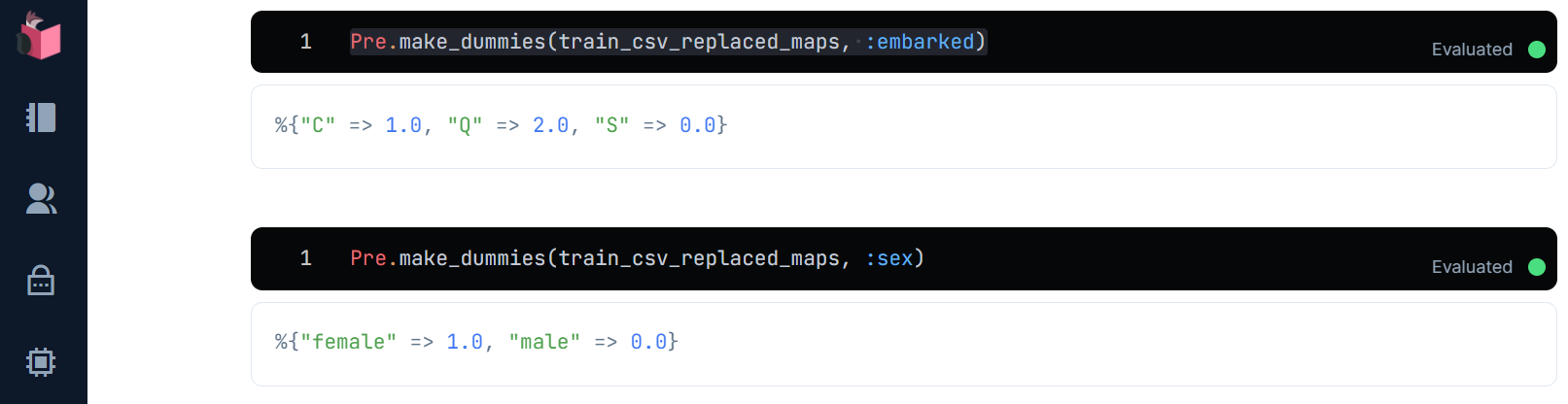
Pre.make_dummies(train_csv_replaced_maps, :embarked)
Pre.make_dummies(train_csv_replaced_maps, :sex)
ダミー値入りマップが生成可能となりました
次に、make_dummiesを使って、指定列をダミー値に入れ替えるto_dummiesという関数を追加します
defmodule Pre do
def count_missings(datas) do
…
def to_dummies(datas, train_maps, keys) do
keys
|> Enum.reduce(datas, fn key, acc ->
acc
|> Enum.map(& Map.put(&1, key, make_dummies(train_maps, key)[Map.get(&1, key)]))
end)
end
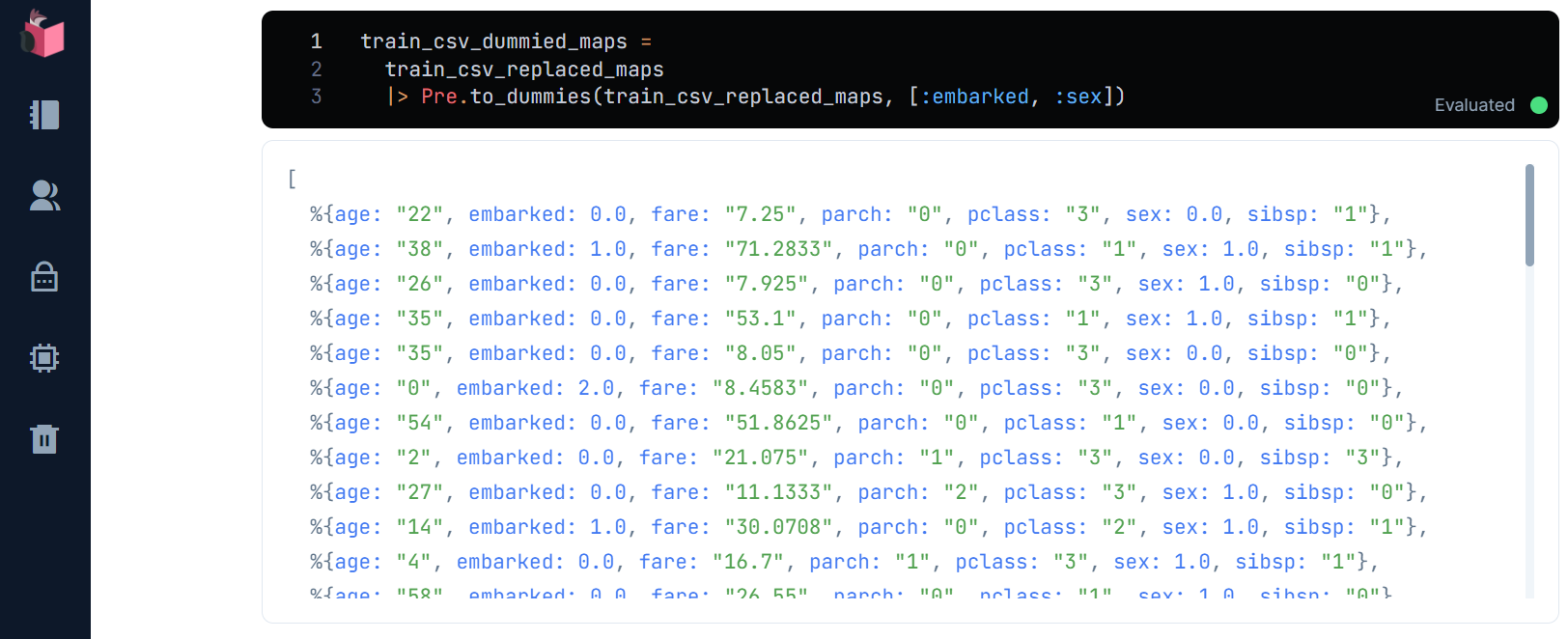
カテゴリ値であるsexとemberkedを置換します
train_csv_dummied_maps = train_csv_replaced_maps
|> Pre.to_dummies(train_csv_replaced_maps, [:embarked, :sex])
カテゴリ値が数値に置換されました
⑥整数を小数に変換
数値文字列から数値への変換を行いますが、ここで、整数と小数が混在する列は、文字列から数値への変換をString.to_integerとString.to_floatを使い分けしなければならなくて面倒なため、整数文字列を全て小数文字列に変換した上で、小数に変換します
まずは、整数値は小数表記の文字列に変換した上で、全て小数に置換するinteger_string_to_floatという関数を追加します
integer_string_to_floatでは、指定された全キーに対し、Enum.reduceを使って、小数化を行っていきます
整数文字列の小数文字列化は、小数点である「.」が存在しない値を整数とみなし、String.replaceの正規表現置換によって後ろに「.0」を付加します
defmodule Pre do
def count_missings(datas) do
…
def integer_string_to_float(datas, keys) do
keys
|> Enum.reduce(datas, fn key, acc ->
acc
|> Enum.map(& Map.put(&1, key, Map.get(&1, key)
|> String.replace(~r/^(?!.*\.).*$/, "\\0\.0")
|> String.to_float))
end)
end
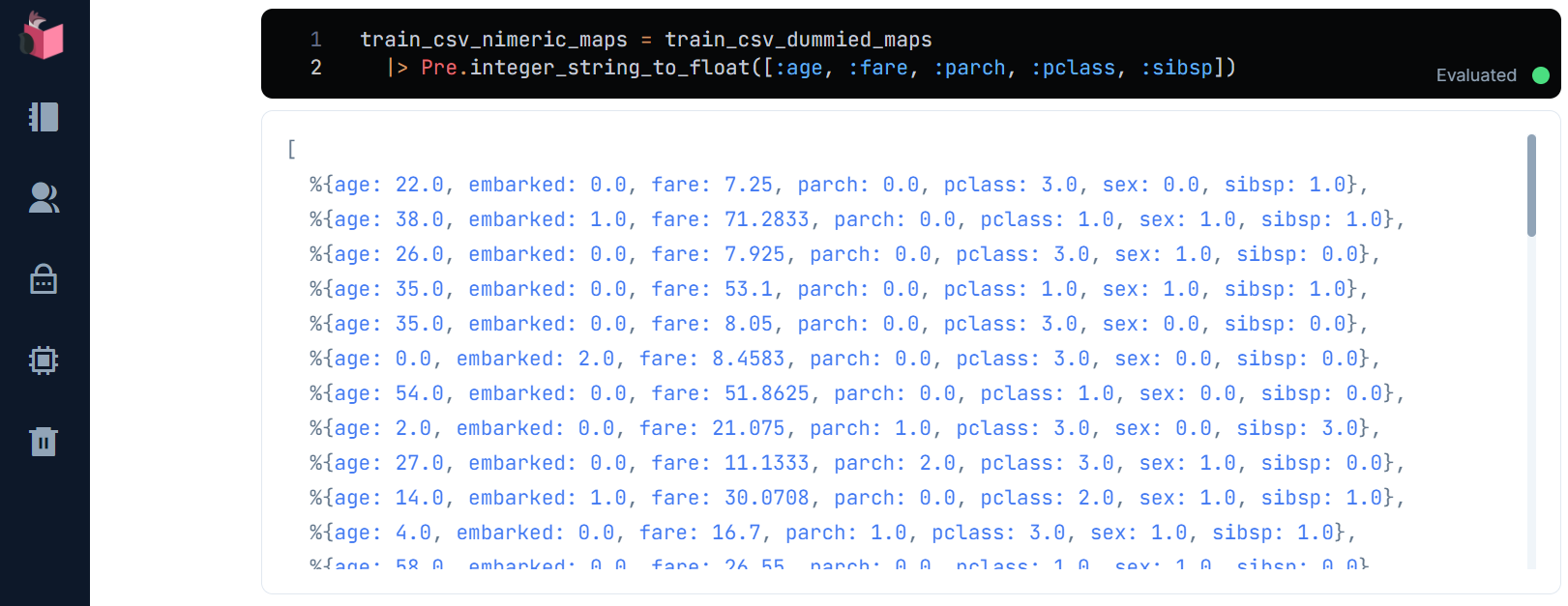
数値列であるage/fare/parch/pclass/sibspが対象です
train_csv_nimeric_maps = train_csv_dummied_maps
|> Pre.integer_string_to_float([:age, :fare, :parch, :pclass, :sibsp])
これで全ての列が、数値化されました
⑦数値を行列に変換
最後に、数値をモデルに入力できるよう、行列に変換するためにmap_to_tensorという関数を追加します
ここで、「2次元行列のリスト」になるよう、Map.valuesで出力されるリストを、更にリスト[~]で囲んだ上で、Nx.tensorにて行列化します
defmodule Pre do
def count_missings(datas) do
…
def map_to_tensor(datas) do
datas
|> Enum.map(& [Map.values(&1)] |> Nx.tensor)
end
end
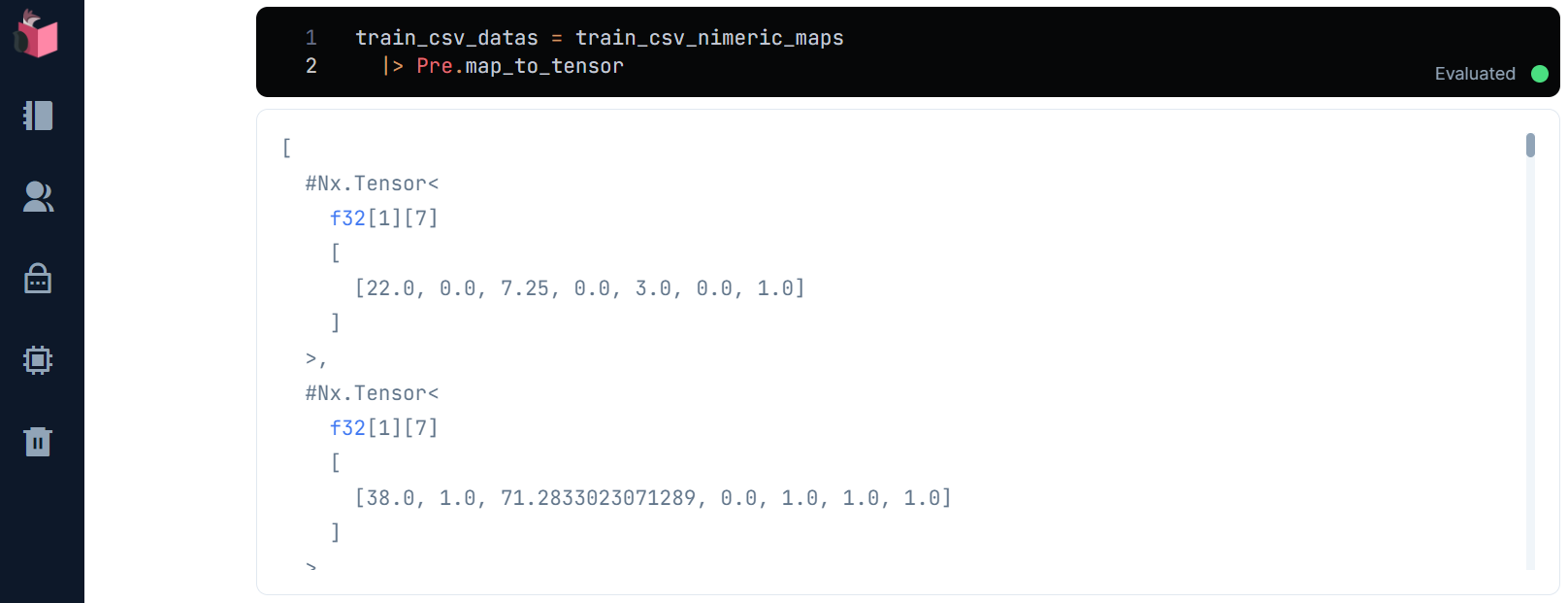
train_csv_datas = train_csv_nimeric_maps
|> Pre.map_to_tensor
学習データが「2次元行列のリスト」に変換されました
⑧「データ前処理」全体の関数化
ここまでの「データ前処理」をprocessという関数で1発で完了するようにします
ここで、datasとtrain_datasの2つの引数を取っている理由ですが、これはto_dummiesの実施が、検証データや未知データではカテゴリ値が網羅されていないケースへの対策として、学習データからカテゴリ値を拾うためです
defmodule Pre do
def count_missings(datas) do
…
def for_dummies(datas) do
datas
|> drop([:cabin, :name, :ticket])
|> empty_replace(%{embarked: "S", age: "0"})
end
def process(datas, train_datas) do
for_dummies_train_data = for_dummies(train_datas)
datas
|> for_dummies
|> to_dummies(for_dummies_train_data, [:embarked, :sex])
|> integer_string_to_float([:age, :fare, :parch, :pclass, :sibsp])
|> map_to_tensor
end
end
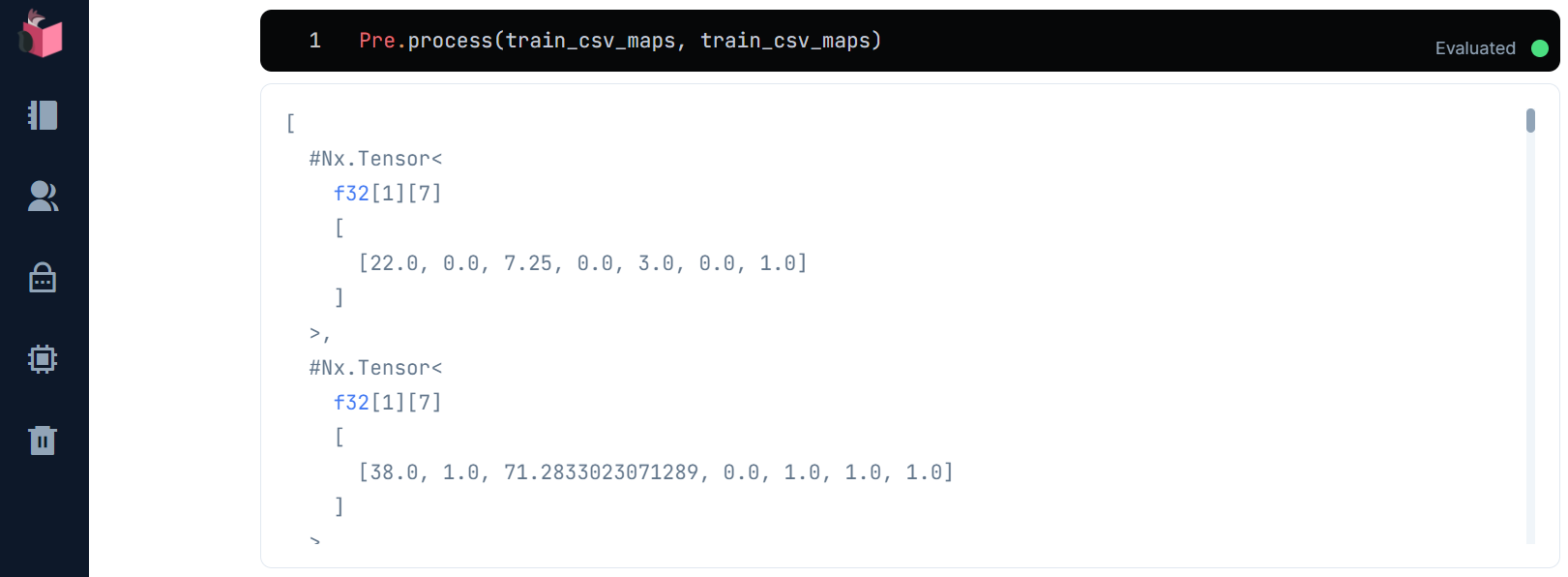
Pre.process(train_csv_maps, train_csv_maps)
1発で「データ前処理」が完了できました
更に、CSVファイルロード/マップ群変換/分離(ID/ラベル/学習データ)を処理する処理を、csv_file_to_datasとして関数化しておきます
defmodule Pre do
def count_missings(datas) do
…
def header_and_csv_datas(path) do
[hd | tl] = File.stream!(path)
|> CSV.decode!
|> Enum.to_list
header = hd
|> Enum.map(&(&1 |> String.downcase |> String.to_atom))
{header, tl}
end
def csv_file_to_datas(path) do
{header, datas} = header_and_csv_datas(path)
datas
|> Enum.map(& List.zip([header, &1]) |> Enum.into(%{}))
|> Pre.separate(:passengerid, :survived)
end
end
{train_csv_ids, train_csv_labels, train_csv_maps} =
Pre.csv_file_to_datas("train.csv")
これで、CSVファイルロードから「データ前処理」まで、2つの関数で済むようになりました
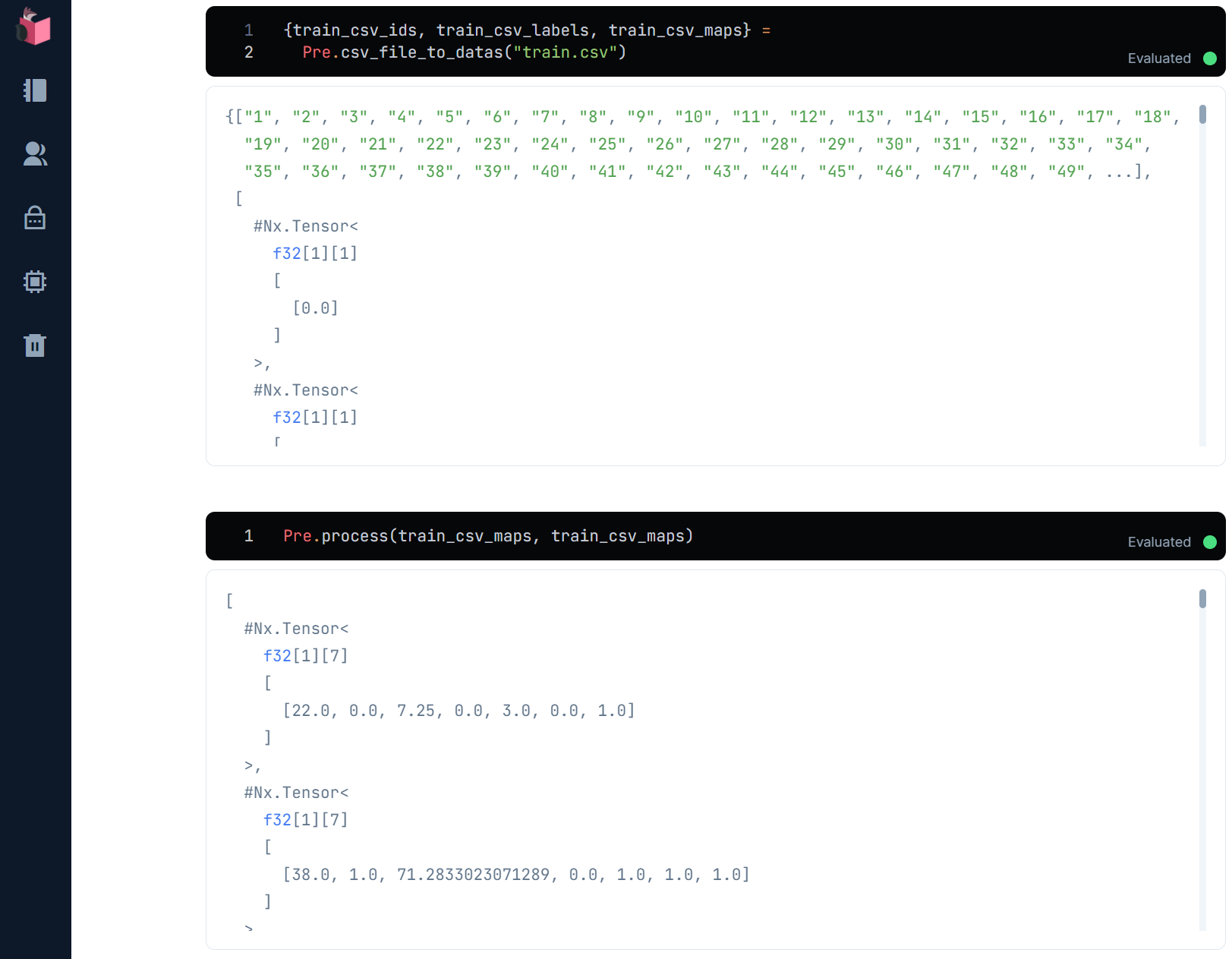
この2つの関数で、学習データだけで無く、検証データや未知データも処理できます
ⅱ)モデルの学習
紙面ボリュームの都合で、解説は今後のシリーズに預けます
ⅲ)検証データによる評価
紙面ボリュームの都合で、解説は今後のシリーズに預けます
ⅳ)未知データに対する予測
①未知データのロードと学習データの列差異の確認
未知データをロードし、学習データとの列差異を確認します
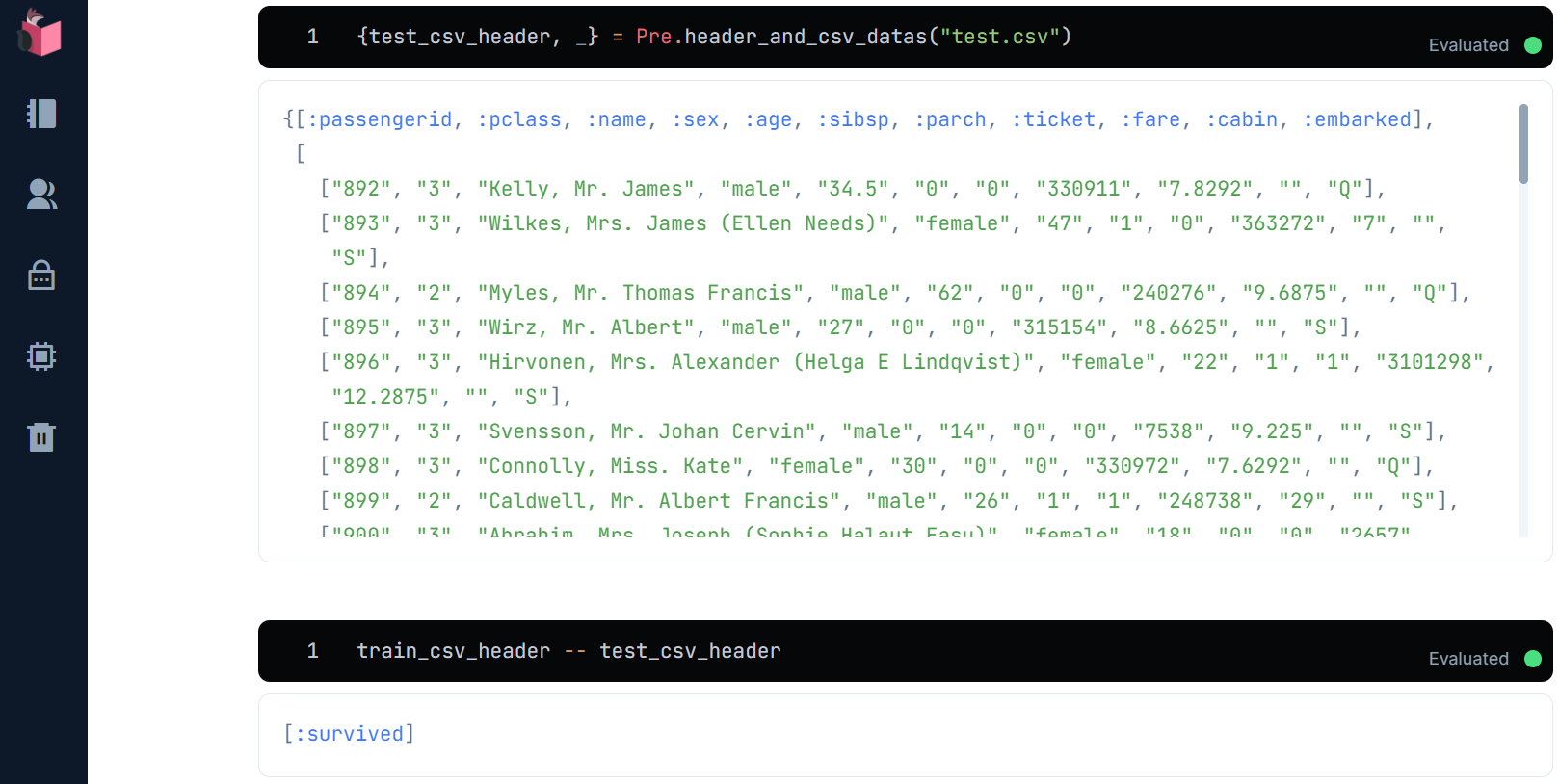
{test_csv_header, _} = Pre.header_and_csv_datas("test.csv")
train_csv_header -- test_csv_header
survivedが存在しません … これは、未知データにはラベルが無いのが当たり前だからです
これに対応するため、Pre.separateを以下のように改修します
defmodule Pre do
def count_missings(datas) do
…
def separate(datas, id, label) do
{
datas |> Enum.map(& Map.get(&1, id)),
+ if Map.has_key?(List.first(datas), label) do
+ datas |> Enum.map(& [[String.to_float("#{Map.get(&1, label)}.0")]] |> Nx.tensor)
+ else
+ nil
+ end,
datas |> Enum.map(& Map.drop(&1, [id, label]))
}
end
…
ラベルが無いCSVファイルのときは、ラベルとしてnilを返せれるようになりました
②空白値の確認
未知データに学習データと異なる欠損値が無いかチェックします
test_csv_maps
|> Pre.count_missings
すると、普通にありましたw … fareの欠損値補完は、現在の「データ前処理」に含まれていないため、改修が必要です

ここではいったん、fareは「0」で補完します
defmodule Pre do
def count_missings(datas) do
…
def for_dummies(datas) do
datas
|> drop([:cabin, :name, :ticket])
+ |> empty_replace(%{embarked: "S", age: "0", fare: "0"})
end
…
fareが「0」で補完されたことを確認できました
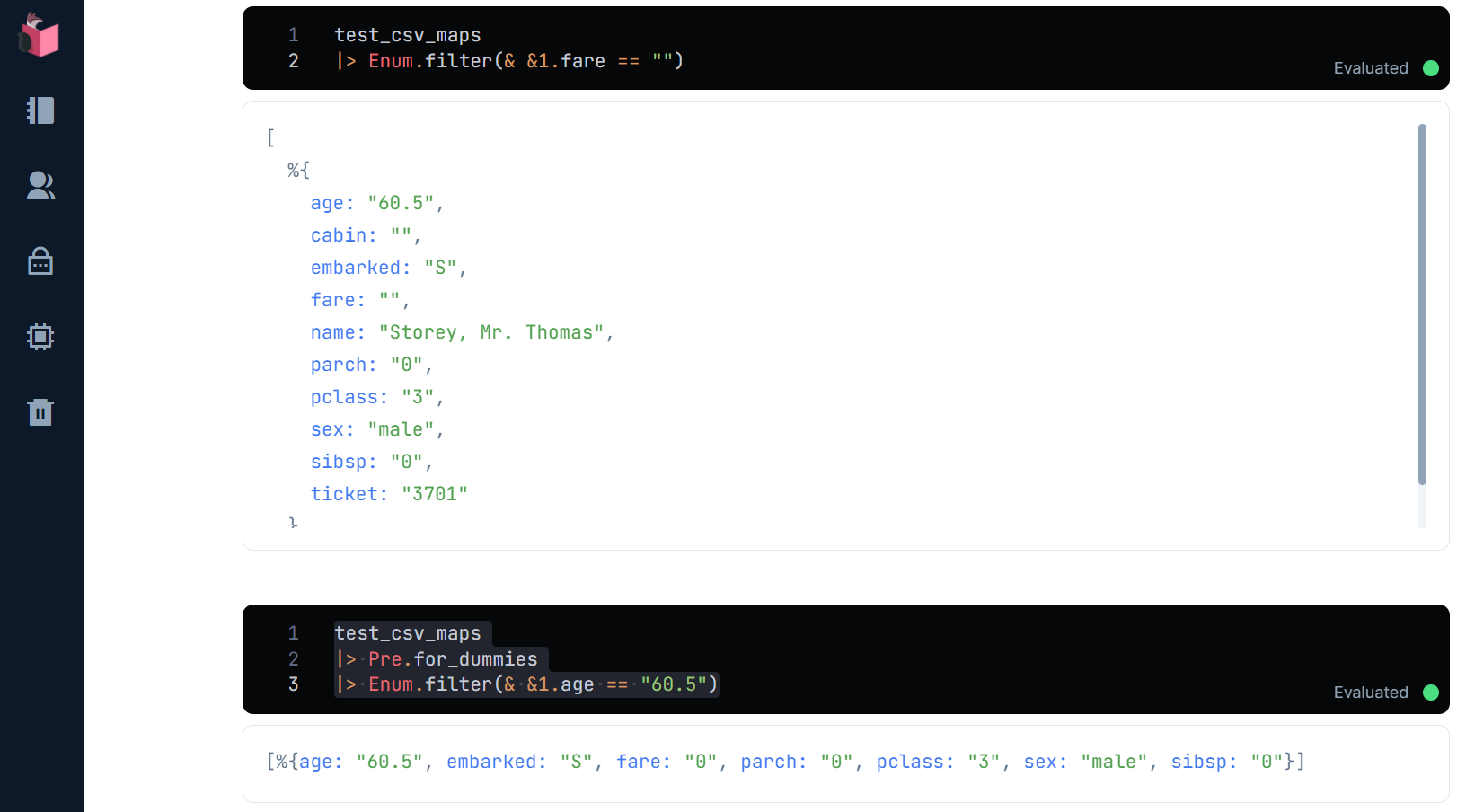
③未知データに対する予測の実施
未知データの「データ前処理」も済んだので、予測を実施してみます
ここで、Pre.processの第二引数に、学習データであるtrain_csv_mapsを指定することがポイントで、これは前述した「to_dummiesの実施時、検証データや未知データではカテゴリ値が網羅されていないケースへの対策として、学習データからカテゴリ値を拾うため」となります
また、test_csv_idsを予測結果リストとEnum.zipで連結し、ヘッダーも付けて、提出用CSVを作成します
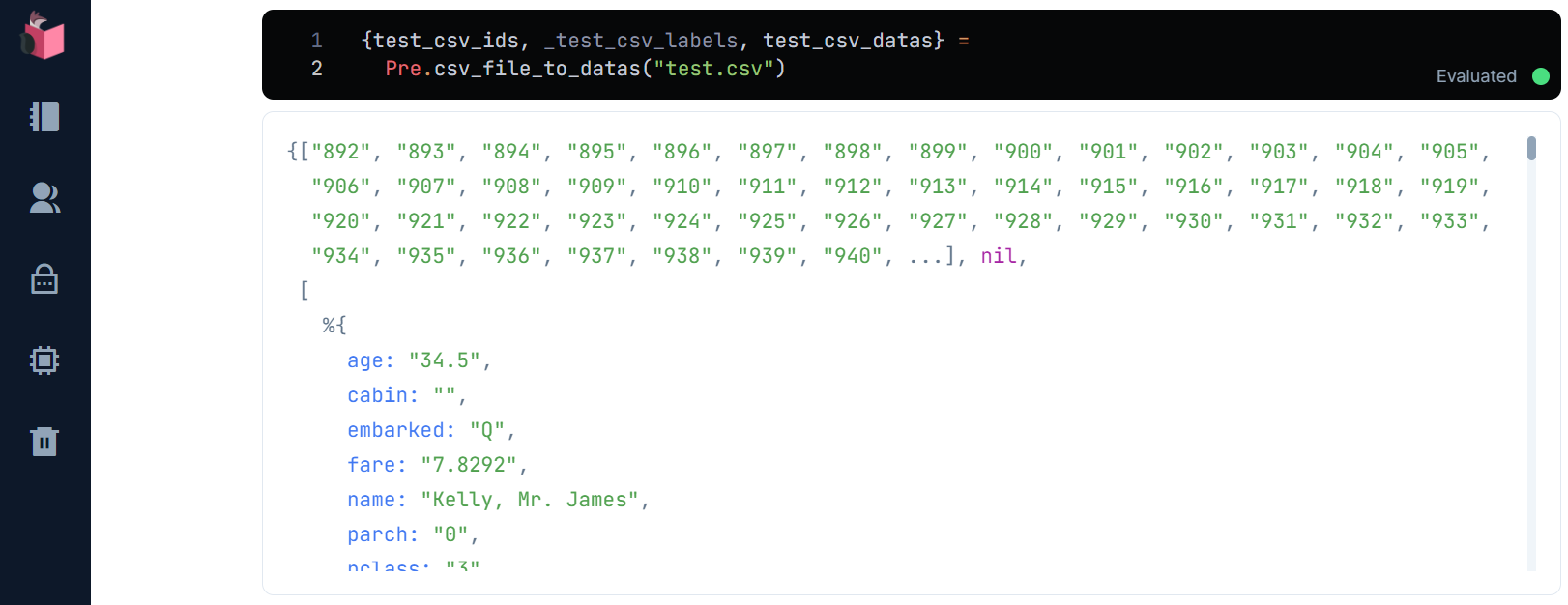
{test_csv_ids, _, test_csv_maps} = Pre.csv_file_to_datas("test.csv")
result = Pre.process(test_csv_maps, train_csv_maps)
|> Enum.map(& Axon.predict(model, trained_state, &1)
|> Nx.to_flat_list |> List.first |> round)
|> then(& Enum.zip(test_csv_ids, &1))
|> Enum.map(fn {k, v} -> [k, Integer.to_string(v)] end)
|> then(& [["PassengerId", "Survived"] | &1])
提出用CSVができました
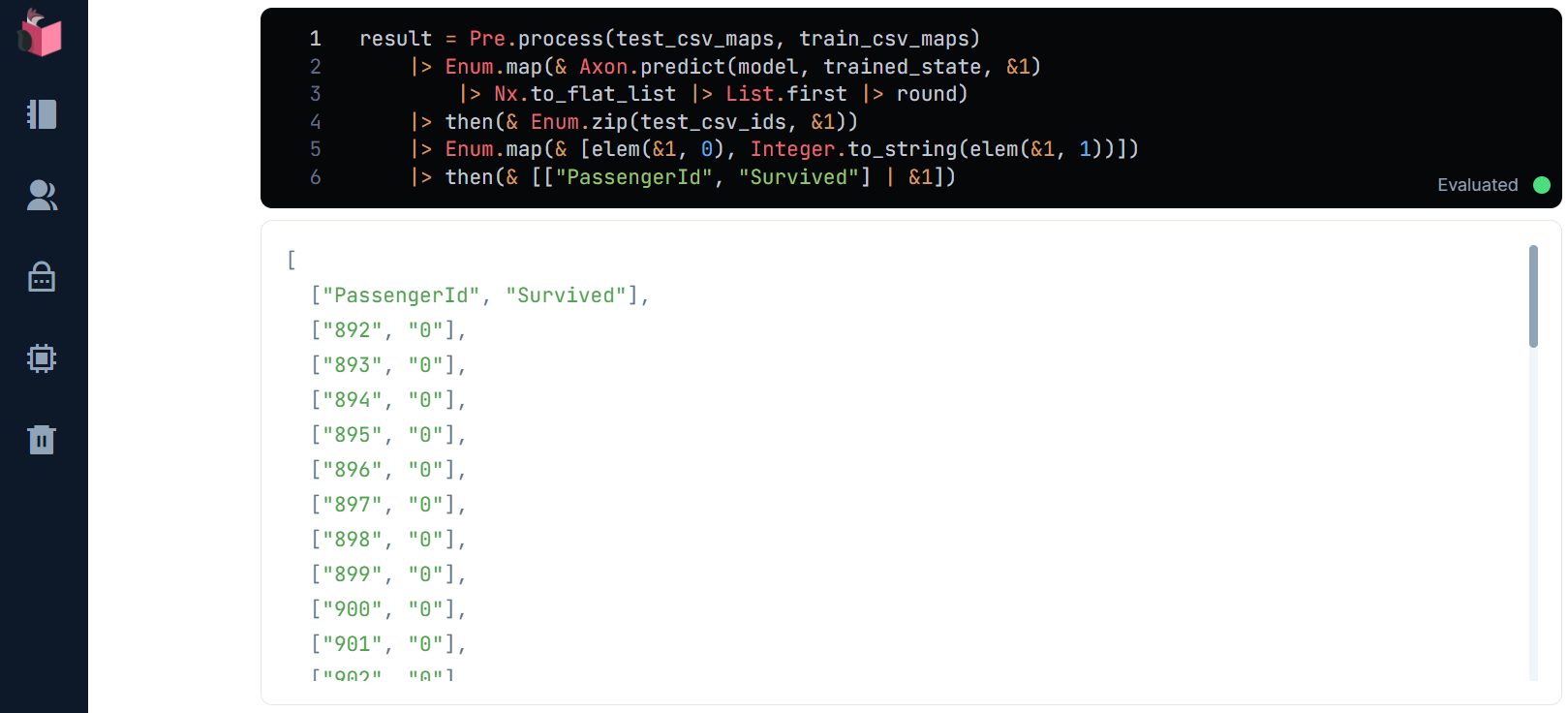
Kaggleに提出(submit)してみる
Kaggleへの提出用CSVファイルをresult.csvで生成します
result
|> CSV.encode
|> Enum.to_list
|> then(& File.write("result.csv", &1))
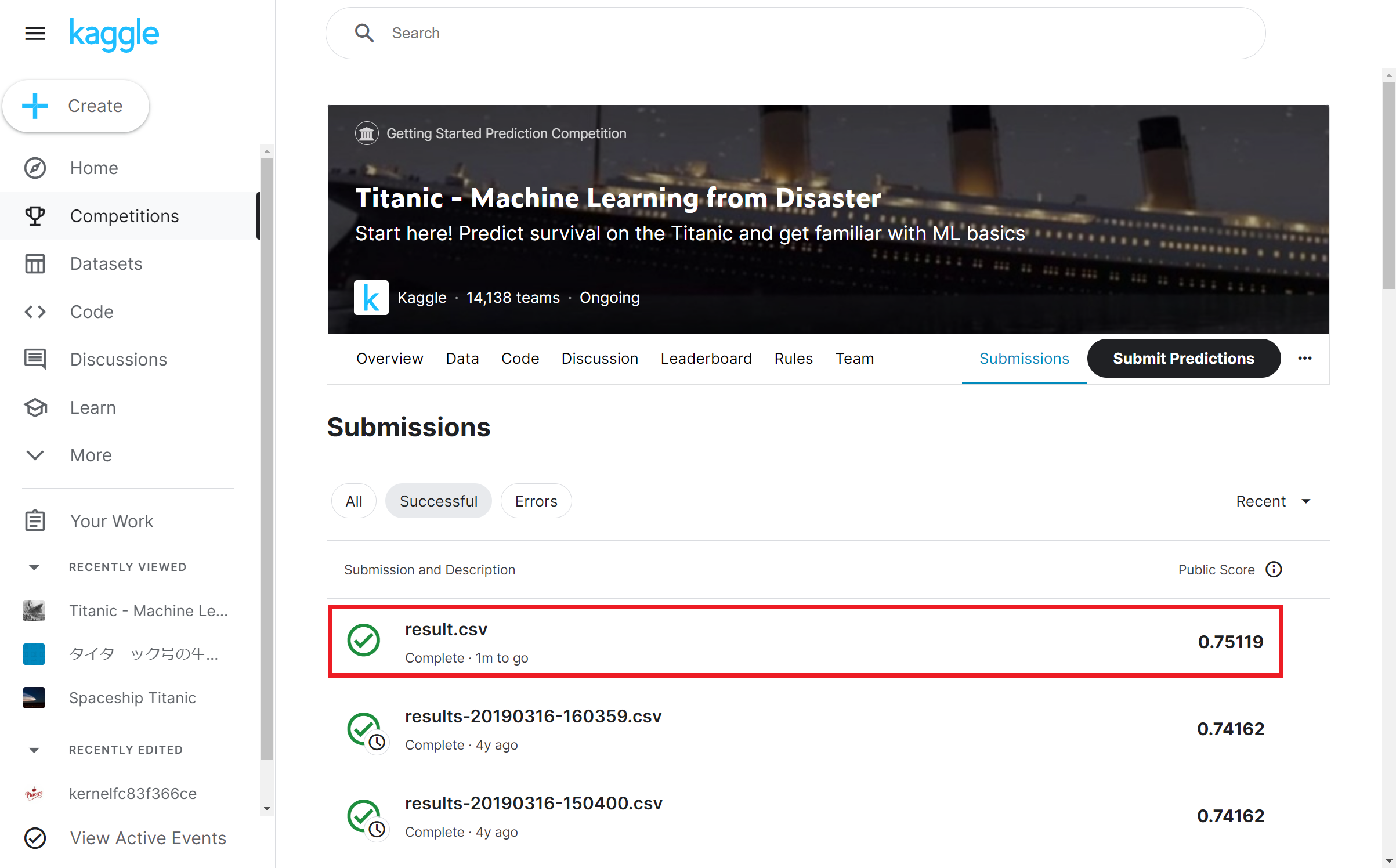
result.csvをKaggleの「Submit Predictions」ボタンをクリックして、アップロードします
アップロードが完了すると、「submit」ボタンがクリック可能になるので、クリックします
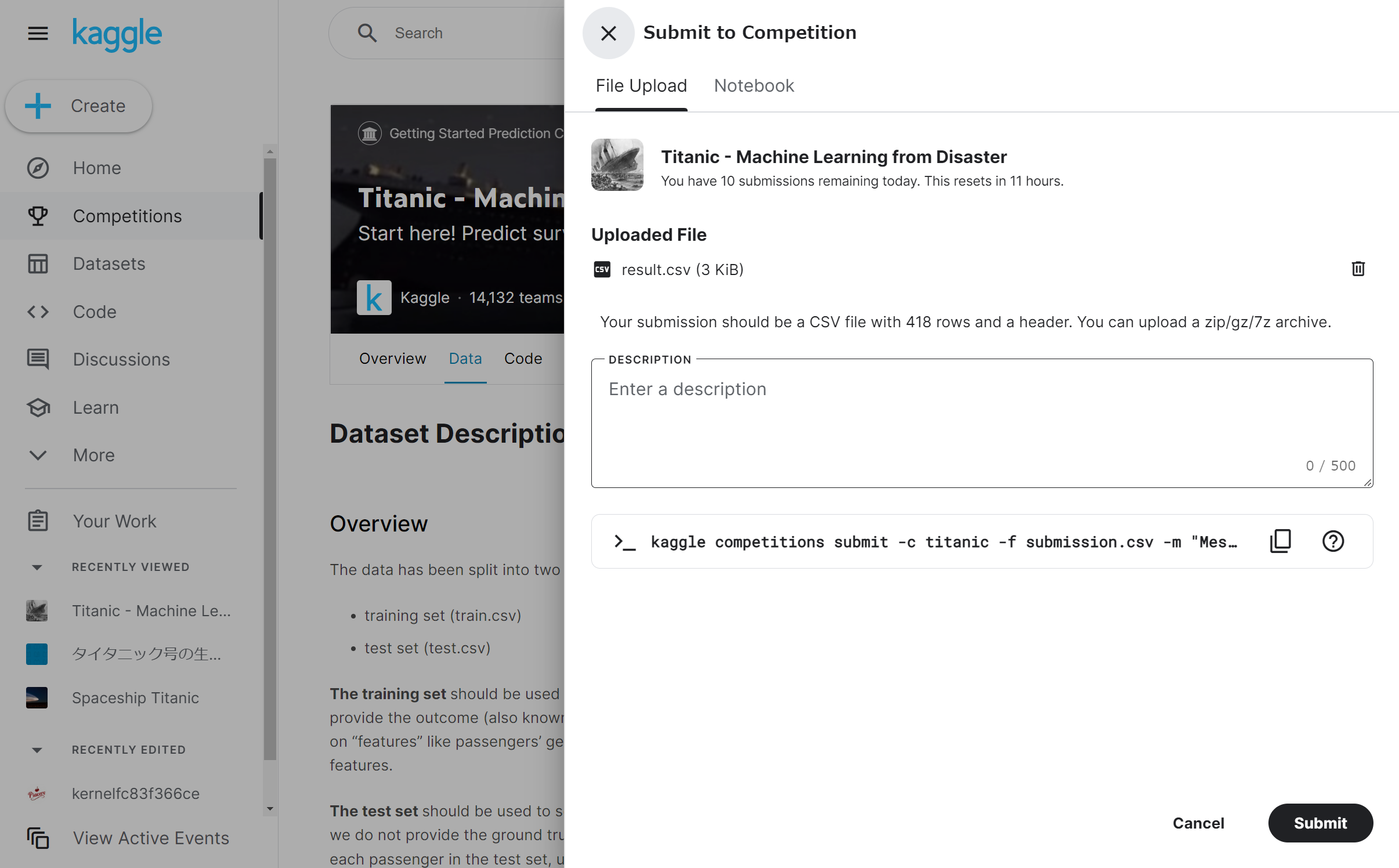
提出した結果の正解率が表示されます … 「75.119%」だそうです
全体ランキングで何位か確認するには、「Leaderboard」タブをクリックし、「Jump to your leaderboard position」ボタンをクリックすると、下図のように順位にジャンプします … 12,292位だそうです ![]()

本講義で実施した範囲は「データ前処理」の基礎編だったため、非常に低い順位でしたが、次回でこれを改善します
今回内容が難しいと感じた方へ
下記コミュニティのイベントで本シリーズ内容の解説やハンズオンをしていますので、ご利用ください
終わり
今回は、Kaggleを題材に「データ前処理」の基礎編をお届けしました
Elixir標準の関数群だけでも、充分に「データ前処理」がこなせるということが伝われば幸いです
次回は、Kaggleの順位を上げるべく、「統計」と「EDA」による「データ前処理」の改善を行います
主催/運営しているElixirコミュニティ紹介
4. LiveView JP : A place to mob-program in LiveView, LiveBook+Nx+Axon, and elixir-desktop
5. Neos.ex : A place to connecting Elixir and NeosVR to create a new world
Elixir生誕10周年を一緒にお祝いしませんか?
12/21(水)19:30~21:00、「過去LTいただいた方々への感謝祭」をテーマに、リモート忘年会を開催
「Elixir生誕10周年」に対するコメントや、今/昔のElixirの進化を聞けるチャンスですので、お見逃し無くッ
※カンパイスタートの会ですので、お酒 or ソフトドリンク、お菓子 or ご飯をお忘れなく
※Zoom接続できれば、本人でも、2Dアバター/3D(VR)アバターでも、お好きな姿でご参加OK
日々アップデートされる、Elixir生誕10周年をお祝いするコラム群についての解説もあります(本コラムも、「第3弾「Elixir/Livebook+NxでPythonっぽくAI・ML」に追加しています)
明日は、@a_utsuki さんで「Elixirでつくりたいもの」です