この記事は、Elixir Advent Calendar 2022 5の14日目です
昨日は、@RyoWakabayashi さんで「Elixir の dbg を Livebook で遊び倒す」でした
piacere です、ご覧いただいてありがとございます ![]()
この2年間で、Elixirの機械学習環境が凄まじく発展し、プロダクションに実戦投入しても問題無いフェーズに入ったので、「Eixirで機械学習に初挑戦」をテーマにシリーズコラムをお届けします
入門者向けに「機械学習とは何か?」や、機械学習の中で出てくる数々のキーワード解説もしていきますので、AI・MLの知識が無いWeb開発者/IoT開発者の方や、PythonでAI・MLを学んだけどイマイチ入らなかった方、Elixir経験者だけどNx/Axon/Livebook等の新テクノロジーに追いつけていない方にも、スッと入りやすい内容としてまとめていこうと思います
今回は、前回学習まで解説した機械学習コード解説の続きで、「予測」の可視化と「精度」の変化、そして「学習過程グラフ」の読み方について学びます
なお、本コラムに対し、更に分かりやすい解説を @RyoWakabayashi さんが書いてくれていますので、本コラムを読んでいて難しいなぁ…と感じた方は、コチラをご参考に理解を深めてください
 Elixir Advent Calendar 総勢16本、熱い冬ヽ(=´▽`=)ノ
Elixir Advent Calendar 総勢16本、熱い冬ヽ(=´▽`=)ノ
例年に無い盛り上がりを見せています … 応援/購読よろしくお願いします ![]()
https://qiita.com/advent-calendar/2022/elixir
本シリーズの目次
①:基礎知識とLivebook+Nx+Axonによる機械学習入門
|> ②:機械学習コードの解説と「学習データの可視化」「学習過程のアニメ化」
|> ③:「予測」の可視化と「精度」の変化要因、「学習過程グラフ」の読み方
|> ④:データ処理に強いElixirでKaggle挑戦(前編)…「データ前処理」基礎編
|> ⑤:データ処理に強いElixirでKaggle挑戦(後編)…「統計」と「EDA」でKaggleに挑む
|> ⑥:いま、Elixir AI・MLで何が出来る? → Elixirのメリット→2023年に攻略する領域
本コラムの検証環境
本コラムは、以下環境で検証しています(恐らくUbuntu実機やMacでも動きます)
- Windows 10 + WSL2 + Ubuntu 22.04 ※最新版のインストール手順はコチラ
- Elixir 1.14.2 ※最新版のインストール手順はコチラ
- Livebook 0.8.0
本コラムで解説するコード範囲
今回、解説するコードの範囲は、「ⅳ)未知データに対する予測」になります

各コードについて解説
今回範囲の各コードについて解説していきます
ⅳ)未知データによる学習済みモデルの評価
未知データで、学習済みモデルでの予測を行い、モデルの精度を評価します
Axon.predict(model, trained_state, %{"input1" => Nx.tensor([[0]]), "input2" => Nx.tensor([[0]])})
Axon.predict(model, trained_state, %{"input1" => Nx.tensor([[0]]), "input2" => Nx.tensor([[1]])})
Axon.predict(model, trained_state, %{"input1" => Nx.tensor([[1]]), "input2" => Nx.tensor([[0]])})
Axon.predict(model, trained_state, %{"input1" => Nx.tensor([[1]]), "input2" => Nx.tensor([[1]])})
OR予測の結果を忘れてしまった方は、前々回の下記講義を見直してください
ⅳ-1.学習済みモデルによる予測
前回、解説した通り、modelには構築したモデル、trained_stateには学習結果状態が入っており、これらを使って、学習済みモデルでの予測を行うのが、Axon.predictです
予測対象となるパラメータは、このモデルが2つの2次元行列をマップで受け取るので、%{"input1" => Nx.tensor([[0]]), "input2" => Nx.tensor([[0]])}のように指定します
Axon.predict(model, trained_state, %{"input1" => Nx.tensor([[0]]), "input2" => Nx.tensor([[0]])})
予測結果は、下記の通り、2次元行列の中に入っており、「0.5」以上なら「1」、「0.5」未満なら「0」という予測となりますが、それなりに「正解率(Accuracy)」が高まっていると、「0」に近い「0.1」以下や「1」に近い「0.9」以上が返ってきます

なお、デジタルな演算を行っていれば、「0」「1」ピッタリの値が返ってくる訳ですが、機械学習では、その予測となる「確率」を求める都合上、ピッタリの値が返ることはありません
ⅳ-2.予測の可視化
実際に、どのような予測が返ってきているかを、複数回の予測を可視化することで確認してみましょう
基本は、前回、実施した学習データの可視化と同じ要領で、予測結果を{x: nnn, y: mmm}という形式でまとめ、[Smart]Cellでチャート化すれば可視化できます
学習済みモデルは、同じ入力に対しては全く同じ出力を返すため、毎回、学習し直すことで、予測が同じ出力にならないようにし、それでも同じような予測傾向を返すことを確認します
X座標は、重ならないよう揺らしており、更に入力「0」「1」はX座標「0.1」付近に、入力「1」「0」はX座標「0.9」付近にズラして、見やすくしています
なお下記コードが難解に思えるときは理解しなくてもOKなので、実行結果を見ることで理解していきましょう
epochs = 5
predicts = 1..5
|> Enum.map(fn _ ->
trained_state =
model
|> Axon.Loop.trainer(:binary_cross_entropy, :sgd)
|> Axon.Loop.metric(:accuracy, "Accuracy")
|> Axon.Loop.run(train_datas, %{}, epochs: epochs, iteration: 1000, compiler: EXLA)
[
%{
x: 0 + Enum.random(0..3) / 100,
y: Axon.predict(model, trained_state,
%{"input1" => Nx.tensor([[0]]), "input2" => Nx.tensor([[0]])})
|> Nx.to_flat_list
|> List.first
},
%{
x: 0.1 + Enum.random(0..3) / 100,
y: Axon.predict(model, trained_state,
%{"input1" => Nx.tensor([[0]]), "input2" => Nx.tensor([[1]])})
|> Nx.to_flat_list
|> List.first
},
%{
x: 0.9 - Enum.random(0..3) / 100,
y: Axon.predict(model, trained_state,
%{"input1" => Nx.tensor([[1]]), "input2" => Nx.tensor([[0]])})
|> Nx.to_flat_list
|> List.first
},
%{
x: 1 - Enum.random(0..3) / 100,
y: Axon.predict(model, trained_state,
%{"input1" => Nx.tensor([[1]]), "input2" => Nx.tensor([[1]])})
|> Nx.to_flat_list
|> List.first
}
]
end)
|> List.flatten
[Smart]Cellから「Chart」で追加してください(WIDTH/HEIGHTは適宜、調整してください)

すると、下図のようなグラフが表示されます(点の集まりを分かりやすくする赤丸と、0.5の赤線は、後付けで付けています)

入力「0」「0」の場合、予測は「0.13」付近に集中しています
同様に、入力「0」「1」は「1.0」付近に、入力「1」「0」、入力「1」「1」も「1.0」付近に予測が集中しています
「0.5」以上なら「1」、「0.5」未満なら「0」という予測となるため、下記ORの条件を満たしています
| 入力1 | 入力2 | 出力 | 予測 | 予測を0.5を堺に0/1に分類 |
|---|---|---|---|---|
| 0 | 0 | 0 | ≒0.13 (< 0.5) | 0 |
| 0 | 1 | 1 | ≒0.99 (> 0.5) | 1 |
| 1 | 0 | 1 | ≒0.99 (> 0.5) | 1 |
| 1 | 1 | 1 | ≒1 (> 0.5) | 1 |
ⅳ-3.学習回数を下げてみる
epochsを5回から、2回に下げると、どうなるでしょう?
上記コードの最上部epochsを2に変更して、再度、実行してみます
epochs = 2
…
すると5回のときよりも、点の集中がバラつき、「0」「0」の予測が「0.5」に近づき、だいぶ怪しくなりました

では、epochsを1回に下げると…?
ナント、「0」「0」の予測の一部が「0.5」以上となってしまい、「0」では無く、「1」で予測されるようになってしまいました…

学習回数が、予測の精度に大きく影響することがお分かりになったでしょうか?
前回お伝えした通り、「学習」とは、「活性化関数」の通過/非活性の度合いの調整、つまり「重み」の更新によって行われるのですが、学習回数が少ないと、「重み」を更新し切れず、精度が下がってしまうのです
ⅳ-4.精度に影響する「最適化アルゴリズム」
精度は、学習回数によってのみ変動するのでしょうか?
ここで思い出して欲しいのが、前回、コード解説中で紹介した「最適化アルゴリズム」です
今回のOR学習では、「SGD(stochastic gradient descent:確率的勾配降下法)」というアルゴリズムを使っていますが、SGDによる「重み」の更新は、「学習率(LR:Learning Rate)」というパラメータによって、更新完了までの速さ/遅さ(同時に雑さ/緻密さ)が変えられます
ここでは、「学習率」を「0.001」(:sgd指定はAxon.Optimizers.sgd(0.001)と指定したのと同じ)から、「0.05」と50倍に引き上げます
epochs = 1
predicts = 1..5
|> Enum.map(fn _ ->
trained_state =
model
|> Axon.Loop.trainer(:binary_cross_entropy, Axon.Optimizers.sgd(0.05))
…
Axon.Optimizers.sgdの詳細は、下記Axonリファレンスに記載されていますが、パラメータにあるmomentumとnesterovも、「学習率」とは異なるアプローチで更新速度を変えられます
結果を見てみると、学習回数が1回にも関わらず、点の集中のバラつきも無くなれば、「0」「0」の予測の一部の予測がおかしくなることも無くなりました

この結果だけを見ると、「学習率」は上げた方が良さそうに思えますが、「学習率」は、更新完了までの速さ/遅さを変えるだけで無く、速くすればするほど、雑な更新になり、遅くすればするほど、丁寧な更新になるため、このトレードオフを学習回数と共に調整することが、機械学習を効率良く進めるコツにもなります
「最適化アルゴリズム」が、どのように更新完了に向かうかを把握することで、より最適なアルゴリズムの選定と調整が可能となります
こうした、人力で調整するパラメータのことを「ハイパーパラメータ」と呼びます
他にも、ハイパーパラメータはは下記があります
- 学習回数(epochs)
- ニューラルネットワークの層数
- 1層あたりのニューロン数
SGDがどのように更新完了に向かうかの把握には、下記コラムがオススメです
ⅳ-5.学習時のグラフの読み方
ここまでの知識を得た上で、前回、学習過程のアニメーション化を行った際に作った学習過程のグラフが読めるようになります

このグラフは、横軸であるinput1と、縦軸であるinput2の組み合わせが、青線を堺に、どちらにあるかで、予測が「0」となるか、「1」となるかを意味します
たとえば、下図の補助線の通り、input1が「0.2」だった場合、input2は「0.62」未満であれば「0」、「0.62」以上であれば「1」と予測が返ってきます

つまり、こういう分類になります

これは、第一回講義で見た、「犬」と「猫」の分類にソックリです … 違いは、直線で分類されるか、曲線で分類されるかの違いだけです(「0」と「1」は逆ですが)
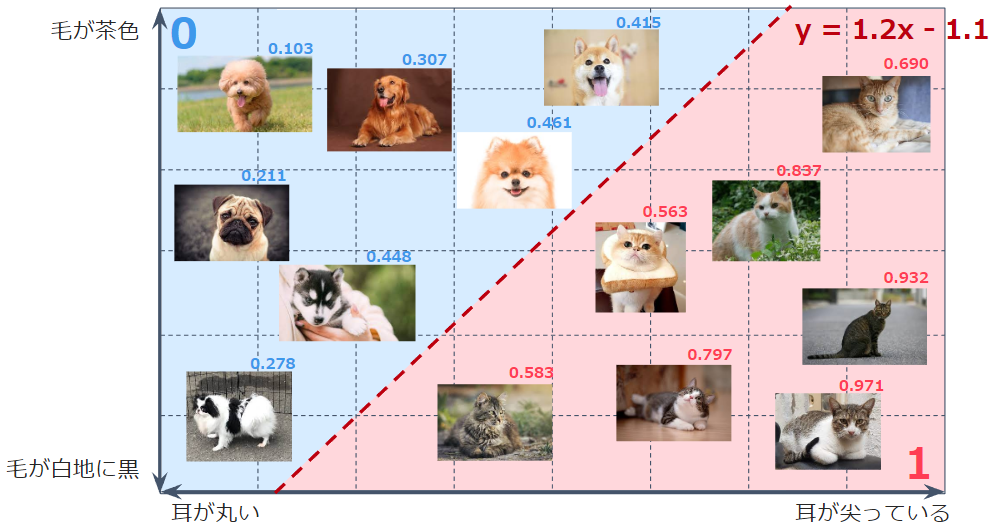
なお、直線で分類されるものを「線形分類」と呼び、非直線で分類されるものを「非線形分類」と呼びます
ディープラーニングを含むニューラルネットワークは、基本的に「非線形分類(ないしは非線形回帰)」を行います
今回内容が難しいと感じた方へ
下記コミュニティのイベントで本シリーズ内容の解説やハンズオンをしていますので、ご利用ください
今回コラムをマスターすると…
下記Elixirディープラーニングのコラムを読みこなすことができると思います … 基本的な構造は同じだからです
Elixirでディープラーニング①:手書き文字識別(MNIST)をLivebook+Axonで
|> ElixirのみでディープラーニングOnnx編:Livebook+AxonOnnxでResnet画像識別
終わり
今回は、「予測」の可視化と、「学習回数」や「学習率」による「精度」の変化、そして「学習グラフ」の読み方を扱いました
学習済みモデルの予測が、どのように出力され、「精度」がどのような要因で変化し、非線形分類によって二値分類が実現していることが分かったかと思います
だいぶ機械学習の正体が見えてきたのでは無いでしょうか?
主催/運営しているElixirコミュニティ紹介
4. LiveView JP : A place to mob-program in LiveView, LiveBook+Nx+Axon, and elixir-desktop
5. Neos.ex : A place to connecting Elixir and NeosVR to create a new world
Elixir生誕10周年を一緒にお祝いしませんか?
12/21(水)19:30~21:00、「過去LTいただいた方々への感謝祭」をテーマに、リモート忘年会を開催
「Elixir生誕10周年」に対するコメントや、今/昔のElixirの進化を聞けるチャンスですので、お見逃し無くッ
※カンパイスタートの会ですので、お酒 or ソフトドリンク、お菓子 or ご飯をお忘れなく
※Zoom接続できれば、本人でも、2Dアバター/3D(VR)アバターでも、お好きな姿でご参加OK
日々アップデートされる、Elixir生誕10周年をお祝いするコラム群についての解説もあります(本コラムも、「第3弾「Elixir/Livebook+NxでPythonっぽくAI・ML」に追加しています)
明日は、@the_haigo さんで「EvisionでDNN.ClassificationModelを使ってクラス分類をする」です