ElixirImp/fukuoka.ex/kokura.exとLiveView JPの piacere です、ご覧いただいてありがとございます ![]()
今回は、ElixirでResnet Onnxモデルを使った画像識別MLをLivebook上で開発します

ResNetによる画像処理やCNNの基礎的なことを学べるコラムにもなっているため、Python/Elixir問わず、画像処理の基礎を学びたい方の入門編コラムでもありますので、これまでAI・MLやディープラーニングを学ぶ機会を逃した方は、このコラムを活かしてください
なお、Elixirにて機械学習/ディープラーニングするツール & ライブラリについては下記をご参考ください
本コラムの検証環境
本コラムは、以下環境で検証しています(Windows WSL2で実施していますが、Windowsネイティブや実機のUbuntu 18.04、Macでも動作する想定です)
- Windows 11+WSL2 Ubuntu 18.04
- Elixir 1.13.4 on WSL2 Ubuntu ※最新版のインストール手順はコチラ
- Livebook 0.6.3 ※最新版のインストール手順はコチラ
ResNetの概要
ResNet(Residual Network)は、「ImageNet」と呼ばれる、1,400万枚以上のカラー写真の教師ラベル付きデータベースサイトで学習した、1,000種類の画像を分類できる学習済みモデルです
2015年、Microsoft Researchによって考案され、「ILSVRC(ImageNet Large Scale Visual Recognition Challenge)」というImageNet画像データセットを識別するコンテストで有償したモデルです
MNISTと同様の多クラス分類によって、1,000種類の各画像にどの程度マッチするかを識別します
学習済みモデルのため、モデルを入手すれば、すぐ利用できる点が便利です
また、このモデルをベースに「転移学習」を行うことで、別の教師ラベル群と紐付けられた画像識別も可能です(これはどこかの回でデモしたいと思います)
ResNet18のアーキテクチャ
今回、使用するResNet18は、下図のような構成を持つモデルで、224(横ピクセル数) x 224(縦ピクセル数) x 3(チャネル数)の画像をインプットとし、1,000種類の各画像との多クラス分類を行います

10層のCNN(Convolutional Neural Network:畳み込みニューラルネットワーク)層とプーリング層、全結合層の全18層から構成されます
CNNは、画像識別においてポピュラーなアルゴリズムで、以下2つのパートで構成されます
①畳み込み層
②プーリング層
畳み込み層は、画像内を縦3ピクセル x 横3ピクセルなどの特定サイズのブロック(カーネルと呼ばれます)でフィルタを施す畳み込み演算を、左上から右下まで1ピクセルずつズラしながら行うことで、特徴抽出を行います
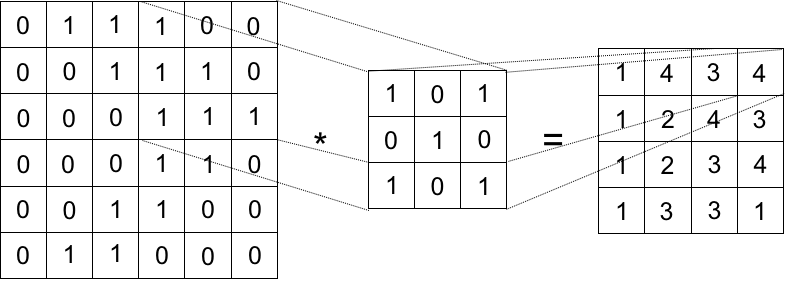
なお、アーキテクチャの図に書かれている「stride(ストライド)」とは、この畳み込み演算を1ピクセルずつズラすのでは無く、数ピクセルまとめてズラすことを指し、図の記載では、2ピクセルずつズラすことで、大きな画像からの特徴抽出結果をより小さなサイズとすることで高速化したり、大雑把な特徴抽出を行う効果があります(ResNetの前半の層で多用されているのはこの理由)
プーリング層は、畳み込み層で特徴抽出済みのデータに対して、プーリング用カーネル(畳み込み層とはサイズが異なることがある)を1ピクセルのデータへと圧縮します
ResNetでは、圧縮方法として、「Average Pooling」というカーネル内の値の平均を取る手法を用います(他には「Max Pooling」と言う画像内のブロックの最大を取る手法もメジャーです)
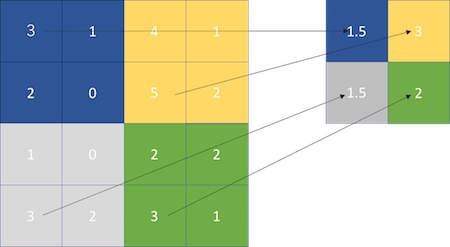
全結合層は、上記の層で特徴抽出された結果を元に予測を行う層で、内部的にソフトマックス関数による多クラス分類が行われる点は、MNISTと同じ仕組みです
Onnxの概要
Onnx(Open Neural Network Exchange)は、機械学習モデルを共通化するためのフォーマットです
これを利用すると、TensorFlow/KerasやPyTorchで学習したモデルを、別の推論エンジン/ライブラリで利用することが可能となります
ElixirのAxonOnnxも、学習済みモデルを読み込み、Axon上のニューラルネットワークとして利用します
ちなみにOnnx化したモデルは、モデル学習時よりも、推論が高速化されるといったメリットがあります
最終的なコード
下記のコードのみでResNet Onnxモデルでの画像識別が実現できます(以降の節で各パートの解説をします)
Mix.install([
{:exla, "~> 0.2"},
{:axon_onnx, "~> 0.1"},
{:stb_image, "~> 0.5"},
{:download, "~> 0.0"},
{:jason, "~> 1.3"},
{:kino, "~> 0.6"},
])
EXLA.set_as_nx_default([:tpu, :cuda, :rocm, :host])
File.rm("imagenet_class_index.json")
classes =
Download.from("https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json")
|> elem(1)
|> File.read!
|> Jason.decode!
File.rm("resnet18-v1-7.onnx")
{model, params} =
Download.from("https://media.githubusercontent.com/media/onnx/models/main/vision/classification/resnet/model/resnet18-v1-7.onnx")
|> elem(1)
|> AxonOnnx.import
File.rm("greatwhiteshark_157273892.jpg")
data =
Download.from("https://www.collinsdictionary.com/images/full/greatwhiteshark_157273892.jpg")
|> elem(1)
|> File.read!
Kino.Image.new(data, :jpeg)
nx_image = data
|> StbImage.read_binary!
|> StbImage.resize(224, 224)
|> StbImage.to_nx
nx_channels = nx_image
|> Nx.axis_size(2)
tensor =
case nx_channels do
3 -> nx_image
4 -> Nx.slice(nx_image, [0, 0, 0], [224, 224, 3])
end
|> Nx.divide(255)
|> Nx.subtract(Nx.tensor([0.485, 0.456, 0.406]))
|> Nx.divide(Nx.tensor([0.229, 0.224, 0.225]))
|> Nx.transpose
|> Nx.new_axis(0)
Axon.predict(model, params, tensor)
|> Nx.flatten
|> Nx.argsort
|> Nx.reverse
|> Nx.slice([0], [5])
|> Nx.to_flat_list
|> Enum.with_index
|> Enum.map(fn {no, index} -> {index, Map.get(classes, to_string(no))} end)
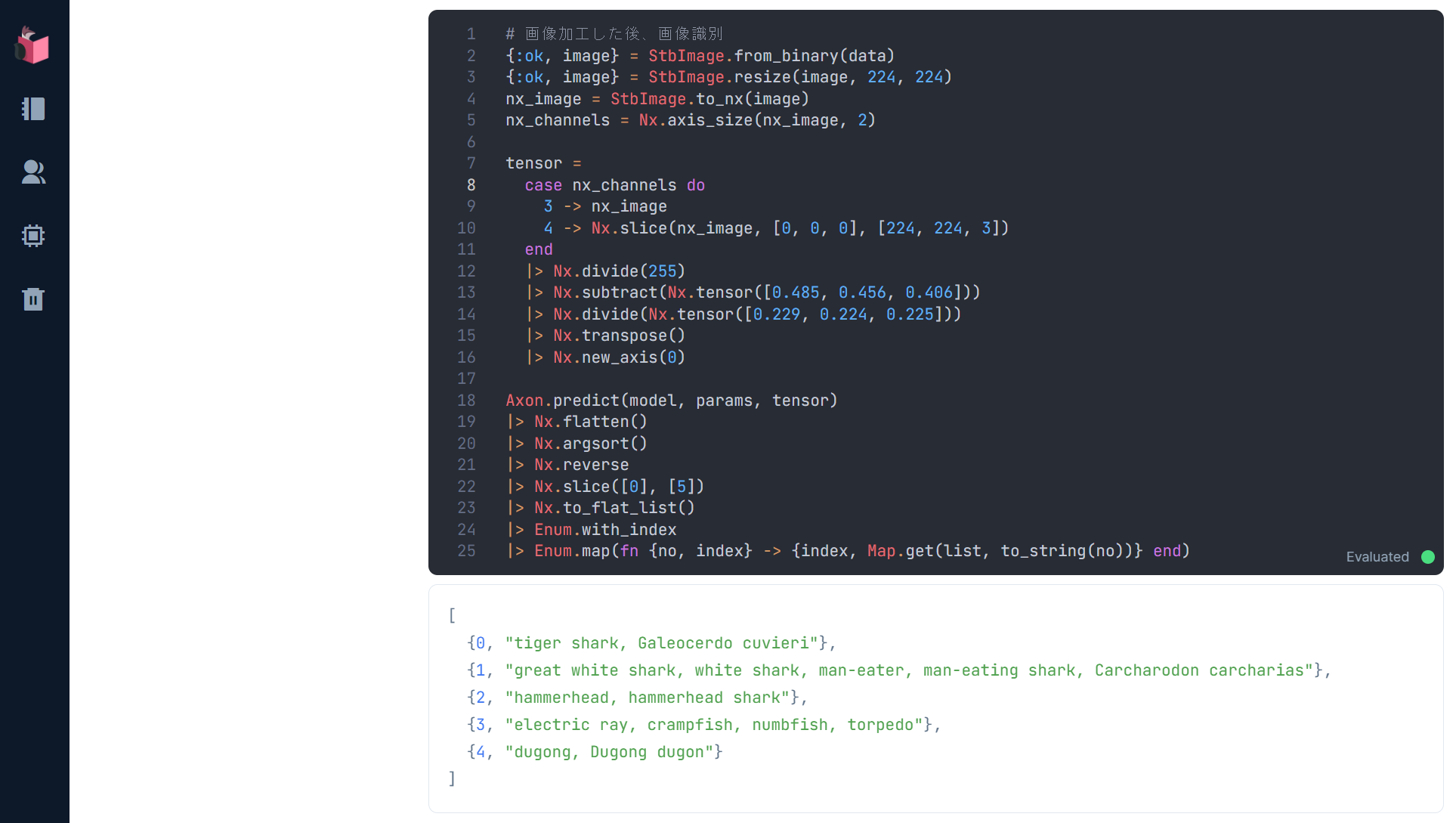
実行結果は、以下の通りで、対象画像がどんな種類の画像かが識別されています
正確には、ResNetの学習元となっているImageNetにある1,000種類の画像のいずれかとして識別されたかの結果が出力されています
各パートについて解説
①ライブラリのロード
Livebookで下記を実行し、必要ライブラリをロードしてください(Livebookが初めての方は、基本的な操作をこちらのコラムで学べます)
新しいLivebookだと、下図のようなライブラリロード用のエリアが追加されているので、この中で実行してください(KinoVegaLiteやKinoDBなどをプラグインしたときも、ココに追加されます)

Mix.install([
{:exla, "~> 0.2"},
{:axon_onnx, "~> 0.1"},
{:stb_image, "~> 0.5"},
{:download, "~> 0.0"},
{:jason, "~> 1.3"},
{:kino, "~> 0.6"},
])
なお、KinoVegaLiteやKinoDBをロードする際は、Kino単独のロードをしなくても、Livebook上での画像やグラフの表示が可能になります
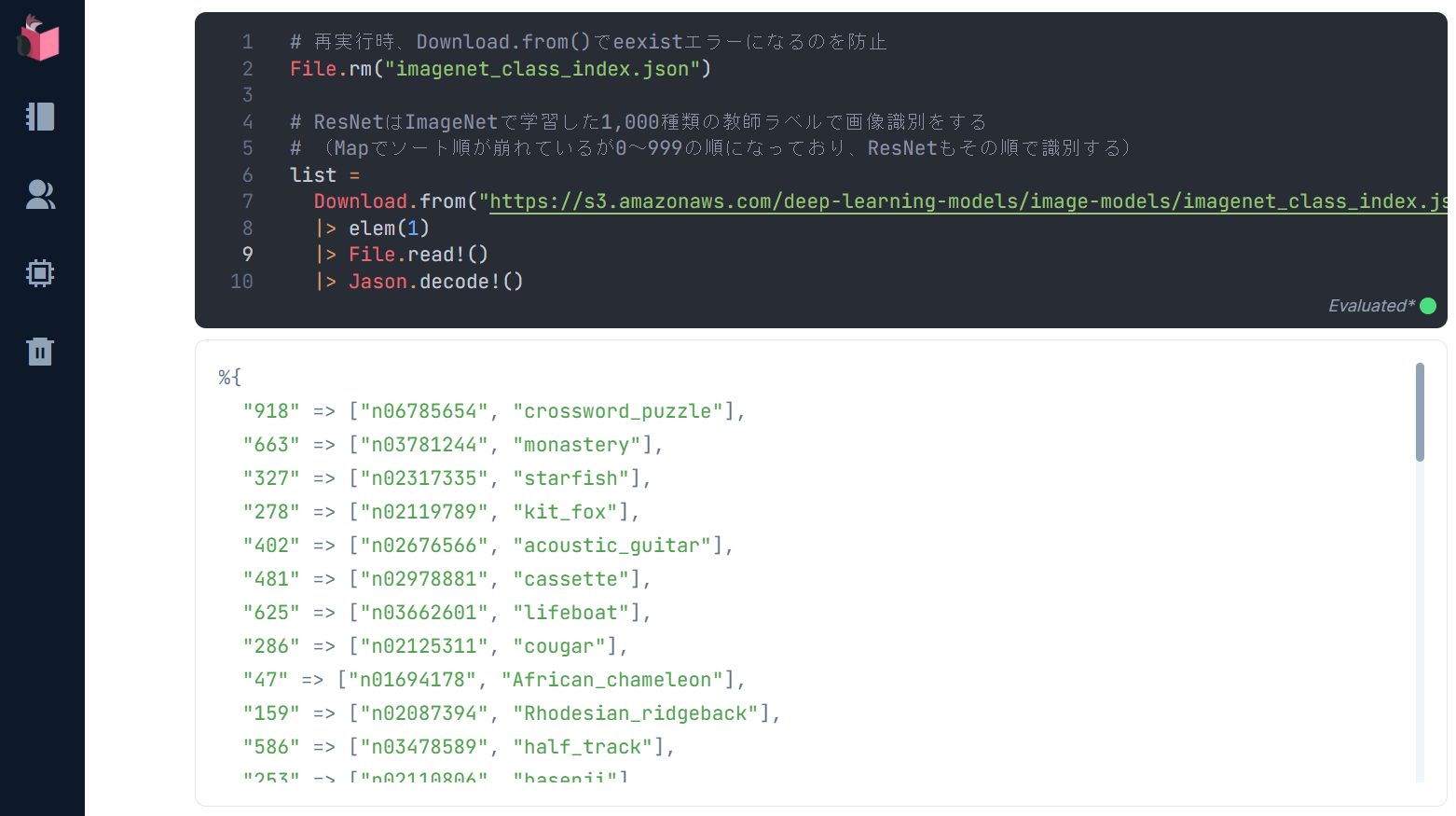
②ImageNetの教師ラベルを準備
ResNetで画像識別すると、1,000種類の画像それぞれに、どの程度マッチしたかが返ってくるため、各画像の教師ラベルを準備することで、どの画像にマッチしているかを人が見て分かる表示ができるようになります
# 再実行時、Download.from()でeexistエラーになるのを防止
File.rm("imagenet_class_index.json")
# ResNetはImageNetで学習した1,000種類の教師ラベルで画像識別をする
# (Mapでソート順が崩れているが0~999の順になっており、ResNetもその順で識別する)
classes =
Download.from("https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json")
|> elem(1)
|> File.read!
|> Jason.decode!
実行結果は以下の通りです(なお、Mapでソート順が崩れていますが、0~999の順で定義されており、ResNetもその順で識別結果を返します)
③Resnet Onnxモデルを準備
Resnet Onnxモデルは、ネット上に保存されているので、それをダウンロードして使います
なお最終的なコードでは、パイプを使うことで、変数 resnet を省略していますが、ここでは説明をカンタンにするために変数化しています
# 再実行時、Download.from()でeexistエラーになるのを防止
File.rm("resnet18-v1-7.onnx")
# ResNet Onnxモデルをダウンロード(20秒程度かかります)
resnet =
Download.from("https://media.githubusercontent.com/media/onnx/models/main/vision/classification/resnet/model/resnet18-v1-7.onnx")
|> elem(1)
ダウンロード後、ローカルに保存されたResNet Onnxモデルを AxonOnnx.import() でインポートします
# ResNet Onnxモデルをインポート(20秒程度かかります)
{model, params} = AxonOnnx.import(resnet)
実行結果として、自前で構築したとき同様、インポートされたモデルのサマリが表示されます
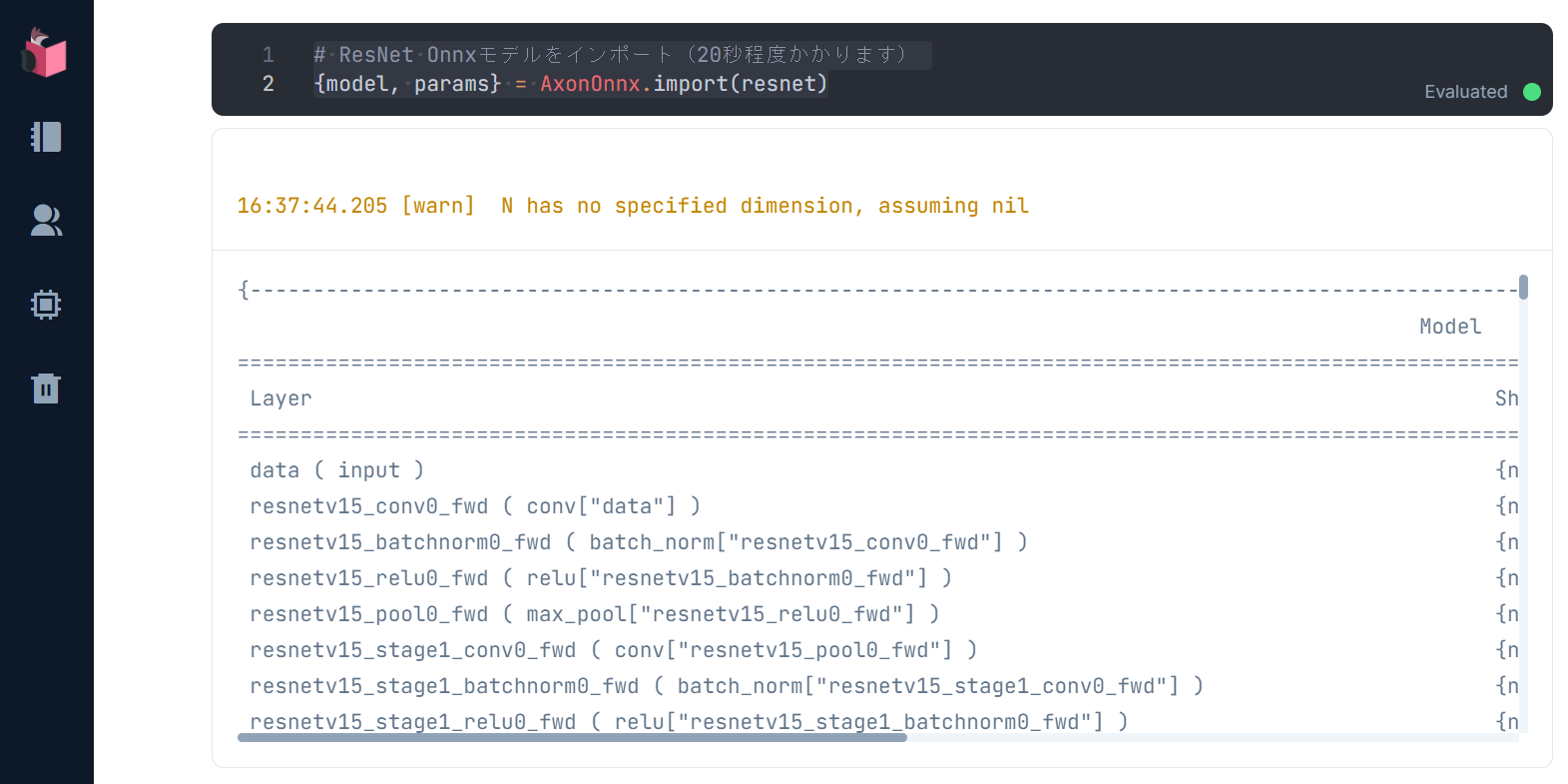
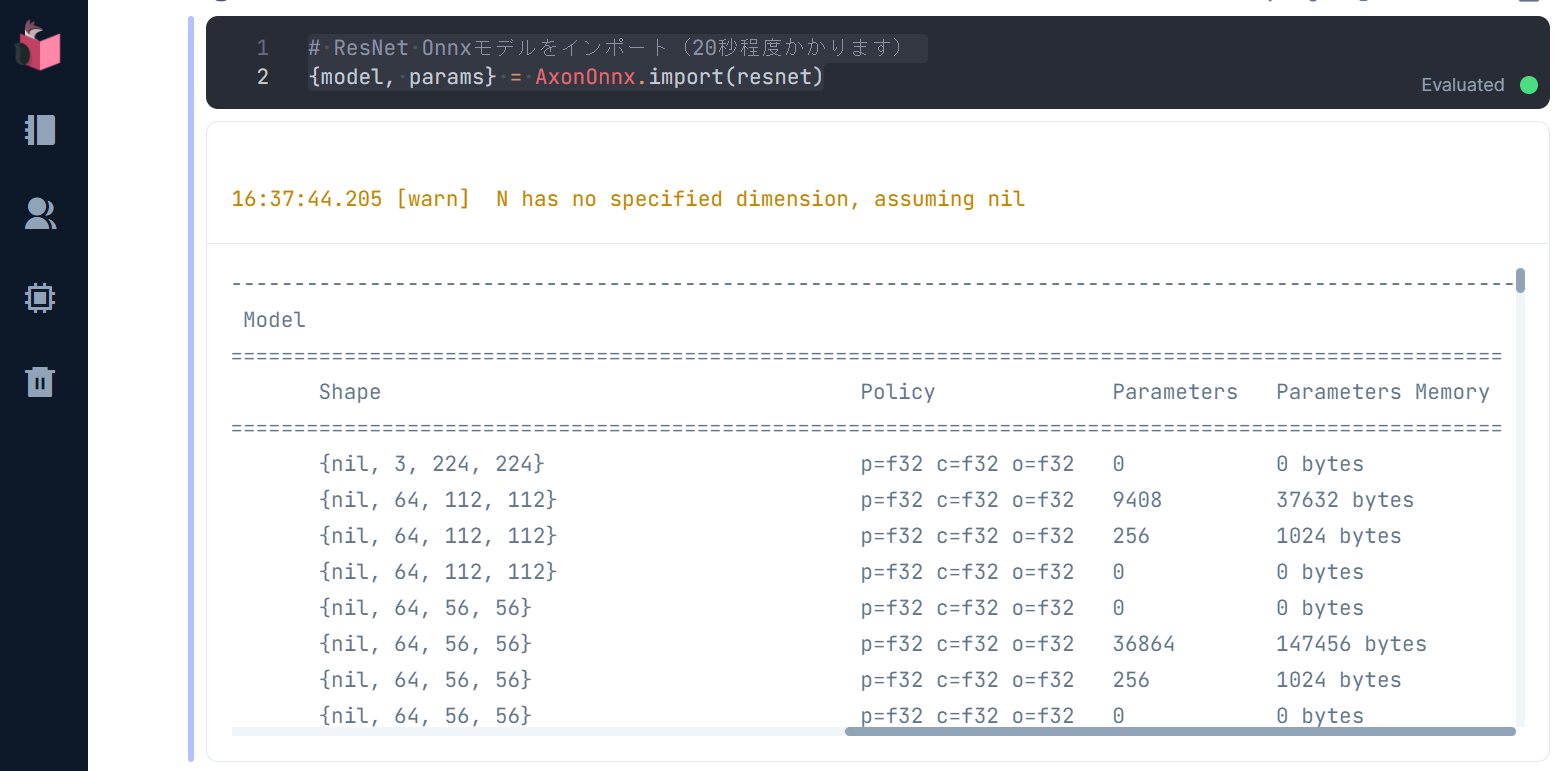
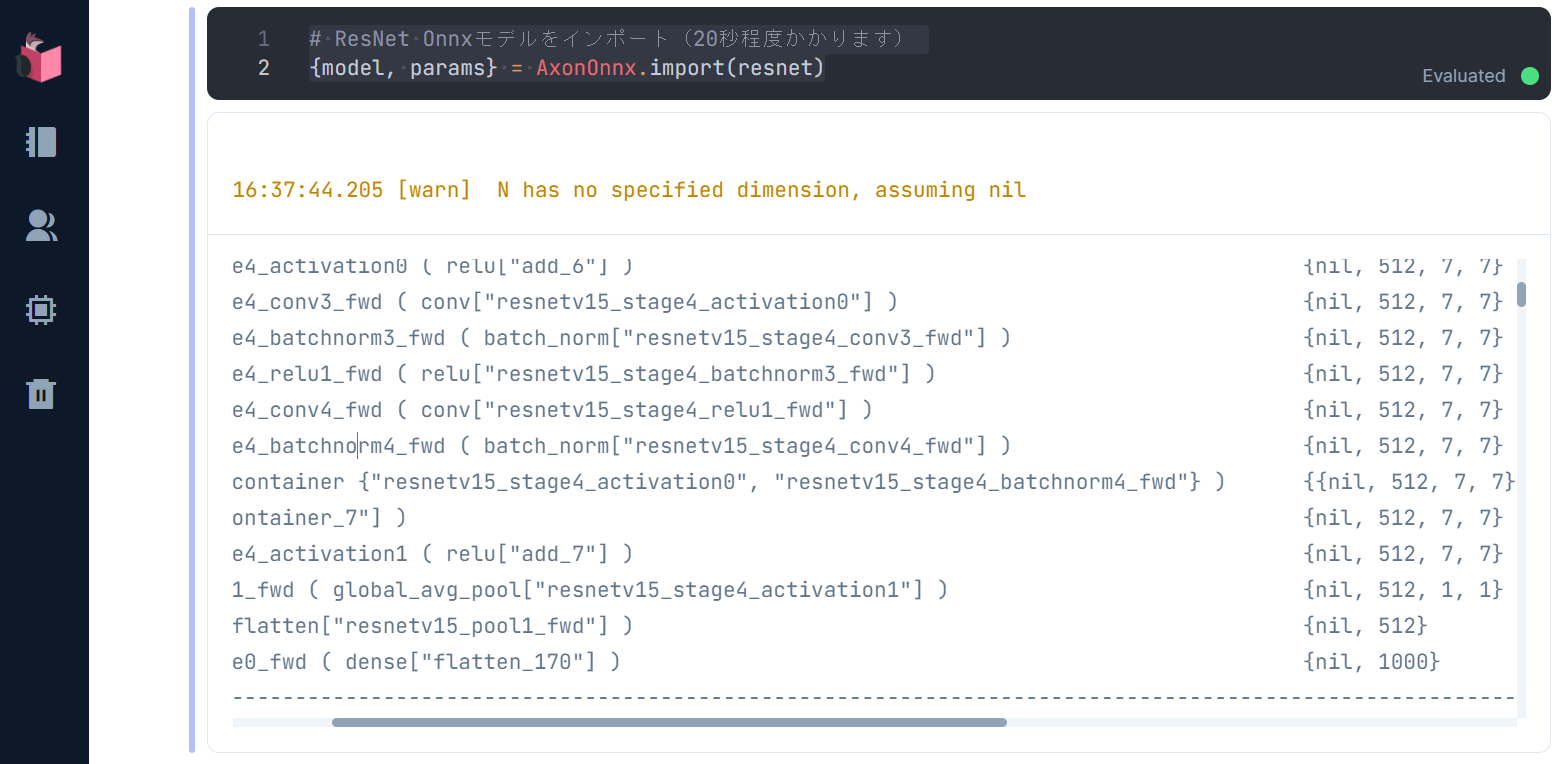
上記サマリは、224 x 224 x 3の画像をインプットとし、10層のCNNと、Average Pooling層、全結合層から構成されるResNetモデル(下図)と同様であることを表しています
上図は、Livebook上で下記コードにより見ることができます
File.rm("f9a8eaaa866c2b783162fe65afdff67171e993fb.png")
Download.from("https://forums.fast.ai/uploads/default/original/3X/f/9/f9a8eaaa866c2b783162fe65afdff67171e993fb.png")
|> elem(1)
|> File.read!
|> Kino.Image.new(:jpeg)
それとサマリの中で、「batchnorm」と書かれた、上記ResNetモデルに記載されていない層がありますが、コレは「Batch Normalization」を意味しており、「内部共変量シフト」と呼ばれる、学習が効率的に進まない状況に対し、正規化により学習を安定化/高速化する層になるのですが、ResNetのような深い層を持つモデルでは重要となります
params には、カーネルが入っています
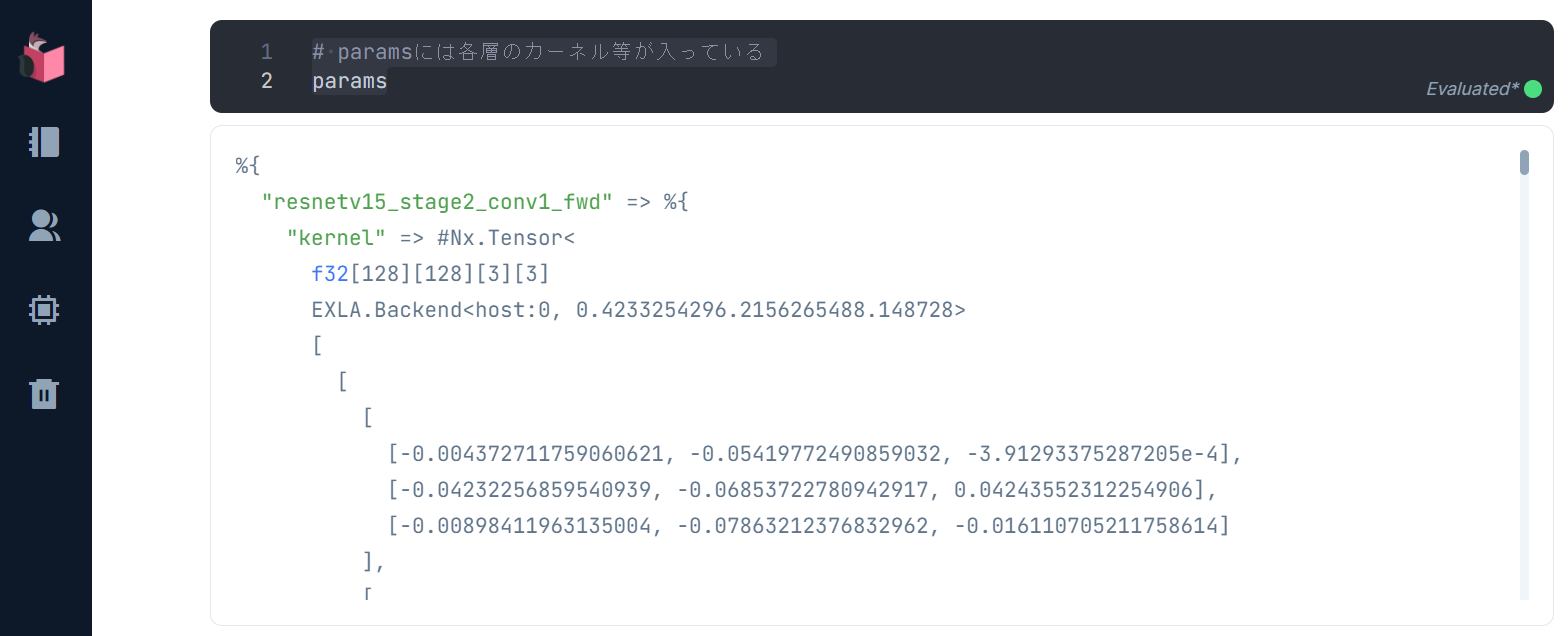
④モデルの学習
ResNetは、学習済みモデルのため、モデルの学習は不要です
⑤学習済みモデルで予測を実施
実際に、学習済みモデルにて未知データでの予測を行ってみます
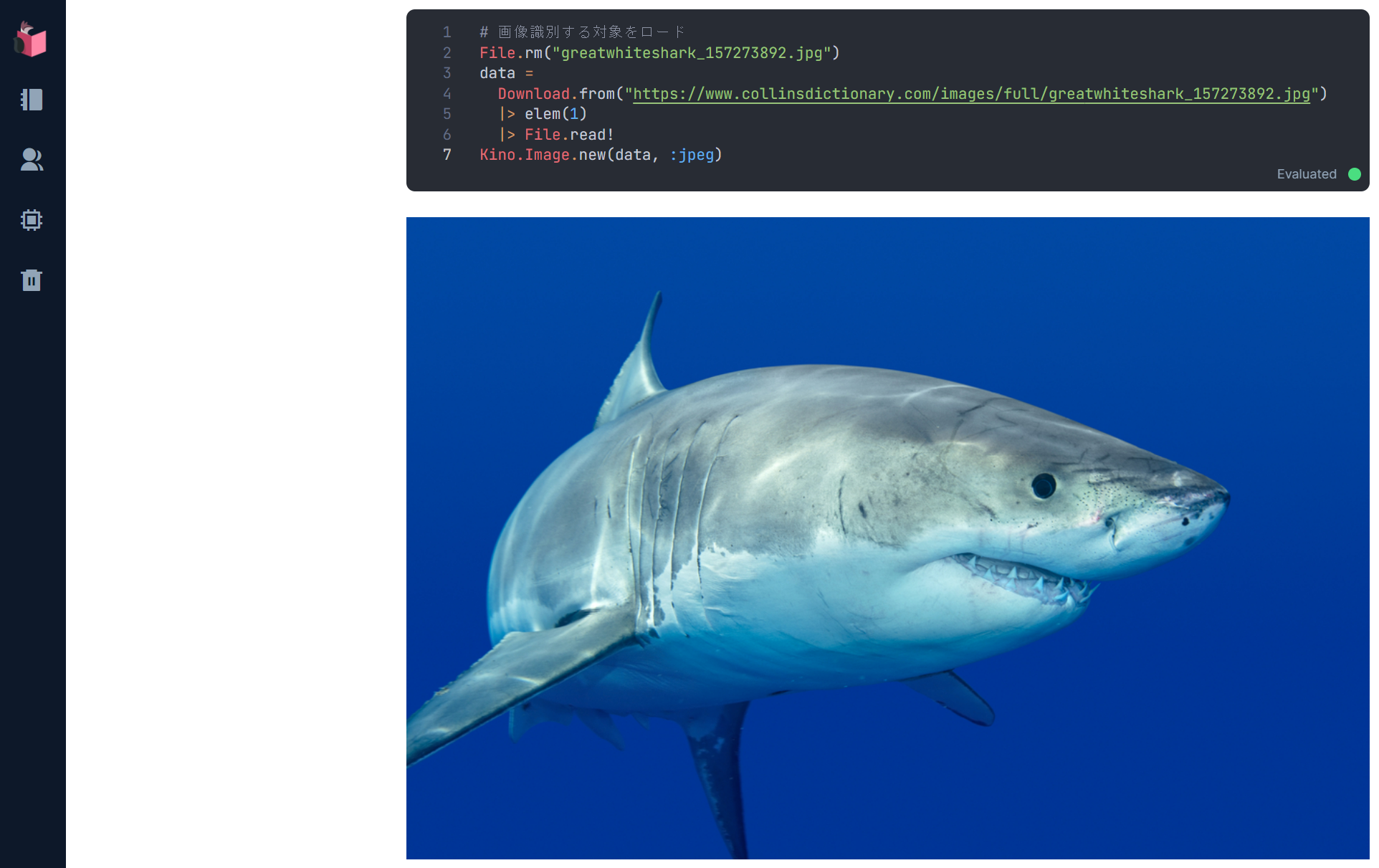
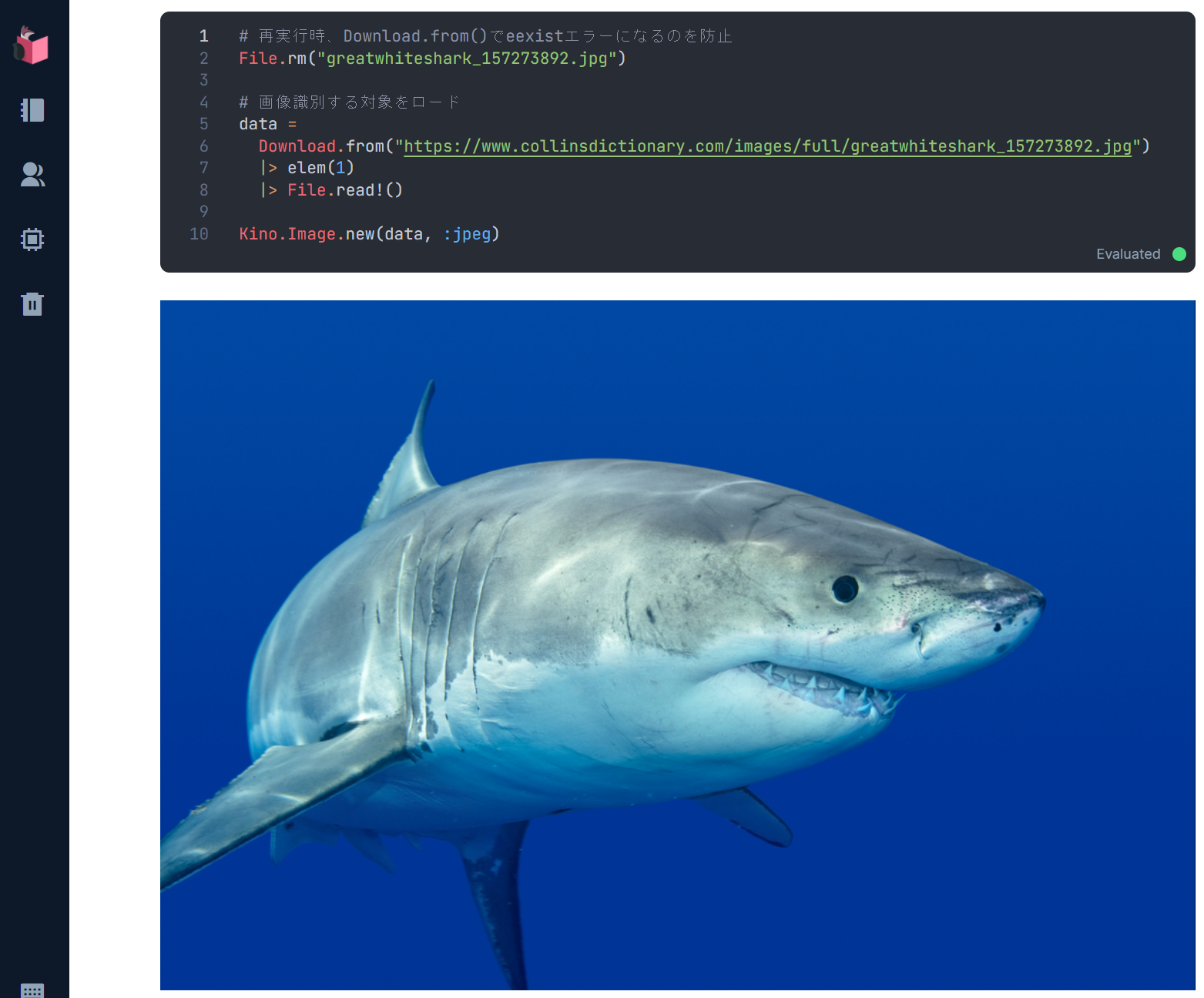
未知データとなる画像のロード
# 再実行時、Download.from()でeexistエラーになるのを防止
File.rm("greatwhiteshark_157273892.jpg")
# 画像識別する対象をロード
data =
Download.from("https://www.collinsdictionary.com/images/full/greatwhiteshark_157273892.jpg")
|> elem(1)
|> File.read!
Kino.Image.new(data, :jpeg)
実行結果は、以下の通りです
次に、この画像をResNetで扱える形(224 x 224 x 3)へと変形し、Nx行列へと変えます
この際、チャンネル数が3では無く、4になっているケースがあるため、3になるよう加工します
なお最終的なコードでは、その後のResNet向け画像加工をまとめてパイプで処理しているため、変数 nx_binary を省略していますが、ここでは各加工仮定をデバッグするために変数化しています
# ResNetにインプットできるよう224 x 224 x 3の画像に加工
nx_image =
data
|> StbImage.read_binary!
|> StbImage.resize(224, 224)
|> StbImage.to_nx
nx_channels =
nx_image
|> Nx.axis_size(2)
nx_binary =
case nx_channels do
3 -> nx_image
4 -> Nx.slice(nx_image, [0, 0, 0], [224, 224, 3])
end
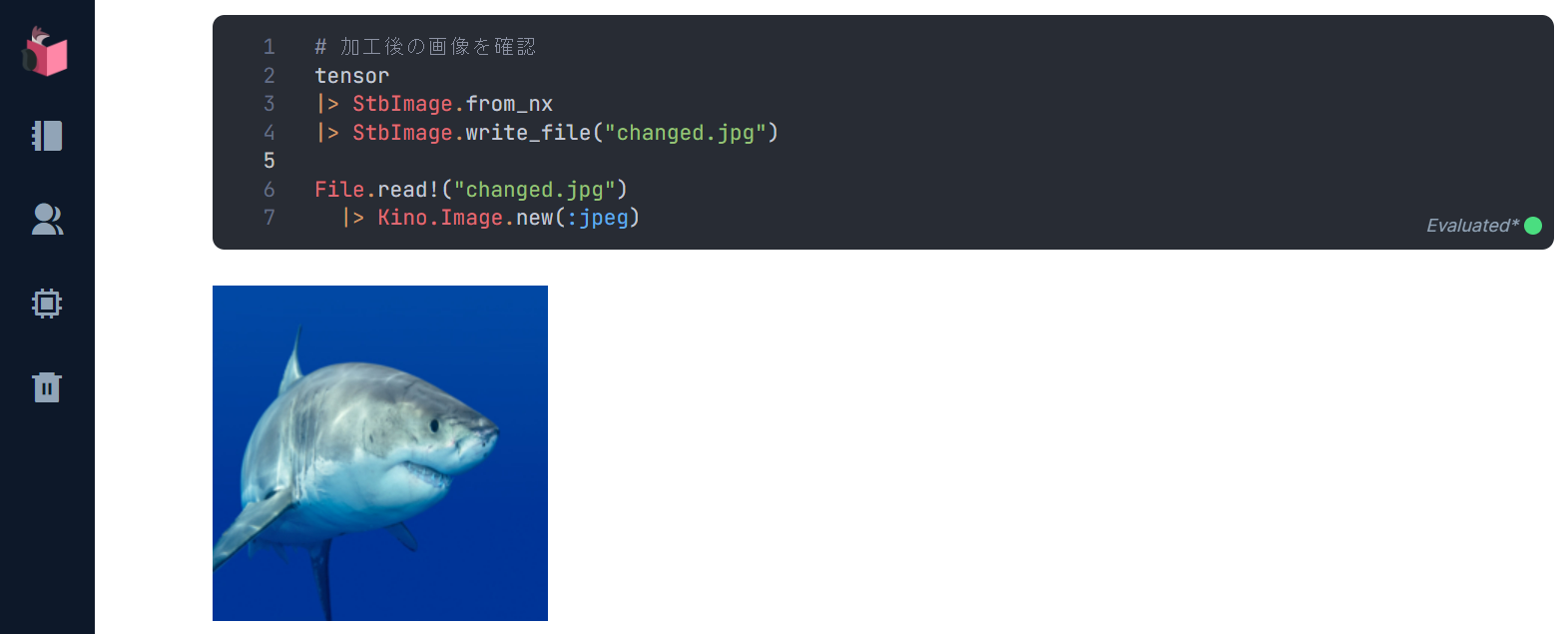
加工後の画像を確認してみます
nx_binary
|> StbImage.from_nx
|> StbImage.write_file("changed.jpg")
File.read!("changed.jpg")
|> Kino.Image.new(:jpeg)
224 x 224 x 3の画像に加工されていることが確認できました
この後、ResNetで扱える画像加工が、以下のように続きます
tensor = nx_binary
|> Nx.divide(255)
|> Nx.subtract(Nx.tensor([0.485, 0.456, 0.406]))
|> Nx.divide(Nx.tensor([0.229, 0.224, 0.225]))
|> Nx.transpose
|> Nx.new_axis(0)
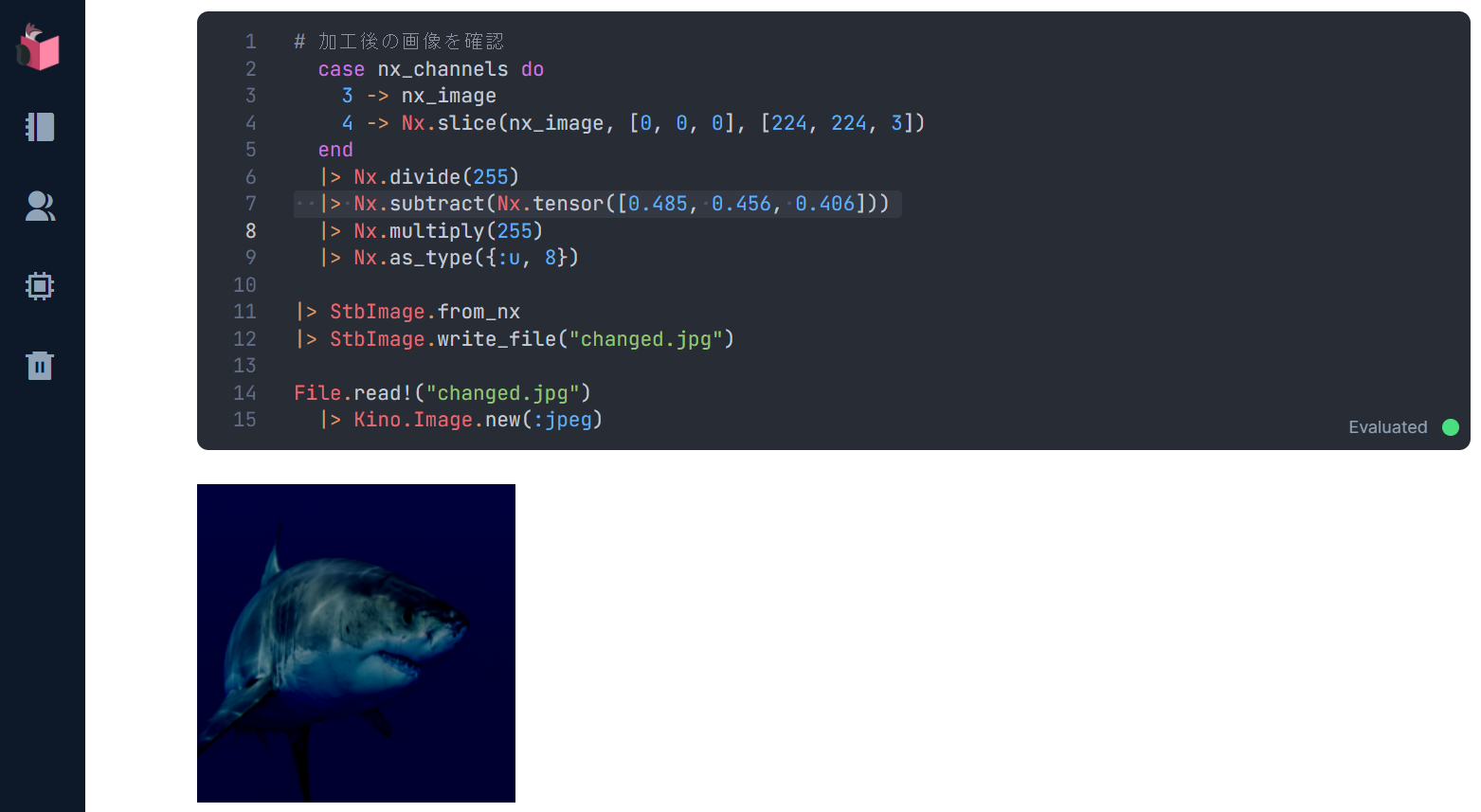
最初に行うのは、ResNetで扱える輝度に下げるために、Nx.subtract(Nx.tensor([0.485, 0.456, 0.406])) を行っているのですが、この加工を下記のようにデバッグしてみましょう
Nx.divide(255) で正規化した後に加工を行っているのですが、このままだとKinoで画像表示できないため、Nx.multiply(255) で非正規化し、画像として扱えるよう |> Nx.as_type({:u, 8}) でf32化されていたデータの小数を除去します
nx_binary
|> Nx.divide(255)
|> Nx.subtract(Nx.tensor([0.485, 0.456, 0.406]))
|> Nx.multiply(255)
|> Nx.as_type({:u, 8})
|> StbImage.from_nx
|> StbImage.write_file("changed.jpg")
File.read!("changed.jpg")
|> Kino.Image.new(:jpeg)
輝度が下げられていることが確認できました
他のResNet向け画像加工も、上記のようにデバッグすれば、どのような加工を行ったかが確認できますので、トライしてみてください
その後、Nx.transpose() で横/縦/チャンネルを逆転させ、Nx.new_axis(0) で深さを1段下げます
画像識別
ResNet向け画像加工が一通り終わったら、Axon.predict() で、モデルと学習済みステート、未知データ行列を渡すと、予測(画像識別)が行われます
# 1,000種類の画像各々にどの程度、適合しているかを予測
predict_per_list =
Axon.predict(model, params, tensor)
以下の通り、各画像とのマッチ率が算出されます
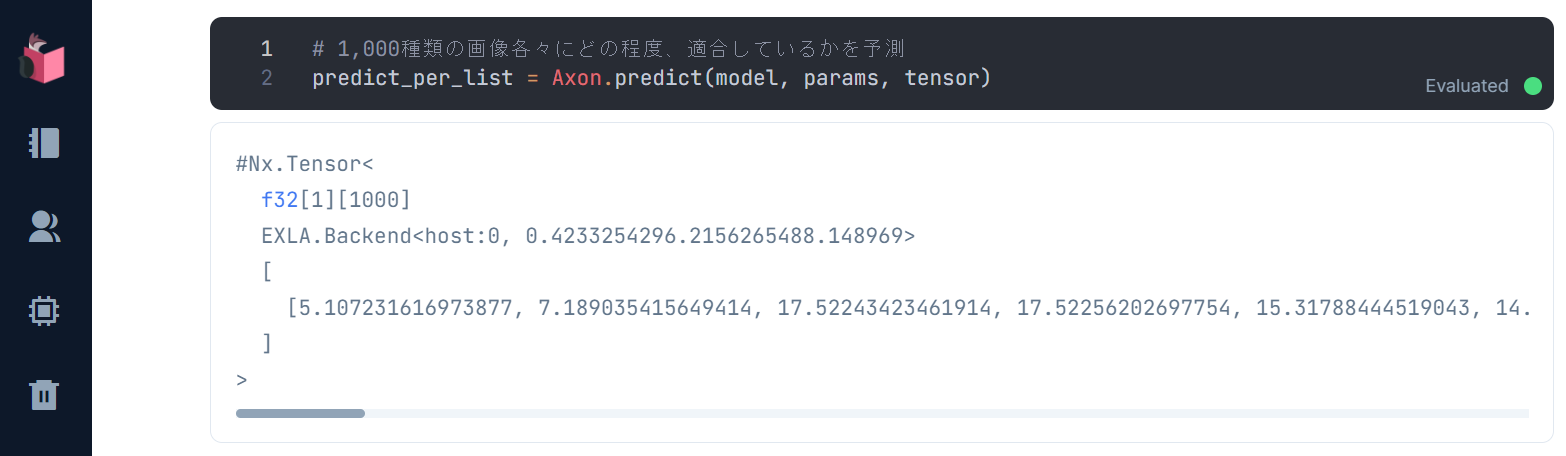
このマッチ率をランク付けし、最もマッチするものから順に並べ替えます
# マッチ率をランク付け
rank = predict_per_list
|> Nx.flatten
|> Nx.argsort
|> Nx.reverse
以下の通り、最もマッチする画像のインデックスが返ってきます
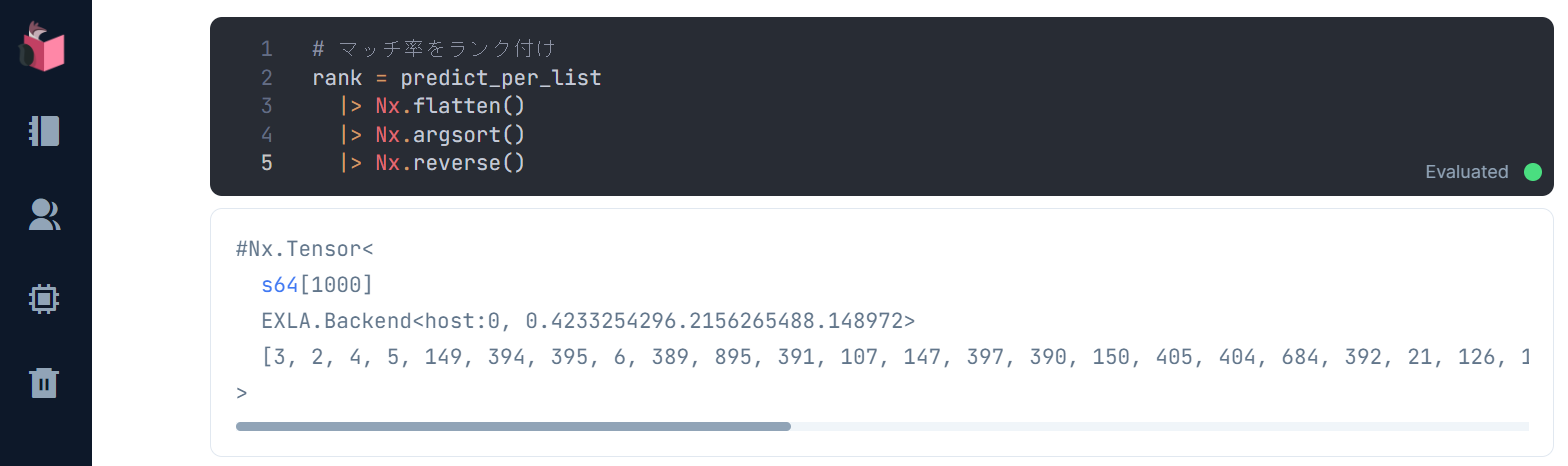
最後に、このランク付けに該当する教師ラベルを取得します
# 識別した1,000種類の教師ラベルを取得
rank
|> Nx.slice([0], [5])
|> Nx.to_flat_list
|> Enum.with_index
|> Enum.map(fn {no, index} -> {index, Map.get(classes, to_string(no))} end)
この実行結果が、画像識別でマッチした順の教師ラベルとなっています
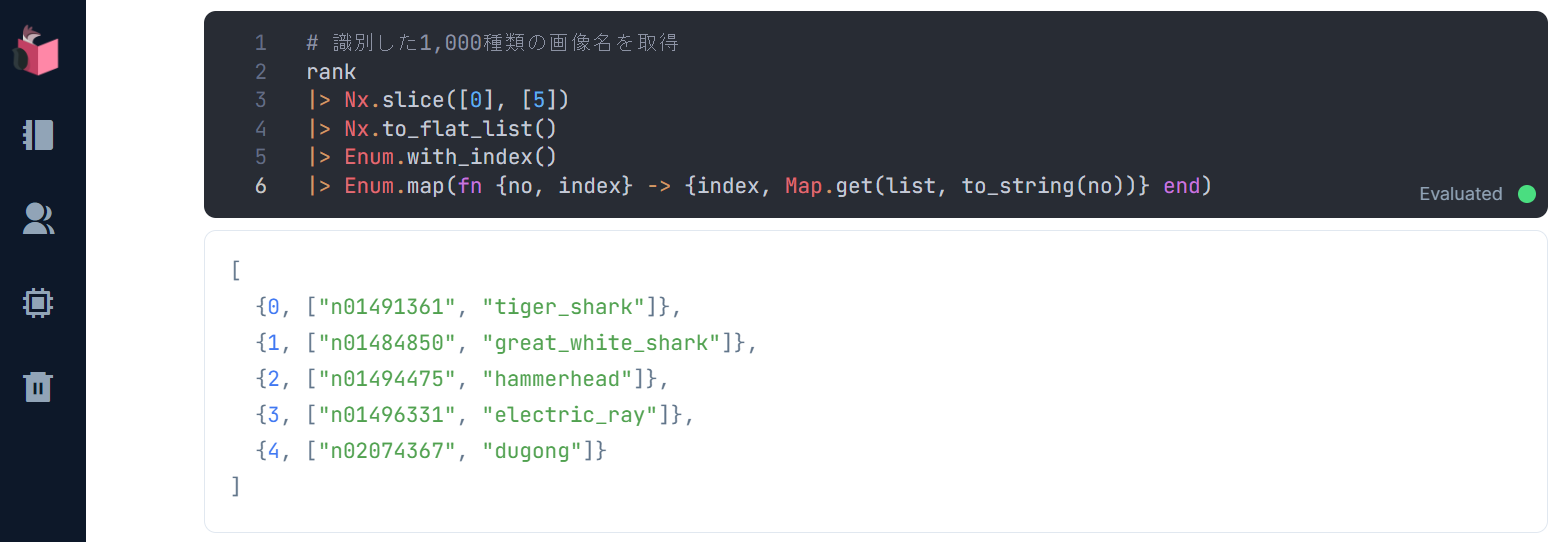
教師ラベルはそれぞれ、以下表の通りで、いい感じに画像識別されていると思います
| 教師ラベル | 日本語訳 | 参考画像 |
|---|---|---|
| tiger_shark | イタチザメ |  |
| great_white_shark | ホオジロザメ |  |
| hammerhead | シュモクザメ |  |
| electric_ray | シビレエイ |  |
| dugong | ジュゴン |  |
終わり
今回は、ResNet OnnxモデルやCNNについて解説し、Livebookで実際にResNet Onnxモデルによる画像識別を実践しました
Livebook+Nx+AxonOnnxを使うことで、PythonのJupyterNotebookやColaboratoryとほぼ同じフィーリングでOnnx学習済みモデルを使ったAI・ML開発が可能であることが実感いただけたでしょうか
また、ResNetによる画像識別は、GPU非搭載PCでも気軽に試すことができる分かりやすいディープラーニング例でもあるので、ディープラーニング入門としてもオススメです
主催/運営しているElixirコミュニティ紹介
4. LiveView JP : A place to mob-program in LiveView, LiveBook+Nx+Axon, and elixir-desktop
5. Neos.ex : A place to connecting Elixir and NeosVR to create a new world
 Elixir生誕10周年を祝い、"Elixirの現在" に追いつける
Elixir生誕10周年を祝い、"Elixirの現在" に追いつける
Elixir界隈に激震をもたらした2021年の大変動を活用するコラム群を日々アップデートしています
本コラムも、第3弾「Elixir/Livebook+NxでPythonっぽくAI・ML」に追加しています
p.s.このコラムが、面白かったり、役に立ったら…
 や
や  にて、どうぞ応援よろしくお願いします:bow
にて、どうぞ応援よろしくお願いします:bow