この記事は、Elixir Advent Calendar 2022 7の21日目です
昨日は、@t-yamanashi さんで「Elixirを使ってNeosVRで花火を打ち上げる 〜ブラウザーからVRのオブジェクトをいじる〜」でした
piacere です、ご覧いただいてありがとございます ![]()
この2年間で、Elixirの機械学習環境が凄まじく発展し、プロダクションに実戦投入しても問題無いフェーズに入ったので、「Eixirで機械学習に初挑戦」をテーマにシリーズコラムをお届けします
入門者向けに「機械学習とは何か?」や、機械学習の中で出てくる数々のキーワード解説もしていきますので、AI・MLの知識が無いWeb開発者/IoT開発者の方や、PythonでAI・MLを学んだけどイマイチ入らなかった方、Elixir経験者だけどNx/Axon/Livebook等の新テクノロジーに追いつけていない方にも、スッと入りやすい内容としてまとめていこうと思います
前回、Kaggleのタイタニック問題を題材に「データ前処理」の基礎を学び、Kaggleコンペに提出も行いましたが、全体ランキングがあまり良い順位で無かったので、「統計」による「データ前処理」の改善と、「EDA(探索的データ分析:Exploratory Data Analysis)」による精度改善を今回は行います
 Elixir Advent Calendar 総勢16本、熱い冬ヽ(=´▽`=)ノ
Elixir Advent Calendar 総勢16本、熱い冬ヽ(=´▽`=)ノ
例年に無い盛り上がりを見せています … 応援/購読よろしくお願いします ![]()
https://qiita.com/advent-calendar/2022/elixir
本シリーズの目次
①:基礎知識とLivebook+Nx+Axonによる機械学習入門
|> ②:機械学習コードの解説と「学習データの可視化」「学習過程のアニメ化」
|> ③:「予測」の可視化と「精度」の変化要因、「学習過程グラフ」の読み方
|> ④:データ処理に強いElixirでKaggle挑戦(前編)…「データ前処理」基礎編
|> ⑤:データ処理に強いElixirでKaggle挑戦(後編)…「統計」と「EDA」でKaggleに挑む
|> ⑥:いま、Elixir AI・MLで何が出来る? → Elixirのメリット→2023年に攻略する領域
本コラムの検証環境
本コラムは、以下環境で検証しています(恐らくUbuntu実機やMacでも動きます)
- Windows 10 + WSL2 + Ubuntu 22.04 ※最新版のインストール手順はコチラ
- Elixir 1.14.2 ※最新版のインストール手順はコチラ
- Livebook 0.8.0
本講義回の最終的なコード
下記のコードをLivebookに打ち込んで、動かすことでタイタニック問題の予測とKaggleコンペへの提出(submit)行えます
Mix.install([
{:csv, "~> 3.0"},
{:exla, "~> 0.4"},
{:axon, "~> 0.3"},
{:statistics, "~> 0.6"},
{:kino_vega_lite, "~> 0.1.7"}
])
defmodule Pre do
def count_missings(datas) do
datas
|> Enum.flat_map(fn map -> Map.filter(map, & elem(&1, 1) == "") |> Map.keys end)
|> Enum.reject(& &1 == [])
|> Enum.frequencies
end
def separate(datas, id, label) do
{
datas |> Enum.map(& Map.get(&1, id)),
if Map.has_key?(List.first(datas), label) do
datas |> Enum.map(& [[String.to_float("#{Map.get(&1, label)}.0")]] |> Nx.tensor)
else
nil
end,
datas |> Enum.map(& Map.drop(&1, [id, label]))
}
end
def drop(datas, keys) do
datas
|> Enum.map(& Map.drop(&1, keys))
end
def empty_replace(datas, replaces_map) do
replaces_map
|> Enum.reduce(datas, fn {key, replace}, acc ->
acc
|> Enum.map(& Map.put(&1, key, String.replace(Map.get(&1, key), ~r/^$/, replace)))
end)
end
def make_dummies(datas, key) do
datas
|> Enum.map(& Map.get(&1, key))
|> Enum.uniq
|> Enum.with_index(& {&1, String.to_float("#{&2}.0")})
|> Enum.into(%{})
end
def to_dummies(datas, train_maps, keys) do
keys
|> Enum.reduce(datas, fn key, acc ->
acc
+ |> Enum.map(& Map.put(&1, key,
+ case make_dummies(train_maps, key)[Map.get(&1, key)] do
+ nil -> 10.0
+ n -> n
+ end))
+ end)
end
def integer_string_to_float(datas, keys) do
keys
|> Enum.reduce(datas, fn key, acc ->
acc
|> Enum.map(& Map.put(&1, key, Map.get(&1, key)
|> String.replace(~r/^(?!.*\.).*$/, "\\0\.0")
|> String.to_float))
end)
end
def map_to_tensor(datas) do
datas
|> Enum.map(& [Map.values(&1)] |> Nx.tensor)
end
def for_dummies(datas) do
datas
+ |> Enum.map(& Map.put(&1, :honor,
+ &1.name |> String.replace(~r/^.*, /, "") |> String.replace(~r/. .*/, "")))
|> drop([:cabin, :name, :ticket])
+ |> empty_replace(%{embarked: "S", age: "30", fare: "32"})
end
def process(datas, train_datas) do
for_dummies_train_data = for_dummies(train_datas)
datas
|> for_dummies
+ |> to_dummies(for_dummies_train_data, [:embarked, :sex, :honor])
|> integer_string_to_float([:age, :fare, :parch, :pclass, :sibsp])
|> map_to_tensor
end
def header_and_csv_datas(path) do
[hd | tl] = File.stream!(path)
|> CSV.decode!
|> Enum.to_list
header = hd
|> Enum.map(& &1 |> String.downcase |> String.to_atom)
{header, tl}
end
def csv_file_to_datas(path) do
{header, datas} = header_and_csv_datas(path)
datas
|> Enum.map(& List.zip([header, &1]) |> Enum.into(%{}))
|> Pre.separate(:passengerid, :survived)
end
end
{train_csv_ids, train_csv_labels, train_csv_maps} = Pre.csv_file_to_datas("train.csv")
train_datas = Enum.zip(Pre.process(train_csv_maps, train_csv_maps), train_csv_labels)
model = Axon.input("input", shape: {nil, 7})
|> Axon.dense(48, activation: :tanh)
|> Axon.dropout(rate: 0.2)
|> Axon.dense(48, activation: :tanh)
|> Axon.dense(1, activation: :sigmoid)
trained_state = model
|> Axon.Loop.trainer(:mean_squared_error, Axon.Optimizers.adam(0.0005))
|> Axon.Loop.metric(:accuracy, "Accuracy")
|> Axon.Loop.run(train_datas, %{}, epochs: 20, compiler: EXLA)
(紙面ボリュームの都合で割愛)
{test_csv_ids, _, test_csv_maps} = Pre.csv_file_to_datas("test.csv")
result = Pre.process(test_csv_maps, train_csv_maps)
|> Enum.map(& Axon.predict(model, trained_state, &1)
|> Nx.to_flat_list |> List.first |> round)
|> then(& Enum.zip(test_csv_ids, &1))
|> Enum.map(& [elem(&1, 0), Integer.to_string(elem(&1, 1))])
|> then(& [["PassengerId", "Survived"] | &1])
result
|> CSV.encode
|> Enum.to_list
|> then(& File.write("result-age_fare_median-name_honor.csv", &1))
Cofee Break:学習は常に同じ結果になる訳では無い
まず最初に、学習済みモデルでの予測は、同じデータに対して常に同じ予測を返す一方、学習自体は毎回、異なるモデルを生成するため、予測精度に変化が出るということです
前回、作成したモデル学習と予測のKaggle提出を、3回、繰り返した結果が以下です … 全くコード/データを変えていないにも関わらず、2.4%の開きが生まれています(前回結果75.119%とだと、2.9%もの開きです)
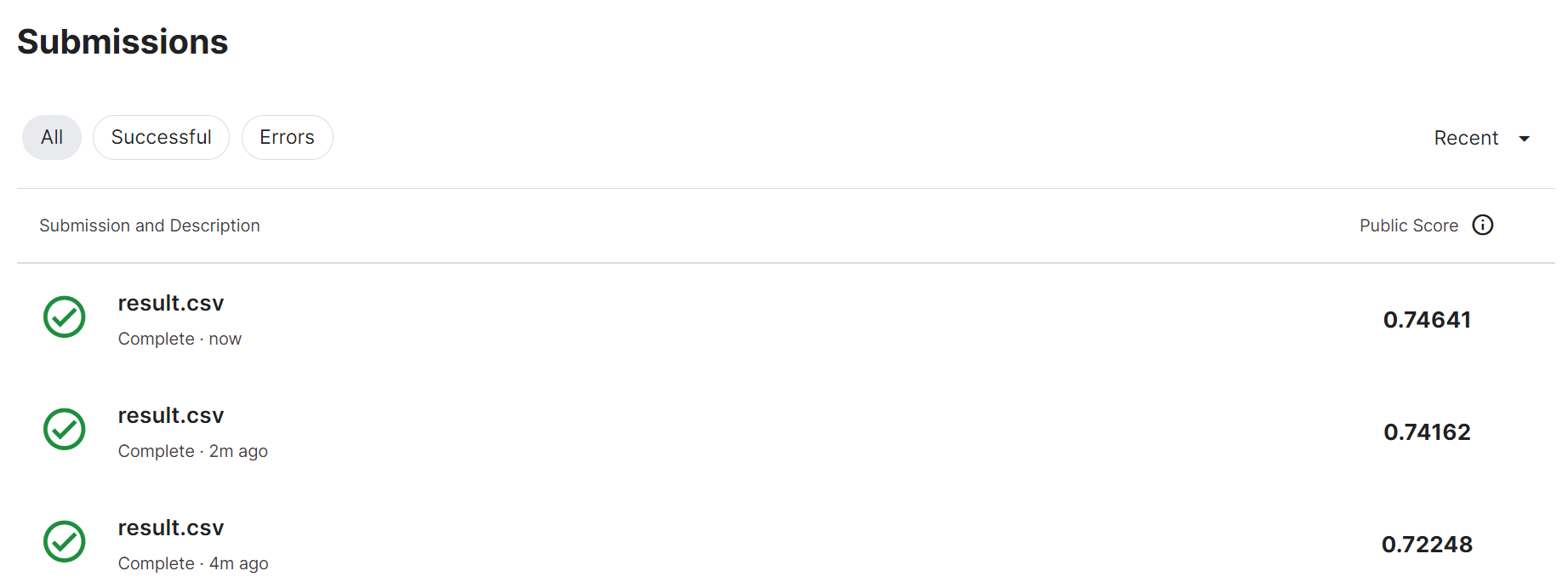
このように、学習都度、モデルが変化するのは「学習時のランダム性の存在」が原因で、今回作ったモデルで言うと、最適化関数の「Adam」のベースとなっている「SGD」がランダムにデータを取り出していることが要因です
逆に言えば、これくらいの変動がSGDベースの学習には発生する … ということなので、何度もKaggleに提出するだけでランキング上昇の可能性があるということですw ![]()
このパターンは、通常の答えがジャストに出てくるプログラミングに慣れた方ほど回避しやすい考え方のため、扱っているタスクが「確率的で、毎度同じ答えが返ってくる訳では無い」ものとして再認識していただくと良いと思います
これを踏まえ、お手元で実施したKaggle提出は、同じ正解率/ランキングとならない点と、以降の改善も同様である点にご注意ください
なお、Kaggleは1日10回しか提出できないので、ご注意ください
ⅰ)学習/検証データとラベルの準備の改善
前回の「ⅰ-4.学習のための最低限の『データ前処理』」で構築したコードを前提に、その続きとして、「データ前処理」の改善を行っていきます
ⅰ-5.精度を向上させるための「データ前処理」
①年齢と料金の補完値を中央値に修正
前回、ageとfareの補完値を、適当に「0」としましたが、これは年齢(学習データのみ)であれば「891名中、19.9%にあたる177名もの0歳の乗客を増加させた」となり、かなり不自然な偏りを発生させており、これが精度低下の原因になり得ます
そのため、下記のようなデータの統計的特性や他項目を用いた推測で補完することが必要となります
- 中央値/平均値/最頻値など、該当項目の統計値で補完する
- 該当項目以外のデータ群から、該当項目の値を推測する
- 欠損値をカテゴリ値として扱う ※欠損していること自体が特徴となるようなケース
- 全項目の欠損傾向から、新たな項目を作り、欠損値は削除する
このあたりについて詳しく知りたい方は、下記コラムが参考になると思います
ここでは、比較的カンタンに実装できる中央値/平均値を取り上げたいと思います
まず、グラフでageのデータ分布を見てみます(学習データに欠損値が存在するのでEnum.rejectで除去しています)
ages = train_csv_maps
|> Enum.reject(&(&1.age == ""))
|> Pre.integer_string_to_float([:age])
|> Enum.map(&Map.take(&1, [:ticket, :age]))
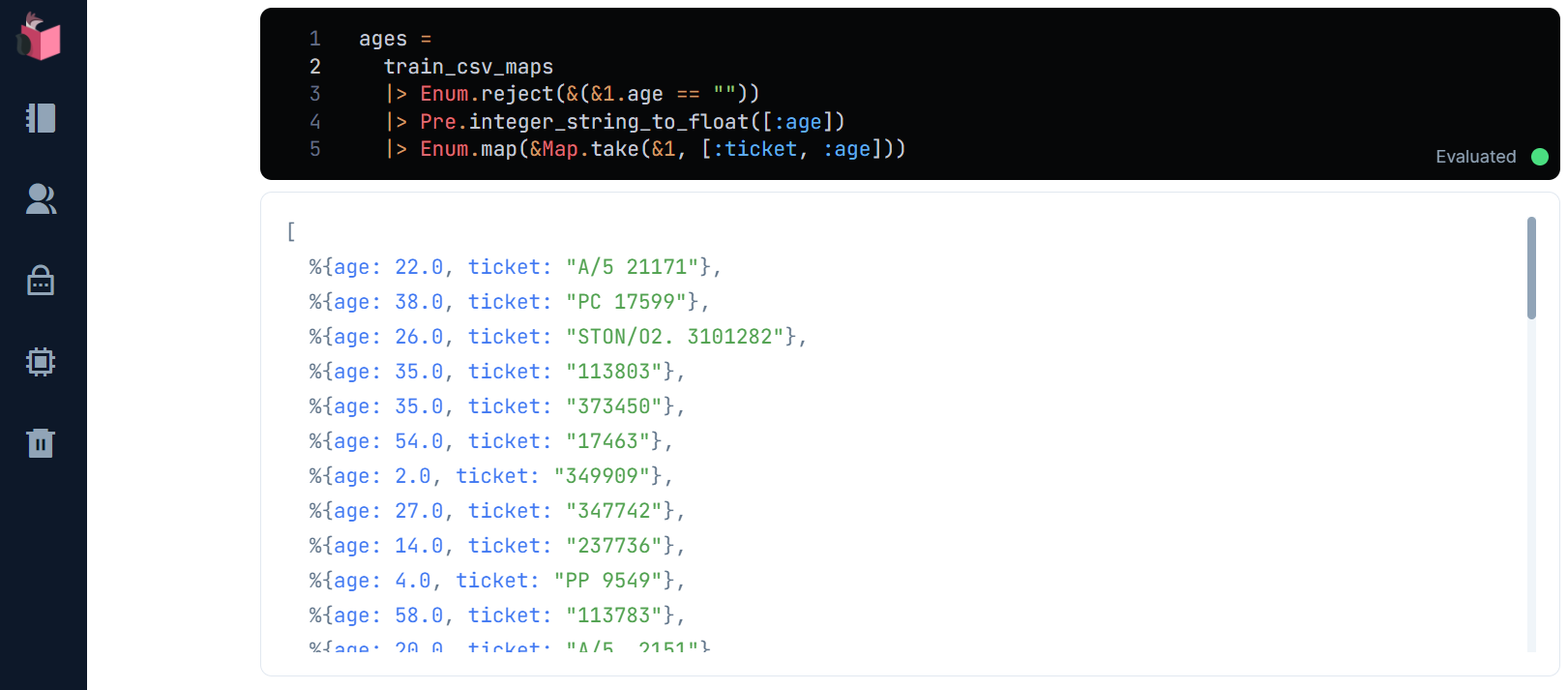
10代中盤から40代後半にかけて最頻しているように見えるので、30歳前後が最も分布している感じです
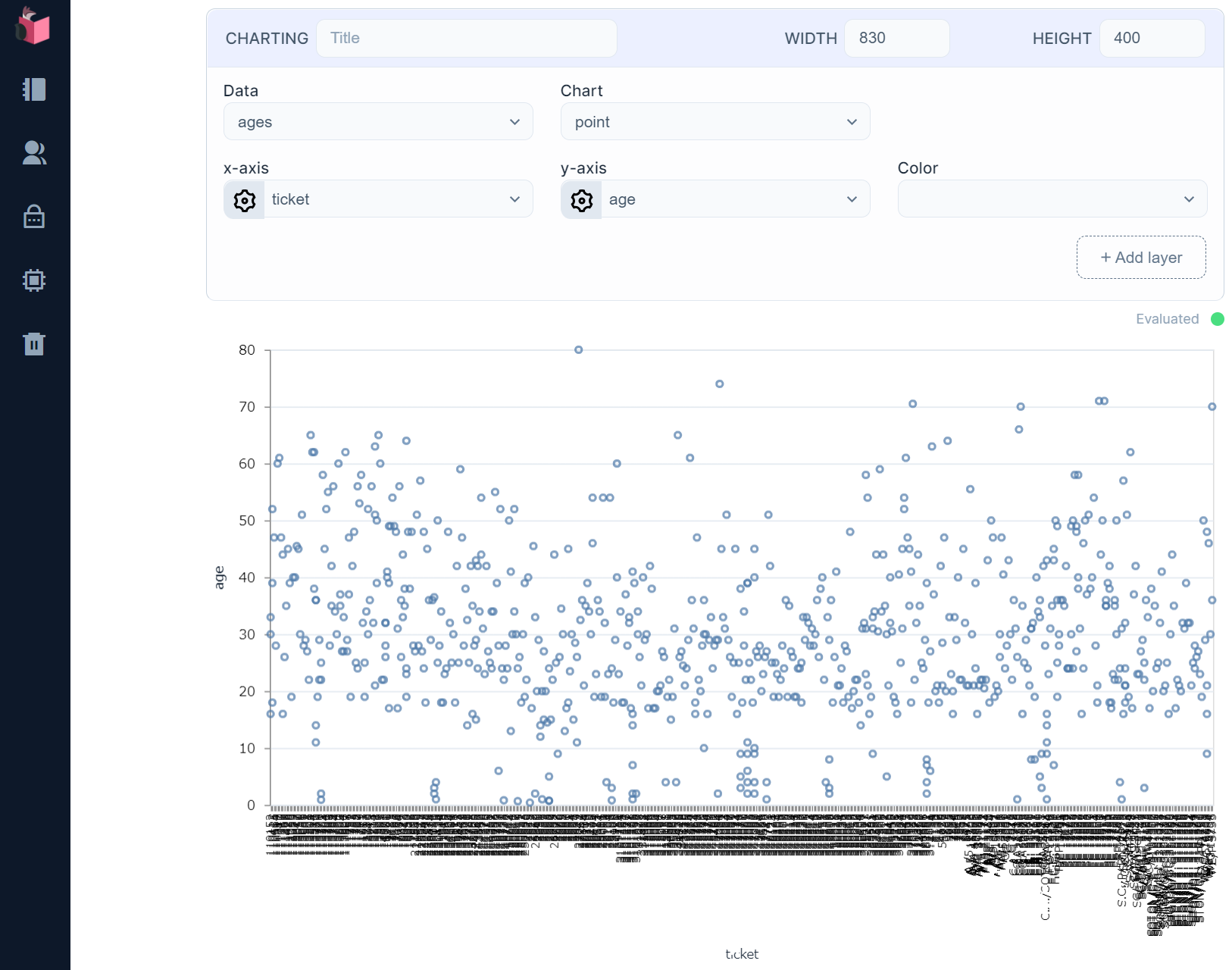
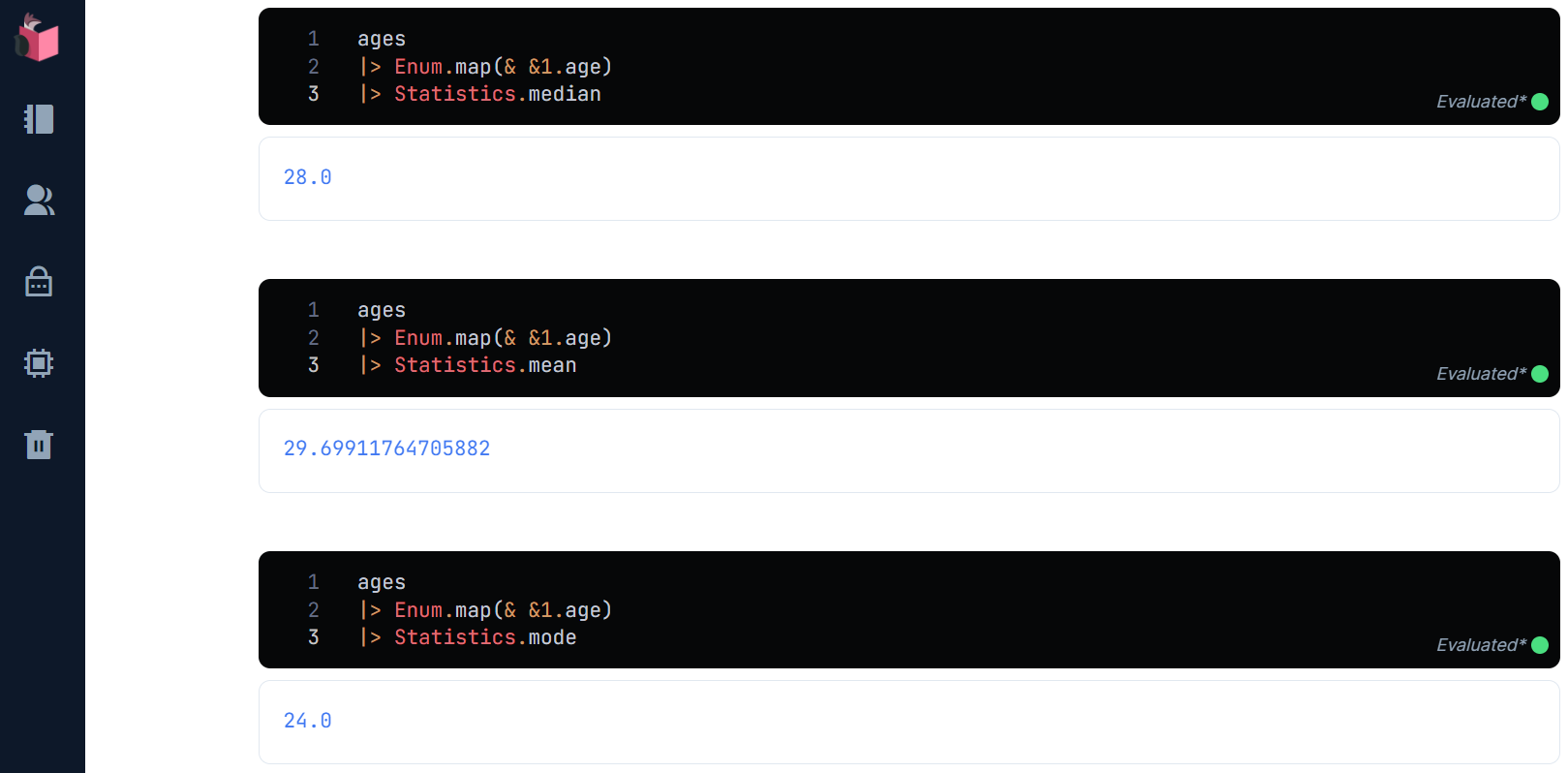
Elixirで統計を取得するときに便利なライブラリ「Statistics」を使って、中央値/平均値/最頻値を取ってみましょう
ages
|> Enum.map(& &1.age)
|> Statistics.median
ages
|> Enum.map(& &1.age)
|> Statistics.mean
ages
|> Enum.map(& &1.age)
|> Statistics.mode
やはり30歳付近になりました … 3つの統計値にさほど大差無いので、ここは中央値を使うこととしましょう
同様に、fareについてもグラフ分布/中央値/平均値/最頻値を出してみます
fares =
train_csv_maps
|> Pre.integer_string_to_float([:fare])
|> Enum.map(&Map.take(&1, [:ticket, :fare]))
けっこうバラついてるので何とも言えませんが、20前後に最頻がありそうに見えます
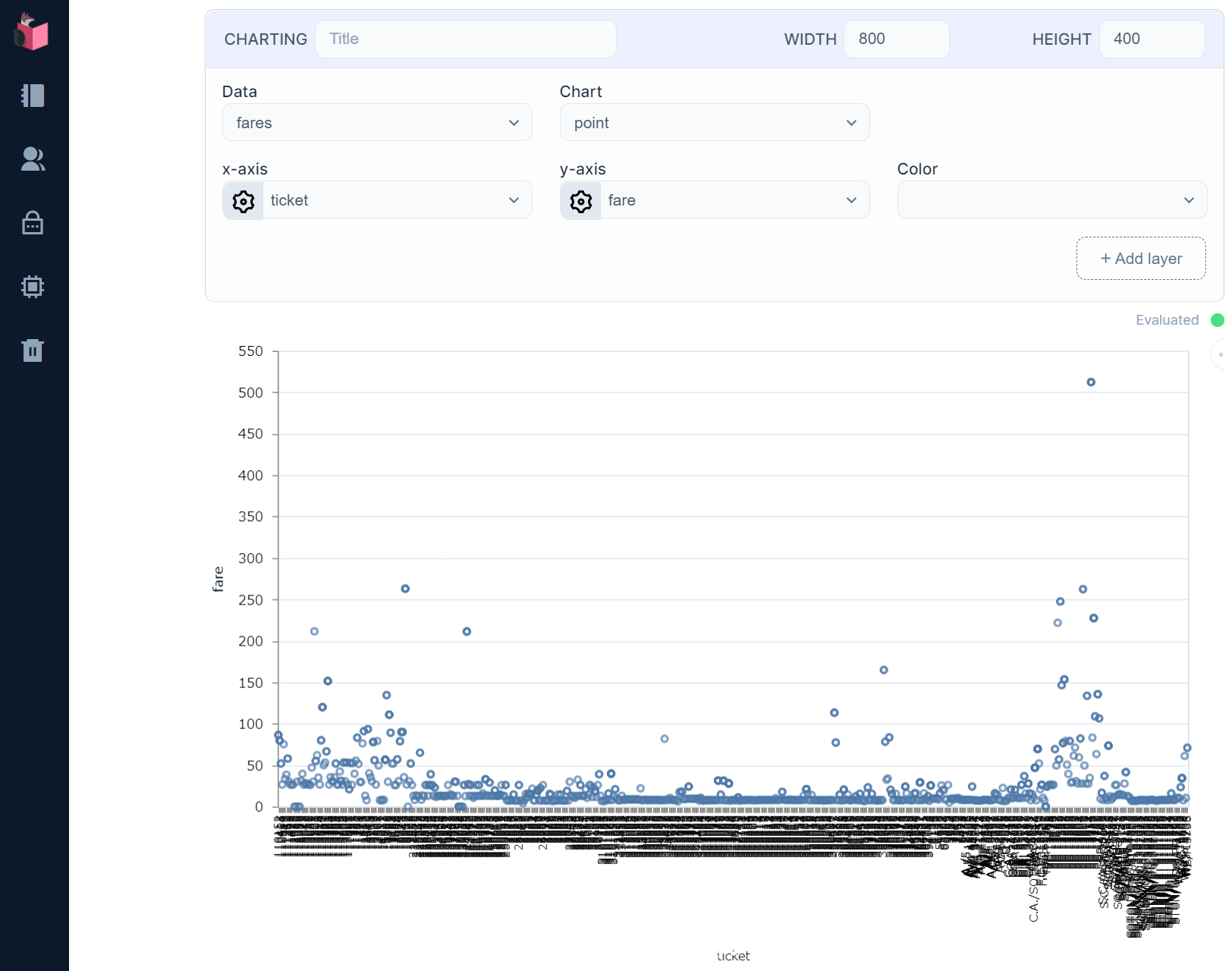
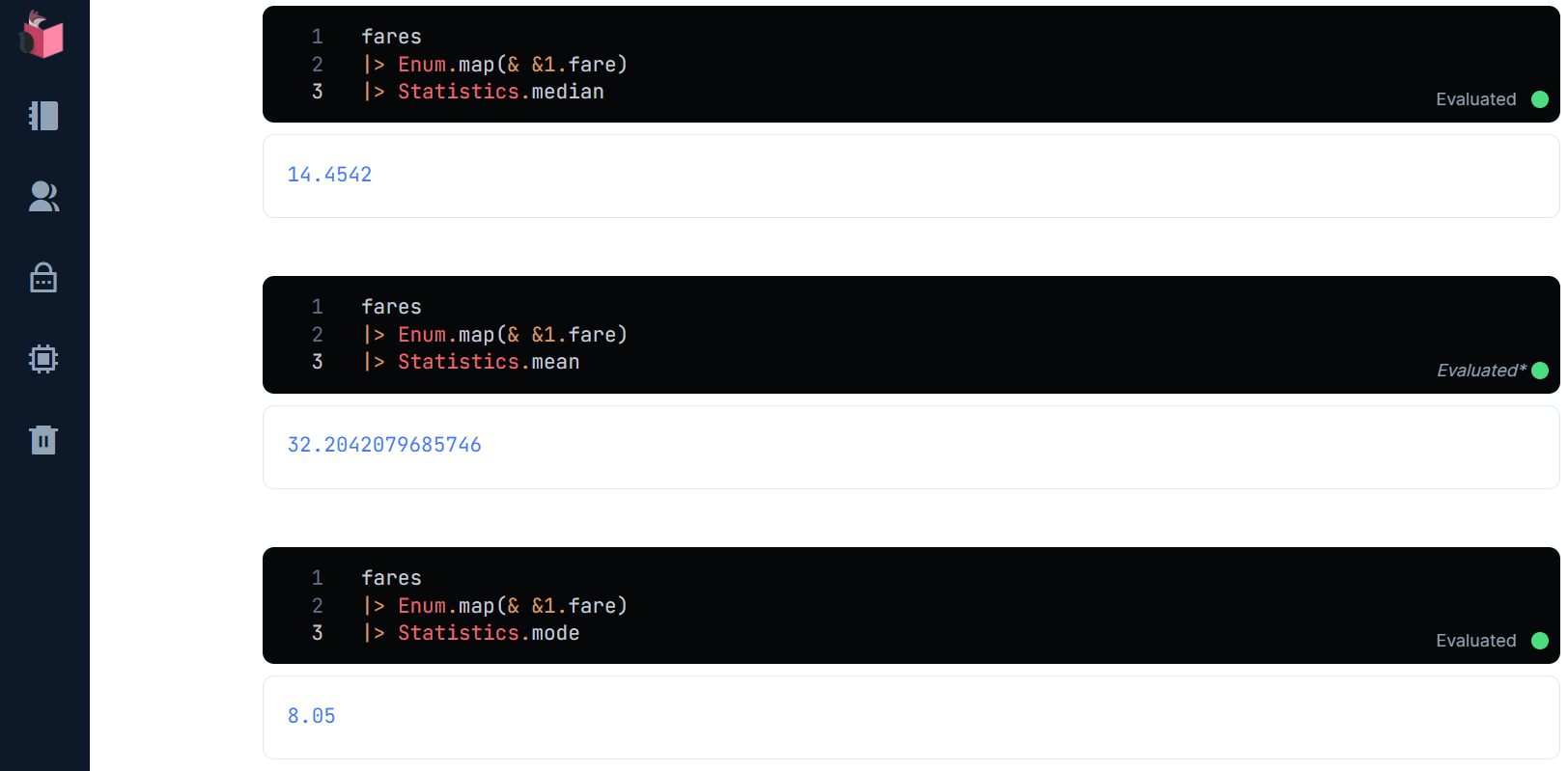
fares
|> Enum.map(& &1.fare)
|> Statistics.median
fares
|> Enum.map(& &1.fare)
|> Statistics.mean
fares
|> Enum.map(& &1.fare)
|> Statistics.mode
fareは、3つの統計値が遠いので、いずれを使うかの判断が必要ですが、データ分布傾向から見ると、バラツキの多い分布であるため中央値が向いていると判断しました
それでは、ここまでの情報を元に、Preモジュール内の補完値を下記のように修正し、学習/予測/Kaggle提出を行います
defmodule Pre do
def count_missings(datas) do
…
def for_dummies(datas) do
datas
|> drop([:cabin, :name, :ticket])
+ |> empty_replace(%{embarked: "S", age: "30", fare: "32"})
end
…
中央値で補完して、Kaggle提出した結果は以下の通りで、精度が向上しています

参考までに、平均値で補完した結果は以下の通りで、あまり改善していないように見えます(最頻値はKaggleの提出制限があるため控えました)

②EDA(探索的データ分析)に基づく改善アイデア
「EDA」は「Exploratory Data Analysis」の略で、日本語にすると「探索的データ分析」といったところでしょうか
モデルを作る前に、データを人が解析して、何らかの特徴を見つけたり、データ分布の特性や偏りを発見したり、特徴の例外たる「外れ値」を除外して確認したり … そういったデータの元となる業務を分析することで、データに何らかの傾向を見出し、利用する活動を指します
この手のタスクをやるには、スプレッドシートやExcelの利用が有効なことも多いです
たとえば、train.csvをスプレッドシートで開き、パッと見でデータを眺めると、nameの中に,やたら「Mr.」があるように思えます … 実際、検索してみると、「Mr.」の数が、517件(train.csv全体の58%)もあることが分かります
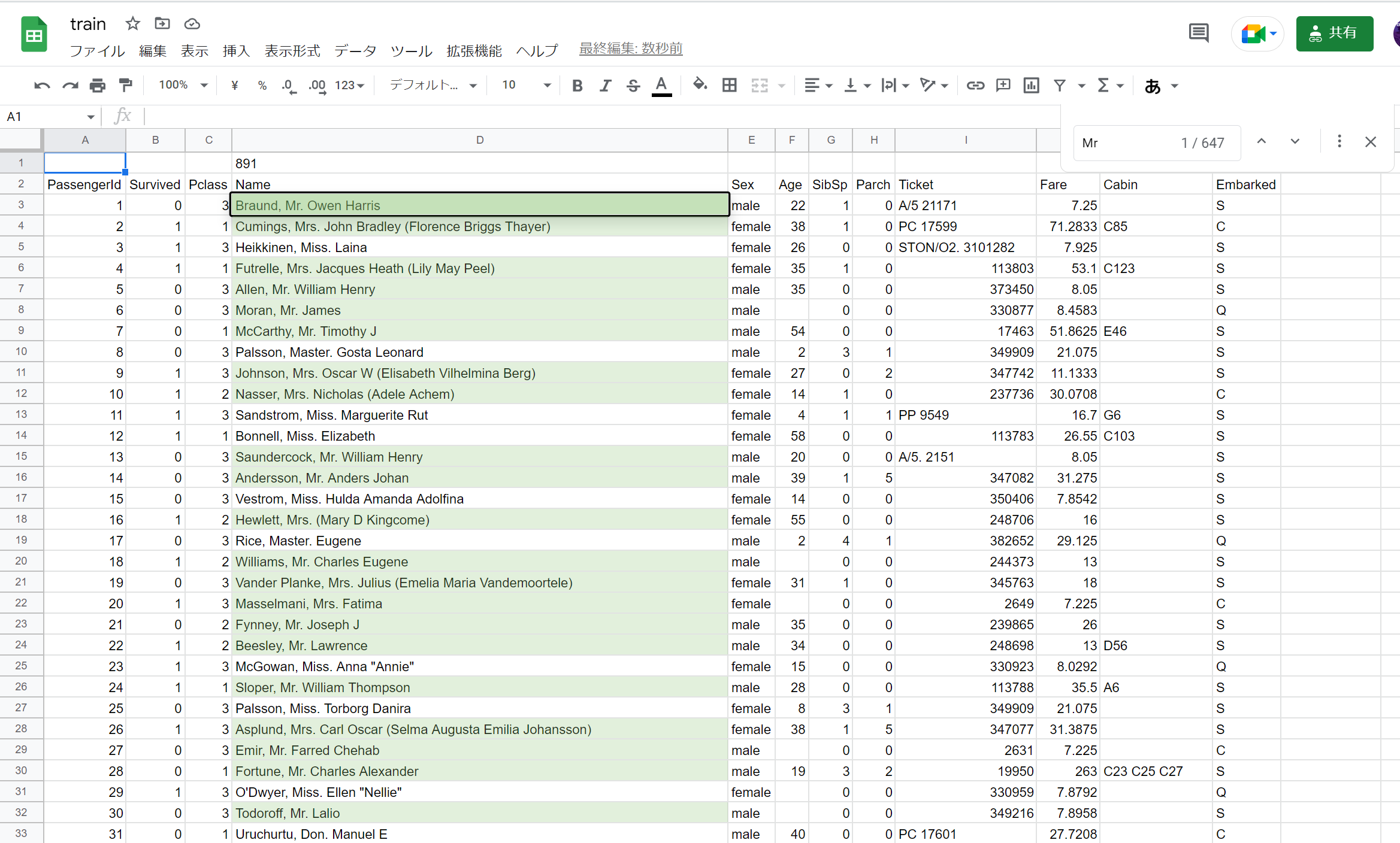
「Mr.」以外にも、「Miss.」や「Mrs.」など、いわゆる敬称(honor)にデータの偏りが存在しそうなので、集計してみましょう
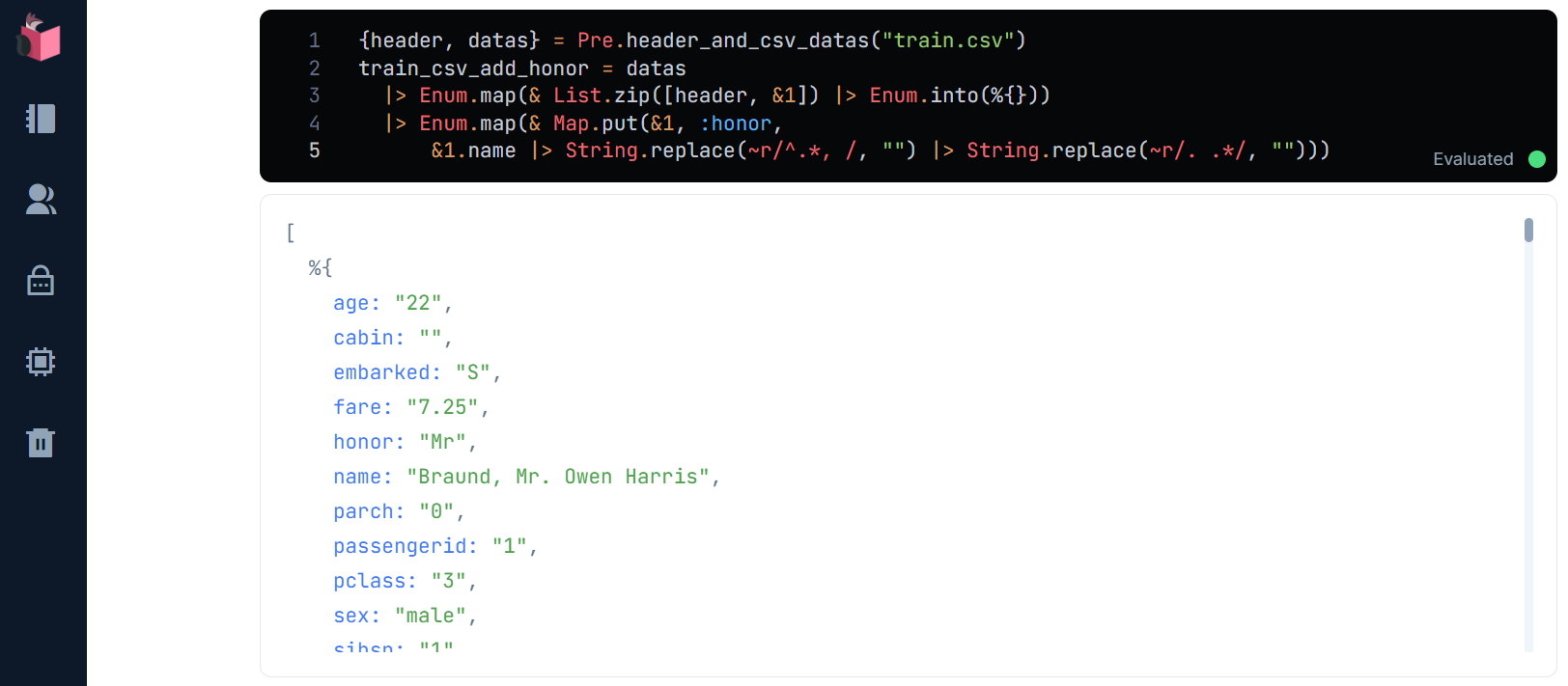
まずは、honorに敬称を切り出します
{header, datas} = Pre.header_and_csv_datas("train.csv")
train_csv_add_honor = datas
|> Enum.map(& List.zip([header, &1]) |> Enum.into(%{}))
|> Enum.map(& Map.put(&1, :honor,
&1.name |> String.replace(~r/^.*, /, "") |> String.replace(~r/. .*/, "")))
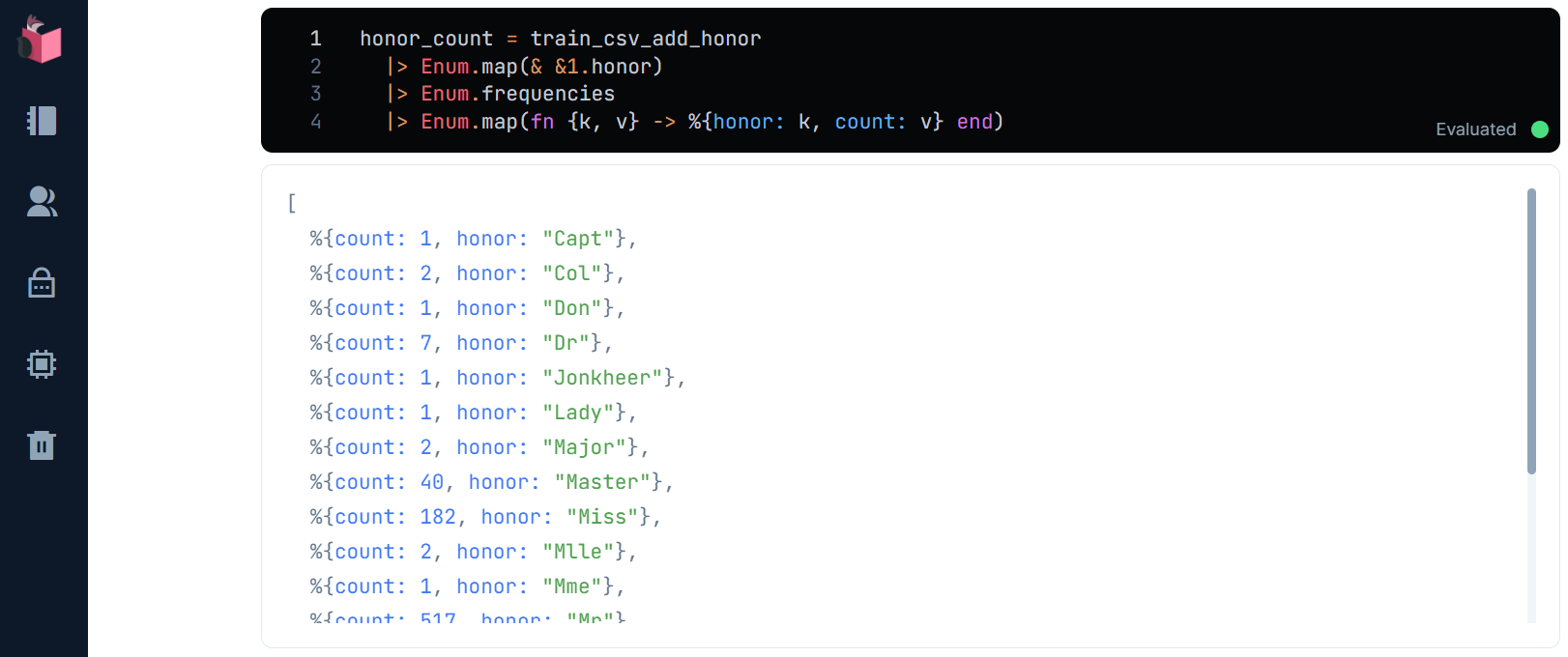
honorの出現頻度をEnum.frequenciesで調べます
honor_count = train_csv_add_honor
|> Enum.map(& &1.honor)
|> Enum.frequencies
|> Enum.map(fn {k, v} -> %{honor: k, count: v} end)
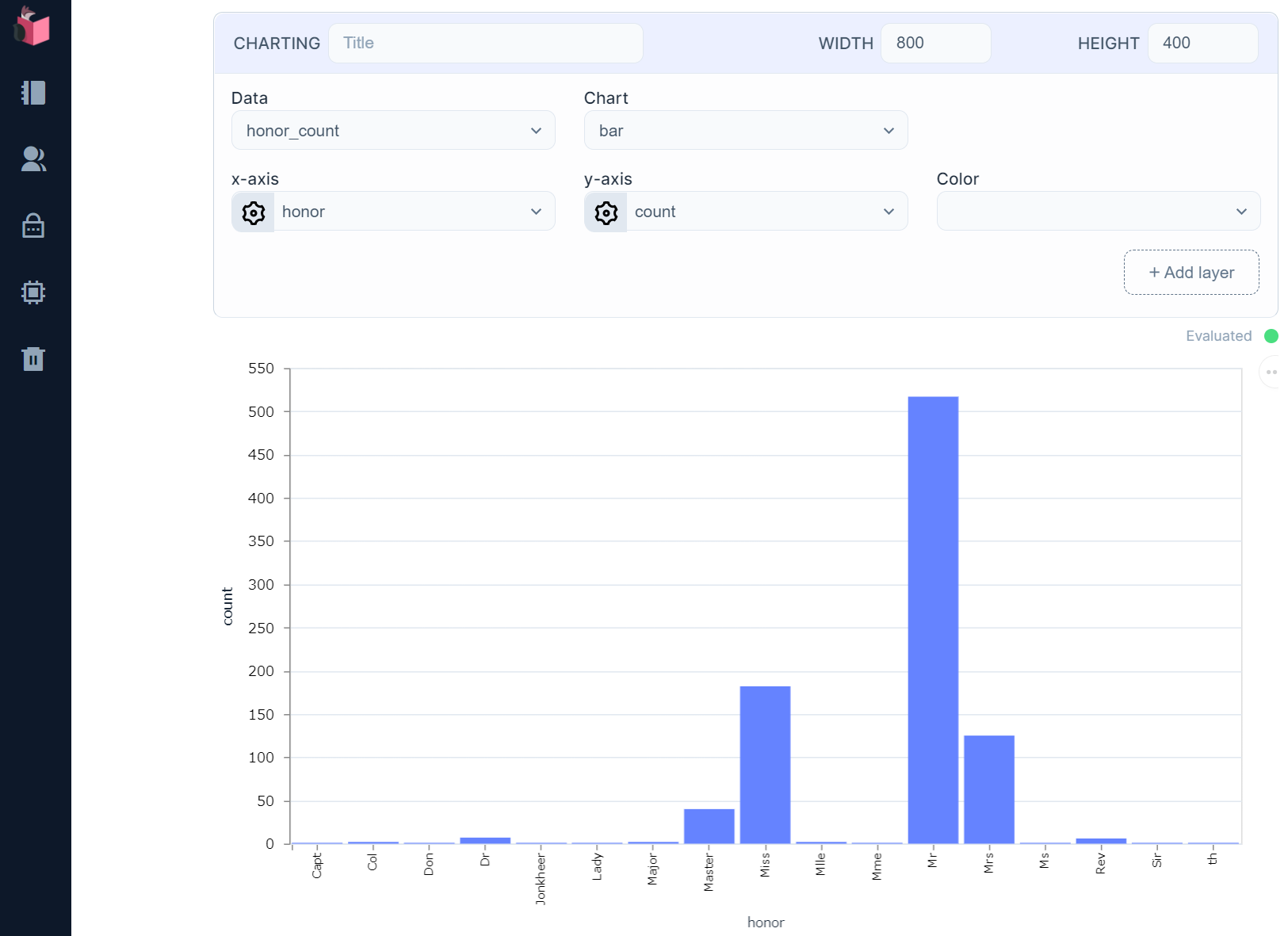
[Chart]で表示させると、「Mr.」に大きな偏りがあり、次いで「Miss.」「Mrs.」が多いという偏りが確認できました
この偏りと、survivedが示す生存有無の間に相関関係があれば、それは重要な特徴となります … さっそく調べてみましょう
survived_honor_count = train_csv_add_honor
|> Enum.map(& Map.take(&1, [:honor, :survived]))
|> Enum.frequencies
|> Enum.map(fn {k, v} -> %{sv_honor: "#{k.honor}-#{k.survived}", count: v} end)
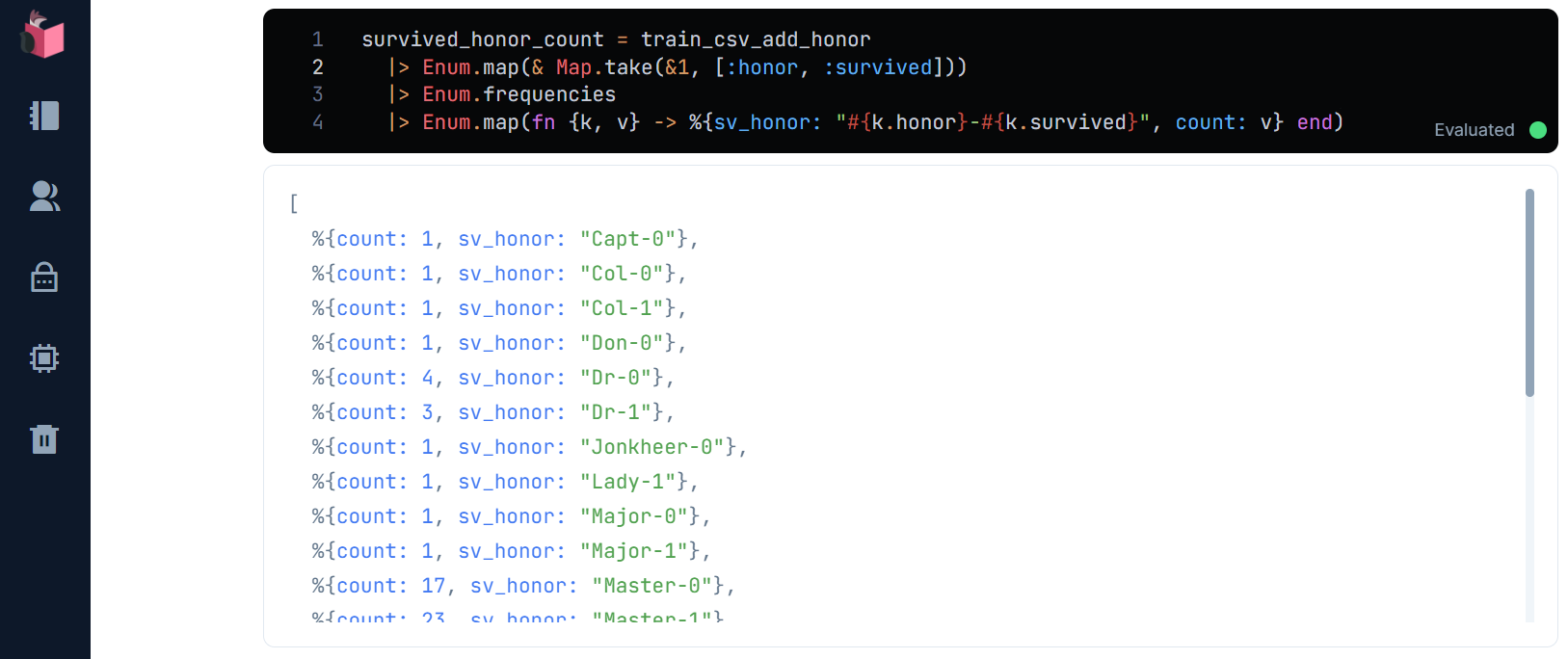
すると、「Mr.」の死亡率が凄まじいことが分かり、逆に「Miss.」「Mrs.」は、生存率の方が明らかに高いことが分かります
この特徴を学習や予測に使えば、精度を向上できそうです(逆に、前回はnameを切り捨てていたので、その分、精度が下がっていたのかも知れません)
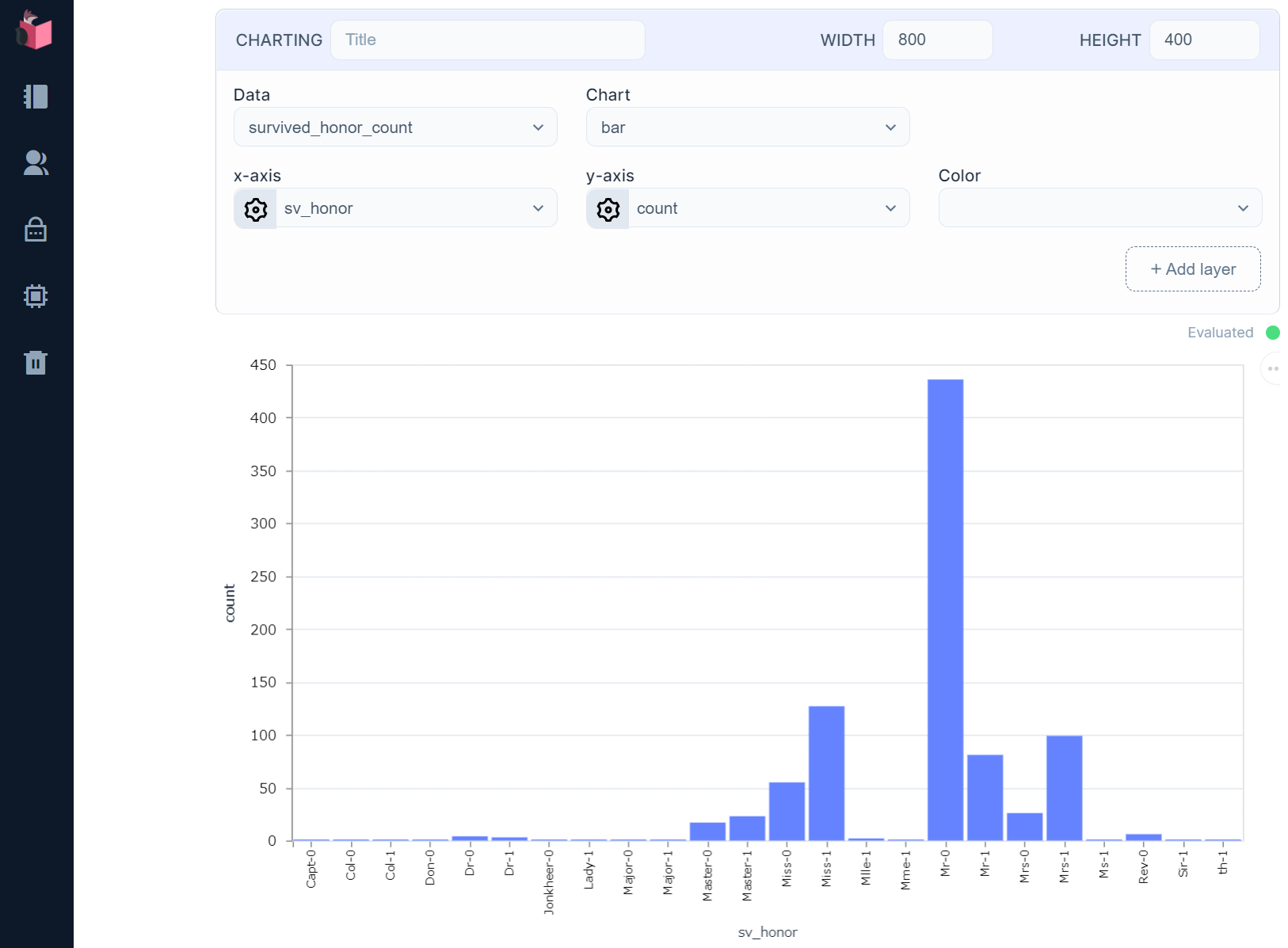
参考までに、この傾向とsexの関連性も見てみましょう
train_csv_survived_sex = datas
|> Enum.map(& List.zip([header, &1]) |> Enum.into(%{}))
|> Enum.map(& Map.take(&1, [:sex, :survived]))
|> Enum.frequencies
|> Enum.map(fn {k, v} -> %{sv_sex: "#{k.sex}-#{k.survived}", count: v} end)
やはり、男性の死亡率が凄まじいことが分かります
さて、有効なEDAができたので、これをPreモジュールに反映してみましょう
なお、honorはカテゴリ値なので、to_dummiesの対象としても追加します
defmodule Pre do
def count_missings(datas) do
…
def for_dummies(datas) do
datas
+ |> Enum.map(& Map.put(&1, :honor,
+ &1.name |> String.replace(~r/^.*, /, "") |> String.replace(~r/. .*/, "")))
|> drop([:cabin, :name, :ticket])
…
def process(datas, train_datas) do
for_dummies_train_data = for_dummies(train_datas)
datas
|> for_dummies
+ |> to_dummies(for_dummies_train_data, [:embarked, :sex, :honor])
|> integer_string_to_float([:age, :fare, :parch, :pclass, :sibsp])
…
おや? … 学習は上手くいってますが、その後の未知データの予測中にエラーが出たようです …
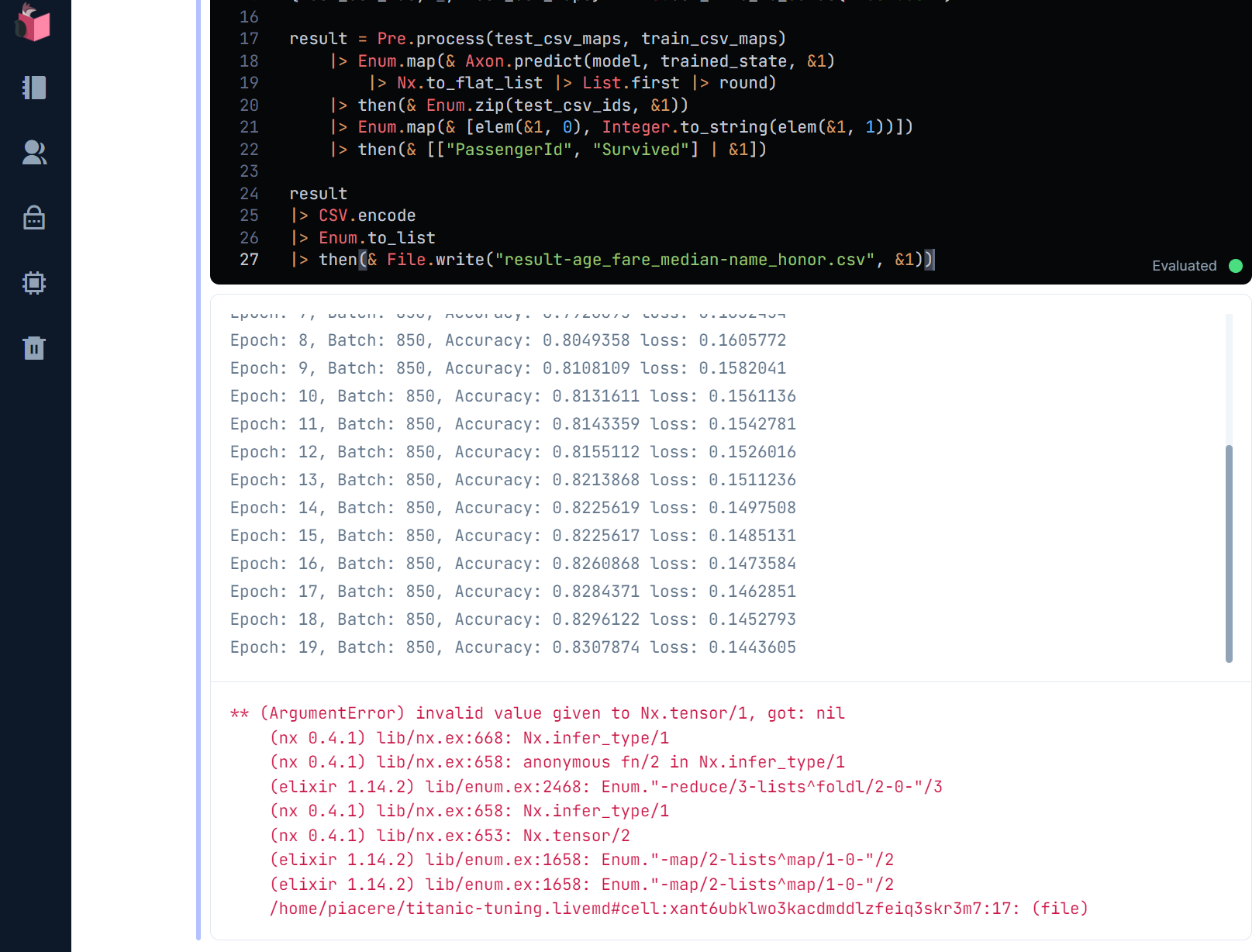
未知データ中に、学習データに無いパターンが存在しているかも知れません
考えられるパターンは、以下2通りでしょう
- 「, 」と「. 」で区切れない
nameが存在する - 学習データに無い
honorのバリエーション
未知データのnameを確認してみましょう
{test_csv_ids, _, test_csv_maps} = Pre.csv_file_to_datas("test.csv")
test_csv_maps
|> Enum.map(& Map.put(&1, :honor,
&1.name |> String.replace(~r/^.*, /, "") |> String.replace(~r/. .*/, "")))
|> Enum.map(& &1.honor)
|> Enum.frequencies
|> Enum.map(fn {k, v} -> %{honor: k, count: v} end)
test.csvのhonorに、空白や、元の値まんまのものが無いので、「, 」と「. 」で区切れないnameは無さそうです
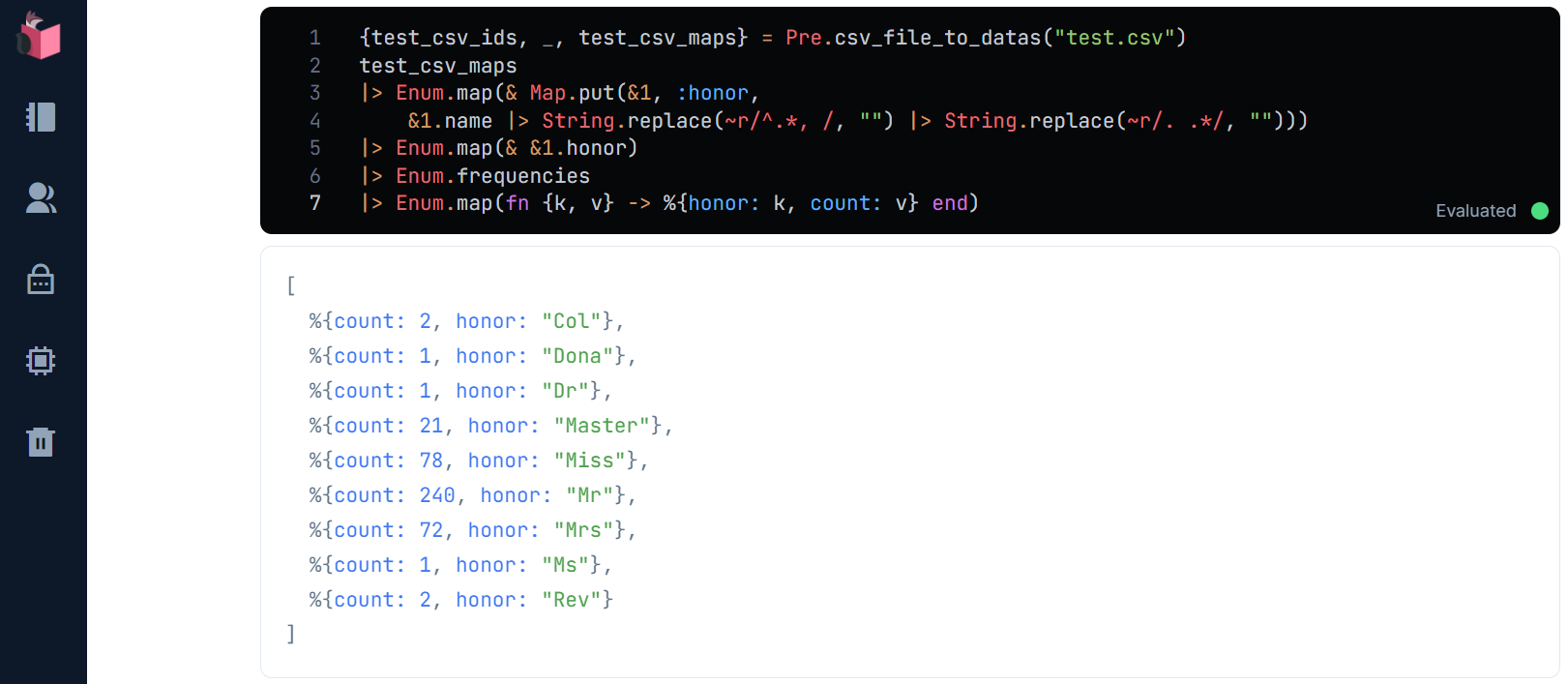
学習データに無いhonorのバリエーションは、どうでしょう?
train_honor = train_csv_add_honor |> Enum.map(& &1.honor) |> Enum.uniq
test_honor = test_csv_maps
|> Enum.map(& Map.put(&1, :honor,
&1.name |> String.replace(~r/^.*, /, "") |> String.replace(~r/. .*/, "")))
|> Enum.map(& &1.honor) |> Enum.uniq
test_honor -- train_honor
どうやら、未知データのみに存在する敬称Donaが存在するようです
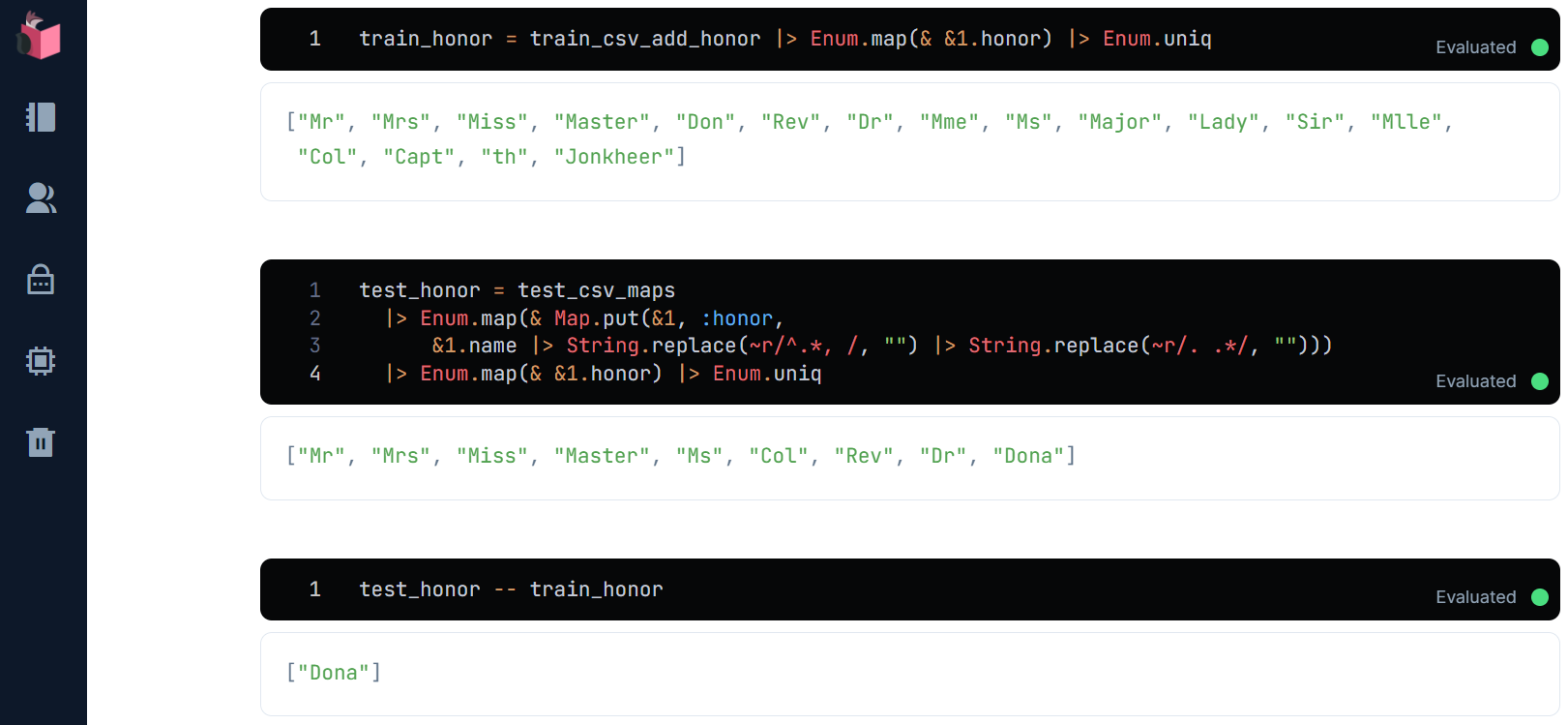
対策としては、以下2通りです
- 未知データのみの差分もカテゴリ値に追加する
- 学習データに無いカテゴリ値が出現したら強制的に数値化する
実際の運用を想定すると、前者で対応することは現実的では無いため、後者での対応をした上で、対象外の未知データ出現をシステム管理者/保守対応者にアラートする(その後、モデルを改修し、デプロイし直す)等の対応が妥当でしょう
ここでは、学習データに無いカテゴリ値が出現したら、強制的にカテゴリ値と被らない数値「10」に置き換えることとします
defmodule Pre do
def count_missings(datas) do
…
def to_dummies(datas, train_maps, keys) do
keys
|> Enum.reduce(datas, fn key, acc ->
acc
+ |> Enum.map(& Map.put(&1, key,
+ case make_dummies(train_maps, key)[Map.get(&1, key)] do
+ nil -> 10.0
+ n -> n
+ end))
+ end)
end
…
敬称も含めた予測でKaggle提出した結果は以下の通りで、精度が向上しています
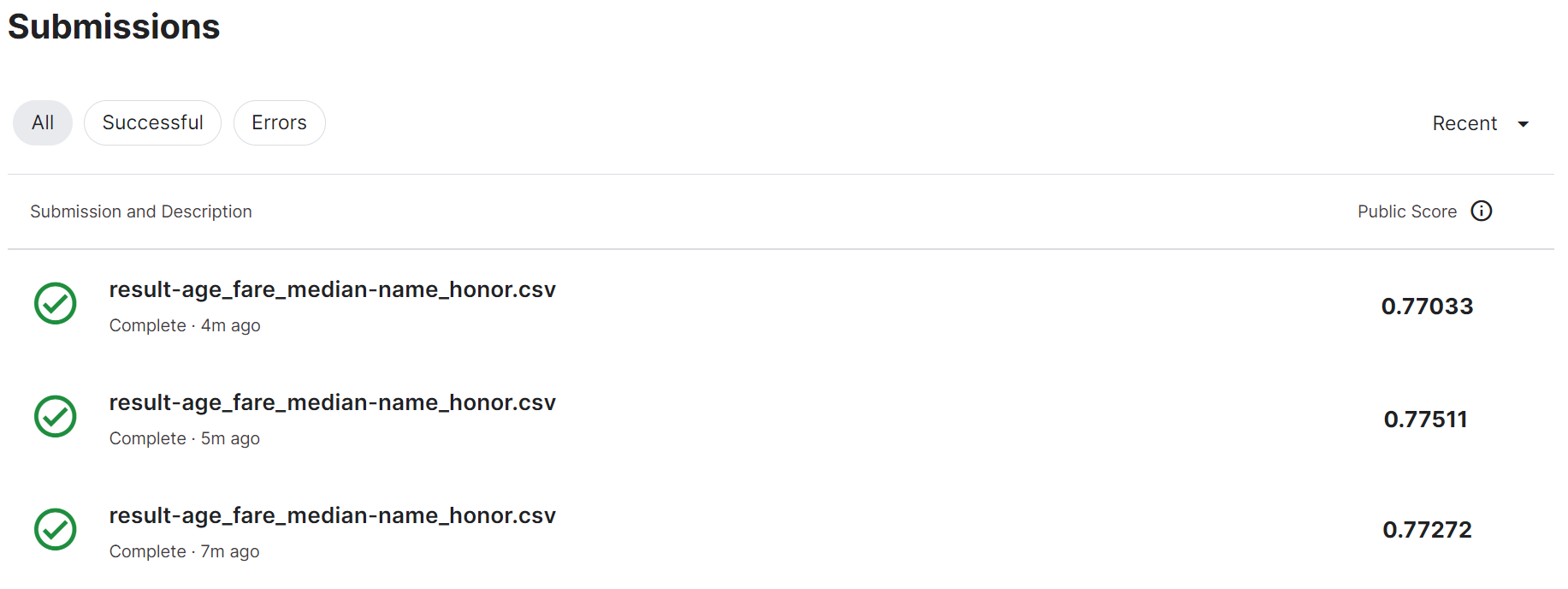
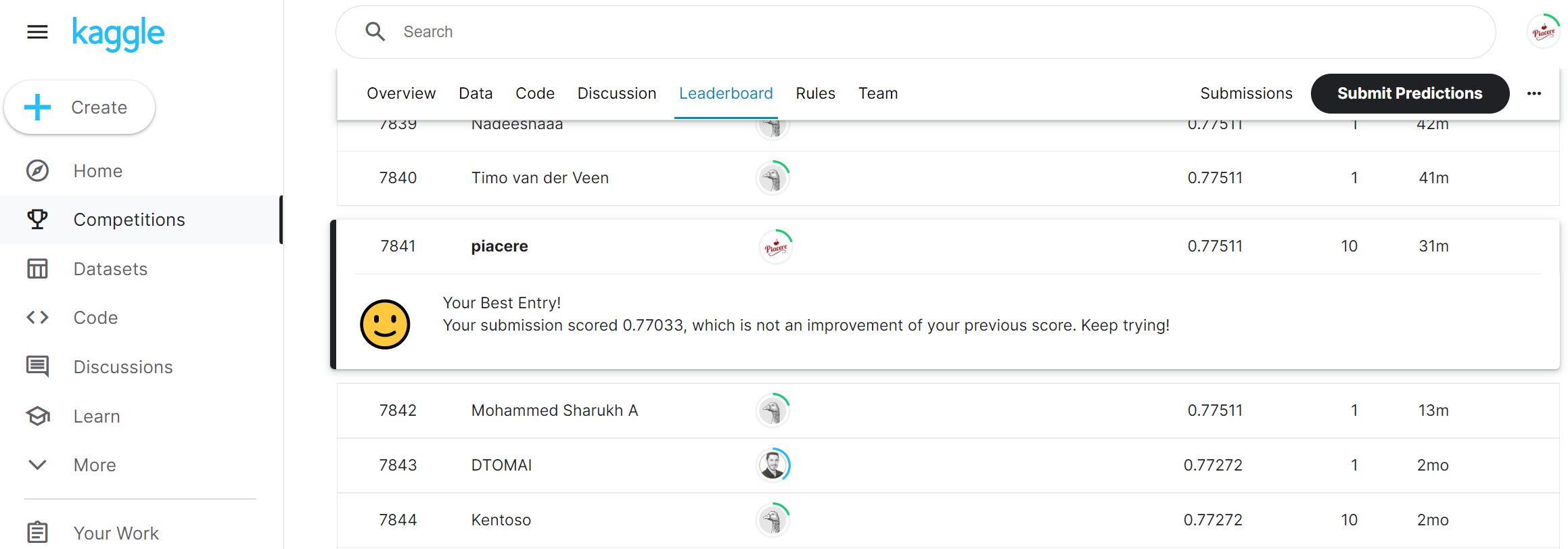
「Leaderboard」タブから全体ランキングを確認すると、7,841位を獲得しており、前回の12,292位から4,000位以上、向上しました
③自習:更なる「データ前処理」の改善について
ここまでの改善で、ランキングは上昇したのですが、もっと精度を向上させることが可能です
たとえば、タイタニック問題では、下記のようなアイデアが有効なことが分かっています(今回コラムで、これらを分析するヒント/コードは出していますので、ぜひトライして上位入賞を試みてください)
-
nameの「敬称」以外の部分のラベルとの相関を利用する -
ageを年齢として扱うのでは無く、「年齢層」として集約する(fareも同様) - 家族の人数を示す
parchとsibspを合計して別項目化する(次元圧縮と言います) - 数値化した後、「標準化」を行い、データの粗さを緩和する
-
pclassのラベルとの相関を分析し、pclassそのものを次元圧縮する -
ticketの文字種/パターンを分析し、文字種/パターン毎のラベルとの相関を利用する - 欠損値の多い
cabinから特徴を見出す -
主成分分析を行い、寄与率の低い項目を除去する ※前述の
honorとsexの高相関はこの対象 - 上記した、他の補完アルゴリズムを試す
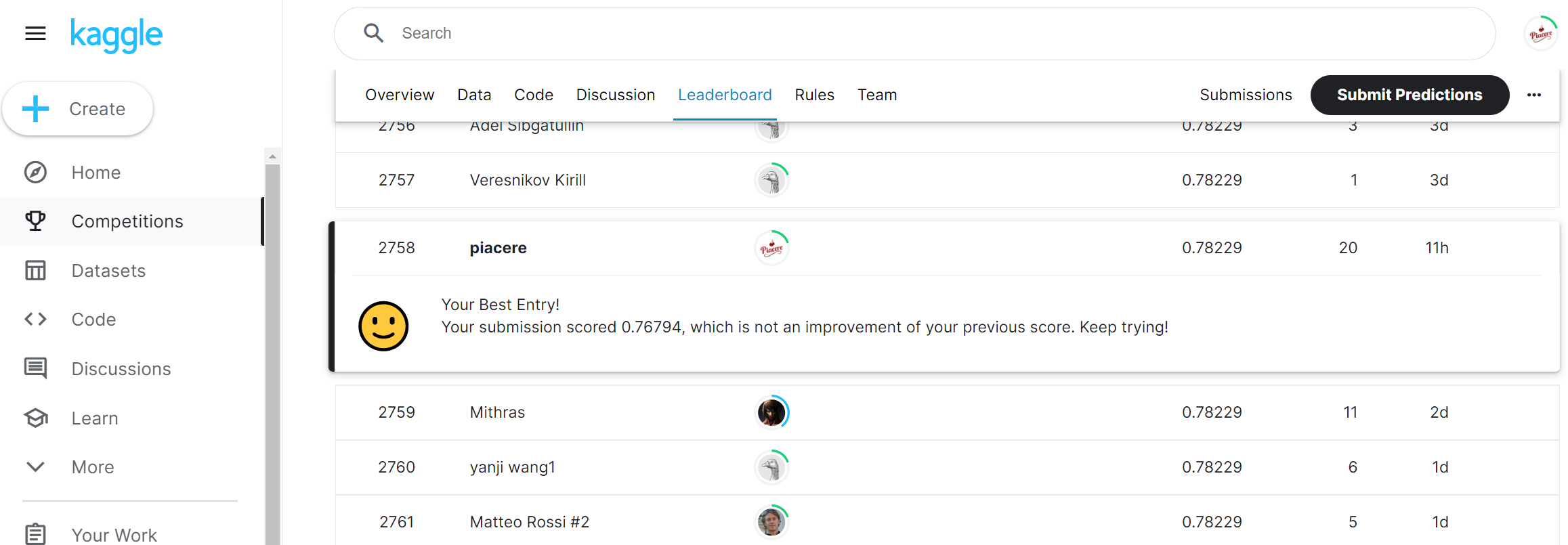
参考までに、ここまでの改善に加え、parchとsibspの次元圧縮と「標準化」を行うと、下図の通り1%くらい上昇し、2,758位にアップしました(この2つは非常に重要なテクニックなので、どこかで講義化したいと思います)
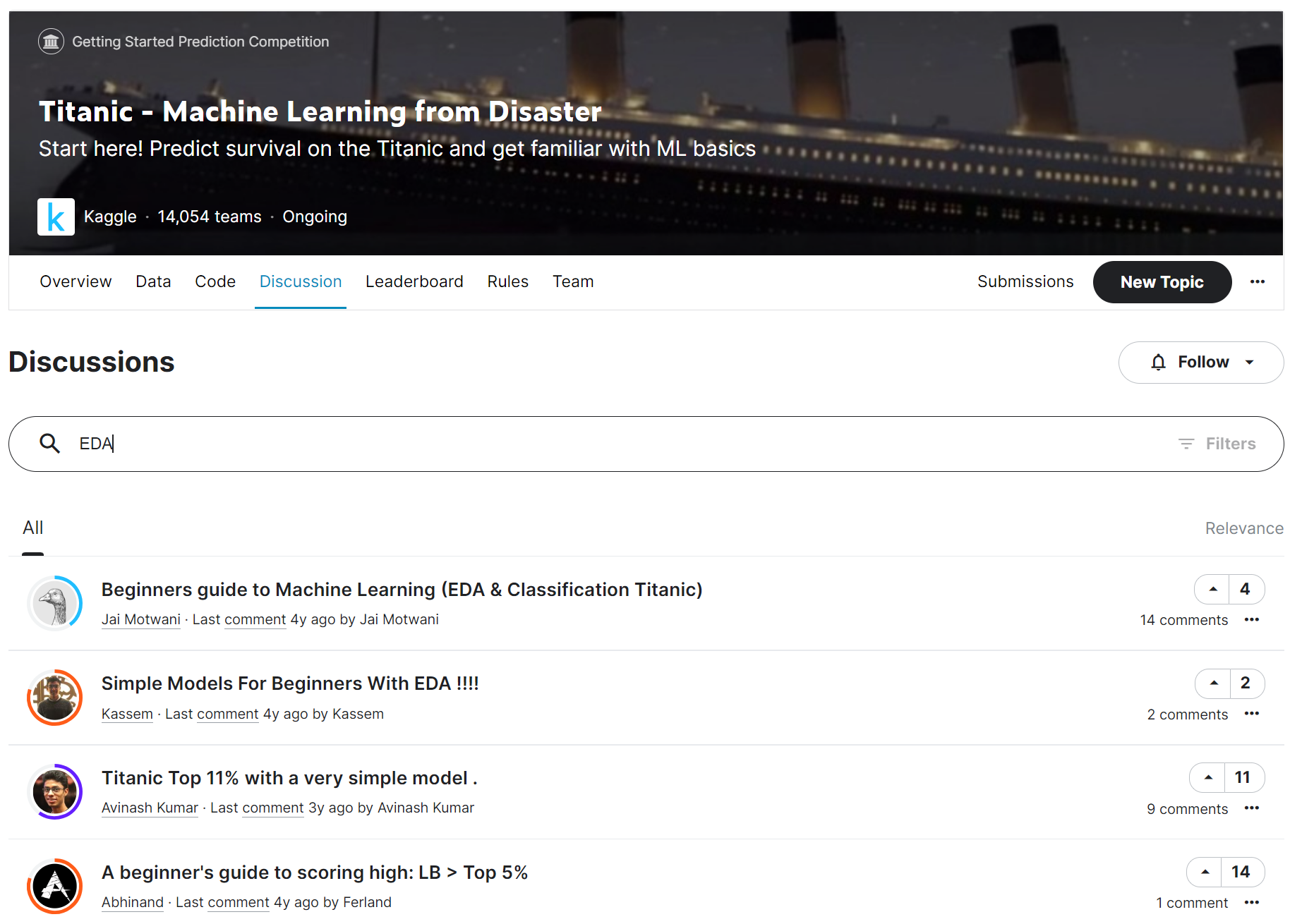
EDAをより追求したい方は、下記のKaggleの「Code」で「EDA」を検索すると、様々なEDA例が投稿されており、「データ処理」全般の良い教材でもあるため、AI・MLやデータサイエンスの分野に詳しくなりたい方は、ここをスタート地点にすることをオススメします
https://www.kaggle.com/competitions/titanic/code?searchQuery=EDA
今回内容が難しいと感じた方へ
下記コミュニティのイベントで本シリーズ内容の解説やハンズオンをしていますので、ご利用ください
終わり
今回は、Kaggleランキング向上のために、「データ前処理」の改善を行いました
機械学習をマスターするためには、モデルの構築以前のところのデータに対する「統計」と「EDA」が重要であることが体感できたでしょうか?
次回は最終回、Elixir AI・MLでどんなことが出来るのか、や、ElixirでAI・MLを構築するメリット … そして、今後どのような活動を拡げていくのかについて語ります
主催/運営しているElixirコミュニティ紹介
4. LiveView JP : A place to mob-program in LiveView, LiveBook+Nx+Axon, and elixir-desktop
5. Neos.ex : A place to connecting Elixir and NeosVR to create a new world
Elixir生誕10周年を祝い、"Elixirの現在" に追いつける
Elixir界隈に激震をもたらした2021年の大変動を記したコラム群を、全11本のカテゴリで日々アップデートしています
本コラムも、第3弾「Elixir/Livebook+NxでPythonっぽくAI・ML」に追加しています
Elixir生誕10周年祭■第1弾:Elixir/Phoenixで会員制サイト構築は瞬殺
|> Elixir生誕10周年祭■第2弾:Elixir/LiveViewでJS不要のSPA+Tailwind UI
|> Elixir生誕10周年祭■第3弾:Elixir/Livebook+NxでPythonっぽくAI・M
|> Elixir生誕10周年祭■第4弾:ElixirDesktopスマホネイティブアプリ開発
|> Elixir生誕10周年祭■第5弾:ElixirでWebAssemblyにトライ
|> Elixir生誕10周年祭■第6弾:Elixir/WebSocketでVR/AR/メタバース連携
|> Elixir生誕10周年祭■第7弾:Elixirでエッジコンピューティング開発
|> Elixir生誕10周年祭■第8弾:Elixirで海外進出を目指す
|> Elixir生誕10周年祭■第9弾:ElixirでWeb3/DID/DAO
|> Elixir生誕10周年祭■第10弾:Elixir/Phoenix 1.7プレビュー
|> Elixir生誕10周年祭■第11弾:Elixir Chip(専用プロセッサ)を作る
明日は、@mnishiguchi さんで「Elixirをデコンパイル(逆コンパイル)」です