オミータです。ツイッターで人工知能や他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
他にも次のような記事を書いていますので興味があればぜひ!
プーリング層だけでも充分!?衝撃の画像認識モデルMetaFormerを解説!
Vision Transformer(以下、ViT)はなぜ高い性能を叩き出せるのでしょうか。「そんなのAttentionのおかげに決まってるでしょ。」そんな声が聞こえてきます。私もそう思っていました。ただ、本当にそうなのでしょうか。今回ご紹介する論文("MetaFormer is Actually What You Need for Vision", Yu, W., et. al, (2021)
)では、ViTが高い性能を叩き出す一番の理由はAttentionではない、という主張を展開します。より正確に言えば、「ViTはMetaFormerの形を取っているからこそ高い性能を叩き出すのだ」、という主張を展開していきます。「MetaFormerって何?」「どうしてそんなことが言えるの?」「てかそもそもViTってなんだっけ?」本記事では、それらの疑問について論文をもとに解説していきます。まずはViTの復習から入り、MetaFormerそしてプーリング層を用いたPoolFormerについて解説していきます。それでは早速この衝撃的なモデルMetaFormerについて見ていきましょう!
-
解説の前に…:
本論文では、MetaFormerの最もシンプルな形であるPoolFormerの性能の高さを実験的に示すことにより、MetaFormerこそが画像認識の新しいベースラインである、という主張を展開していきます。
本記事の流れ:
- 忙しい方へ
-
MetaFormerの解説
- Vision Transformerの復習
- MetaFormerの解説
- PoolFormerの詳解
-
PoolFormerの実験結果
- ベンチマークデータセットによる実験結果
- アブレーションスタディ
- まとめと所感
- 補足
- 参考
原論文: "MetaFormer is Actually What You Need for Vision", Yu, W., Luo, M., Zhou, P., Si, C., Zhou, Y., Wang, X., Feng, F., Yan, S. (2021)
公式実装: PyTorch
0. 忙しい方へ
-
MetaFormerは、Vision Transformerを一般化したモデルだよ
- ViT: Attentionを用いたMetaFormer
- MLP-Mixer: MLPを用いたMetaFormer
- PoolFormer: Poolingを用いたMetaFormer。階層的構造を採用。
-
PoolFormerは、以下のタスクでRSB-ResNet/DeiT/ResMLPなどよりも高い性能を示したよ
- 画像分類(下図)
- 物体検出
- インスタンスセグメンテーション
- セマンティックセグメンテーション
- MetaFormerこそ画像認識における新たなベースラインモデルとなるべき(=MetaFormer is Actually What You Need for Vision)、という主張をしているよ
| 略語 | 正式名称 |
|---|---|
| ViT | Vision Transformer |
| MACs | Multiply-Accumulate |
1. MetaFormerの解説
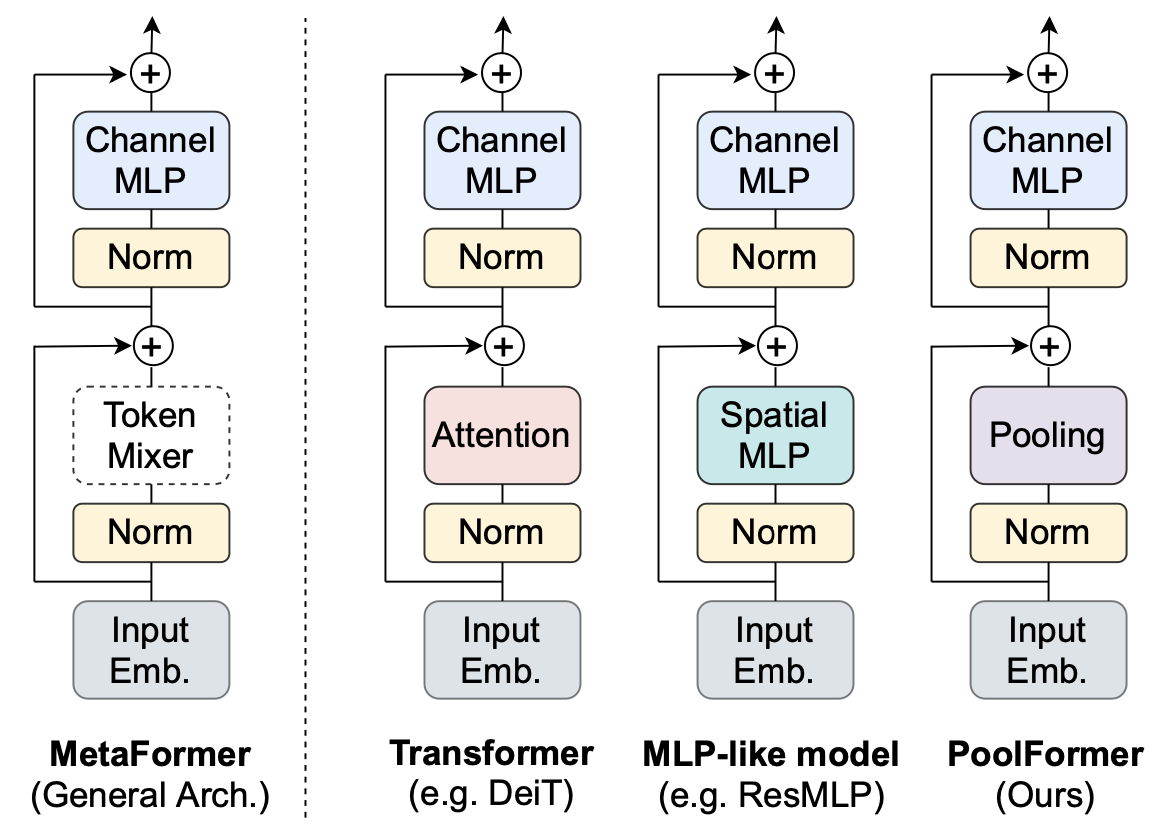
まず皆さんに認識してていただきたいのは、MetaFormerとは実在するモデルではない、ということです。MetaFormerはあくまで、ViTやMLP-Mixerなどの一般形になります。プログラミング的に言うと、MetaFormerが抽象クラスでViTがそれを実現するサブクラス、という具合でしょうか。(クラスvsインスタンスでも良い気がします。)
この章ではまず、Vision Transformerの復習を行います。その後、ViTなどの一般形であるMetaFormerを導入し、最後に最もシンプルなMetaFormerであるPoolFormerについて解説していきます。
1.1 Vision Transformerの復習
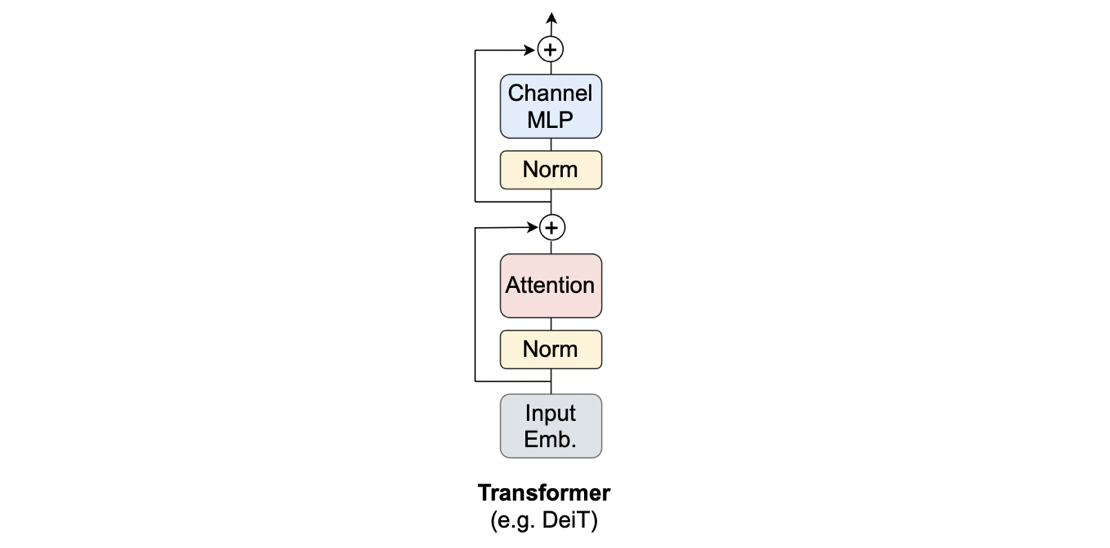
Vision Transformer(以下、ViT)について簡単に復習しましょう。すでにViTを理解している方は読み飛ばして結構です。上図をご覧ください。上図は大きく2つのパートに分かれます。それは、Input Emb. と Input Emb.以外です。Input Emb.は、入力画像の埋め込みの訳ですから、パッチ埋め込み -> クラストークンの結合 -> 位置エンコーディングの加算を行います。Input Emb.が終わると、続いて「Input Emb.以外」、つまり、Norm -> Attention -> Norm -> ChannelMLPへと流れていきます。ViTでは、Norm->...->ChannleMLPが1つのブロックになっており、このブロックを多段に重ねることでViTがほぼ完成します。「ほぼ」と言ったのは、本当のViTとなるには、最終層としてMLP Headを加える必要があるためです。今回のMetaFormerでは上図がViTを表していることさえわかれば良いので、ViTについてより詳しく知りたい方は画像認識の大革命。AI界で話題爆発中の「Vision Transformer」を解説!をご参照ください。
ここで、Attentionは、トークン(≒パッチ)同士をごちゃ混ぜにする役割を担っているということを意識しておいてください。ここまでを式でも表してみましょう(式と呼ぶのもおこがましいですが。。。)。まずInput Emb.を次のように書きます。ここで入力は画像$I\in\mathbb{R}^{C\times H\times W}$で、出力はそのパッチ埋め込み$X\in\mathbb{R}^{N\times C}$になります。
X=\text{InputEmb}(I)
続いて、Attention辺りを次の式で表します。ここで$\text{Norm}(\cdot)$はノーマライゼーション層で、生粋のViTの場合はレイヤーノーム(LayerNorm)になります。
Y=\text{Attention}(\text{Norm}(X))+X
そして最後のChannel MLPのところを次の式で表します。ここで$\sigma(\cdot)$は活性化関数で、生粋のViTの場合はGELUが使われます。また、$W_1\in\mathbb{R}^{C\times rC}$、$W_2\in\mathbb{R}^{rC\times C}$は全結合層で、$r$は拡張率(Expansion ratio)で生粋のViTでは$r=4$などです。
Z=\sigma(\text{Norm}(Y)W_{1})W_{2} + Y
それではこれの一般形であるMetaFormerについて見ていきましょう。
1.2 MetaFormerの解説
1.2.1 MLP-Mixer
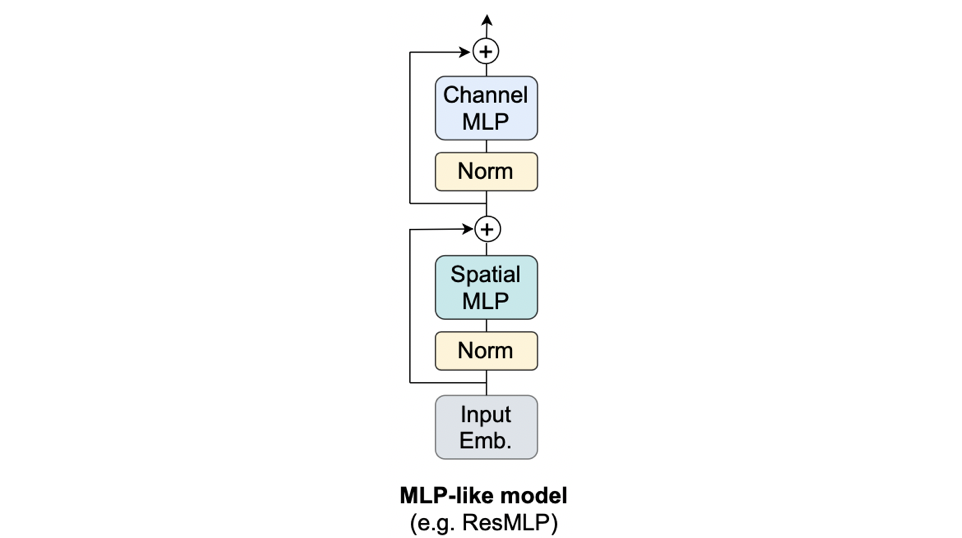
前項で、「Attentionは、トークン(≒パッチ)同士をごちゃ混ぜにする役割」というふうに述べました。この「トークン同士をごちゃ混ぜにする役割」を、AttentionではなくMLPに任せたものは上の図のように示せます。これは世間を揺るがしたあのMLP-Mixer[Tolstikhin, I.(2021)](やResMLP)です。ViTとの違いは、トークン同士をごちゃ混ぜにする役割をMLPに任せたという点です。変更した箇所だけを式で表すと、次のように表せます。
Y=\text{SpatialMLP}(\text{Norm}(X))+X
$\text{Attention}(\cdot)$が$\text{SpatialMLP}(\cdot)$に変わっただけですね。このように、トークン同士をごちゃ混ぜにする役割を何に任せるかによってViT系だったりMLP系だったりとアーキテクチャの呼称が変わっていることが分かります。それでは、これらを一般化したMetaFormerを見ていきましょう。
1.2.2 MetaFormer
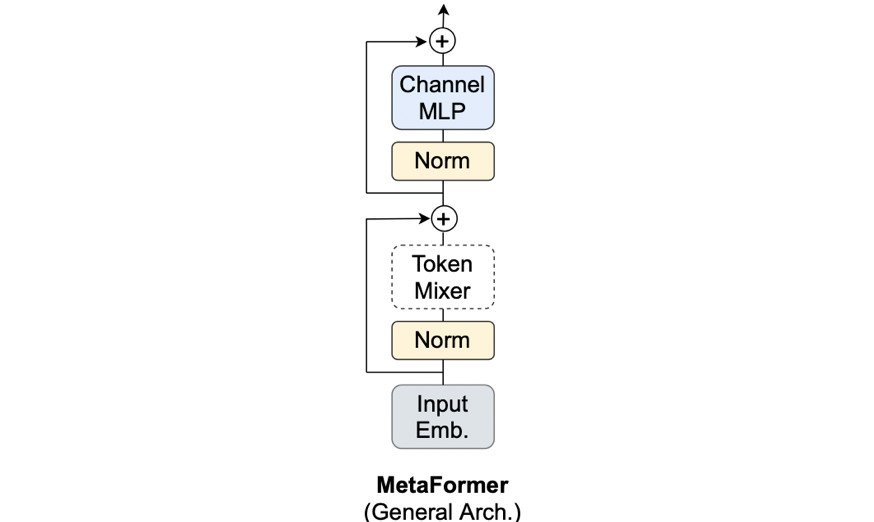
上図がViT系やMLP系などの一般形であるMetaFormerです。AttentionやSpatial MLPが居た箇所が、点線のToken Mixerというものに変わっています。つまり、こうなっています。
Y=\text{TokenMixer}(\text{Norm}(X))+X
このToken Mixer(=トークン同士をごちゃ混ぜにするやつ)にAttentionを入れればViT系、MLPを入れればMLP(-Mixer)系ということでした。本論文では、最近の画像認識モデルはこのMetaFormerの形に則っているからこそ強いのではないか(=MetaFormer is Actually What You Need for Vision)、という主張をしています。ただ、どうすればこの主張の妥当性を確認できるのでしょうか。Attentionが良いのではなく、MetaFormerという構造が良いと言いたいのですから、Token Mixerに「最も単純な処理」を採用したモデルでも実験的に強いことが分かれば良さそうです。この「最も単純な処理」こそがプーリング層になります。
1.3 PoolFormerの解説
1.3.1 PoolFormerの概要
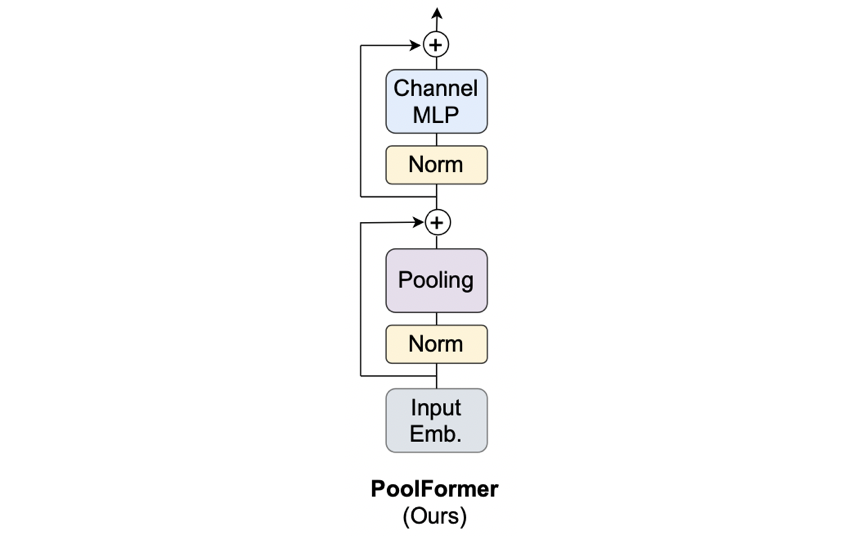
Token Mixerとして最もシンプルな処理を採用したモデルが割と高い性能を叩き出せれば、「MetaFormer is Actually What You Need for Vision」の妥当性が増しそうです。繰り返しになりますが、トークン同士をごちゃ混ぜにするやつの中で最もシンプルな処理こそがプーリング層でした。そのため、Token Mixerとしてプーリング層を採用し、そのMetaFormerのことをPoolFormerと呼びます。次のような感じでも書けます。
Y=\text{Pooling}(\text{Norm}(X))+X
PoolFormerで用いるのは平均プーリングです。平均プーリングは下図のような処理でしたね。
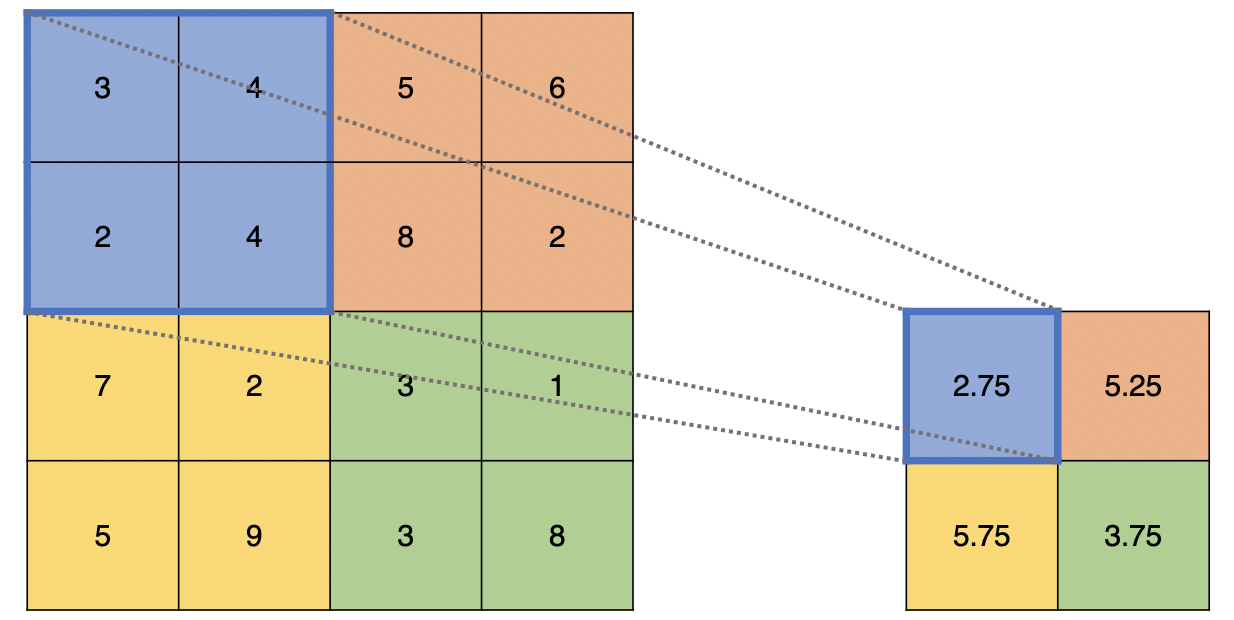
PoolFormerにおいて少し不思議なのが、$\text{Pooling}$の入力を$T\in\mathbb{R}^{C\times H\times W}$とした時の出力$T'$は次のようになっていることです。
T'_{;,i,j}=\frac{1}{K\times K}\sum_{p,q=1}^{K}(T_{:,i+p-\frac{K+1}{2},{j+q-\frac{K+1}{2}}})-T_{:,i,j}
右辺の第1項は、位置$(i,j)$で平均プーリング(カーネルサイズ$K$)した結果ですが、問題は第2項の$-T_{:,i,j}$です。元の自分で引き算してます。ここはみなさん疑問に思うようで、こちらの記事やこのissueでも取り上げられています。この引き算はPoolingの後にあるResidualを打ち消すためのものです。なぜ打ち消しているかというと、「打ち消した時の方が実験の結果が良かったから」という単純な理由のようです。このPoolFormerが本論文での実験中の主人公になるので、もう少し詳しくアーキテクチャを見ていきましょう。
1.3.2 PoolFormerのアーキテクチャ
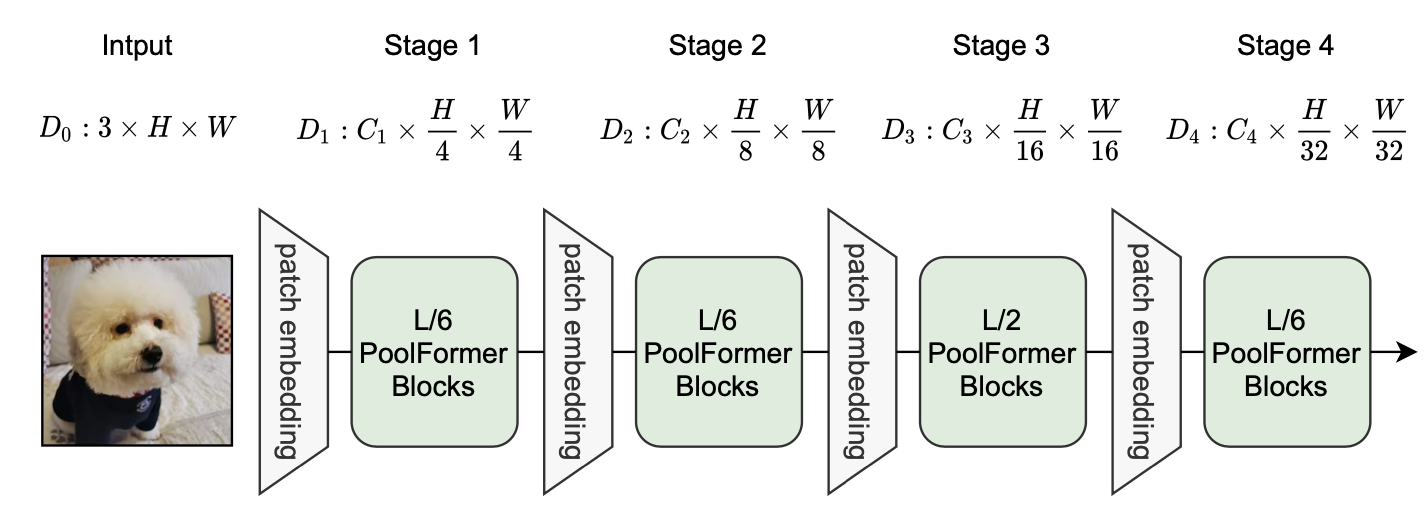
PoolFormerの具体的なアーキテクチャは上の図のようになります。
だいたい見ての通りですが、ここで特に重要となってくるのは、階層的構造(Hierarchical Structure) をとっていることでしょう。
この階層的構造とは、何も新しいものではなく、ResNetなどのCNNで採用されている「入力から出力に向けて画像サイズを徐々に小さくしていく」という基本的な構造のことです。上図からも分かるように、$\frac{H}{4}$や$\frac{H}{8}$など、画像サイズ単位でステージを分けていますね。PVT(Pyramid Vision Transformer)やSwin Transformerなど、最近のViTたちもこの階層的構造を採用し、高い性能を示しています。Pyramid Structureとも言われます。後述のアブレーションスタディでも触れますが、主に用いているプーリング層のカーネルサイズは$K=3$、ストライドは$s=2$になっています。また、ノーマライゼーション層はグループノーム(Group Norm)、活性化関数はGELUを用いています。また、PoolFormerには、積み上げるブロックの数などによってS12、S24、S36、M36、M48の5つのモデルがあります。詳しいアーキテクチャは5.1 アーキテクチャの詳細をご覧ください。
完全に余談になりますが、Patch Emb.としてOverlapped Patch Emb.(つまり、パッチ同士が少し重なっている)を用いているのが個人的に面白いと思いました(アーキテクチャの各ステージのPatch Embeddingたちです。)。最近のViTたちではパッチ同士をoverlapさせて埋め込むのが主流なのでしょうか。ご存知の方はコメントかTwitterで教えていただけると幸いです。それではPoolFormerを用いた実験結果を見ていきましょう。
3. PoolFormerの実験結果
本論文で行っている実験は、大きく2つのパートに分かれます。
-
ベンチマークデータセットによる実験結果
- 画像分類
- 物体検出およびインスタンスセグメンテーション
- セマンティックセグメンテーション
- アブレーションスタディ
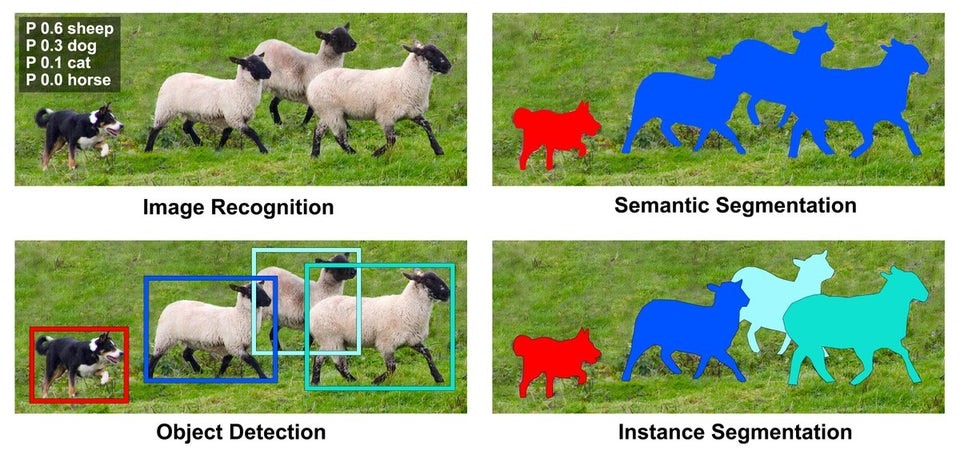
各タスクの違いは下の画像が分かりやすいのでこちらを参考として貼っておきます。それでは実験結果から見ていきましょう!
3.1 ベンチマークデータセットによる実験結果
3.1.1 画像分類
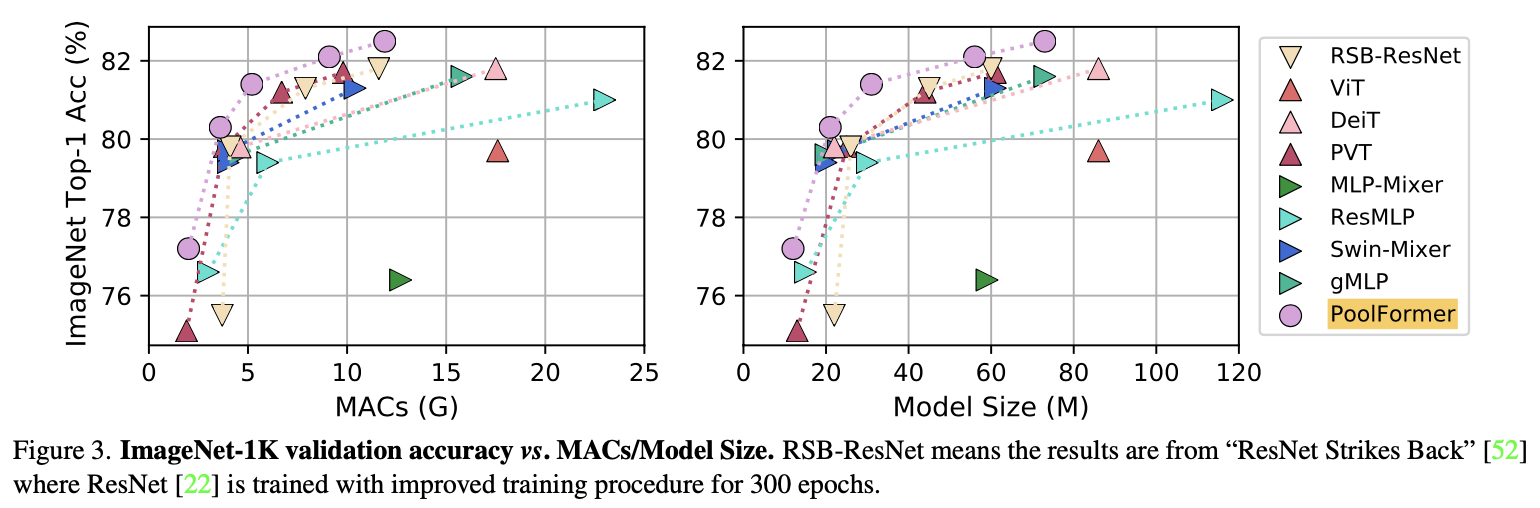
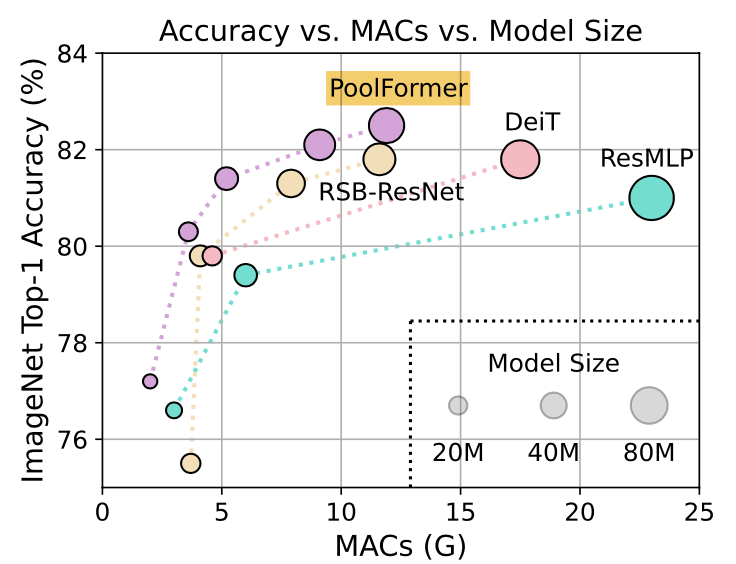
ImageNet-1kで学習し、評価したものです。横軸に左図はMACs、右図はモデルサイズを取り、縦軸はいずれもImageNet-1kの分類精度になっています。PoolFormerがDeiTやらResMLPを超える性能を示しています。さらに最近話題になった、ResNet Strikes BackのResNet(=RSB-ResNet)も見事にPoolFormerが超えています。PoolFormerすごいですね。ただのPoolingでこの性能ですから、驚きです。
3.1.2 物体検出およびインスタンスセグメンテーション
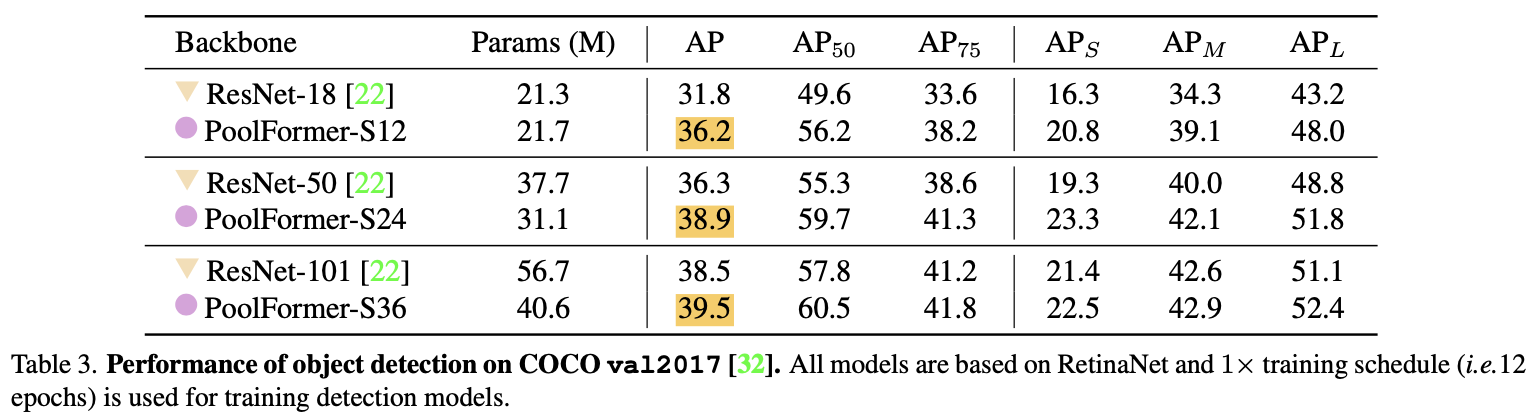
まずは物体検出の結果です。ImageNet-1kで事前学習を行なったPoolFormerをバックボーンとして用います。モデルには、RetinaNetを用いています。結果は、COCO2017のバリデーションデータになっています。PoolFormerの強さが分かります。特に、小さいモデルでの差が顕著で、APを見るとPoolFormer-S12がResNet-18を大きく上回っていることが分かりますね。ちなみに$\text{AP}_S, \text{AP}_M, \text{AP}_L$はオブジェクトの大きさごとに評価しているAPです。それぞれ、S:Small(大きさ$\lt32^2$px)、M:Medium($32^2\lt$大きさ$\lt96^2$px)、L:Large(大きさ$\gt96^2$px、となります。詳しくは、こちらをご参照ください。
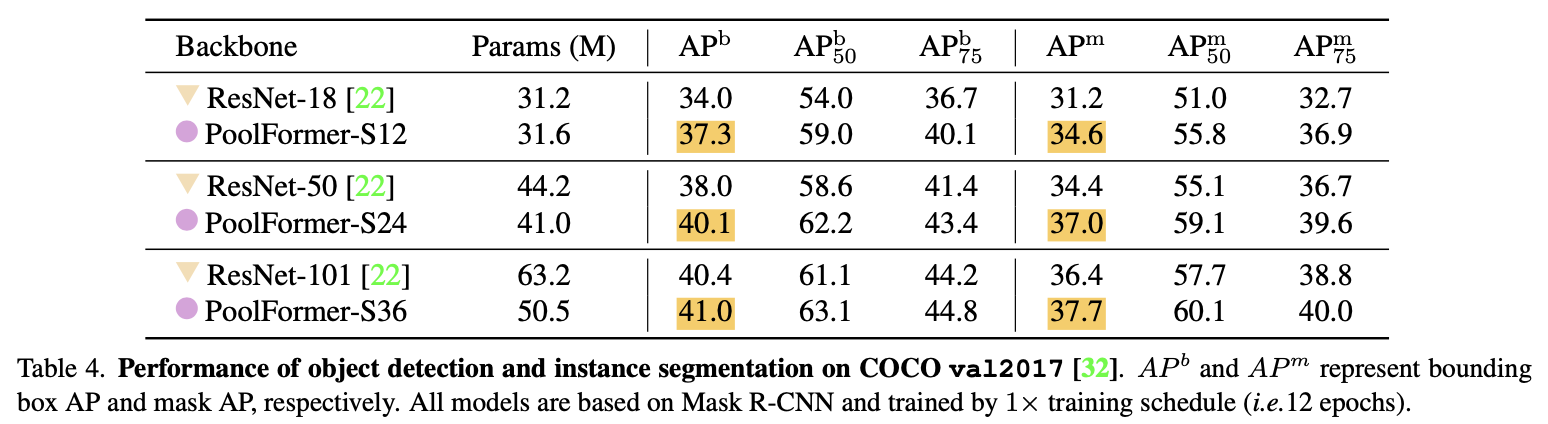
続けて物体検出およびインスタンスセグメンテーションの結果です。モデルには、Mask-RCNNを用いています。$\text{AP}^b$および$\text{AP}^m$がそれぞれ物体検出およびインスタンスセグメンテーションの結果ですが、ここでも先程と同様、特にPoolFormer-S12がResNet-18を大きく上回っていることが分かります。
3.1.3 セマンティックセグメンテーション

それではセマンティックセグメンテーションの結果を見ます。データはADE20Kで、モデルはSemantic FPNを用います。バックボーンとしてImageNet-1kで学習済みのPoolFormerを用います。ここでは対抗手法として、PVTやResNeXtも登場します。セマンティックセグメンテーションにおいてもPoolFormerが他のモデルよりも高い性能を示していることが分かります。
3.2 アブレーションスタディ

ここではMetaFormerのアーキテクチャをいろいろと探索しています。ImageNet-1Kの画像分類を用いて実験を行なっています。ベースラインとしてPoolFormer-S12を用いています。大切だと思った3つの箇所とその結果を黄色の蛍光マーカーで目立たせてみました。それぞれから以下のことが分かります。
- プーリング層すら使わない(Identity mapping)でもある程度の分類精度(74.3%)が出ている
- プーリングのカーネルサイズが大きい($K=9$)からと言って良いわけではない。
- 後半のステージをAttentionに帰ることでさらなる精度向上(+3.8%)が望める。
プーリング層を使わないでもある程度の分類精度が出ることや、後半をAttentionに変えることで精度向上が狙えることは、MetaFormerの可能性が垣間見えます。ちなみに、Normalizationおよび活性化関数については、グループノームおよびGELUが最も良いことが分かります(GELUに関してはSiLUと同じ結果ですが。)。
4. まとめと所感
論文中の特に大切な点をまとめると、以下の4点になると思います。
- MetaFormerは、ViTやMLP-Mixerなどを一般化したモデルだよ
- PoolFormerは、トークン同士をごちゃ混ぜにする役割を(平均)プーリングに任せたモデルだよ
- PoolFormerが幅広いタスクでViT系やMLP系よりも高い性能を示したよ
- MetaFormer is Actually What You Need for Vision
個人的には、このMetaFormerがコンピュータビジョンの基本的なアーキテクチャとして君臨するのかが見ものです。論文によると、MetaFormerの強さを自然言語などでも確かめていく、とのことなので後続の論文が出てきたらすぐに読みたいです。
Twitterで人工知能や他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ:
5. 補足
5.1 アーキテクチャの詳細
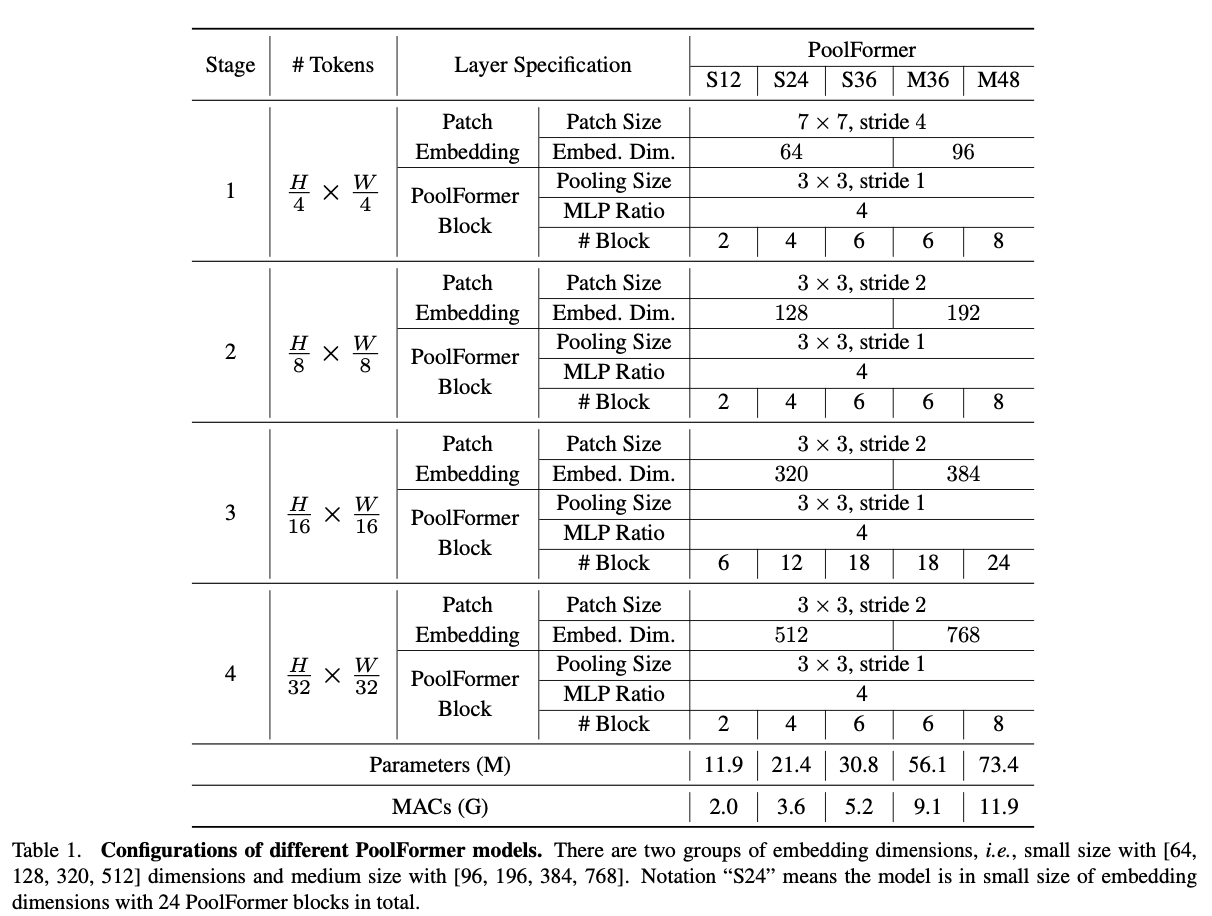
PoolFormerはモデルの大きさによって、S12やらM36やらなどがあります。S12において、SはPatch Emb.の埋め込みサイズが小さい(=Small)ということを示し、12はPoolFormerのブロック数を示しています。実際に上表を見ると、M36やM48は埋め込みサイズが(Sと比較して)中程度(=Medeium)であることがわかります。
6. 参考
-
"MetaFormer is Actually What You Need for Vision", Yu, W., Luo, M., Zhou, P., Si, C., Zhou, Y., Wang, X., Feng, F., Yan, S. (2021)
原論文 -
rafaelpadilla / review_object_detection_metrics
物体検出の評価方法まとめ。 -
LayerScale
PoolFormerの実験において採用しているLayerScaleの説明。