オミータです。ツイッターで人工知能のことや他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
他にも次のような記事を書いていますので興味があればぜひ!
帰ってきたResNet!最新の画像認識モデル「ResNet-RS」を解説!
2012年に登場したAlexNetが与えた衝撃に匹敵するほどの影響力を持つモデルにResNetがあります。ResNetの登場以降はWideResNetやResNeXt、DenseNetなどResNetのアーキテクチャを発展させることでさらなる高い汎化性能を獲得してきました。2019年には、EfficientNet(拙著記事)のような複雑なモデルや2021年3月にはそのバージョン2となるEfficientNetV2(拙著記事)も登場しています。今回紹介する論文は、学習方法とスケールアップ方法を工夫することでResNetをSoTAレベルの性能にまで向上させています。ここで用いられている学習のテクニックたちはResNetのみならず他のモデルにも使えるものばかりです。これらのテクニックを用いて学習されたResNetをResNet-RS(re-scaled ResNet)と呼んでいます。それでは性能を爆上げする10個のテクニックを見ていきましょう!
本記事の流れ:
- 忙しい方へ
- ImageNetにおける改善方法の小まとめ
- ResNet-RSの説明
- ResNet-RSの実験結果
- まとめと所感
- 参考
原論文: "Revisiting ResNets: Improved Training and Scaling Strategies", Bello, I., Fedus, W., Du, X., Cubuk, E., Srinivas, A., Lin, T., Shlens, J., Zoph, B., (2021)
公式実装: TensorFlow
0. 忙しい方へ
- ResNet-RSは、ResNetの学習手法とスケールアップ手法をそれぞれを改善し、EfficientNetよりも2.1~3.3倍(GPU)も速いよ
-
学習手法は以下だよ
- テクニックたち(DropoutやLabel smoothingなど(Table1))
- 小さな重み減衰率$4e-5$
-
スケールアップ方法は以下だよ
- モデルの深さは過学習が起こった時にスケールアップ(起こっていないなら幅をスケールアップ)
- 画像サイズはすぐに大きくしすぎない
- 半教師あり学習、転移学習、動画分類にも有効だよ
- ベースラインとしてこれからはResNet-RSを用いるべきだよ
1. ImageNetにおける改善方法の小まとめ
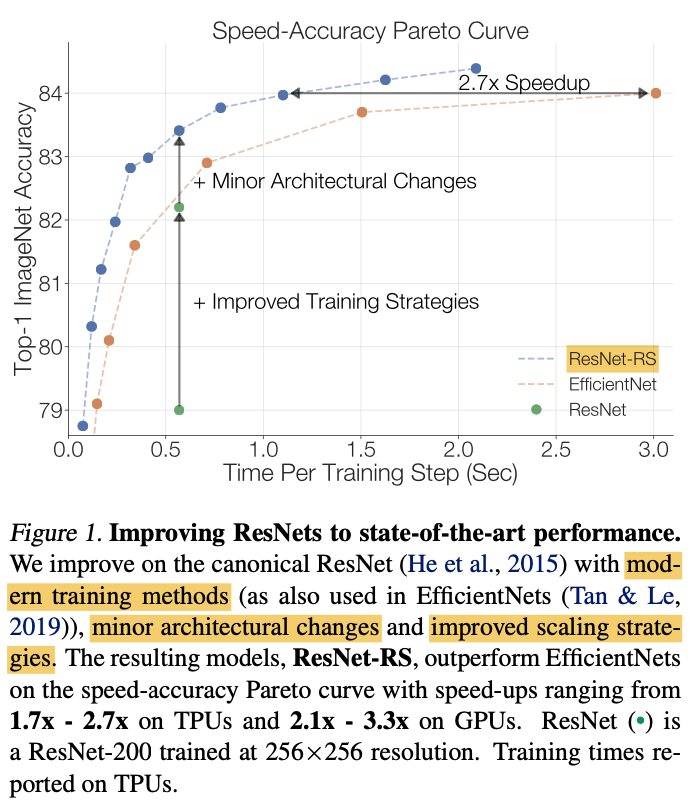
ResNet-RSに入る前にまず、これまでの研究で行われた画像認識モデルの改善方法について簡単にまとめたいと思います。これらの手法は以下の4つに分類することができます。それぞれの代表例も簡単に列挙しました。これまでの研究ではアーキテクチャにおける改善が盛んに行われてきましたが、本論文では 「学習および正則化手法」 と 「スケールアップの方法」 に注目しています。これらによってEfficientNetよりも1.7 - 2.7倍も速いResNet-RSが完成しています。
-
アーキテクチャ
- 人間による改善: AlexNetやResNetなど
- 自動探索: NasNetやEfficientNetなど
- 畳み込み以外のモジュール: Self-AttentionやLambda層など
-
学習および正則化手法
- ドロップアウト
- ラベルスムージング
- Stochastic Depth
- Dropback
- データ水増し手法
- 学習率スケジューラ
-
スケールアップの方法
- 深さ: ResNet-18やResNet-101など
- 幅: Wide ResNetなど
- 入力画像のサイズ: EfficientNetなど(*)
-
学習データの増加
- 事前学習: ViTやNFNetsなど
- 半教師あり学習: Noisy Studentなど
- 疑似ラベル: Meta pseudo-labelsなど
(*) EfficientNetは深さ、幅、入力画像のサイズ(解像度)の3つをお互いにバランスさせながらスケールアップさせています(=複合スケーリング(compound scaling))。詳しくはこちらを参照してください。
2. ResNet-RSの説明
ここでは本題のResNet-RSについて説明していきます。前述した通り、次の2つについて説明していきます。
- 学習手法の改善
- スケールアップ方法の改善
ResNet-RSでは主に学習方法とスケールアップ方法に着目していると繰り返し述べていますが、実はアーキテクチャにも少しだけ変更を加えています。といっても新しいものを考案している訳ではなく、既に存在する2つの手法を取り入れているだけです。学習手法の改善とスケールアップ方法の改善について述べる前にアーキテクチャにおける変更はとても簡単なので先に触れておきます。アーキテクチャにおける2つの手法は以下の2つです。
- SEブロック[Hu, J.(CVPR'18)]: チャネル方向のAttentionを計算してくれる(とされている)ブロック。詳細はこちら。
-
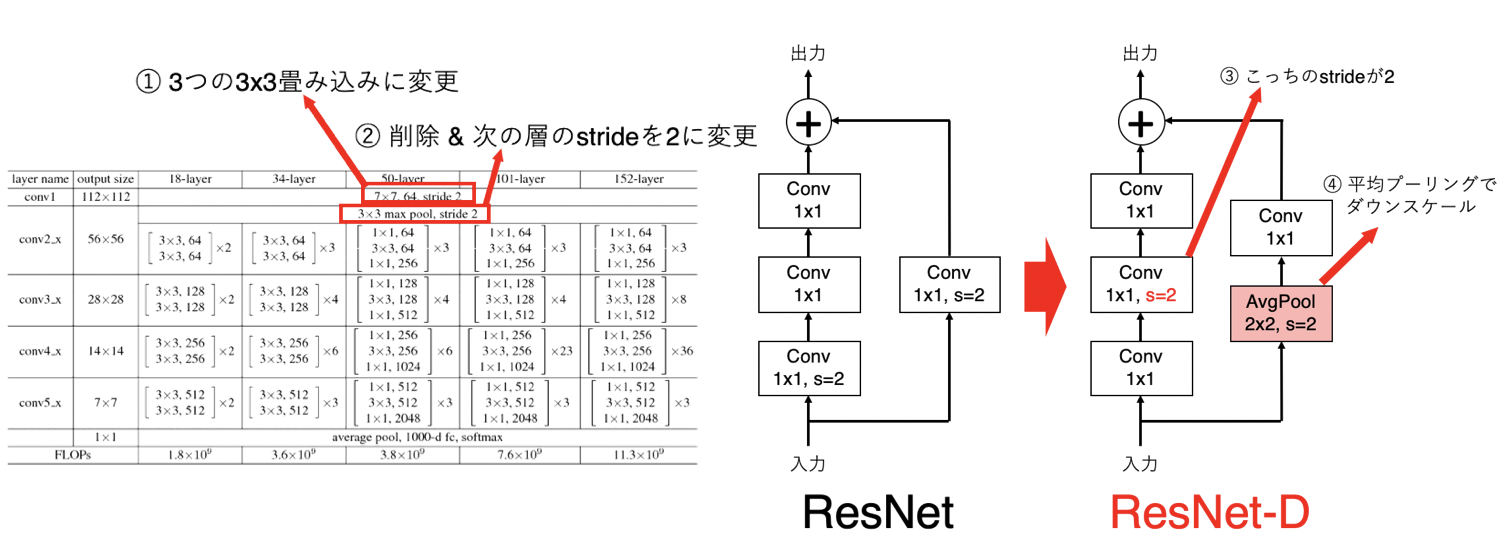
ResNet-D[He, T.(2018)]: ResNetの改良版
- 1層目を3つの3x3畳み込みに変更
- 2層目を削除し、その次の層を
stride=2 - Residualブロックにおいて
stride=2の位置を変更 - Residualブロックにおいて平均プーリングを導入
ResNet-Dは、文字だけではわかりづらいので上述した4点を下図に示しました。
そして最終的なResNet-RSのアーキテクチャは下の表で表されています。左表が各ステージのブロックの数を表しており、右表がResNet-RS-101のアーキテクチャになっています。

それでは本題の学習手法の改善とスケールアップ手法の改善について見てみましょう。
2.1 学習手法の改善
2.1.1 テクニックたち
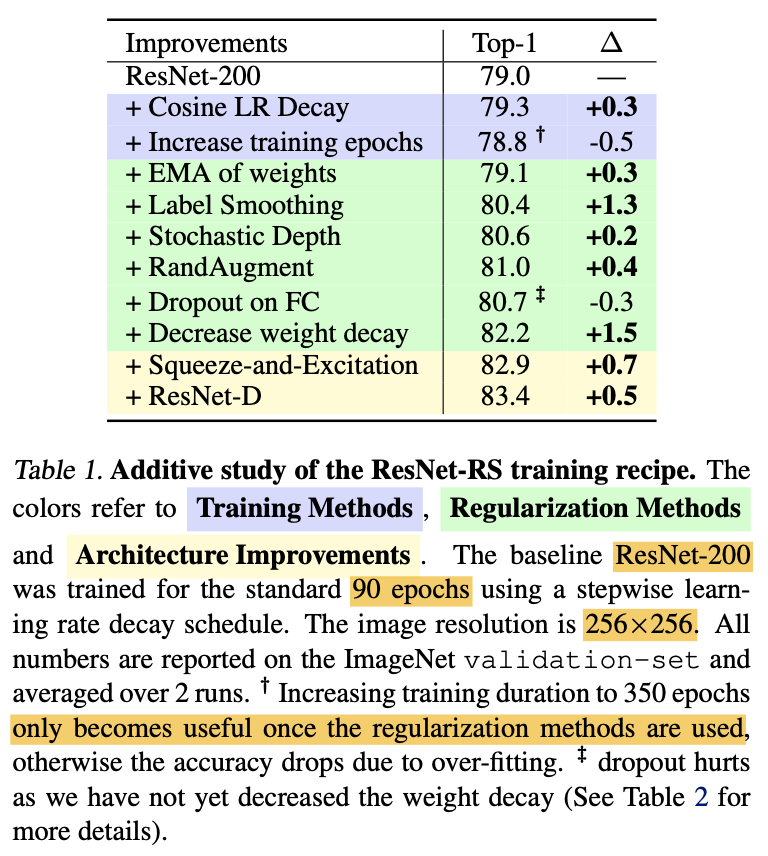
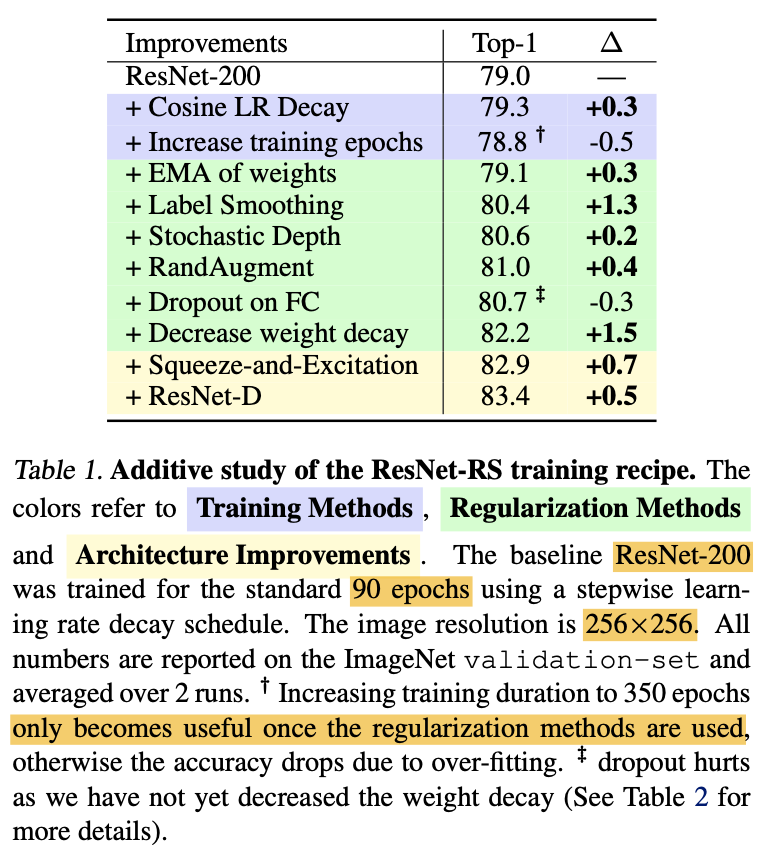
ここでモデルはResNet-200を用いており、ImageNetを90エポック学習させています。入力画像サイズは256x256です。上表を見ると、アーキテクチャを変えずとも3.2%ものゲインが得られていることがわかります。また、アーキテクチャにSEブロックやResNet-Dなどの変更を加えると分類精度がさらに上がっていることがわかります。
ちなみに、エポック数を350まで伸ばした時とドロップアウトを用いた時のゲインがマイナスになっていることが分かります。エポック数に関しては、この時点でまだ正則化手法を組み込んでいないためです。また、ドロップアウトに関しては重み減衰率が大きい($1e-4)$ためです。次項では重み減衰率について考えます。
2.1.2 重み減衰率の大きさ
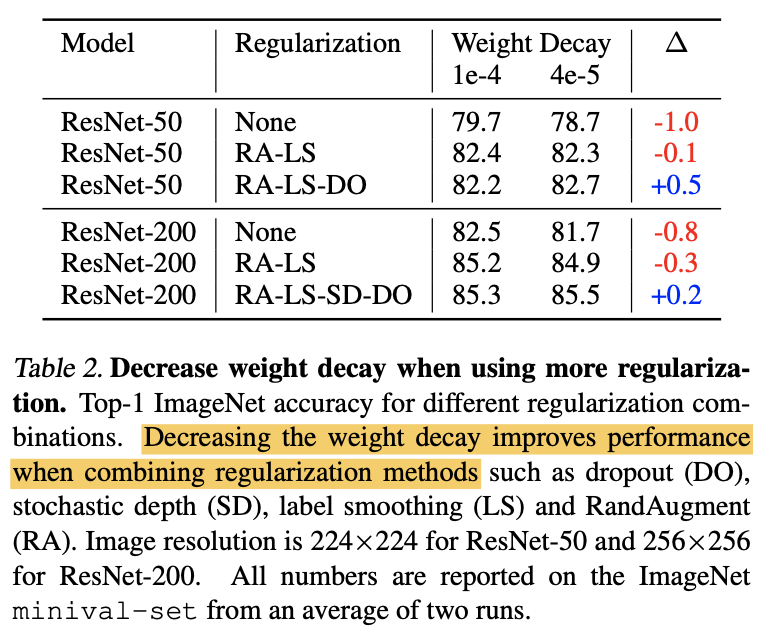
前項では、ラベルスムージングやStochastic Depthなどの多くの正則化手法を加えました。そのため重み減衰(Weight Decay)の値が大きいと正則化がかかりすぎてしまうと考えられます。重み減衰率の値としてよく用いられる値として$1e-4$があります。ここではこれを少し小さくした$4e-5$と比較しています。上表がその結果です。モデルにはResNet-50とResNet-200を用いています。上表からわかることは次の2つです。
- RandAugmentとラベルスムージング(RA-LS)を用いる時は重み減衰率は大きいままで良い。
- RandAugmentとラベルスムージングに加え、Stochastic Depthやドロップアウト(RA-LS-SD-DO)などを用いる時は重み減衰率は小さい方が良い。
2.2 スケールアップ方法の改善
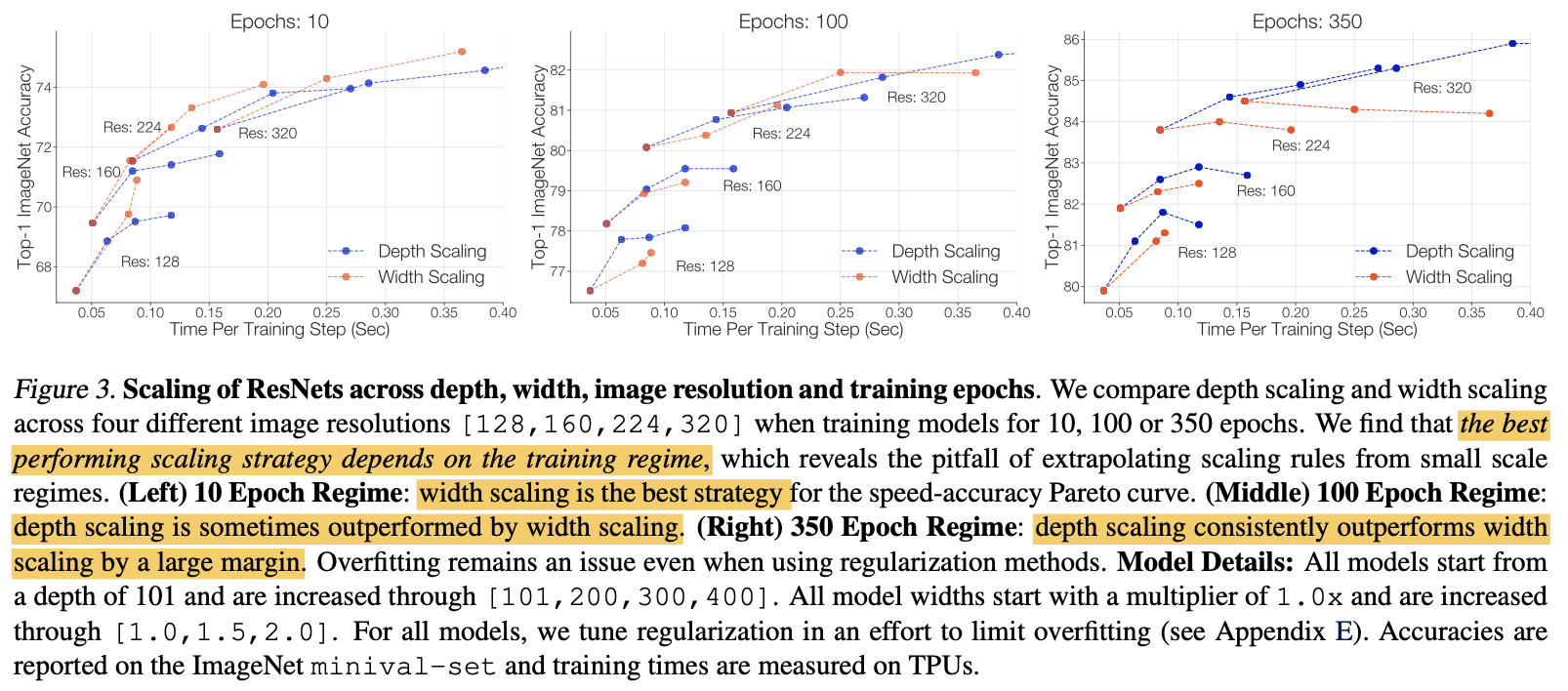
上の表では左からエポック数を10、100、350とした場合のImageNetの分類精度を示しています。ここで確かめたいことは、最適なスケールアップ方法は学習設定(エポック数)に依存するということです。青色が深さを、赤色が幅をスケールアップした場合の結果で、入力画像のサイズ(Res)が同じものは線で繋がっています。
この図は、エポック数が10(左図)の時とエポック数が350(右図)の時を見比べるとわかりやすいです。まず、エポック数が10(左図)の時を見ると同じ画像サイズでは赤線の方が青線よりも高い分類精度となっていることがわかります。一方でエポック数が350の時(右図)は逆に青線の方が赤線の方よりも高い分類精度となっています。これらのことから、過学習を起こしていない時(エポック数が少ない)は幅をスケールアップし、過学習を起こしている時(エポック数が多い)は深さをスケールアップするのが良い、ということが言えそうです。このように最適なスケールアップの方法は学習設定にも依存しています。
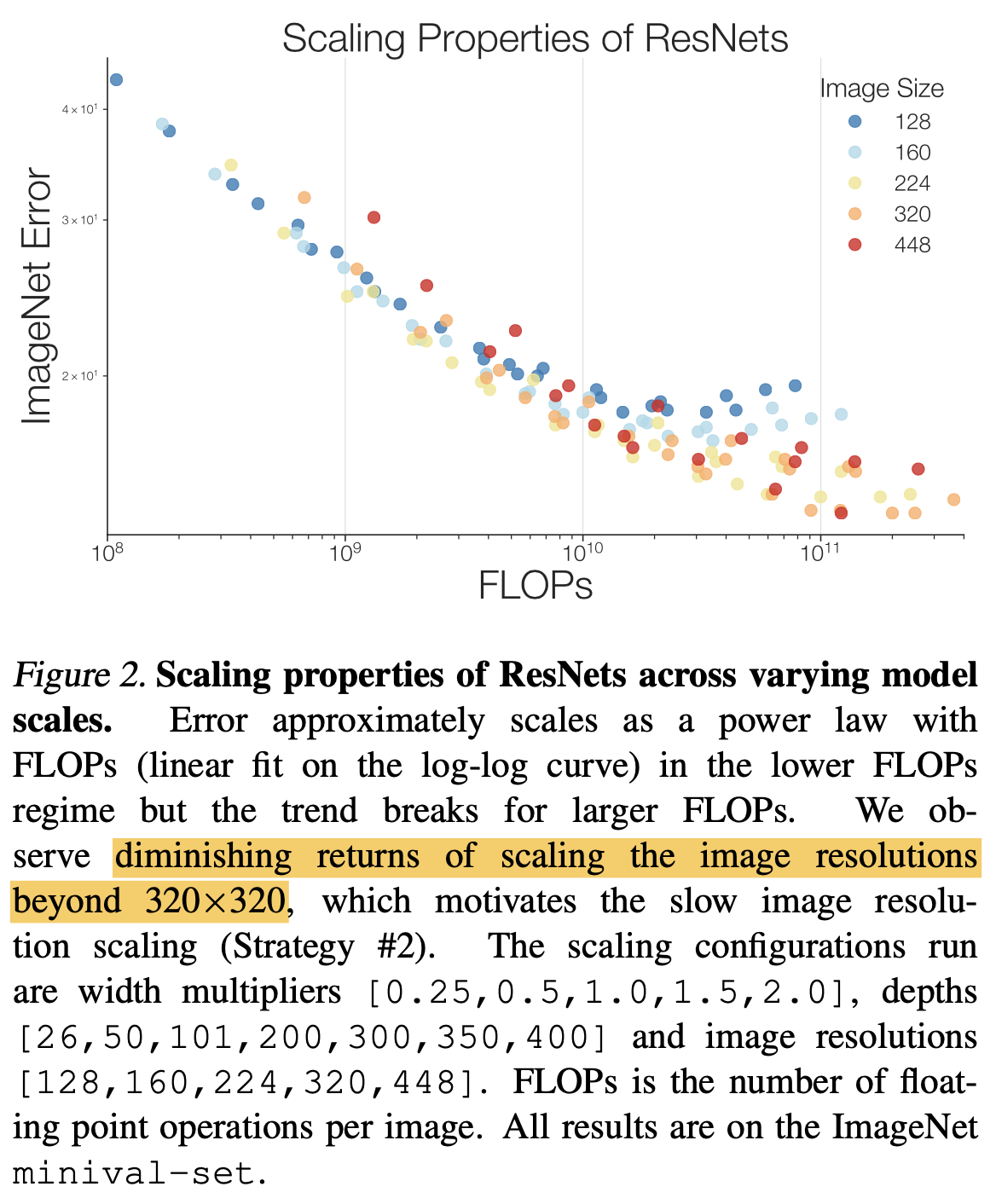
続いて、上図ですが、横軸がFLOPs数で縦軸がImageNetに対するエラー率(低ければ良い)を示しています。各点の色は入力画像のサイズを表しており、各入力画像サイズに対して様々な大きさのモデルを用意し実験していることがわかります。上図からは画像サイズが小さい点たち(青色や水色)よりも画像サイズが大きい点たち(黄色や橙色)の方が平均して低いエラー率を獲得していることがわかります。ただ、橙色の点たちと赤色の点たちのエラー率はあまり変わっておらず、画像サイズが大きすぎてもあまりゲインがないことがわかります。このことから、モデルをスケールアップしても画像サイズを急激には大きくすべきではないことがわかります。
これらをまとめた次の2つがまさに今回のスケールアップで用いるスケールアップ方法です
。
- 過学習なら深さ、過学習でないなら幅をスケールアップ
- 解像度の大きさはゆっくりスケールアップ
それでは学習方法とスケールアップ方法を用いた実験の結果を見ていきましょう。
3. ResNet-RSの実験結果
- ResNet-RSとEfficientNetの比較
- EfficientNet-RS
- 半教師あり学習
- 転移学習
- 動画分類
3.1 ResNet-RSとEfficientNetの比較
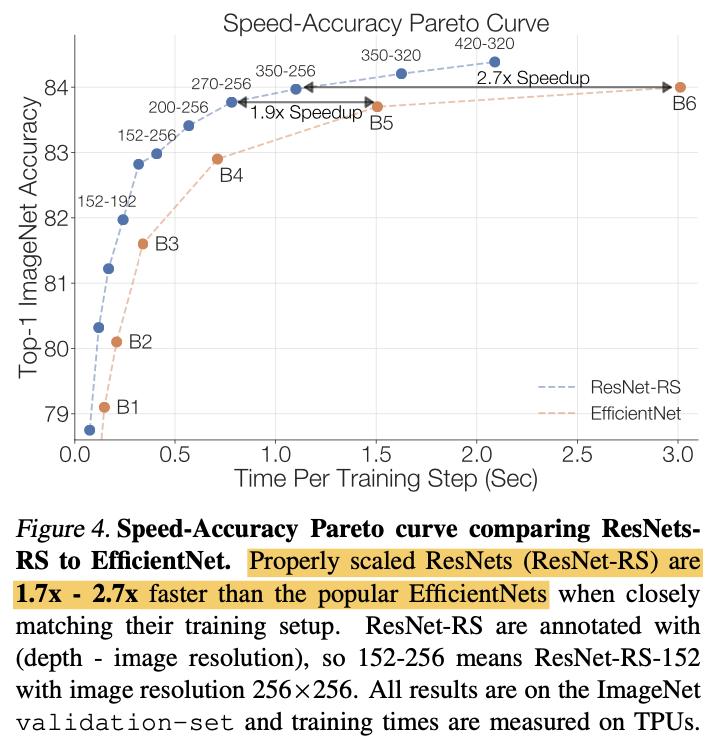
ResNet-RSは1.7-2.7倍も速い学習時間で、EfficientNetと同じ分類精度を達成できています。EfficientNetと比べ、学習時間が半分未満になると考えると驚異的に時間短縮ができることがわかります。
ちなみに、モデルの速度を評価するときはFLOPs、モデルのメモリ消費を評価する時にはパラメータ数がよく用いられてきましたが、これらの指標はそれぞれモデルの速度とメモリ消費を正確に表しているわけではありません。このことが実験的にまとめられているのが下表です。緑がパラメータ数および実際のメモリ消費、紫がFLOPs数と実際の学習時間(Latency)を示しています。
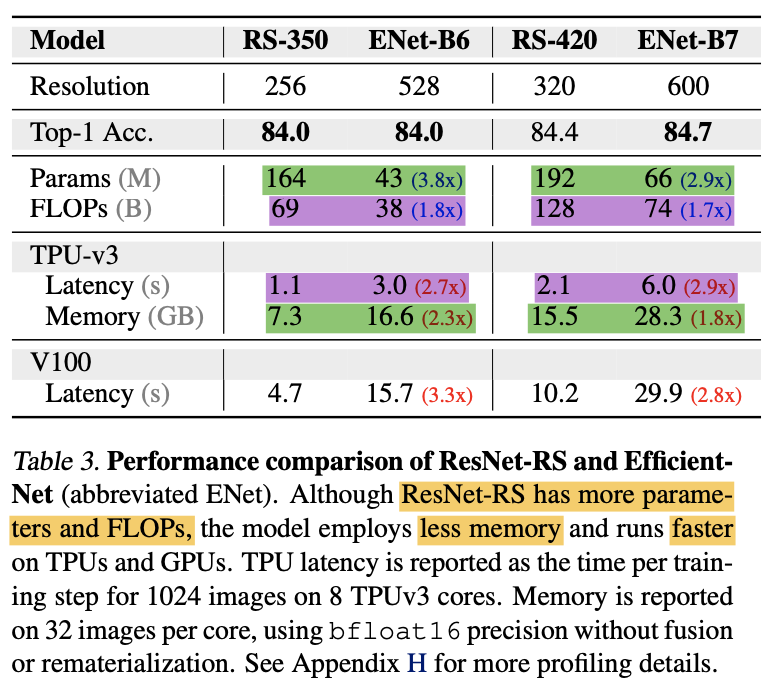
ResNet-RSはEfficientNetと比べ、パラメータ数は3.8倍も大きいですがメモリ消費は2.3倍も小さいです。また、FLOPs数においてもResNet-RSが1.8倍も大きいですが実際の学習時間は2.7倍も速いことがわかります。
3.2 EfficientNet-RS
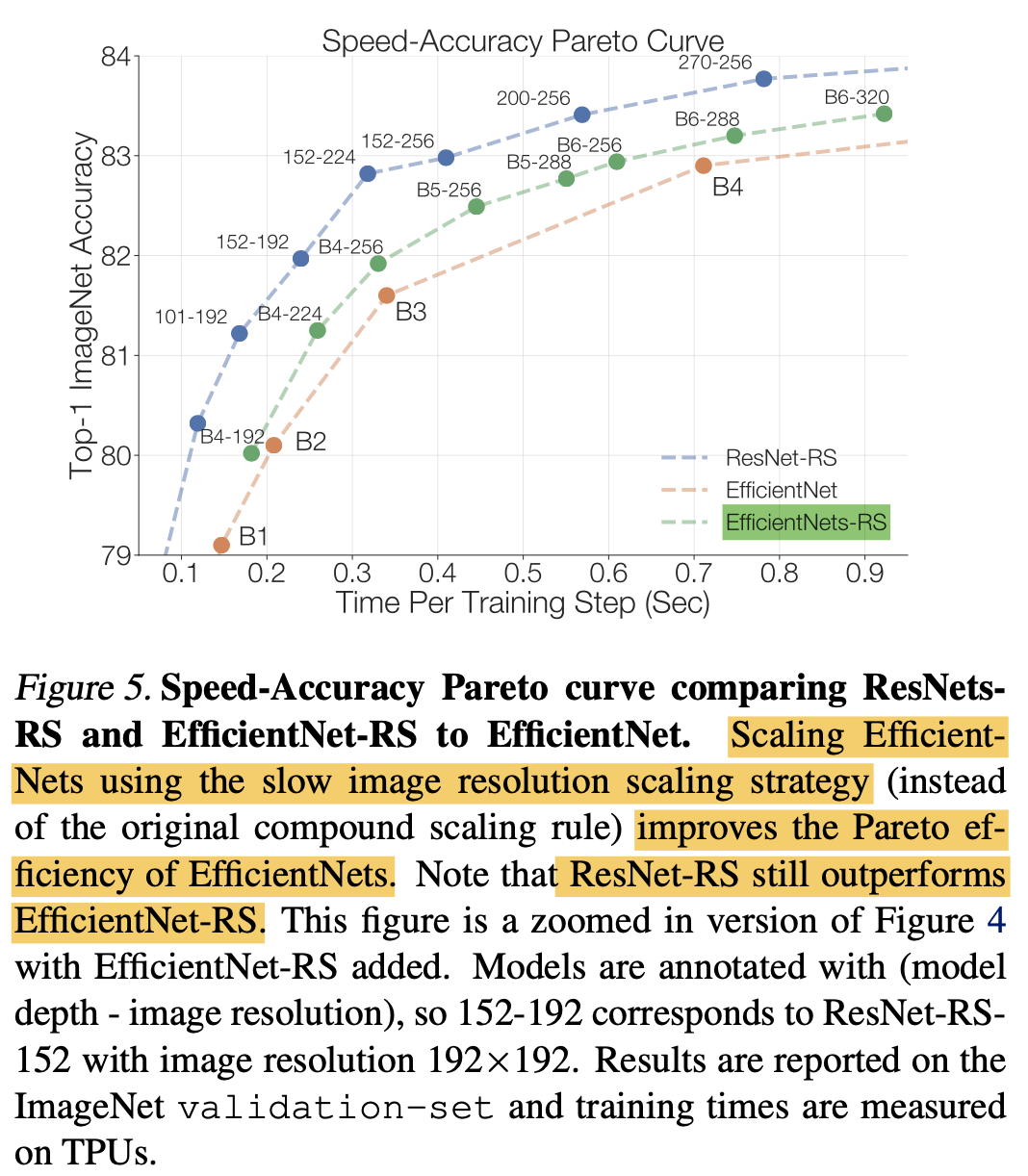
2.2で、画像サイズは急に大きくしすぎない方が良いことがわかりました。これをEfficientNetに適用させてみます。EfficientNetとEfficientNet-RSで用いる画像サイズの一部を下表にまとめました。上表の緑色の破線がEfficientNet-RSの結果を示しており、オリジナル(橙色)よりも高い分類精度を示していることがわかります。ただ、ResNet-RS(青色)はそれよりも高い性能となっています。
| Eff | Eff-RS | |
|---|---|---|
| B4 | 380 | 192 ~ 256 |
| B5 | 456 | 256 ~ 288 |
| B6 | 528 | 256 ~ 320 |
3.3 半教師あり学習
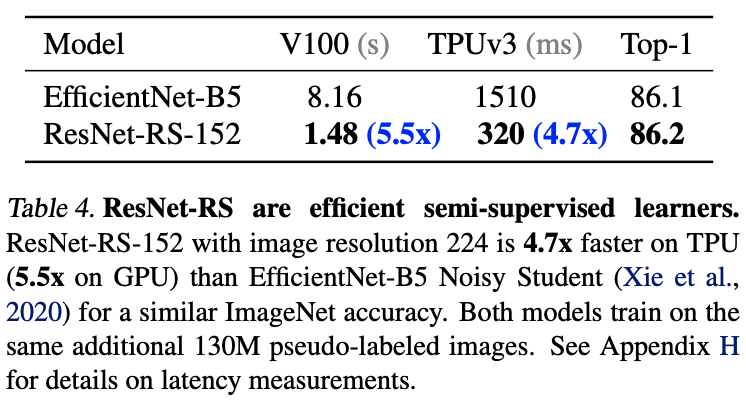
ここでは、ラベルあり画像に加え大量のラベルなし画像も用いることにします。ラベルあり画像は今まで通り120万枚のImageNetの画像を用い、ラベルなし画像は1,300万枚も用います。ラベルなし画像たちにはEfficientNet-L2(ImageNet分類精度88.4%)によって疑似ラベルが付与されます。つまり、ラベルあり画像と大量の疑似ラベルあり画像を全て学習に用いたときの分類精度を見ています。下表がその結果になっています。なんと、ResNet-RSはEfficientNetよりもV100で5.5倍も早いことがわかります(TPUでは4.7倍)。
3.4 転移学習
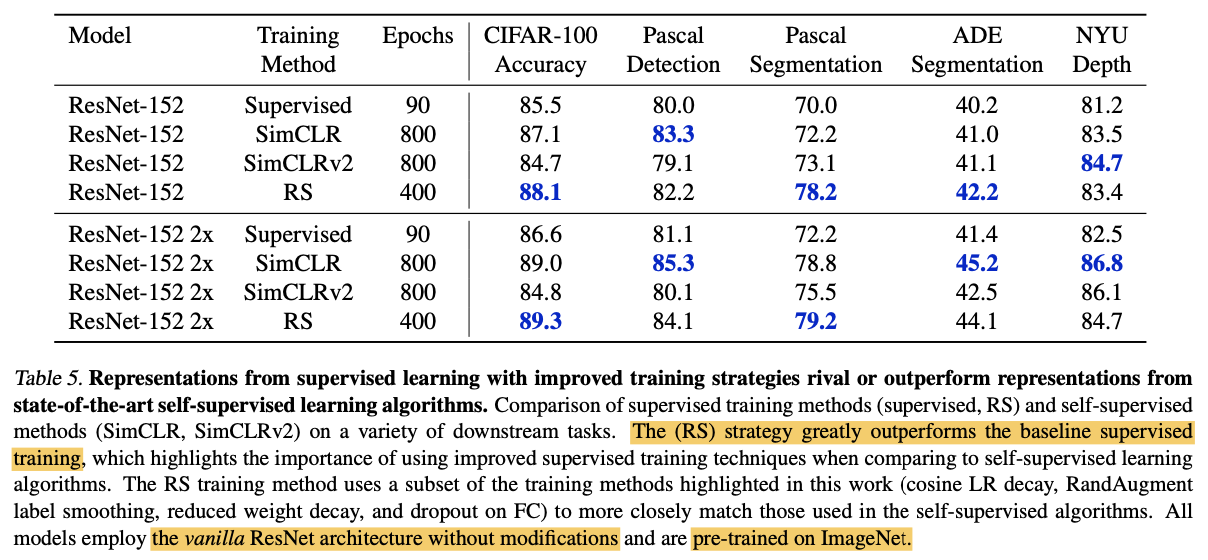
ここでは、本論文で提案した学習方法をRSと呼んでいます。RSで学習したモデルが汎用的な表現を学習できているかを見てみます。比較として、通常の教師あり学習(Supervised)と自己教師あり学習であるSimCLRおよびSimCLRv2を用います。教師あり学習では、単にImageNetで学習させるだけです。ここで自己教師あり学習が出てくるのは、近年自己教師あり学習が事前学習として高い性能を示しているためです。(参照:2020年超盛り上がり!自己教師あり学習の最前線まとめ!)
転移学習先として、画像分類(CIFAR-100)、物体検出(Pascal)、セマンティックセグメンテーション(Pascal/ADE)、深度推定(NYU)の4つのタスクを行っています。性能を公平に比較するため、提案手法であるRSもオリジナルのResNetを用いており、ResNet-DおよびSEモジュールのようなアーキテクチャに変化を加えるようなテクニックは用いていません。上表から言えることは次の2つです。
- RSは教師あり学習よりも常に良い。
- SimCLRには10個中5個で、SimCLRv2には10個中8個でRSの方が高い性能を示している。
3.5 動画分類
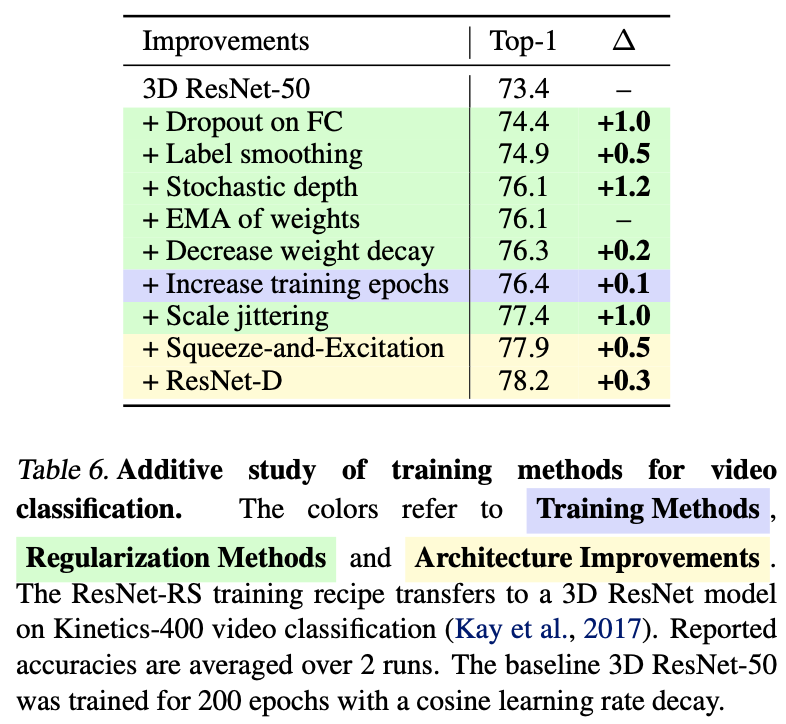
画像分類の学習に対してかなり有効なRSを、動画分類の学習にも用いた場合を見てみます。ここではモデルに3D-ResNetを、データセットにはKinetics-400を用いています。3D-ResNetとは、時間軸を考慮させるために3D畳み込みで構成されたResNetのことです。動画分類にもRSは非常に有効で全部で4.8%ものゲインがあることがわかります。画像分類以外にもこういったテクニックたちが有効なのは面白いですね。
4. まとめと所感
本記事では最新のResNetである、ResNet-RSについて見てきました。ResNet-RSがEfficientNetと同程度の性能に2~3倍も速く到達することがわかりました。これまで使われてきたテクニックたちを用いたり正しくスケールアップするだけでResNetの性能がここまで上がるのは驚きです。特にテクニックたちはResNetのみならず他のモデルおよびタスクにも有効なことが本論文の実験からわかっているので積極的に用いていきたいですね。特別な実装もあまり必要がないので、これからはResNet-RSをベースラインとして用いてみてください!
Twitterで人工知能のことや他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ: