オミータです。ツイッターで人工知能のことや他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
他にも次のような記事を書いていますので興味があればぜひ!
2021年最強になるか!?最新の画像認識モデルEfficientNetV2を解説
いきなりですがMobileNetやInception、YOLOなどに共通するものは何かわかりますか。どれも画像モデルではありますが、それだけではありません。いずれもバージョン2が存在しています。このように、エポックメイキングなモデルたちにはバージョン2が存在しています。そして、この度なんとEfficientNetのバージョン2である「EfficientNetV2」が満を持して登場したのです。2019年に登場しあらゆるデータセットでSoTAを叩き出したEfficientNet(拙著記事)は、今やKaggleなどのコンペではデファクトで用いられています。そんなEfficientNetのバージョン2が登場したということで非常に期待が高まります。早速EfficientNetV2の中身と強さを見ていきましょう。EfficientNetV2では、学習速度とパラメータ数を改善させています。
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
本記事の流れ:
- 忙しい方へ
- EfficietNetV2の説明
- Progressive Learningの説明
- EfficientNetV2の実験
- まとめと所感
- 参考
原論文: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
公式実装: 公開予定
| 略語 | 正式名称 |
|---|---|
| NAS | Neural Architecture Search |
0. 忙しい方へ
- EfficientNetV2は、EfficientNetにFused-MBConvとProgressive Learningを組み込んだものだよ。
- EfficientNetV2は、学習効率の観点でEfficientNetを改良したモデルだよ
- EfficientNetV2は、SoTAモデルたちよりも6.8倍小さく、11倍も速い学習で、ImageNet/CIFAR/Flowers/Carsで高い分類精度を示したよ
1. EfficientNetV2の説明
ここでは、EfficientNetについて簡単にレビューします。その後、EfficientNetの問題点を見ていきます。そして最後EfficientNetV2を提案します。つまり、次の3つです。
- EfficientNetの概略
- EfficientNetの問題点
- EfficientNetV2の提案
1.1 EfficientNetの概略
EfficientNetは[Tan, M.(ICML'19)]で提案されました。[Tan, M.(ICML'19)]では、分類精度とFLOPs数の両方を最適化するようなモデルをNASによって探索しています。これによって探索されたモデルをEfficientNet-B0と名付け、あとはB0の深さ、幅、入力画像の大きさをcompound scaling method(解説)と呼ばれる式に従って大きくすることでB1からB7まで定義しています。EfficientNetの詳細は拙著の記事で解説しておりますのでそちらをご参照ください。ここでは、次の2つのことを理解していればOKです。
- EfficientNet(-B0)はFLOPs数と分類精度を最適化するNASで探索されている
- B0を簡単なcompound scaling methodでスケールアップする(B1からB7)ことでより高い精度を獲得している
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
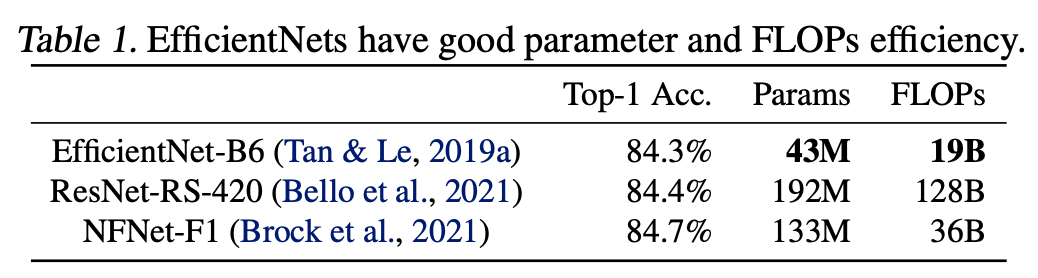
モデルの学習速度を速くする試みは多くされていますが、それらではパラメータ数は無視されてしまい比較的巨大なものが完成してしまっています(上表、最新モデルたちよりB6のパラメータ数およびFLOPs数が小さいことがわかります)。EfficientNetV2ではパラメータ数を抑えたまま学習速度を速めることを目的としています。
1.2 EfficientNetの問題点
本論文中で指摘しているEfficientNetの問題点は次の3つです。
- 画像サイズが大きいと学習が遅い
- モデルの先頭付近にDepthwise畳み込みがあると学習が遅い
- モデルを均等にスケールアップするのは最適ではない
1.2.1 画像サイズが大きいと学習が遅い
これはすごく単純なことで、画像サイズ大きい -> メモリに乗っかるデータが少なくなる -> バッチサイズ小さくする -> 学習が遅くなるという論理になっています。これだけです。EfficientNetV2では、最初に小さい画像サイズを用い徐々に画像サイズを上げていくという戦略をとります。
1.2.2 モデルの先頭付近にDepthwise畳み込みがあると学習が遅い
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
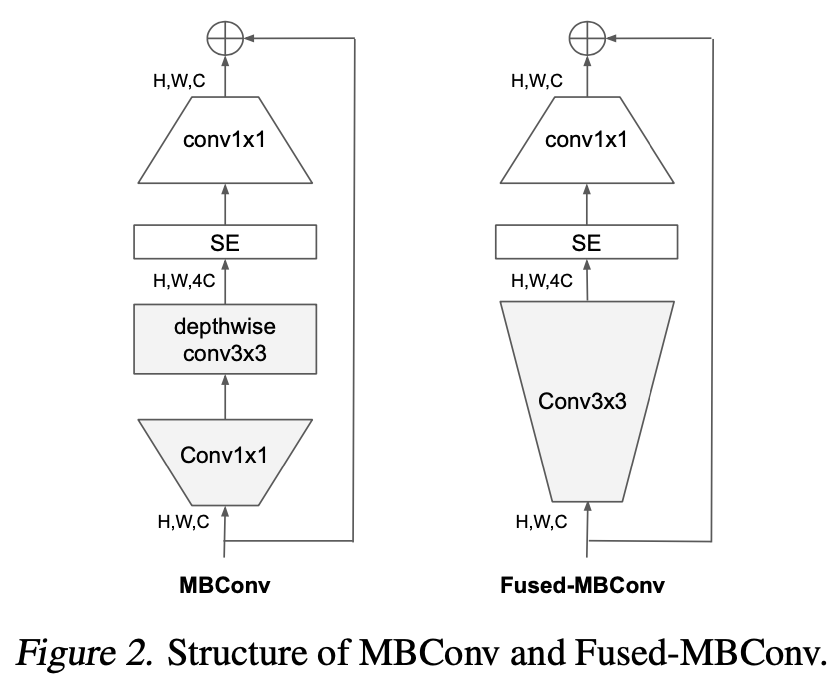
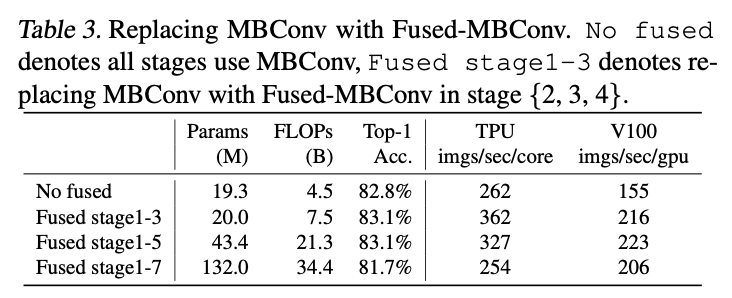
EfficientNetはMBConv(上図左)と呼ばれるブロックを繰り返し用いています。これはパラメータ数削減のためDepthwise畳み込みを含んでいますが、このDepthwise畳み込みはGPUやTPUをフル活用できていません。(私の経験上、Depthwise畳み込みを含むモデルはパラメータ数の割に学習が遅い印象です。(PyTorchのGrouped Convに特有の問題かもしれませんが。。。)そのため、[Gupta, S. (2019)]ではFused-MBConvと呼ばれるブロックが提案されています。Fused-MBConvでは、Pointwise畳み込み(=1x1畳み込み)とDepthwise畳み込みの代わりに3x3畳み込みを用いています。EfficientNetの各ステージをFused-MBConvに置き換えたときの結果は下表になります。
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
最初のステージをFused-MBConvにした場合(Fused stage1-3)、パラメータが少しだけ増えますが精度も処理速度も最も良いです。このFused-MBConvと通常のMBConvの組み合わせもNASによって探索していきます。
1.2.3 モデルを均等にスケールアップするのは最適ではない
EfficientNetをスケールアップするとき各ステージを均等にスケールアップするのはよくない、ということを言っています。ここでステージとは、モデル内の一定の塊のブロックたちを指します。オリジナルのEfficientNet(=EfficientNetV1)では、深さを2倍するときはモデルの全ステージを2倍にします。EfficientNetV2ではもう少し複雑(と言っても単純ですが)な方法でスケールアップさせます。これについては後述します。
1.3 EfficientNetV2の提案
1.3.1 NAS
EfficientNetV2では次の探索空間でNASを実行します。
| パラメータ | 探索空間 |
|---|---|
| ブロック | {MBConv, Fused-MBConv} |
| カーネルサイズ | {3x3, 5x5} |
| 拡張率 | {1, 4, 6} |
その他層の数も探索空間に入れています。ここで拡張率とは、MBConvの最初のConvでチャネル数を何倍にするかの係数のことで、こちらでより詳しく解説しています。
探索は精度$A$、ステップごとの学習時間$S$、パラメータサイズ$P$を用いて、$A\cdot S^w\cdot P^v$を最大化するように行われます。ここで$w=-0.07, v=-0.05$であり、これらの値は実験的に決定されています。
1.3.2 EfficientNetV2のアーキテクチャ
下表がEfficientNetV2のSサイズのモデルになります。
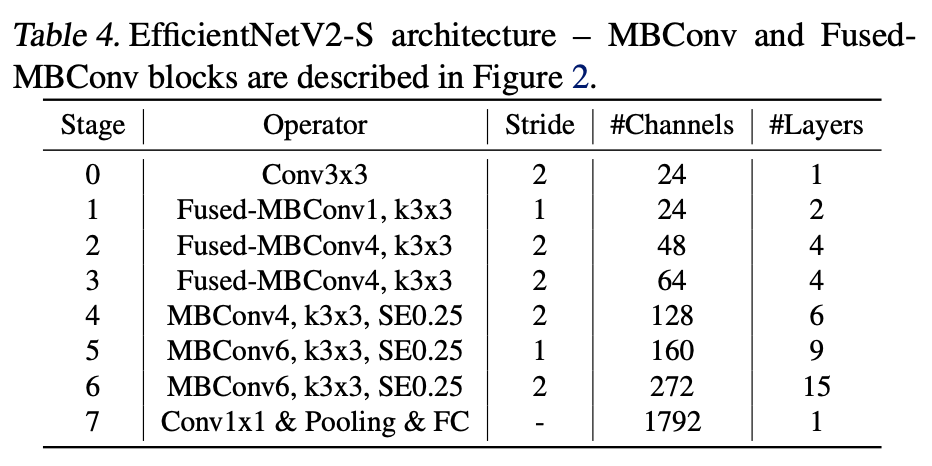
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
比較のためにEfficientNet-B0(i.e. V1)のアーキテクチャも下に載せます。
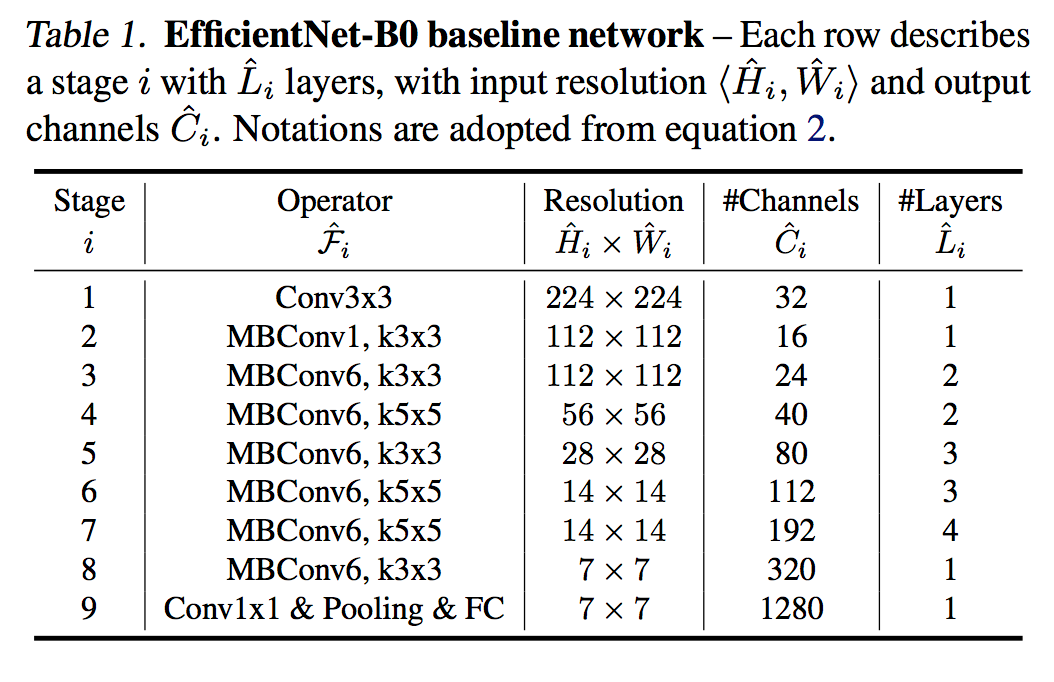
V2(-S)とV1の違いは次の4つになります。
- V2は、MBConvおよびFused-MBConvのいずれも用いている。
- V2は、MBConvの拡張率が小さい(
MBConvXのXが拡張率を指す)。 - V2は、カーネルサイズが小さく主に3x3を用いている。それに伴い層の数は大きく増えている。
- V2では、V1のステージ8にある
stride=1のMBConvがなくなっている。
1.3.3 EfficientNetV2のスケーリング
V1では単純なcompound scaling methodに従ってB0の深さ、幅、入力画像の解像度を定数倍大きくしていくことでB0からB7まで実現しました。V2でも同様にV2-Sをスケールアップしていくことで、MサイズとLサイズを作っていきます。V2も基本的にV1のcompound scaling methodに従いながらスケールアップするのですが、次の2つの変更点があります。
- テスト時の画像サイズは最大で480
- 層の数は主に後半のステージで増やす
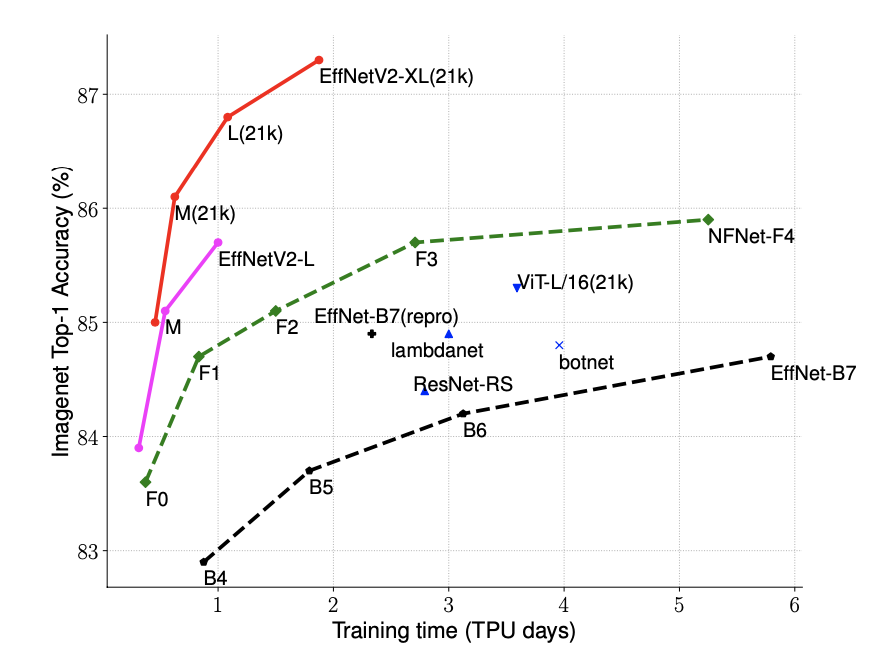
横軸をバッチごとの学習時間、縦軸を分類精度としたグラフを下図のようにプロットしています。比較にはEfficientNetV1に加えLambdaNetやNFNetなどを用いています。エポック数はいずれも350の場合で、下図からも学習時間の速度と分類精度のトレードオフはEfficientNetV2(ピンク色)が最も良いことがわかる。
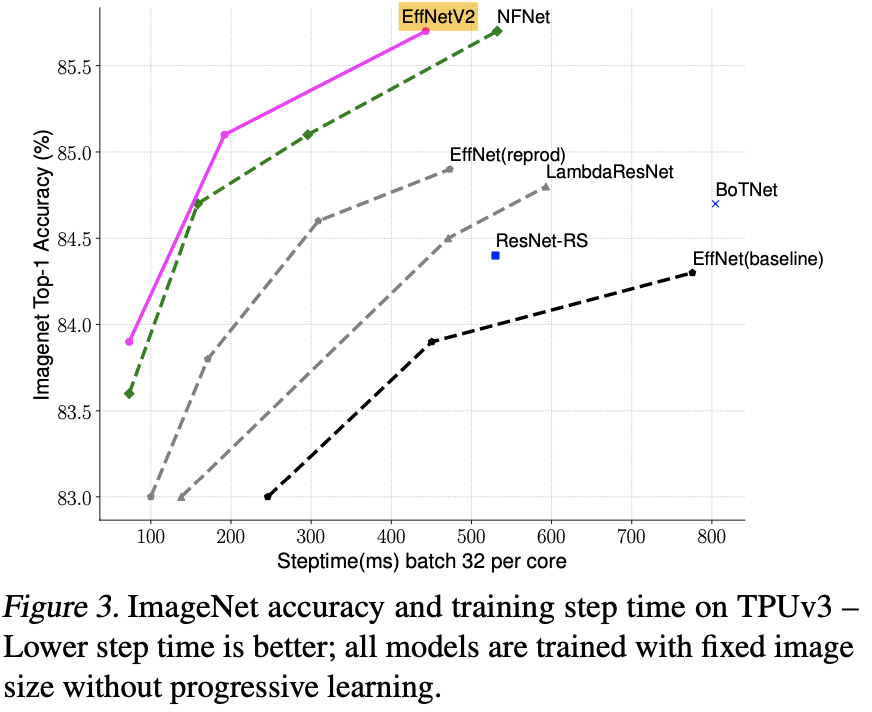
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
2. Progressive Learningの説明
2.1 モチベーション
学習過程によって画像サイズを変更するProgressive Learningはこれまでも意外に用いられてきてはいましたが、どうしても分類精度の低下を伴うものばかりでした。本論文では、この精度低下を抑えるために正則化に着目しています。私の解釈ですが、私は正則化をモデルへの嫌がらせと捉えています。ニューラルネットはデータに過学習しがちなので、モデルにあえて嫌がらせ(Dropoutや画像の加工など)をすることでモデルの汎化性能を上げています。「画像サイズに伴って正則化の強さも変える」という作戦を取っています。これは、小さい画像で学習したモデルには弱い正則化が必要で、大きい画像で学習したモデルには強い正則化が必要なはず、という仮定に基づきます。この仮定を実験的にも確かめた結果が下の表になります。この表は、RandAugmentの強さ(magnitude)と画像サイズを変えた時のImageNetの分類精度を示しています。列(画像サイズ)ごとに見ていくと、仮定の通り、画像サイズが小さい時はRandAugmentは弱い方がよく、画像サイズが大きい時はRandAugmentが強い方が良いことがわかります。

画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
2.2 正則化を考慮したProgressive Learning

画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
先ほどの2.1節で得られたことをベースとして、実際に正則化を考慮したProgressive Learningは上図のようになります。学習が進むにつれて画像サイズおよび正則化の強さも大きくなっていることがわかります。ここで正則化テクニックとして次の3つを用いています。
- Dropout
- RandAugment
- Mixup
正則化を考慮したProgressive Learningを疑似コードで表記すると下のようになります。

画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
アルゴリズムは見た通りですが、簡単に説明します。と言っても、画像サイズおよび正規化の強さにおいて初期値($S_0$および$\phi_0^k$)と最後の値($S_e$および$\phi_e^k$)さえ決めてしまえば終了です。あとは初期値から開始し、各ステージ$i$でこれらの値を線形的に大きくしていき最後の値$S_e$および$\phi_e^k$にしているだけです。
それではEfficientNetV2をこの新たなProgressive Learningで学習させた結果を見ていきましょう。
3. 実験結果
実験は大きく画像分類、転移学習そしてアブレーションスタディの3つを行っています。それではそれぞれについて見ていきましょう。
- 画像分類
- 転移学習
- アブレーションスタディ
3.1 画像分類
3.1.1 ImageNetに対する実験結果
ここで用いるImageNet(正確にはImageNet ILSVRC2012)とは、言わずと知れた画像分類タスクのベンチマークデータセットで、学習用画像は約130万枚あります。クラス数は1,000個となっています。実験設定はEfficientNetV1のものに大きく従っています。代表的なものだけ下表にまとめました。
| パラメータ | 値 |
|---|---|
| オプティマイザー | RMSProp |
| エポック数 | 350 |
| バッチサイズ | 4,096 |
| 初期学習率* | 0.256 |
| 重み減衰率 | 1e-5 |
| ステージ数 | 4 |
| * 正確にはWarmupで0から0.256に到達し、2.4エポックごとに0.97掛けされている。 |
Progressive Learningに関するパラメータは以下表です。ステージ数は4なので$350\div4\approx87$で各ステージのエポック数は87となります。
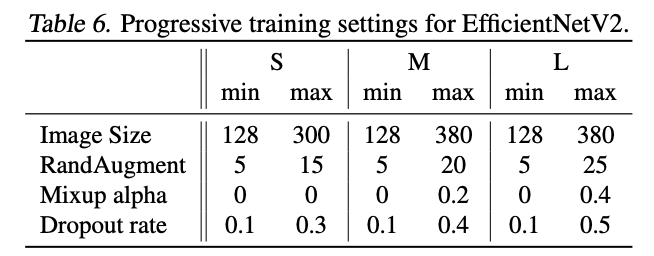
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
結果は下表になります。ここで(21k)と書いてあるのは、1,300万枚の学習用画像および21,841個のクラスを含むImageNet21kというデータセットで事前学習した結果です。この事前学習の時にはデータセットが巨大なのでエポック数は60または30エポックまで小さくしています。ImageNetへのファインチューニングではエポック数が15となっています。それでは結果を見てみます。
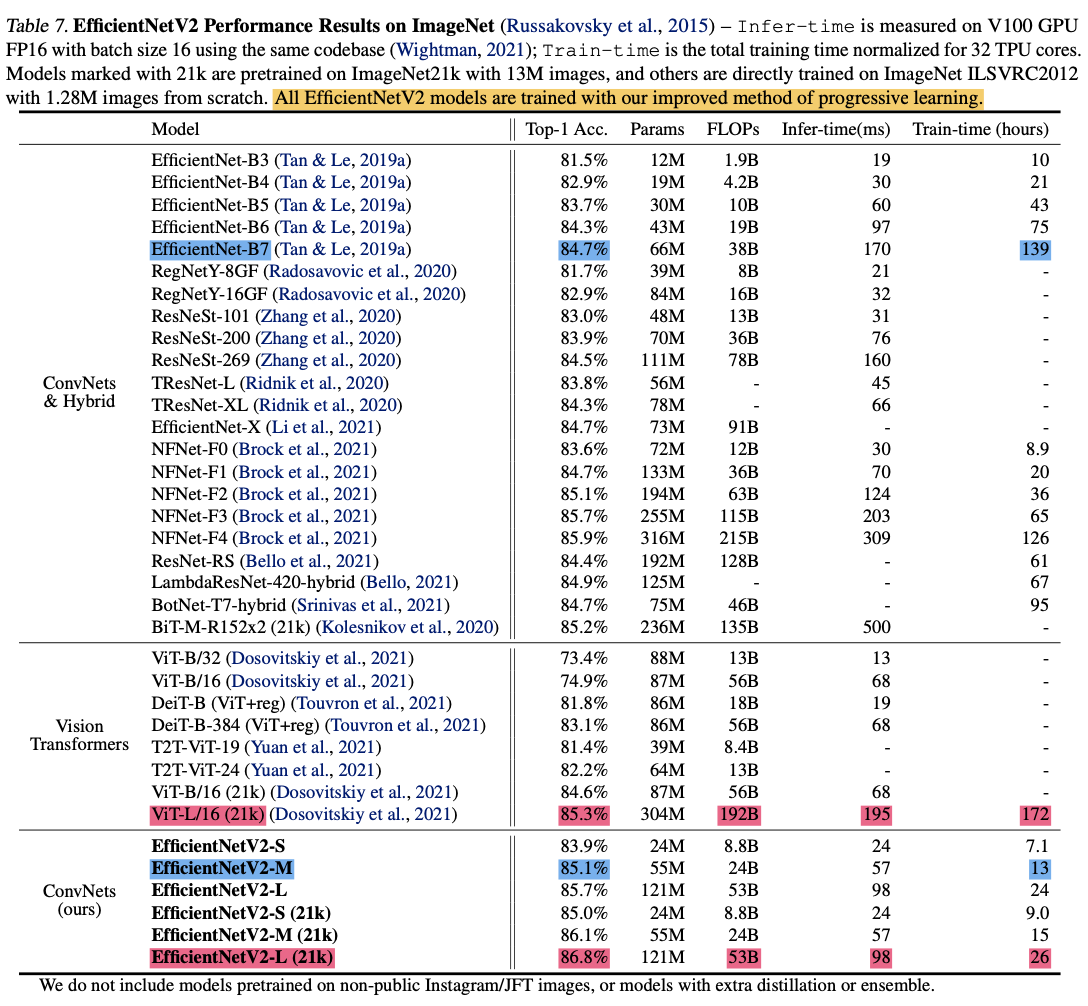
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
上表の結果の中で注目すべき点は2つ青色のマーカーとピンクのマーカーで印をつけた2つです。
- 青色のマーカー: 純粋にImageNetで学習させた結果。V2-MがB7と同程度の分類精度を11倍も速い学習速度で叩き出しています。
- ピンク色のマーカー: ImageNet21kで事前学習させImageNetにファインチューニングさせた結果。V2-LがViT-L/16よりも1.5%高い分類精度を、2.5倍少ないパラメータ数、3.6倍少ないFLOPs数、そして6-7倍早い学習および推論時間で達成しています。
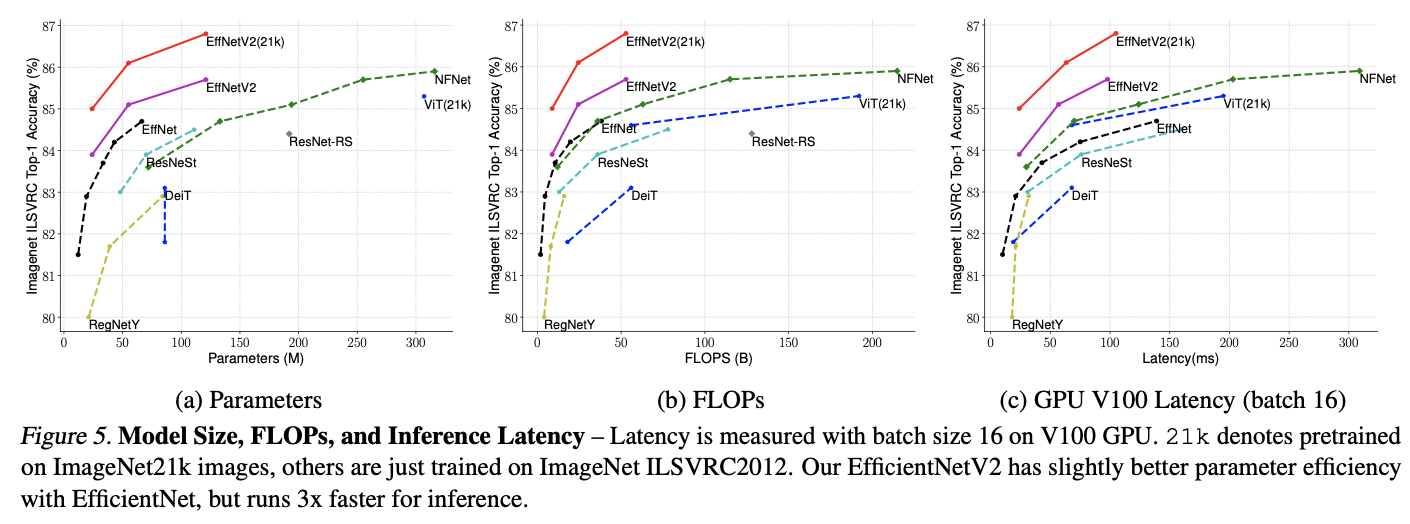
特にパラメータ数、FLOPs数、V100での推論時にバッチサイズ16の1ステップにかかる時間をまとめた結果が下の表になっています。効率性という面でV2が圧倒的に良いことがわかります。
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
これらの結果全てからさらに次の2つがわかります。
- 高い分類精度を叩き出すモデルにおいては、モデルサイズよりもデータサイズをスケールアップした方が良い。
- ImageNet21kでの事前学習は現実的な時間で終わる。
1つ目に関しては、モデルサイズを大きくした時よりもImageNet21kで事前学習させた時の方が精度のゲインが高いことからわかります。また2つ目に関しては、ImageNet21kを用いた場合ViTでは数週間かかる一方でEfficientNetV2では2日以内で終わるためだそうです。今後はImageNet21kをデフォルトのデータセットとして用いるべきという提言までもしています(エグいです)。それでは続いて転移学習について見ていきましょう。
3.2 転移学習
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
ここでは上の4つのデータセットに転移学習させます。事前学習ではImageNet ILSVRC2012(クラス数が1,000個のImageNet)を用いています。転移学習の簡単な実験設定は下の表のようになります。
| パラメータ | 値 |
|---|---|
| ステップ数 | 10,000 |
| バッチサイズ | 512 |
| 初期学習率 | 0.001 |
| 学習率スケジューラ | コサイン |
転移学習の結果は下の表です。いずれのデータセットにおいてもEfficientNetV2-Lが最も良いことがわかります。EfficientNet-V2がImageNet以外のデータセットにも有効なことがわかります。(画像系の転移学習を評価するためのVTABベンチマークの結果も見てみたいですが。。。)
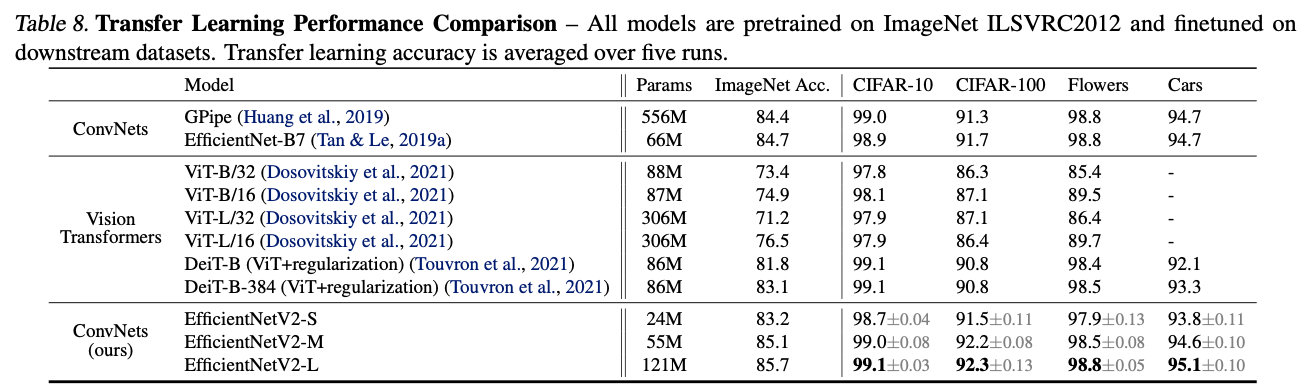
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
3.3 アブレーションスタディ
アブレーションスタディでは次の3つを行っています。
- EfficientNetV1との比較
- 他モデルへのProgressive Learningの適用
- 正則化の強さを変化させる重要性
3.3.1 EfficientNetV1との比較
ここではV1との比較を行います。特にV2の効率性に着目したものとなっています。ここではV1もV2もいずれも提案手法のProgressive Learningで学習させています。
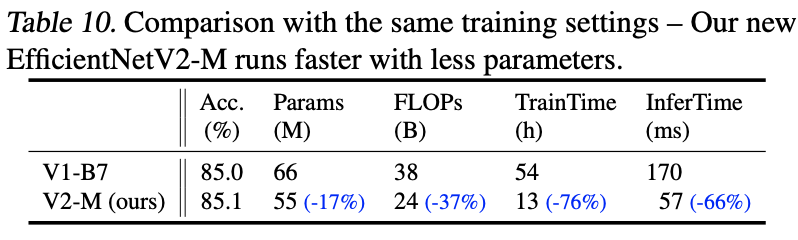
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
まず上表から、B7と同程度の分類精度を出すV2-Mの方がより効率的なモデルになっていることがわかります。V1もV2もいずれも同様の実験設定なので、V2のアーキテクチャがV1よりも効率的であることがわかります。
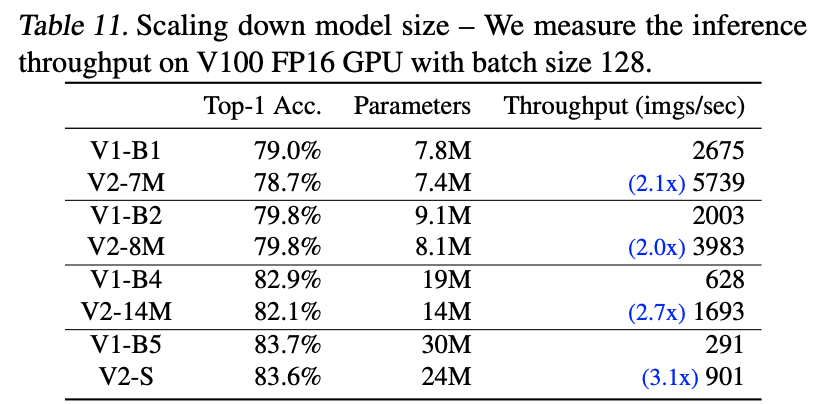
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
また、上表ではV2-Sをさらに小さくしたモデルたちとV1を比較しています。これを見るとV1よりもV2のスループットがとても高いことがわかりますね。小さなモデルでもV2の効率の良さが見て取れます。
3.3.2 他モデルへのProgressive Learningの適用
ここでは提案手法のProgressive Learningの有効性を見るため、ResNetにも適用しています。その結果が下の表です。学習時間において、ResNetでもかなりのゲインが得られることがわかりますね。
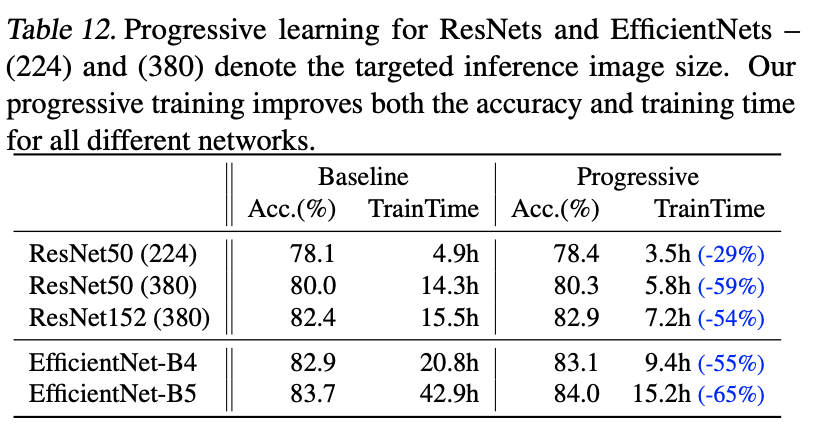
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
3.3.3 正則化の強さを変化させる重要性
ここでは提案手法のProgressive Learningにおいて、正則化の強さを変化させることが分類精度に影響を与えているかどうかを見ています。結論から言うと、正則化の強さを変えると分類精度が上がります。下図では緑色の方が高い分類精度となっているため、このことからも分かります。
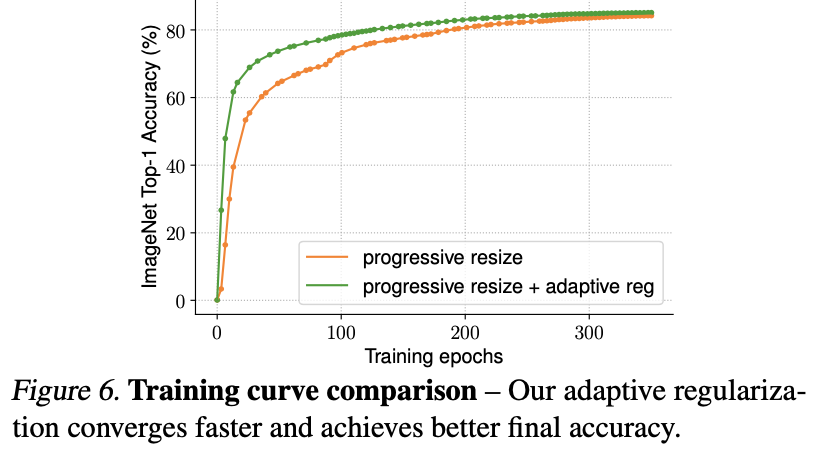
画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
本論文ではこれまでの実験で用いてきた画像を線形的に大きくしていく(Progressive resize)手法に加え、8エポックごとに画像サイズをランダムに決定する(Random resize)手法に対しても正則化の強さを変化させた場合を実験しています。下表がその結果で、Progressive resizeおよびRandom resizeいずれにおいても正則化の強さを変化させることでさらに高い分類精度を得られていることがわかります。

画像: "EfficientNetV2: Smaller Models and Faster Training", Tan, M., Le, Q., (2021)
4. まとめと所感
本記事ではEfficentNetV2を見てきました。EfficientNetV2は主に学習の効率性というところに着目したもので、V1はもちろん最近のモデル(ConvNetsおよびTransformers)たちよりも効率的な学習ができていることがわかりました。個人的には、Progressive Learningで画像サイズなどをどこでどう変化させるかのハイパラが増えてしまっていることが少し気になります。MobileNetやInceptionもV3が存在するので、EfficientNetのV3が登場するかもしれないので要注目ですね!
Twitterで人工知能のことや他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ: