オミータです。ツイッターで人工知能や他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
他にも次のような記事を書いていますので興味があればぜひ!
畳み込み+Attention=最強?最高性能を叩き出した画像認識モデル「CoAtNet」を解説!
2020年秋にVision Transformer[Dosovitskiy, A.(ICLR'21)](以下、ViT)が登場してからと言うものその人気が爆発し、2021年はViTに溢れた年と言えるでしょう(ViTについて詳しく知りたい方は拙著記事もご参照ください)。ただ、ViTが登場したがために、CNNがSelf-Attentionによって完全に駆逐されたかと言うと、そうではありません。畳み込みには、少ないパラメータ数でも効率よく学習できることや局所性を保持しているなど多くの利点があります。今回解説する論文"CoAtNet: Marrying Convolution and Attention for All Data Sizes", Dai, Z., et al., (2021)では、畳み込みとSelf-Attention、両者の良いとこどりをしたCoAtNet(読み方:コートネット)というモデルを提案し、ImageNetでSoTA(Top-1精度:90.88%)を叩き出しました。本記事では畳み込みとSAの復習から丁寧に入り、CoAtNetの説明および実験結果を解説します。それではCoAtNetの仕組みを見ていきましょう!
本記事の流れ:
- 忙しい方へ
-
CoAtNetの解説
- 畳み込みとSAの復習
- 畳み込みとSAを1つの式で表現
- CoAtNetのアーキテクチャ
- CoAtNetの実験結果
- まとめと所感
- 参考
原論文: "CoAtNet: Marrying Convolution and Attention for All Data Sizes", Dai, Z., Liu, H., Le, Q., Tan, M., (2021)
実装(非公式): PyTorch
0. 忙しい方へ
- CoAtNetは、DWConv(=Depthwise畳み込み) と SA(=Self-Attention) の良いとこどりをしたモデルだよ
- Relative Attentionを用いることで、DW畳み込みとSAの2つを1つの式で表現したよ
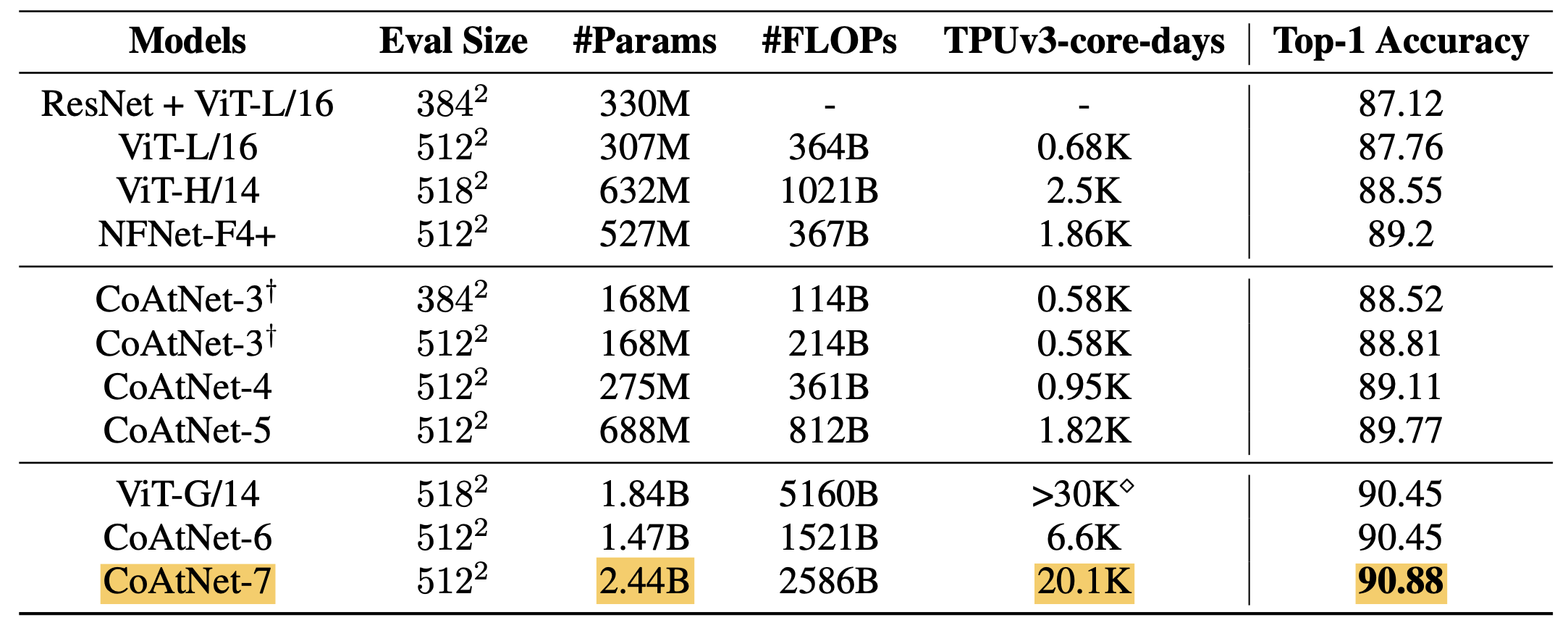
- 事前学習にJFT-3Bを用いることで、ImageNetにおいてCoAtNetがViT-G/14(過去SoTA)の4分の1の学習時間で同等の分類精度(90.45%)、そして3分の2の学習時間で新たなSoTA(90.88%) を叩き出したよ
| 略語 | 正式名称 |
|---|---|
| SA | Self-Attention |
| DW | Depthwise |
1. CoAtNetの解説
1.1 畳み込みとSAの復習
コンピュータビジョンで用いられている大きな仕組みに畳み込みとSelf-Attention(=SA)があります。畳み込みではEfficientNet、SAではViTが有名ですね。EfficientNetについてはこちらの拙著記事、ViTについてはこちらの拙著記事をご参照ください。CoAtNetでは、この畳み込みとSAの良いとこ取りをしたブロックを作ることが一番の目的になっています。畳み込みとSAの式を復習しておきましょう。ここでは畳み込みの中でもDW(=Depthwise)畳み込みを取り扱います。そして、本論文では分かりやすさを優先しているのか、式の細かいところ(SAにおけるqkvの埋め込みなど)はあえて排除しているように見えるので、理解しやすいです。
1.1.1 畳み込みの式
本論文では、畳み込みの中でもDW(=Depthwise)畳み込みを取り扱っています。DW畳み込みとは、各チャネルに対して1枚のフィルターのみを用いる畳み込みです。DW畳み込みについてより詳しく知りたい方は、拙著解説もご覧ください。論文中では、$x_{i},y_{i}\in\mathbb{R}^D$を用いて、DW畳み込みを下式で示しています。ここで$j\in\mathcal{L}(i)$はピクセル$j$の近傍ピクセル($3\times3$など)、$x_{i},y_{i}$はそれぞれ位置$i$に対する入力および出力のベクトル(長さ$D$)、です。(厳密には、この式だとDepthwise畳み込みのうち、さらにチャネル方向に重みを共有したLightweight畳み込みになっているように見えますが。。。ご意見などTwitterかコメントでお待ちしてます。)
\begin{align}
y_i = \sum_{j\in\mathcal{L}(i)} w_{i-j}\odot x_{j}
\end{align}
ここで言いたいのは、以下の3つです。
- DW畳み込みは、入力ベクトル$x_{j}$の加重和。(重みは$w_{i-j}$)
- 重み$w_{i-j}$は学習時に決定するもので、推論時に(より正確には入力値によって)変わることはない。
- 重みが$w_{i-j}$であることから、加重和の重みはピクセル$i$と近傍$j$の相対位置によってのみ決定する
3つ目の加重和の重みが相対位置によって決定する、というのが後述するTranslation Equivarianceという畳み込みの良いところを実現してくれています。それでは続いてSA(=Self-Attention)について見ていきましょう。
1.1.2 SAの式
先程のDW畳み込みと同様に、SAの式を表します。本論文では分かりやすさのために細かい正確性はここで画像全体の位置たちを$\mathcal{G}$、位置$i$に対する入力および出力のベクトルをそれぞれ$x_{i},y_{i}\in\mathbb{R}^D$、Attentionスコアを$A_{i,j}$とするとSAは下の式で表せます。
$$
\begin{align}
y_i = \sum_{j\in\mathcal{G}} A_{i,j} x_{j}
\end{align}
$$
非常に簡単です。ただの$A_{i,j}$による加重和ですね。SAもDW畳み込みも基本的にはただの加重和です。ただDW畳み込みと決定的に異なるのが次の2点です。
- 加重和の重み$A_{i,j}$は入力値によって決定される。
- $y_{i}$の計算に考慮する範囲が画像全体$G$である。
2つ目に関しては$j\in\mathcal{G}$から自明です。1つ目に関してですが、これはAttentionスコア$A_{i,j}$がどう計算されていたかを思い出せば分かります。$A_{i,j}$は$(x_{i},x_{j})$の類似度 です。より正確には、内積にsoftmaxを適用した値となっています。式で表すと、下のようになります。
$$
\begin{align}
A_{i,j} = \frac{\exp{(x_{i}^{\top} x_{j})}}{\sum_{k\in\mathcal{G}}\exp{(x_{i}^{\top} x_{k})}}
\end{align}
$$
この式からも、Attentionスコア(加重和の重み)は入力値の$x_i$などで決定していることが分かります。例えば、推論時にも入力画像によってこの重み$A_{i,j}$は変わると言うことですね。DW畳み込みとSAとでは、この加重和の重みが固定されているか、入力値によって変動するのか、というのが大きく異なっています。SAではこの加重和が入力値によって臨機応変に変わるので、柔軟性が高いと見ることもできます。最後に、上式を合わせてSA全体の式を示します。
$$
\begin{align}
y_i = \sum_{j\in\mathcal{G}} \frac{\exp{(x_{i}^{\top} x_{j})}}{\sum_{k\in\mathcal{G}}\exp{(x_{i}^{\top} x_{k})}} x_{j}
\end{align}
$$
1.1.3 畳み込みとSAの良いところを比較
それでは畳み込みとSAの良いところとは何があるのでしょうか。それをまとめた表が下の表になります。

この表を見ると、畳み込みには「Translation Equivariance」なるものが、SAには「Input-adaptive Weighting」および「Global Receptive Field」なるものが良いところとしてあるようです。これだけ言われてもよくわかりませんね。これらを噛み砕くと次のような説明になります。
- Translation Equivariance: 入力画像が平行移動されると出力も平行移動したものになるよ(さらに、Poolingなどと組み合わせることで画像の平行移動に対してロバストに埋め込めると私は解釈しています。)
- Input-adaptive Weighting: 入力の値によって重み(正確にはAttentionスコア)が変わるよ
- Global Receptive Field: 画像全体を一気に見ることができるよ

Translation Equivarianceの例。入力が平行移動すると出力の特徴マップも同様に平行移動する。
GIF: Harmonic Networks: Deep Translation and Rotation Equivariance
畳み込みのTranslation Equivarianceの詳しい説明は、こちらの記事や動画が大変わかりやすいです。これら3つの特性が組み合わさったものがあれば最強に思えます。それでは、これら3つの特性を組み込んだ最強なブロックを次の項で見てみましょう。
1.2 畳み込みとSAを1つの式で表現
畳み込みとSAの組み合わせ方ですが、非常にシンプルです。SAの式において、Softmax適用前に重み$w\in\mathbb{R}^{O(|\mathcal{G}|)}$を足し算するだけです。重み$w$は、画像全体の相対位置に対して値を持っています。ここではパラメータ数が激増しないように、$w_{i-j}$はスカラーになっています。
$$
\begin{align}
y_{i}^{\text{pre}}=\sum_{j\in\mathcal{G}} \frac{\exp{(x_{i}^{\top} x_{j} + w_{i-j})}}{\sum_{k\in\mathcal{G}}\exp{(x_{i}^{\top} x_{k} + w_{i-k})}} x_{j}\
\end{align}
$$
気持ちとしては、Attentionスコアの計算時にTranslation Equivarianceを持つ$w_{i-j}$を追加している、ということになります。これによってTranslation Equivariance、Input-adaptive WeightingおよびGlobal Receptive Fieldの3つを組み込んでいるということです。ちなみに、Relative Attention[Shaw, P.(NAACL'18)]をご存知の方は気づいたかもしれませんが、上の式はRelative Attentionの一種と見ることができます。それでは実際にこの式を用いたTransformerブロックを積み上げることで、CoAtNet全体を作っていきましょう。
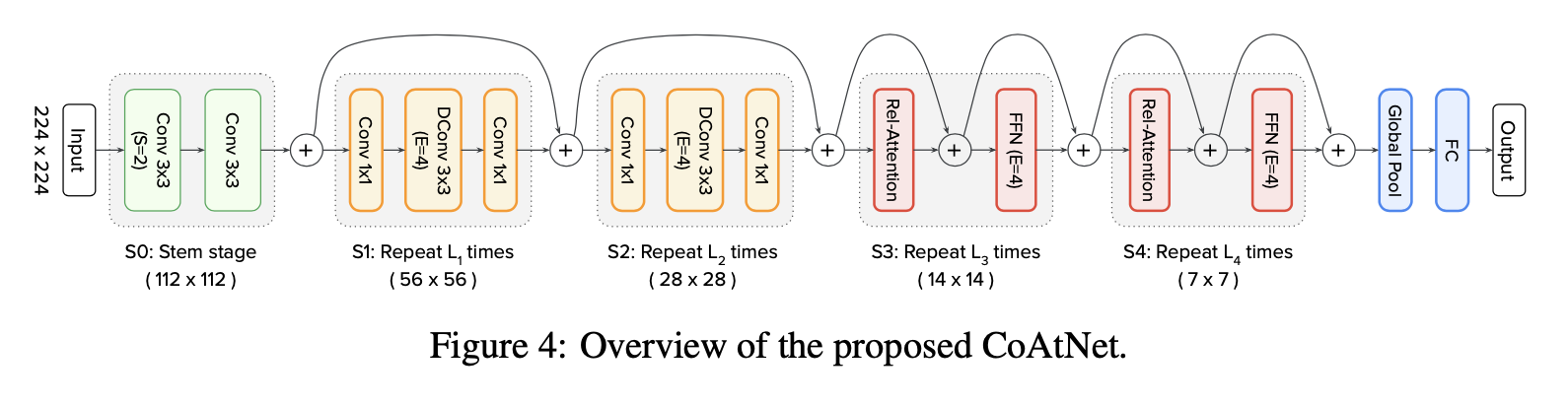
1.3 CoAtNetのアーキテクチャ
それでは、上述した式を用いたTransformerブロックのみを積み上げてCoAtNetを作っていきましょう。としたいのですが、SA系が持つ入力画像サイズの二乗で計算量が増えてしまう問題にぶち当たってしまいます。これを回避するためにMBConvブロックを併用します。MBConvブロックとは、MobileNetV2から登場したMobile Inverted Bottleneckブロックのことで、畳み込みで構成されています。EfficientNetにも用いられています。MBブロックは、DW畳み込みをフィルターサイズが1x1の畳み込み(=Pointwise畳み込み)で挟んだ形になります。また、Inverted Bottleneck(=逆ボトルネック)という名前の通り、最初のPointwise畳み込みでチャネル数を4倍に増やし、2つ目のPointwise畳み込みで元のチャネル数に戻すと言う構造になります。
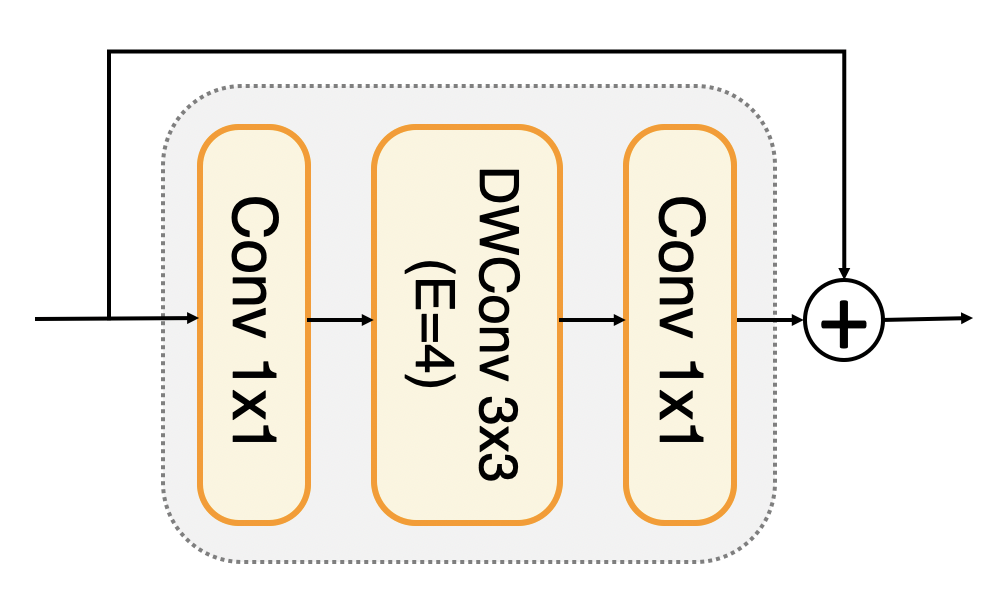
MBConvの構造。EはExpansion ratio(拡張率)を指す。この図では、チャネル数をConv1x1で4倍にし、それをDWConv3x3で処理したあと、Conv1x1で元のチャネル数に戻すということ。
MBConvブロックとTransformerブロックをどのように積み上げるかが肝になります。本論文では次の3つの観点から実験的にベストなアーキテクチャを探しています。下の箇条書きで、この論文における具体的な比較方法も記載しておきます。
- 汎化性能(Generalization): 学習時のlossが同じモデルを比較し、推論時の分類精度が高いと汎化性能が高いとするよ
- モデルのキャパシティ(Model capacity): 学習データをかなり増やしてもしっかり性能が向上する場合は、モデルのキャパシティが大きいとするよ
- 転移学習時の性能(Transferability): 転移学習後の性能が良いと、Transferebilityが高いとするよ
これら3つの指標を用いて最適なモデルを探すのですが、候補となるモデルのアーキテクチャはResNetなどと同様に5ステージ制にしており、一番最初のブロック(これをS0と呼ぶ)は2層の畳み込みで固定しています。それ以降のS1~S4の4つのブロックを選ぶことになります。候補となるモデルたちはC-C-C-C、C-C-C-T、C-C-T-T、C-T-T-T、 $\text{ViT}_\text{REL}$ の5つです。ここでCはMBConv、Tは上述したRel. Attn.を用いたTransformerブロックとします。例えば、C-C-C-Tは最初の3ブロックがMBConvで最後だけTransformerブロック、ということです。 ここで$\text{ViT}_\text{REL}$は全層Transformerブロックになっているため、Rel. Attn.を用いたViTと言うことができます。それでは、3つの観点で行った実験結果だけを一気に見ていきます。
- 汎化性能(Generalization): ImageNet-1K(画像数:130万枚)での分類精度比較。左側にあるほど良いということです。畳み込み系が強いです。
$$
\text{C-C-C-C} \approx \text{C-C-C-T} \geq \text{C-C-T-T} \gt \text{C-T-T-T} \gg \text{ViT}_\text{REL}
$$
2. モデルのキャパシティ(Model capacity): JFT-300M(画像数:3億枚)での分類精度比較。左側にあるほど良いということです。
$$
\text{C-C-T-T} \approx \text{C-T-T-T} \gt \text{ViT}_\text{REL} \gt \text{C-C-C-T} \gt \text{C-C-C-C}
$$
3. 転移学習時の性能(Transferability): JFTで事前学習、ImageNet-1Kにファインチューニングした結果の比較。この実験は、C-C-T-TとC-T-T-Tの頂上決戦となっています。
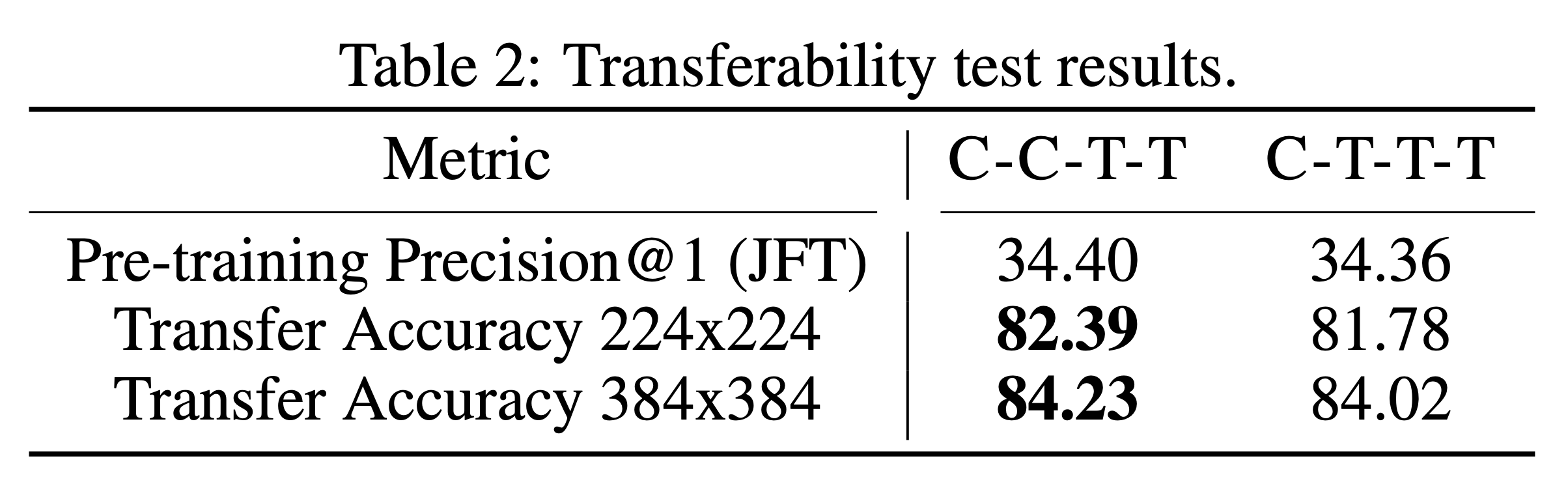
これらの実験をもとに選ばれたC-C-T-Tを新たなモデルCoAtNetとして提案しています。全体のアーキテクチャを図で表すと、下の図のようになります。それではCoAtNetの真の実力を実験結果たちで見ていきましょう。
2. CoAtNetの実験結果
本論文で行っている実験は、次のように体系立てられます。
-
画像分類タスク
- ImageNet-1K
- ImageNet-21K
- JFT-300M/JFT-3B
-
アブレーションスタディ
- Rel. Attn.について
- CoAtNetのアーキテクチャについて
ここでは、下表のようにレイヤー数やチャネル数をいじることでCoAtNet-0からCoAtNet-4までバラエティ豊かに揃えています(JFTデータセットに対しては、CoAtNet-7まで登場します)。下表の説明文で急にSEが登場しますが、MBConvの中にSEを用いているやつのようですね。(この辺りの詳細はMobileNetの記事で解説しておりますので、ご参照ください。)

2.1 画像分類タスクの結果
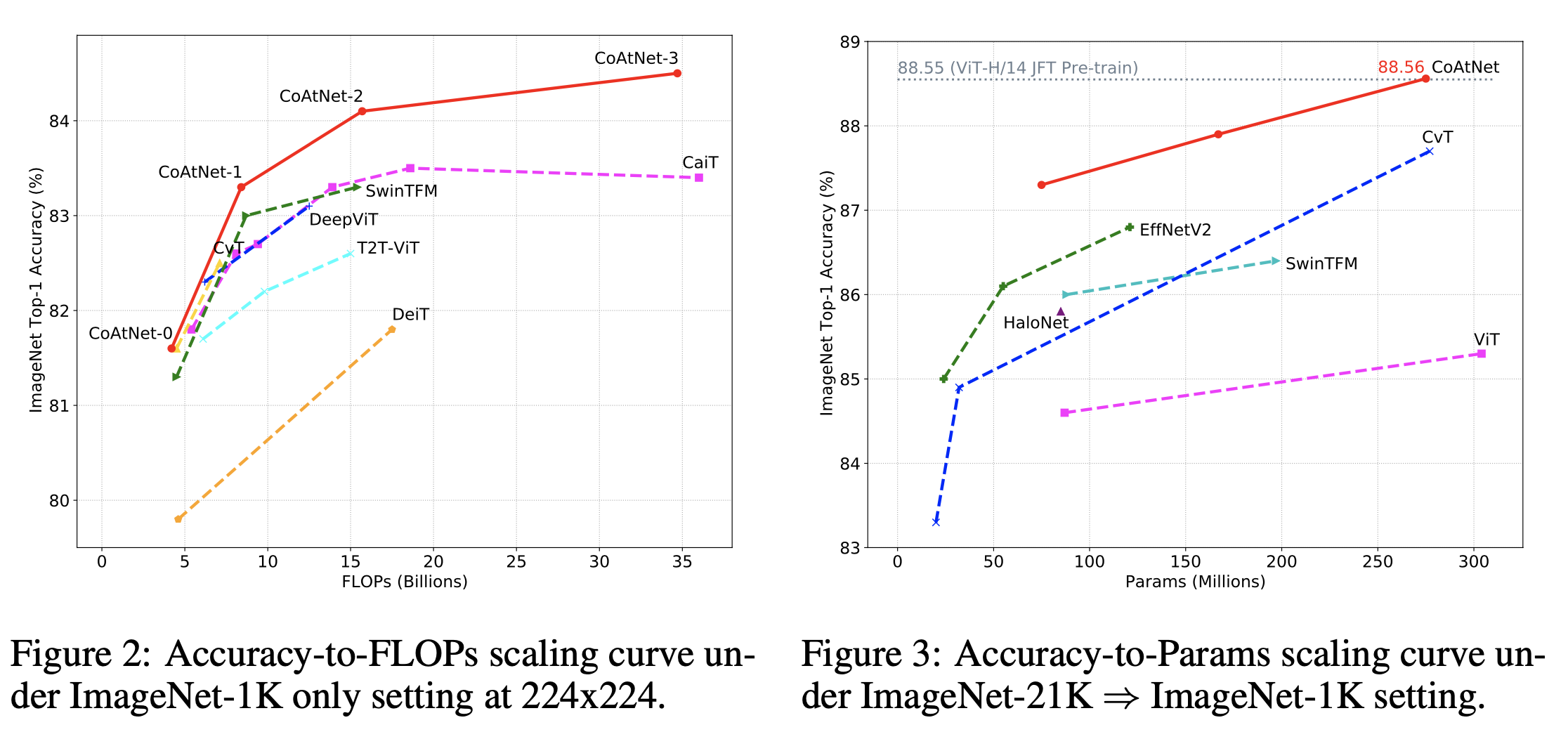
まずはImageNet-1KとImageNet-21K(画像数:1,400万枚)について一気に見ていきます。分類精度は全てImageNet-1Kで評価されています。ImageNet-21Kは事前学習で用いるだけです。左図がImageNet-1Kのみで学習した結果、右図がImageNet-21Kで事前学習しImageNet-1Kにファインチューニングした結果になっています。横軸がFLOPs、縦軸が分類精度になっています。赤線がCoAtNetですが、ViT系のCvT(拙著解説)やCNN系のEfficientNetV2(拙著解説)などをCoAtNetが引き離す形になっています。これを見るとCoAtNetの凄さを感じますね。ただ、せっかくならImageNet-1Kの改良版であるReaL(拙著解説)などの結果も載せて欲しいと思ってしまいますが。。。それではJFTによる事前学習の結果を見てみましょう。
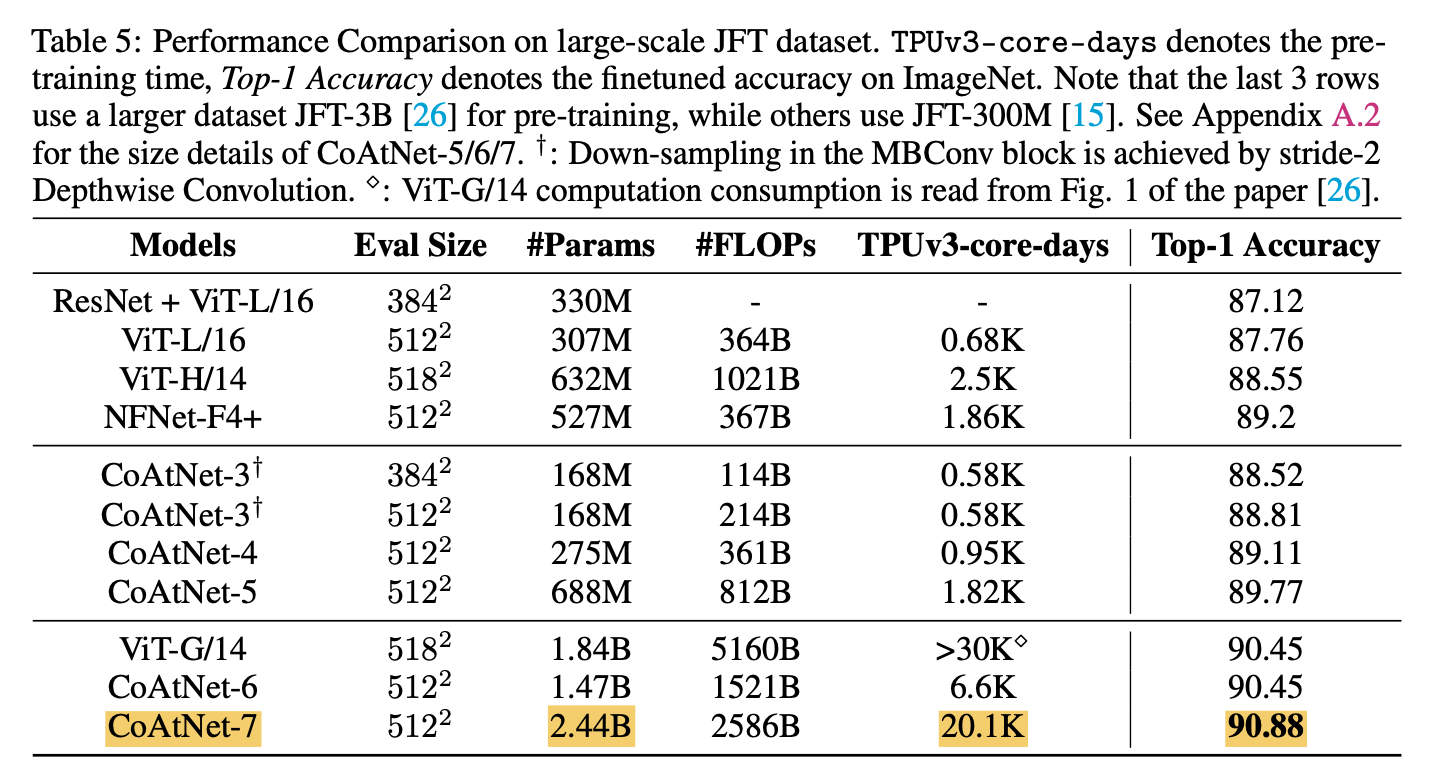
上の表がJFT-3Bで事前学習した場合のImageNetの分類精度になります。まずは、CoAtNet-7がViT-G/14の3分の2の計算リソース(TPUv3-core-days)で、90.88%という新たなSoTAを達成しています。また、CoAtNet-6を見てみると、こちらはViT-G/14と同等の分類精度を4分の1の計算リソースで達成しています。CoAtNetが効率の良いモデルであることがわかります。
2.2 アブレーションスタディ
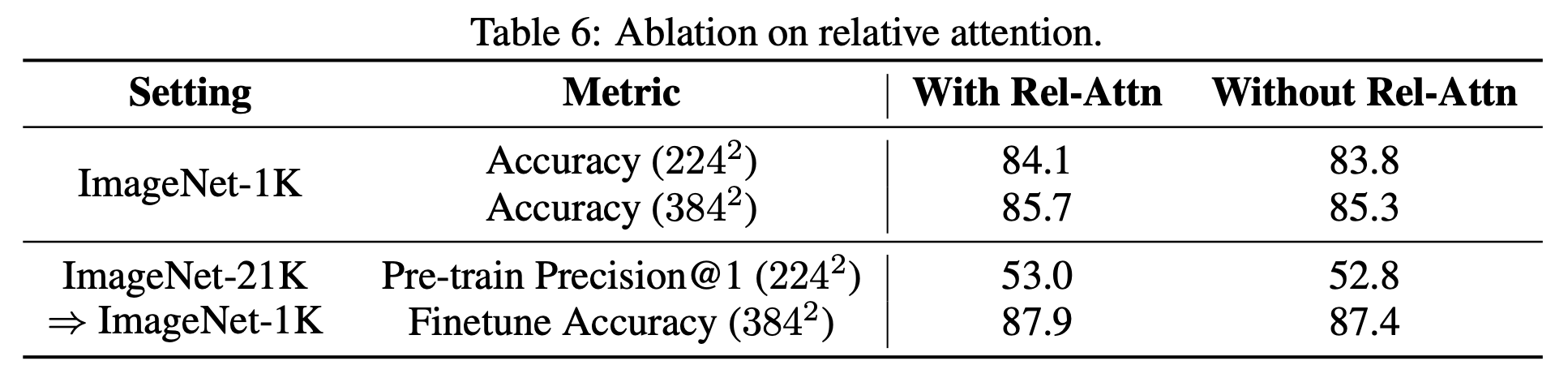
上の表では、Rel. Attn.が通常のSAよりも良いかどうかを見ています。「Without Rel-Attn」では通常のSAを用いています。データセットにはImageNet-1K/-21Kを用いています。画像サイズも少し変えて評価もしています。いずれにおいても、CoAtNetで用いられているRel. Attn.が通常のSAよりも良いことが分かります。
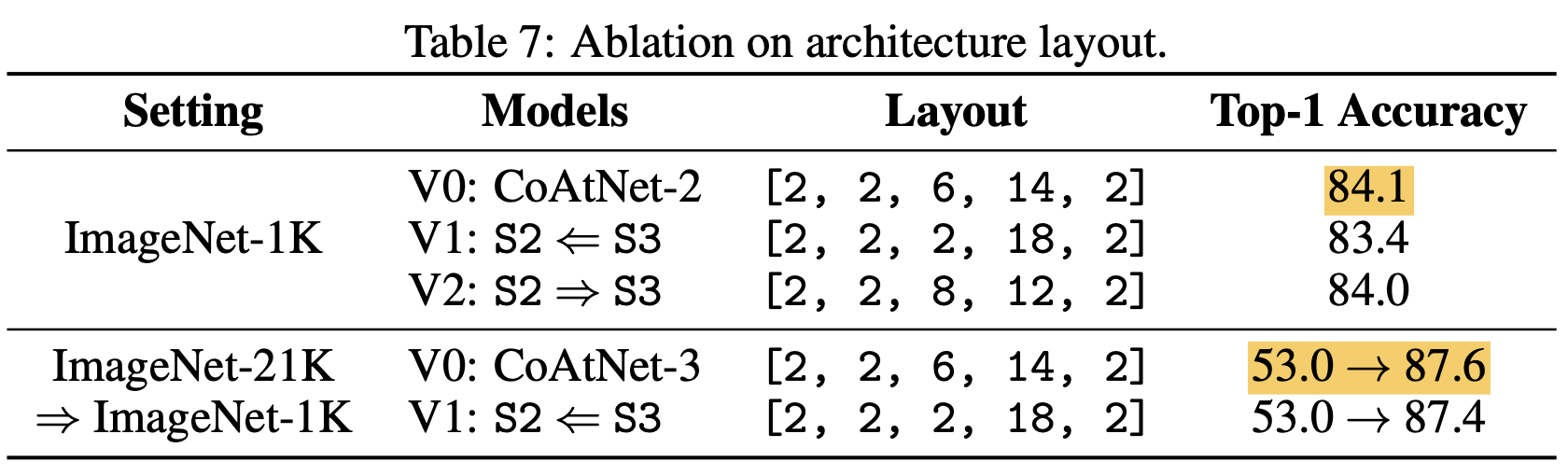
ここでは主にS2とS3のレイヤー数について見ています。CoAtNetがC-C-T-Tであったことを思い出すと、S2とS3は畳み込みとTransformerが入れ替わるところでした。それぞれのブロックの層の数はいずれか一方だけを増やした方がいい、というわけでもなく、ちょうどいい均衡があることが分かります。

最後にヘッドの数(32 vs 64)およびノーマライゼーション(バッチノーム vs レイヤーノーム)について見ています。ヘッドの数は32の方が良いですが、ノーマライゼーションはBNもLNもあまり変わりません。ちなみに、TPUにおいては、ヘッドの数は多い方が、またノーマライゼーションはBNの方が、処理が速いようです。
3. まとめと所感
本記事では、ImageNetの新たなSoTAであるCoAtNetについて見てきました。CoAtNetは、畳み込みとSAを組み合わせたRelative Attentionをうまく用いることで、これまでのモデルよりも効率の良い学習ができていました。畳み込みとSAどちらか一方だけを良しとするのではなく、それらを上手にハイブリッドするという研究がこれからも盛んに行われそうです。CoAtNetの展望として、物体検出やセマンティックセグメンテーションへの応用も挙げられているので、そちらにも大きく期待ができそうですね!
Twitterで人工知能や他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ:
4. 参考
-
"CoAtNet: Marrying Convolution and Attention for All Data Sizes", Dai, Z., Liu, H., Le, Q., Tan, M., (2021)
原論文 -
"Self-Attention with Relative Position Representations", Shaw, P., Uszkoreit, J., Vaswani, A., (NAACL'18)
Relative Position(Attention)を提案した論文 -
"Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models", Chang, T., Xu, Y., Xu, W., Tu, Z., (ACL-IJCNLP'21)
Depthwise ConvolutionとSelf-Attentionの関連性をわかりやすく書いてくれている論文 -
CNNs and Equivariance - Part 1/2
畳み込みのTranslation Equivarianceについて解説してくれている記事。 -
05 Imperial's Deep learning course: Equivariance and Invariance
畳み込みのTranslation Equivarianceについて解説してくれている動画。