オミータです。ツイッターで人工知能のことや他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
他にも次のような記事を書いていますので興味があればぜひ!
新たな学習方法!「教師あり」Contrastive Learningを解説!
2020年に大流行した自己教師あり学習のContrastive Learningをご存知でしょうか。Contrastive Learning(以下、CL)とは言わばラベルなしデータたちだけを用いてデータの表現を学ぶ学習方法で、「似ているものは似た表現、異なるものは違う表現に埋め込む」 ことをニューラルネットに学ばせます(CLの手法やアーキテクチャなどのまとめは拙著のこちらをご覧ください)。このCLによって自己教師あり学習は2020年大きく飛躍したのですが、このCLを教師あり学習と組み合わせたものが"Supervised Contrastive Learning", Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D., (NeurIPS'20)で提案された教師ありCLです。教師ありCLによって、クロスエントロピー損失を用いる通常の教師あり学習よりも高い分類精度およびロバスト性を示しました。教師ありCLは、原理が簡単で注目度も高いです。それではその中身を見ていきましょう!

本記事の流れ:
- 忙しい方へ
-
教師ありContrastive Learningの説明
- Contrastive Learning
- SimCLR
- 教師ありContrastive Learning
- 教師ありContrastive Learningの実験
- まとめと所感
- 参考
原論文: "Supervised Contrastive Learning", Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D., (NeurIPS'20)
公式実装: TensorFlow / PyTorch
| 略語 | 正式名称 |
|---|---|
| CL | Contrastive Learning |
| DA | Data Augmentation |
0. 忙しい方へ
- Contrastive Learningにラベル情報を用いる教師ありCLを提案したよ
- 教師ありCLで用いる損失関数はSupCon(=Supervised Contrastive)という名前だよ
-
教師ありCLがクロスエントロピー損失を用いた通常の教師あり学習よりも高い性能を示したよ
- ImageNet/CIFAR-10/CIFAR-100の画像分類タスクでより高い分類精度を示したよ
- ハイパーパラメーター(e.g. 学習率)への高い安定性も示したよ
- ImageNet-Cへのロバスト性もより良いよ
1. 教師ありContrastive Learningの説明
1.1 Contrastive Learning
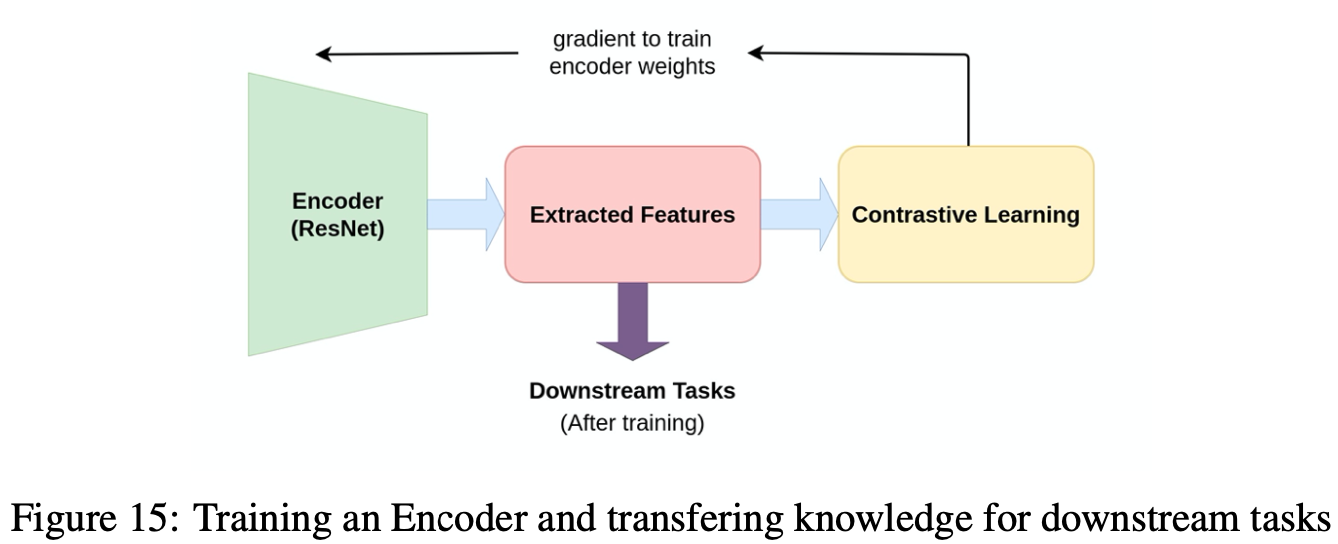
そもそもContrastive Learning(以下、CL)は、モデルの事前学習のように用いられることが多いです。つまり、画像の特徴量をうまく抽出できるようなモデル(上図のEncoder)をCLによって作ってしまおうということです。それを達成させるためにCLでは、「似ているデータは潜在空間でも似た埋め込みベクトルになり、異なるデータは潜在空間でも異なる埋め込みベクトルになる」ようにモデルを学習させます。これがCLの根幹にあるアイデアになります。
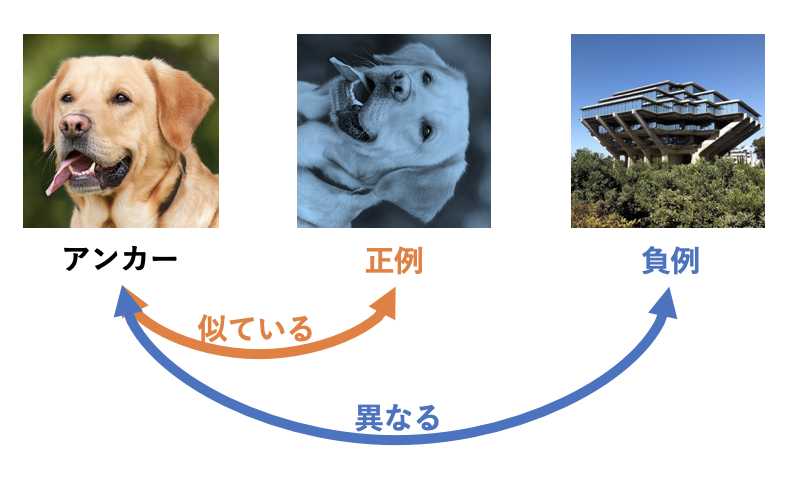
CLではさらに アンカー(Anchor) と 正例(Positive) と 負例(Negative) の3つが登場します。アンカーを軸としてアンカーと似ているデータを正例、アンカーと異なるデータを負例と呼びます。上図の例ではアンカーとして犬画像を用い、アンカーをデータオーギュメンテーション(以下、DA)したものが正例になっています。一方で負例は建物の画像で全く異なるものになっています。上図のように、正例としてアンカーにDAを適用したものを用いることが多い一方で負例の獲得方法はいろいろなものが提案されています。教師ありCLでは、一番単純な「バッチ内のアンカー以外の画像たちを負例とする」作戦を取っています。そのほかの獲得方法について詳しく知りたい方はこちらをご参照ください。これと同じ負例の定義をしているものにSimCLR[Chen, T.(ICML'20)]があります。実際に、教師ありCLはそのほとんどがSimCLRを踏襲したものになっています。次項でSimCLRについて簡単に説明をしていきます。
1.2 SimCLR
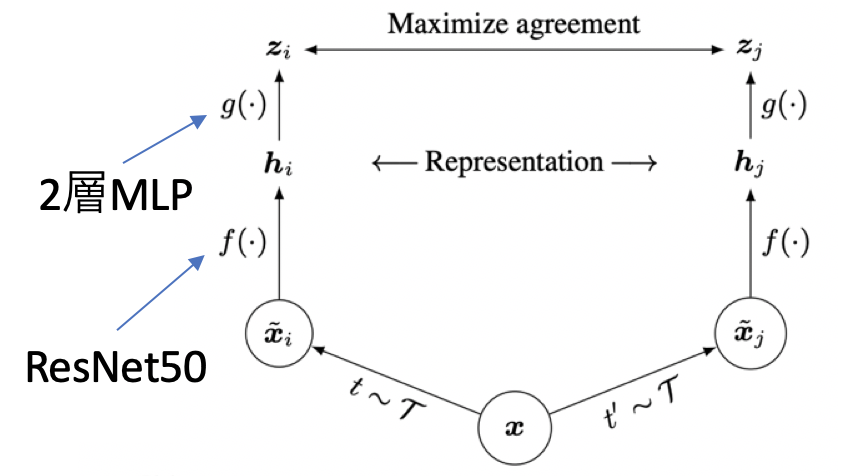
[Chen, T.(ICML'20)]で提案されたSimCLRでは、負例としてバッチ内のアンカー以外の画像たちを用います。SimCLRでは次の3つが大きな構成部品となっています。
- データオーギュメンテーション, $t(\cdot)$: $t$はDAの集合$\mathcal{T}$からサンプルし、バッチに適用。$t$と$t'$を別々に適用する
- エンコーダー, $f(\cdot)$: 転移学習などにも用いる埋め込み表現(2048次元ベクトル、正規化済み)を出力するネットワーク。ResNet50などの識別器よりも前の部分。
- プロジェクションネットワーク, $g(\cdot)$: Contrastive Learningで用いられる埋め込み表現(128次元ベクトル、正規化済み)を出力するネットワーク。
ここで1点注意して欲しいことは、SimCLRではアンカーもDAされていることです。そのため、アンカーの元画像にまた別のDAを適用したものが正例となります。通常のバッチが$N$個だとすると、それぞれのDAを適用したバッチがあるので全体で大きさ$2N$のバッチが出来上がります。前者(サイズN)をバッチ、後者(サイズ2N)をmultiviewedバッチと呼びます。
このSimCLRでは、CLの最大の目的「似ているデータは潜在空間でも似た埋め込みベクトルになり、異なるデータは潜在空間でも異なる埋め込みベクトルになる」を実現するために損失関数として以下式のNormalized Temperature Cross Entropy(=NTXent)を用います。
\mathcal{L}^{self}=\sum_{i\in I} \mathcal{L}_i^{self} = -\sum_{i\in I}\log{\frac{ \exp(\mathbf{z}_i\cdot\mathbf{z}_{j(i)}/\tau) } { \sum_{a\in A(i)}\exp(\mathbf{z}_i\cdot\mathbf{z}_a/\tau) } }
ここで、$I$はmultiviewedバッチ内の画像たち全て、$i$はアンカー画像、$A$は$I{\backslash{i}}$つまりアンカー$i$以外の全ての画像として定義されます。$\mathbf{z}$は画像の埋め込み表現です。$\tau$は温度と呼ばれるハイパーパラメーターです。上式はぱっと見わかりづらいですが、よく見ると単にアンカー$\mathbf{z}_i$との内積たちに温度付きソフトマックスを適用しているだけです。つまり、気持ちとしてはアンカー$\mathbf{z}i$とその正例$\mathbf{z}{j(i)}$の内積をアンカーと負例の内積たちよりも一番大きくしたい、という感じです。

最後に、通常のCLをもう一度図でまとめます。上図の画像たちを埋め込む時、アンカー(灰色)と正例(オレンジ色)は近くに配置され負例(赤色)たちはそれらよりも遠くに配置されます。これがCLの概要ですが、1つ問題を孕んでいます。それは、同じ意味を有す画像たちも負例となってしまっていることです。これは本来CLではラベル情報を使わずに負例を獲得するため、アンカーと同じラベルを有す画像だとしても元画像が異なるためにお構いなしで負例とみなされてしまうのです。上図で言うとアンカーの犬画像に対して、赤枠で囲われた犬画像が負例とされてしまっています。意味の似たような画像たちは近くに埋め込まれるべきなのに、上図のままでは遠くに配置させようとしまい学習に悪影響を与えそうです。これを回避するために、提案手法の教師ありCLではラベル情報を使います。ここに教師ありと呼ばれる所以がありますね。
1.3 教師ありContrastive Learning

上図のようにアンカーと同じ意味を持つ画像も正例としたいです。教師ありCLでは、これを実現するためにラベルを用いるだけです。とても簡単です。同じラベルの画像たち(とそのDA)を正例とするだけです。これを学習に組み込むのは損失関数として次式を用いることでできます。下式で$P(i)$はアンカー$i$と同じラベルの正例たちで、${p\in A(i):\mathbf{\tilde{y}}_p = \mathbf{\tilde{y}}_i}$で定義されます。
\mathcal{L}^{sup}_{out}=\sum_{i\in I} \mathcal{L}^{sup}_{out, i} = \sum_{i\in I} \frac{-1}{|P(i)|} \sum_{p\in P(i)} \log{\frac{ \exp(\mathbf{z}_i\cdot\mathbf{z}_{p}/\tau) } { \sum_{a\in A(i)}\exp(\mathbf{z}_i\cdot\mathbf{z}_a/\tau) } }
ラベルごとにCLの平均を取っている感じですね。正例も負例と同様バッチ内から取ってきているようです。教師ありCLはこれを用いるだけです。あとはSimCLRとほぼ同じです。それではこの教師ありCLが通常のクロスエントロピーを用いた場合の教師あり学習と比べてどうなのかを次節で見ていきましょう。
2. 教師ありContrastive Learningの実験
実験内容は大きく次の3つです。
- 画像分類
- ロバスト性(ノイズ/ハイパーパラメーター)
- 転移学習
比較対象として通常の教師あり学習であるクロスエントロピー損失を用いた学習モデルと自己教師あり学習のSimCLRを主に用いています。ネットワークはResNet-50/-200/-101を用いています。
2.1 画像分類

まずはResNet-50におけるCIFAR10/CIFAR100/ImageNetの画像分類を行っています。上表の通り、通常の教師あり学習であるCross-Entropyや自己教師あり学習のSimCLRよりも提案手法のSupConが良いことがわかりますね。下表にはより詳しく書かれています。

ResNet-50においてはSupConにAutoAugmentを用いたものが最も良いです。ResNet-200においてはSupConにStacked RandAugmentを用いたものが最もいいです。AutoAugment[Cubuk, T. (CVPR'19)]とは、強化学習で探索した最適なDAの組み合わせを用いたもので、Stacked RandAugmentとは、SimCLRで用いられたDAにランダムにハイパーパラメータを探索するRandAugment[Cubuk, T. (CVPRW'20)]を組み合わせたものです。
2.2 ロバスト性
2.2.1 ノイズへのロバスト性

ここでは、モデルのノイズへの堅牢性(ロバスト性)を見ます。このとき上図のような何かしらの自然的な変化が加えられた画像を用います。ここではImageNet-C(上図)と呼ばれるデータセットで評価します。用いる評価指標はmCE(=mean Corruption Error)とrel. mCE(=relative mCE)です。mCEは単なるエラー率で、rel. mCEはTop-1分類精度が異なるモデル同士での比較に向いている指標です。これらを比較したものが下表です。

baselinesは論文から取ってきたもののようです。提案手法の教師ありCLが一番ノイズへのロバスト性がありますね。続いて、このノイズの具合を徐々に高めていったときの挙動を見ていきます。

横軸がノイズの強さ(Corruption Severity)を表しており、右に行けば行くほどノイズが強くなっていきます。そのため、Top-1精度も落ちていきます。青がクロスエントロピーで、紫が提案手法の教師ありCLになっています。わずかではありますが、紫の方がTop-1精度が常に高いです。このことからも教師ありCLのノイズのロバスト性が通常のクロスエントロピーよりも高いことがわかります。
2.2.2 ハイパーパラメーターへのロバスト性

ここでは各ハイパーパラメーターを変化させた時のモデル(ResNet-50)の挙動を見ていきます。全体を通して紫が提案手法、青がクロスエントロピーを示しています。上図の左から右にその結果から得られる考察をまとめました。
- DA/オプティマイザー/学習率: 提案手法(紫)の方が分散が小さく、ハイパーパラメーターによる影響を受けづらい。
- バッチサイズ: いずれのバッチサイズにおいても提案手法(紫)がより良い。2048(でか。)くらいでちょうどいい。
- エポック数: 350くらいがちょうどいい。
- 温度: あまり大きくない方がよく、0.1がベスト。
2.3 転移学習

転移学習に関しては提案手法の教師ありCL(SupCon)が一番というわけではなく、他のSimCLRやクロスエントロピー(Xent)と拮抗した感じです。ImageNetの精度が高いからと言って転移学習もうまくいくわけではなく、通常の学習と転移学習との関連性はFuture Workとしています。
3. まとめと所感
新たに提案された教師ありCLについて見てきました。教師ありCLとは単にラベル情報を用いたContrastive Learningで、画像分類精度およびロバスト性において通常のクロスエントロピーを用いた教師あり学習よりも高い性能を示しました。ただし、バッチサイズは2048ととても大きいため、ここさえ解決できれば画像のみならずNLPやグラフなど他分野でも新たな学習方法として広く注目される可能性もあります。いずれにせよこの先もContrastive Learningがいろいろなところで猛威を奮ってきそうですね。
Twitterで人工知能のことや他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ: