オミータです。ツイッターで人工知能のことや他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
他にも次のような記事を書いていますので興味があればぜひ!
画像生成も畳み込まない!TransformerによるGAN「TransGAN」誕生&解説!
2021年2月にとうとうGAN(Generative Adversarial Networks)でも誕生しました。畳み込みは全く用いずTransformerのみで画像を生成する、TransGANです。しかもSTL-10の画像生成においてはCNNベースのGANを打ち破りState-of-the-Art(SoTA) な性能を示しています。つい最近ViT(Vision Transformer)[拙著解説]が画像分類タスクでSoTAを達成したと思えば、もう画像生成タスクにもTransformerがやってきてしまいました。TransGANのアーキテクチャはViTに非常に似ておりとてもシンプルです。本記事ではTransGANのアーキテクチャから入り、実験結果およびTransGANの学習に用いられている小技について解説していきます。それでは早速TransGANについて見ていきましょう!
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
本記事の流れ:
- 忙しい方へ
- TransGANの説明
- TransGANの実験
- まとめと所感
- 参考
原論文: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
公式実装: PyTorch
| 略語 | 正式名称 |
|---|---|
| GAN | Generative Adversarial Networks |
| G | Generator |
| D | Discriminator |
| DA | Data Augmentation |
| SA | Self-Attention |
| MSA | Multi-Head Self-Attention |
| LN | Layer Normalization |
0. 忙しい方へ
- CNNから完全に解放された画像生成のGANを目指したよ
- TransGANは生成器(G)にも識別器(D)にもTransformerのエンコーダを用いているよ
- TransGANで高い性能を得るには次の4つが欠かせないよ
- データオーギュメンテーション
- 超解像タスクを用いたCo-training
- Self-Attention(SA)の適用範囲の調整
- スケールアップ
- STL-10では、CNNベースのGANの性能を超えState-of-the-Art(SoTA)な性能を叩き出したよ
1. TransGANの説明
1.1 Transformerエンコーダ
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
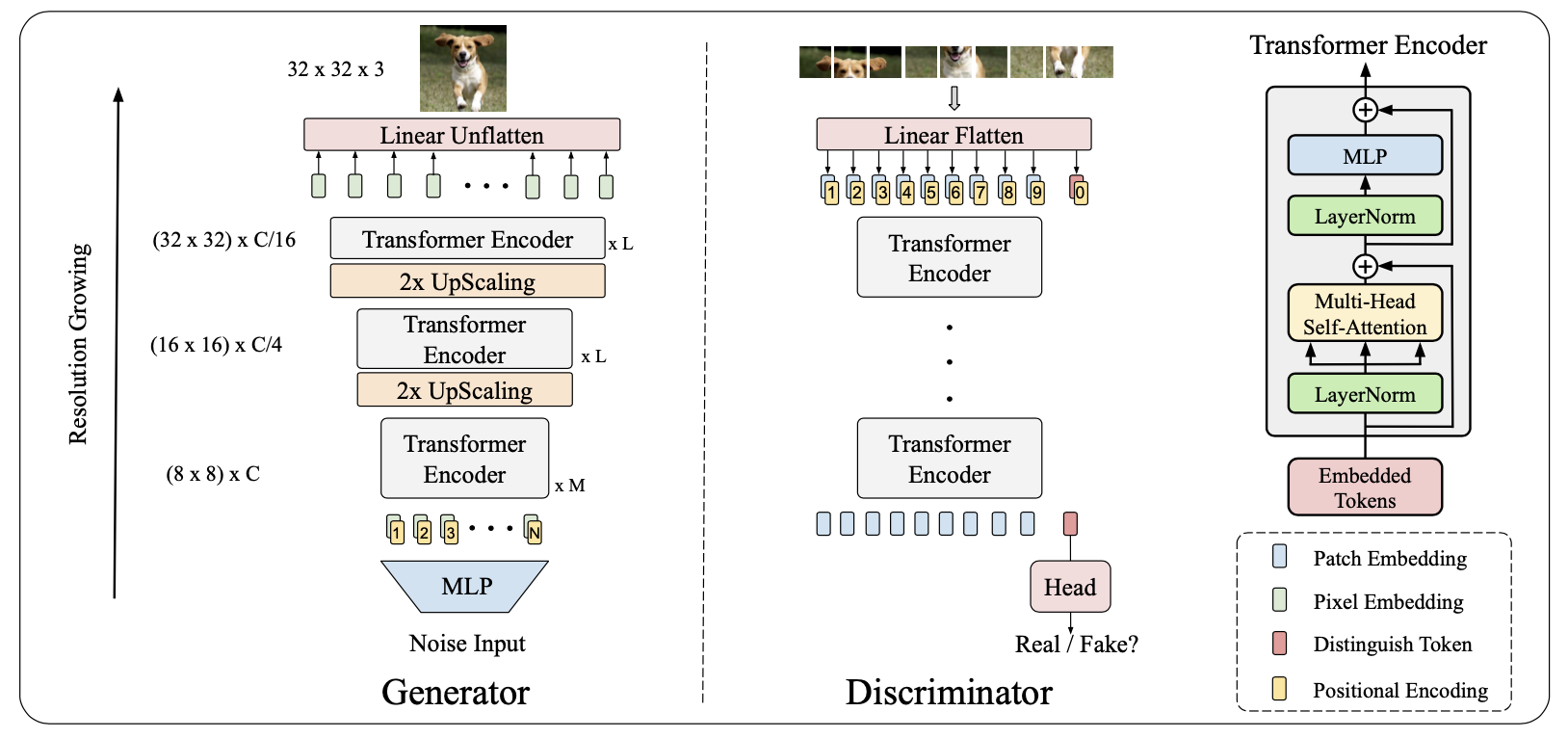
TransGANはTransformerのエンコーダブロックを多段に重ねることで高い性能を示しています。上図がエンコーダブロックになっていますが、これはViTと同じものです。構成部分は次の3つです。
- レイヤーノーマライゼーション(LN)
- マルチヘッドSelf-Attention(MSA)
- 全結合層
ここで、入力はEmbeded Tokensとなっていますが、これもViTと同様です。ViTでは、このEmbeded Tokensを作る方法に一番の工夫がある(と私は思っている)ので、少し詳しく説明します。
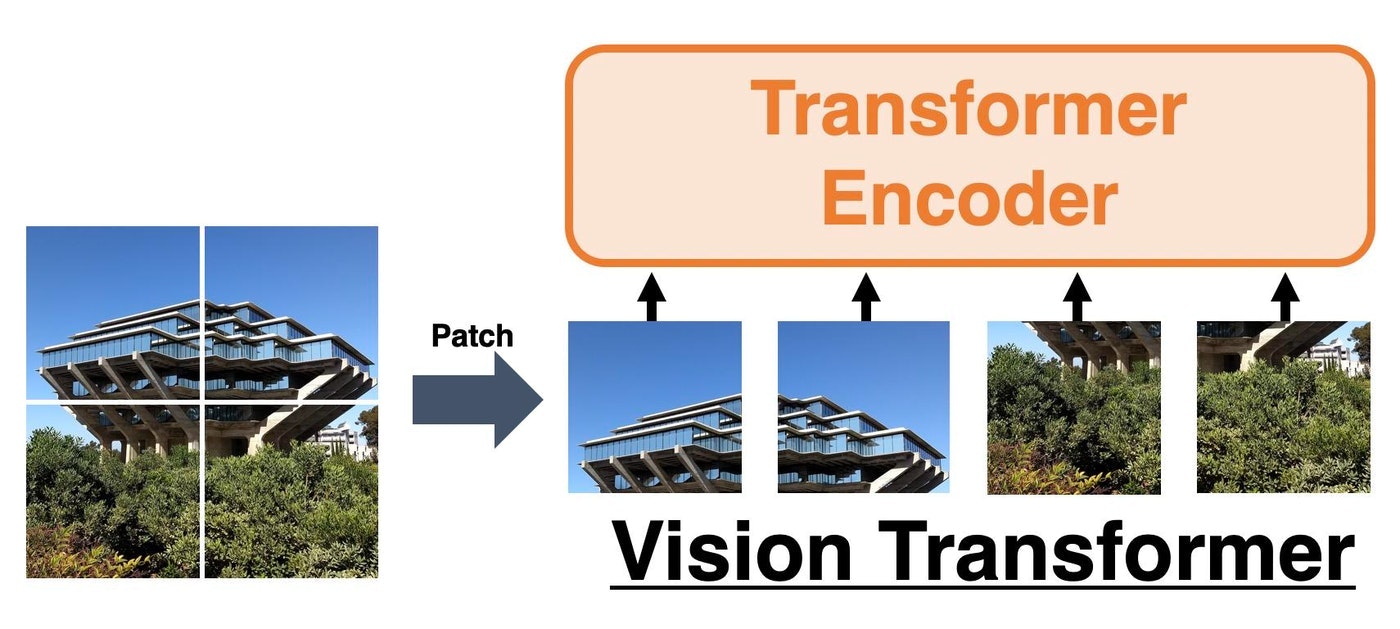
具体的に、入力画像を高さ32、幅32、チャネル数3(i.e. RGB)の画像$\mathbf{X}\in\mathbb{R}^{32\times 32\times 3}$とします。これをグリッド状に$2\times2$つまり$4$個のパッチに分けます。こうすると、1つのパッチの大きさは$16\times 16$となることがわかります。(単に$32\div2=16$なので。)
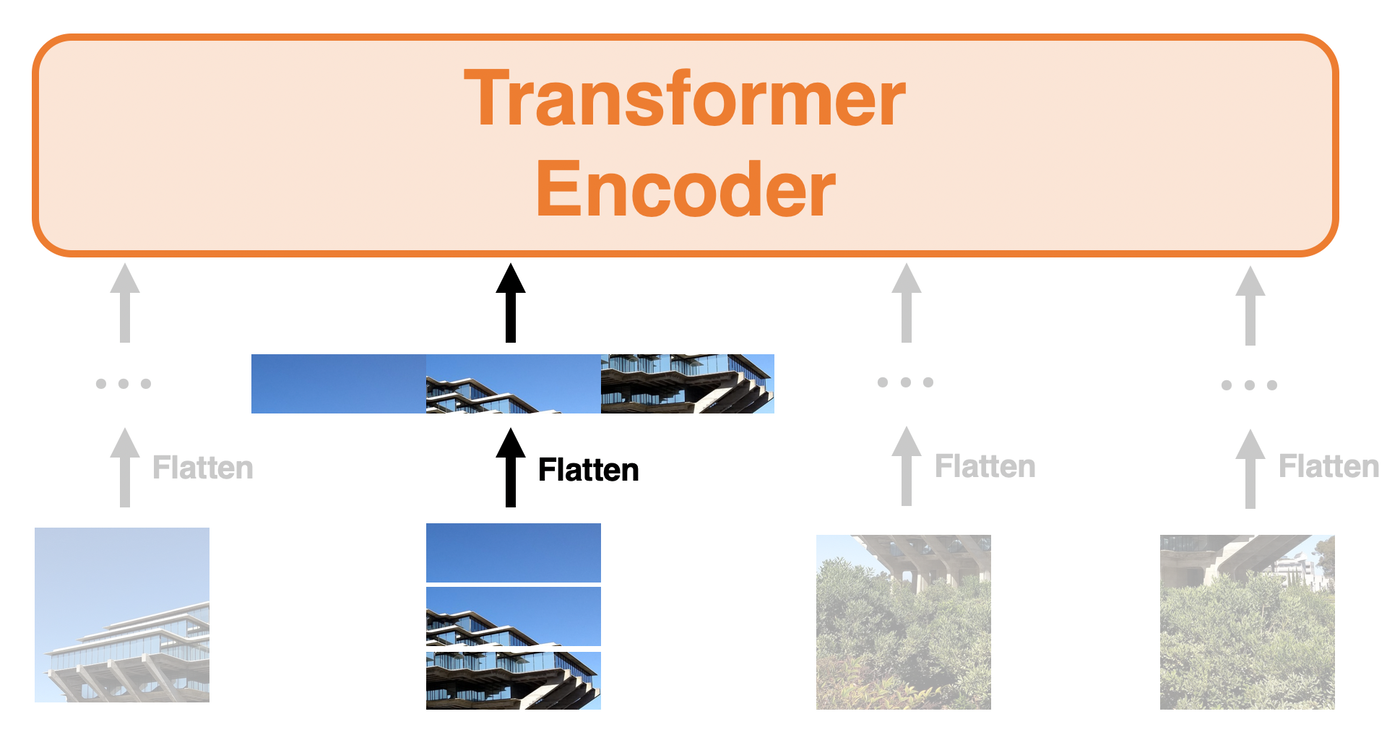
続いて、この$16\times 16$のパッチを一行のベクトルにflattenします。チャネル方向の長さが$3$であることを考慮すると、1つのパッチあたり、長さ$16\cdot16\cdot3=768$のベクトルが誕生します。上図ではわかりやすさのためチャネルなどは考えずにとりあえずflattenしたイメージを示しています。パッチは4つあるので、$\mathbb{R}^{32\times 32\times 3}$だった入力画像は$\mathbb{R}^{4\times768}$というふうに、まるで4個の単語(長さ768のベクトル)が連なったような形になります。ここまで来ればあとは通常のTransformerと同様、線形変換で特定の次元に埋め込み、パッチの位置に応じて位置エンコーディングを足せばEmbeded Tokensの完成です。あとはEmbeded Tokensを本節一番上の図にあるLN、MSA、全結合層たちに入力するだけです。Transformerエンコーダのさらに詳しい説明は拙著のViT解説記事にて載せておりますので、そちらをご参照ください。
1.2 生成器Gのアーキテクチャ
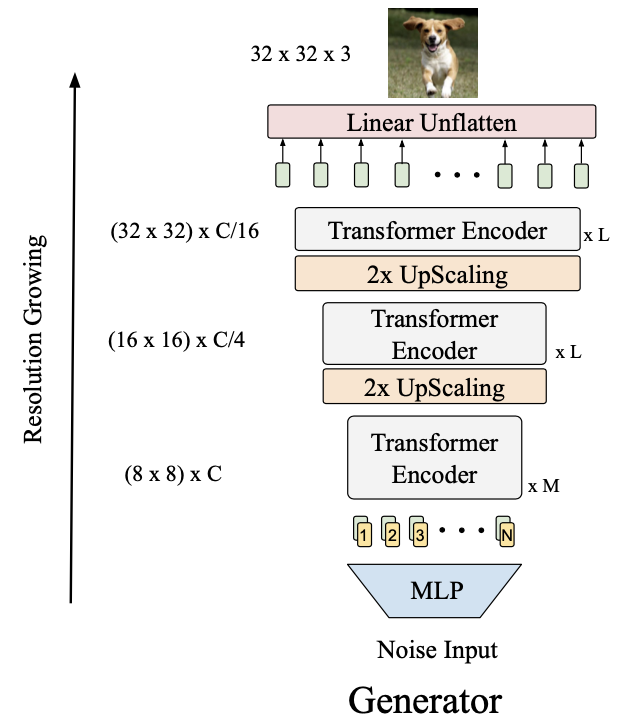
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
通常のGANのようにノイズを入力して、各ステージでアップスケールすることで目的の大きさ(上図では$32\times 32$)の画像を生成します。
1.2.1 ノイズからTransformer Encoderまで
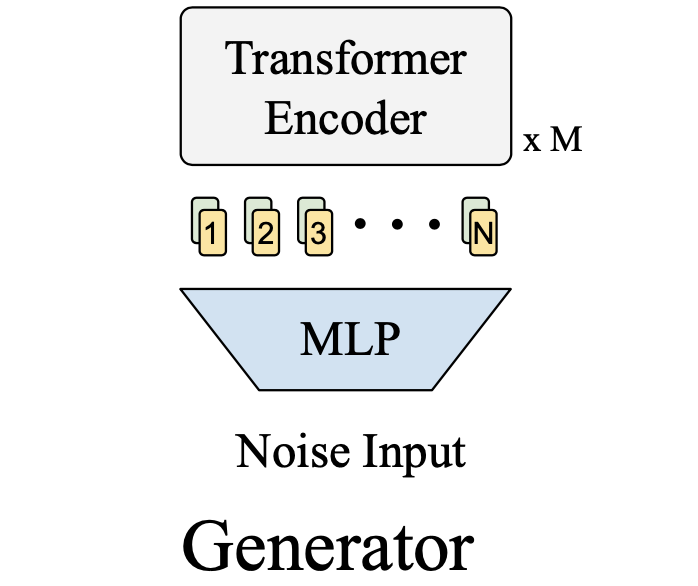
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
TransGANのステージ数は3つで各ステージの間で2倍の大きさにアップスケールが行われます。生成したい画像が$32\times 32$なら、ノイズはMLPによって長さ$\mathbb{R}^{64C}$のベクトルに埋め込まれます。ここで$C$は埋め込み次元であり、$\mathbb{R}^{64\times C}$にreshapeすると64個の長さ$C$のベクトルと見なすことができます。各ベクトルに位置エンコーディングを足すことでステージ1のTransformer Encoderへの入力が完成します。あとは各ステージが有する複数のTransformer Encoderたちに通すだけです。ただ、Encoderに通すだけでは大きさが変わりません。この大きさを変えるため、UpScaling層が存在します。
1.2.2 UpScaling層
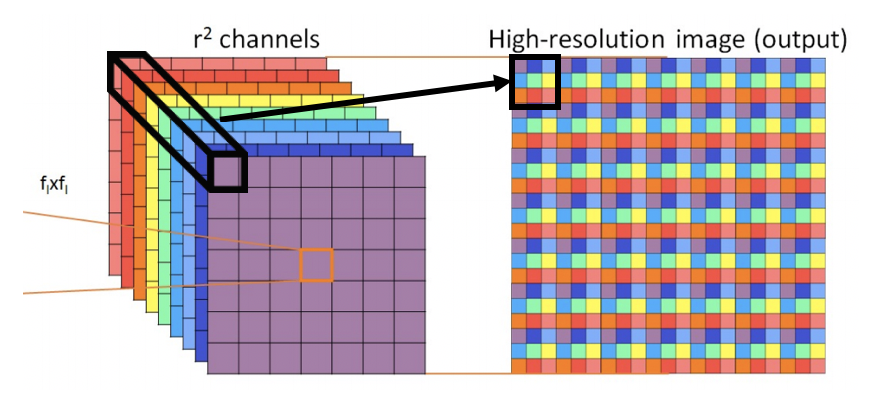
UpScaling層ではまず各ベクトルを2次元へとreshapeします。例えばステージ1の出力の形状は$64\times C$なので、$8\times8\times C$にreshapeします。
そうしたら、PixelShuffleというものを用いてアップスケールします。PixelShuffleは[Shi, W.(CVPR'16)]で超解像タスクのために提案されたアップスケーリング手法で、上図がその例を示しています。アイデアとしては、空間方向を大きくする一方でチャネル方向は少なくするような処理になります。このおかげで、TransGANにおいて空間方向を大きくしてもパラメータ数が爆発するのを抑えることができます。操作は式で見るとわかりやすく、上図に倣って入力の特徴マップを$\mathbf{F}\in\mathbb{R}^{f_l\times f_l\times r^2}$とすると、出力は$\mathbf{F'}\in\mathbb{R}^{f_l\cdot r\times f_l\cdot r\times 1}$となります。空間方向はそれぞれ$r$倍され、それに伴いチャネル方向は$1/r^2$倍になっています。これは上図の黒太線で囲った箇所の色に注目すると、チャネル方向のベクトル$\mathbb{R}^{r^2}$を$\mathbb{R}^{r\times r\times 1}$へと展開しているだけであることがわかります。TransGANではPixelShuffleを用いることで空間方向にそれぞれ2倍となるようにアップスケールしています。ちなみにPyTorchではnn.PixelShuffle(scale_factor=2)で2倍にアップスケールできます。
あとは、Transformer Encoderに入力するためにベクトルへと戻したいので、形状が$16\times16\times C/4$となっているtensorを$256\times C/4$へreshapeしてあげればここでの処理は終わりです。
1.2.3 Gの出力層
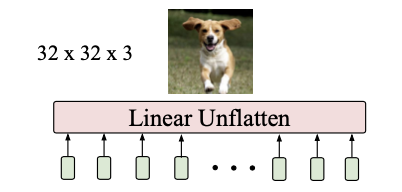
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
ここはただの全結合層です。今回作りたい画像サイズは$32\times32$なので、出力層直前のtensorの形は$1024\times C/16$となっているはずです。($1024=32\cdot32$)作りたい画像はRGB画像なので、チャネルは$3$であって欲しいです。そのため、全結合層は$\mathbf{W}\in\mathbb{R}^{\frac{C}{16}\times3}$を重みとして持ちます。(PyTorchならnn.Linear(C/16,3)やTensorFlowならlayers.Dense(3))。これによって$1024\times3$となっているtensorを$32\times32\times3$にreshapeすれば生成器Gは終わりです。
1.3 識別器Dのアーキテクチャ
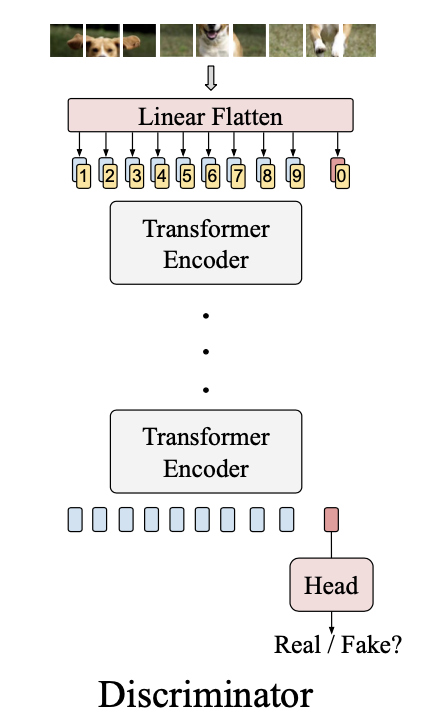
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
DはGよりも簡潔です。多段のTransformerエンコーダに入力していき最後に真偽を判定するだけです。
もう少し詳しく説明すると、まず1.1 Transformerエンコーダで述べたように入力画像からEmbeded Tokens(つまり、入力画像をflattenして線形変換したら位置エンコーディングを足す)を作ります。ただ1つ注意して欲しいのは、上図のLinear Flatten直後に「0」が登場しています。これは [CLS]トークン と呼ばれ、最後の真偽判定ではこの[CLS]トークンのみが使用されます。(BERTと同じですね[拙著解説])実装上では、[CLS]トークンは単なるランダムの初期値から始まる学習可能なパラメータになっています。(PyTorchではnn.Parameter(torch.randn(1,1,C))として持たせます。ここでCはLinear Flattenの出力の埋め込みの次元です。)この[CLS]トークンはLinear Flattenの出力にconcatされます。つまり、入力画像を$8\times8$個のパッチに分けたとすると全部でパッチは$64$個あるので、Linear Flattenの出力は$64\times C$となっています。この$64\times C$に$1\times C$の[CLS]トークンをconcatするので、$65\times C$のtensorが出来上がります。これに位置エンコーディングを加算し、Transformerエンコーダへと入力していきます。このTransGANの識別器はTransformerエンコーダが7つ連なっており、最後の出力の[CLS]トークンだけを全結合層に入力することで真偽を判定します。これでTransGANの全体像を理解できたと思います。続いてはこのTransGANを用いた時の実験結果を見ていきましょう!
2. TransGANの実験結果
TransGANでは大きく以下の2つの実験を行っています。
- TransGANを探る実験
- SoTAとの比較実験
1.では、TransGANの能力を最大限に引き出すための様々なテクニックを探っています。2.では、1.で見つけたテクニックを全て組み込んでCNNベースのSoTAモデルたちとの比較実験を行います。それではTransGANを探る実験から見ていきましょう。
2.1 TransGANを探る実験
ここでは高性能なTransGANを手に入れるために、次の5つの実験を行っています。いずれの実験もCIFAR-10を用いて性能評価を行っています。評価指標にはIS(=Inception Score)およびFID(=Fréchet Inception Distance)を用いています。ISは大きければ良く、FIDは(距離なので)小さければ良いです。
- AutoGANへのTransformerの導入
- データオーギュメンテーション
- 超解像によるCo-training
- 局所的Self-Attention
- スケールアップ
2.1.1 AutoGANへのTransformerの導入
Transformerによる性能への影響を見るために、まずはCNNベースのGANであるAutoGAN[Gong, X.(ICCV'19)]にTransformerを組み込んでいきます。AutoGANとは名前からも察しがつくように、Neural Architecture Search(NAS)を用いて作られたGANで高い性能を示しています。このAutoGANに対してTransformerを組み込む場合、次の4つのパターンが考えられます。
| Generator | Discriminator | |
|---|---|---|
| ① | AutoGAN | AutoGAN |
| ② | Transformer | AutoGAN |
| ③ | AutoGAN | Transformer |
| ④ | Transformer | Transformer |
①と④はそれぞれただのAutoGANとTransGANになります。これらの4つの組み合わせに対してCIFAR-10で性能評価した結果が以下の表になります。
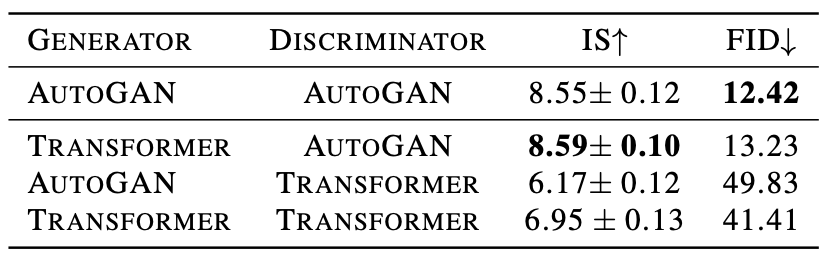
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
この結果からわかることは次の2つです。
- Transformerベースの生成器は強い
- 一方で、Transformerベースの識別器は弱い
生成器をCNNから完全に解放させることに成功しましたが、識別器もCNNから解放させるべく次に続く4つの実験では学習にさらなる工夫を加えます。論文中では、次のように述べられておりなんとも厨二魂がくすぐられます。「俺たちの冒険はこれからも続く!」的な感じですね。それではその冒険を見ていきましょう。
For our much more ambitious goal of making GAN completely free of convolutions, our journey has to continue.
2.1.2 データオーギュメンテーション
まず1つ目の工夫として、データオーギュメンテーションを用いていきます。これは[Zhao, S.(NeurIPS'20)]や[Zhao, Z.(2020)]などでGANに対してもDAが有効であることが分かっているからですね(GAN+DAについて詳しく知りたい方はこちらをどうぞ)。結果は下の表のようになります。
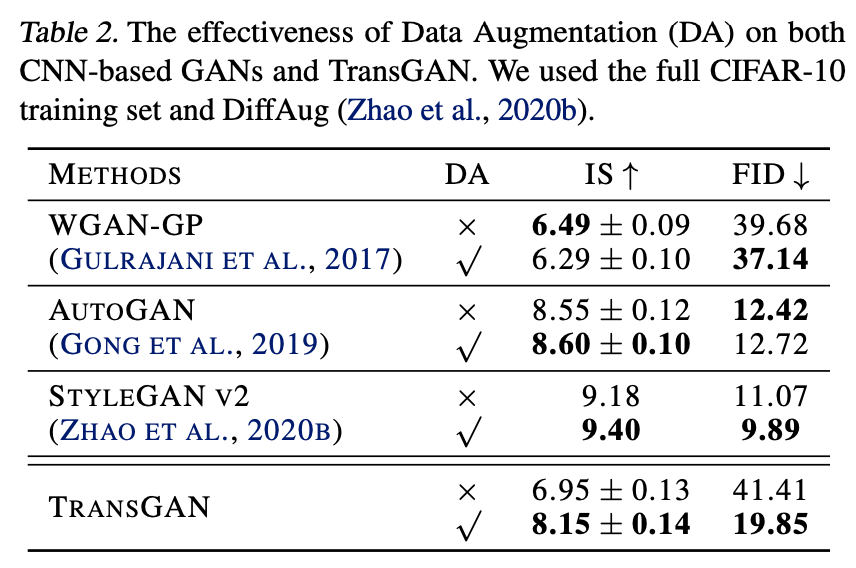
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
比較手法としてWGAN-GP/AutoGAN/StyleGANv2を用いています。CNNベースのGANではDAによる性能向上がわずか(または性能低下)である一方で、TransGANにはDAがとてつもなく有効であることがわかります。論文中ではTransGANにDAが有効な理由として、Transformerがデータハングリーであるためだとしています。実際にTransGANのもととなっているVision TransformerはJFT-300M(3億枚の画像!ImageNetは130万枚)というGoogleの巨大な内部データセットを用いて事前学習することで、CNNベースのモデルを超える画像分類精度を叩き出しています。
2.1.3 超解像によるCo-training
続いて2つ目の工夫として、Co-trainingを組み込みます。これは、BERTが自己教師あり学習によって性能向上が得られていることに由来します。ここではCo-trainingを行うためのタスクとして超解像タスクを採用しています。超解像タスクとは、低解像度の画像を高解像度に変換するタスクです。高解像度と低解像度の画像のペアは、元画像を高解像度、元画像を小さいサイズにリサイズしたものを低解像とすることで容易に得られます。超解像タスクは下の図のようにして組み込んでいます。
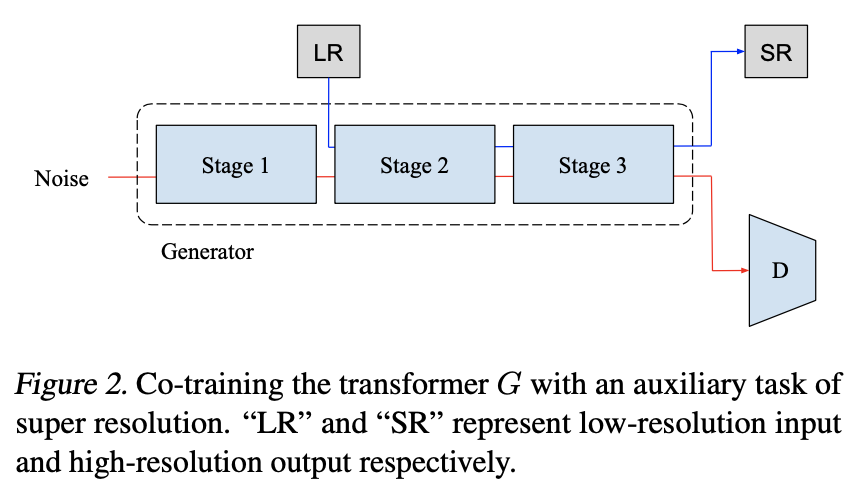
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
この時、低解像(LR)に対して超解像(SR)が予測となりますが、損失は単にSRと正解の高解像度の間で平均二乗誤差(MSE)を取るだけです。超解像タスクによる損失を$L_{\text{SR}}$とすると、生成器の損失に$\lambda\cdot L_{\text{SR}}$を足すことでMulti-Task Co-Training(MT-CT)を実現しています。ちなみに$\lambda =50$としています。MT-CTによる結果は次項の局所的Self-Attentionの結果とともに表しますので、3つ目の工夫を見ていきましょう。
2.1.4 局所的Self-Attention
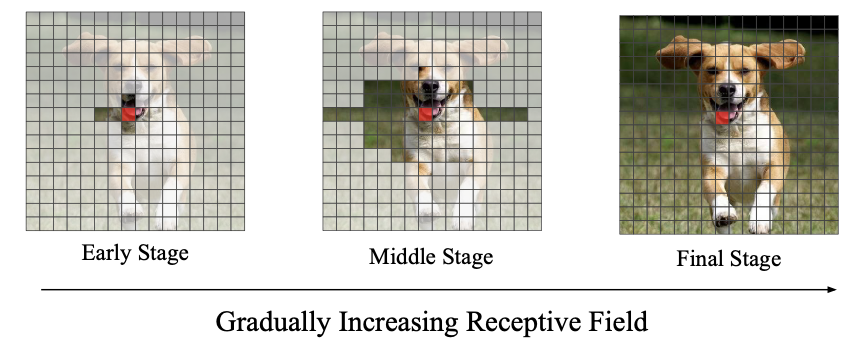
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
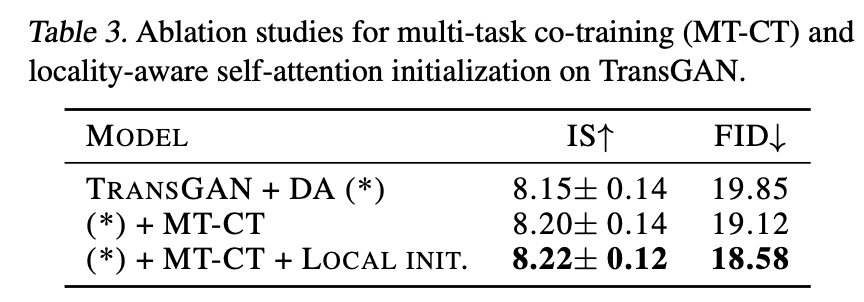
そして3つ目の工夫として、Self-Attentionへの局所的初期値の設定(Locality-Aware Initialization for Self-Attention)を用います。CNNではあるピクセルの周辺ピクセルの情報しか得られなかったのに対して、Self-Attentionでは画像全体から一気に情報を得ることができました。これがTransformerによるCNNの駆逐を可能としています。しかし、CNNが持つ局所性というのは全く捨てたもんではありません。実際にViTがCNNと同じような特徴量を学ぶことが報告されています。そのため、CNNが有する局所性をSelf-Attentionに直接的に組み込んだものがここでの工夫となります。実際には、学習初期ではSelf-Attentionが見れる範囲を狭め、徐々に広げていくことでSelf-Attentionに局所性を学ぶように強制しています。上図がその例になります。赤いピクセルが注目ピクセルで、白く濁っていないピクセルからのみ情報を収集するようになっています。学習が進んでいくと左から右へSelf-Attentionが適用できる範囲が広がっていきます。先ほどのMT-CTとこのLocal Init.を用いた場合の結果は下表のようになります。1行目がGANを用いた場合の結果です。2行目を見ると、MT-CT(超解像タスク)を用いることで性能が上がっていることがわかります。また3行目から、学習初期ではSelf-Attentionの学習範囲を狭めた(Local Init.)ほうが画像生成には良いことがわかります。
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
2.1.5 スケールアップ
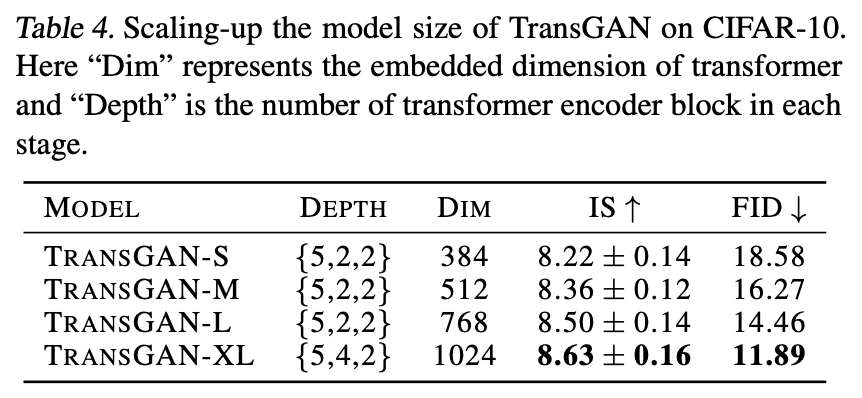
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
最後に4つ目の工夫として、生成器をスケールアップさせます。これまでの実験で用いていたモデルをTransGAN-Sとすると、生成器の埋め込みの次元を増やすことで-M/-Lとスケールアップさせていきます。最後には生成器のブロックの数も増やしTransGAN-XLとしています。上の表を見ても生成器をスケールアップさせることで見事に性能が向上していることがわかります。ここで識別器のスケールアップによるゲインはあまり無かったため、識別器は大きさを固定したようです。これにより実戦で十分戦えるTransGANが完成しました。続いての実験ではTransGAN-XLを用いてCNNベースのSoTAモデルたちと比較実験を行います。
2.2 SoTAとの比較実験
ついにSoTAモデルたちとの比較を行います。データセットには、CIFAR-10、STL-10、CelebAを用います。それぞれ生成する画像サイズは$32\times 32$、$48\times 48$、$64\times 64$です。オプティマイザーにAdamを用い、学習率は$1e-4$としています。バッチサイズは生成器は128、識別器は64となっています。CelebAに対してはバッチサイズを生成器で32、識別器で16としています。
2.2.1 CIFAR-10における実験結果
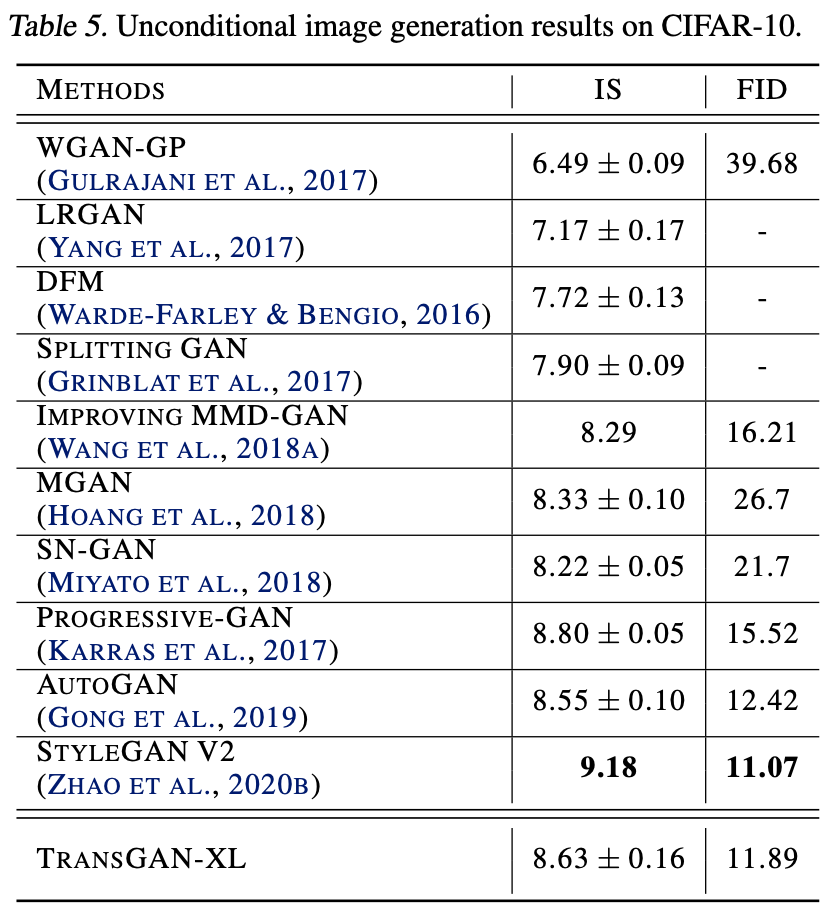
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
CIFAR-10における実験結果は上表のようになっています。TransGAN-XLがSNGANやAutoGANなどに勝っていることがわかります。一方でProgressive-GAN(のIS)およびStyleGANv2には負けてしまっていますが、これらが様々なエンジニアリングの元に出来上がったモデルであることを考慮すると、TransGAN-XLが十分に健闘できていると言えます。
2.2.2 STL-10における実験結果
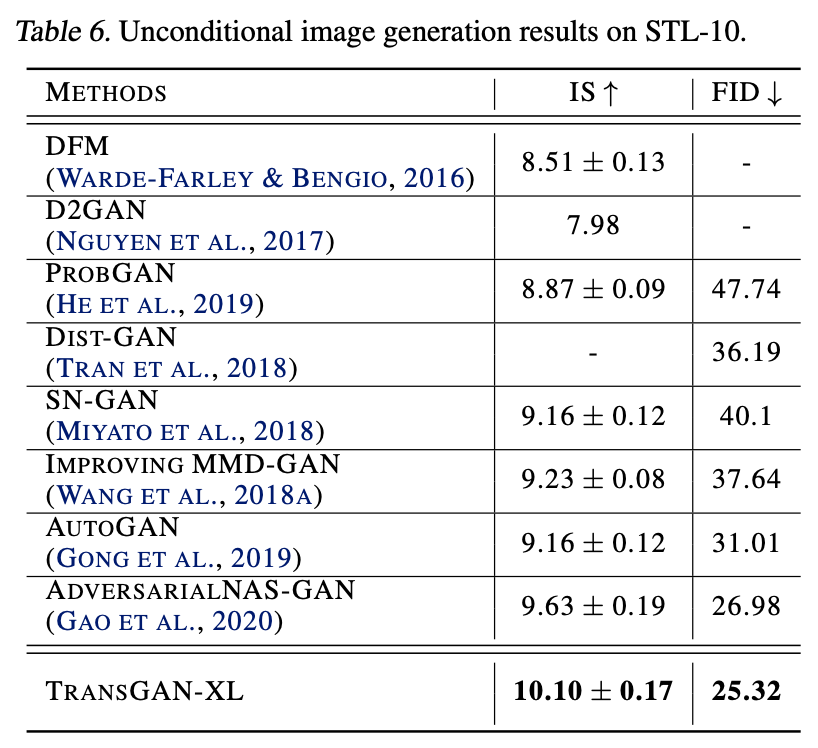
画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
続いてSTL-10における実験結果を見てみます。STL-10では、見事CNNベースのGANを打ち破りSoTAを達成しています。(CIFAR-10で敗れたProgressive-GANとStyleGANv2が居ませんが。。。)STL-10の性能が良かった理由として、論文中ではSTL-10のデータ数が(ラベルなしデータも用いているため)CIFAR-10の2倍あり、Transformerのデータハングリー性にマッチしているためとしています。
2.2.3 CelebAにおける実験結果

画像: "TransGAN: Two Transformers Can Make One Strong GAN", Jiang, Y., Chang, S., Wang, Z. (2021)
最後にさらに$64\times64$のCelebAにおける実験結果を示しています。実際のところ $64\times64$ではTransGANはあまりうまくいっていません。TTURを用いたDCGAN(FID:12.50)にはTransGAN(FID:12.23)がわずかに勝ったようですが、他のCNNベースのGANには負けてしまっているようです。高解像度(といっても$64\times64$ですが。)の画像に対しては、学習方法などをチューニングすることでTransGANの性能を上げられるとしています。上図がCIFAR-10/STL-10/CelebAそれぞれに対する画像生成の結果になっています。
3. まとめと所感
ついに、画像生成を行うGANでもTransformerだけを用いたものが登場しました。しかもSTL-10でSoTAを達成しています。ついこの前ViTが登場したと思えばもうGANまでTransformerがやってきました。アーキテクチャもほぼViTであることを考えると、ViTの影響力の大きさを改めて感じます。このTransGANを皮切りにCNNでいうStyleGANのような我々を驚かすGANが登場してくれるのでしょうか。Transformerによるコンピュータビジョンへの進撃はこれからも目が離せません!
Twitterで人工知能のことや他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ: