オミータです。ツイッターで人工知能のことや他媒体で書いている記事など を紹介していますので、人工知能のことをもっと知りたい方などは気軽に@omiita_atiimoをフォローしてください!
GANにもオーギュメンテーションは超有効!DAだけでSoTA達成した最新論文を解説!
画像生成といえば、やはりGANだろう。2014年に[Goodfellow, I.(NIPS'14)]によって提案されてからGANのモデルは驚異的なスピードで発展を続けてきた。被引用数も21,377(08/2020現在)と化け物論文になっている。その発展によってどれだけ性能向上しているかは下の画像で一目瞭然。2018年のものはもはや人間にすら本物かどうか見分けることが難しくなっている。

Credit: Ian Goodfellow
一方で、画像分類の性能向上にはモデルもさることながら、データオーギュメンテーション(=DA, Data Augmentation)によるものも大きい。データオーギュメンテーション(以下、DA)とは、オリジナルの画像に特定の処理(水平反転や部分クロップなど)を施し新たなデータとして用いる手法のことで、日本語ではデータ水増しとも呼ばれる。(DAの様々な手法については[拙著解説]でまとめましたのでそちらもご覧ください。)
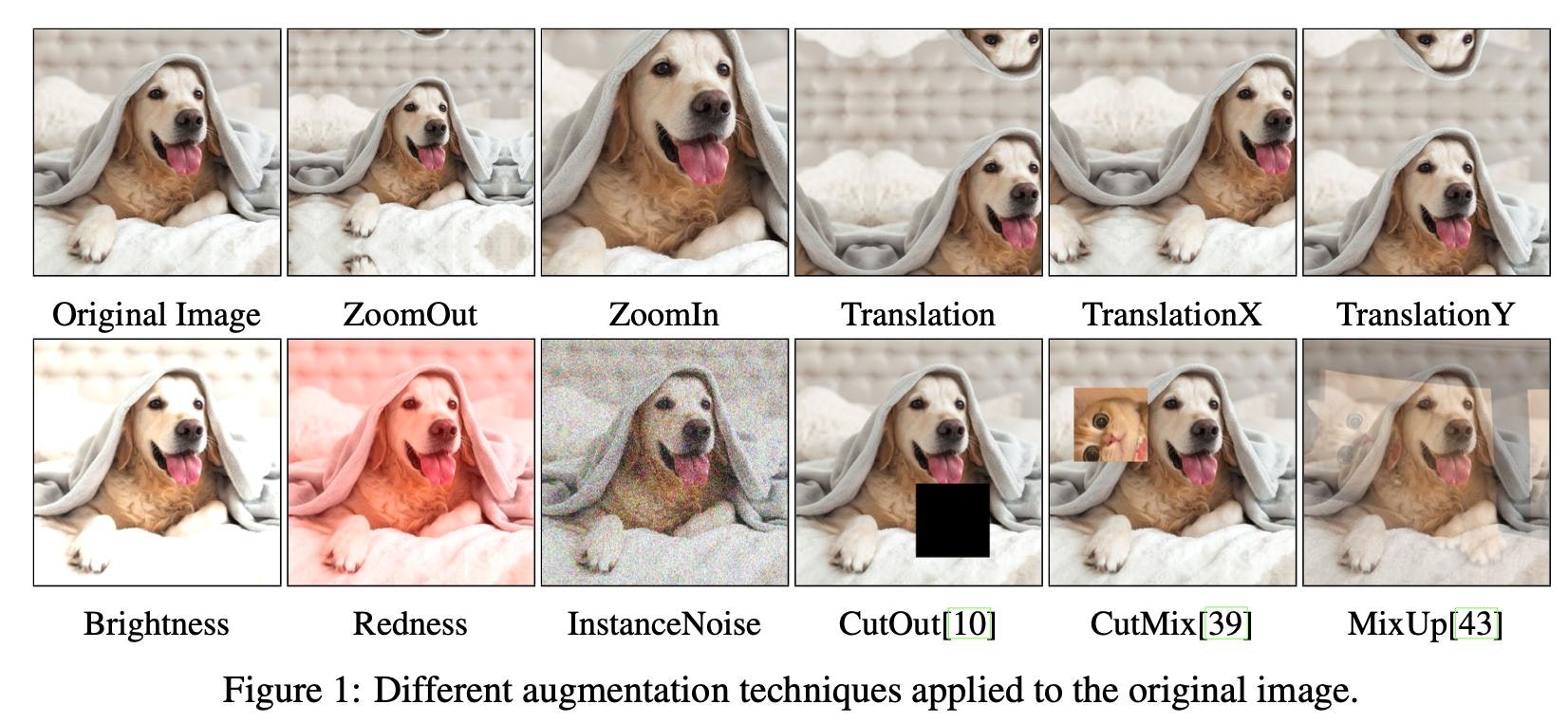
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
Googleによって出された今回の論文のテーマは、画像分類で広く使われているDAをGANにも使ってみるというもの。そしてなんと、DAを用いるだけでSoTA並みの性能を示したというから驚きである。どんなDAをどう用いたのか。本論文を通して早速見ていこう。(ちなみに、第一筆者であるZhao氏はGoogle Brainでのインターン中にこの論文を書いたと言うからさらに驚き。)
読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!Twitter@omiita_attimoもどうぞ
流れ:
- 忙しい方へ
- 論文解説
- まとめと所感
- 用語と補足
- 参考
原論文: "Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
0. 忙しい方へ
- データオーギュメンテーション(以下、DA)をGANに用いて色々と実験したよ
- ちなみに今まではGANに対してスタンダードDA(Crop+Flip)だけがほぼ使われてたよ
- 空間的なDA(TranslationやZoomoutなど)が大きく性能向上に寄与したよ
- DAをリアル画像およびフェイク画像どちらにも適用すると性能が著しく向上するよ
- GANの性能向上は、DAがリアル画像分布とフェイク画像分布の重なりを増やしてくれているからだよ
- DAを用いた手法であるConsistency正則化とContrastive損失も用いることでCIFAR-10生成でSoTAを達成したよ
- 複数のDAを用いることでさらなる性能向上が期待できるよ
1. 論文「Image Augmentations for GAN Training」解説
1.0 要約
データオーギュメンテーション(以下、DA)は画像分類では広く使われ精度向上に大きく貢献してきたが、GANの分野ではあまり研究されてこなかった。
そのため、本論文では既存のDA手法を用いたGANの学習を様々な環境下で行い、その結果をまとめた。その結果、
- DAをリアル画像とフェイク画像の両方に適用することで、SoTA並みの結果を得られた。
- DAを用いた手法であるContrastive学習やConsistensy正則化なども用いるとさらなる性能向上が見られた。
- CIFAR-10の生成でSoTAを達成
1.1 導入
画像分類や物体検出、セマンティックセグメンテーションなどでは広く使われているDAだが、GANのような画像生成にはDAの効果はあまりわかっていないのが現実だ。上記の画像認識タスクと比べると、画像生成にとって最適なDAを見つけてくるのは極めて難しい。GANにDAを適用した例はすでにあるものの、そのほとんどがDiscriminatorに入る直前のリアル画像にのみDAを適用するというもの。しかし、この方法ではDiscriminatorがDA適用後の画像も実際の画像の分布に含まれていると勘違いしてしまうため、あまり強いDAを適用させることができない。結果として、GANのSoTAモデルたちは「ランダムクロップ+水平反転」といういわゆるスタンダードDAを使うに留まってしまっている。
一方で近年、教師なし学習や自己教師あり学習の分野ではDAの重要性が高まっている。そして、GANにおいてもConsistency正則化というものが良い結果を残した。Consistency正則化とは[Zhang, H.(ICLR'20)]で提案されたもので、DAをリアル画像に適用してもDiscriminatorの出力は変化しないようにするというもの。さらに[Zhao, Z.(2020)]ではこれを改良し、リアル画像のみならずフェイク画像にもDAを適用させたConsistency正則化(=BCR)が提案されている。しかし、結局GANに対してどうDAを適用させるかは様々な疑問が残る。例えば、以下のようなもの。
- どのDAがGANにとっては最も効果的なのか。
- フェイク画像にもDAを適用すべきなのか。
- どの画像に対してもConsistencyを学ぶようにすべきか。
- DAを他の損失関数とともに用いることはできるのか。
本論文では、実験を通してこれらの疑問に答えていく。
まずリアル画像にだけDAを適用した場合で実験を行い、その後リアル画像およびフェイク画像両方にDAを適用した場合で実験を行う。このとき、DAのかけ具合(e.g.ノイズの強さ)は様々な値に変化させて実験を行った。本論文のコントリビューションは以下の4つ。
- GANにおける各DAの効果を評価
- リアル/フェイク画像両方にDAを適用した場合に著しく性能向上
- DAに加えConsistency正則化も用いることでさらなる性能向上
- Consistency損失 & Contrastive損失を用いることでSoTA
1.2 オーギュメンテーション手法と実験方法
ここでは本実験について説明する。
1.2.1 表記方法
| 記号 | 意味 |
|---|---|
| $\mathcal{T}$ | DA手法の集合 |
| $t$ | $t\sim\mathcal{T}$で、各DA手法 |
| $\mathcal{I}_0$ | サイズ$(H, W)$のオリジナル画像 |
| $t(\mathcal{I}_0)$ | DA適用後の画像 |
| $\lambda_{\mathrm{aug}}$ | DAのかかり具合 |
| $\mathcal{U(\cdot,\cdot)}$ | 一様分布 |
| $\mathcal{N(\cdot,\cdot)}$ | ガウス分布 |
| $\mathcal{B(\cdot,\cdot)}$ | ベータ分布 |
1.2.2 画像DA
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
今回用いた手法は上図に示されているとおりだが、説明が必要なものだけ説明する。それ以外は名前の通り。
| 手法 | 概要 |
|---|---|
| Translation | 平行移動。TranslatioX/YはそれぞれX/Y方向のみ。 |
| Redness | RGBのR(赤)に定数を加減算。Blueness(青)/Greenness(緑)も存在。 |
| InstanceNoise | ガウスノイズを加算。 |
| CutOut | 画像の一部をマスク。 |
| Mixup | 2枚の画像を凸結合。ラベルも同じ比率で凸結合。 |
| CutMix | Cutout+Mixup。ラベルは2枚の画像の面積比を比率とした凸結合。 |
また、論文中ではこれらを空間的なDAと見た目的なDAの2つに大別しており、それぞれの内訳は以下。
- 空間的なDA:
Zoomout / Zoomin / Translation / TranslationX / TranslationY / CutOut / CutMix - 見た目的なDA:
Brightness / Redness / Greenness / Blueness / MixUp
1.2.3 データセットおよび評価方法
全ての実験でデータセットにはCIFAR-10を用いた。
| データセット | #訓練データ | #テストデータ | #クラス |
|---|---|---|---|
| CIFAR-10 | 50,000 | 10,000 | 10 |
評価方法にはFID(=Fréchet Inception Distance)を用いた。FIDスコアは低い方が良い。ただし、FIDスコアが良い(=低い)からと言って人間的に必ずしもクオリティが高いというわけではないが、GANの性能評価に広く用いられているためFIDを用いた。
1.2.4. GANアーキテクチャおよびハイパーパラメータ
GANのアーキテクチャには、以下の2つ。
- SNDCGAN[Miyato, T.(ICLR'18)], [Kurach, K.(ICML'19)] (条件なし画像生成)
- BigGAN[Brock, A.(ICLR'19)] (条件あり画像生成)
ハイパーパラメータは以下。
| モデル | バッチサイズ | 学習ステップ数 | 損失関数 |
|---|---|---|---|
| SNDCGAN | 64 | 200k | ヒンジ損失 |
| BigGAN | 256 | 100k | ヒンジ損失 |
1.3 DAによるGANへの影響
リアル画像にのみDAを適用した場合の実験をまず行う。
その次にリアル/フェイク画像どちらにもDAを適用した場合の結果を示す。
1.3.1 リアル画像にのみDAを適用した場合の性能劣化
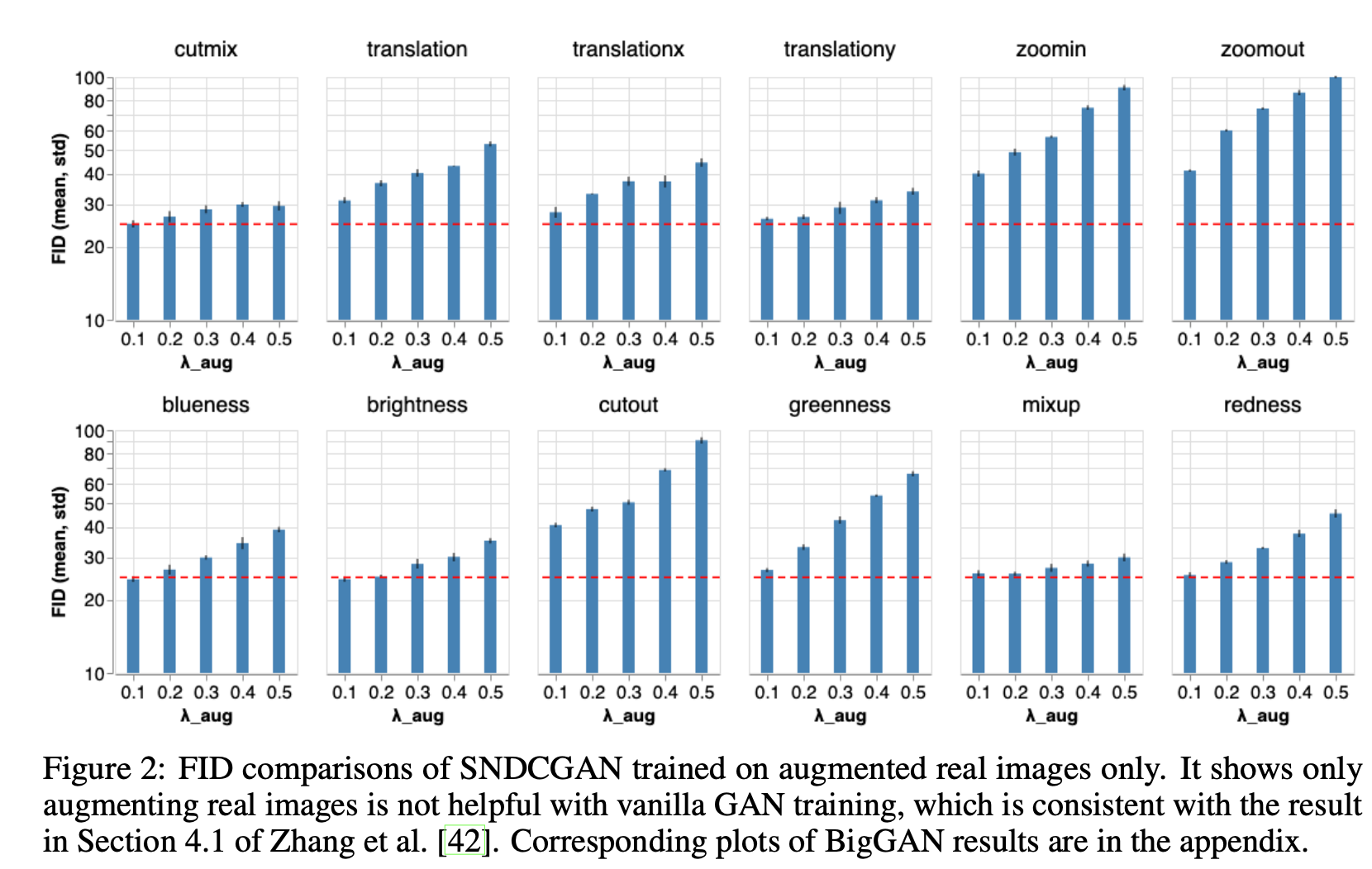
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
まず、リアル画像にのみDAを適用する。モデルはSNDCGAN。この手法は現在広く使われており、GANを学習するときのデファクトになってきている。しかし、今回の実験でわかったことはこのデファクトな方法(=リアル画像にのみDAを適用)がむしろ性能劣化を引き起こしているという真逆の結果。上図がまさにその結果で、各DA手法におけるDAのかかり具合(=$\lambda_\mathrm{aug}$)とそのFIDを示している。赤破線はDAをかけていない場合のFIDを示しているが、軒並みFIDが上昇してしまい性能劣化を及ぼしていることがわかる。
この理由としては、DiscriminatorがDA部分も実際の画像の大事な特徴だと勘違いしてしまうためであり、これは下図を見てもGANがDA部分も真似しようとしてしまっていることがわかる。下図はDAとしてBluenessを適用した場合の生成画像であり、青みがかっている画像が所々出てきてしまっている。

"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
1.3.2 リアル/フェイク画像両方にDAを適用した場合の性能向上
続いて、リアル/フェイク画像いずれにもDAを適用してみる。これにより、Discriminatorが「DAされてるからリアル画像だ!」というセコ技を使うことがなくなる。ここではモデルにSNDCGANとBigGANを用いた。データセットは変わらずCIFAR-10。
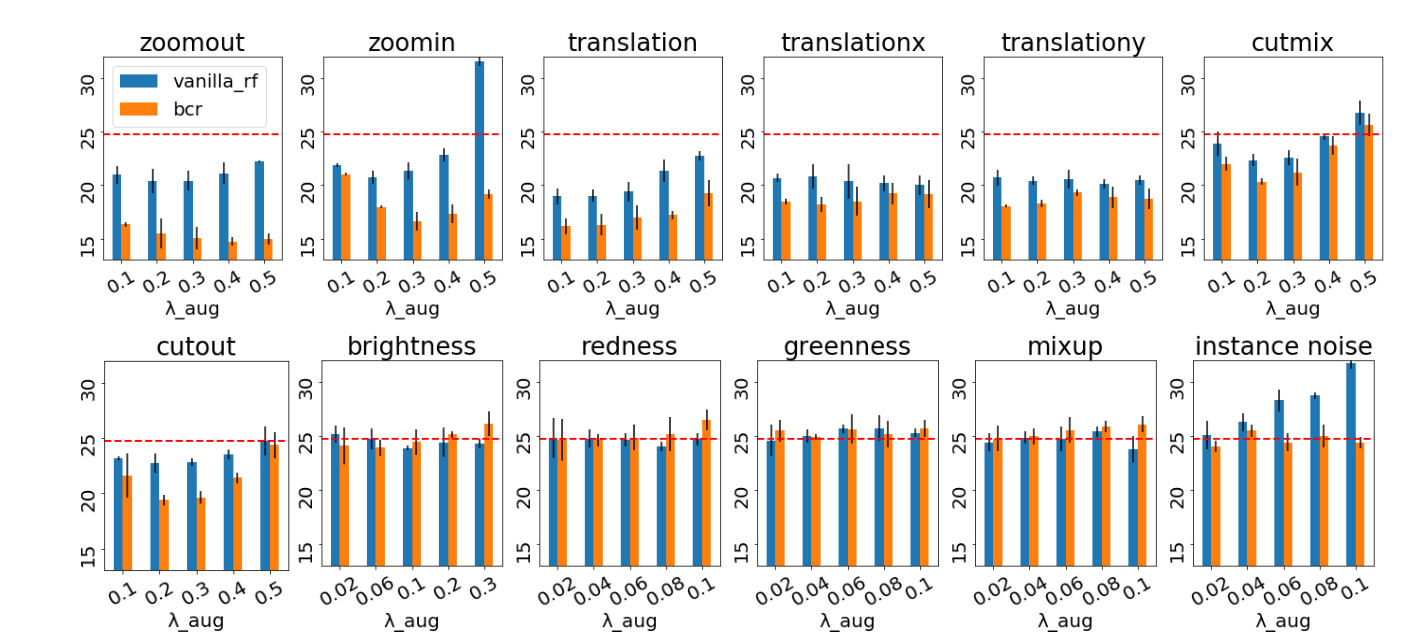
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
まず、SNDCGANの結果は上図。先ほどの1.3.1と同じく各DA手法に対するFIDを示している。赤破線はDAを使わなかった場合のSNDCGANの結果(FID=24.73)。青色の棒グラフがその結果で、オレンジ色の方は1.4で説明する。これを見るとわかるが、先ほどとは異なりDAをリアル/フェイク画像いずれにも適用することで性能が著しく向上している(=FIDが小さい) ことがわかる。また、この図から特に、見た目的なDA(=下行のDAたち)よりも空間的なDA(=上行のDAたち)の方がGANには効果的であることがわかる。画像の見た目を大きく変えてしまうようなInstanceNoiseはむしろ性能劣化を起こしてしまっている。
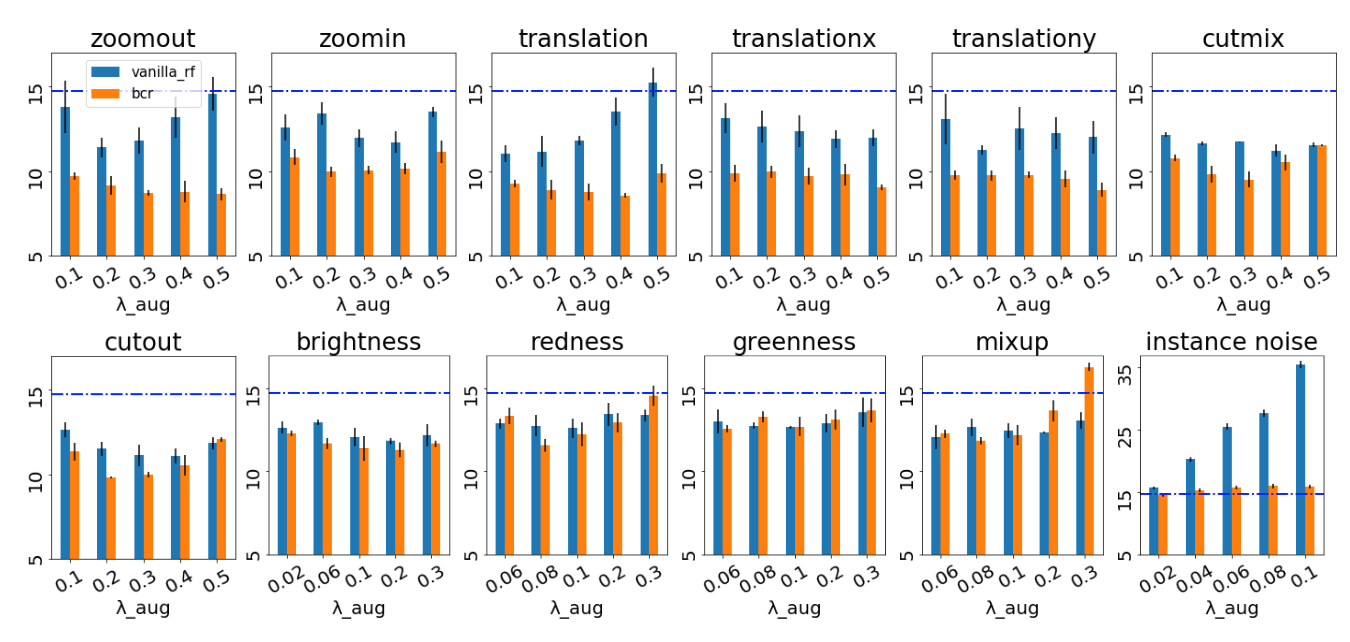
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
続いて、上図はBigGANの結果。ここでは青線がDAを使わなかった場合の結果(FID=14.73)。青色の棒グラフを見ると、BigGANでもSNDCGANと同じような傾向が見られることがわかる。
1.3.3 DAによるリアルとフェイクの分布の重なり増加

"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
ここではなぜDAをリアル画像とフェイク画像に適用することで性能向上が果たせたかを簡単に考えてみる。GANというのは生成(=フェイク)画像分布をリアル画像分布に近づけるようとしているものだが、このリアル画像分布とフェイク画像分布がそもそも全く重なっていないことがGANの学習を困難にさせている一因と考えられている。各DA適用時のリアル画像分布とフェイク画像分布の距離を測ったものが上図。DAを適用すればするほどその距離が縮まっていることがわかる。このことからも、リアル/フェイク画像にDAを適用することでリアル画像分布と生成画像分布の重なりが促進されると言うことができる。
(ただし、DAを強くかければかけるほど距離が縮まっている"translation"は、1.3.2の図を見ると実際はDAが強すぎると逆に性能劣化が引き起こされているので単に距離を近づけたからといって必ずしも精度が上がるわけでもない。)
1.4 Consistency正則化を加えたGANへのDAによる影響
さらなる性能向上のために、DAを用いた正則化手法であるBCR(=Balanced Consistency Regularization)を用いる。BCR[Zhao, Z.(2020)]は、[Zhang, H.(ICLR'20)]で提案されたConsistency正則化を改良させたもの。このConsistency正則化およびBCRについては1.1導入でも簡単に説明したが、DAを適用してもDiscriminatorの出力には一貫性を持たせるようにする正則化のこと。下図が視覚的な説明となっている。左がCR(=Consistency正則化)で右がBCR。リアル画像にのみConsistency正則化を適用していたオリジナル(左)に対して、BCRではフェイク画像にもConsistency正則化を適用しているだけ。
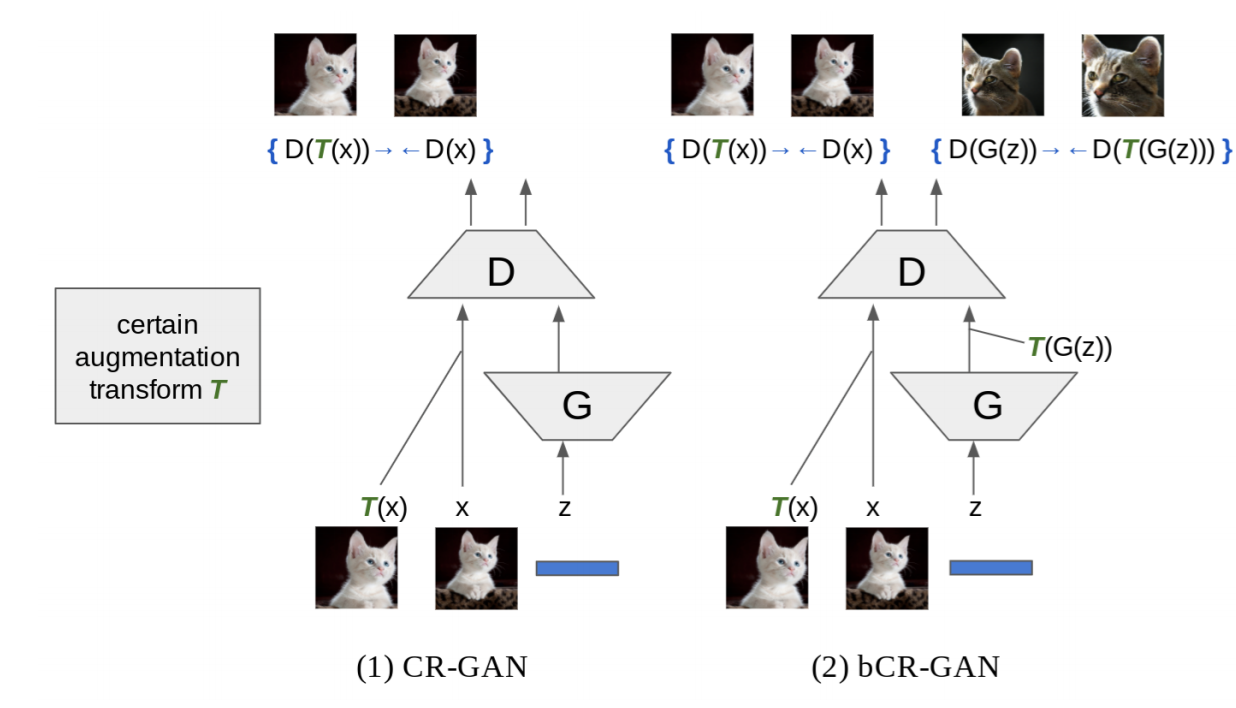
実際に、下記のBCRのアルゴリズムを見てみても差分をとって(3行目)、正則化項としてDiscriminatorの損失関数に加算している(4行目)だけ。このとき、$\lambda_{\mathrm{BCR}}$はハイパーパラメータで本実験では$\lambda_{\mathrm{BCR}}=10$としている。また、$L_D$はヒンジ損失。
- DA手法を1つサンプリング: $t_1\sim\mathcal{T}, t_2\sim\mathcal{T}$
- DAをリアル/フェイク画像に適用: $t_1(\mathcal{I}_ {\mathrm{real}}), t_2(\mathcal{I}_{\mathrm{fake}})$
- $L_{\mathrm{BCR}}\leftarrow ||D( \mathcal{I}_ {\mathrm{real}})-D(t_1(\mathcal{I}_ {\mathrm{real}}))||^2+||D( \mathcal{I}_ {\mathrm{fake}})-D(t_2(\mathcal{I}_ {\mathrm{fake}}))||^2$
- $\theta_D \leftarrow \mathrm{AdamOptimizer}(L_D+\lambda_{\mathrm{BCR}}L_{\mathrm{BCR}})$
実験の結果はすでに1.3.2でも示しているが、ここでも再掲する。
まず、SNDCGANにBCRを用いた場合は以下図(橙色棒グラフ)。縦軸はFIDで低ければ低いほど良い。全体的にBCRはさらに性能向上していることがわかる。
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
続いてBigGANの結果。こちらもBCRが全体的に性能向上していることがわかる。Instance Noiseにおいても性能劣化を防ぐことができている。
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
SNDCGANおよびBigGANどちらも適切なDAを用いることでそのモデルにおけるSoTAのFIDを叩き出している。
| Model | New | DA ($\lambda_\mathrm{aug}$) | Old |
|---|---|---|---|
| SNDCGAN | 14.72 | Zoomout (0.4) | 15.87 |
| BigGAN | 8.65 | Translation (0.4) | 9.21 |
1.5 Contrastive損失を加えたGANへのDAによる影響
DAはContrastive学習においても重要な役割を果たしている。Contrastive学習は自己教師あり学習の分野で大きな成果を出しており、いずれもDAを用いた手法である、「Contrastive学習」と「Consistency正則化」を併用することでさらなる性能向上が望めそうである。Contrastive学習とはContrastive損失(以下、Cntr損失)を用いた学習方法であるが、まずはCntr損失をどうやってGANの学習に組み込むかを説明したのちに、各DA手法によるCntr-GANの性能の違いを分析する。
1.5.1 GAN学習のためのContrastive損失
元々Cntr損失は[Hadsell, R.(2006)]にて提案され、その気持ちは正のペア同士は近づけて、負のペアは遠ざけるというものである。これをGANに当てはめると、異なる画像同士の表現は遠ざけて同じ画像のDA後の画像同士は同じ表現になるようにDiscriminatorを学習させる、ということ。Cntr損失関数は次式。$\mathrm{sim(\cdot, \cdot)}, \tau$はそれぞれCos類似度と温度パラメータ(全体的に温度付きソフトマックス関数に似ていることがわかる)。
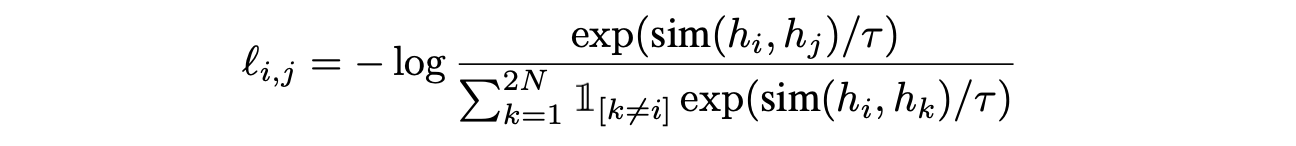
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
ここで$h=f(D_h(t(\mathcal{I})))$であり、これはDAを適用した画像($=t(\mathcal{I})$)のDiscriminatorによる表現ベクトル($=D_h(t(\mathcal{I}))$)をプロジェクションヘッド$f(\cdot)$に通したもの($=f(D_h(t(\mathcal{I})))$)のこと。この式は自己教師あり学習で高精度を叩き出したSimCLR[拙著解説]での損失関数と同じもので、ここで用いるDAもSimCLRで用いたものと同じDA(=RandomResizedCrop+RandomHorizontalFlip+ColorJitter)を適用している。プロジェクションヘッド$f(\cdot)$に関するアーキテクチャは記載されていなかったが、おそらくSimCLRと同じAffine+ReLU(つまり、$f(\cdot)=\mathrm{ReLU}(W\cdot)$)。これをリアル/フェイク画像のどちらに対しても行う。Cntr損失を考慮した最終的な損失および更新は以下のようになる。ここで$\lambda_{\mathrm{Cntr}}$はハイパーパラメータ。
- $L_{\mathrm{Cntr}} \leftarrow \mathrm{CntrLoss(h_{\mathrm{real1}},h_{\mathrm{real2}})} + \mathrm{CntrLoss(h_{\mathrm{fake1}},h_{\mathrm{fake2}})}$
- $\theta_D \leftarrow \mathrm{AdamOptimizer}(L_D+\lambda_{\mathrm{Cntr}}L_{\mathrm{Cntr}})$
そしてBigGANを用いた実験結果は次のようになった。
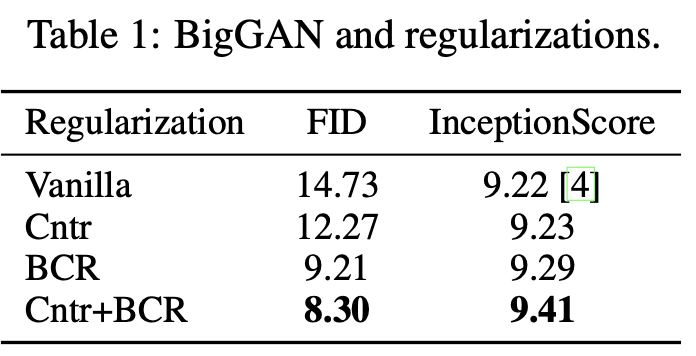
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
この表から言えることは次の2つ。
- Cntr損失による性能向上
- Cntr+BCRでSoTA達成($\lambda_{\mathrm{Cntr}}=0.1, \lambda_{\mathrm{BCR}}=5$)
さらに、Cntr損失において他のDAでも実験を行ったところ、Cntr損失においても空間的なDAの方が見た目的なDAよりも良い性能を示した。
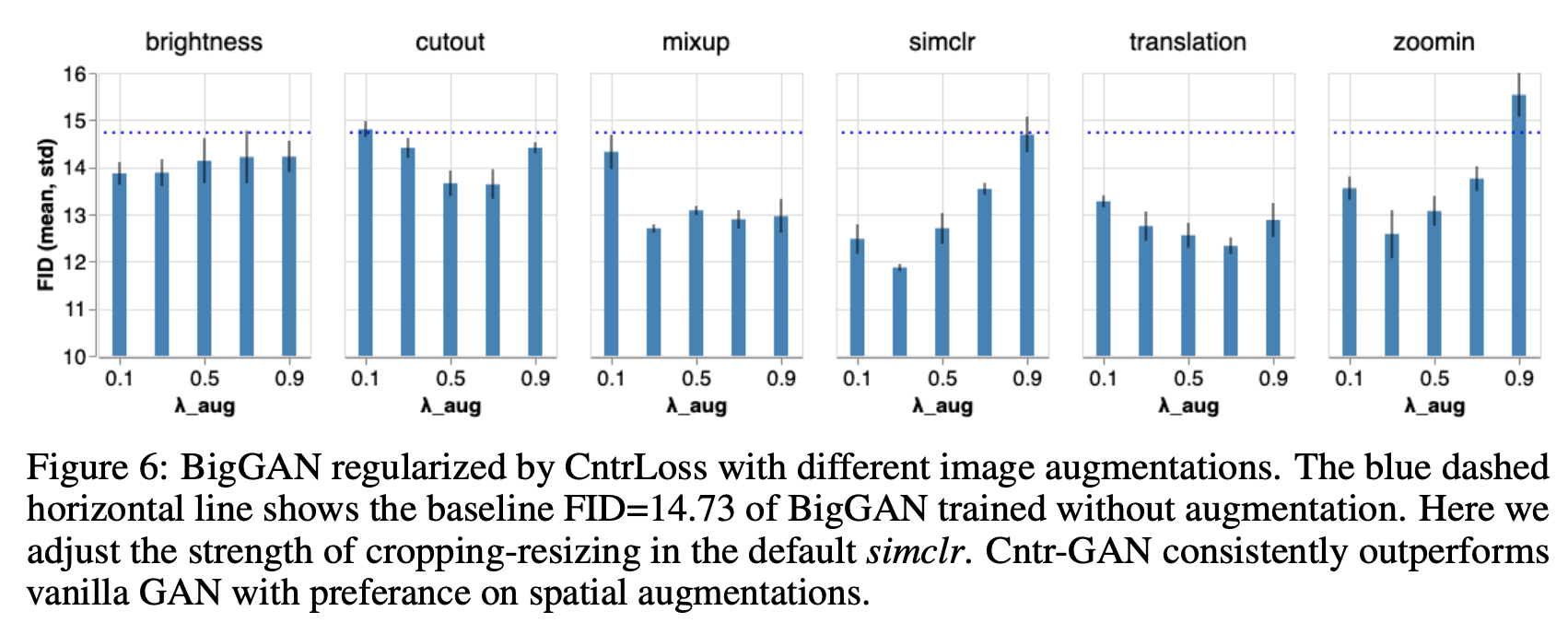
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
1.6 考察
1.6.1 DAによる画像生成への影響
ここでは実際に生成された画像の一部を見てみる。リアル画像にのみDAを加えるとそのDAが生成(=フェイク)画像にも出現してしまうことはすでに述べた通りで、リアル/フェイク画像の両方にDAをかけるとその影響を抑えることができる。そして、Cntr損失やConsistency正則化を用いることで生成画像の質が向上することも下の図(Cutoutの例)から視覚的に確認できる。

"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
1.6.2 DAのかかり具合を徐々に減少
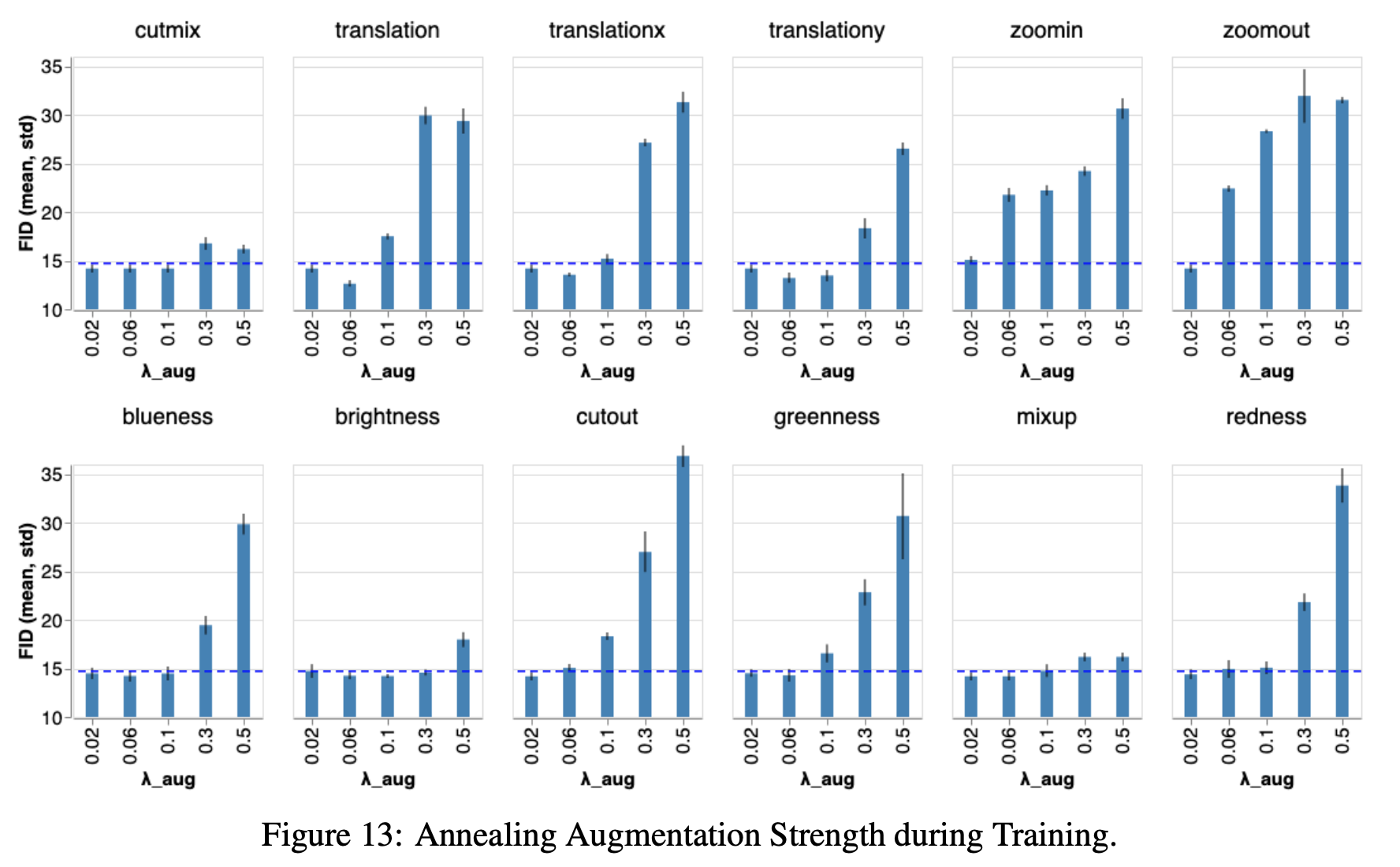
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
上図から分かるように、DAのかかり具合を徐々に減少させるアニーリングは効果がない。(DAのかかり具合は一定値の方が良い。)
1.6.3 複数DAによる影響
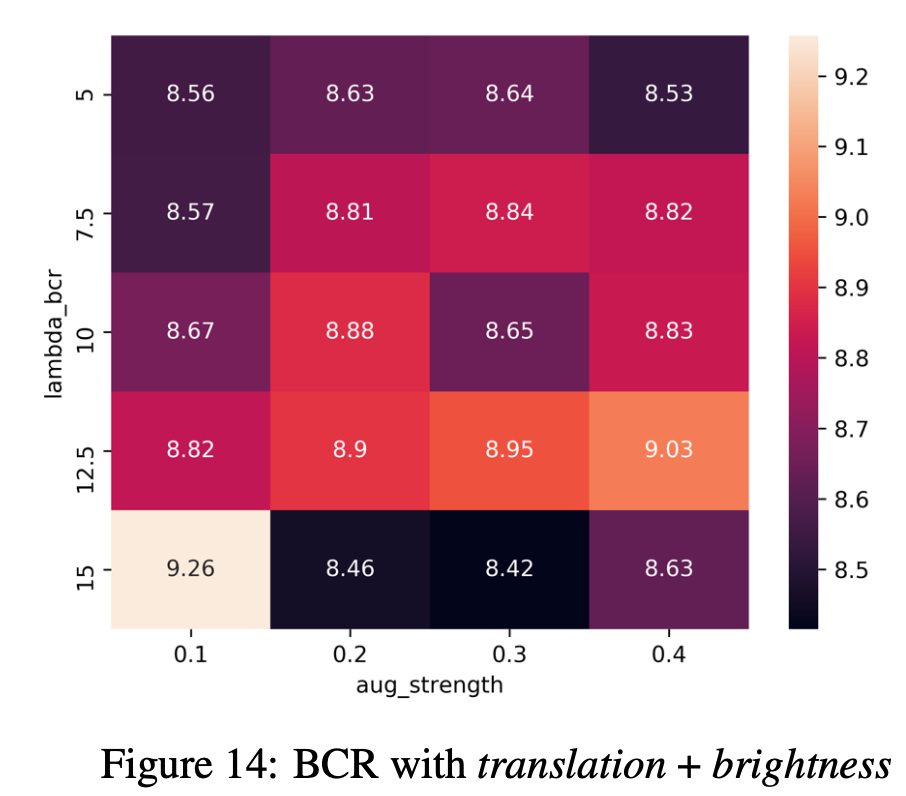
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
ここまでは主にDAを1つだけ適用して実験してきたが2つ同時に適用した場合はどうなるのか。BCRを用いたGAN(FID=8.58)に対して実験を行った。ここでは空間的なDAであるtranslationと見た目的なDAであるbrightnessを組み合わせてみた。その結果が上図であるが、$\lambda_\mathrm{BCR}=15, \lambda_{aug}=0.3$の時にはFID=8.42まで性能が向上した。そのため、複数のDAを用いることでさらなるゲインが得られると考えられる。
1.7 関連研究
DAはモデルのロバスト性と汎化性能を大きく上げてくれるため、画像認識分野では欠かせない存在になっている。最近は半教師あり学習や教師なし学習でも盛り上がりを見せており、発展的なDA[拙著解説]も次々に出てきている。
ただし、DAは依然として画像分類分野においてしか広く研究されておらず、DAによってGANの画像生成のクオリティが上がるかはいまだに謎が多く残っている。最近ではGANにおいてもDAが研究されることが増えてきている。MixUpやガウスノイズを用いてGANの学習の安定化を図ったり、DA自体のみならずConsistency正則化やSelf-Supervised GANのような自己教師あり学習などのDAに関連した手法も提案されている。
1.8 結論
本研究では、様々なDAによってGANの生成能力がどう変化するかを見てきた。その結果、特に次の3つのことがわかった。
- DAはリアル/フェイク画像のどちらにも適用すべき
- Consistency正則化が強力
- Consistenct正則化とContrastive損失を組み合わせることでSoTA
2. 所感とまとめ
画像分類では絶大な効果を発揮しているデータオーギュメンテーションを、GANに適用した場合どうなるのかを多くの実験で示しているおもしろい論文。ほぼノーコストでGANの生成画像のクオリティを上げられるのはDAの凄さを再認識できた。画像生成におけるデータオーギュメンテーションがこの論文をきっかけにさらに発展していきそう。実装もDAを適用するだけでとても簡単なので、ぜひ試してみてはいかがだろうか。
Twitterで人工知能のことや他媒体で書いている記事などを紹介していますのでぜひフォロー@omiita_atiimoしてください!
3. 用語と補足
3.1 モデルのアーキテクチャ
SNDCGANに関しては[Kurach, K.(ICML'19)]、BigGANに関しては[Brock, A.(ICLR'19)]を参照のこと。

"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
4.参考
-
"Image Augmentations for GAN Training", Zhao, Z., Zhang, Z., Singh, S., Zhang, H. (2020)
原論文 -
"Consistency Regularization for Generative Adversarial Networks", Zhang, H., Zhang, Z., Odena, A., Lee, H. (ICLR'20)
Consistency正則化の論文 -
"Improved Consistency Regularization for GANs", Zhao, Z., Singh, S., Lee, H., Zhang, Z., Odena, A., Zhang, H. (2020)
BCRの論文