はじめに
ViTの論文発表以降、数多くの改良モデルが提案され、現在は応用に関する論文が毎日のように発表されている。このように隆盛を誇るAttentionベースのViT界隈に対して、一石を投じると思われる論文が新たに発表されたので紹介する。
筆者は、この夏にViTとMLPMixerに関する論文リンクの記事を作成して以来、新しいモデル提案の論文は大体目を通しているつもりなのだが、最近ではこの論文が一番驚いた。
以下は、上述した筆者が作成した論文リンク。MetaFormerはどちらとも分類できなかったのでリンク集に入れなかった。
Transformer系画像認識モデル論文リンク集
MLP系画像認識モデル論文リンク集
「ViT時代の終焉?」というのはちょっと煽りタイトル気味だけれども、この論文をいち早く紹介している中国語の記事のタイトルは「Transformer的终章还是新起点?」とあり、同じような感想を持つ人もそれなりにいるようだ。
ここでは簡単な論文紹介に加え、実証実験も行う。
MetaFormerとは
論文はこちら。
MetaFormer is Actually What You Need for Vision
Abstractを筆者なりに整理すると、以下の通り。
- 一般にViTの成功は「AttentionベースのTokenMixing」によるものと思われている。
- しかしMLPMixerのようにAttentionをSpatialMLPで置き換えても結構いい性能が出る。
- ということは、ViTの成功はTokenMixing部分ではなく、「Transformerの構造自体」に起因するのではないか?
- この仮説を確認するため、TokenMixingの部分をAveragePoolingで置き換えたもの(PoolFormer)を作成して実験してみた。
- 驚いたことに、単純なPoolingでもViTやMLPMixerと十分比肩できるような性能が出せた。
- そこで、ViTやMLPMixerを含めた構造を一般化した「MetaFormer」という新しいコンセプトを提案する。
- この論文により、今後はTokenMixingに焦点を当てるのではなく、MetaFormer構造の研究が要請されることになる。
乱暴に言ってしまうと、Attention is All You Need論文の流れを汲んで「Attentionすごい」というViTに対し、「MLPでもいいじゃないか」というMLPMixerの出現を受けて、「Pooling(学習パラメータなし)でもいいんだから、そこはもうどうでもいいよ」的なMetaFormerの提案となっている。
以下論文から引用した図で、構造図とImageNet-1Kでの成績比較のグラフ。1
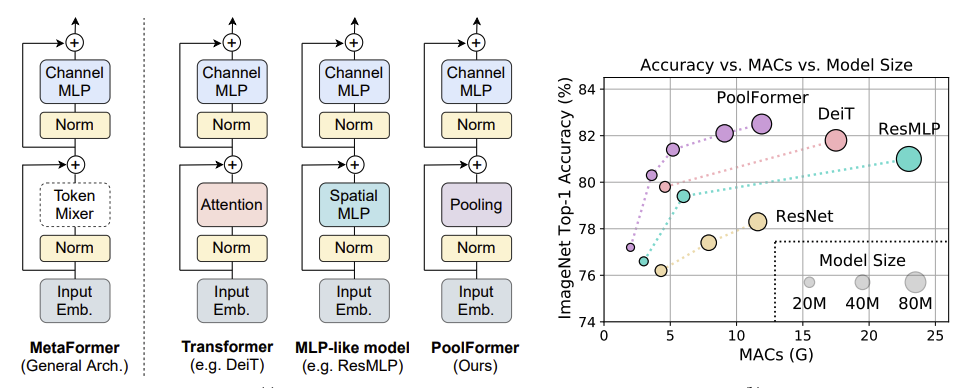
AttentionやSpatialMLPは「Token Mixer」という形で抽象化されて、それを含む一般的な構造をMetaFormerと呼ぶ、ということを構造図が示す。
この論文はSOTAを狙ったものではないが、ImageNetの成績比較は驚くべきもののように思われる。
成績比較の詳細は以下。1
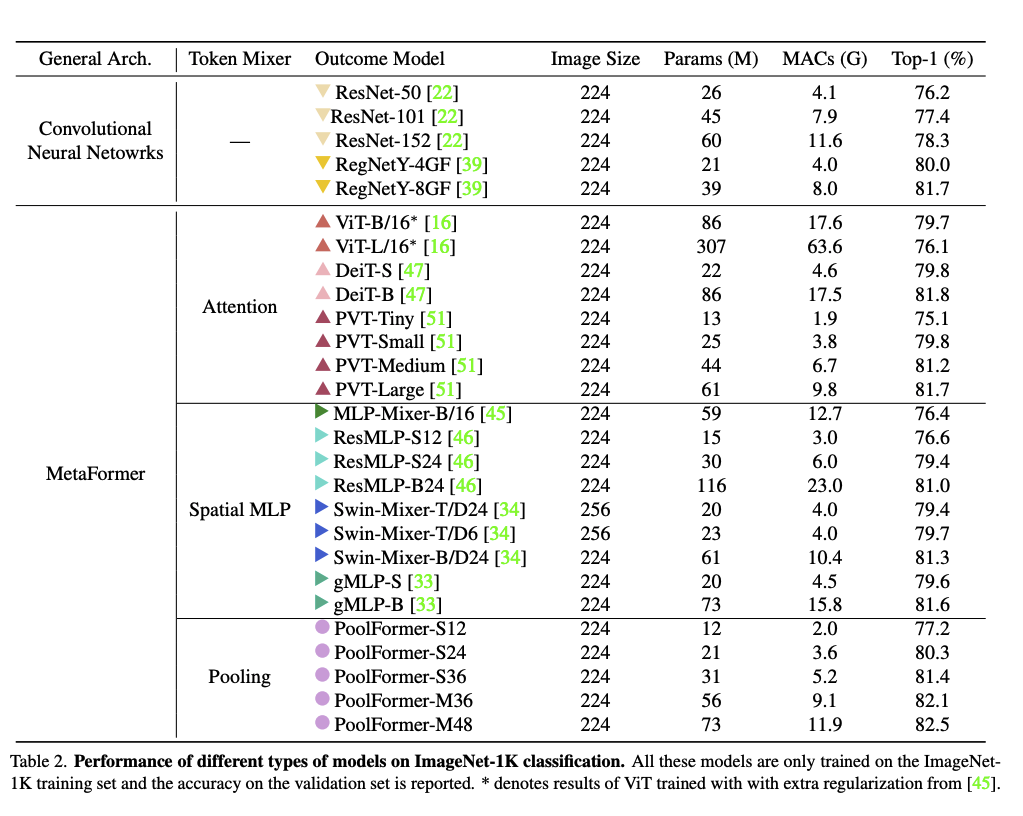
PoolFormerとして実験に使われたものは以下のような構造で、学習パラメータが存在しない。

Poolingのあとに減算があるが、これは「あってもなくても機能するが、減算した方が少し成績が良い」というのがGitHub内の著者のコメントにある。
モデル全体の構造は以下のようになっている。
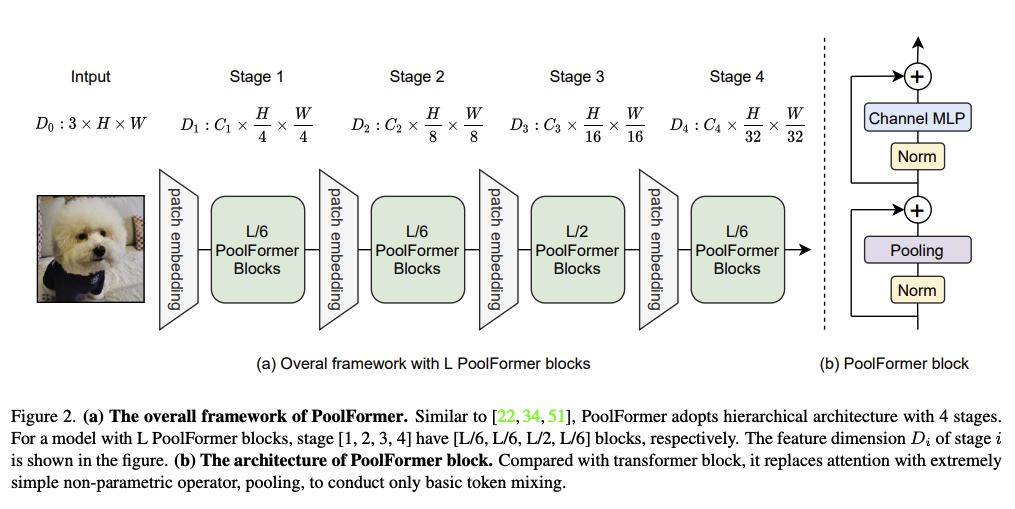
ちなみに、ステージに分けてFeature Mapを縮小していく処理はオリジナルのViTでは存在しないが、最近のViT派生モデルでは割と標準的に行われる。これは「Patch Embedding」と呼んでいるが実態はConvolutionでStrideをつけて縮小する。ViTは当初は「畳み込みはもう要らない!」的に喧伝されていた節もあるが、画像認識に関しては流石に効率が悪すぎるので畳み込みとハイブリッドで、というところに落ち着きつつあるように思われる。
オリジナルのViTから変わらないChannel MLP部分も、結局はカーネルサイズ1x1のPointwise Convolutionともみなせて、実際この論文に掲載されているReferenceコードにはConv2Dとして実装してある。
実装
以下、実際に実装&実験して確認してみる。
TensorFlow2.7.0使用。
MetaFormer
著者たちによるGitHubにはPoolFormerとして実装されているが、ここでは論文の趣旨を尊重してより抽象的なMetaFormerとして実装し、TokenMixingを変更できるようにしている。
def ChannelMLP(x, mlp_ratio, normalize, drop_path=0.0, prefix='' ):
dense_kwargs = {
'kernel_initializer':'he_normal',
'bias_initializer': tf.keras.initializers.RandomNormal(stddev=1e-2),
}
in_shape = x.shape
dim = in_shape[-1]
mlp_dim = dim*mlp_ratio
shortcut = x
# norm
x = normalize(x, name = prefix+"_normalize")
x = layers.Dense(mlp_dim, name=prefix+'_fc1', **dense_kwargs)(x)
x = layers.Activation(tf.nn.gelu, name=prefix+'_activation')(x)
x = layers.Dense(dim, name=prefix+'_fc2', **dense_kwargs)(x)
x = DropPath( drop_path, name=prefix+'_droppath')((shortcut,x))
return x
class DropPath(tf.keras.layers.Layer):
def __init__(self, drop_rate=0.0, use_layer_scale=True, layer_scale_init_value=1e-5,
**kwargs):
super().__init__(**kwargs)
self.drop_rate = drop_rate
self.use_layer_scale=use_layer_scale
self.layer_scale_init_value = layer_scale_init_value
def build(self, input_shape):
if self.use_layer_scale:
self.alpha = self.add_weight("alpha",
shape=[input_shape[0][-1]],
initializer=tf.initializers.Constant(self.layer_scale_init_value),
trainable=True,
dtype=tf.float32)
super().build(input_shape)
def get_config(self):
config = {'drop_rate': self.drop_rate}
base_config = super().get_config()
return dict(list(base_config.items()) + list(config.items()))
def call(self, inputs):
shortcut, x = inputs
if self.drop_rate != 0.0:
noise_shape = [None] + [1 for _ in range(x.shape.rank-1)]
x = layers.Dropout(rate=self.drop_rate, noise_shape=noise_shape)(x)
if self.use_layer_scale:
alpha = tf.expand_dims(tf.expand_dims(self.alpha,0),0)
else:
alpha = tf.constant(1.0)
x = layers.Add()([shortcut, x*alpha])
return x
def patch_embed(x, patch_size=16, stride=16,
embed_dim=768, normalize=None, prefix=''):
x = layers.Conv2D(embed_dim, kernel_size=patch_size,
strides=stride, padding='same', kernel_initializer='he_normal',
name=prefix+'_Conv2D')(x)
if normalize:
x = normalize(x, name=prefix+'_normalize')
return x
def meta_former(
image_size = 224,
patch_size = 16,
channels = 3,
width = 1.0,
num_classes = 1000,
stages = [2, 2, 6, 2],
embed_dims = [64, 128, 320, 512],
mlp_ratios = [4, 4, 4, 4],
downsamples = [True, True, True, True],
in_patch_size=7, in_stride=4,
down_patch_size=3, down_stride=2,
drop_path=0.0,
tokenmixer_type = 'pooling',
norm_type = 'group'
):
embed_dims = [int(dim*width) for dim in embed_dims ]
def normalize(x, name):
if norm_type=='layer':
return layers.LayerNormalization(epsilon=1e-6, name=name)(x)
elif norm_type=='group':
return GroupNorm(groups=32, name=name)(x)
x = inputs = layers.Input(shape=(image_size, image_size, channels), name="Input")
x = patch_embed(x, in_patch_size, in_stride, embed_dims[0], normalize=normalize,
prefix='stem_embedding')
num_layers = sum(stages)
base_drop_rate = drop_path/num_layers
drop_path = 0.0
for i in range(len(stages)):
num_layers_per_stage = stages[i]
for block_idx in range(num_layers_per_stage):
drop_path += base_drop_rate
prefix = f'S{i}B{block_idx}'
x = TokenMixer(x, tokenmixer_type, i, x, normalize, drop_path, prefix)
x = ChannelMLP(x, 4, normalize, drop_path=drop_path,
prefix=prefix+'_ChannelMLP')
if i < len(stages)-1 and downsamples[i]:
x = patch_embed(x, down_patch_size, down_stride, embed_dims[i+1],normalize=normalize,
prefix=prefix+'_embedding')
x = normalize(x, name="Head_norm")
x = layers.GlobalAveragePooling2D(name='Head_averaging')(x)
x = layers.Dense(num_classes, kernel_initializer='he_normal' , name="Head_fc")(x)
return tf.keras.Model(inputs,x)
デフォルトでは論文内でS12として規定されている構造になっている。3番目のステージ(14x14)だけは6層と他より3倍になっているが、そもそもオリジナルのViTではこのステージしかないと解釈できるので、大体ここの層を多くするようだ。
DropPathのところで学習パラメータがあるのは、Going deeper with Image Transformers論文で提案されたLayerScaleを導入しているため。DropPathのレートはオリジナルでは全ステージ0.1固定のようだが、ここではStochastic Depth的に層が深まるごとに徐々に確率が増えるようにしてある。またGroupNormはオリジナルはグループ数1だが、ここでは32で実験した。
その他は概ねPoolFormer(S12)と同じような処理になるようにしてあるが、モデル作成時にwidth引数でフィルター数を調整できるようにしてあり、以降の実験では0.5で行った。
TokenMixing
TokenMixerは以下のように実装してある。前述のようにオリジナルはPoolFormerのみだが、実験のため色々追加してみた。
def TokenMixer(x, tokenmixer_type, stage, normalize, drop_path, prefix):
if tokenmixer_type==None or tokenmixer_type=='empty':
return x
shortcut = x
# norm
x = normalize(x, name = prefix+"_norm")
# token mixing
if tokenmixer_type=='pooling':
x = PoolFormer_Block(x, prefix=prefix+'_PoolFormer')
elif tokenmixer_type=='attention':
heads = [1, 2, 3, 3]
x = MHSA_Block(x, heads[stage] , prefix=prefix+'_MHSA')
elif tokenmixer_type=='mlp':
x = MLPMixer_Block(x, 4, prefix=prefix+'_MLPMixer')
elif tokenmixer_type=='conv':
x = Conv_Block(x, prefix=prefix+'_Conv')
elif tokenmixer_type=='dwconv':
x = DWConv_Block(x, prefix=prefix+'_DWConv')
else:
print('Uknown TokenMixer', tokenmixer_type)
# droppath
x = DropPath( drop_path, name=prefix+'_droppath')((shortcut,x))
return x
Pooling
特に説明なし。
def PoolFormer_Block(x, prefix):
poolsize = 3
x = layers.AveragePooling2D( pool_size=poolsize, strides=1, padding='same',
name = prefix+"_pool")(x) - x
return x
Attention
ヘッド数をステージ毎に変えたMHSAとなっている。1,2,3,3の順番にヘッド数が変わる。
def MHSA_Block(x, num_heads, prefix):
dense_kwargs = {
'kernel_initializer':'he_normal',
'bias_initializer': tf.keras.initializers.RandomNormal(stddev=1e-2),
}
x = layers.Reshape([in_shape[1]*in_shape[2], in_shape[3]], name=prefix+'_reshape1')(x)
x = layers.MultiHeadAttention(num_heads, x.shape[-1]//num_heads, **dense_kwargs,
name=prefix+'_attention')(x,x)
x = layers.Reshape([in_shape[1],in_shape[2], in_shape[3]], name=prefix+'_reshape2')(x)
return x
MLP
MLPMixer風の処理。
def MLPMixer_Block(x, mlp_ratio, prefix):
dense_kwargs = {
'kernel_initializer':'he_normal',
'bias_initializer': tf.keras.initializers.RandomNormal(stddev=1e-2),
}
in_shape = x.shape
x = layers.Reshape([in_shape[1]*in_shape[2], in_shape[3]], name=prefix+'_reshape1')(x)
x = layers.Permute((2, 1), name = prefix+"_swap_axes")(x)
x = layers.Dense(in_shape[3]*mlp_ratio, name=prefix+'_fc1', **dense_kwargs)(x)
x = layers.Activation(tf.nn.gelu, name=prefix+'_activation')(x)
x = layers.Dense(in_shape[1]*in_shape[2], name=prefix+'_fc2', **dense_kwargs)(x)
x = layers.Permute((2, 1), name = prefix+"_swap_axes2")(x)
x = layers.Reshape([in_shape[1],in_shape[2], in_shape[3]], name=prefix+'_reshape2')(x)
return x
Conv2D
2層の畳み込みにしてみた。最初の層だけフィルター数を下げてボトルネック風にしてあるのはパラメータ数を下げたかったため。
def Conv_Block(x, prefix):
conv_kwargs = {
'kernel_initializer':'he_normal',
'bias_initializer': tf.keras.initializers.RandomNormal(stddev=1e-2),
'strides':1,
'padding':'same'
}
dim = x.shape[-1]
kernelsize = 3
x = layers.Conv2D( dim//4, kernelsize, name = prefix+"_conv1", **conv_kwargs)(x)
x = layers.Activation(tf.nn.gelu, name=prefix+'_activation')(x)
x = layers.Conv2D( dim, kernelsize, name = prefix+"_conv2", **conv_kwargs)(x)
return x
DepthwiseConv2D
こちらはDepthwiseConvを2層使用。これだとConvMixerに少し似た感じになる。
def DWConv_Block(x):
conv_kwargs = {
'kernel_initializer':'he_normal',
'bias_initializer': tf.keras.initializers.RandomNormal(stddev=1e-2),
'strides':1,
'padding':'same'
}
kernelsize = 3
x = layers.DepthwiseConv2D( kernelsize, name = prefix+"_dwconv1", **conv_kwargs)(x)
x = layers.Activation(tf.nn.gelu, name=prefix+'_activation')(x)
x = layers.DepthwiseConv2D( kernelsize, name = prefix+"_dwconv2", **conv_kwargs)(x)
return x
Empty
「TokenMixingがどうでもいいのなら、むしろ無くてもいいんじゃないか?」という発想の元に、TokenMixingなしでも実験している。論文内では"Identity Mapping"として同様の実験をしている。
実験
Google Colab上でCIFAR10で確認した。ViT系は過学習対策が大事、ということでBasicのAugmentationに追加して、回転や拡大縮小、CutMixやMixUpを使っている。
基本的には全て同じ設定で、バッチサイズ256で300エポック実施した。
その他詳しいことはソースコード参照のこと。
Accuracy順に掲載すると以下のようになった。
| TokeMixer | Parameters | Time(sec) | Accuracy(%) |
|---|---|---|---|
| Conv2D | 4,191,498 | 6,256 | 97.03 |
| DepthwiseConv2D | 2,895,594 | 6,036 | 96.30 |
| Pooling | 2,862,314 | 5,331 | 96.06 |
| MLP | 6,992,516 | 6,222 | 95.89 |
| Attention | 4,042,706 | 13,008 | 95.72 |
| Empty | 2,857,322 | 4,407 | 94.66 |
パラメータ数が揃っていないので比較は難しいが、以下所見。
- パラメータ数や所要時間が少ないPoolingでも、MLPやAttentionと同等かそれを上回る性能が出たので、論文に沿った結果が出ていると思われる。
- PoolingとDepthwiseConv2Dでは大きな差がないのでほぼ同等。
- Conv2Dの結果が明白に良かったので、流石にTokenMixerがなんでもいいというわけでもない。
- ちなみにハイブリッド(ステージごとにTokenMixerを変更)での実験結果も論文にあって、Stage前半はPooling、後半はAttentionにしたりすると性能が上がるようだ。
- Empty(TokenMixer無し)でも94.66%までいけてしまう。ImageNetでも同様に結構良い結果が出ることが論文内で示されている。
TokenMixerなしでそれなりの性能が出てしまうので、こうなるとTransformerの構造が良いというよりも「Patch Embedding」という名目の、初期のCNNからずっと使われている「ステージ間でConv2Dを使ってFeature Mapを縮小していく構造」が優秀なだけの気もする。
論文では同様の結果に対して、「Surprisingly,MetaFormer with identity mapping can still achieve 74.3% top-1 accuracy, supporting the claim that MetaFormer is actually what we need to guarantee reasonable performance.」とあって、これはMetaFormerが有効な証だと、むしろ肯定的に評価している。
まとめ
取り急ぎ、MetaFormerの概念とその実証モデルであるPoolFormerを紹介し、実験を行った。
実験の結果、概ね論文の主張が再現できた。
「PoolFormerの性能が本当にTransformer固有の構造に由来すると言えるのか」という点で若干疑問はあるが、これをベースに今後新しいモデルに発展する可能性もあるのかもしれない。
-
本記事は2021/11/22付の論文v1によるもので、引用画像もv1から。2021/11/29付で更新された論文v2では比較対象がResNetからRSB-ResNetに変更されているので、そこが本記事とは異なる。RSB-ResNetはまだあまり知られていないはずなので、ここは差し替えないでおく。 ↩ ↩2