CNTK 2.2 Python API 入門 (6) - <総集編> Fashion-MNIST データセットの活用
0. はじめに
◆ CNTK ( Microsoft Cognitive Toolkit ) 2.2 Python API 入門の第6弾 (最終回) です。
今回は入門シリーズの総集編という位置づけで、Fashion-MNIST という新しいデータセットを利用して
(復習として) ここまでに CNTK 実装で学んだコンピュータビジョン関連タスクを総ざらいします。
Fashion-MNIST は MNIST の代替データセットとして、Zalando から2017年8月に公開されました。
フォーマットが MNIST と完全互換であるとともに、(容易過ぎるというような) MNIST の欠点を補います。
私見ですが、機械学習視点から難易度が適度に高い良いデータセットだと思います。
※ 余談ですが @masao-classcat が翻訳した、Fashion-MNIST の README の日本語ドキュメントは README-ja として github の公式レポジトリに含まれています。
◆ 前回までの記事 (CNTK 2.2 Python API 入門 (1) 基本, (2) 2 クラス分類, (3) MNIST, (4) LSTM, (5) オートエンコーダ) で、CNTK 2.2 Tutorials の 100 番台 (初級) を概ねカバーしました。
チュートリアル: CNTK 104: Time Series Basics with Pandas and Finance Data だけは pandas の説明が一つの軸であるためにスキップしました。興味があれば、トライしてみてください。
CNTK 2.2 について次のような点がお分かり頂けたかと思います :
- CNTK Python API を利用して Python プログラムで深層学習モデルが構築できます。
- CNTK はデータとしてテンソルとシークエンスを扱います。
- 深層学習フレームワークでお馴染みのビルディング・ブロックも多数用意されています。
- コンピュータビジョンのための畳み込みネットワーク/オートエンコーダや時系列予測のための LSTM モデルも CNTK で簡単に実装できます。
- ネットワーク定義は Python 関数オブジェクトとして実装され、For ループや lambda 記法も利用できる Python ライクな記法で簡潔に定義可能です。
- Trainer クラスでカプセル化したトレーニングの実装も分かりやすく簡潔です。
- CTF フォーマットの利用で CNTK データ・リーダー (= Reader) が簡単に構成できます。
◆ 次回からは、CNTK 2.2 Tutorials (中級~, 200 番台) への橋渡しとなるような CNTK 2.2 Python API の記事を作成していきます。
※ 今回までの入門編では、Python と機械学習の基本的な知識を持つ読者を想定しています。
※ 他の深層学習フレームワークの経験があれば問題なく読み通せます。

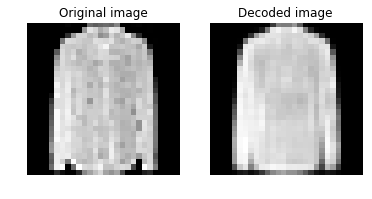
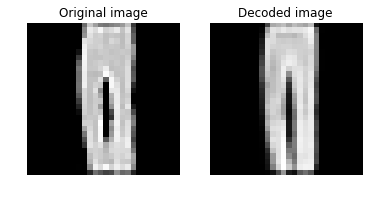
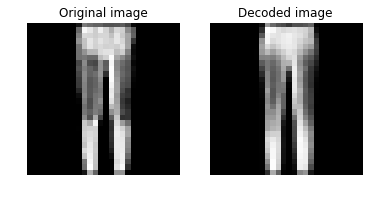
今回の内容は :
- 動作環境と Jupyter Notebook について
- Fashion-MNIST データセットとは / 前処理 (CTF ファイルへセーブ)
- 本記事で使用する CNTK Python API
- MLP (多層パーセプトロン) で分類タスク
- CNN (畳み込みニューラルネットワーク) で分類タスク
- 深層オートエンコーダ
- What's Next
本記事は以下の CNTK チュートリアルを参考にしています :
1. 動作環境と Jupyter Notebook について
動作環境
動作環境の構築が必要な場合には、Cognitive Toolkit 2.2 を Azure Linux GPU 仮想マシンにインストール を参考にしてください。Azure ポータルと Ubuntu Linux にある程度慣れていれば、30 分程度で以下のような環境が構築できるかと思います :
- Azure NC 仮想マシン with NVIDIA Tesla® K80 GPU
- Ubuntu 16.04 LTS
- NVIDIA CUDA 8.0 & cuDNN 6.0
- Anaconda 3 4.1.1
- CNTK 2.2 (for GPU)
Jupyter Notebook
また、本記事でも CNTK チュートリアルでも Jupyter Notebook を多用します。
Jupyter Notebook の利用方法については「CNTK 2.2 Python API 入門 (2)」の記事中の Jupyter Notebook の活用 を参照してください。
2. Fashion-MNIST データセットとは / 前処理 (CTF ファイルへセーブ)
さて、本題に入ります。今回は CNTK 2.2 Python API 入門の総集編という位置づけで、入門シリーズの復習を行ないたいと思います。具体的には、Fashion-MNIST という新しいデータセットを利用して以下のコンピュータビジョン関連タスクを実行してみましょう :
- 前処理 (CTF ファイルへセーブ)、
- MLP (多層パーセプトロン) による分類タスク、
- CNN (畳み込みニューラルネットワーク) による分類タスク、
- そして深層オートエンコーダです。
※ 本章から Jupyter Notebook の利用を想定しています。
2-1 Fashion-MNIST データセット概要
Fashion-MNIST データセットは MNIST の代替データセットとして、Zalando から 2017年8月 に公開されました。
MNIST の欠点を補うとともに、フォーマットは MNIST と完全互換です。ファイル名まで同じです!
私見では、MNIST と完全互換でありながら、MNIST よりも (機械学習の視点から) 適度に難しい、という優れたデータセットです。
(MNIST と同様に) 60,000 サンプルの訓練セットと 10,000 サンプルのテストセットから成り、各サンプルは 28×28 グレースケール画像です。そして以下の 10 クラスのラベルと関連付けられています :
| ラベル | 記述 |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
※ Fashion-MNIST の詳細については Fashion-MNIST README-ja を参照してください。以下はサンプル画像です :

2-2 前処理 (データセットを CTF フォーマットでセーブする)
前処理として、Fashion-MNIST のデータセットをダウンロードした後、CTF (CNTK Text-Format) フォーマットでセーブします。
4 章からのコンピュータビジョン・タスクではこの CTF フォーマットのファイルから Fashion-MNIST データセットを読み込むことになります。
インポート
最初に必要なコンポーネントをインポートします。ここでは CNTK 関連モジュールは必要ありません。
※ ここで Jupyter Notebook の新しいノートブックを作成して使用していきましょう :
from __future__ import print_function
import gzip
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import os
import shutil
import struct
import sys
try:
from urllib.request import urlretrieve
except ImportError:
from urllib import urlretrieve
%matplotlib inline
データセットのダウンロード
次に Fashion-MNIST データセットをダウンロードして NumPy で読み込むためのユティリティ関数を定義します。
これは MNIST 用の関数定義をそのまま流用しています。Fashion-MNIST データセットは MNIST と完全互換であるためにこのような利用方法が可能になります。
実装は標準的ですが、loadData 関数について簡単に説明しておきますと :
- 画像データをダウンロードして解凍します。
- ヘッダの (データセットの種類を表わす) マジック・ナンバー、要素数、行数、カラム数を確認します。
- numpy.fromstring で ndarray に読み込んで、shape (60000, 784) に reshape して返します (784 = 28*28)。
loadLabels 関数もラベルについて同様の処理を行ないます。
そして try_download は loadData と loadLabels 関数がそれぞれ返した ndarray を numpy.hstack で水平に連結します。
つまり、1つの (平坦化された) 画像データと1つのラベルデータが連結されて1つの行に保持されます :
def loadData(src, cimg):
print ('Downloading ' + src)
gzfname, h = urlretrieve(src, './delete.me')
print ('Done.')
try:
with gzip.open(gzfname) as gz:
n = struct.unpack('I', gz.read(4))
if n[0] != 0x3080000:
raise Exception('Invalid file: unexpected magic number.')
n = struct.unpack('>I', gz.read(4))[0]
if n != cimg:
raise Exception('Invalid file: expected {0} entries.'.format(cimg))
crow = struct.unpack('>I', gz.read(4))[0]
ccol = struct.unpack('>I', gz.read(4))[0]
if crow != 28 or ccol != 28:
raise Exception('Invalid file: expected 28 rows/cols per image.')
res = np.fromstring(gz.read(cimg * crow * ccol), dtype = np.uint8)
finally:
os.remove(gzfname)
return res.reshape((cimg, crow * ccol))
def loadLabels(src, cimg):
print ('Downloading ' + src)
gzfname, h = urlretrieve(src, './delete.me')
print ('Done.')
try:
with gzip.open(gzfname) as gz:
n = struct.unpack('I', gz.read(4))
if n[0] != 0x1080000:
raise Exception('Invalid file: unexpected magic number.')
n = struct.unpack('>I', gz.read(4))
if n[0] != cimg:
raise Exception('Invalid file: expected {0} rows.'.format(cimg))
res = np.fromstring(gz.read(cimg), dtype = np.uint8)
finally:
os.remove(gzfname)
return res.reshape((cimg, 1))
def try_download(dataSrc, labelsSrc, cimg):
data = loadData(dataSrc, cimg)
labels = loadLabels(labelsSrc, cimg)
return np.hstack((data, labels))
さて、実際にダウンロードを実行します。URL として Fashion-MNIST のレポジトリを指定しています :
URL='http://fashion-mnist.s3-website.eu-central-1.amazonaws.com'
url_train_image = "%s/train-images-idx3-ubyte.gz" % URL
url_train_labels = "%s/train-labels-idx1-ubyte.gz" % URL
num_train_samples = 60000
print("Downloading train data")
train = try_download(url_train_image, url_train_labels, num_train_samples)
url_test_image = "%s/t10k-images-idx3-ubyte.gz" % URL
url_test_labels = "%s/t10k-labels-idx1-ubyte.gz" % URL
num_test_samples = 10000
print("Downloading test data")
test = try_download(url_test_image, url_test_labels, num_test_samples)
Downloading train data
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
Done.
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
Done.
Downloading test data
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
Done.
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
Done.
インメモリで展開され、この時点で、train 変数が訓練データを保持し、test 変数がテストデータを保持しています。
データを可視化する
train 変数が訓練データを保持していますので、サンプルとして、インデックス 5001 の訓練データを可視化してみましょう。
train[sample_number, :-1] で :-1 により最後のバイト (正確には np.uint8) を除外しているのは、最後のバイトはラベルデータであるためです :
sample_number = 5001
plt.imshow(train[sample_number,:-1].reshape(28,28), cmap="gray_r")
plt.axis('off')
print("Image Label: ", train[sample_number,-1])
Image Label: 0

今まで馴染みがないデータセットだと思いますので、もう少し幾つか画像表示してみましょう :
sample_numbers = [5001, 5002, 5003, 5004, 5005, 5006, 5007, 5008]
sample_labels = []
plt.figure(figsize=(28*4,28))
for i, sample_number in enumerate(sample_numbers):
plt.subplot(1, 8, i+1)
plt.imshow(train[sample_number,:-1].reshape(28,28), cmap="gray_r")
plt.axis('off')
sample_labels.append(train[sample_number,-1])
#print("Image Label: ", train[sample_number,-1])
plt.show()
print("Image Labels : ", sample_labels)
Image Labels : [0, 7, 9, 9, 9, 4, 4, 3]
前節の対応表でマップしてみると、それぞれ次のようになります :
T-shirt/top, Sneaker, Ankle boot, Ankle boot, Ankle boot, Coat, Coat, Dress
CTF フォーマットのテキストファイルとしてセーブする
ndarray (n-次元配列) に展開された画像とラベルデータは .npy, .npz あるいは .pickle ファイルにセーブされることが多いですが、ここでは CNTK テキスト・リーダーと互換性のある CTF フォーマットでセーブします。
そのようなセーブを行なう savetxt 関数を定義します :
def savetxt(filename, ndarray):
dir = os.path.dirname(filename)
if not os.path.exists(dir):
os.makedirs(dir)
if not os.path.isfile(filename):
print("Saving", filename )
with open(filename, 'w') as f:
labels = list(map(' '.join, np.eye(10, dtype=np.uint).astype(str)))
for row in ndarray:
row_str = row.astype(str)
label_str = labels[row[-1]]
feature_str = ' '.join(row_str[:-1])
f.write('|labels {} |features {}\n'.format(label_str, feature_str))
else:
print("File already exists", filename)
ラベルデータは one-hot ベクトルに変換されることに注意しましょう。
セーブを実行します :
data_dir = os.path.join(".", "data", "FASHION")
print ('Writing train text file...')
savetxt(os.path.join(data_dir, "Train-28x28_cntk_text.fashion.txt"), train)
print ('Writing test text file...')
savetxt(os.path.join(data_dir, "Test-28x28_cntk_text.fashion.txt"), test)
print('Done')
Writing train text file...
Saving ./data/FASHION/Train-28x28_cntk_text.fashion.txt
Writing test text file...
Saving ./data/FASHION/Test-28x28_cntk_text.fashion.txt
Done
Jupyter Notebook を実行しているディレクトリ下に、
./data/FASHION/Train-28x28_cntk_text.fashion.txt 及び Test-28x28_cntk_text.fashion.txt としてセーブされます。
普通のテキストファイルですから、ダンプも可能です :
$ wc -l *.txt
10000 Test-28x28_cntk_text.fashion.txt
60000 Train-28x28_cntk_text.fashion.txt
70000 total
$ head -n 1 Train-28x28_cntk_text.fashion.txt
|labels 0 0 0 0 0 0 0 0 0 1 |features 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 13 73 0 0 1 4 0 0 0 0 1 1 3 4 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 6 0 102 204 176 134 144 123 23 0 0 0 0 12 10 0 0 0 0 0 0 0 0 0 0 072 15 0 0 0 0 0 0 0 0 0 0 0 1 0 69 207 223 218 216 216 163 127 121 122 146 141 88 172 66 0 0 0 0 0 0 0 7 123 196 229 0 0 0 0 0 0 0 0 0 0 0 0 0 0 183 225 216 223 228 235 227 224 222 224 221 223 245 173 0 0 0 211 213 223 220 243 202 0 0 0 0 0 0 0 0 0 0 1 3 0 12 219 220 212 218 192 169 227 208 218 224 212 226 103 198 221 215 213 222 220 245 119 167 56 0 0 0 0 0 0 0 0 0 4 0 0 55 236 228 230 228 240 232 213 218 22 217 223 222 219 222 221 216 223 229 215 218 255 77 0 0 3 0 0 0 0 0 0 0 62 145 204 228 207 213 221 218 4 82 107 189 228 220 222 217 226 200 205 211 230 224 234 176 188 250 248 233 238 215 0 0 57 187 208 22455 255 221 234 221 211 220 232 246 0 3 202 228 224 221 211 211 214 205 205 205 220 240 80 150 255 229 20 222 229 229 234 249 220 194 215 217 241 65 73 106 117 168 219 221 215 217 223 223 224 229 29 75 204 2 227 245 239 223 218 212 209 222 220 221 230 67 48 203 183 194 213 197 185 190 194 192 202 214 219 221 5 0 122 219 193 179 171 183 196 204 210 213 207 211 210 200 196 194 191 195 191 198 192 176 156 167 177 188 193 198 204 209 210 210 211 188 188 194 192 216 170 0 2 0 0 0 66 200 222 237 239 242 246 243 244 2 0 0 0 0 0 0 40 61 44 72 41 35 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
3. 本記事で使用する CNTK Python API
今回使用する CNTK Python API を先にリストアップしておきます。
実際には前回までに使用した API で、今回は復習という位置づけですので初出の API はありません。
cntk.io パッケージ
| API | 説明 |
|---|---|
CTFDeserializer |
組み込みの deserializer(*) で、CTF (CNTK Text Format) リーダーを構成します。 |
INFINITELY_REPEAT |
全データ sweep (総なめ) のサイズに等しい、ミニバッチ・スケジューリング・ユニットを指定するために使用される定数です。 |
MinibatchSource |
CNTK の Python API 用リーダーです。 |
StreamDef |
deserializer を使用するためにストリームを構成します。 |
StreamDefs |
キーワード引数からレコードを構築します。API というよりも (Python の) 辞書のような働きをします。 |
※ deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
cntk.layers パッケージ
cntk.layers.blocks モジュール
| API | 説明 |
|---|---|
LSTM |
recurrence の内側での使用のための LSTM ブロックを作成するための層ファクトリ関数です。 |
cntk.layers.higher_order_layers モジュール
| API | 説明 |
|---|---|
Sequential |
入力上に層のシーケンス (または任意の関数) を適用する合成 (= composite) を作成する層ファクトリ関数です。 |
cntk.layers.layers モジュール
| API | 説明 |
|---|---|
Convolution2D |
2D 畳み込み層を作成する層ファクトリ関数です。 |
Dense |
完全結合線形層のインスタンスを作成するための層ファクトリ関数です。 |
Dropout |
dropout 層を作成するための層ファクトリ関数です。 |
Embedding |
embedding (埋め込み) 層を作成するための層ファクトリ関数です。 |
MaxPooling |
マックス・プーリング層を作成するための層ファクトリ関数です。 |
cntk.layers.sequence モジュール
| API | 説明 |
|---|---|
Recurrence |
RNN, LSTM, そして GRU を含む、リカレント・モデルを実装する層ファクトリ関数です。 |
cntk.learners パッケージ
| API | 説明 |
|---|---|
learning_rate_schedule |
学習率スケジュールを作成します。 |
adam |
モデル・パラメータを学習するために Adam learner インスタンスを作成します。 |
fsadagrad |
モデル・パラメータを学習するために FSAdaGrad learner インスタンスを作成します。 |
sgd |
モデル・パラメータを学習するために SGD learner インスタンスを作成します。 |
UnitType |
schedule の値がサンプル毎上かミニバッチ毎上で指定されるかを示します。 |
cntk.losses パッケージ
| API | 説明 |
|---|---|
cross_entropy_with_softmax (output_vector, target_vector) |
target_vector と output_vector の softmax 間の交差エントロピーを計算します。 |
squared_error |
二乗誤差 - この演算は2つの入力行列の要素間の二乗の差異の総和を計算します。 |
cntk.metrics パッケージ
| API | 説明 |
|---|---|
classification_error (output_vector, target_vector) |
分類エラーを計算します。 |
cntk.ops パッケージ
| API | 説明 |
|---|---|
input_variable |
ネットワークの入力を作成します : 特徴やラベルのようなデータが供給される場所で、いわゆるプレースホルダーです。 |
log |
element-wise に自然対数を計算します。 |
parameter |
パラメータ・テンソルを作成します。 |
relu |
ReLU 活性化関数です。 |
sigmoid |
sigmoid 活性化関数です。 |
softmax |
softmax 活性化関数です。 |
times |
乗算ですが、この演算の出力は2つの入力行列の積 (= matrix product) です。ブロードキャストをサポートします。 |
cntk.ops.sequence パッケージ
| API | 説明 |
|---|---|
sequence.input_variable |
ネットワークの入力を作成します: 特徴やラベルのようなデータが提供されるべき場所です。 |
sequence.last (seq) |
symbolic 入力シーケンス seq の最後の要素を返します。 |
cntk.tests.test_utils パッケージ
| API | 説明 |
|---|---|
set_device_from_pytest_env() |
Jupyter Notebook 利用時に正しいターゲット・デバイスを選択するためのヘルパー関数です。総ての Jupyter Notebook の開始時にこれを呼び出す必要があります。 |
cntk.train パッケージ
cntk.train.trainer モジュール
| API | 説明 |
|---|---|
Trainer |
モデル・パラメータをトレーニングするクラス。 |
4. MLP (多層パーセプトロン) で分類タスク
2 章でデータセットの前処理が完了しましたので、Fashion-MNIST データセットの分類タスクのために MLP (多層パーセプトロン) モデルを実装します。
繰り返しになりますが、Fashion-MNIST は MNIST と完全互換ですから、MNIST 用の実装がそのまま流用できます。
インポート
最初に必要なコンポーネントをインポートします。Jupyter Notebook の新しいノートブックを作成して使用しましょう :
from __future__ import print_function
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import sys
import os
import cntk as C
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env()
C.cntk_py.set_fixed_random_seed(1)
%matplotlib inline
4-1 データ・リーディング
リーダーの作成
Fashion-MNIST データは 2 章で CTF フォーマットでセーブしてあります。
各サンプルは 2 フィールド (labels, features) を含み、そのフォーマットは次のようなものです :
|labels 0 0 0 1 0 0 0 0 0 0 |features 0 0 0 0 ...
(各々がピクセルを表現する 784 整数)
特徴ベクトルに相当するのは、"features" という名前の整数ストリームです。各整数がピクセルに対応しています。
ラベルは one-hot にエンコードされています。
◆ まず、入力次元と出力クラスを定義します :
input_dim = 784
num_output_classes = 10
◆ 訓練/テストデータを読むための create_reader 関数を作成します。cntk.io.CTFDeserializer を使用すれば CTF フォーマットのテキストを読むことができます :
def create_reader(path, is_training, input_dim, num_label_classes):
return C.io.MinibatchSource(C.io.CTFDeserializer(path, C.io.StreamDefs(
labels = C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False),
features = C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)
)), randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)
※ deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
訓練とテストデータが利用可能であることを確認します :
data_dir = os.path.join(".", "data", "FASHION")
train_file = os.path.join(data_dir, "Train-28x28_cntk_text.fashion.txt")
test_file = os.path.join(data_dir, "Test-28x28_cntk_text.fashion.txt")
if not (os.path.isfile(train_file) and os.path.isfile(test_file)):
raise ValueError("Please generate the data by completing CNTK 103 Part A")
print("Data directory is {0}".format(data_dir))
Data directory is ./data/FASHION
4-2 モデル作成 / ネットワーク構築
モデル作成
作成する多層パーセプトロンは隠れ層 2 つの単純なものです。最初の Dense 層の仕様の概略を示しますと :
- 入力次元 = 784 (各入力ピクセル)
- 出力次元 = 400 (隠れ層の数、ユーザにより指定されるパラメータ)
- 活性化関数は
relu
それぞれが relu の活性化関数を持つ隠れ層としての 2 dense 層を持ち、活性化関数を持たない一つの出力層を持ちます。
2つの隠れ層 (num_hidden_layers) の出力次元 (i.e. 隠れノードの数) は同じ数の隠れノード 400 に hidden_layers_dim として設定しています :
num_hidden_layers = 2
hidden_layers_dim = 400
◆ 最終出力層は 10 値のベクトルを吐きます。
モデルの出力を正規化するために softmax を使用しますので、この層では活性化関数は使用しません。CNTK の softmax 演算は loss 関数とバンドルされています。
ネットワーク構築
入力変数 input_variable は、データが供給されるコンテナ、あるいはプレースホルダーです :
input = C.input_variable(input_dim)
label = C.input_variable(num_output_classes)
以下はモデルの直訳としてのコードです :
def create_model(features):
with C.layers.default_options(init = C.layers.glorot_uniform(), activation = C.ops.relu):
h = features
for _ in range(num_hidden_layers):
h = C.layers.Dense(hidden_layers_dim)(h)
r = C.layers.Dense(num_output_classes, activation = None)(h)
return r
z はネットワーク出力を表わすために使用されます。
入力を 255.0 で除算して (各ピクセルを [0, 1] の範囲に) 正規化していることに注意してください :
z = create_model(input/255.0)
4-3 トレーニング
損失関数と評価メトリクス
エビデンスをクラスに渡る確率分布にマップするために softmax 関数を使用します。
そしてラベルとこのネットワークにより予測される確率の間の交差エントロピーを最小化することがモデル・パラメータの学習プロセスです。
CNTK の cross_entropy_with_softmax(z, label) は正解ラベル label と、ネットワーク出力 z の softmax 間の交差エントロピーを計算してくれます。
cntk.metrics.classification_error を利用すれば分類エラーを計算できます :
loss = C.cross_entropy_with_softmax(z, label)
label_error = C.classification_error(z, label)
trainer を構成する
モデル・パラメータのトレーニングを駆動する Trainer クラスをインスタンス化します。
Trainer コンストラクタの基本的な引数は、モデル、損失関数等の評価尺度のタプル、learner (オプティマイザ) のリストです :
learning_rate = 0.2
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
learner = C.sgd(z.parameters, lr_schedule)
trainer = C.Trainer(z, (loss, label_error), [learner])
訓練の進捗を可視化するために必要なヘルパー関数を作成します :
def moving_average(a, w=5):
if len(a) < w:
return a[:] # Need to send a copy of the array
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
def print_training_progress(trainer, mb, frequency, verbose=1):
training_loss = "NA"
eval_error = "NA"
if mb%frequency == 0:
training_loss = trainer.previous_minibatch_loss_average
eval_error = trainer.previous_minibatch_evaluation_average
if verbose:
print ("Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%".format(mb, training_loss, eval_error*100))
return mb, training_loss, eval_error
trainer を実行する
ネットワークを訓練する準備ができましたので、訓練エンジンに供給するデータの形状を決定します。
オプティマイザの各反復は minibatch_size 64 のサンプルを使用するものとして、総計 60,000 データポイント上でトレーニングします。 更にデータポイント全体に渡り num_sweeps_to_train_with で指定される複数回のパス (= エポック数) を通します。反復数 (= 総ステップ数) は num_minibatches_to_train で表わされます :
minibatch_size = 64
num_samples_per_sweep = 60000
num_sweeps_to_train_with = 20
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size
※ Fashion-MNIST データセットは MNIST よりも難しいので、エポック数は (10 から) 20 に増やしました。
◆ トレーニングを実行します :
reader_train = create_reader(train_file, True, input_dim, num_output_classes)
input_map = {
label : reader_train.streams.labels,
input : reader_train.streams.features
}
training_progress_output_freq = 500
plotdata = {"batchsize":[], "loss":[], "error":[]}
for i in range(0, int(num_minibatches_to_train)):
data = reader_train.next_minibatch(minibatch_size, input_map = input_map)
trainer.train_minibatch(data)
batchsize, loss, error = print_training_progress(trainer, i, training_progress_output_freq, verbose=1)
if not (loss == "NA" or error =="NA"):
plotdata["batchsize"].append(batchsize)
plotdata["loss"].append(loss)
plotdata["error"].append(error)
Minibatch: 0, Loss: 2.2303, Error: 78.12%
Minibatch: 500, Loss: 0.3980, Error: 10.94%
Minibatch: 1000, Loss: 0.3538, Error: 15.62%
Minibatch: 1500, Loss: 0.2891, Error: 10.94%
Minibatch: 2000, Loss: 0.5299, Error: 15.62%
Minibatch: 2500, Loss: 0.3839, Error: 12.50%
Minibatch: 3000, Loss: 0.3229, Error: 9.38%
Minibatch: 3500, Loss: 0.1604, Error: 4.69%
Minibatch: 4000, Loss: 0.3731, Error: 12.50%
Minibatch: 4500, Loss: 0.4468, Error: 18.75%
Minibatch: 5000, Loss: 0.3313, Error: 9.38%
Minibatch: 5500, Loss: 0.2462, Error: 12.50%
Minibatch: 6000, Loss: 0.1977, Error: 9.38%
Minibatch: 6500, Loss: 0.5160, Error: 21.88%
Minibatch: 7000, Loss: 0.3142, Error: 12.50%
Minibatch: 7500, Loss: 0.2757, Error: 10.94%
Minibatch: 8000, Loss: 0.1934, Error: 4.69%
Minibatch: 8500, Loss: 0.1561, Error: 6.25%
Minibatch: 9000, Loss: 0.1686, Error: 7.81%
Minibatch: 9500, Loss: 0.2127, Error: 7.81%
Minibatch: 10000, Loss: 0.1926, Error: 7.81%
Minibatch: 10500, Loss: 0.2572, Error: 9.38%
Minibatch: 11000, Loss: 0.2309, Error: 7.81%
Minibatch: 11500, Loss: 0.2768, Error: 10.94%
Minibatch: 12000, Loss: 0.2366, Error: 9.38%
Minibatch: 12500, Loss: 0.4730, Error: 20.31%
Minibatch: 13000, Loss: 0.2084, Error: 9.38%
Minibatch: 13500, Loss: 0.2515, Error: 9.38%
Minibatch: 14000, Loss: 0.1665, Error: 4.69%
Minibatch: 14500, Loss: 0.1407, Error: 4.69%
Minibatch: 15000, Loss: 0.1881, Error: 7.81%
Minibatch: 15500, Loss: 0.2558, Error: 10.94%
Minibatch: 16000, Loss: 0.1648, Error: 7.81%
Minibatch: 16500, Loss: 0.0798, Error: 3.12%
Minibatch: 17000, Loss: 0.0894, Error: 6.25%
Minibatch: 17500, Loss: 0.0940, Error: 1.56%
Minibatch: 18000, Loss: 0.2195, Error: 7.81%
Minibatch: 18500, Loss: 0.0579, Error: 1.56%
トレーニング中に保持しておいた plotdata を利用して、訓練の進捗をミニバッチ・ベースで可視化してみます :
plotdata["avgloss"] = moving_average(plotdata["loss"])
plotdata["avgerror"] = moving_average(plotdata["error"])
import matplotlib.pyplot as plt
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata["batchsize"], plotdata["avgloss"], 'b--')
plt.xlabel('Minibatch number')
plt.ylabel('Loss')
plt.title('Minibatch run vs. Training loss')
plt.show()
plt.subplot(212)
plt.plot(plotdata["batchsize"], plotdata["avgerror"], 'r--')
plt.xlabel('Minibatch number')
plt.ylabel('Label Prediction Error')
plt.title('Minibatch run vs. Label Prediction Error')
plt.show()
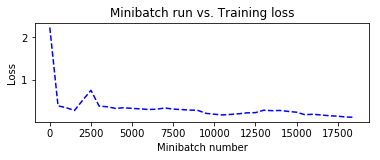
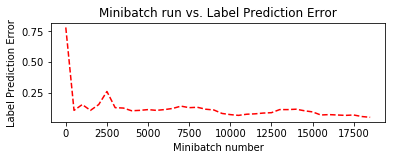
4-4 評価
テストを実行する
テストデータを使用して訓練されたネットワークを評価します。そのためには trainer.test_minibatch メソッドを使用します :
reader_test = create_reader(test_file, False, input_dim, num_output_classes)
test_input_map = {
label : reader_test.streams.labels,
input : reader_test.streams.features,
}
test_minibatch_size = 512
num_samples = 10000
num_minibatches_to_test = num_samples // test_minibatch_size
test_result = 0.0
for i in range(num_minibatches_to_test):
data = reader_test.next_minibatch(test_minibatch_size,
input_map = test_input_map)
eval_error = trainer.test_minibatch(data)
test_result = test_result + eval_error
print("Average test error: {0:.2f}%".format(test_result*100 / num_minibatches_to_test))
Average test error: 10.77%
MNIST は 10 epochs で 1.76% でしたので、20 epochs で 10.77 % は Fashion-MNIST の難易度が高いことを示しています。
予測を確認する
先にエラーの累積による計測を行ないましたが、個々のデータポイントについての確率を得ましょう。各データポイントについては、eval 関数が総てのクラスに渡る確率分布を返します。
最初にネットワーク出力を softmax 関数を通します。これはネットワークに渡る合計の活性化を 10 クラスに渡る確率にマップします。
ネットワーク定義には softmax を含めていなかったことを思い出してください。
out = C.softmax(z)
テストデータからのミニバッチ・サンプル上で試してみます :
reader_eval = create_reader(test_file, False, input_dim, num_output_classes)
eval_minibatch_size = 25
eval_input_map = {input: reader_eval.streams.features}
data = reader_test.next_minibatch(eval_minibatch_size, input_map = test_input_map)
img_label = data[label].asarray()
img_data = data[input].asarray()
predicted_label_prob = [out.eval(img_data[i]) for i in range(len(img_data))]
pred = [np.argmax(predicted_label_prob[i]) for i in range(len(predicted_label_prob))]
gtlabel = [np.argmax(img_label[i]) for i in range(len(img_label))]
print("Label :", gtlabel[:25])
print("Predicted:", pred)
Label : [1, 6, 1, 6, 8, 5, 4, 0, 4, 0, 4, 9, 3, 8, 5, 2, 8, 6, 2, 8, 0, 4, 4, 0, 8]
Predicted: [1, 6, 1, 6, 8, 5, 4, 0, 4, 0, 4, 9, 3, 8, 5, 2, 8, 6, 2, 8, 6, 4, 4, 0, 8]
平均テストエラーが高い割りには、ここでの誤分類は1つだけでした。
可視化
結果の一つを可視化してみます :
sample_number = 5
plt.imshow(img_data[sample_number].reshape(28,28), cmap="gray_r")
plt.axis('off')
img_gt, img_pred = gtlabel[sample_number], pred[sample_number]
print("Image Label: ", img_pred)
Image Label: 5

5 は "Sandal" ですので、合っているものと思われます。
5. CNN (畳み込みネットワーク) で分類タスク
Fasion-MNIST データの分類タスクのために、前章では多層パーセプトロン・モデルを使用しました。
次に、畳み込みニューラルネットワーク・モデルを CNTK で実装して Fashion-MNIST データを分類します。
ここでも MNIST のために使用したコードが流用できますが、(難易度が高い) Fashion-MNIST のために単純ですがモデルを改良する努力をしてみます。
インポート
例によって最初に必要なコンポーネントをインポートします。Jupyter Notebook の新しいノートブックを作成して使用しましょう :
from __future__ import print_function
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import os
import sys
import time
import cntk as C
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env()
C.cntk_py.set_fixed_random_seed(1)
%matplotlib inline
5-1 データ・リーディング
入力次元
本章でも作成済みの CTF フォーマットの Fashion-MNIST データを利用します。
但し、MLP ではベクトルに平坦化された入力画像を使用していましたが、畳み込みネットワークでは空間的な特性も利用します。
畳み込みネットワークでは、入力データは通常は 3D 行列 (チャネル数, 画像幅, 画像高さ) に shape されます、これはピクセル間の空間的な関係を保存しています。
自然風景のカラー画像はしばしば Red-Green-Blue (RGB) カラーチャネルとして表現されます。
そのような画像の入力次元はタプル (3, 画像幅, 画像高さ) として指定されます。
MNIST 画像は単一チャネル (グレースケール) データですので、入力次元はタプル (1, 画像幅, 画像高さ) として指定されます :
# データ次元を定義します。
input_dim_model = (1, 28, 28) # 画像は 28 x 28 でカラーの 1 チャネル (グレー) を持ちます。
input_dim = 28*28 # 入力データをベクトルとして扱うためにリーダーで使用されます。
num_output_classes = 10
データフォーマット
Fashion-MNIST データは 2 章で CTF (CNTK Text-Format) フォーマットでストアされています。
各サンプルは 2 フィールド (labels, features) を含み、そのフォーマットは次のようなものです :
|labels 0 0 0 1 0 0 0 0 0 0 |features 0 0 0 0 ...
(各々がピクセルを表現する 784 整数)
特徴ベクトルに相当するのは、"features" という名前の整数ストリームです。各整数がピクセルに対応しています。
ラベルは one-hot にエンコードされています。
リーダーの作成
訓練/テストデータを読むための create_reader 関数を作成しますが、これも前章と同じです。
cntk.io.CTFDeserializer を使用すれば CTF フォーマットのテキストを読むことができます。
deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
def create_reader(path, is_training, input_dim, num_label_classes):
ctf = C.io.CTFDeserializer(path, C.io.StreamDefs(
labels=C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False),
features=C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)))
return C.io.MinibatchSource(ctf,
randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)
(既に確認済みですが、) 2 章で作成した訓練とテストデータが利用可能であることを確認します :
data_dir = os.path.join(".", "data", "FASHION")
train_file = os.path.join(data_dir, "Train-28x28_cntk_text.fashion.txt")
test_file = os.path.join(data_dir, "Test-28x28_cntk_text.fashion.txt")
if not (os.path.isfile(train_file) and os.path.isfile(test_file)):
raise ValueError("Please generate the data by completing CNTK 103 Part A")
print("Data directory is {0}".format(data_dir))
Data directory is ./data/FASHION
5-2 ネットワーク構築
ネットワーク入力
今までと同様に、プレースホルダーとしての入力変数 input_variable を2つ定義します。
入力 Fashion-MNIST 画像のために1つ、10 数字に相当するラベルのために1つですが、畳み込みニューラルネットワークでは注意点があります。
リーダーはデータを読むとき、画像あたり 784 ピクセルのデータを、タプル input_dim_model で定義された shape に自動的にマップ することです。
今回の例では input_dim_model は先に (1,28,28) に設定されています :
# input_dim_model = (1, 28, 28)
x = C.input_variable(input_dim_model)
y = C.input_variable(num_output_classes)
ネットワーク定義
MNIST で使用した定義では畳み込み層のフィルタ数は 8 と 16 でしたが、Fashion-MNIST のために 32 と 64 に増やしてみました :
def create_model(features):
with C.layers.default_options(init = C.layers.glorot_uniform(), activation = C.relu):
h = features
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=32,
strides=(1,1),
pad=True, name="first_conv")(h)
h = C.layers.MaxPooling(filter_shape=(2,2),
strides=(2,2), name="first_max")(h)
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=64,
strides=(1,1),
pad=True, name="second_conv")(h)
h = C.layers.MaxPooling(filter_shape=(3,3),
strides=(3,3), name="second_max")(h)
r = C.layers.Dense(num_output_classes, activation = None, name="classify")(h)
return r
さて、モデルのインスタンスを作成してモデルの各種コンポーネントを少しばかり探求しましょう。
z はネットワーク出力を表わすために使用されます :
# モデルを作成する
z = create_model(x)
# 出力 shape / 各種コンポーネントのパラメータを出力表示します。
print("Output Shape of the first convolution layer:", z.first_conv.shape)
print("Bias value of the last dense layer:", z.classify.b.value)
Output Shape of the first convolution layer: (32, 28, 28)
Bias value of the last dense layer: [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
見積もられるモデル・パラメータの数の理解は深層学習において大切です、何故ならば持つべきデータの総量への直接的な依存関係があるからです。より大きな数のパラメータを持つモデルがオーバーフィッティングを回避するためにはより多くのデータが必要です。換言すれば、固定されたデータ総量を持つならば、パラメータ数を抑制しなければなりません。
※ モデル訓練の性能を データ拡張 でブーストできる方法はあります。
# ネットワークのパラメータの総数
C.logging.log_number_of_parameters(z)
Training 62346 parameters in 6 parameter tensors.
5-3 トレーニング
モデルパラメータの学習
エビデンスをクラスに渡る確率分布にマップするために softmax 関数を使用します。そしてラベルとこのネットワークにより予測される確率の間の交差エントロピーを最小化することがモデル・パラメータの学習のプロセスです。
CNTK の cross_entropy_with_softmax(z, label) は正解ラベル label と、ネットワーク出力 z の softmax 間の交差エントロピーを計算してくれます。
cntk.metrics.classification_error を利用すれば分類エラーを計算できます :
def create_criterion_function(model, labels):
loss = C.cross_entropy_with_softmax(model, labels)
errs = C.classification_error(model, labels)
return loss, errs # (model, labels) -> (loss, error metric)
trainer を構成する
先に訓練に関連する異なる関数を可視化するために必要とされるヘルパー関数を作成しておきます :
def moving_average(a, w=5):
if len(a) < w:
return a[:] # Need to send a copy of the array
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
def print_training_progress(trainer, mb, frequency, verbose=1):
training_loss = "NA"
eval_error = "NA"
if mb%frequency == 0:
training_loss = trainer.previous_minibatch_loss_average
eval_error = trainer.previous_minibatch_evaluation_average
if verbose:
print ("Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%".format(mb, training_loss, eval_error*100))
return mb, training_loss, eval_error
そして、既に損失関数、オプティマイザ (or learner) 等々のモデルを訓練するために必要な個々のテクニックについての説明は十分だと思いますので、モデル訓練とテストのためのコードをまとめて簡潔にまとめてみましょう :
plotdata = {"batchsize":[], "loss":[], "error":[]}
def train_test(train_reader, test_reader, model_func, num_sweeps_to_train_with=10):
# モデル関数をインスタンス化します; x は入力 (feature) 変数です。
# 総ての入力値を 255 で除算して入力画像ピクセルを 0-1 の範囲内にスケールします。
model = model_func(x/255)
# 損失とエラー関数をインスタンス化します。
loss, label_error = create_criterion_function(model, y)
# モデル訓練を駆動するための trainer オブジェクトをインスタンス化
learning_rate = 0.2
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
learner = C.sgd(z.parameters, lr_schedule)
trainer = C.Trainer(z, (loss, label_error), [learner])
# trainer のためのパラメータの初期化
minibatch_size = 64
num_samples_per_sweep = 60000
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size
# データストリームを入力とラベルにマップします。
input_map={
y : train_reader.streams.labels,
x : train_reader.streams.features
}
# ログ出力の頻度
training_progress_output_freq = 500
# タイマーの開始
start = time.time()
for i in range(0, int(num_minibatches_to_train)):
# 訓練データファイルからミニバッチを読みます。
data=train_reader.next_minibatch(minibatch_size, input_map=input_map)
trainer.train_minibatch(data)
#print_training_progress(trainer, i, training_progress_output_freq, verbose=1)
batchsize, loss, error = print_training_progress(trainer, i, training_progress_output_freq, verbose=1)
if not (loss == "NA" or error =="NA"):
plotdata["batchsize"].append(batchsize)
plotdata["loss"].append(loss)
plotdata["error"].append(error)
# 訓練時間の出力表示
print("Training took {:.1f} sec".format(time.time() - start))
# モデルのテスト
test_input_map = {
y : test_reader.streams.labels,
x : test_reader.streams.features
}
# 訓練されたモデルのためのテストデータ
test_minibatch_size = 512
num_samples = 10000
num_minibatches_to_test = num_samples // test_minibatch_size
test_result = 0.0
for i in range(num_minibatches_to_test):
# test_minibatch_size で指定されたバッチとしてテストデータをロードします。
data = test_reader.next_minibatch(test_minibatch_size, input_map=test_input_map)
eval_error = trainer.test_minibatch(data)
test_result = test_result + eval_error
# 総てのテスト・ミニバッチの評価エラーの平均
print("Average test error: {0:.2f}%".format(test_result*100 / num_minibatches_to_test))
trainer を実行する
畳み込みニューラルネットを訓練する準備ができましたので、実行してみましょう。train_test の引数で 50 エポックを指定しています :
def do_train_test():
global z
z = create_model(x)
reader_train = create_reader(train_file, True, input_dim, num_output_classes)
reader_test = create_reader(test_file, False, input_dim, num_output_classes)
train_test(reader_train, reader_test, z, num_sweeps_to_train_with=50)
do_train_test()
Minibatch: 0, Loss: 2.2744, Error: 82.81%
Minibatch: 500, Loss: 0.3144, Error: 7.81%
Minibatch: 1000, Loss: 0.3043, Error: 12.50%
Minibatch: 1500, Loss: 0.2347, Error: 4.69%
Minibatch: 2000, Loss: 0.4274, Error: 15.62%
Minibatch: 2500, Loss: 0.2096, Error: 7.81%
Minibatch: 3000, Loss: 0.2195, Error: 9.38%
Minibatch: 3500, Loss: 0.0818, Error: 3.12%
Minibatch: 4000, Loss: 0.2172, Error: 7.81%
Minibatch: 4500, Loss: 0.3045, Error: 10.94%
Minibatch: 5000, Loss: 0.2357, Error: 4.69%
Minibatch: 5500, Loss: 0.1980, Error: 9.38%
Minibatch: 6000, Loss: 0.2151, Error: 4.69%
Minibatch: 6500, Loss: 0.5589, Error: 10.94%
Minibatch: 7000, Loss: 0.3352, Error: 12.50%
Minibatch: 7500, Loss: 0.2004, Error: 10.94%
Minibatch: 8000, Loss: 0.2216, Error: 10.94%
Minibatch: 8500, Loss: 0.1420, Error: 4.69%
Minibatch: 9000, Loss: 0.1828, Error: 3.12%
Minibatch: 9500, Loss: 0.2406, Error: 10.94%
Minibatch: 10000, Loss: 0.1886, Error: 3.12%
... (省略)...
Minibatch: 40000, Loss: 0.0473, Error: 1.56%
Minibatch: 40500, Loss: 0.0216, Error: 1.56%
Minibatch: 41000, Loss: 0.1313, Error: 7.81%
Minibatch: 41500, Loss: 0.0752, Error: 4.69%
Minibatch: 42000, Loss: 0.0561, Error: 3.12%
Minibatch: 42500, Loss: 0.0110, Error: 0.00%
Minibatch: 43000, Loss: 0.0681, Error: 3.12%
Minibatch: 43500, Loss: 0.0537, Error: 1.56%
Minibatch: 44000, Loss: 0.0746, Error: 1.56%
Minibatch: 44500, Loss: 0.0319, Error: 1.56%
Minibatch: 45000, Loss: 0.0564, Error: 1.56%
Minibatch: 45500, Loss: 0.0223, Error: 0.00%
Minibatch: 46000, Loss: 0.0666, Error: 4.69%
Minibatch: 46500, Loss: 0.0286, Error: 3.12%
Training took 236.7 sec
Average test error: 9.77%
何とかテスト精度 90 % を確保できましたが、MNIST の結果と比較すると Fashion-MNIST の難易度が高いことが分かります :
-
MLP モデル : MNIST は 10 epochs で 1.76% の平均テストエラーでした。
Fashion-MNIST では 20 epochs で 10.77 % です。 -
CNN モデル : MNIST はフィルタ数 8, 16 そして 10 epochs の訓練で 0.90 % の平均テストエラーでした。
Fashion-MNIST ではフィルタ数 32, 64 そして 50 epochs の訓練で 9.77 % です。
精度を上げるためにはモデル自身の改良が必要ですが、画像サイズが小さいので意外に難しいです。いずれ機会があれば改良に挑戦して結果を報告します。
トレーニング中に保持しておいた plotdata を利用して、訓練の進捗をミニバッチ・ベースで可視化してみます :
plotdata["avgloss"] = moving_average(plotdata["loss"])
plotdata["avgerror"] = moving_average(plotdata["error"])
import matplotlib.pyplot as plt
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata["batchsize"], plotdata["avgloss"], 'b--')
plt.xlabel('Minibatch number')
plt.ylabel('Loss')
plt.title('Minibatch run vs. Training loss')
plt.show()
plt.subplot(212)
plt.plot(plotdata["batchsize"], plotdata["avgerror"], 'r--')
plt.xlabel('Minibatch number')
plt.ylabel('Label Prediction Error')
plt.title('Minibatch run vs. Label Prediction Error')
plt.show()
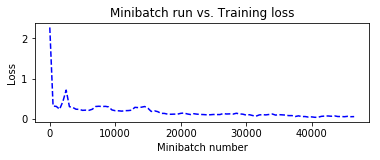
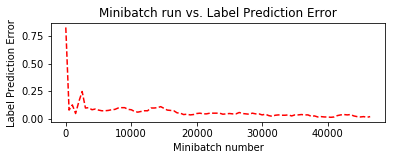
6. 深層オートエンコーダ
次に前回の記事で試した、深層オートエンコーダを実装して Fashion-MNIST で試してみます。
6-1 準備
目標は Fashion-MNIST 画像をより小さい次元のベクトルに圧縮してから画像を復元するようなオートエンコーダを訓練することです。
従来通りに必要なコンポーネントをインポートします。ここで Jupyter Notebook の新しいノートブックを作成して使用していきましょう :
from __future__ import print_function # Use a function definition from future version (say 3.x from 2.7 interpreter)
import matplotlib.pyplot as plt
import numpy as np
import os
import sys
# Import CNTK
import cntk as C
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env() # (only needed for our build system)
C.cntk_py.set_fixed_random_seed(1) # fix a random seed for CNTK components
%matplotlib inline
便宜上、2つの実行モードがあります :
- Fast モード: isFast を True に設定します。デフォルト・モードで、より少ない反復で訓練するか限定されたデータで訓練/テストすることを意味します。これは機能的な正当性という意味では確かなものですが、生成されたモデルは完全な訓練によって生成されたものからはかけ離れています。
- Slow モード: 実装に精通した後、異なるパラメータ等でより長い時間、訓練を実行することで洞察を得ることを望むのであれば、このフラグを False に設定してください。
isFast = False
# isFast = True
ここでは Slow モードで試した結果を示します。GPU 環境であれば Slow モードでもそれほど時間はかかりません。
※ Fast モードで試したい場合には、上の設定で isFast = True の設定を有効にしてください。
6-2 データ・リーディング
リーダー (= Reader) の作成
CTF deserializer を使用して訓練とテストデータを読むために create_reader 関数を定義します。
deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます :
# Read a CTF formatted text (as mentioned above) using the CTF deserializer from a file
def create_reader(path, is_training, input_dim, num_label_classes):
return C.io.MinibatchSource(C.io.CTFDeserializer(path, C.io.StreamDefs(
labels_viz = C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False),
features = C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)
)), randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)
訓練とテストデータファイルがダウンロード済みで、create_reader 関数で読み込むために利用可能であるかを確認します :
# Ensure the training and test data is generated and available for this tutorial.
# We search in two locations in the toolkit for the cached MNIST data set.
data_found = False
data_dir = os.path.join("data", "FASHION")
train_file = os.path.join(data_dir, "Train-28x28_cntk_text.fashion.txt")
test_file = os.path.join(data_dir, "Test-28x28_cntk_text.fashion.txt")
if os.path.isfile(train_file) and os.path.isfile(test_file):
data_found = True
if not data_found:
raise ValueError("Please generate the data by completing CNTK 103 Part A")
print("Data directory is {0}".format(data_dir))
Data directory is data/FASHION
6-3 モデル作成
Dense 層の積層を使用した、深層オートエンコーダを作成してみましょう。
(入力を 784 次元として、) エンコードする次元は 128, 64 そして 32 で、一方でデコードする次元は対照的に 64, 128 そして 784 と逆になります。このように変換をモデリングするために使用されるパラメータの数を増やすことで、より長い訓練期間を費やせばより低いエラー率を獲得することができます。
input_dim = 784
encoding_dims = [128,64,32]
decoding_dims = [64,128]
encoded_model = None
def create_deep_model(features):
with C.layers.default_options(init = C.layers.glorot_uniform()):
encode = C.element_times(C.constant(1.0/255.0), features)
for encoding_dim in encoding_dims:
encode = C.layers.Dense(encoding_dim, activation = C.relu)(encode)
global encoded_model
encoded_model= encode
decode = encode
for decoding_dim in decoding_dims:
decode = C.layers.Dense(decoding_dim, activation = C.relu)(decode)
decode = C.layers.Dense(input_dim, activation = C.sigmoid)(decode)
return decode
6-4 訓練と評価
ここでは、ある種のレシピとして使用できるように2つのコンポーネントを一つに結合したテンプレートを提示します。
train_and_test 関数は2つの主要なタスクを遂行します :
- モデルを訓練する。
- テストデータ上でモデルの精度を評価する。
特徴的な点として、訓練のために :
- この関数は入力としてリーダー (
reader_train) とモデル関数 (model_func) を取ります。 - Fast モードで 5 エポック、Slow モードで 100 エポックの訓練をします。
- Adam オプティマイザの変種 (
FSAdaGrad) を使用します。 - カスタム損失関数 (実体は交差エントロピー) : loss = -(target * C.log(model) + (1 - target) * C.log(1 - model)) をどのように作成して渡すかを示します。
- ラベルは入力 Fashion-MNIST 画像と同じです (オートエンコーダのためには input == label i.e. データストリームを input と label にマップします)。 モデルの内側で入力を 0-1 範囲にスケールしていますので、ラベルも同じ範囲に再スケールします。
-
C.classification_error関数を使用してラベル・エラーを計算するためにも label 変数の正規化が必要です。
テストのために :
- この関数は追加でリーダー (
reader_test) を取ります。 - そしてモデルにより予測されたピクセル値を参照データ、この場合は各画像に対する元のピクセル値に対して評価します。
def train_and_test(reader_train, reader_test, model_func):
###############################################
# モデルを訓練する
###############################################
# 入力とラベル変数をインスタンス化します。
input = C.input_variable(input_dim)
label = C.input_variable(input_dim)
# モデル関数を作成します。
model = model_func(input)
# このネットワークのためのラベルは入力 MNIST 画像と同じです。
# Note: モデルの内側で入力を 0-1 範囲にスケールしています。
# それ故にラベルも同じ範囲に再スケールします。
# カスタム損失関数をどのように使用するかを示します。
# loss = -(y* log(p)+ (1-y) * log(1-p)) ここで p = モデル出力 そして y = target
# 入力を 0-1 の範囲に正規化しました。よって target も同じ範囲にスケールします。
target = label/255.0
loss = -(target * C.log(model) + (1 - target) * C.log(1 - model))
label_error = C.classification_error(model, target)
# 訓練 config
epoch_size = 30000 # 30000 samples is half the dataset size
minibatch_size = 64
num_sweeps_to_train_with = 5 if isFast else 100
num_samples_per_sweep = 60000
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) // minibatch_size
# モデル訓練を駆動するために trainer オブジェクトをインスタンス化します。
lr_per_sample = [0.00003]
lr_schedule = C.learning_rate_schedule(lr_per_sample, C.UnitType.sample, epoch_size)
# Momentum
momentum_as_time_constant = C.momentum_as_time_constant_schedule(700)
# このデータセットで上手く動作することが知られている、Adam オプティマイザの変種を使用します。
learner = C.fsadagrad(model.parameters,
lr=lr_schedule, momentum=momentum_as_time_constant)
# trainer をインスタンス化します
progress_printer = C.logging.ProgressPrinter(0)
trainer = C.Trainer(model, (loss, label_error), learner, progress_printer)
# Map the data streams to the input and labels.
# Note: for autoencoders input == label
input_map = {
input : reader_train.streams.features,
label : reader_train.streams.features
}
aggregate_metric = 0
for i in range(num_minibatches_to_train):
# 訓練データファイルからミニバッチを読みます。
data = reader_train.next_minibatch(minibatch_size, input_map = input_map)
# trainer を実行してモデル訓練を遂行します。
trainer.train_minibatch(data)
samples = trainer.previous_minibatch_sample_count
aggregate_metric += trainer.previous_minibatch_evaluation_average * samples
train_error = (aggregate_metric*100.0) / (trainer.total_number_of_samples_seen)
print("Average training error: {0:0.2f}%".format(train_error))
#############################################################################
# モデルをテストします
# Note: 訓練データとは異なるデータを読むためにテストファイル・リーダーを使用します。
#############################################################################
# 訓練されたモデルのためのテストデータ
test_minibatch_size = 32
num_samples = 10000
num_minibatches_to_test = num_samples / test_minibatch_size
test_result = 0.0
# Test error metric calculation
metric_numer = 0
metric_denom = 0
test_input_map = {
input : reader_test.streams.features,
label : reader_test.streams.features
}
for i in range(0, int(num_minibatches_to_test)):
# test_minibatch_size で指定されたバッチとしてテストデータをロードします
# ミニバッチの各データポイントは 1 次元 1 ピクセルの 784 次元の MNIST 数字画像です。
# 訓練されたモデルで enocode/decode します。
data = reader_test.next_minibatch(test_minibatch_size,
input_map = test_input_map)
eval_error = trainer.test_minibatch(data)
metric_numer += np.abs(eval_error * test_minibatch_size)
metric_denom += test_minibatch_size
# 総てのテスト・ミニバッチの評価エラーの平均
test_error = (metric_numer*100.0) / (metric_denom)
print("Average test error: {0:0.2f}%".format(test_error))
return model, train_error, test_error
深層オートエンコーダの訓練/評価を実行しましょう。訓練/テスト・リーダーを作成して渡します :
num_label_classes = 10
reader_train = create_reader(train_file, True, input_dim, num_label_classes)
reader_test = create_reader(test_file, False, input_dim, num_label_classes)
model, deep_ae_train_error, deep_ae_test_error = train_and_test(reader_train,
reader_test,
model_func = create_deep_model)
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per 1 samples: 3e-05
544 544 0.456 0.456 64
544 544 0.452 0.45 192
544 544 0.444 0.438 448
543 542 0.433 0.424 960
535 528 0.416 0.4 1984
486 437 0.405 0.393 4032
421 358 0.388 0.371 8128
361 300 0.363 0.338 16320
319 277 0.337 0.312 32704
285 251 0.303 0.268 65472
263 242 0.278 0.253 131008
249 234 0.26 0.241 262080
239 229 0.244 0.227 524224
231 223 0.224 0.204 1048512
225 218 0.205 0.186 2097088
220 215 0.189 0.173 4194240
Average training error: 18.17%
Average test error: 16.34%
ちなみに MNIST では平均訓練エラーが 2.07% で、テストエラーが 1.25% でした。
比較するとかなり悪いですが、ここではこのまま進めます。
6-5 結果の可視化
デコードされた画像を元画像と比較することで視覚的に評価できます。
画像を無作為に選択して、まずはスタッツを表示してみます :
# 評価を実行するために幾つかデータを読みます。
num_label_classes = 10
reader_eval = create_reader(test_file, False, input_dim, num_label_classes)
eval_minibatch_size = 50
eval_input_map = { input : reader_eval.streams.features }
eval_data = reader_eval.next_minibatch(eval_minibatch_size,
input_map = eval_input_map)
img_data = eval_data[input].asarray()
# 画像を無作為に選択します。
np.random.seed(0)
idx = np.random.choice(eval_minibatch_size)
idx2 = np.random.choice(eval_minibatch_size)
idx3 = np.random.choice(eval_minibatch_size)
idx4 = np.random.choice(eval_minibatch_size)
print(idx, idx2, idx3, idx4)
orig_image = img_data[idx,:,:]
decoded_image = model.eval(orig_image)[0]*255
orig_image2 = img_data[idx2,:,:]
decoded_image2 = model.eval(orig_image2)[0]*255
orig_image3 = img_data[idx3,:,:]
decoded_image3 = model.eval(orig_image3)[0]*255
orig_image4 = img_data[idx4,:,:]
decoded_image4 = model.eval(orig_image4)[0]*255
# 画像のスタッツを出力表示します。
def print_image_stats(img, text):
print(text)
print("Max: {0:.2f}, Median: {1:.2f}, Mean: {2:.2f}, Min: {3:.2f}".format(np.max(img),
np.median(img),
np.mean(img),
np.min(img)))
# 元画像の情報を出力します。
print_image_stats(orig_image, "Original image statistics:")
# デコードされた画像の情報を出力します。
print_image_stats(decoded_image, "Decoded image statistics:")
print_image_stats(orig_image2, "Original image statistics:")
print_image_stats(decoded_image2, "Decoded image statistics:")
print_image_stats(orig_image3, "Original image statistics:")
print_image_stats(decoded_image3, "Decoded image statistics:")
print_image_stats(orig_image4, "Original image statistics:")
print_image_stats(decoded_image4, "Decoded image statistics:")
44 47 0 3
Original image statistics:
Max: 255.00, Median: 179.50, Mean: 120.63, Min: 0.00
Decoded image statistics:
Max: 236.74, Median: 181.32, Mean: 119.00, Min: 0.00
Original image statistics:
Max: 255.00, Median: 0.00, Mean: 64.14, Min: 0.00
Decoded image statistics:
Max: 248.74, Median: 0.00, Mean: 62.51, Min: 0.00
Original image statistics:
Max: 255.00, Median: 0.00, Mean: 42.67, Min: 0.00
Decoded image statistics:
Max: 231.01, Median: 0.01, Mean: 44.06, Min: 0.00
Original image statistics:
Max: 255.00, Median: 0.00, Mean: 45.12, Min: 0.00
Decoded image statistics:
Max: 238.19, Median: 0.00, Mean: 43.79, Min: 0.00
スタッツは、最大値、中央値、平均値、最小値です。最大値が意外にずれています。
次に元画像とデコードされた画像をプロットしましょう。それらは視覚的に類似しているはずです :
# 画像のペアをプロットするためのヘルパー関数を定義します。
def plot_image_pair(img1, text1, img2, text2):
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(6, 6))
axes[0].imshow(img1, cmap="gray")
axes[0].set_title(text1)
axes[0].axis("off")
axes[1].imshow(img2, cmap="gray")
axes[1].set_title(text2)
axes[1].axis("off")
# Plot the original and the decoded image
img1 = orig_image.reshape(28,28)
text1 = 'Original image'
img2 = decoded_image.reshape(28,28)
text2 = 'Decoded image'
#
img1_2 = orig_image2.reshape(28,28)
img2_2 = decoded_image2.reshape(28,28)
img1_3 = orig_image3.reshape(28,28)
img2_3 = decoded_image3.reshape(28,28)
img1_4 = orig_image4.reshape(28,28)
img2_4 = decoded_image4.reshape(28,28)
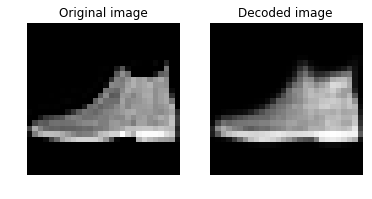
plot_image_pair(img1, text1, img2, text2)
plot_image_pair(img1_2, text1, img2_2, text2)
plot_image_pair(img1_3, text1, img2_3, text2)
plot_image_pair(img1_4, text1, img2_4, text2)
視覚的にはだいたい復元されていて、許容範囲でしょうか。
7. What's Next
CNTK 2.2 Python API をマスターするためには CNTK 2.2 Tutorials が最適ですが、今回までの記事で以下のチュートリアル 9 編をカバーしたことになります :
- CNTK 101: Logistic Regression and ML Primer
- CNTK 102: Feed Forward Network with Simulated Data
- CNTK 103: Part A - MNIST Data Loader
- CNTK 103: Part B - Logistic Regression with MNIST
- CNTK 103: Part C - Multi Layer Perceptron with MNIST
- CNTK 103: Part D - Convolutional Neural Network with MNIST
- CNTK 105: Basic autoencoder (AE) with MNIST data
- CNTK 106: Part A - Time series prediction with LSTM (Basics)
- CNTK 106: Part B - Time series prediction with LSTM (IOT Data)
また併せて以下のリソースもカバーしています :
従って、残りの初級チュートリアル 104 に取り組んでも良いのですが、これは pandas の説明が中心ですので、より上位の 200 番台に取り組むのがお勧めです。
以上