CNTK 2.2 Python API 入門 (3) - MNIST 総集編 (CTF / 多項 LR, MLP & CNN)
0. はじめに
◆ CNTK ( Microsoft Cognitive Toolkit ) 2.2 の Python API 入門第3弾です。
今回は MNIST 総集編として、CNTK CTF フォーマットでセーブした MNIST データセットを題材にして
3種類のモデルを CNTK Python API で実装して多クラス分類問題を解いてみます。
前回までの記事 (CNTK 2.2 Python API 入門 (1), (2)) で CNTK 2.2 について次のような点がお分かり頂けたかと思います :
- Python API が公開されていて、他の深層学習フレームワークと同様に Python プログラムで深層学習モデルが構築できます。
- 層ライブラリのような、深層学習フレームワークでお馴染みのビルディング・ブロックも多数用意されています。
- ネットワーク定義は Python 関数オブジェクトとして実装され、For ループや lambda 記法も利用できる Python ライクな記法で簡潔に定義可能です。
- Trainer クラスでカプセル化したトレーニングの実装も分かりやすく簡潔です。
引き続き、CNTK 2.2 Tutorials への橋渡しとなるような CNTK 2.2 Python API の入門記事を作成していきます。
※ Python と機械学習の基本的な知識を持つ読者を想定しています。
※ 他の深層学習フレームワークの経験があれば問題なく読み通せます。

今回の題材は定番の MNIST データセットですが、CTF (CNTK Text-Format) フォーマットで扱う点が特徴的です。
そして CNTK で実装するモデルは多項ロジスティック回帰, 多層パーセプトロン (MLP), そして畳み込みネットワーク (CNN) の3種類になります。
チュートリアルのプログラムを参考にしながら、分かりやすい構成にして平易な言葉で説明することを心がけました。
入門という位置づけですので基礎理論にも言及はしますがそれは要点のみにとどめて、
CNTK Python API の説明を重視してプログラマ視点から実践的な内容にしています。
※ 初出の API にはリファレンス・マニュアルへリンクを張り、また今回までに記事で扱った CNTK Python API はまとめてあります。
※ GPU メモリの消費量にも注意を払いました。
内容は :
- 動作環境と Jupyter Notebook について
- MNIST データセットを CNTK CTF フォーマットでセーブする
- 本記事で使用する CNTK Python API
- 多項ロジスティック回帰で MNIST を分類
- 多層パーセプトロンで MNIST を分類
- 畳み込みネットワークで MNIST を分類
- What's Next
本記事は以下のチュートリアルを参考にしています :
- CNTK 103: Part A - MNIST Data Loader
- CNTK 103: Part B - Logistic Regression with MNIST
- CNTK 103: Part C - Multi Layer Perceptron with MNIST
- CNTK 103: Part D - Convolutional Neural Network with MNIST
1. 動作環境と Jupyter Notebook について
動作環境
動作環境の構築が必要な場合には、Cognitive Toolkit 2.2 を Azure Linux GPU 仮想マシンにインストール を参考にしてください。Azure ポータルと Ubuntu Linux にある程度慣れていれば、30 分程度で以下のような環境が構築できるかと思います :
- Azure NC 仮想マシン with NVIDIA Tesla® K80 GPU
- Ubuntu 16.04 LTS
- NVIDIA CUDA 8.0 & cuDNN 6.0
- Anaconda 3 4.1.1
- CNTK 2.2 (for GPU)
Jupyter Notebook
また、本記事でも CNTK チュートリアルでも Jupyter Notebook を多用します。
Jupyter Notebook の利用方法については前回の記事中の Jupyter Notebook の活用 を参照してください。
2. MNIST データセットを CNTK CTF フォーマットでセーブする
◆ MNIST データセット は説明するまでもなく、機械学習アルゴリズムの訓練とテストのために広く使われています。
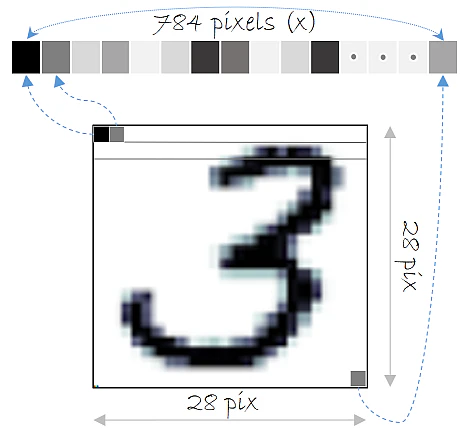
28 x 28 ピクセルのグレースケールな手書き数字画像を含み、60,000 画像の訓練セットと 10,000 画像のテストセットから構成されます。
この章では、4 章以降で利用するために、MNIST の前処理を行ないます。
特徴的な点は、MNIST データセットをダウンロードした後、CNTK テキスト・リーダで読み込めるフォーマット「CTF フォーマット」でセーブ することです。CTF は CNTK Text-Format を意味します。
4 章以降のどのモデルもこの CTF フォーマットから MNIST データセットを読み込みますので、少し詳しく見ていきましょう。
インポート
最初に必要なコンポーネントをインポートします。この章では CNTK 関連モジュールは使用しません :
from __future__ import print_function
import gzip
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import os
import shutil
import struct
import sys
try:
from urllib.request import urlretrieve
except ImportError:
from urllib import urlretrieve
%matplotlib inline
MNIST データセットのダウンロード
次に MNIST データセットをダウンロードして numpy で読み込むためのユティリティ関数を定義します :
def loadData(src, cimg):
print ('Downloading ' + src)
gzfname, h = urlretrieve(src, './delete.me')
print ('Done.')
try:
with gzip.open(gzfname) as gz:
n = struct.unpack('I', gz.read(4))
if n[0] != 0x3080000:
raise Exception('Invalid file: unexpected magic number.')
n = struct.unpack('>I', gz.read(4))[0]
if n != cimg:
raise Exception('Invalid file: expected {0} entries.'.format(cimg))
crow = struct.unpack('>I', gz.read(4))[0]
ccol = struct.unpack('>I', gz.read(4))[0]
if crow != 28 or ccol != 28:
raise Exception('Invalid file: expected 28 rows/cols per image.')
res = np.fromstring(gz.read(cimg * crow * ccol), dtype = np.uint8)
finally:
os.remove(gzfname)
return res.reshape((cimg, crow * ccol))
def loadLabels(src, cimg):
print ('Downloading ' + src)
gzfname, h = urlretrieve(src, './delete.me')
print ('Done.')
try:
with gzip.open(gzfname) as gz:
n = struct.unpack('I', gz.read(4))
if n[0] != 0x1080000:
raise Exception('Invalid file: unexpected magic number.')
n = struct.unpack('>I', gz.read(4))
if n[0] != cimg:
raise Exception('Invalid file: expected {0} rows.'.format(cimg))
res = np.fromstring(gz.read(cimg), dtype = np.uint8)
finally:
os.remove(gzfname)
return res.reshape((cimg, 1))
def try_download(dataSrc, labelsSrc, cimg):
data = loadData(dataSrc, cimg)
labels = loadLabels(labelsSrc, cimg)
return np.hstack((data, labels))
実装は標準的ですが、loadData 関数について簡単に説明しておきますと :
- 画像データをダウンロードして解凍します。
- ヘッダの (データセットの種類を表わす) マジック・ナンバー、要素数、行数、カラム数を確認します。
-
numpy.fromstringで ndarray に読み込んで、shape (60000, 784) に reshape して返します (784 = 28*28)。
loadLabel 関数もラベルについて同様の処理を行ないます。
そして try_download は loadData と loadLabel 関数がそれぞれ返した ndarray を numpy.hstack で水平に連結します。
つまり、1つの (平坦化された) 画像データと1つのラベルデータが連結されて1つの行に保持されます。
◆ さて、実際にダウンロードを実行しましょう :
url_train_image = 'http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz'
url_train_labels = 'http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz'
num_train_samples = 60000
print("Downloading train data")
train = try_download(url_train_image, url_train_labels, num_train_samples)
url_test_image = 'http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz'
url_test_labels = 'http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz'
num_test_samples = 10000
print("Downloading test data")
test = try_download(url_test_image, url_test_labels, num_test_samples)
Downloading train data
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Done.
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Done.
Downloading test data
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Done.
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Done.
インメモリで展開され、この時点で、train 変数が訓練データを保持し、test 変数がテストデータを保持 していることに注意してください。
データを可視化する
train 変数が訓練データを保持していますので、サンプルとして、インデックス 5001 の訓練データを可視化してみましょう。
train[sample_number, :-1] で :-1 により最後のバイト (正確には np.uint8) を除外しているのは、最後のバイトはラベルデータであるためです :
sample_number = 5001
plt.imshow(train[sample_number,:-1].reshape(28,28), cmap="gray_r")
plt.axis('off')
print("Image Label: ", train[sample_number,-1])
Image Label: 3
CTF フォーマットのテキストファイルとしてセーブする
ndarray (n-次元配列) に展開された画像とラベルデータは .npy, .npz あるいは .pickle ファイルにセーブされることが多いですが、ここでは CNTK テキスト・リーダーと互換性のある CTF フォーマットにセーブします。
そのようなセーブを行なう savetxt 関数を定義します :
def savetxt(filename, ndarray):
dir = os.path.dirname(filename)
if not os.path.exists(dir):
os.makedirs(dir)
if not os.path.isfile(filename):
print("Saving", filename )
with open(filename, 'w') as f:
labels = list(map(' '.join, np.eye(10, dtype=np.uint).astype(str)))
for row in ndarray:
row_str = row.astype(str)
label_str = labels[row[-1]]
feature_str = ' '.join(row_str[:-1])
f.write('|labels {} |features {}\n'.format(label_str, feature_str))
else:
print("File already exists", filename)
ラベルデータは one-hot ベクトルに変換されることに注意しましょう。
np.eye(10, dtype=np.uint).astype(str) の挙動が分かれば理解しやすいと思います :
>>> np.eye(10, dtype=np.uint).astype(str)
array([['1', '0', '0', '0', '0', '0', '0', '0', '0', '0'],
['0', '1', '0', '0', '0', '0', '0', '0', '0', '0'],
['0', '0', '1', '0', '0', '0', '0', '0', '0', '0'],
['0', '0', '0', '1', '0', '0', '0', '0', '0', '0'],
['0', '0', '0', '0', '1', '0', '0', '0', '0', '0'],
['0', '0', '0', '0', '0', '1', '0', '0', '0', '0'],
['0', '0', '0', '0', '0', '0', '1', '0', '0', '0'],
['0', '0', '0', '0', '0', '0', '0', '1', '0', '0'],
['0', '0', '0', '0', '0', '0', '0', '0', '1', '0'],
['0', '0', '0', '0', '0', '0', '0', '0', '0', '1']],
dtype='<U20')
セーブを実行します :
data_dir = os.path.join(".", "data", "MNIST")
print ('Writing train text file...')
savetxt(os.path.join(data_dir, "Train-28x28_cntk_text.txt"), train)
print ('Writing test text file...')
savetxt(os.path.join(data_dir, "Test-28x28_cntk_text.txt"), test)
print('Done')
Writing train text file...
Saving ./data/MNIST/Train-28x28_cntk_text.txt
Writing test text file...
Saving ./data/MNIST/Test-28x28_cntk_text.txt
Done
Jupyter Notebook を実行しているディレクトリ下に、
./data/MNIST/Train-28x28_cntk_text.txt 及び Test-28x28_cntk_text.txt としてセーブされます。
※ ここでは保存先として "./data/MNIST" ディレクトリを指定しています。
変更したい場合は data_dir 変数の設定を変えれば良いですが、4 章以降でも "./data/MNIST" を読み込み先としていますのでご注意ください。
データフォーマットについて補記
セーブされたファイルのフォーマットについて、幾つか補足しておきます :
(1) 画像はベクトルに平坦化されます、つまり 28x28 ピクセル画像が 784 長のデータポイントの配列になります。
これは loadData 関数の res.reshape((cimg, crow * ccol)) で設定しています。
(2) ラベルは 1-hot ベクトルにエンコードされます (例えば、数字 3 の画像のラベルは 0001000000 になります、最初のインデックスは数字の 0 に相当し、最後の一つは数字の 9 に相当します。) :

ファイルの内容を確認する
上の (1) (2) を念頭に置いて、セーブされたファイルの内容を実際に確認してみましょう。テキストなので直接確認できます :
$ ls -l
合計 127336
-rw-rw-r-- 1 masao masao 18649443 10月 2 17:15 Test-28x28_cntk_text.txt
-rw-rw-r-- 1 masao masao 111735994 10月 2 17:15 Train-28x28_cntk_text.txt
# ファイルの行数を確認します。
$ wc -l *
10000 Test-28x28_cntk_text.txt
60000 Train-28x28_cntk_text.txt
70000 合計
# 可視化した、インデックス 5001 のサンプルを確認します。nl はファイルの各行にナンバリングします。
$ nl -v 0 -w 8 Train-28x28_cntk_text.txt | egrep "^\s+5001\s"
5001 |labels 0 0 0 1 0 0 0 0 0 0 |features 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 31 132 254 253 254 213 82 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 21 142 233 252 253 252 253 252 223 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 123 254 253 254 253 224 203 203 223 255 213 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 203 253 252 253 212 20 0 0 61 253 252 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 41 243 224 203 183 41 152 30 0 0 255 253 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 40 20 0 0 102 253 50 0 82 253 252 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 82 214 31 113 233 254 233 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 62 102 82 41 253 232 253 252 233 50 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 152 253 254 253 254 253 254 233 123 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 152 252 253 252 253 252 192 50 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 62 183 203 243 254 253 62 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 40 172 252 203 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 21 0 0 0 0 0 0 0 0 0 183 254 112 0 0 0 0 0 0 0 0 0 0 0 0 0 0 62 203 163 0 0 0 0 0 0 0 0 61 253 151 0 0 0 0 0 0 0 0 0 0 0 0 0 21 214 192 0 0 0 0 0 0 0 0 11 213 254 151 0 0 0 0 0 0 0 0 0 0 0 0 0 102 253 151 0 0 0 0 0 0 0 41 213 252 253 111 0 0 0 0 0 0 0 0 0 0 0 0 0 41 255 213 92 51 0 0 31 92 173 253 254 253 142 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 172 252 253 252 203 203 233 252 253 252 253 130 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 21 203 255 253 254 253 254 253 244 203 82 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 20 151 151 253 171 151 151 40 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ファイル Train-28x28_cntk_text.txt, Test-28x28_cntk_text.txt はそれぞれ 60,000 行, 10,000 行で構成されています。
これは訓練データセットとテストデータセットのサンプル数に相当します。つまり、データサンプル一つが 1 行で構成されています。
データサンプル1つに相当する各行は |labels 0 0 0 1 0 0 0 0 0 0 |features 0 0 0 ... 31 132 254 ... 0 0 0 のように表現されています (savetxt 関数で f.write('|labels {} |features {}\n'.format(label_str, feature_str)) のように出力されています)。
3. 本記事で使用する CNTK Python API
今回使用する CNTK Python API を先にリストアップしておきます。
前回までに使用した API に本記事で初出の API を追加してまとめました。
今回は層関連の API: Convolution2D / MaxPooling と I/O 関連の API が追加されています。
cntk.io パッケージ
| API | 説明 |
|---|---|
CTFDeserializer |
組み込みの deserializer(*) で、CTF (CNTK Text Format) リーダーを構成します。 |
MinibatchSource |
CNTK の Python API 用リーダーです。 |
StreamDef |
deserializer を使用するためにストリームを構成します。 |
StreamDefs |
キーワード引数からレコードを構築します。API というよりも (Python の) 辞書のような働きをします。 |
※ deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
cntk.layers パッケージ
cntk.layers.layers モジュール
| API | 説明 |
|---|---|
Convolution2D |
2D 畳み込み層を作成する層ファクトリ関数です。 |
Dense |
完全結合線形層のインスタンスを作成するための層ファクトリ関数です。 |
MaxPooling |
マックス・プーリング層を作成するための層ファクトリ関数です。 |
cntk.learners パッケージ
| API | 説明 |
|---|---|
learning_rate_schedule |
学習率スケジュールを作成します。 |
adam |
モデル・パラメータを学習するために Adam learner インスタンスを作成します。 |
sgd |
モデル・パラメータを学習するために SGD learner インスタンスを作成します。 |
cntk.losses パッケージ
| API | 説明 |
|---|---|
cross_entropy_with_softmax(output_vector, target_vector) |
target_vector と output_vector の softmax 間の交差エントロピーを計算します。 |
cntk.metrics パッケージ
| API | 説明 |
|---|---|
classification_error(output_vector, target_vector) |
分類エラーを計算します。 |
cntk.ops パッケージ
| API | 説明 |
|---|---|
input_variable |
ネットワークの入力を作成します : 特徴やラベルのようなデータが供給される場所で、いわゆるプレースホルダーです。 |
parameter |
パラメータ・テンソルを作成します。 |
relu |
ReLU 活性化関数です。 |
sigmoid |
sigmoid 活性化関数です。 |
softmax |
softmax 活性化関数です。 |
times |
乗算ですが、この演算の出力は2つの入力行列の積 (= matrix product) です。ブロードキャストをサポートします。 |
cntk.tests.test_utils パッケージ
| API | 説明 |
|---|---|
set_device_from_pytest_env() |
Jupyter Notebook 利用時に正しいターゲット・デバイスを選択するためのヘルパー関数です。総ての Jupyter Notebook の開始時にこれを呼び出す必要があります。 |
cntk.train パッケージ
cntk.train.trainer モジュール
| API | 説明 |
|---|---|
Trainer |
モデル・パラメータをトレーニングするクラス。 |
4. 多項ロジスティック回帰で MNIST を分類
この章から先は下の例のような MNIST データを3つのモデルで多クラス分類していきます。
この章では多項ロジスティック回帰モデルを CNTK Python API で構築して訓練、評価します。
Jupyter Notebook の新しいノートブックを作成して使用しましょう。
from IPython.display import Image
Image(url= "http://3.bp.blogspot.com/_UpN7DfJA0j4/TJtUBWPk0SI/AAAAAAAAABY/oWPMtmqJn3k/s1600/mnist_originals.png", width=240, height=240)

4-1 多項ロジスティック回帰
ロジスティック回帰は、特徴の線形の重み付けられた組み合わせを使用して、確率に基づいて異なるクラスの予測を生成する基本的な機械学習テクニックです。ロジスティック回帰については前回の記事 ( CNTK 2.2 Python API 入門 (2) ) で既に説明していますが、ここでは二項/多項ロジスティック回帰という切り口で改めて簡単に説明しておきます。
ロジスティック回帰には2つの基本的な形式があります:
- 二項ロジスティック回帰 : 2つのクラスを予測できる単一の出力を持ちます。
- 多項ロジスティック回帰 : 複数の出力を持ち、その各々は単一のクラスを予測するために使用されます。

二項ロジスティック回帰 は上図の上側 "Binary LR" で図示されます。
入力特徴はそれぞれが線形に重み付けられて一緒に集計されます。
この総和は sigmoid のようなスカッシング (押し込み) 関数 (活性化関数として使用されます) を通して [0, 1] 内の出力を生成します。そしてこの出力値は (0.5 のような) しきい値と比較されて二値ラベル (0 または 1) を生成します。
この方法は2つの出力クラスの分類問題だけをサポートしますので、二値ロジスティック回帰と呼称されます。
多項ロジスティック回帰 は上図の下側 "Multiclass LR" で図示されます。(通常は多項ロジスティック回帰は "multinomial Logistic Regrresion" と表記されます。)
2 またはそれ以上の出力ノードが使用され、一つ一つが予測される各々の出力クラスのために使用されます。
各総和ノードは入力特徴を自身の重みセットでスケールしてそれらを一緒に集計します。
重み付けられた特徴の総和出力を sigmoid スカッシング関数を通す代わりに、しばしば出力は softmax 関数を通して渡されます。softmax は sigmoid のようなスカッシング (押し込み) の機能に加えて、全ての正規化されていないノードの総和を利用して、各総和ノードの出力値を正規化します。
本章では、MNIST の手書き数字 (0-9) を分類するために、出力クラスの各々のために一つ、合計 10 出力ノードを使用して多項ロジスティック回帰を適用します。
4-2 インポート
最初に必要なコンポーネントをインポートします。既にお馴染みのものでしょう :
from __future__ import print_function
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import sys
import os
import cntk as C
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env()
C.cntk_py.set_fixed_random_seed(1)
%matplotlib inline
※ cntk.tests.test_utils サブパッケージの set_device_from_pytest_env は Jupyter Notebook でターゲット・デバイスを正しく選択するためのユティリティ関数です。
4-3 データ・リーディング
2 章で CNTK CTF フォーマットでテキストファイルにセーブしておいた MNIST データを読み込んで利用します。
入力次元
入力次元と出力クラス数を定義します。784 = 28 x 28 は平坦化された画像の次元です :
input_dim = 784
num_output_classes = 10
データ・フォーマット
CTF (CNTK Text-Format) フォーマットは単純なテキストフォーマット仕様です。
各行が各サンプルに相当し、各サンプルは名前フィールドとそれらのデータの組み合わせのセットを含み、そのサンプルのセットを収めています。
MNIST データは 2 章によりこの CTF フォーマットでストアされていて、各サンプルは2つのフィールドを含んでいます : labels と features です。
そしてそのフォーマットは次のようなものです :
|labels 0 0 0 1 0 0 0 0 0 0 |features 0 0 0 0 ...
(各々がピクセルを表現する 784 整数)
特徴ベクトルに相当するのは、features という名前の整数ストリームです。各整数がピクセルに対応しています。
ラベルは one-hot にエンコードされています。
◆ さて、訓練/テストデータを読むための create_reader 関数を作成します。
cntk.io.CTFDeserializer を使用すれば CTF フォーマットのテキストを読むことができます。
deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
def create_reader(path, is_training, input_dim, num_label_classes):
labelStream = C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False)
featureStream = C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)
deserailizer = C.io.CTFDeserializer(path, C.io.StreamDefs(labels = labelStream, features = featureStream))
return C.io.MinibatchSource(deserailizer,
randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)
初出の CNTK Python API が多いのでまとめておきますと :
-
cntk.io.StreamDefは deserializer を使用するためにストリームを構成します。 -
cntk.io.StreamDefsはキーワード引数からレコードを構築します。API というよりも (Python の) 辞書のような働きをします。 -
cntk.io.CTFDeserializerは組み込みの deserializer で、CTF リーダーを構成します。 -
cntk.io.MinibatchSourceは CNTK の Python API 用リーダーです。
2 章で作成した、訓練とテストデータが利用可能であることを確認しておきましょう :
data_dir = os.path.join(".", "data", "MNIST")
train_file = os.path.join(data_dir, "Train-28x28_cntk_text.txt")
test_file = os.path.join(data_dir, "Test-28x28_cntk_text.txt")
if not (os.path.isfile(train_file) and os.path.isfile(test_file)):
raise ValueError("Please generate the data by completing CNTK 103 Part A")
print("Data directory is {0}".format(data_dir))
Data directory is ./data/MNIST
4-4 モデル作成
下図は、多項ロジスティック回帰モデルを MNIST データのコンテキストで要約しています :

ロジスティック回帰は単純な線形モデルで、入力として分類する対象の特性を表現する数値のベクトル (特徴ベクトル, $\bf \vec{x}$) を取り、エビデンス (証拠・根拠) ($z$) を出力します。
今回の例では、特徴ベクトルは MNIST 手書き数字画像のピクセル・セットです。10 種類の手書き数字の各々に対して、図で示されているように、入力ピクセルに対応した重みベクトルがあります。これらの 10 個の重みベクトルは次元 10 x 784 を持つ重み行列 ($\bf {W}$) を定義します。入力層の各特徴は対応する重み $w$ ($\bf{W}$ 行列からの個々の重み値) により総和ノードへと接続されます。分類される各数字に対して1つずつそのようなノードが 10 個あります。
◆ 最初のステップは一つの観測データポイントに対してエビデンスを計算することです。
$$\vec{z} = \textbf{W} \bf \vec{x}^T + \vec{b}$$
ここで $\bf{W}$ は次元 10 x 784 の重み行列で、$\vec{b}$ は (各数字に一つの数値) 長さ 10 のバイアス・ベクトルです。
ここではエビデンス ($\vec{z}$) は、sigmoid のようなスカッシング関数 (押し込み関数) でスカッシュしません (スカッシュはエビデンスをある値域に押し込めるくらいのニュアンスです)。代わりにエビデンス出力は softmax 関数を使用して正規化され、その結果総ての出力の合計は 1 の値となりますので、予測に確率的な解釈が適用できます。
CNTK では交差エントロピー関数と結合した softmax 演算を使用します。
4-5 ネットワーク構築
4-5-1 ネットワーク入力
(既に前回の記事で何度も説明していますが、念のため、) 最初に CNTK のプレースホルダーについて説明しておきます :
input = C.input_variable(input_dim)
label = C.input_variable(num_output_classes)
入力変数 input_variable() は CNTK の主要なコンセプトの一つです。
データが供給されるコンテナあるいはプレースホルダーで、モデルの訓練/評価中に、ユーザ・コードがこのコンテナをモデル関数オブジェクトへの入力となるデータポイント (今回の例では画像ピクセルを持つデータポイント) で満たしていきます。
入力の shape は提供されるデータの shape にマッチしていなければなりません。
4-5-2 ネットワーク定義
CNTK 層モジュールは Dense 関数を提供します。
これは完全結合層を作成し、"4-4 モデル作成" の節で説明した、重み付けられた総和とバイアス加算の演算を遂行します。
def create_model(features):
with C.layers.default_options(init = C.glorot_uniform()):
r = C.layers.Dense(num_output_classes, activation = None)(features)
return r
z はネットワーク出力を表わすために使用されます。
ここでは、入力を 255.0 で除算して (各ピクセルを [0, 1] の範囲に) 正規化していることに注意してください :
z = create_model(input/255.0)
※ 実はこの時点で GPU 上での計算が発生しています :
Selected GPU[0] Tesla K80 as the process wide default device.
$ nvidia-smi
Sat Oct 7 02:04:20 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.66 Driver Version: 384.66 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 000025C4:00:00.0 Off | Off |
| N/A 74C P0 65W / 149W | 78MiB / 12205MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 14079 C /home/masao/anaconda3/bin/python 67MiB |
+-----------------------------------------------------------------------------+
4-6 トレーニング
4-6-1 モデル・パラメータの学習
蓄積されたエビデンスをクラスに渡る確率分布にマップするために softmax 関数を使用します。
そしてラベルとこのネットワークにより予測される確率の間の交差エントロピーを最小化することがモデル・パラメータの学習のプロセスです。交差エントロピーは簡単に言えば、確率分布に直されたネットワーク出力と正解ラベルの差異をエントロピーという乱雑さを表わす尺度を利用して計算します。
CNTK では cntk.losses.cross_entropy_with_softmax という便利な関数が用意されています。
cross_entropy_with_softmax(z, label) は正解ラベル label と、ネットワーク出力 z の softmax 間の交差エントロピーを計算してくれます :
loss = C.cross_entropy_with_softmax(z, label)
4-6-2 評価
分類を評価するために、ネットワーク出力をラベルと比較することもできます。
これは、各観測データポイントのためにクラス数と同じ次元でエビデンスのベクトルを出力します (そして softmax 関数を使用して確率に変換することもできます)。
cntk.metrics.classification_error を利用すれば分類エラーを計算できます。これは (エラーを計算するのが目的ですから) モデルが正しい場合 - つまり真のラベルに多くの確率を割り当てた場合には 0、そうでない場合には 1 になります :
label_error = C.classification_error(z, label)
4-6-3 trainer を構成する
モデル・パラメータのトレーニングを駆動する cntk.train.Trainer クラスのインスタンスである trainer は最適化テクニックで loss 関数を最小化していきます。ここでは、基本的な確率的勾配降下 (SGD, Stochastic Gradient Descent, cntk.learners.sgd ) を使用します。
trainer を作成する準備が整いましたので、Trainer クラスをインスタンス化しましょう。
Trainer コンストラクタの基本的な引数は、モデル、損失関数等の評価尺度のタプル、learner (オプティマイザ) のリストです :
learning_rate = 0.2
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
learner = C.sgd(z.parameters, lr_schedule)
trainer = C.Trainer(z, (loss, label_error), [learner])
次に幾つかヘルパー関数を作成しておきますが、これらは訓練の進捗を可視化するためだけに必要なものです :
def moving_average(a, w=5):
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
def print_training_progress(trainer, mb, frequency, verbose=1):
training_loss = "NA"
eval_error = "NA"
if mb%frequency == 0:
training_loss = trainer.previous_minibatch_loss_average
eval_error = trainer.previous_minibatch_evaluation_average
if verbose:
print ("Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%".format(mb, training_loss, eval_error*100))
return mb, training_loss, eval_error
4-6-4 trainer を実行する
ネットワークをトレーニングする準備ができましたが、どのようなデータを訓練エンジンに供給するかを決定する必要があります。
オプティマイザの各反復は minibatch_size 64 のサンプルを使用するものとして、総計 60,000 データポイント上でトレーニングします。更にデータポイント全体に渡り num_sweeps_to_train_with で指定される複数回のパスを通します (エポック数と考えて良いです)。反復数 (= ステップ総数) は num_minibatches_to_train で表わされます :
minibatch_size = 64
num_samples_per_sweep = 60000
num_sweeps_to_train_with = 10
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size
# 訓練データセットのためのリーダーを作成します。
reader_train = create_reader(train_file, True, input_dim, num_output_classes)
# データ・ストリームを label と input キーにマップします。
input_map = {
label : reader_train.streams.labels,
input : reader_train.streams.features
}
training_progress_output_freq = 500
plotdata = {"batchsize":[], "loss":[], "error":[]}
for i in range(0, int(num_minibatches_to_train)):
# 訓練データファイルからミニバッチを読みます。
data = reader_train.next_minibatch(minibatch_size, input_map = input_map)
trainer.train_minibatch(data)
batchsize, loss, error = print_training_progress(trainer, i, training_progress_output_freq, verbose=1)
if not (loss == "NA" or error =="NA"):
plotdata["batchsize"].append(batchsize)
plotdata["loss"].append(loss)
plotdata["error"].append(error)
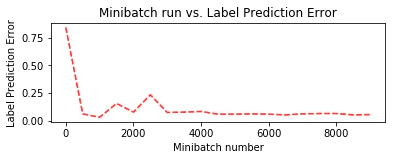
Minibatch: 0, Loss: 2.2688, Error: 84.38%
Minibatch: 500, Loss: 0.2542, Error: 6.25%
Minibatch: 1000, Loss: 0.2631, Error: 3.12%
Minibatch: 1500, Loss: 0.4910, Error: 15.62%
Minibatch: 2000, Loss: 0.2292, Error: 7.81%
Minibatch: 2500, Loss: 0.1546, Error: 4.69%
Minibatch: 3000, Loss: 0.2870, Error: 7.81%
Minibatch: 3500, Loss: 0.2961, Error: 6.25%
Minibatch: 4000, Loss: 0.2764, Error: 3.12%
Minibatch: 4500, Loss: 0.2333, Error: 7.81%
Minibatch: 5000, Loss: 0.2287, Error: 6.25%
Minibatch: 5500, Loss: 0.1871, Error: 6.25%
Minibatch: 6000, Loss: 0.1601, Error: 3.12%
Minibatch: 6500, Loss: 0.2085, Error: 7.81%
Minibatch: 7000, Loss: 0.3106, Error: 9.38%
Minibatch: 7500, Loss: 0.2929, Error: 6.25%
Minibatch: 8000, Loss: 0.0857, Error: 0.00%
Minibatch: 8500, Loss: 0.1392, Error: 4.69%
Minibatch: 9000, Loss: 0.3307, Error: 9.38%
ここで、(ssh 接続した) bash シェル上で nvidia-smi コマンドを実行してみると、以下のように GPU メモリが割り当てられたことが分かります :
$ nvidia-smi
Sat Oct 7 02:17:58 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.66 Driver Version: 384.66 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 000025C4:00:00.0 Off | Off |
| N/A 81C P0 67W / 149W | 96MiB / 12205MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 14079 C /home/masao/anaconda3/bin/python 85MiB |
+-----------------------------------------------------------------------------+
さて、トレーニング中に保持しておいた plotdata を利用して、訓練の進捗をミニバッチ・ベースで可視化してみましょう :
# SGD でノイズを除去して滑らかにするために移動平均損失を計算します。
plotdata["avgloss"] = moving_average(plotdata["loss"])
plotdata["avgerror"] = moving_average(plotdata["error"])
import matplotlib.pyplot as plt
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata["batchsize"], plotdata["avgloss"], 'b--')
plt.xlabel('Minibatch number')
plt.ylabel('Loss')
plt.title('Minibatch run vs. Training loss')
plt.show()
plt.subplot(212)
plt.plot(plotdata["batchsize"], plotdata["avgerror"], 'r--')
plt.xlabel('Minibatch number')
plt.ylabel('Label Prediction Error')
plt.title('Minibatch run vs. Label Prediction Error')
plt.show()

4-7 評価
4-7-1 テストを実行する
テストデータを使用して訓練されたネットワークを評価しましょう。そのためには trainer.test_minibatch メソッドを使用します :
# テストデータを読みます。
reader_test = create_reader(test_file, False, input_dim, num_output_classes)
test_input_map = {
label : reader_test.streams.labels,
input : reader_test.streams.features,
}
test_minibatch_size = 512
num_samples = 10000
num_minibatches_to_test = num_samples // test_minibatch_size
test_result = 0.0
for i in range(num_minibatches_to_test):
# test_minibatch_size で指定されたバッチでテストデータをロードします。
data = reader_test.next_minibatch(test_minibatch_size,
input_map = test_input_map)
eval_error = trainer.test_minibatch(data)
test_result = test_result + eval_error
# 総てのテスト・ミニバッチの評価エラーの平均
print("Average test error: {0:.2f}%".format(test_result*100 / num_minibatches_to_test))
Average test error: 7.64%
このエラーが訓練エラーよりも極端に大きい場合には、訓練されたモデルは (訓練中に見ていない) 新規のデータ上では上手く動作していないことを示しています。この状態を汎化性能が出ていないと表現しますが、要因としてはオーバーフィッティングなどがあげられます。
4-7-2 予測を確認する
先にエラーの累積による計測を行ないましたが、個々のデータポイントについての確率を得ましょう。
各データポイントについては、eval 関数が総てのクラスに渡る確率分布を返します。
最初にネットワーク出力を softmax 関数を通します。これはネットワークに渡る合計の活性化を 10 クラスに渡る確率にマップします。
ネットワーク定義には softmax を含めていなかったことを思い出してください。
out = C.softmax(z)
テストデータからのミニバッチ・サンプル上で試してみます :
# 評価するためのデータを読む。
reader_eval = create_reader(test_file, False, input_dim, num_output_classes)
eval_minibatch_size = 25
eval_input_map = {input: reader_eval.streams.features}
data = reader_test.next_minibatch(eval_minibatch_size, input_map = test_input_map)
img_label = data[label].asarray()
img_data = data[input].asarray()
predicted_label_prob = [out.eval(img_data[i]) for i in range(len(img_data))]
# 予測と正解ラベルについて最大値を持つインデックスを検索。
pred = [np.argmax(predicted_label_prob[i]) for i in range(len(predicted_label_prob))]
gtlabel = [np.argmax(img_label[i]) for i in range(len(img_label))]
print("Label :", gtlabel[:25])
print("Predicted:", pred)
Label : [4, 5, 6, 7, 8, 9, 7, 4, 6, 1, 4, 0, 9, 9, 3, 7, 8, 4, 7, 5, 8, 5, 3, 2, 2]
Predicted: [4, 6, 6, 7, 5, 8, 7, 4, 6, 1, 6, 0, 4, 9, 3, 7, 1, 2, 7, 5, 8, 6, 3, 2, 0]
平均テストエラーが 7.64% だけに、誤ったラベルを張っているサンプルも目立ちます。
4-7-3 可視化
結果の一つを可視化してみます :
sample_number = 5
plt.imshow(img_data[sample_number].reshape(28,28), cmap="gray_r")
plt.axis('off')
img_gt, img_pred = gtlabel[sample_number], pred[sample_number]
print("Image Label: ", img_pred)
Image Label: 8

5. MLP (多層パーセプトロン) で MNIST を分類
5-1 多層パーセプトロン
MNIST データの多クラス分類のために、4 章では多項ロジスティック回帰モデルを構築して訓練、評価しましたが、本章では CNTK Python API で多層パーセプトロン・モデルを実装します。
多層パーセプトロン・モデルでは多項ロジスティック回帰・モデルよりもエラー率が減少することが期待されます。
※ 前章と重なる部分については要点のみを説明します。
5-2 インポート
Jupyter Notebook の新しいノートブックを作成して使用しましょう。
最初に必要なコンポーネントをインポートしますが、説明はもう不要でしょう :
from IPython.display import display, Image
from __future__ import print_function
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import sys
import os
import cntk as C
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env()
C.cntk_py.set_fixed_random_seed(1)
%matplotlib inline
5-3 データ・リーディング
入力次元
入力次元と出力クラスを定義します。多項ロジスティック回帰の場合と同じです :
input_dim = 784
num_output_classes = 10
データフォーマット
MNIST データは 2 章で CTF (CNTK Text-Format) フォーマットでストアされています。
各サンプルは 2 フィールド (labels, features) を含み、そのフォーマットは次のようなものです :
|labels 0 0 0 1 0 0 0 0 0 0 |features 0 0 0 0 ...
(各々がピクセルを表現する 784 整数)
特徴ベクトルに相当するのは、"features" という名前の整数ストリームです。各整数がピクセルに対応しています。
ラベルは one-hot にエンコードされています。
◆ 前章で詳しく説明しましたが、訓練/テストデータを読むための create_reader 関数を作成します。
cntk.io.CTFDeserializer を使用すれば CTF フォーマットのテキストを読むことができます。
deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
def create_reader(path, is_training, input_dim, num_label_classes):
return C.io.MinibatchSource(C.io.CTFDeserializer(path, C.io.StreamDefs(
labels = C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False),
features = C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)
)), randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)
(前章で確認済みですが、) 2 章で作成した訓練とテストデータが利用可能であることを確認します :
data_dir = os.path.join(".", "data", "MNIST")
train_file = os.path.join(data_dir, "Train-28x28_cntk_text.txt")
test_file = os.path.join(data_dir, "Test-28x28_cntk_text.txt")
if not (os.path.isfile(train_file) and os.path.isfile(test_file)):
raise ValueError("Please generate the data by completing CNTK 103 Part A")
print("Data directory is {0}".format(data_dir))
Data directory is ./data/MNIST
5-4 モデル作成
本章で使用する多層パーセプトロンは隠れ層 2 つの単純なものです (num_hidden_layers)。
隠れ層のノード数は hidden_layers_dim で指定されます。
下図は MNIST データのコンテキストで使用するモデル全体を表わしています :
下図は Dense 層の仕様の概略を示しています :
- 入力次元 = 784 (各入力ピクセル)
- 出力次元 = 400 (隠れ層の数、ユーザにより指定されるパラメータ)
- 活性化関数は
relu

今回のモデルでは、それぞれが relu の活性化関数を持つ隠れ層としての 2 dense 層を持ち、活性化関数を持たない一つの出力層を持ちます。
2つの隠れ層の出力次元 (i.e. 隠れノードの数) は最初の図では 400 と 200 に設定されていましたが、
下のコードでは両者の層を同じ数の隠れノード 400 に設定しています。隠れ層の数は 2 です :
num_hidden_layers = 2
hidden_layers_dim = 400
◆ なお、最終出力層は 10 値のベクトルを吐きます。
モデルの出力を正規化するためには softmax を使用しますので、この層では活性化関数は使用しません。
CNTK の softmax 演算は loss 関数とバンドルされています。
5-5 ネットワーク構築
ネットワーク入力についての説明は既に十分でしょう。入力変数 input_variable は、データが供給されるコンテナ、あるいはプレースホルダーです :
input = C.input_variable(input_dim)
label = C.input_variable(num_output_classes)
以下はモデルの直訳としてのコードです :
def create_model(features):
with C.layers.default_options(init = C.layers.glorot_uniform(), activation = C.ops.relu):
h = features
for _ in range(num_hidden_layers):
h = C.layers.Dense(hidden_layers_dim)(h)
r = C.layers.Dense(num_output_classes, activation = None)(h)
return r
z はネットワーク出力を表わすために使用されます。
入力を 255.0 で除算して (各ピクセルを [0, 1] の範囲に) 正規化していることに注意してください :
z = create_model(input/255.0)
5-6 トレーニング
5-6-1 モデル・パラメータの学習
エビデンスをクラスに渡る確率分布にマップするために softmax 関数を使用します。そしてラベルとこのネットワークにより予測される確率の間の交差エントロピーを最小化することがモデル・パラメータの学習プロセスです。
CNTK の cross_entropy_with_softmax(z, label) は正解ラベル label と、ネットワーク出力 z の softmax 間の交差エントロピーを計算してくれます :
loss = C.cross_entropy_with_softmax(z, label)
cntk.metrics.classification_error を利用すれば分類エラーを計算できます :
label_error = C.classification_error(z, label)
5-6-2 trainer を構成する
モデル・パラメータのトレーニングを駆動する Trainer クラスをインスタンス化しましょう。
Trainer コンストラクタの基本的な引数は、モデル、損失関数等の評価尺度のタプル、learner (オプティマイザ) のリストです :
learning_rate = 0.2
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
learner = C.sgd(z.parameters, lr_schedule)
trainer = C.Trainer(z, (loss, label_error), [learner])
訓練の進捗を可視化するために必要なヘルパー関数を作成します :
def moving_average(a, w=5):
if len(a) < w:
return a[:] # Need to send a copy of the array
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
def print_training_progress(trainer, mb, frequency, verbose=1):
training_loss = "NA"
eval_error = "NA"
if mb%frequency == 0:
training_loss = trainer.previous_minibatch_loss_average
eval_error = trainer.previous_minibatch_evaluation_average
if verbose:
print ("Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%".format(mb, training_loss, eval_error*100))
return mb, training_loss, eval_error
5-6-3 trainer を実行する
ネットワークを訓練する準備ができましたので、どのようなデータを訓練エンジンに供給するかを決定します。
オプティマイザの各反復は minibatch_size 64 のサンプルを使用するものとして、総計 60,000 データポイント上でトレーニングします。 更にデータポイント全体に渡り num_sweeps_to_train_with で指定される複数回のパス (= エポック数) を通します。反復数 (= 総ステップ数) は num_minibatches_to_train で表わされます :
minibatch_size = 64
num_samples_per_sweep = 60000
num_sweeps_to_train_with = 10
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size
トレーニングを実行します :
reader_train = create_reader(train_file, True, input_dim, num_output_classes)
input_map = {
label : reader_train.streams.labels,
input : reader_train.streams.features
}
training_progress_output_freq = 500
plotdata = {"batchsize":[], "loss":[], "error":[]}
for i in range(0, int(num_minibatches_to_train)):
data = reader_train.next_minibatch(minibatch_size, input_map = input_map)
trainer.train_minibatch(data)
batchsize, loss, error = print_training_progress(trainer, i, training_progress_output_freq, verbose=1)
if not (loss == "NA" or error =="NA"):
plotdata["batchsize"].append(batchsize)
plotdata["loss"].append(loss)
plotdata["error"].append(error)
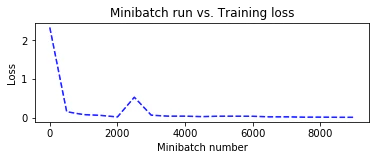
Minibatch: 0, Loss: 2.3311, Error: 95.31%
Minibatch: 500, Loss: 0.1553, Error: 6.25%
Minibatch: 1000, Loss: 0.0810, Error: 1.56%
Minibatch: 1500, Loss: 0.0613, Error: 3.12%
Minibatch: 2000, Loss: 0.0199, Error: 0.00%
Minibatch: 2500, Loss: 0.0129, Error: 0.00%
Minibatch: 3000, Loss: 0.0286, Error: 1.56%
Minibatch: 3500, Loss: 0.0793, Error: 4.69%
Minibatch: 4000, Loss: 0.0041, Error: 0.00%
Minibatch: 4500, Loss: 0.0725, Error: 1.56%
Minibatch: 5000, Loss: 0.0118, Error: 0.00%
Minibatch: 5500, Loss: 0.0215, Error: 0.00%
Minibatch: 6000, Loss: 0.0054, Error: 0.00%
Minibatch: 6500, Loss: 0.0071, Error: 0.00%
Minibatch: 7000, Loss: 0.0257, Error: 1.56%
Minibatch: 7500, Loss: 0.0170, Error: 1.56%
Minibatch: 8000, Loss: 0.0020, Error: 0.00%
Minibatch: 8500, Loss: 0.0042, Error: 0.00%
Minibatch: 9000, Loss: 0.0013, Error: 0.00%
ここで、bash シェル上、nvidia-smi コマンドで GPU メモリの消費を確認しておきましょう :
$ nvidia-smi
Sat Oct 7 02:52:50 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.66 Driver Version: 384.66 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 000025C4:00:00.0 Off | Off |
| N/A 80C P0 67W / 149W | 102MiB / 12205MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 26323 C /home/masao/anaconda3/bin/python 91MiB |
+-----------------------------------------------------------------------------+
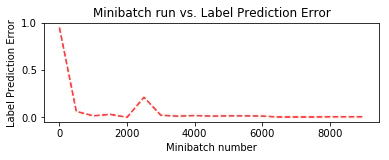
トレーニング中に保持しておいた plotdata を利用して、訓練の進捗をミニバッチ・ベースで可視化してみます :
plotdata["avgloss"] = moving_average(plotdata["loss"])
plotdata["avgerror"] = moving_average(plotdata["error"])
import matplotlib.pyplot as plt
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata["batchsize"], plotdata["avgloss"], 'b--')
plt.xlabel('Minibatch number')
plt.ylabel('Loss')
plt.title('Minibatch run vs. Training loss')
plt.show()
plt.subplot(212)
plt.plot(plotdata["batchsize"], plotdata["avgerror"], 'r--')
plt.xlabel('Minibatch number')
plt.ylabel('Label Prediction Error')
plt.title('Minibatch run vs. Label Prediction Error')
plt.show()
5-7 評価
5-7-1 テストを実行する
テストデータを使用して訓練されたネットワークを評価します。そのためには trainer.test_minibatch メソッドを使用します :
reader_test = create_reader(test_file, False, input_dim, num_output_classes)
test_input_map = {
label : reader_test.streams.labels,
input : reader_test.streams.features,
}
test_minibatch_size = 512
num_samples = 10000
num_minibatches_to_test = num_samples // test_minibatch_size
test_result = 0.0
for i in range(num_minibatches_to_test):
data = reader_test.next_minibatch(test_minibatch_size,
input_map = test_input_map)
eval_error = trainer.test_minibatch(data)
test_result = test_result + eval_error
print("Average test error: {0:.2f}%".format(test_result*100 / num_minibatches_to_test))
Average test error: 1.76%
多項ロジスティック回帰 (7.64%) に比べて、エラー率が大きく改善されました!
5-7-2 予測を確認する
先にエラーの累積による計測を行ないましたが、個々のデータポイントについての確率を得ましょう。各データポイントについては、eval 関数が総てのクラスに渡る確率分布を返します。
最初にネットワーク出力を softmax 関数を通します。これはネットワークに渡る合計の活性化を 10 クラスに渡る確率にマップします。
ネットワーク定義には softmax を含めていなかったことを思い出してください。
out = C.softmax(z)
テストデータからのミニバッチ・サンプル上で試してみます :
reader_eval = create_reader(test_file, False, input_dim, num_output_classes)
eval_minibatch_size = 25
eval_input_map = {input: reader_eval.streams.features}
data = reader_test.next_minibatch(eval_minibatch_size, input_map = test_input_map)
img_label = data[label].asarray()
img_data = data[input].asarray()
predicted_label_prob = [out.eval(img_data[i]) for i in range(len(img_data))]
pred = [np.argmax(predicted_label_prob[i]) for i in range(len(predicted_label_prob))]
gtlabel = [np.argmax(img_label[i]) for i in range(len(img_label))]
print("Label :", gtlabel[:25])
print("Predicted:", pred)
Label : [4, 5, 6, 7, 8, 9, 7, 4, 6, 1, 4, 0, 9, 9, 3, 7, 8, 4, 7, 5, 8, 5, 3, 2, 2]
Predicted: [4, 6, 6, 7, 8, 9, 7, 4, 6, 1, 4, 0, 9, 9, 3, 7, 8, 0, 7, 5, 8, 5, 3, 2, 2]
5-7-3 可視化
結果の一つを可視化してみます :
sample_number = 5
plt.imshow(img_data[sample_number].reshape(28,28), cmap="gray_r")
plt.axis('off')
img_gt, img_pred = gtlabel[sample_number], pred[sample_number]
print("Image Label: ", img_pred)
Image Label: 9

6. 畳み込みニューラルネットワークで MNIST を分類
MNIST データの多クラス分類のために、4 章では多項ロジスティック回帰モデルを使用し、5 章では多層パーセプトロン・モデルを使用しました。
最後に、畳み込みニューラルネットワークを CNTK Python API で実装して MNIST データを分類します。
6-1 畳み込みニューラルネットワーク
畳み込みニューラルネットワーク (CNN または ConvNet) は学習可能な重みとバイアスを持つニューロンからなるタイプの順伝播ニューラルネットワークで、前章の通常の多層パーセプトロン (MLP) ネットワークに良く似ています。けれども、CNN はデータの空間的な性質を利用します。
本来的に私たちは異なる物体をそれらの形状、サイズやカラーで知覚しています。例えば、自然風景の物体は典型的にはエッジ、角・頂点、カラーパッチ etc. が該当します。これらのプリミティブは現実世界のビジョン関連タスクでは異なる検出器 (e.g. エッジ検出器、カラー検出器) や検出器の組み合わせでしばしば識別されます。これらの検出器はまたフィルタとしても知られています。
畳み込みは数学的な演算で、入力として画像とフィルタを取り、(例えば入力画像のエッジ、コーナー、カラー etc を表わすような) フィルタリングされた出力を生成します。歴史的にはこれらのフィルタは手作業で作成されたり数学関数 (e.g. Gaussian / Laplacian / Canny filter) でモデル化された重みのセットでした。フィルタ出力は非線形活性化関数を通してマップされニューロンと呼ばれる人間の脳のセルを模倣しています
MLP では (入力と出力間の) 個々の完全結合のペアごとの重みを学習しますが、その代わりに、畳み込みネットワークはフィルタの重みを学習する ことにフォーカスします。このアプローチでは前章の伝統的な MLP ネットワークに比較して学習する重みの数が削減されます。
本章では、畳み込み演算と CNN の様々なパラメータについても説明します。
6-2 インポート
Jupyter Notebook の新しいノートブックを作成して使用しましょう。
from IPython.display import display, Image
from __future__ import print_function
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import os
import sys
import time
import cntk as C
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env()
C.cntk_py.set_fixed_random_seed(1)
%matplotlib inline
6-3 データ・リーディング
本章でも 2 章で作成した CTF フォーマットの MNIST データを利用します。
但し、多項ロジスティック回帰と MLP は下図のようにベクトルに平坦化された入力画像を使用していましたが、畳み込みネットワークでは空間的な特性も利用します :

入力次元
畳み込みネットワークでは、入力データは通常は 3D 行列 (チャネル数, 画像幅, 画像高さ) に shape されます、これはピクセル間の空間的な関係を保存しています。
自然風景のカラー画像はしばしば Red-Green-Blue (RGB) カラーチャネルとして表現されます。
そのような画像の入力次元はタプル (3, 画像幅, 画像高さ) として指定されます。

MNIST 画像は単一チャネル (グレースケール) データですので、入力次元はタプル (1, 画像幅, 画像高さ) として指定されます :
# データ次元を定義します。
input_dim_model = (1, 28, 28) # 画像は 28 x 28 でカラーの 1 チャネル (グレー) を持ちます。
input_dim = 28*28 # 入力データをベクトルとして扱うためにリーダーで使用されます。
num_output_classes = 10
データフォーマット
MNIST データは 2 章で CTF (CNTK Text-Format) フォーマットでストアされています。
各サンプルは 2 フィールド (labels, features) を含み、そのフォーマットは次のようなものです :
|labels 0 0 0 1 0 0 0 0 0 0 |features 0 0 0 0 ...
(各々がピクセルを表現する 784 整数)
特徴ベクトルに相当するのは、"features" という名前の整数ストリームです。各整数がピクセルに対応しています。
ラベルは one-hot にエンコードされています。
◆ 訓練/テストデータを読むための create_reader 関数を作成しますが、これも 4, 5 章と同じです。
cntk.io.CTFDeserializer を使用すれば CTF フォーマットのテキストを読むことができます。
deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
def create_reader(path, is_training, input_dim, num_label_classes):
ctf = C.io.CTFDeserializer(path, C.io.StreamDefs(
labels=C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False),
features=C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)))
return C.io.MinibatchSource(ctf,
randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)
(確認済みですが、) 2 章で作成した訓練とテストデータが利用可能であることを確認します :
data_dir = os.path.join(".", "data", "MNIST")
train_file = os.path.join(data_dir, "Train-28x28_cntk_text.txt")
test_file = os.path.join(data_dir, "Test-28x28_cntk_text.txt")
if not (os.path.isfile(train_file) and os.path.isfile(test_file)):
raise ValueError("Please generate the data by completing CNTK 103 Part A")
print("Data directory is {0}".format(data_dir))
Data directory is ./data/MNIST
6-4 モデル作成
6-4-1 CNN 概要
CNN は (MLP と同様に) 一つの層の出力が次の層の入力になるような多くの層から構成される順伝播ネットワークですが、パラメータ総量の視点では大きな違いがあります :
- MLP では入力ピクセルの総ての (出力ノードと) 接続可能なペアは各ペアが重みを持ちながら出力ノードに接続されます。
学習すべきパラメータの組合わせ爆発につながり、そしてオーバーフィッティングの可能性もまた高まります ( 参考 ) 。 - 畳み込み層はピクセルの空間的配置を利用してネットワークのパラメータの総量を本質的に減少させる複数のフィルタを学習します ( 参考 )。
この章では、畳み込み演算の基本を紹介します。
MNIST データはグレースケール画像 (単一チャネル) ですが、RGB 画像 (3 チャネル) のコンテキストで図示します。
6-4-2 畳み込み層
畳み込み層はフィルタのセットです。各フィルタは重み (W) 行列とバイアス ($b$) で定義されます。

これらのフィルタで画像に渡ってスキャンされ、重みと相当する入力値 ($x$) の間のドット積を遂行していきます。
バイアス値はドット積の出力に追加されて結果としての総和は活性化関数を通してマップされます。
このプロセスは次のアニメーションで示されます :
Image(url="https://www.cntk.ai/jup/cntk103d_conv2d_final.gif", width= 300)

畳み込み層は次の特徴を持ちます :
-
入力と出力ノードの総てのペアとして完全結合する代わりに、各畳み込みノードは、RF (Receptive Field, 受容野) とも呼ばれる、より小さな入力領域に局所化された入力ノードのサブセットに局所接続 (locally-connected) されます。
上図は画像の小さな 3 x 3 領域を RF 領域としています。RGB の場合は 3 x 3 領域が3つです、3 カラーチャネルの各々に一つです。 -
(Dense 層の中のように) 重みの単一セットを持つ代わりに、畳み込み層は (節の最初の図で複数のカラーで示されている) 複数のセットを持ち、これは フィルタ と呼ばれます。各フィルタは入力画像の各々の可能な RF 内の特徴を検出します。
畳み込みの出力はn副層 (sub-layer) のセットで、ここでnはフィルタの数です。
6-4-3 ストライドと Pad パラメータ
フィルタは対象と重ねるときに通常は、左から右へそして上から下へと移動されます。各畳み込み層は、フィルタの幅と高さを指定するパラメータ filter_shape を持ちます。パラメータ strides は、フィルタを行内で複数の RF を通して動かすときに右にどのくらいの距離をステップするかを制御し、次の行に動かすときにどのくらいの距離をステップダウンするかを制御します。ブーリアン・パラメータ pad は縁 (= border) 近くの RF の完全なタイリングを可能にするために縁 (= edge) まわりでパディングされるべきかを制御します。
前節のアニメーションは filter_shape = (3, 3), strides = (2, 2) そして pad = False によるプロセスを示しています。
下の2つのアニメーションは pad が True に設定されたときのプロセスを示します。最初のストライドは 2 で、2つ目は 1 のストライドを持ちます。
※ 出力 (ティール色の層) の shape はストライド設定で異なります。
# Plot images with strides of 2 and 1 with padding turned on
images = [("https://www.cntk.ai/jup/cntk103d_padding_strides.gif" , 'With stride = 2'),
("https://www.cntk.ai/jup/cntk103d_same_padding_no_strides.gif", 'With stride = 1')]
for im in images:
print(im[1])
display(Image(url=im[0], width=200, height=200))
With stride = 2

With stride = 1

6-5 ネットワーク構築
6-5-1 ネットワーク入力
今までと同様に、プレースホルダーとしての入力変数 input_variable を2つ定義します。
入力 MNIST 画像のために1つ、10 数字に相当するラベルのために1つですが、今回は新たな注意点があります。
リーダーはデータを読むとき、画像あたり 784 ピクセルのデータを、タプル input_dim_model で定義された shape に自動的にマップ することです。
今回の例では input_dim_model は先に (1,28,28) に設定されています :
# input_dim_model = (1, 28, 28)
x = C.input_variable(input_dim_model)
y = C.input_variable(num_output_classes)
6-5-2 ネットワーク定義
構築する最初のモデルは2つの畳み込み層 Convolution2D のみの単純なネットワークです (プーリング層については後述されます)。
タスクは MNIST データセットの 10 個の数字を検出することですから、ネットワーク出力は長さ 10 のベクトルであるべきですが、これは num_output_classes の出力を持つ dense 層で最後の畳み込み層の出力を射影することで達成できます。
訓練中に cross entropy 損失関数と結合される softmax 演算を使用しますので、最終的な dense 層はそれに関連する活性化関数は持たないことに注意してください。
次の図は構築するモデルを示しています。図中のパラメータは実際に使用されるものですが、ハイパーパラメータとも呼ばれます。
フィルタ shape の増加はモデル・パラメータ数の増加に繋がりますので、計算時間を増やす代わりにモデルをデータにより良くフィットさせることができますが、オーバーフィッティングの危険もあります。
通常は、より深い層のフィルタの数はそれらよりも前の層のフィルタの数よりも多いです。最初と2番目の層のためにそれぞれ 8, 16 を選択しました。

def create_model(features):
with C.layers.default_options(init=C.glorot_uniform(), activation=C.relu):
h = features
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=8,
strides=(2,2),
pad=True, name='first_conv')(h)
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=16,
strides=(2,2),
pad=True, name='second_conv')(h)
r = C.layers.Dense(num_output_classes, activation=None, name='classify')(h)
return r
C.layers.default_options は簡潔なモデルを書くためのエレガントな方法です。
モデリングのエラーを最小化して貴重なデバッグ時間をセーブするためのキーです。
※ default_options についての詳細は 層ライブラリ・リファレンス を参照してください。
さて、モデルのインスタンスを作成してモデルの各種コンポーネントを探求しましょう。
z はネットワーク出力を表わすために使用されます :
# モデルを作成する
z = create_model(x)
# 出力 shape / 各種コンポーネントのパラメータを出力表示します。
print("Output Shape of the first convolution layer:", z.first_conv.shape)
print("Bias value of the last dense layer:", z.classify.b.value)
Output Shape of the first convolution layer: (8, 14, 14)
Bias value of the last dense layer: [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
見積もられるモデル・パラメータの数の理解は深層学習において大切です、何故ならば持つべきデータの総量への直接的な依存関係があるからです。より大きな数のパラメータを持つモデルがオーバーフィッティングを回避するためにはより多くのデータが必要です。換言すれば、固定されたデータ総量を持つならば、パラメータ数を抑制しなければなりません。
※ モデル訓練の性能を データ拡張 でブーストできる方法はあります。
# ネットワークのパラメータの総数
C.logging.log_number_of_parameters(z)
Training 11274 parameters in 6 parameter tensors.
パラメータを理解する
今回のモデルは各々が重みとバイアスを持つ2つの畳み込み層を持ち、加えて dense 層が重みとバイアステンソルを持ちます。
パラメータ数をカウントしてみましょう :
-
最初の畳み込み層 : 各々のサイズ (1 x 5 x 5) の 8 フィルタがあります、ここで 1 は入力画像のチャネル数です。これは重み行列で合計 200 値と 8 バイアス値になります。
-
2番目の畳み込み層 : 各々のサイズ (8 x 5 x 5) の 16 フィルタがあります、ここで 8 は2番目の層への入力 (= 最初の層の出力) のチャネル数です。これは重み行列で合計 3200 値と 16 バイアス値になります。
-
最後の dense 層 : 16 x 7 x 7 入力値があり、MNIST データセットの 10 数字に相当する 10 出力値を生成します。これは (16 x 7 x 7) x 10 重み値と 10 バイアス値に対応します。
合計で 11274 パラメータになります。
6-6 トレーニング
6-6-1 モデルパラメータの学習
エビデンスをクラスに渡る確率分布にマップするために softmax 関数を使用します。そしてラベルとこのネットワークにより予測される確率の間の交差エントロピーを最小化することがモデル・パラメータの学習のプロセスです。
CNTK の cross_entropy_with_softmax(z, label) は正解ラベル label と、ネットワーク出力 z の softmax 間の交差エントロピーを計算してくれます。
cntk.metrics.classification_error を利用すれば分類エラーを計算できます :
def create_criterion_function(model, labels):
loss = C.cross_entropy_with_softmax(model, labels)
errs = C.classification_error(model, labels)
return loss, errs # (model, labels) -> (loss, error metric)
6-6-2 trainer を構成する
先に訓練に関連する異なる関数を可視化するために必要とされるヘルパー関数を作成しておきます :
def moving_average(a, w=5):
if len(a) < w:
return a[:] # Need to send a copy of the array
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
def print_training_progress(trainer, mb, frequency, verbose=1):
training_loss = "NA"
eval_error = "NA"
if mb%frequency == 0:
training_loss = trainer.previous_minibatch_loss_average
eval_error = trainer.previous_minibatch_evaluation_average
if verbose:
print ("Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%".format(mb, training_loss, eval_error*100))
return mb, training_loss, eval_error
そして、既に損失関数、オプティマイザ (or learner) 等々のモデルを訓練するために必要な個々のテクニックについての説明は十分だと思いますので、モデル訓練とテストのためのコードをまとめて簡潔にまとめてみましょう :
def train_test(train_reader, test_reader, model_func, num_sweeps_to_train_with=10):
# モデル関数をインスタンス化します; x は入力 (feature) 変数です。
# 総ての入力値を 255 で除算して入力画像ピクセルを 0-1 の範囲内にスケールします。
model = model_func(x/255)
# 損失とエラー関数をインスタンス化します。
loss, label_error = create_criterion_function(model, y)
# モデル訓練を駆動するための trainer オブジェクトをインスタンス化
learning_rate = 0.2
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
learner = C.sgd(z.parameters, lr_schedule)
trainer = C.Trainer(z, (loss, label_error), [learner])
# trainer のためのパラメータの初期化
minibatch_size = 64
num_samples_per_sweep = 60000
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size
# データストリームを入力とラベルにマップします。
input_map={
y : train_reader.streams.labels,
x : train_reader.streams.features
}
# ログ出力の頻度
training_progress_output_freq = 500
# タイマーの開始
start = time.time()
for i in range(0, int(num_minibatches_to_train)):
# 訓練データファイルからミニバッチを読みます。
data=train_reader.next_minibatch(minibatch_size, input_map=input_map)
trainer.train_minibatch(data)
print_training_progress(trainer, i, training_progress_output_freq, verbose=1)
# 訓練時間の出力表示
print("Training took {:.1f} sec".format(time.time() - start))
# モデルのテスト
test_input_map = {
y : test_reader.streams.labels,
x : test_reader.streams.features
}
# 訓練されたモデルのためのテストデータ
test_minibatch_size = 512
num_samples = 10000
num_minibatches_to_test = num_samples // test_minibatch_size
test_result = 0.0
for i in range(num_minibatches_to_test):
# test_minibatch_size で指定されたバッチとしてテストデータをロードします。
data = test_reader.next_minibatch(test_minibatch_size, input_map=test_input_map)
eval_error = trainer.test_minibatch(data)
test_result = test_result + eval_error
# 総てのテスト・ミニバッチの評価エラーの平均
print("Average test error: {0:.2f}%".format(test_result*100 / num_minibatches_to_test))
6-6-3 trainer を実行する
畳み込みニューラルネットを訓練する準備ができましたので、実行してみましょう :
def do_train_test():
global z
z = create_model(x)
reader_train = create_reader(train_file, True, input_dim, num_output_classes)
reader_test = create_reader(test_file, False, input_dim, num_output_classes)
train_test(reader_train, reader_test, z)
do_train_test()
Minibatch: 0, Loss: 2.3062, Error: 92.19%
Minibatch: 500, Loss: 0.1314, Error: 3.12%
Minibatch: 1000, Loss: 0.0923, Error: 3.12%
Minibatch: 1500, Loss: 0.0783, Error: 3.12%
Minibatch: 2000, Loss: 0.0363, Error: 1.56%
Minibatch: 2500, Loss: 0.0141, Error: 0.00%
Minibatch: 3000, Loss: 0.0407, Error: 1.56%
Minibatch: 3500, Loss: 0.1865, Error: 7.81%
Minibatch: 4000, Loss: 0.0061, Error: 0.00%
Minibatch: 4500, Loss: 0.0434, Error: 1.56%
Minibatch: 5000, Loss: 0.0163, Error: 0.00%
Minibatch: 5500, Loss: 0.0336, Error: 1.56%
Minibatch: 6000, Loss: 0.0102, Error: 0.00%
Minibatch: 6500, Loss: 0.0194, Error: 0.00%
Minibatch: 7000, Loss: 0.1019, Error: 3.12%
Minibatch: 7500, Loss: 0.0145, Error: 0.00%
Minibatch: 8000, Loss: 0.0282, Error: 1.56%
Minibatch: 8500, Loss: 0.0078, Error: 0.00%
Minibatch: 9000, Loss: 0.0240, Error: 1.56%
Training took 20.6 sec
Average test error: 1.53%
ここで、bash シェル上、nvidia-smi コマンドで GPU メモリの消費を確認しておきましょう :
$ nvidia-smi
Sat Oct 7 03:54:19 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.66 Driver Version: 384.66 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 000025C4:00:00.0 Off | Off |
| N/A 79C P0 67W / 149W | 139MiB / 12205MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 38640 C /home/masao/anaconda3/bin/python 128MiB |
+-----------------------------------------------------------------------------+
ネットワーク・パラメータの値の一つ、出力 dense 層のバイアス値をチェックしてみましょう。
先に確認した時は総て 0 でしたが、今は非ゼロ値です。モデル・パラメータが訓練中に更新されたことが分かります :
print("Bias value of the last dense layer:", z.classify.b.value)
Bias value of the last dense layer: [-0.03937254 -0.01128678 0.04710101 -0.1083153 -0.0122034 -0.01845592
-0.04610331 -0.09404257 0.27852851 0.00400356]
6-7 評価
先にエラーの累積による計測を行ないましたが、個々のデータポイントについての確率を得ましょう。 各データポイントについては、eval 関数が総てのクラスに渡る確率分布を返します。
最初にネットワーク出力を softmax 関数を通します。これはネットワークに渡る合計の活性化を 10 クラスに渡る確率にマップします :
out = C.softmax(z)
テストデータからのミニバッチ・サンプル上で試してみます :
reader_eval=create_reader(test_file, False, input_dim, num_output_classes)
eval_minibatch_size = 25
eval_input_map = {x: reader_eval.streams.features, y:reader_eval.streams.labels}
data = reader_eval.next_minibatch(eval_minibatch_size, input_map=eval_input_map)
img_label = data[y].asarray()
img_data = data[x].asarray()
# reshape img_data to: M x 1 x 28 x 28 to be compatible with model
img_data = np.reshape(img_data, (eval_minibatch_size, 1, 28, 28))
predicted_label_prob = [out.eval(img_data[i]) for i in range(len(img_data))]
pred = [np.argmax(predicted_label_prob[i]) for i in range(len(predicted_label_prob))]
gtlabel = [np.argmax(img_label[i]) for i in range(len(img_label))]
print("Label :", gtlabel[:25])
print("Predicted:", pred)
Label : [7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5, 4]
Predicted: [7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5, 4]
結果の一つを可視化しましょう :
sample_number = 5
plt.imshow(img_data[sample_number].reshape(28,28), cmap="gray_r")
plt.axis('off')
img_gt, img_pred = gtlabel[sample_number], pred[sample_number]
print("Image Label: ", img_pred)
Image Label: 1

6-8 プーリング層
深層ネットワークではしばしばパラメータ数を制御する必要があります。
畳み込み層出力の総ての層 (i.e 各層はフィルタ出力に対応します) について、プーリング層が持てます。プーリング層は典型的には以下の理由で導入されます :
- 前の層の次元を削減します (その結果、ネットワークを高速化もします)。
- モデルを画像における物体の位置の変化に対して耐性があるようにします。
例えば、数字が中央にある代わりに画像の一つのサイドにシフトされた場合でも、
分類器は分類タスクを上手く遂行します。
プーリング・ノード上の計算は通常の順伝播ノードよりも遥かに単純です。それは重み、バイアス、あるいは活性化関数を持たず、出力を計算するためには (max や average のような) 単純な集計関数を使用します。最も一般的に使用される関数は max です - マックスプーリング・ノードは単純に入力のフィルタ位置に対応する入力値の最大値を出力します。
下の図は 4 x 4 領域の入力値を示します。マックスプーリング・ウインドウサイズは 2 x 2 で左上隅から開始され、ウインドウ内の最大値が領域の出力になります。(下図で示されるように) ストライド・パラメータで指定された総量でモデルがシフトされるたびに maximum プーリング演算が繰り返されます。

もう一つの選択肢は average プーリングです。これは最大値の代わりに平均値を出力します。
2つの異なるプーリング演算は下のアニメーションで要約されます :
# Plot images with strides of 2 and 1 with padding turned on
images = [("https://www.cntk.ai/jup/c103d_max_pooling.gif" , 'Max pooling'),
("https://www.cntk.ai/jup/c103d_average_pooling.gif", 'Average pooling')]
for im in images:
print(im[1])
display(Image(url=im[0], width=300, height=300))
Max pooling

Average pooling

6-9 典型的な畳み込みネットワーク

典型的な CNN は交互の畳み込みとプーリング層のセットを含み、分類のための dense 出力層が続きます。
この構造の変形は多くの古典的な深層ネットワーク (VGG, AlexNet etc) で見つかります。
上図は 2-次元 (2D) 画像のコンテキストで表現されていますが、そのコンセプトと CNTK コンポーネントは任意の次元データ上で演算できます。
CNN の典型的なストラテジーは各中間層の空間的なサイズを減少させる一方でより深い層でフィルタの数を増やすことです。
6-10 マックス・プーリングでネットワークを再作成する
6-10-1 課題
典型的な畳み込みネットワークは組み合わせた畳み込みとマックス・プール層を持ちます。
先に作成したモデルは畳み込み層だけを持ちました。この節では、次のアーキテクチャでモデルを作成します :

このタスクを達成するために MaxPooling 関数を使用します。
(定義済みの) 下の create_model 関数を修正して MaxPooling 演算を追加してみましょう :
# Modify this model
def create_model(features):
with C.layers.default_options(init = C.glorot_uniform(), activation = C.relu):
h = features
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=8,
strides=(2,2),
pad=True, name='first_conv')(h)
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=16,
strides=(2,2),
pad=True, name='second_conv')(h)
r = C.layers.Dense(num_output_classes, activation = None, name='classify')(h)
return r
# do_train_test()
6-10-2 解法
次のコードがその解で、同時にこのモデルの訓練とテストの実行もできます :
# function to build model
def create_model(features):
with C.layers.default_options(init = C.layers.glorot_uniform(), activation = C.relu):
h = features
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=8,
strides=(1,1),
pad=True, name="first_conv")(h)
h = C.layers.MaxPooling(filter_shape=(2,2),
strides=(2,2), name="first_max")(h)
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=16,
strides=(1,1),
pad=True, name="second_conv")(h)
h = C.layers.MaxPooling(filter_shape=(3,3),
strides=(3,3), name="second_max")(h)
r = C.layers.Dense(num_output_classes, activation = None, name="classify")(h)
return r
do_train_test()
Minibatch: 0, Loss: 2.3342, Error: 92.19%
Minibatch: 500, Loss: 0.0591, Error: 1.56%
Minibatch: 1000, Loss: 0.1213, Error: 3.12%
Minibatch: 1500, Loss: 0.0192, Error: 0.00%
Minibatch: 2000, Loss: 0.0240, Error: 0.00%
Minibatch: 2500, Loss: 0.0250, Error: 0.00%
Minibatch: 3000, Loss: 0.0952, Error: 3.12%
Minibatch: 3500, Loss: 0.1446, Error: 3.12%
Minibatch: 4000, Loss: 0.0021, Error: 0.00%
Minibatch: 4500, Loss: 0.0381, Error: 1.56%
Minibatch: 5000, Loss: 0.0071, Error: 0.00%
Minibatch: 5500, Loss: 0.0142, Error: 0.00%
Minibatch: 6000, Loss: 0.0113, Error: 0.00%
Minibatch: 6500, Loss: 0.0029, Error: 0.00%
Minibatch: 7000, Loss: 0.0647, Error: 1.56%
Minibatch: 7500, Loss: 0.0173, Error: 1.56%
Minibatch: 8000, Loss: 0.0197, Error: 1.56%
Minibatch: 8500, Loss: 0.0015, Error: 0.00%
Minibatch: 9000, Loss: 0.0032, Error: 0.00%
Training took 20.1 sec
Average test error: 0.90%
平均テストエラーが 1 % を切りました!
7. What's Next
CNTK 2.2 Python API をマスターするためには Tutorials が最適ですが、前回と今回の記事で以下のチュートリアル 6 編をカバーしています :
- CNTK 101: Logistic Regression and ML Primer
- CNTK 102: Feed Forward Network with Simulated Data
- CNTK 103: Part A - MNIST Data Loader
- CNTK 103: Part B - Logistic Regression with MNIST
- CNTK 103: Part C - Multi Layer Perceptron with MNIST
- CNTK 103: Part D - Convolutional Neural Network with MNIST
従って、他の初級チュートリアルに該当する 104, 105 & 106 に取り組むのが良いでしょう。
以上