CNTK 2.2 Python API 入門 (5) - Autoencoder 基本実装
0. はじめに
◆ CNTK ( Microsoft Cognitive Toolkit ) 2.2 Python API 入門の第5弾です。
今回の記事で CNTK 2.2 Tutorials の 100 番台 (初級) を概ねカバーしたことになります。
今回はオートエンコーダ (= Autoencoder) を CNTK で実装します。
オートエンコーダは次元削減とノイズ除去 (= denoising) の領域で威力を発揮します。
基本的な概念を単相のオートエンコーダで学習した後、より本格的な深層オートエンコーダを CNTK で実装します。
前回までの記事 (CNTK 2.2 Python API 入門 (1) 基本, (2) 2 クラス分類, (3) MNIST, (4) LSTM) で
CNTK 2.2 について次のような点がお分かり頂けたかと思います :
- CNTK Python API を利用して Python プログラムで深層学習モデルが構築できます。
- CNTK はデータとしてテンソルとシークエンスを扱います。
- 深層学習フレームワークでお馴染みのビルディング・ブロックも多数用意されています。
- コンピュータビジョンのための畳み込みネットワークや時系列予測のための LSTM モデルも CNTK で簡単に実装できます。
- ネットワーク定義は Python 関数オブジェクトとして実装され、For ループや lambda 記法も利用できる Python ライクな記法で簡潔に定義可能です。
- Trainer クラスでカプセル化したトレーニングの実装も分かりやすく簡潔です。
- CTF フォーマットの利用で CNTK データ・リーダー (= Reader) が簡単に構成できます。
次回からは、CNTK 2.2 Tutorials (中級~) への橋渡しとなるような CNTK 2.2 Python API の記事を作成していきます。
※ 今回までの入門編では、Python と機械学習の基本的な知識を持つ読者を想定しています。
※ 他の深層学習フレームワークの経験があれば問題なく読み通せます。
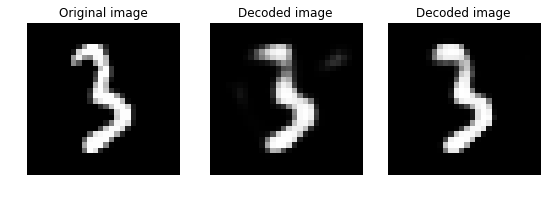
今回の内容は :
- 動作環境と Jupyter Notebook について
- 本記事で使用する CNTK Python API
- オートエンコーダの基本概念
- 深層オートエンコーダ
- What's Next
本記事は以下の CNTK チュートリアルを参考にしています :
1. 動作環境と Jupyter Notebook について
動作環境
動作環境の構築が必要な場合には、Cognitive Toolkit 2.2 を Azure Linux GPU 仮想マシンにインストール を参考にしてください。Azure ポータルと Ubuntu Linux にある程度慣れていれば、30 分程度で以下のような環境が構築できるかと思います :
- Azure NC 仮想マシン with NVIDIA Tesla® K80 GPU
- Ubuntu 16.04 LTS
- NVIDIA CUDA 8.0 & cuDNN 6.0
- Anaconda 3 4.1.1
- CNTK 2.2 (for GPU)
Jupyter Notebook
また、本記事でも CNTK チュートリアルでも Jupyter Notebook を多用します。
Jupyter Notebook の利用方法については「CNTK 2.2 Python API 入門 (2)」の記事中の Jupyter Notebook の活用 を参照してください。
2. 本記事で使用する CNTK Python API
今回使用する CNTK Python API を先にリストアップしておきます。前回までに使用した API に本記事で初出の API を追加しているのですが、実は今回初出の API は cntk.ops.log だけです。
※ 本記事で初出の API は太字で示されています。
cntk.io パッケージ
| API | 説明 |
|---|---|
CTFDeserializer |
組み込みの deserializer(*) で、CTF (CNTK Text Format) リーダーを構成します。 |
INFINITELY_REPEAT |
全データ sweep (総なめ) のサイズに等しい、ミニバッチ・スケジューリング・ユニットを指定するために使用される定数です。 |
MinibatchSource |
CNTK の Python API 用リーダーです。 |
StreamDef |
deserializer を使用するためにストリームを構成します。 |
StreamDefs |
キーワード引数からレコードを構築します。API というよりも (Python の) 辞書のような働きをします。 |
※ deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
cntk.layers パッケージ
cntk.layers.blocks モジュール
| API | 説明 |
|---|---|
LSTM |
recurrence の内側での使用のための LSTM ブロックを作成するための層ファクトリ関数です。 |
cntk.layers.higher_order_layers モジュール
| API | 説明 |
|---|---|
Sequential |
入力上に層のシーケンス (または任意の関数) を適用する合成 (= composite) を作成する層ファクトリ関数です。 |
cntk.layers.layers モジュール
| API | 説明 |
|---|---|
Convolution2D |
2D 畳み込み層を作成する層ファクトリ関数です。 |
Dense |
完全結合線形層のインスタンスを作成するための層ファクトリ関数です。 |
Dropout |
dropout 層を作成するための層ファクトリ関数です。 |
Embedding |
embedding (埋め込み) 層を作成するための層ファクトリ関数です。 |
MaxPooling |
マックス・プーリング層を作成するための層ファクトリ関数です。 |
cntk.layers.sequence モジュール
| API | 説明 |
|---|---|
Recurrence |
RNN, LSTM, そして GRU を含む、リカレント・モデルを実装する層ファクトリ関数です。 |
cntk.learners パッケージ
| API | 説明 |
|---|---|
learning_rate_schedule |
学習率スケジュールを作成します。 |
adam |
モデル・パラメータを学習するために Adam learner インスタンスを作成します。 |
fsadagrad |
モデル・パラメータを学習するために FSAdaGrad learner インスタンスを作成します。 |
sgd |
モデル・パラメータを学習するために SGD learner インスタンスを作成します。 |
UnitType |
schedule の値がサンプル毎上かミニバッチ毎上で指定されるかを示します。 |
cntk.losses パッケージ
| API | 説明 |
|---|---|
cross_entropy_with_softmax (output_vector, target_vector) |
target_vector と output_vector の softmax 間の交差エントロピーを計算します。 |
squared_error |
二乗誤差 - この演算は2つの入力行列の要素間の二乗の差異の総和を計算します。 |
cntk.metrics パッケージ
| API | 説明 |
|---|---|
classification_error (output_vector, target_vector) |
分類エラーを計算します。 |
cntk.ops パッケージ
| API | 説明 |
|---|---|
input_variable |
ネットワークの入力を作成します : 特徴やラベルのようなデータが供給される場所で、いわゆるプレースホルダーです。 |
log |
element-wise に自然対数を計算します。 |
parameter |
パラメータ・テンソルを作成します。 |
relu |
ReLU 活性化関数です。 |
sigmoid |
sigmoid 活性化関数です。 |
softmax |
softmax 活性化関数です。 |
times |
乗算ですが、この演算の出力は2つの入力行列の積 (= matrix product) です。ブロードキャストをサポートします。 |
cntk.ops.sequence パッケージ
| API | 説明 |
|---|---|
sequence.input_variable |
ネットワークの入力を作成します: 特徴やラベルのようなデータが提供されるべき場所です。 |
sequence.last (seq) |
symbolic 入力シーケンス seq の最後の要素を返します。 |
cntk.tests.test_utils パッケージ
| API | 説明 |
|---|---|
set_device_from_pytest_env() |
Jupyter Notebook 利用時に正しいターゲット・デバイスを選択するためのヘルパー関数です。総ての Jupyter Notebook の開始時にこれを呼び出す必要があります。 |
cntk.train パッケージ
cntk.train.trainer モジュール
| API | 説明 |
|---|---|
Trainer |
モデル・パラメータをトレーニングするクラス。 |
3. オートエンコーダの基本概念
オートエンコーダの解説に入ります。最初にオートエンコーダ ( Autoencoder ) の基本的な概念を紹介します。
※ 本章から Jupyter Notebook の利用を想定しています。
3-1 概要
(Wikipedia によれば、) オートエンコーダは人工的なニューラルネットワークで、効率的なエンコーディングの教師なし学習のために使用されます。言い換えれば、人間が加工した特徴に頼る代わりに自動的に学習される、不可逆でデータ特有な圧縮のために使用されます。そしてオートエンコーダの目的はデータセットのための表現 (エンコーディング) を学習することで、典型的には次元削減を目的とします。
オートエンコーダは利用する手元のデータセットに非常に特有なものです。
JPEG, MPEG によるエンコーディングのような標準的なコーデックとは異なり、一度情報がエンコードされて元の次元にデコードされて戻されれば、そのプロセス間に情報の何某かの量が失われてしまいます。エンコーディングがデータ特有の表現であると仮定しても、オートエンコーダは圧縮のために使用されるわけではありません。
けれども、オートエンコーダが非常に効果的であると見出された2つの領域があります : ノイズ除去 (= denoising) と次元削減です。
オートエンコーダが注意を引きつけてきたのは、教師なし学習のための潜在的なアプローチであると長い間考えられてきたからです。しかし真に教師なしのアプローチはラベルの必要なく有用な表現を学習することを条件とします。
オートエンコーダは 自己教師あり学習 (= self-supervised learning) に該当し、教師あり学習の特定のインスタンスでターゲットは入力データから生成されます。
目標
目標は MNIST 数字画像をより小さい次元のベクトルに圧縮してから画像を復元するようなオートエンコーダを訓練することです。
オートエンコーダに基づく順伝播ネットワークを示します: 単純な単層のものと (次章の) 深層オートエンコーダです。元の画像と復元された画像を可視化もしてみます。順伝播ネットワークを使用してどのように画像がエンコードされてデコード(復元)されるかを示すために MNIST 手書き数字データセットを使用します。MNIST データは非常に小さい背景ノイズを持つ手書き数字から構成されます。
※ ここで Jupyter Notebook の新しいノートブックを作成して使用していきましょう。
from IPython.display import Image
Image(url="http://cntk.ai/jup/MNIST-image.jpg", width=300, height=300)

インポート
従来通りに必要なコンポーネントをインポートします :
from __future__ import print_function
import matplotlib.pyplot as plt
import numpy as np
import os
import sys
import cntk as C
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env() # (only needed for our build system)
C.cntk_py.set_fixed_random_seed(1) # fix a random seed for CNTK components
%matplotlib inline
便宜上、2つの実行モードがあります :
- Fast モード: isFast を True に設定します。デフォルト・モードで、より少ない反復で訓練するか限定されたデータで訓練/テストすることを意味します。これは機能的な正当性という意味では確かなものですが、生成されたモデルは完全な訓練によって生成されたものからはかけ離れています。
- Slow モード: 実装に精通した後、異なるパラメータ等でより長い時間、訓練を実行することで洞察を得ることを望むのであれば、このフラグを False に設定してください。
isFast = False
# isFast = True
ここでは Slow モードで試した結果を示します。GPU 環境であれば Slow モードでもそれほど時間はかかりません。
※ Fast モードで試したい場合には、上の設定で isFast = True の設定を有効にしてください。
3-2 データ・リーディング
データセットとしては、「CNTK 2.2 Python API 入門 (3) MNIST 総集編」の 2. MNIST データセットを CNTK CTF フォーマットでセーブする で作成済みのファイルを流用します。
このデータは次のフォーマットにあります :
|labels 0 0 0 0 0 0 0 1 0 0 |features 0 0 0 0 ...
(784 integers each representing a pixel)
オートエンコーダのためには、"features" という名前の整数ストリームに対応した画像ピクセルを使用します。
ラベルは 1-hot encoded ですが、オートエンコーダでは必要ありませんのでこれらは無視します。
リーダー (= Reader) の作成
CTF deserializer を使用して訓練とテストデータを読むために create_reader 関数を定義します。
deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます :
def create_reader(path, is_training, input_dim, num_label_classes):
return C.io.MinibatchSource(C.io.CTFDeserializer(path, C.io.StreamDefs(
labels_viz = C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False),
features = C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)
)), randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)
訓練とテストデータファイルがダウンロード済みで、create_reader 関数で読み込むために利用可能であるかを確認します :
data_found = False
data_dir = os.path.join("data", "MNIST")
train_file = os.path.join(data_dir, "Train-28x28_cntk_text.txt")
test_file = os.path.join(data_dir, "Test-28x28_cntk_text.txt")
if os.path.isfile(train_file) and os.path.isfile(test_file):
data_found = True
if not data_found:
raise ValueError("Please generate the data by completing CNTK 103 Part A")
print("Data directory is {0}".format(data_dir))
Data directory is data/MNIST
3-3 単層モデル作成
事前の準備ができましたので、オートエンコーダをモデル化します。
エンコーダとデコーダとして、最も単純なケース、それぞれが単層の完全結合順伝播ネットワークから始めます (下の図で示されます) :
Image(url="http://cntk.ai/jup/SimpleAEfig.jpg", width=200, height=200)
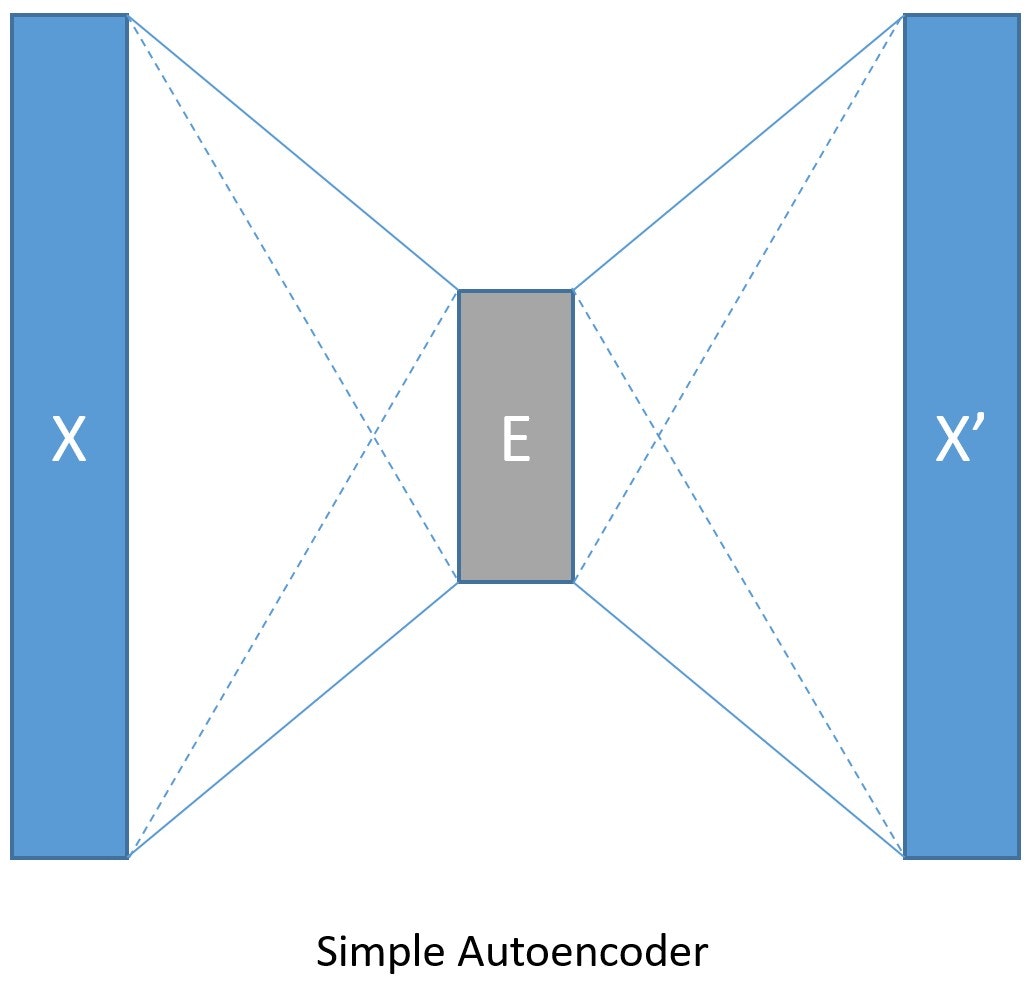
入力データはそれぞれが 28 x 28 ピクセルの手書き数字画像のセットです。
ここでは、各画像は 784 ピクセル値の線形配列です。これらのピクセルは 784 次元を持つ入力として考えられます、ピクセルあたり一つです。
オートエンコーダの目標はデータを圧縮してから元の画像を再構築することですから、出力次元は入力次元と同じです。
入力をわずか 32 次元にまで圧縮します (encoding_dim として参照されます)。また、入力最大値は 255 なので、0 と 1 の間に正規化します :
input_dim = 784
encoding_dim = 32
output_dim = input_dim
def create_model(features):
with C.layers.default_options(init = C.glorot_uniform()):
# 入力ピクセルを 0-1 範囲にスケールします。
encode = C.layers.Dense(encoding_dim, activation = C.relu)(features/255.0)
decode = C.layers.Dense(input_dim, activation = C.sigmoid)(encode)
return decode
3-4 訓練とテスト
これまでの記事では訓練とテストをそれぞれ別々に定義しましたが、
ここでは、ある種のレシピとして使用できるように2つのコンポーネントを一つに結合したテンプレートを提示します。
train_and_test 関数は2つの主要なタスクを遂行します :
- モデルを訓練する。
- テストデータ上でモデルの精度を評価する。
特徴的な点として、訓練のために :
- この関数は入力としてリーダー (
reader_train) とモデル関数 (model_func) を取ります。 - Fast モードで 5 エポック、Slow モードで 100 エポックの訓練をします。
-
Adamオプティマイザの変種 (FSAdaGrad) を使用します。 - カスタム損失関数 (実体は交差エントロピー) :
loss = -(target * C.log(model) + (1 - target) * C.log(1 - model))をどのように作成して渡すかを示します。 -
ラベルは入力 MNIST 画像と同じです (オートエンコーダのためには input == label i.e. データストリームを input と label にマップします)。
モデルの内側で入力を 0-1 範囲にスケールしていますので、ラベルも同じ範囲に再スケールします。 -
C.classification_error関数を使用してラベル・エラーを計算するためにもlabel変数の正規化が必要です。
テストのために :
- この関数は追加でリーダー (
reader_test) を取ります。 - そしてモデルにより予測されたピクセル値を参照データ、この場合は各画像に対する元のピクセル値に対して評価します。
def train_and_test(reader_train, reader_test, model_func):
###############################################
# モデルを訓練する
###############################################
# 入力とラベル変数をインスタンス化します。
input = C.input_variable(input_dim)
label = C.input_variable(input_dim)
# モデル関数を作成します。
model = model_func(input)
# このネットワークのためのラベルは入力 MNIST 画像と同じです。
# Note: モデルの内側で入力を 0-1 範囲にスケールしています。
# それ故にラベルも同じ範囲に再スケールします。
# カスタム損失関数をどのように使用するかを示します。
# loss = -(y* log(p)+ (1-y) * log(1-p)) ここで p = モデル出力 そして y = target
# 入力を 0-1 の範囲に正規化しました。よって target も同じ範囲にスケールします。
target = label/255.0
loss = -(target * C.log(model) + (1 - target) * C.log(1 - model))
label_error = C.classification_error(model, target)
# 訓練設定
epoch_size = 30000 # 30000 サンプルはデータセット・サイズの半分です。
minibatch_size = 64
num_sweeps_to_train_with = 5 if isFast else 100
num_samples_per_sweep = 60000
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) // minibatch_size
# モデル訓練を駆動するために trainer オブジェクトをインスタンス化します。
lr_per_sample = [0.00003]
lr_schedule = C.learning_rate_schedule(lr_per_sample, C.UnitType.sample, epoch_size)
# Momentum
momentum_as_time_constant = C.momentum_as_time_constant_schedule(700)
# このデータセットで上手く動作することが知られている、Adam オプティマイザの変種を使用します。
learner = C.fsadagrad(model.parameters,
lr=lr_schedule, momentum=momentum_as_time_constant)
# trainer をインスタンス化します
progress_printer = C.logging.ProgressPrinter(0)
trainer = C.Trainer(model, (loss, label_error), learner, progress_printer)
# データストリームを input と label にマップします。
# Note: オートエンコーダのためには input == label
input_map = {
input : reader_train.streams.features,
label : reader_train.streams.features
}
aggregate_metric = 0
for i in range(num_minibatches_to_train):
# 訓練データファイルからミニバッチを読みます。
data = reader_train.next_minibatch(minibatch_size, input_map = input_map)
# trainer を実行してモデル訓練を遂行します。
trainer.train_minibatch(data)
samples = trainer.previous_minibatch_sample_count
aggregate_metric += trainer.previous_minibatch_evaluation_average * samples
train_error = (aggregate_metric*100.0) / (trainer.total_number_of_samples_seen)
print("Average training error: {0:0.2f}%".format(train_error))
#############################################################################
# モデルをテストします
# Note: 訓練データとは異なるデータを読むためにテストファイル・リーダーを使用します。
#############################################################################
# 訓練されたモデルのためのテストデータ
test_minibatch_size = 32
num_samples = 10000
num_minibatches_to_test = num_samples / test_minibatch_size
test_result = 0.0
# Test error metric calculation
metric_numer = 0
metric_denom = 0
test_input_map = {
input : reader_test.streams.features,
label : reader_test.streams.features
}
for i in range(0, int(num_minibatches_to_test)):
# test_minibatch_size で指定されたバッチとしてテストデータをロードします
# ミニバッチの各データポイントは 1 次元 1 ピクセルの 784 次元の MNIST 数字画像です。
# 訓練されたモデルで enocode/decode します。
data = reader_test.next_minibatch(test_minibatch_size,
input_map = test_input_map)
eval_error = trainer.test_minibatch(data)
metric_numer += np.abs(eval_error * test_minibatch_size)
metric_denom += test_minibatch_size
# 総てのテスト・ミニバッチの評価エラーの平均
test_error = (metric_numer*100.0) / (metric_denom)
print("Average test error: {0:0.2f}%".format(test_error))
return model, train_error, test_error
◆ それでは、単相オートエンコーダの訓練/評価を実行しましょう。訓練/テスト・リーダーを作成して渡します :
num_label_classes = 10
reader_train = create_reader(train_file, True, input_dim, num_label_classes)
reader_test = create_reader(test_file, False, input_dim, num_label_classes)
model, simple_ae_train_error, simple_ae_test_error = train_and_test(reader_train,
reader_test,
model_func = create_model )
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per 1 samples: 3e-05
544 544 0.846 0.846 64
544 544 0.848 0.85 192
544 543 0.868 0.883 448
542 541 0.859 0.852 960
538 533 0.848 0.837 1984
496 456 0.754 0.662 4032
385 275 0.584 0.417 8128
303 221 0.442 0.301 16320
250 197 0.339 0.236 32704
208 167 0.257 0.176 65472
173 138 0.182 0.108 131008
142 111 0.116 0.0496 262080
116 90.2 0.0721 0.0283 524224
96.5 76.9 0.0465 0.0208 1048512
84.9 73.4 0.0328 0.0191 2097088
78.9 72.8 0.0259 0.0191 4194240
Average training error: 2.39%
Average test error: 1.73%
3-5 結果の可視化
デコードされた画像を元画像と比較することで視覚的に評価できます。
画像を無作為に選択して、まずはスタッツを表示してみます :
# 評価を実行するために幾つかデータを読みます。
num_label_classes = 10
reader_eval = create_reader(test_file, False, input_dim, num_label_classes)
eval_minibatch_size = 50
eval_input_map = { input : reader_eval.streams.features }
eval_data = reader_eval.next_minibatch(eval_minibatch_size,
input_map = eval_input_map)
img_data = eval_data[input].asarray()
# 画像を無作為に選択します。
np.random.seed(0)
idx = np.random.choice(eval_minibatch_size)
orig_image = img_data[idx,:,:]
decoded_image = model.eval(orig_image)[0]*255
# 画像のスタッツを出力表示します。
def print_image_stats(img, text):
print(text)
print("Max: {0:.2f}, Median: {1:.2f}, Mean: {2:.2f}, Min: {3:.2f}".format(np.max(img),
np.median(img),
np.mean(img),
np.min(img)))
# 元画像の情報を出力します。
print_image_stats(orig_image, "Original image statistics:")
# デコードされた画像の情報を出力します。
print_image_stats(decoded_image, "Decoded image statistics:")
Original image statistics:
Max: 255.00, Median: 0.00, Mean: 24.07, Min: 0.00
Decoded image statistics:
Max: 254.42, Median: 0.10, Mean: 24.75, Min: 0.00
スタッツは、最大値、中央値、平均値、最小値です。多少のずれは見られますが、概ね問題ないようです。
次に元画像とデコードされた画像をプロットしましょう。それらは視覚的に類似しているはずです :
# 画像のペアをプロットするためのヘルパー関数を定義します。
def plot_image_pair(img1, text1, img2, text2):
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(6, 6))
axes[0].imshow(img1, cmap="gray")
axes[0].set_title(text1)
axes[0].axis("off")
axes[1].imshow(img2, cmap="gray")
axes[1].set_title(text2)
axes[1].axis("off")
# Plot the original and the decoded image
img1 = orig_image.reshape(28,28)
text1 = 'Original image'
img2 = decoded_image.reshape(28,28)
text2 = 'Decoded image'
plot_image_pair(img1, text1, img2, text2)
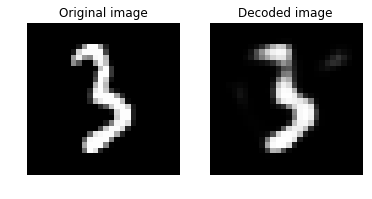
もう一つ見てみましょう :
idx2 = np.random.choice(eval_minibatch_size)
orig_image2 = img_data[idx2,:,:]
decoded_image2 = model.eval(orig_image2)[0]*255
img2_1 = orig_image2.reshape(28,28)
img2_2 = decoded_image2.reshape(28,28)
plot_image_pair(img2_1, text1, img2_2, text2)
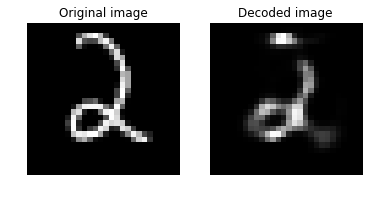
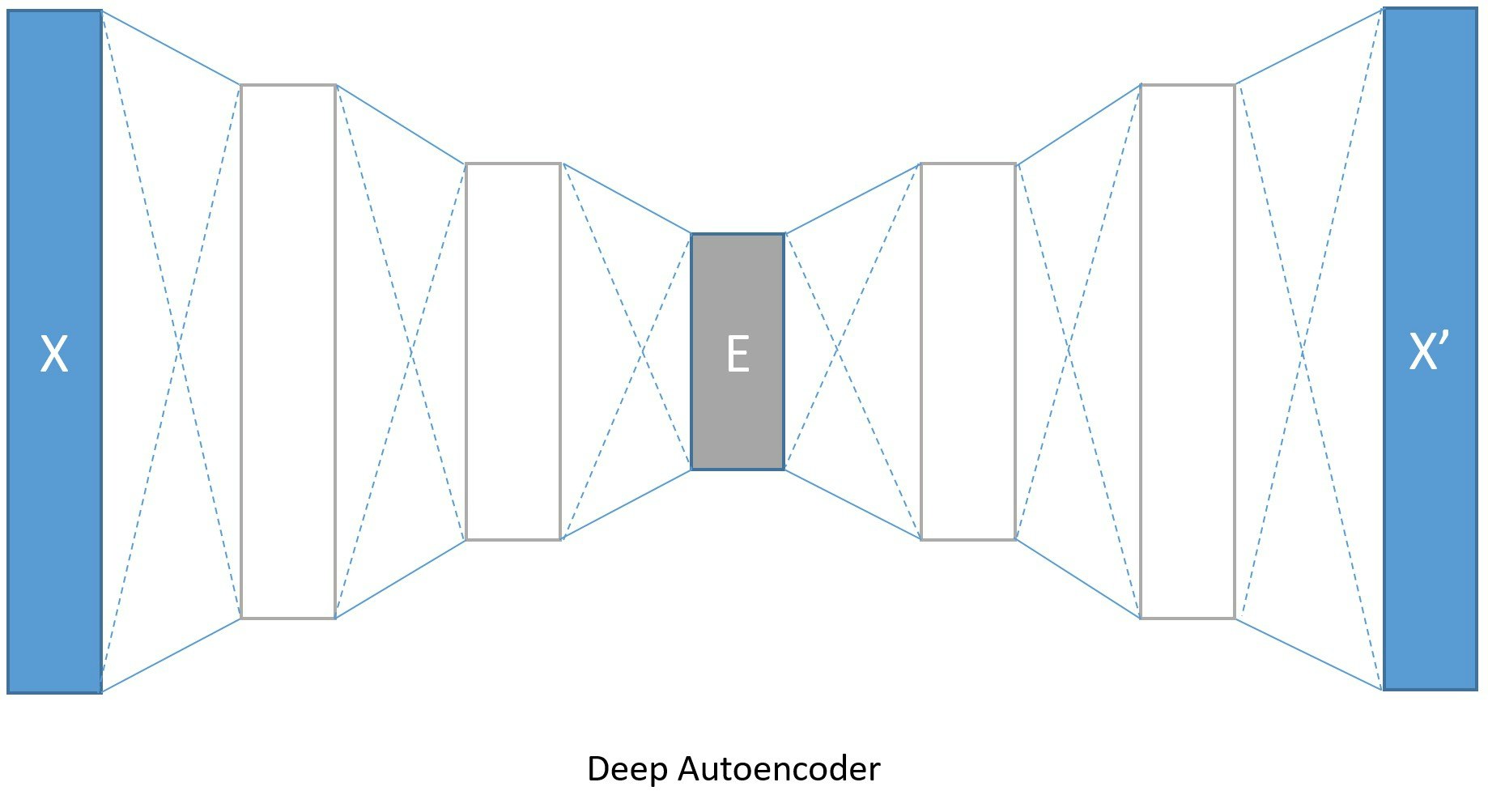
4 深層オートエンコーダ
4-1 深層モデルの作成、訓練、そしてテスト
前章のように、エンコーダあるいはデコーダとして単一の層に制限しなければならないわけではありません。
代わりに dense 層の積層を使用できますので、深層オートエンコーダも作成してみましょう。
※ 定義済みのコードを使い回しますので、Jupyter Notebook は同じノートをそのまま続けてお使いください。
Image(url="http://cntk.ai/jup/DeepAEfig.jpg", width=500, height=300)
(入力を 784 次元として、) エンコードする次元は 128, 64 そして 32 で、一方でデコードする次元は対照的に 64, 128 そして 784 と逆になります。このように変換をモデリングするために使用されるパラメータの数を増やすことで、より長い訓練期間を費やせばより低いエラー率を獲得することができます。
※ 深層エンコーダの訓練のためには、isFast フラグを False に設定することが望ましいです。
◆ モデルを再定義します。モデルの定義自体は難しくありませんが、encoded_model 変数に注意してください。
encoded_model 変数はエンコードの結果 (エンコーディング、上図のボックス E) を保持するグローバル変数 で、エンコーディングの抽出時に役立ちます :
input_dim = 784
encoding_dims = [128,64,32]
decoding_dims = [64,128]
encoded_model = None
def create_deep_model(features):
with C.layers.default_options(init = C.layers.glorot_uniform()):
encode = C.element_times(C.constant(1.0/255.0), features)
for encoding_dim in encoding_dims:
encode = C.layers.Dense(encoding_dim, activation = C.relu)(encode)
global encoded_model
encoded_model= encode
decode = encode
for decoding_dim in decoding_dims:
decode = C.layers.Dense(decoding_dim, activation = C.relu)(decode)
decode = C.layers.Dense(input_dim, activation = C.sigmoid)(decode)
return decode
◆ トレーニングを実行します :
num_label_classes = 10
reader_train = create_reader(train_file, True, input_dim, num_label_classes)
reader_test = create_reader(test_file, False, input_dim, num_label_classes)
model, deep_ae_train_error, deep_ae_test_error = train_and_test(reader_train,
reader_test,
model_func = create_deep_model)
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per 1 samples: 3e-05
544 544 0.739 0.739 64
544 544 0.794 0.822 192
544 543 0.801 0.805 448
543 542 0.817 0.831 960
530 518 0.876 0.931 1984
415 304 0.743 0.615 4032
315 216 0.594 0.448 8128
259 204 0.493 0.392 16320
215 172 0.366 0.24 32704
177 138 0.254 0.141 65472
145 113 0.165 0.0759 131008
120 95.9 0.104 0.0431 262080
103 84.6 0.067 0.03 524224
89.9 77.2 0.0451 0.0232 1048512
80.3 70.8 0.0317 0.0183 2097088
73.2 66.1 0.0234 0.0152 4194240
Average training error: 2.07%
Average test error: 1.25%
単相モデルでは、平均訓練エラー : 2.39% ; 平均テストエラー : 1.73% でしたので、改善されていることが分かります。
可視化
続いて、可視化しましょう。スタッツを出力した後、元画像とデコードされた画像を表示します :
orig_image = img_data[idx,:,:]
decoded_image = model.eval(orig_image)[0]*255
def print_image_stats(img, text):
print(text)
print("Max: {0:.2f}, Median: {1:.2f}, Mean: {2:.2f}, Min: {3:.2f}".format(np.max(img),
np.median(img),
np.mean(img),
np.min(img)))
# Print original image
print_image_stats(orig_image, "Original image statistics:")
# Print decoded image
print_image_stats(decoded_image, "Decoded image statistics:")
Original image statistics:
Max: 255.00, Median: 0.00, Mean: 24.07, Min: 0.00
Decoded image statistics:
Max: 254.58, Median: 0.00, Mean: 24.65, Min: 0.00
img1 = orig_image.reshape(28,28)
text1 = 'Original image'
img2 = decoded_image.reshape(28,28)
text2 = 'Decoded image'
plot_image_pair(img1, text1, img2, text2)
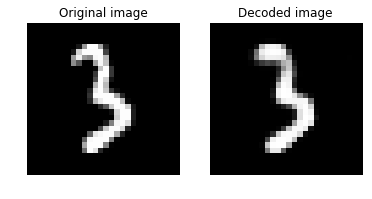
以下の画像群は、元画像 -> 単相モデルのデコード画像 -> 深層モデルのデコード画像の順に並べたものです。視覚的には深層モデルの方が上手くいっているように見えます :
4-2 画像の類似度を測る (コサイン類似度)
オートエンコーダの実装で、入力をどのようにエンコードしてデコードするかを示してきました。
ここからは、一つ画像を別の画像とどのように比較するのかを探求し、そして与えられた入力に対してエンコードされた入力をどのように抽出するかを示します。
高次元データを 2D に可視化するためには、t-SNE は多分ベストの方法の一つですが、典型的には比較的低次元のデータを要求します。そこで高次元データにおける類似関係を可視化するための良いストラテジーは、最初にオートエンコーダを使用して低次元空間 (e.g. 32 次元の) にデータをエンコードして、この入力データのエンコーディングを抽出して、続いて圧縮されたデータを 2D 平面にマップするために t-SNE を使用することです。
深層オートエンコーダ出力を以下のために使用します :
- 2つの画像を比較してそして
- エンコードされた (圧縮された) データをどのように取得できるかを示します。
最初に幾つかの画像データをそれらのラベルと一緒に読み必要があります :
# 画像と相当するラベルの幾つかのデータを取得します。
num_label_classes = 10
reader_viz = create_reader(test_file, False, input_dim, num_label_classes)
image = C.input_variable(input_dim)
image_label = C.input_variable(num_label_classes)
viz_minibatch_size = 50
viz_input_map = {
image : reader_viz.streams.features,
image_label : reader_viz.streams.labels_viz
}
viz_data = reader_eval.next_minibatch(viz_minibatch_size,
input_map = viz_input_map)
img_data = viz_data[image].asarray()
imglabel_raw = viz_data[image_label].asarray()
image_data は画像データ、imglabel_raw は one-hot のラベルを NumPy で持っています。
ラベルに該当する、ミニバッチのインデックスを得ます :
# 画像ラベルをミニバッチ配列のインデックスにマップします。
img_labels = [np.argmax(imglabel_raw[i,:,:]) for i in range(0, imglabel_raw.shape[0])]
from collections import defaultdict
label_dict=defaultdict(list)
for img_idx, img_label, in enumerate(img_labels):
label_dict[img_label].append(img_idx)
# 3 個の数字に対応するインデックスを出力表示します。
randIdx = [1, 3, 9]
for i in randIdx:
print("{0}: {1}".format(i, label_dict[i]))
1: [7, 24, 39, 44, 46]
3: [1, 13, 18, 26, 37, 40, 43]
9: [8, 12, 23, 28, 42, 49]
scipy を利用してコサイン類似度を測る関数を定義します :
from scipy import spatial
def image_pair_cosine_distance(img1, img2):
if img1.size != img2.size:
raise ValueError("Two images need to be of same dimension")
return 1 - spatial.distance.cosine(img1, img2)
注意 :
spatial.distance.cosineは距離を計算しますので、類似度を得るためには 1 からその値を減算しなければなりません (チュートリアルでは距離と類似度を広義に同じ意味で使用していますので注意しましょう)。
# 同じ数字の2つの画像間の距離を計算しましょう。
digit_of_interest = 6
digit_index_list = label_dict[digit_of_interest]
if len(digit_index_list) < 2:
print("Need at least two images to compare")
else:
imgA = img_data[digit_index_list[0],:,:][0]
imgB = img_data[digit_index_list[1],:,:][0]
# 元画像間の距離を出力します。
imgA_B_dist = image_pair_cosine_distance(imgA, imgB)
print("Distance between two original image: {0:.3f}".format(imgA_B_dist))
# 2つの画像をプロットします。
img1 = imgA.reshape(28,28)
text1 = 'Original image 1'
img2 = imgB.reshape(28,28)
text2 = 'Original image 2'
plot_image_pair(img1, text1, img2, text2)
# エンコードされたストリームをデコードします。
imgA_decoded = model.eval([imgA])[0]
imgB_decoded = model.eval([imgB]) [0]
imgA_B_decoded_dist = image_pair_cosine_distance(imgA_decoded, imgB_decoded)
# デコードされた画像間の距離を出力します。
print("Distance between two decoded image: {0:.3f}".format(imgA_B_decoded_dist))
# デコードされた画像をプロットします。
img1 = imgA_decoded.reshape(28,28)
text1 = 'Decoded image 1'
img2 = imgB_decoded.reshape(28,28)
text2 = 'Decoded image 2'
plot_image_pair(img1, text1, img2, text2)
Distance between two original image: 0.294
Distance between two decoded image: 0.303
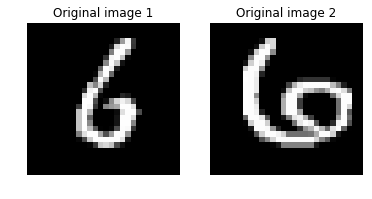
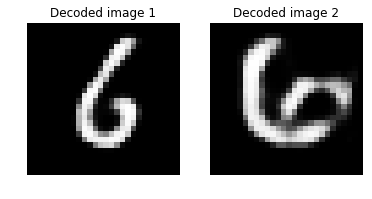
元の画像間のコサイン距離は、相当するデコードされた画像間の距離と比較可能 です。
コサイン類似度としては、1 の値は画像間の高い類似性を示して 0 は類似性がないことを示します。
4-3 エンコーディングの抽出
入力画像に対応するエンコードされたベクトル (エンコーディング) をどのように得るかを見てみましょう。
以下は再掲載の図ですが、エンコーディングは E のラベルが貼られたボックスで示されるネットワークのチョークポイントの次元を持つはずです (ここでは 32 次元) :
深層モデル定義の際に言及した、エンコーディングのための encoded_model 変数が役立ちます :
imgA = img_data[digit_index_list[0],:,:][0]
imgA_encoded = encoded_model.eval([imgA])
print("Length of the original image is {0:3d} and the encoded image is {1:3d}".format(len(imgA),
len(imgA_encoded[0])))
print("\nThe encoded image: ")
print(imgA_encoded[0])
Length of the original image is 784 and the encoded image is 32
The encoded image:
[ 13.60858917 8.04278183 9.94152927 6.13674641 0. 7.65627813
17.22723007 15.49608898 16.32130241 10.17695332 0. 24.50992012
11.33311081 16.52668571 12.09259987 8.85882187 12.953578
15.24253654 7.65890837 10.65802574 13.21836567 8.56726551
5.43466425 8.66965389 10.88025284 0. 10.7107029
11.15876961 5.47416973 8.30848312 17.50150681 13.83495045]
以下は数字を指定して、そのデコード画像を得る方法です :
digitA = 3
digitB = 8
digitA_index = label_dict[digitA]
digitB_index = label_dict[digitB]
imgA = img_data[digitA_index[0],:,:][0]
imgB = img_data[digitB_index[0],:,:][0]
# 元画像間の距離を出力します。
imgA_B_dist = image_pair_cosine_distance(imgA, imgB)
print("Distance between two original image: {0:.3f}".format(imgA_B_dist))
# 2つの画像をプロットします。
img1 = imgA.reshape(28,28)
text1 = 'Original image 1'
img2 = imgB.reshape(28,28)
text2 = 'Original image 2'
plot_image_pair(img1, text1, img2, text2)
# エンコードされたストリームをデコードします。
imgA_decoded = model.eval([imgA])[0]
imgB_decoded = model.eval([imgB])[0]
imgA_B_decoded_dist = image_pair_cosine_distance(imgA_decoded, imgB_decoded)
# 2つのデコードされた画像間の距離を出力します。
print("Distance between two decoded image: {0:.3f}".format(imgA_B_decoded_dist))
# デコードされた画像をプロットします。
img1 = imgA_decoded.reshape(28,28)
text1 = 'Decoded image 1'
img2 = imgB_decoded.reshape(28,28)
text2 = 'Decoded image 2'
plot_image_pair(img1, text1, img2, text2)
Distance between two original image: 0.376
Distance between two decoded image: 0.388
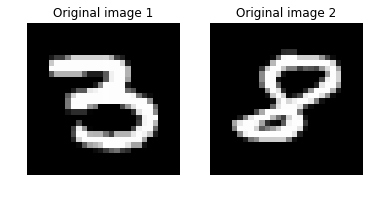
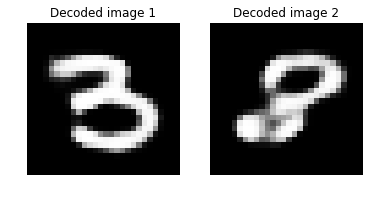
5. What's Next
CNTK 2.2 Python API をマスターするためには CNTK 2.2 Tutorials が最適ですが、
今回までの記事で以下の初級チュートリアル 9 編をカバーしたことになります :
- CNTK 101: Logistic Regression and ML Primer
- CNTK 102: Feed Forward Network with Simulated Data
- CNTK 103: Part A - MNIST Data Loader
- CNTK 103: Part B - Logistic Regression with MNIST
- CNTK 103: Part C - Multi Layer Perceptron with MNIST
- CNTK 103: Part D - Convolutional Neural Network with MNIST
- CNTK 105: Basic autoencoder (AE) with MNIST data
- CNTK 106: Part A - Time series prediction with LSTM (Basics)
- CNTK 106: Part B - Time series prediction with LSTM (IOT Data)
また併せて以下のリソースもカバーしています :
従って、次に残りの初級チュートリアル 104 に取り組んでも良いのですが、
これは pandas の説明が中心ですので、より上位の 200 番台に取り組むのがお勧めです。
以上