目次
本記事はPyTorchを使って自然言語処理 $\times$ DeepLearningをとりあえず実装してみたい、という方向けの入門講座になっております。以下の順番で読み進めていただくとPyTorchを使った自然言語処理の実装方法がなんとなくわかった気になれるかもしれません。
- PyTorchを使ってLSTMで文章分類を実装してみた
- PyTorchを使ってLSTMで文章分類を実装してみた(バッチ化対応ver)
- PyTorchでSeq2Seqを実装してみた
- PyTorchでAttention Seq2Seqを実装してみた
- PyTorchのBidirectional LSTMのoutputの仕様を確認してみた
- PyTorchでSelf Attentionによる文章分類を実装してみた
- PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた ←イマココ
はじめに
huggingfaceのtransformersのおかけでPyTorchを使って日本語BERTモデルがとても簡単に扱えるようになりました。
既にいろんな方がhuggingface/transformersを使って日本語BERTに関する記事を投稿されておりますが、私も勉強がてら記事を投稿しようと思いました。
参考
つくりながら学ぶ! PyTorchによる発展ディープラーニングの著者の方が投稿されている以下の記事が圧倒的にわかりやすいです。私のようなBERT初学者が詰まりそうなところも含めて丁寧に解説してくれてます。
- 【実装解説】日本語版BERTをGoogle Colaboratoryで使う方法(PyTorch)
- 【実装解説】日本語版BERTでlivedoorニュース分類:Google Colaboratoryで(PyTorch)
上記書籍&Qiita記事を参考に(というかほとんど写経)、私もBERTによる文章分類を実装してみます。
ついでにAttentionによる可視化にも触れていこうと思います。
とりあえずBERTを使って文章分類したい、Attentionの可視化を見てみたいって方向けです。BERTの理論的は話には一切触れておりません。
問題設定
いつもどおりlivedoorニュースコーパスを検証データとして扱います。参考記事ではlivedoorニュースの本文を利用されていますが、全く同じでは面白くないので、昔書いた記事と同様にlivedoorニュースコーパスのタイトルのみを使って、文章分類を行ってみようと思います。
実装
参考記事と同様にGoogle Colab上で実装しています。
データ準備
まずはcolabにGoogle Driveをマウント
from google.colab import drive
drive.mount('/content/drive')
こちらなどを参考にしていただきながら、livedoorニュースコーパスを取得します。Google Driveにlivedoorニュースコーパスのタイトルとカテゴリーを抜き出したデータセットをDataFrameとかにしておいて、Google Driveに格納しておきます。格納後、データの中身を確認した様子は以下のような感じです。
import pickle
import pandas as pd
# データセット格納先
drive_dir = "drive/My Drive/Colab Notebooks/livedoor_data/"
with open(drive_dir + "livedoor_title_category.pickle", 'rb') as f:
livedoor_data = pickle.load(f)
livedoor_data.head()
# title category
# 0 海外でも快適インターネット!KDDI、「au Wi-Fi SPOT」のサービスを拡充 it-life-hack
# 1 【特集/JOURNEY】 刺激的で優しいアラブの国へ (4/8) livedoor-homme
# 2 独女のTwitter、意外な楽しみ方 dokujo-tsushin
# 3 ピラミッドが20年でつくられたという話は嘘 movie-enter
# 4 剛力彩芽、“愛情たっぷり”の手作りチョコケーキをプレゼント movie-enter
カテゴリーをID化しましょう。
# カテゴリーのリストをデータセットから取得
categories = list(set(livedoor_data['category']))
print(categories)
# ['topic-news', 'movie-enter', 'livedoor-homme', 'it-life-hack', 'dokujo-tsushin', 'sports-watch', 'kaden-channel', 'peachy', 'smax']
# カテゴリーのID辞書を作成
id2cat = dict(zip(list(range(len(categories))), categories))
cat2id = dict(zip(categories, list(range(len(categories)))))
print(id2cat)
print(cat2id)
# {0: 'topic-news', 1: 'movie-enter', 2: 'livedoor-homme', 3: 'it-life-hack', 4: 'dokujo-tsushin', 5: 'sports-watch', 6: 'kaden-channel', 7: 'peachy', 8: 'smax'}
# {'topic-news': 0, 'movie-enter': 1, 'livedoor-homme': 2, 'it-life-hack': 3, 'dokujo-tsushin': 4, 'sports-watch': 5, 'kaden-channel': 6, 'peachy': 7, 'smax': 8}
# DataFrameにカテゴリーID列を追加
livedoor_data['category_id'] = livedoor_data['category'].map(cat2id)
# 念の為シャッフル
livedoor_data = livedoor_data.sample(frac=1).reset_index(drop=True)
# データセットをタイトルとカテゴリーID列だけにする
livedoor_data = livedoor_data[['title', 'category_id']]
livedoor_data.head()
# title category_id
# 0 ナイナイ岡村、AKB特番の出演依頼を拒否 「ああいうところに出るのは……」 0
# 1 C-3POが名場面を紹介する『スター・ウォーズinコンサート』日本上陸 1
# 2 盗撮現場を配信!? 無料イベント中継のはずが衝撃的瞬間が発覚【話題】 6
# 3 「相棒最終回で及川光博へ“非情な仕打ち”」と女性自身 0
# 4 長谷部やカズよりも上? 「小学生が好きなスポーツ選手」に意外な選手が 5
データの前処理にはtorchtextを使いますので、データセットを学習用、テスト用に分け、tsvファイルに保存します。
# 学習用データとテストデータに分ける
from sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(livedoor_data, train_size=0.8)
print("学習データサイズ", train_df.shape[0])
print("テストデータサイズ", test_df.shape[0])
# 学習データサイズ 5900
# テストデータサイズ 1476
# tsvファイルとして保存する
train_df.to_csv(drive_dir + 'train.tsv', sep='\t', index=False, header=None)
test_df.to_csv(drive_dir + 'test.tsv', sep='\t', index=False, header=None)
MeCabとhuggingface/transformersをインストール
こちらに記載させていただいたのですが、MeCabインストールには若干の注意が必要っぽいです。現状は以下のようにpipであれこれインストールすればエラーなく動きました。
# MeCabとtransformersを用意する
!apt install aptitude swig
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
# 以下で報告があるようにmecab-python3のバージョンを0.996.5にしないとtokezerで落ちる
# https://stackoverflow.com/questions/62860717/huggingface-for-japanese-tokenizer
!pip install mecab-python3==0.996.5
!pip install unidic-lite # これないとMeCab実行時にエラーで落ちる
!pip install transformers
torchtextでイテレータを作成
tokenizer.encodeで日本語BERTモデルで使える分かち書きが実行でき、tokenizer.convert_ids_to_tokensで分かち書きされたID列を形態素やサブワードに変換できる。めっちゃ便利。
import torch
import torchtext
from transformers.modeling_bert import BertModel
from transformers.tokenization_bert_japanese import BertJapaneseTokenizer
# 日本語BERTの分かち書き用tokenizerを宣言
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# 試しに分かち書きしてみる。
text = list(train_df['title'])[0]
wakati_ids = tokenizer.encode(text, return_tensors='pt')
print(tokenizer.convert_ids_to_tokens(wakati_ids[0].tolist()))
print(wakati_ids)
print(wakati_ids.size())
# ['[CLS]', '身長', 'が', '低い', '女性', 'は', '結婚', 'に', '不利', '?', '[SEP]']
# tensor([[ 2, 7236, 14, 3458, 969, 9, 1519, 7, 9839, 2935, 3]])
# torch.Size([1, 11])
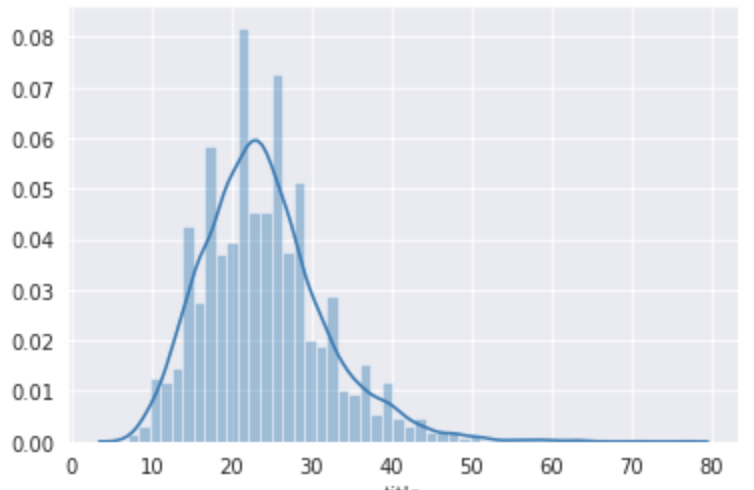
huggingfaceから扱える東北大学の日本語事前学習モデルは文章の形態素数(サブワード数)は512個までです。なのでもし、扱うデータの形態素、サブワード数が512を超える場合はmax_lengthを512に指定しましょう。ただし、今回のlivedoorニュースコーパスのタイトルに関しては以下の通り最大でも76個なので、今回はmax_lengthを指定していません。
# 日本語BERTで扱える文章の長さは512だけど、livedoorニュースのタイトルの長さは最大でもCLS, SEPトークン入れても76
import seaborn as sns
title_length = livedoor_data['title'].map(tokenizer.encode).map(len)
print(max(title_length))
# 76
sns.distplot(title_length)
以下のような感じでイテレータを作成する。
tokenizer.encodeのサイズは(1×文章の長さ)なので、[0]を指定する必要がある。
# torchtextを使って、学習データとテストデータのイテレータを作成
def bert_tokenizer(text):
return tokenizer.encode(text, return_tensors='pt')[0]
TEXT = torchtext.data.Field(sequential=True, tokenize=bert_tokenizer, use_vocab=False, lower=False,
include_lengths=True, batch_first=True, pad_token=0)
LABEL = torchtext.data.Field(sequential=False, use_vocab=False)
train_data, test_data = torchtext.data.TabularDataset.splits(
path=drive_dir, train='train.tsv', test='test.tsv', format='tsv', fields=[('Text', TEXT), ('Label', LABEL)])
# BERTではミニバッチサイズは16か32を使うようですが、livedoorタイトルは文章の長さが短いので32でもcolab上で動きます。
BATCH_SIZE = 32
train_iter, test_iter = torchtext.data.Iterator.splits((train_data, test_data), batch_sizes=(BATCH_SIZE, BATCH_SIZE), repeat=False, sort=False)
分類モデルの宣言
の前に学習済み日本語BERTのインプットとアウトプットの形式を確認しておきましょう。
BERTモデルは以下のように1行で簡単に宣言することができます。便利すぎ
from transformers.modeling_bert import BertModel
model = BertModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
モデル自体をprintするとBERTの構造を確認することができます。出力が長いので閉じておきます。
BERTモデルの構造
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(32000, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
この結果を見てわかるように、まずは単語をベクトル変換するEmbeddingの層があって、その次にBertLayerが12個あることがわかります。
更に単語のベクトル次元数や内部の隠れ層の次元数が768次元であることも確認できます。
BertModelのインプット、アウトプットの形式をリファレンスで確認しましょう。
BERTモデルのインプットの形式は(batch_size, sequence_length)と書いてあります。
アウトプットはデフォルトではlast_hidden_stateとpooler_outputが返ってくるようですが、Attention weightはoutput_attentions=Trueを指定することで得られるようです。
Attentionは12層のBertLayerの中にあるそれぞれの12個のMulti head attentionの結果を全て返してくれます。
# 上で作ったテストデータのイテレータから
batch = next(iter(test_iter))
print(batch.Text[0].size())
# torch.Size([32, 48]) ←(batch_size, sequence_length)
# BERTの順伝搬時にoutput_attentions=TrueでAttention weightを取得できる
last_hidden_state, pooler_output, attentions = model(batch.Text[0], output_attentions=True)
print(last_hidden_state.size())
print(pooler_output.size())
print(len(attentions), attentions[-1].size())
# torch.Size([32, 48, 768]) ← (batch_size, sequence_length×hidden_size)
# torch.Size([32, 768])
# 12 torch.Size([32, 12, 48, 48]) ← (batch_size, num_heads, sequence_length, sequence_length)
BERTで文章ベクトルを取得するときは、last_hidden_stateの各単語ベクトルのうち、先頭のclsトークンのベクトルを文章ベクトルとみなして利用します。
BERTモデルのインプットとアウトプットの形式がなんとなくわかったところで、実際にBERTを使って文章分類を行うモデルを構築します。
私も参考記事の方がそうしているように、huggingfaceが用意しているクラス分類用のライブラリを使うのではなく、自分で実装したほうが勉強になるし、構造がわかりやすいと思うので、クラス分類用ライブラリは使わずに実装します。
from torch import nn
import torch.nn.functional as F
from transformers.modeling_bert import BertModel
class BertClassifier(nn.Module):
def __init__(self):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# BERTの隠れ層の次元数は768, livedoorニュースのカテゴリ数が9
self.linear = nn.Linear(768, 9)
# 重み初期化処理
nn.init.normal_(self.linear.weight, std=0.02)
nn.init.normal_(self.linear.bias, 0)
def forward(self, input_ids):
# last_hidden_stateとattentionsを受け取る
vec, _, attentions = self.bert(input_ids, output_attentions=True)
# 先頭トークンclsのベクトルだけ取得
vec = vec[:,0,:]
vec = vec.view(-1, 768)
# 全結合層でクラス分類用に次元を変換
out = self.linear(vec)
return F.log_softmax(out), attentions
classifier = BertClassifier()
ファインチューニングの設定
今までファインチューニングとかしたことなかったのですが、参考記事のように一旦全てのパラメータを計算OFFにしてからパラメータを更新したい箇所だけを更新していくってやり方をするんですね。勉強になりました。
更に学習率もBERTの最後の層は事前学習済なわけで更新は少しだけにして、クラス分類用に差し込んだ最後の全結合層は学習率大きめにするとのこと。なるほどなるほど。
# ファインチューニングの設定
# 勾配計算を最後のBertLayerモジュールと追加した分類アダプターのみ実行
# まずは全部OFF
for param in classifier.parameters():
param.requires_grad = False
# BERTの最後の層だけ更新ON
for param in classifier.bert.encoder.layer[-1].parameters():
param.requires_grad = True
# クラス分類のところもON
for param in classifier.linear.parameters():
param.requires_grad = True
import torch.optim as optim
# 事前学習済の箇所は学習率小さめ、最後の全結合層は大きめにする。
optimizer = optim.Adam([
{'params': classifier.bert.encoder.layer[-1].parameters(), 'lr': 5e-5},
{'params': classifier.linear.parameters(), 'lr': 1e-4}
])
# 損失関数の設定
loss_function = nn.NLLLoss()
学習
参考記事のように本当は訓練モード、検証モードとかで分けて書いたほうが良いところですが、とりあえず動かしたいってことで以下のように学習するのに最低限のコードだけでループを回しております。
エポック数は5でも10でも最終的な精度があまり変化しなかったので、今回はエポック数は5にしておきました。
順調にlossが減っているのでとりあえずよし。
# GPUの設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# ネットワークをGPUへ送る
classifier.to(device)
losses = []
# エポック数は5で
for epoch in range(5):
all_loss = 0
for idx, batch in enumerate(train_iter):
batch_loss = 0
classifier.zero_grad()
input_ids = batch.Text[0].to(device)
label_ids = batch.Label.to(device)
out, _ = classifier(input_ids)
batch_loss = loss_function(out, label_ids)
batch_loss.backward()
optimizer.step()
all_loss += batch_loss.item()
print("epoch", epoch, "\t" , "loss", all_loss)
# epoch 0 loss 246.03703904151917
# epoch 1 loss 108.01931090652943
# epoch 2 loss 80.69403756409883
# epoch 3 loss 62.87365382164717
# epoch 4 loss 50.78619819134474
精度確認
Fスコアを見てみます。
記事の本文だと90%を超えるようですが、タイトルだけの分類だと85%という結果になりました。
タイトルはたしかに記事の要約的な意味はあるものの、よくこの短いセンテンスで85%も出たなぁと関心しました。
from sklearn.metrics import classification_report
answer = []
prediction = []
with torch.no_grad():
for batch in test_iter:
text_tensor = batch.Text[0].to(device)
label_tensor = batch.Label.to(device)
score, _ = classifier(text_tensor)
_, pred = torch.max(score, 1)
prediction += list(pred.cpu().numpy())
answer += list(label_tensor.cpu().numpy())
print(classification_report(prediction, answer, target_names=categories))
# precision recall f1-score support
#
# topic-news 0.80 0.82 0.81 158
# movie-enter 0.85 0.82 0.83 178
# livedoor-homme 0.68 0.73 0.70 108
# it-life-hack 0.88 0.82 0.85 179
# dokujo-tsushin 0.82 0.85 0.84 144
# sports-watch 0.89 0.87 0.88 180
# kaden-channel 0.91 0.97 0.94 180
# peachy 0.78 0.77 0.78 172
# smax 0.94 0.91 0.92 177
#
# accuracy 0.85 1476
# macro avg 0.84 0.84 0.84 1476
# weighted avg 0.85 0.85 0.85 1476
Attentionの可視化
最後にAttentionを可視化をすることで文章分類の判断根拠を確認してみます。
可視化するAttention weightはファインチューニングの設定時にBertLayerの最後の層のパラメータを更新させていた、つまり最後の層のAttention weightが今回のタイトル分類用に学習されているので、最後の層のAttention weightが今回のタスクの判断根拠として使えそうです。
今回宣言したBertClassiferモデルはAttention weightを全て返すようにしているので、最後の層だけを以下のようにして取得して、サイズを改めて確認します。
batch = next(iter(test_iter))
score, attentions = classifier(batch.Text[0].to(device))
# 最後の層のAttention weightだけ取得して、サイズを確認
print(attentions[-1].size())
# torch.Size([32, 12, 48, 48])
今一度リファレンスを確認すると、このサイズの意味は(batch_size, num_heads, sequence_length, sequence_length)でした。BertEncoderのAttentionはSelf Attentionですので、1つ目のsequence_lengthの各単語に対して、2つ目のsequence_lengthの各単語にどれだけAttentionしているかってことになるのかと。今回は先頭トークンclsを使って文章分類したわけなので、先頭トークンのベクトルがどの単語にAttentionしているかを可視化することで、今回のタスクの判断根拠と見なすことができそうです。
さらにBERTのSelf Attentionは12個のMulti head attentionなので、可視化する際は12個のAttention weightを全て足し合わせて使ってみようと思います。
参考書籍を参考に可視化部分を以下のように実装してみました。
def highlight(word, attn):
html_color = '#%02X%02X%02X' % (255, int(255*(1 - attn)), int(255*(1 - attn)))
return '<span style="background-color: {}">{}</span>'.format(html_color, word)
def mk_html(index, batch, preds, attention_weight):
sentence = batch.Text[0][index]
label =batch.Label[index].item()
pred = preds[index].item()
label_str = id2cat[label]
pred_str = id2cat[pred]
html = "正解カテゴリ: {}<br>予測カテゴリ: {}<br>".format(label_str, pred_str)
# 文章の長さ分のzero tensorを宣言
seq_len = attention_weight.size()[2]
all_attens = torch.zeros(seq_len).to(device)
for i in range(12):
all_attens += attention_weight[index, i, 0, :]
for word, attn in zip(sentence, all_attens):
if tokenizer.convert_ids_to_tokens([word.tolist()])[0] == "[SEP]":
break
html += highlight(tokenizer.convert_ids_to_tokens([word.numpy().tolist()])[0], attn)
html += "<br><br>"
return html
batch = next(iter(test_iter))
score, attentions = classifier(batch.Text[0].to(device))
_, pred = torch.max(score, 1)
from IPython.display import display, HTML
for i in range(BATCH_SIZE):
html_output = mk_html(i, batch, pred, attentions[-1])
display(HTML(html_output))
いくつか可視化結果を紹介します。
-
ヨドバシカメラ梅田店がサブワードで分割されまくりながらも家電に関連するってことで部分的ではあるもののしっかりattentionしてますね。

-
高橋名人(連打早い人)を根拠にkaden-channelと判定してるの面白い

-
peachy(女性に関する恋愛とかの記事)。これもいい感じ。

-
本音トークでpeachyに引きずられてしまったか。

良さげなものを中心に紹介しましたが、正直全体的には微妙なattentionかなって思いました。(実装本当に正しいか不安になってきた...)
とはいえ、サブワードに分割されてもぽい箇所をattentionするのはすごいなぁと関心しました。
おわりに
huggingface/transformersと参考記事のおかけでなんとなくではあるものの自分もBERTを動かせるようになりました。
いろんなタスクでBERTを使ってみたいなぁ
おわり
2021/4/7 追記
本記事のコメントで@nishi2433様からコメントでいただいているように、現時点では本記事のソースコードではエラーが発生します。エラーの内容はBertModel.from_pretrainedで取得した学習済み日本語BERTモデルに対し、Attentionの結果も受け取るため、順伝播のときにoutput_attentions=Trueを指定しているのですが、forward()にはそんな引数ないよ、と怒られてしまう、というものです。
おそらくはライブラリのバージョンが記事投稿時と比べてずいぶんとアップデートされているが故だと思います。
今一度私の方でも本記事のソースコードを順番に実行したところ、なんと他にもあれこれエラーが出てしまうことが判明したので、エラーを解消する変更箇所を記載させていただきます。
transformersのバージョンを指定する
参考記事にもあるようにtransformersをpipでインストールする際、以下のようにバージョンを固定します。
!pip install transformers==2.9.0
2021/4/7時点でのtransformersの最新バージョンは4.5.0のようですが、とあるバージョンから、こちらにもあるようにtransformers.modeling_bertやtransformers.tokenization_bert_japaneseでエラーが発生します。
どこまでのバージョンで動くかの検証はしていないですが、上記のバージョン2.9.0はエラーがでないことが確認できました。(teratailにあるように3.5.1だと私は以下のようなエラーが出てしまいました...)
ImportError: cannot import name 'SAVE_STATE_WARNING' from 'torch.optim.lr_scheduler' (/usr/local/lib/python3.7/dist-packages/torch/optim/lr_scheduler.py)
torchtext.data -> torchtext.legacy.data
torchtextの扱いも変わったようです。torchtext.dataで以下のようなエラーが発生します。
TEXT = torchtext.data.Field(sequential=True, tokenize=bert_tokenizer, use_vocab=False, lower=False,
include_lengths=True, batch_first=True, pad_token=0)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-9-34d05561ff4f> in <module>()
3 return tokenizer.encode(text, return_tensors='pt')[0]
4
----> 5 TEXT = torchtext.data.Field(sequential=True, tokenize=bert_tokenizer, use_vocab=False, lower=False,
6 include_lengths=True, batch_first=True, pad_token=0)
7 LABEL = torchtext.legacy.data.Field(sequential=False, use_vocab=False)
AttributeError: module 'torchtext.data' has no attribute 'Field'
こちらについては、ここで言及されているようにtorchtext.dataをtorchtext.legacy.dataに変更すれば動きます。本記事のtorchtextを扱っている箇所を以下で置き換えると動きました。
# torchtextを使って、学習データとテストデータのイテレータを作成
def bert_tokenizer(text):
return tokenizer.encode(text, return_tensors='pt')[0]
TEXT = torchtext.legacy.data.Field(sequential=True, tokenize=bert_tokenizer, use_vocab=False, lower=False,
include_lengths=True, batch_first=True, pad_token=0)
LABEL = torchtext.legacy.data.Field(sequential=False, use_vocab=False)
train_data, test_data = torchtext.legacy.data.TabularDataset.splits(
path=drive_dir, train='train.tsv', test='test.tsv', format='tsv', fields=[('Text', TEXT), ('Label', LABEL)])
# BERTではミニバッチサイズは16か32を使うようですが、livedoorタイトルは文章の長さが短いので32を使用してみる
BATCH_SIZE = 32
train_iter, test_iter = torchtext.legacy.data.Iterator.splits((train_data, test_data), batch_sizes=(BATCH_SIZE, BATCH_SIZE), repeat=False, sort=False)
output_attentions=Trueの指定
コメントでご指摘いただいた点についてです。
output_attentions=Trueの指定箇所を以下のようにBertModel.from_pretrainedのときに指定することで動くことを確認しました。
BertModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking', output_attentions=True)
とりあえず、以前の文法で日本語BERTを動かすなら上記の変更で良さそうですが、最新のtransformersで日本語BERT動かすにはどうするのか、については引き続き勉強しようと思います。
->最新のtransformers(4.5.0)で日本語BERTを動かすサンプルソースコードを公開しました!