この記事はPytorch Advent Calendar 2019の25日目の記事です!
目次
本記事はPyTorchを使って自然言語処理 $\times$ DeepLearningをとりあえず実装してみたい、という方向けの入門講座になっております。以下の順番で読み進めていただくとPyTorchを使った自然言語処理の実装方法がなんとなくわかった気になれるかもしれません。
- PyTorchを使ってLSTMで文章分類を実装してみた
- PyTorchを使ってLSTMで文章分類を実装してみた(バッチ化対応ver)
- PyTorchでSeq2Seqを実装してみた
- PyTorchでAttention Seq2Seqを実装してみた
- PyTorchのBidirectional LSTMのoutputの仕様を確認してみた
- PyTorchでSelf Attentionによる文章分類を実装してみた ←イマココ
- PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた
はじめに
以前でEncoder-DecoderモデルにおけるAttentionの実装をしましたが、今回はSelf Attentionにおける文章分類の実装をしてみます。
Self Attentionにおける文章の埋め込み表現は以下の論文で紹介されており、Transformerで有名な論文「Attention Is All You Need」でも引用されています。
本記事はこの論文で紹介されているSelf Attentionを実装してみます。
参考
実装に関しては以下の方の記事をほぼまるぱくり参考にさせていただきました。
① 【 self attention 】簡単に予測理由を可視化できる文書分類モデルを実装する
また、実装に関して前処理などが便利に行えるtorchtextを用いますが、torchtextも同じ方の以下の記事をとても参考にさせていただきました。
仕組み
参考①で本論文の仕組みを簡潔にご説明されておりますが、アルゴリズムは大きく分けて以下の3ステップで構成されます。
- 長さ$n$の文章をBidirectional LSTM(隠れ層の次元は$u$)で変換(下図(a)の各$h_i, (n\times 2u)$を取得)
- Bidirectional LSTMの各隠れ層の値をインプットにしてNeural NetworkでAttentionを計算(下図(b)の$A=(A_{ij}), 1\leq i \leq r, 1\leq j \leq n$を取得)
- Bidirectional LSTMの各隠れ層のベクトルを各Attention$A_{ij}$で重み付けしてNeural Networkで文章の埋め込みを取得
ここで、Attentionを計算する際の$d_a$とか$r$とかはハイパーパラメータです。$d_a$はAttentionをNeural Networkで予測する際の重み行列のサイズを表し、$r$はAttentionを何層重ねるか、に相当するパラメータです。
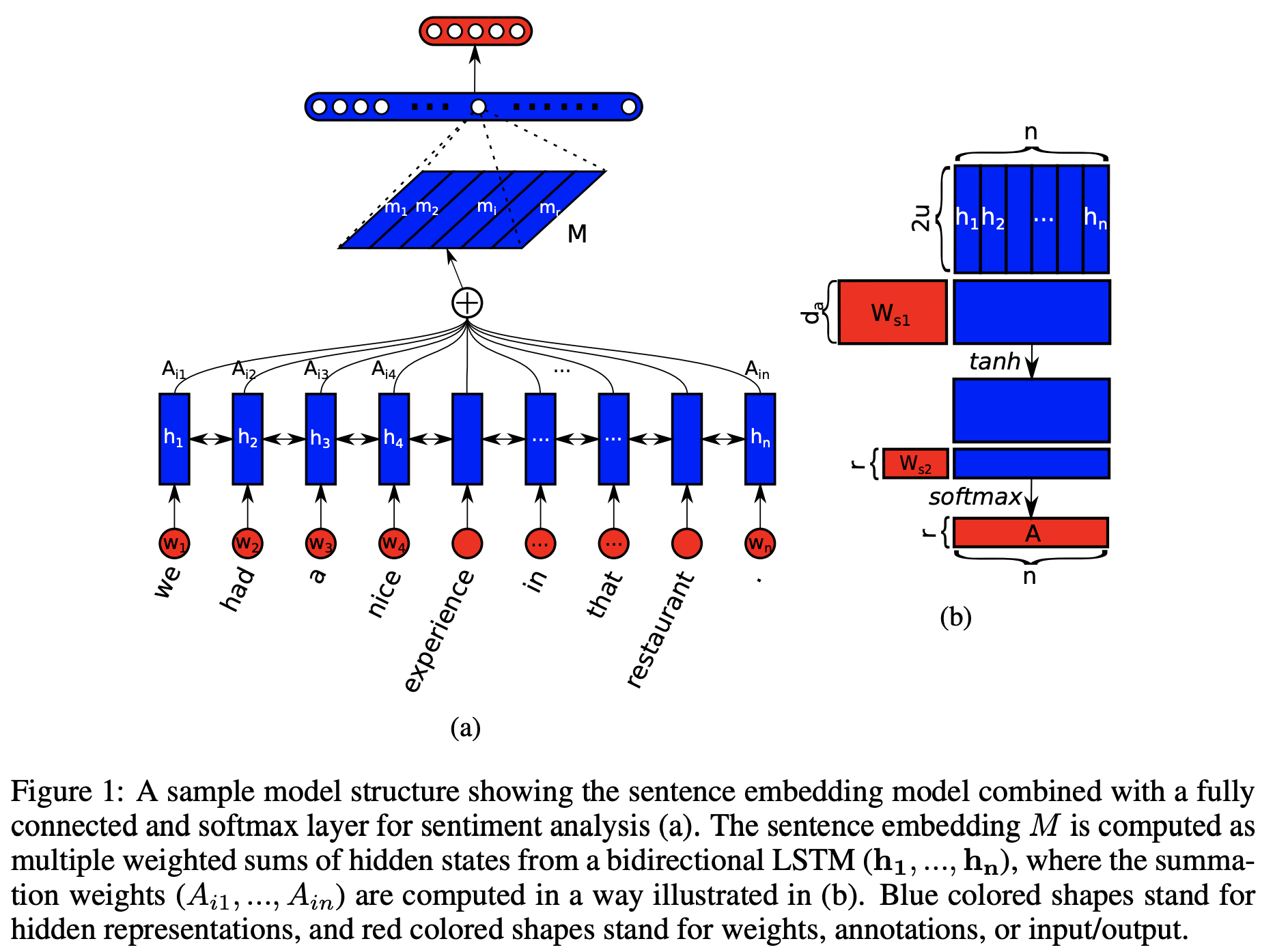
アイディアはとても単純で、要は文章分類をする際に、どの単語を重要視(重み付け)すべきかということをNeural Networkで学習させちゃおう、というものです。
実装
それでは上記の仕組みを坦々とPyTorchで実装していきます。解かせるタスクはIMDbの映画レビューのネガポジ判定とします。データは以下からダウンロードすることができます。
※以下の実装例はGoogle Colabで動かすことを前提に書いてます。
ライブラリのインポート
- 実装で使うライブラリをいろいろインポート
- データセットは英語なので、形態素解析エンジンはまぁいらんかなと思いますが、一応nltkである程度の前処理を実施する関数を用意(torchtextの前処理と被るところがあるけど一旦気にしない)。nltkについてはこちらをご参考ください。
# torchtext
import torchtext
from torchtext import data
from torchtext import datasets
from torchtext.vocab import GloVe
from torchtext.vocab import Vectors
# pytorch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch
# その他もろもろ
import os
import pickle
import numpy as np
import pandas as pd
from itertools import chain
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 最後にattentionを可視化するときに使います。
import itertools
import random
from IPython.display import display, HTML
# nltkによる前処理用
import re
import nltk
from nltk import stem
nltk.download('punkt')
# nltkによる形態素エンジンを用意
def nltk_analyzer(text):
stemmer = stem.LancasterStemmer()
text = re.sub(re.compile(r'[!-\/:-@[-`{-~]'), ' ', text)
text = stemmer.stem(text)
text = text.replace('\n', '') # 改行削除
text = text.replace('\t', '') # タブ削除
morph = nltk.word_tokenize(text)
return morph
データ準備
- 上記のURLからデータセットをダウンロードしてきて、以下のような形式のtsvファイルを用意します。
- train, testともに用意
- positiveは0、negativeは1でラベルを数値化しておきます。
ご参考
データの準備の仕方は例えば以下のような感じでしました。
train_pos_dir = 'aclImdb/train/pos/'
train_neg_dir = 'aclImdb/train/neg/'
test_pos_dir = 'aclImdb/test/pos/'
test_neg_dir = 'aclImdb/test/neg/'
header = ['text', 'label', 'label_id']
train_pos_files = os.listdir(train_pos_dir)
train_neg_files = os.listdir(train_neg_dir)
test_pos_files = os.listdir(test_pos_dir)
test_neg_files = os.listdir(test_neg_dir)
def make_row(root_dir, files, label, idx):
row = []
for file in files:
tmp = []
with open(root_dir + file, 'r') as f:
text = f.read()
tmp.append(text)
tmp.append(label)
tmp.append(idx)
row.append(tmp)
return row
row = make_row(train_pos_dir, train_pos_files, 'pos', 0)
row += make_row(train_neg_dir, train_neg_files, 'neg', 1)
train_df = pd.DataFrame(row, columns=header)
row = make_row(test_pos_dir, test_pos_files, 'pos', 0)
row += make_row(test_neg_dir, test_neg_files, 'neg', 1)
test_df = pd.DataFrame(row, columns=header)
上みたいな感じでデータを準備して、(label列は一旦いらないから消しつつ)最終的に以下のようなdataframeを作成しておきます。
train_df = pd.read_csv(imdb_dir + 'train.tsv', delimiter="\t", header=None)
train_df
torchtextによる前処理
- torchtextでデータの前処理、単語の分散表現の取得、ミニバッチ化などをサクッと行う
- 単語の分散表現は200次元のGloVeを用いました。torchtextでもダウンロードしてくれますが、毎回ダウンロードしたくないなどの理由でここからglove.6B.200d.txtを拝借しました。サイズ大きめなのでちょっと注意!
# train.tsv, test.tsvをここに置いとく
imdb_dir = "drive/My Drive/Colab Notebooks/imdb_datasets/"
# glove.6B.200d.txtをここに置いとく
word_embedding_dir = "drive/My Drive/Colab Notebooks/word_embedding_models/"
TEXT = data.Field(sequential=True, tokenize=nltk_analyzer, lower=True, include_lengths=True, batch_first=True)
LABEL = data.Field(sequential=False, use_vocab=False, is_target=True)
train, test = data.TabularDataset.splits(
path=imdb_dir, train='train.tsv', test='test.tsv', format='tsv',
fields=[('Text', TEXT), ('Label', LABEL)])
glove_vectors = Vectors(name=word_embedding_dir + "glove.6B.200d.txt")
TEXT.build_vocab(train, vectors=glove_vectors, min_freq=1)
ハイパーパラメータの設定など
- とくに理由はありませんが、以下のパラメータを用いました。
- Attentionの層の下図は3層にしてみました。
# GPU使いたい
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
BATCH_SIZE = 100 # バッチサイズ
EMBEDDING_DIM = 200 # 単語の埋め込み次元数
LSTM_DIM = 128 # LSTMの隠れ層の次元数
VOCAB_SIZE =TEXT.vocab.vectors.size()[0] # 全単語数
TAG_SIZE = 2 # 今回はネガポジ判定を行うのでネットワークの最後のサイズは2
DA = 64 # AttentionをNeural Networkで計算する際の重み行列のサイズ
R = 3 # Attentionを3層重ねて見る
モデル定義
Bidirectional LSTM
- 文章をBidrectional LSTMで変換
- PyTorchのBidirectional LSTMの仕様などはこちらをご参照ください。
class BiLSTMEncoder(nn.Module):
def __init__(self, embedding_dim, lstm_dim, vocab_size):
super(BiLSTMEncoder, self).__init__()
self.lstm_dim = lstm_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
# 学習済単語ベクトルをembeddingとしてセットする
self.word_embeddings.weight.data.copy_(TEXT.vocab.vectors)
# 単語ベクトルを誤差逆伝播で更新させないためにrequires_gradをFalseに設定する
self.word_embeddings.requires_grad_ = False
# bidirectional=Trueでお手軽に双方向のLSTMにできる
self.bilstm = nn.LSTM(embedding_dim, lstm_dim, batch_first=True, bidirectional=True)
def forward(self, text):
embeds = self.word_embeddings(text)
# 各隠れ層のベクトルがほしいので第1戻り値を受け取る
out, _ = self.bilstm(embeds)
# 前方向と後ろ方向の各隠れ層のベクトルを結合したままの状態で返す
return out
Self Attention層
- Bidirectional LSTMの各隠れ層のベクトルを受け取って、AttentionをNeural Networkで計算
- 論文に従って活性化関数に
Tanh()を使ってますが、参考①でご紹介した方の記事ではReLU()を使われているので、まぁどっちでも良いと思われます。
class SelfAttention(nn.Module):
def __init__(self, lstm_dim, da, r):
super(SelfAttention, self).__init__()
self.lstm_dim = lstm_dim
self.da = da
self.r = r
self.main = nn.Sequential(
# Bidirectionalなので各隠れ層のベクトルの次元は2倍のサイズになってます。
nn.Linear(lstm_dim * 2, da),
nn.Tanh(),
nn.Linear(da, r)
)
def forward(self, out):
return F.softmax(self.main(out), dim=1)
Attentionを考慮して分類するところ
- Attention weightで各隠れ層のベクトルを重み付けしてNeural Networkで2値分類用の予測を返す
- 各Attenionの層で重み付けした後の処理が正直イマイチよくわかっておらず、今回はとりあえず以下のステップで処理してみました。
- 3つのAttention層の重みでBidirectional LSTMの各隠れ層のベクトルを重み付け
- 重み付けされた各ベクトルを足してm1, m2, m3を取得
- m1, m2, m3の3つのベクトルをそのまま結合(次元数が
lstm_dim * 2 * 3になっちゃう)
class SelfAttentionClassifier(nn.Module):
def __init__(self, lstm_dim, da, r, tagset_size):
super(SelfAttentionClassifier, self).__init__()
self.lstm_dim = lstm_dim
self.r = r
self.attn = SelfAttention(lstm_dim, da, r)
self.main = nn.Linear(lstm_dim * 6, tagset_size)
def forward(self, out):
attention_weight = self.attn(out)
m1 = (out * attention_weight[:,:,0].unsqueeze(2)).sum(dim=1)
m2 = (out * attention_weight[:,:,1].unsqueeze(2)).sum(dim=1)
m3 = (out * attention_weight[:,:,2].unsqueeze(2)).sum(dim=1)
feats = torch.cat([m1, m2, m3], dim=1)
return F.log_softmax(self.main(feats)), attention_weight
モデル宣言
encoder = BiLSTMEncoder(EMBEDDING_DIM, LSTM_DIM, VOCAB_SIZE).to(device)
classifier = SelfAttentionClassifier(LSTM_DIM, DA, R, TAG_SIZE).to(device)
loss_function = nn.NLLLoss()
# 複数のモデルを from itertools import chain で囲えばoptimizerをまとめて1つにできる
optimizer = optim.Adam(chain(encoder.parameters(), classifier.parameters()), lr=0.001)
train_iter, test_iter = data.Iterator.splits((train, test), batch_sizes=(BATCH_SIZE, BATCH_SIZE), device=device, repeat=False, sort=False)
学習させる
- とりあえずエポック10で学習させてみました。
- lossは順調に減ってるのでとりあえずよし
losses = []
for epoch in range(10):
all_loss = 0
for idx, batch in enumerate(train_iter):
batch_loss = 0
encoder.zero_grad()
classifier.zero_grad()
text_tensor = batch.Text[0]
label_tensor = batch.Label
out = encoder(text_tensor)
score, attn = classifier(out)
batch_loss = loss_function(score, label_tensor)
batch_loss.backward()
optimizer.step()
all_loss += batch_loss.item()
print("epoch", epoch, "\t" , "loss", all_loss)
# epoch 0 loss 97.37978366017342
# epoch 1 loss 50.07680431008339
# epoch 2 loss 27.79373042844236
# epoch 3 loss 9.353876578621566
# epoch 4 loss 1.9509600398596376
# epoch 5 loss 0.22650832029466983
# epoch 6 loss 0.021685686125238135
# epoch 7 loss 0.011305359620109812
# epoch 8 loss 0.007448446772286843
# epoch 9 loss 0.005398457038154447
予測&精度
- 精度が思ったよりよくない気が...
- 参考①の方は精度が90%ほどでたとおっしゃっており、いくつか実装が異なるところがいろいろ裏目にでてるっぽい...
answer = []
prediction = []
with torch.no_grad():
for batch in test_iter:
text_tensor = batch.Text[0]
label_tensor = batch.Label
out = encoder(text_tensor)
score, _ = classifier(out)
_, pred = torch.max(score, 1)
prediction += list(pred.cpu().numpy())
answer += list(label_tensor.cpu().numpy())
print(classification_report(prediction, answer, target_names=['positive', 'negative']))
# precision recall f1-score support
#
# positive 0.86 0.88 0.87 12103
# negative 0.89 0.86 0.87 12897
#
# accuracy 0.87 25000
# macro avg 0.87 0.87 0.87 25000
# weighted avg 0.87 0.87 0.87 25000
Attention可視化
- どの単語をAttentionしているかをハイライトして可視化します。
- ハイライトする関数は参考①の方のソースをそのまま拝借させていただきました。
- jupyter notebookなどでHTMLを表示する際はこちらをご参照ください。
- forループとか変な処理をしてますが、単にテストデータからランダムに1件ピックアップして予測させたかっただけです。しょうもない実装で申し訳...
def highlight(word, attn):
html_color = '#%02X%02X%02X' % (255, int(255*(1 - attn)), int(255*(1 - attn)))
return '<span style="background-color: {}">{}</span>'.format(html_color, word)
def mk_html(sentence, attns):
html = ""
for word, attn in zip(sentence, attns):
html += ' ' + highlight(
TEXT.vocab.itos[word],
attn
)
return html
id2ans = {'0': 'positive', '1':'negative'}
_, test_iter = data.Iterator.splits((train, test), batch_sizes=(1, 1), device=device, repeat=False, sort=False)
n = random.randrange(len(test_iter))
for batch in itertools.islice(test_iter, n-1,n):
x = batch.Text[0]
y = batch.Label
encoder_outputs = encoder(x)
output, attn = classifier(encoder_outputs)
pred = output.data.max(1, keepdim=True)[1]
display(HTML('【正解】' + id2ans[str(y.item())] + '\t【予測】' + id2ans[str(pred.item())] + '<br><br>'))
for i in range(attn.size()[2]):
display(HTML(mk_html(x.data[0], attn.data[0,:,i]) + '<br><br>'))
ちっちゃくなって申し訳ですが、可視化するとこんな感じで表示されます。同じ文章が3つ表示されますが、Attention層を3つにしているので、それぞれの層がどの単語をattentionしているかを表示しています。
各Attention層で微妙に単語のattention度合いが違いますが、ほぼ同様にattentionしてるようです。

補足
Self Attentionなしだと...
- ちなみですが、今回のネガポジ判定をSelf AttentionなしでBidirectional LSTMだけで解くと、精度が約79.4%でした。
- Bidirectional LSTMだけで解く場合は以下のようなネットワークを用いて、その他パラメータはそのままです。
- Self Attentionは精度の底上げに大きく貢献してるようです。
class BiLSTMEncoder(nn.Module):
def __init__(self, embedding_dim, lstm_dim, vocab_size, tagset_size):
super(BiLSTMEncoder, self).__init__()
self.lstm_dim = lstm_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.word_embeddings.weight.data.copy_(TEXT.vocab.vectors)
self.word_embeddings.requires_grad_ = False
self.bilstm = nn.LSTM(embedding_dim, lstm_dim, batch_first=True, bidirectional=True)
self.hidden2tag = nn.Linear(lstm_dim * 2, tagset_size)
self.softmax = nn.LogSoftmax()
def forward(self, text):
embeds = self.word_embeddings(text)
_, bilstm_hc = self.bilstm(embeds)
bilstm_out = torch.cat([bilstm_hc[0][0], bilstm_hc[0][1]], dim=1)
tag_space = self.hidden2tag(bilstm_out)
tag_scores = self.softmax(tag_space.squeeze())
return tag_scores
おわりに
- ちょっと気になってるのが、Transformerなどで実装されているようなAttentionを辞書的に計算するパターン(単語のembeddingをquery, key, valueにわけるやつ)と本論文のNeural NetworkでAttentionを予測させるパターンの違いがいまいちよくわかっておりません。この論文を知る前はAttentionと行ったら内積とってうんたらかんたらするものだと思っていたので、Attentionといってもいろんな計算方法があるのかな?
- 次はいよいよBERTに触れてみたいと思います! Next → PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた
おわり