目次
本記事はPyTorchを使って自然言語処理 $\times$ DeepLearningをとりあえず実装してみたい、という方向けの入門講座になっております。以下の順番で読み進めていただくとPyTorchを使った自然言語処理の実装方法がなんとなくわかった気になれるかもしれません。
- PyTorchを使ってLSTMで文章分類を実装してみた
- PyTorchを使ってLSTMで文章分類を実装してみた(バッチ化対応ver) ←イマココ
- PyTorchでSeq2Seqを実装してみた
- PyTorchでAttention Seq2Seqを実装してみた
- PyTorchのBidirectional LSTMのoutputの仕様を確認してみた
- PyTorchでSelf Attentionによる文章分類を実装してみた
- PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた
はじめに
前回の記事でPytorchでLSTMを使って文章分類(ニュース記事のタイトルのカテゴリ分類)を実装しました。
その際、バッチ化はひとまず置いといて(バッチサイズ=1)で実装していましたが、今回はバッチ化対応したので、LSTMのバッチ化がわからないなどバッチ化で躓いている人のために参考になればと思い、ここに実装例を記載いたします。
(色々実装が間違っている可能性があるので、お気づきの方はぜひともご指摘いただけたらと思います。)
Google Colab用の準備
バッチ化することの最大のメリットはやはりGPUによる爆速化かと思います。私の手元にはGPUマシンがないので、Google ColabのGPUを使います。
データのアップロード
前回の記事と同様の問題(livedoorニュースコーパスの記事のタイトル分類)を扱います。
まずはlivedoorニュースコーパスデータをcolabから読み込めるようにするための準備が入ります。
colabを開いて、以下を実行します。
from google.colab import drive
drive.mount('/content/drive')
すると、こんなような出力になると思います。
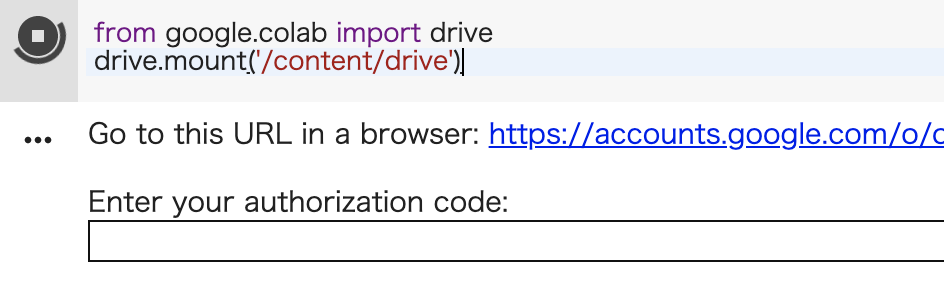
Go to this in a browser のURLをクリックしてGoogleアカウントでログインします。

黒くしている部分にコードが記載されているので、それをコピーして、上のEnter your authorization code:にペーストします。
すると、Google driveがマウントされ、colab上からGoogle driveのファイルへアクセスできます。
livedoorニュースコーパスのデータをGoogle driveに置いておきましょう。
MeCabを使えるようにする
こちらにcolabでMeCabを使えるようにするための手順の記載があります。
ColaboratoryでMeCabを使えようにする。
上記記事のように以下のコマンドをcolab上で実行しましょう。
# MeCabをcolabで使えるようにする
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3
colab上でMeCabが使えるようになります。(以下でエラーでなければOK)
import MeCab
バッチ化
LSTMのインプットの形式は前回の記事でも言及したように文章の長さ × バッチサイズ × ベクトル次元数の3次元テンソルでした。
実際のデータ(ニュース記事のタイトル)の長さ(厳密には形態素の数)は異なりますが、データをバッチ化してまとめてLSTMに流すために文章の系列の長さを揃える必要があります。
系列の長さを揃えるために単語リストに新しく<pad>(単語ID=0)を追加して短い文章を0パディングします。
詳細はソースコードを見たほうがわかりやすいと思うので、いきなり全ソースを載せつつ、前回の記事と比べてバッチ化対応するために変更した部分に言及してきます。
データをDataFrameにまとめる
Google driveのデータを読み込むようにしたところ以外は変更なし
import os
from glob import glob
import pandas as pd
import linecache
drive_dir = "drive/My Drive/Colab Notebooks/"
categories = [name for name in os.listdir(drive_dir + 'text') if os.path.isdir(drive_dir + "text/" +name)]
print(categories)
datasets = pd.DataFrame(columns=["title", "category"])
for cat in categories:
path = drive_dir + "text/" + cat + "/*.txt"
files = glob(path)
for text_name in files:
title = linecache.getline(text_name, 3)
s = pd.Series([title, cat], index=datasets.columns)
datasets = datasets.append(s, ignore_index=True)
形態素解析エンジン定義
前回と変更なし
import MeCab
import re
tagger = MeCab.Tagger("-Owakati")
def make_wakati(sentence):
sentence = tagger.parse(sentence)
sentence = re.sub(r'[0-90-9a-zA-Za-zA-Z]+', " ", sentence)
sentence = re.sub(r'[\._-―─!@#$%^&\-‐|\\*\“()_■×+α※÷⇒—●★☆〇◎◆▼◇△□(:〜~+=)/*&^%$#@!~`){}[]…\[\]\"\'\”\’:;<>?<>〔〕〈〉?、。・,\./『』【】「」→←○《》≪≫\n\u3000]+', "", sentence)
wakati = sentence.split(" ")
wakati = list(filter(("").__ne__, wakati))
return wakati
単語IDの辞書を定義
単語IDの辞書に新しく<pad>を追加
word2index = {}
# 系列を揃えるためのパディング文字列<pad>を追加
# パディング文字列のIDは0とする
word2index.update({"<pad>":0})
for title in datasets["title"]:
wakati = make_wakati(title)
for word in wakati:
if word in word2index: continue
word2index[word] = len(word2index)
print("vocab size : ", len(word2index))
系列の長さを揃えてバッチでまとめる
from sklearn.model_selection import train_test_split
import random
from sklearn.utils import shuffle
cat2index = {}
for cat in categories:
if cat in cat2index: continue
cat2index[cat] = len(cat2index)
def sentence2index(sentence):
wakati = make_wakati(sentence)
return [word2index[w] for w in wakati]
def category2index(cat):
return [cat2index[cat]]
index_datasets_title_tmp = []
index_datasets_category = []
# 系列の長さの最大値を取得。この長さに他の系列の長さをあわせる
max_len = 0
for title, category in zip(datasets["title"], datasets["category"]):
index_title = sentence2index(title)
index_category = category2index(category)
index_datasets_title_tmp.append(index_title)
index_datasets_category.append(index_category)
if max_len < len(index_title):
max_len = len(index_title)
# 系列の長さを揃えるために短い系列にパディングを追加
# 後ろパディングだと正しく学習できなかったので、前パディング
index_datasets_title = []
for title in index_datasets_title_tmp:
for i in range(max_len - len(title)):
title.insert(0, 0) # 前パディング
# title.append(0) # 後ろパディング
index_datasets_title.append(title)
train_x, test_x, train_y, test_y = train_test_split(index_datasets_title, index_datasets_category, train_size=0.7)
# データをバッチでまとめるための関数
def train2batch(title, category, batch_size=100):
title_batch = []
category_batch = []
title_shuffle, category_shuffle = shuffle(title, category)
for i in range(0, len(title), batch_size):
title_batch.append(title_shuffle[i:i+batch_size])
category_batch.append(category_shuffle[i:i+batch_size])
return title_batch, category_batch
モデル定義
パディング文字列ももちろん埋め込む必要があるわけですが、<pad>は0ベクトルで埋め込み、学習の妨げにならないようにする(?)ために、nn.Embedding()にてpadding_idx=0を追加しています。
LSTMを定義する際、batch_first=Trueを指定すると、LSTMのインプットの形式がバッチサイズ × 文章の長さ × ベクトル次元数になります。こうしたほうが次元を操作する際にわかりやすいと思います。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# GPUを使うために必要
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class LSTMClassifier(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size):
super(LSTMClassifier, self).__init__()
self.hidden_dim = hidden_dim
# <pad>の単語IDが0なので、padding_idx=0としている
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
# batch_first=Trueが大事!
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
self.softmax = nn.LogSoftmax()
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
#embeds.size() = (batch_size × len(sentence) × embedding_dim)
_, lstm_out = self.lstm(embeds)
# lstm_out[0].size() = (1 × batch_size × hidden_dim)
tag_space = self.hidden2tag(lstm_out[0])
# tag_space.size() = (1 × batch_size × tagset_size)
# (batch_size × tagset_size)にするためにsqueeze()する
tag_scores = self.softmax(tag_space.squeeze())
# tag_scores.size() = (batch_size × tagset_size)
return tag_scores
# 単語の埋め込み次元数上げた。精度がそこそこアップ!ハイパーパラメータのチューニング大事。
EMBEDDING_DIM = 200
HIDDEN_DIM = 128
VOCAB_SIZE = len(word2index)
TAG_SIZE = len(categories)
# to(device)でモデルがGPU対応する
model = LSTMClassifier(EMBEDDING_DIM, HIDDEN_DIM, VOCAB_SIZE, TAG_SIZE).to(device)
loss_function = nn.NLLLoss()
# SGDからAdamに変更。特に意味はなし
optimizer = optim.Adam(model.parameters(), lr=0.001)
学習
1epoch毎に全バッチを学習させます。バッチごとに逆伝搬してパラメータ更新させてます。
losses = []
for epoch in range(100):
all_loss = 0
title_batch, category_batch = train2batch(train_x, train_y)
for i in range(len(title_batch)):
batch_loss = 0
model.zero_grad()
# 順伝搬させるtensorはGPUで処理させるためdevice=にGPUをセット
title_tensor = torch.tensor(title_batch[i], device=device)
# category_tensor.size() = (batch_size × 1)なので、squeeze()
category_tensor = torch.tensor(category_batch[i], device=device).squeeze()
out = model(title_tensor)
batch_loss = loss_function(out, category_tensor)
batch_loss.backward()
optimizer.step()
all_loss += batch_loss.item()
print("epoch", epoch, "\t" , "loss", all_loss)
if all_loss < 0.1: break
print("done.")
予測
バッチ毎にまとめて予測。
前回と比べて精度が上がっているのは単語の埋め込み次元数を上げたからだと思われます。
test_num = len(test_x)
a = 0
with torch.no_grad():
title_batch, category_batch = train2batch(test_x, test_y)
for i in range(len(title_batch)):
title_tensor = torch.tensor(title_batch[i], device=device)
category_tensor = torch.tensor(category_batch[i], device=device)
out = model(title_tensor)
_, predicts = torch.max(out, 1)
for j, ans in enumerate(category_tensor):
if predicts[j].item() == ans.item():
a += 1
print("predict : ", a / test_num)
# predict : 0.6967916854948034
最後に
バッチ化対応の一番苦労したところはやはり次元の扱いでした。私と同じように次元数によるエラーで躓いている方は、全てのtensorの次元を逐一確認して、データの形状を細かく追ってみるのがよいと思います。
Next → PyTorchでSeq2Seqを実装してみた
おわり