目次
本記事はPyTorchを使って自然言語処理 $\times$ DeepLearningをとりあえず実装してみたい、という方向けの入門講座になっております。本記事をご覧になった後、以下の順番で読み進めていただくとPyTorchを使った自然言語処理の実装方法がなんとなくわかった気になれるかもしれません。
- PyTorchを使ってLSTMで文章分類を実装してみた ←イマココ
- PyTorchを使ってLSTMで文章分類を実装してみた(バッチ化対応ver)
- PyTorchでSeq2Seqを実装してみた
- PyTorchでAttention Seq2Seqを実装してみた
- PyTorchのBidirectional LSTMのoutputの仕様を確認してみた
- PyTorchでSelf Attentionによる文章分類を実装してみた
- PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた
はじめに
PyTorchでLSTMの実装の勉強をし、そこそこしっくりくる形で理解できたので、できるだけ細かく自分の頭にあるものをここに吐き出しておきます。PyTorchの使い方(特にLSTM)で詰まっている方がこの記事を見て少しでも助けになれれば幸いです。
ここでは、LSTMの理論的な側面や最適化に関する話は触れません。PyTorchのLSTMの使い方について、特にインプットのデータの形式に焦点を当てています。
以下を読んで勉強しました。本記事がわかりにくかったら以下の記事を読むことをおすすめします。
参考
- PyTorchのAutogradについて
- Define by runについて
- LSTMのPyTorchチュートリアル
- LSTMのreference
- pytorchでLSTMに入門したい...したくない?
いろいろおかしな理解している可能性があるので、変なこと書いていると思われた方は遠慮なくご指摘いただけると幸いです。
問題設定
LSTMはRNNと比べてより系列の長い文章も学習できるようになったとはいってもそこまで長い文章はさすがに学習できないと思うので、短めの文章で、しかも簡単そうなタスクで検証しようと思います。
今回は日本語の自然言語処理でよく使われるデータセット「livedoorニュースコーパス」のニュース記事のタイトルの分類を行ってみようと思います。
データ準備
以下からlivedoorニュースコーパスのデータをダウンロードします。
https://www.rondhuit.com/download.html
の「ldcc-20140209.tar.gz」ってやつ
解凍します。
$ tar xvf ldcc-20140209.tar.gz
解凍したディレクトリに text/ というディレクトリができたかと思います。その中にニュースのカテゴリ毎のフォルダがあり、そのカテゴリに関する記事が各フォルダ内に格納されています。
$ cd text
$ ls
CHANGES.txt dokujo-tsushin kaden-channel movie-enter smax topic-news
README.txt it-life-hack livedoor-homme peachy sports-watch
それぞれのニュース記事のタイトルですが、いくつかデータを確認したところ、3行目にタイトルらしき文字列の記載があるので、それを取得してデータフレームを作っちゃいます。
import os
from glob import glob
import pandas as pd
import linecache
# カテゴリを配列で取得
categories = [name for name in os.listdir("text") if os.path.isdir("text/" + name)]
print(categories)
# ['movie-enter', 'it-life-hack', 'kaden-channel', 'topic-news', 'livedoor-homme', 'peachy', 'sports-watch', 'dokujo-tsushin', 'smax']
datasets = pd.DataFrame(columns=["title", "category"])
for cat in categories:
path = "text/" + cat + "/*.txt"
files = glob(path)
for text_name in files:
title = linecache.getline(text_name, 3)
s = pd.Series([title, cat], index=datasets.columns)
datasets = datasets.append(s, ignore_index=True)
# データフレームシャッフル
datasets = datasets.sample(frac=1).reset_index(drop=True)
datasets.head()
# title category
# 0 兼用アンテナ搭載の「Viewer Dock」が同梱!シャープのドコモ向けハイエンドエンタメ系... smax
# 1 女は“愛嬌”、男も“愛嬌”-人事担当者がこっそり教える採用ウラ話 vol.6\n livedoor-homme
# 2 社会貢献×ファッションがカッコイイ、今年の春旋風を巻き起こしたMODE for Charit... peachy
# 3 今でも、後でも読めるニュースがここにある!スマホでもタブレットでも読みやすいITニュース活用... it-life-hack
# 4 被災地の缶詰を途上国に…「正気じゃない。人殺しだ!!」\n topic-news
インプットデータの前処理
PyTorchでLSTMをする際、食わせるインプットデータは3次元のテンソルある必要があります。具体的には、文章の長さ × バッチサイズ × ベクトル次元数 となっています。今回のインプットデータは文章(livedoorニュースのタイトル文)であり、この文章を3次元テンソルに変換する必要があります。
バッチサイズは一旦無視して、ひとまず文章を以下のように2次元のマトリクスに変換することを考えます。
人口知能は人間の仕事を奪った
(形態素解析)→['人口','知能','は','人間','の','仕事','を','奪っ','た']
(各単語をベクトルで置換)→[[0.2 0.5 -0.9 1.3 ...], # 「人口」の単語ベクトル
[1.3 0.1 2.9 -1.3 ...], # 「知能」の単語ベクトル
...
[0.9 -0.3 -0.1 3.0 ...] # 「た」の単語ベクトル
]
単語のベクトルは例えばWord2Vecで学習済みのものがあればそれを使う方が精度が良いらしいですが、一旦はPyTorchの torch.nn.Embedding を使いましょう。こいつの詳細はPyTorchのチュートリアルに任せますが、要はランダムな単語ベクトル群を生成してくれるやつです。実際に使ってみると分かりやすいです。
import torch
import torch.nn as nn
# 以下の宣言で行が単語ベクトル、列が単語のインデックスのマトリクスを生成してる感じ
embeds = nn.Embedding(10, 6) # (Embedding(単語の合計数, ベクトル次元数))
# 3行目の要素を取り出したいならば
w1 = torch.tensor([2])
print(embeds(w1))
# tensor([[-1.5947, -0.8387, 0.7669, -0.9644, -0.7902, 2.7167]],
# grad_fn=<EmbeddingBackward>)
# 3行目、5行目、10行目の要素を取り出したいならば、
w2 = torch.tensor([2,4,9])
print(embeds(w2))
# tensor([[-1.5947, -0.8387, 0.7669, -0.9644, -0.7902, 2.7167],
# [ 0.0405, 1.4236, 0.1947, 0.2609, 0.2047, -1.4964],
# [ 1.7325, -0.2543, -0.5139, -0.9527, -0.1344, 0.0984]],
# grad_fn=<EmbeddingBackward>)
torch.nn.Embeddingを使えば文章を簡単に2次元のマトリクスにすることができます。そのために、文章を単語IDの系列データとして変換すれば、さくっと文章を2次元のマトリクスにできそうです。文章を形態素解析して、全ての単語にIDを割り振って、文章を単語IDの系列データにする前の一連の流れは、例えば以下のような感じでよいでしょう。
(形態素解析にはとりえあずMeCab使います。前処理で英数字や記号は諸々削除していますが、実際は要件に応じて相談。)
import MeCab
import re
import torch
tagger = MeCab.Tagger("-Owakati")
def make_wakati(sentence):
# MeCabで分かち書き
sentence = tagger.parse(sentence)
# 半角全角英数字除去
sentence = re.sub(r'[0-90-9a-zA-Za-zA-Z]+', " ", sentence)
# 記号もろもろ除去
sentence = re.sub(r'[\._-―─!@#$%^&\-‐|\\*\“()_■×+α※÷⇒—●★☆〇◎◆▼◇△□(:〜~+=)/*&^%$#@!~`){}[]…\[\]\"\'\”\’:;<>?<>〔〕〈〉?、。・,\./『』【】「」→←○《》≪≫\n\u3000]+', "", sentence)
# スペースで区切って形態素の配列へ
wakati = sentence.split(" ")
# 空の要素は削除
wakati = list(filter(("").__ne__, wakati))
return wakati
# テスト
test = "【人工知能】は「人間」の仕事を奪った"
print(make_wakati(test))
# ['人工', '知能', 'は', '人間', 'の', '仕事', 'を', '奪っ', 'た']
# 単語ID辞書を作成する
word2index = {}
for title in datasets["title"]:
wakati = make_wakati(title)
for word in wakati:
if word in word2index: continue
word2index[word] = len(word2index)
print("vocab size : ", len(word2index))
# vocab size : 13229
# 文章を単語IDの系列データに変換
# PyTorchのLSTMのインプットになるデータなので、もちろんtensor型で
def sentence2index(sentence):
wakati = make_wakati(sentence)
return torch.tensor([word2index[w] for w in wakati], dtype=torch.long)
# テスト
test = "例のあのメニューも!ニコニコ超会議のフードコートメニュー14種類紹介(前半)"
print(sentence2index(test))
# tensor([11320, 3, 449, 5483, 26, 3096, 1493, 1368, 3, 11371, 7835, 174, 8280])
これらを組み合わせると、以下のように文章を2次元のマトリクスにできます。
# 全単語数を取得
VOCAB_SIZE = len(word2index)
# 単語のベクトル数
EMBEDDING_DIM = 10
test = "ユージの前に立ちはだかったJOY「僕はAKBの高橋みなみを守る」"
# 単語IDの系列データに変換
inputs = sentence2index(test)
# 各単語のベクトルをまとめて取得
embeds = nn.Embedding(VOCAB_SIZE, EMBEDDING_DIM)
sentence_matrix = embeds(inputs)
print(sentence_matrix.size())
print(sentence_matrix)
# torch.Size([13, 10])
# tensor([[ 0.5991, 0.2086, 1.6805, -0.2688, -0.5661, 1.0238, -0.8815, 2.0745, 0.8218, -1.0922],
# [-0.7200, 1.3530, -1.7728, -0.3340, -0.2927, -0.2114, 0.1669, 1.4174, 1.0367, -0.1559],
# [ 2.0492, -0.0129, -0.1688, -0.4127, -1.8662, 0.6761, 0.0921, 0.3018, 0.0510, -0.9186],
# [-0.0932, -0.4891, 0.5047, -0.2488, -2.6789, 0.3175, 0.4011, 0.9005, 0.8657, -0.7729],
# [ 0.6532, 0.8718, -0.6497, 0.5400, -0.1419, 0.8451, -0.5677, 0.1743, -0.0216, 0.8146],
# [-1.2233, -0.9399, 0.2994, 0.9843, 0.6436, -0.1621, 0.6975, -0.4586, 0.9937, -0.4859],
# [ 1.1178, -1.2890, 0.6551, -0.3249, -0.1036, -0.4176, -1.6938, -0.6290, -2.7653, -0.1765],
# [ 0.5090, 1.4671, -0.8971, 1.3293, -0.5948, -1.7585, 0.0609, 0.1469, -0.9665, -0.4266],
# [-0.7200, 1.3530, -1.7728, -0.3340, -0.2927, -0.2114, 0.1669, 1.4174, 1.0367, -0.1559],
# [ 0.6907, 1.8703, 0.1093, -0.2989, -0.7074, -0.1824, -1.1053, 0.6469, -1.0702, 2.3492],
# [ 1.1241, -0.8715, 0.4012, -0.5327, -0.1104, 1.7967, -0.9907, 1.4248, -1.7789, 1.6670],
# [ 0.2470, 1.8372, 0.9765, 0.5153, 0.0936, 0.2957, -1.7517, -0.0556, -2.0370, -0.7433],
# [-0.3896, 1.6902, -2.0145, -0.0156, 0.4149, 0.7111, 1.3389, -0.1780, -1.5560, -1.0672]],
# grad_fn=<EmbeddingBackward>)
最後に、これだけだとバッチサイズが考慮されていないので実際にLSTMに食わせると次元数がおかしいと怒られます。
今回は(とりあえず)バッチサイズは1とします。上記のように文章を2次元のマトリクスにしたのですが、PyTorchのtensor型なので、view関数を使えばいい感じに変換できます。viewについてはPyTorchのチュートリアルを見るのがよいですが、要は以下のような感じで。
sentence_matrix.view(len(sentence_matrix), 1, -1).size()
# torch.Size([13, 1, 10])
これで文章をLSTMにくわせる準備が整いました。
モデル定義
これからLSTMによる分類器の作成に入るわけですが、PyTorchでLSTMを使う場合、torch.nn.LSTMを使います。こいつの詳細はPyTorchのチュートリアルを見るのが良いですが、どんなものかはとりあえず使ってみると見えてきます。
VOCAB_SIZE = len(word2index)
EMBEDDING_DIM = 10
HIDDEN_DIM = 128
embeds = nn.Embedding(VOCAB_SIZE, EMBEDDING_DIM)
lstm = nn.LSTM(EMBEDDING_DIM, HIDDEN_DIM)
s1 = "震災をうけて感じた、大切だと思ったこと"
print(make_wakati(s1))
# ['震災', 'を', 'うけ', 'て', '感じ', 'た', '大切', 'だ', 'と', '思っ', 'た', 'こと']
inputs1 = sentence2index(s1)
emb1 = embeds(inputs1)
lstm_inputs1 = emb1.view(len(inputs1), 1, -1)
out1, out2 = lstm(lstm_inputs1)
print(out1)
print(out2)
# out1
# tensor([[[-0.0146, -0.0069, 0.0323, ..., -0.0091, -0.0313, 0.0114]],
# [[-0.0321, -0.0447, 0.0491, ..., 0.0175, -0.0253, 0.0031]],
# [[-0.0091, -0.0532, 0.0144, ..., -0.0411, -0.0329, -0.0310]],
# ...,
# [[-0.0061, 0.0423, 0.0123, ..., -0.0647, -0.0303, -0.0459]],
# [[-0.0410, 0.0180, 0.0554, ..., -0.0595, -0.0158, -0.0479]],
# [[ 0.0323, -0.0564, -0.0181, ..., 0.0236, -0.0057, 0.0101]]],
# grad_fn=<StackBackward>)
# out2
# (tensor([[[ 0.0323, -0.0564, -0.0181, 0.0247, -0.0147, 0.0248, 0.0125,
# (長いので省略)
# -0.0057, 0.0101]]], grad_fn=<StackBackward>),
# tensor([[[ 0.0711, -0.1137, -0.0448, 0.0477, -0.0253, 0.0564, 0.0251,
# -0.1323, 0.1250, 0.0682, 0.0218, -0.0083, -0.0245, 0.0315,
# (長いので省略)
# -0.0124, 0.0266]]], grad_fn=<StackBackward>))
LSTMのリファレンスに書いてある通り、torch.nn.LSTMのoutputはoutput,(h_n, c_n) = torch.nn.LSTMという形式です。これを理解するにはLSTMのネットワークを思い出す必要があります。
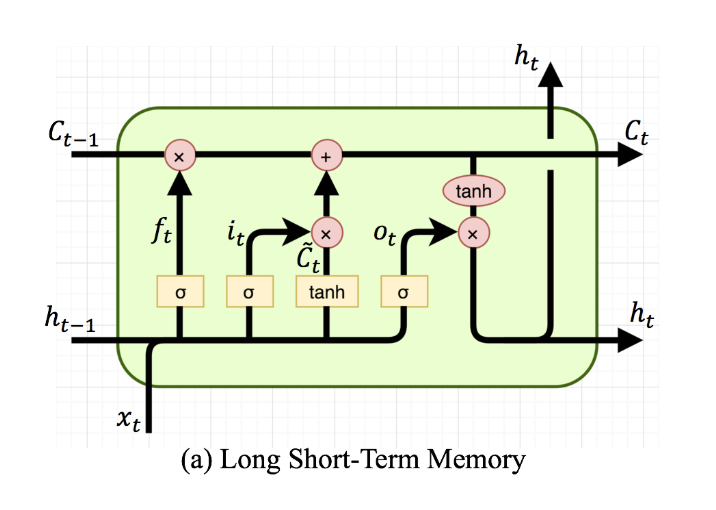
LSTMの(隠れ層の)ネットワークは上図の通り3つ(上矢印の$h_t$, $C_t$, 左矢印の$h_t$)あるのですが、これらがtorch.nn.LSTMの各戻り値に対応しています。
- output :全ての隠れ層の(上矢印の)$h_t$.上記の例でいえば、「震災」の$h_t$が
out1[0]であり、out1[0]と「を」の$h_t$がout1[1]であり...といった具合です。上の例はインプットの系列の長さが12なので、当然len(out1) = 12です。 - (h_t, C_t): 最後の隠れ層の$h_t$と$C_t$です。つまり、 上記の例でいれば、
out1[11] = out2[0]です。
これらのどの戻り値を使うべきかは、LSTMで解きたいタスクによります。
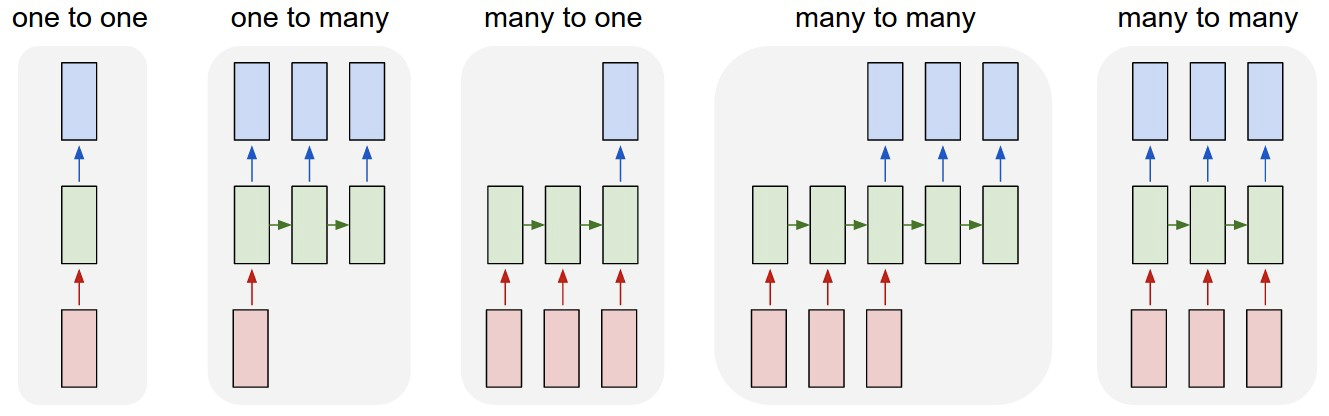
今回の例で言えば、文章(many)を1つのカテゴリに分類(one)したいので、 many to one のモデルです。なので、LSTMの最後の隠れ層の出力$h_t$を使うことになるでしょう。上記の例で言えばout1[11]かout2[0]を使えば良いことになります。many to manyのタスクを解きたければLSTMの第一戻り値を使えばよいです。
あとは、LSTMの戻り値を全結合層で次元を整えながらsoftmax食わせて出力すればOK。例えば以下の様な感じ。
# nn.Moduleを継承して新しいクラスを作る。決まり文句
class LSTMClassifier(nn.Module):
# モデルで使う各ネットワークをコンストラクタで定義
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size):
# 親クラスのコンストラクタ。決まり文句
super(LSTMClassifier, self).__init__()
# 隠れ層の次元数。これは好きな値に設定しても行列計算の過程で出力には出てこないので。
self.hidden_dim = hidden_dim
# インプットの単語をベクトル化するために使う
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
# LSTMの隠れ層。これ1つでOK。超便利。
self.lstm = nn.LSTM(embedding_dim, hidden_dim)
# LSTMの出力を受け取って全結合してsoftmaxに食わせるための1層のネットワーク
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
# softmaxのLog版。dim=0で列、dim=1で行方向を確率変換。
self.softmax = nn.LogSoftmax(dim=1)
# 順伝播処理はforward関数に記載
def forward(self, sentence):
# 文章内の各単語をベクトル化して出力。2次元のテンソル
embeds = self.word_embeddings(sentence)
# 2次元テンソルをLSTMに食わせられる様にviewで3次元テンソルにした上でLSTMへ流す。
# 上記で説明した様にmany to oneのタスクを解きたいので、第二戻り値だけ使う。
_, lstm_out = self.lstm(embeds.view(len(sentence), 1, -1))
# lstm_out[0]は3次元テンソルになってしまっているので2次元に調整して全結合。
tag_space = self.hidden2tag(lstm_out[0].view(-1, self.hidden_dim))
# softmaxに食わせて、確率として表現
tag_scores = self.softmax(tag_space)
return tag_scores
正解ラベルの変換
上記のネットワークのoutputがいわば予測の結果になるわけですが、その形式をみると、
tensor([[ -0.5003, -3.5191, -8.0818, -2.5900, -8.1883, -8.2956, -11.2307,
-11.2474, -1.2442]], grad_fn=<LogSoftmaxBackward>)
こんな感じでtorch.Size([1, 9])となっています。今回分類したいカテゴリの数が全部で9つあったので、要素が9個あるわけです。これの意味するところは各要素が各カテゴリである確率的なものを表しています。(LogSoftmaxなので、0~1の値ではないですが)
一番大きい値がネットワークの予測結果として使うことができます。
なので、各要素をどのカテゴリの確率にするかをこちらで決めないといけないわけですが、そのために以下のように分類先のカテゴリにIDを割り振って、そのIDの値を持つtensorを返す関数を用意します。
category2index = {}
for cat in categories:
if cat in category2index: continue
category2index[cat] = len(category2index)
print(category2index)
# {'movie-enter': 0, 'it-life-hack': 1, 'kaden-channel': 2, 'topic-news': 3, 'livedoor-homme': 4, 'peachy': 5, 'sports-watch': 6, 'dokujo-tsushin': 7, 'smax': 8}
def category2tensor(cat):
return torch.tensor([category2index[cat]], dtype=torch.long)
print(category2tensor("it-life-hack"))
# tensor([1])
これを上のネットワークの予測結果と共に損失関数のインプットとして使います。
学習
ここまでくれば、あとは上記のモデルで系列を学習すれば良いです。損失関数や最適化の手法は一旦チュートリアルに記載されているものをそのまま使いましょう。例えば以下の様な感じで。
from sklearn.model_selection import train_test_split
import torch.optim as optim
# 元データを7:3に分ける(7->学習、3->テスト)
traindata, testdata = train_test_split(datasets, train_size=0.7)
# 単語のベクトル次元数
EMBEDDING_DIM = 10
# 隠れ層の次元数
HIDDEN_DIM = 128
# データ全体の単語数
VOCAB_SIZE = len(word2index)
# 分類先のカテゴリの数
TAG_SIZE = len(categories)
# モデル宣言
model = LSTMClassifier(EMBEDDING_DIM, HIDDEN_DIM, VOCAB_SIZE, TAG_SIZE)
# 損失関数はNLLLoss()を使う。LogSoftmaxを使う時はこれを使うらしい。
loss_function = nn.NLLLoss()
# 最適化の手法はSGDで。lossの減りに時間かかるけど、一旦はこれを使う。
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 各エポックの合計loss値を格納する
losses = []
# 100ループ回してみる。(バッチ化とかGPU使ってないので結構時間かかる...)
for epoch in range(100):
all_loss = 0
for title, cat in zip(traindata["title"], traindata["category"]):
# モデルが持ってる勾配の情報をリセット
model.zero_grad()
# 文章を単語IDの系列に変換(modelに食わせられる形に変換)
inputs = sentence2index(title)
# 順伝播の結果を受け取る
out = model(inputs)
# 正解カテゴリをテンソル化
answer = category2tensor(cat)
# 正解とのlossを計算
loss = loss_function(out, answer)
# 勾配をセット
loss.backward()
# 逆伝播でパラメータ更新
optimizer.step()
# lossを集計
all_loss += loss.item()
losses.append(all_loss)
print("epoch", epoch, "\t" , "loss", all_loss)
print("done.")
上記を実行すると以下のように各epochの損失の合計が出力され、だんだん損失が減っていく様子が伺えると思います。
epoch 0 loss 10668.673820495605
epoch 1 loss 9863.269760727882
〜省略〜
epoch 16 loss 3090.170276284218
epoch 17 loss 2631.8297827243805
〜省略〜
epoch 46 loss 38.32667517662048
epoch 47 loss 37.58159351348877
〜省略〜
epoch 98 loss 26.222567558288574
epoch 99 loss 26.151493310928345
done.
損失をグラフで可視化すると、epoch30あたりからほとんど学習してないことがわかります。
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(losses)

予測精度確認
学習したモデルを使ってテストデータを評価してみます。下記のポイントはtorch.no_grad()です。with torch.no_grad():以下に書かれたコードでは、データがネットワークを通る際にautogradによる勾配の自動計算を行わないようにしています。
# テストデータの母数計算
test_num = len(testdata)
# 正解の件数
a = 0
# 勾配自動計算OFF
with torch.no_grad():
for title, category in zip(testdata["title"], testdata["category"]):
# テストデータの予測
inputs = sentence2index(title)
out = model(inputs)
# outの一番大きい要素を予測結果をする
_, predict = torch.max(out, 1)
answer = category2tensor(category)
if predict == answer:
a += 1
print("predict : ", a / test_num)
# predict : 0.6118391323994578
全然精度よくない...
ちょっとだけ分析
過学習を疑う
学習データで予測してみると...
traindata_num = len(traindata)
a = 0
with torch.no_grad():
for title, category in zip(traindata["title"], traindata["category"]):
inputs = sentence2index(title)
out = model(inputs)
_, predict = torch.max(out, 1)
answer = category2tensor(category)
if predict == answer:
a += 1
print("predict : ", a / traindata_num)
# predict : 0.9984505132674801
思いっきり過学習してるっぽいかも...
Fスコアを見てみる
import collections
# IDをカテゴリに戻す用
index2category = {}
for cat, idx in category2index.items():
index2category[idx] = cat
# answer -> 正解ラベル、predict->LSTMの予測結果、exact->正解してたらO,間違っていたらX
predict_df = pd.DataFrame(columns=["answer", "predict", "exact"])
# 予測して結果を上のDFに格納
with torch.no_grad():
for title, category in zip(testdata["title"], testdata["category"]):
out = model(sentence2index(title))
_, predict = torch.max(out, 1)
answer = category2tensor(category)
exact = "O" if predict.item() == answer.item() else "X"
s = pd.Series([answer.item(), predict.item(), exact], index=predict_df.columns)
predict_df = predict_df.append(s, ignore_index=True)
# Fスコア格納用のDF
fscore_df = pd.DataFrame(columns=["category", "all","precison", "recall", "fscore"])
# 分類器が答えた各カテゴリの件数
prediction_count = collections.Counter(predict_df["predict"])
# 各カテゴリの総件数
answer_count = collections.Counter(predict_df["answer"])
# Fスコア求める
for i in range(9):
all_count = answer_count[i]
precision = len(predict_df.query('predict == ' + str(i) + ' and exact == "O"')) / prediction_count[i]
recall = len(predict_df.query('answer == ' + str(i) + ' and exact == "O"')) / all_count
fscore = 2*precision*recall / (precision + recall)
s = pd.Series([index2category[i], all_count, round(precision, 2), round(recall, 2), round(fscore, 2)], index=fscore_df.columns)
fscore_df = fscore_df.append(s, ignore_index=True)
print(fscore_df)
以下のような感じになった
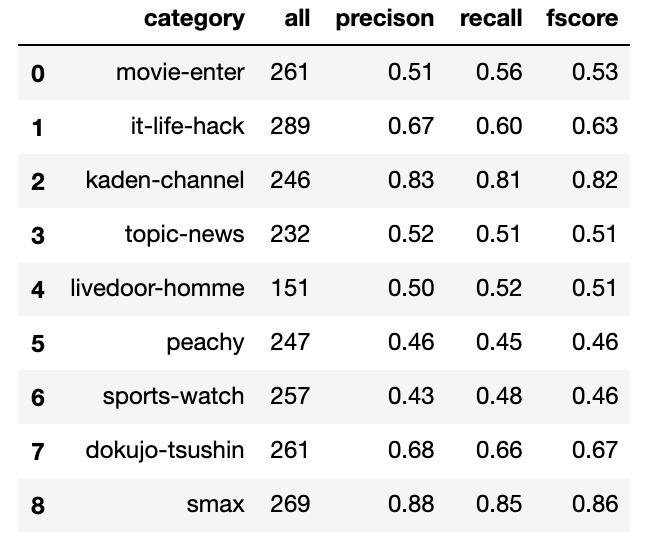
Fスコアに結構ばらつきがあります。smax、kaden-channelは良さげだけど、peachy、sports-watchがよろしくなさげ。
topic-newsが一番悪くなると思ってたけど、そういうわけでもなかった。(topic-newsはカテゴリというよりかは主要ニュースって感じでカテゴリが限定されているわけではないので)
本記事はあくまでPyTorchによるLSTMの実装方法が目的なので、今回の問題に対する精度については、これ以上立ち入らない様にしますが、これ以上精度をあげるなら、
- 各カテゴリの誤判定(なんのカテゴリをなんのカテゴリを勘違いしたか)を集計してみる
- ってか形態素が雑(せめて品詞を限定するとかstopwords入れるとかして)
- こういったニュース記事のタイトルの分類って各分類で特定の単語とか使われてそうだから、LSTMなんかよりも無難にword2vecやTF-IDFでまずやってみる
- ってかまずはデータをよく見ろ
とかしたほうがいいんだろうなぁと思いました。
おわりに
Next → PyTorchを使ってLSTMで文章分類を実装してみた(バッチ化対応)
おわり