目次
本記事はPyTorchを使って自然言語処理 $\times$ DeepLearningをとりあえず実装してみたい、という方向けの入門講座になっております。以下の順番で読み進めていただくとPyTorchを使った自然言語処理の実装方法がなんとなくわかった気になれるかもしれません。
- PyTorchを使ってLSTMで文章分類を実装してみた
- PyTorchを使ってLSTMで文章分類を実装してみた(バッチ化対応ver)
- PyTorchでSeq2Seqを実装してみた ←イマココ
- PyTorchでAttention Seq2Seqを実装してみた
- PyTorchのBidirectional LSTMのoutputの仕様を確認してみた
- PyTorchでSelf Attentionによる文章分類を実装してみた
- PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた
はじめに
LSTMに引き続き、今度はPytorchでseq2seqの実装してみました。
以下の参考記事や書籍で仕組みや実装方法を勉強させていただきました。
※独学ゆえ、説明や実装が間違っている可能性があります。変なこと書いてたらぜひご指摘ください!
参考記事/書籍
- PyTorchによるSeq2seqの実装
- ゼロから作るDeep Learning ❷ ―自然言語処理編
- Sequence to Sequence Learning
with Neural Networks
Seq2Seqとは?
Seq2Seq(sequence to sequence)は、以下で説明するEncoderとDecoderを備えたEncoder-Decoderモデルを使って、系列データを別の系列データに変換するモデルのことを指します。
ご想像の通り、seq2seqで翻訳をしたり、対話モデルを作ったりすることが可能になります。
Encoder
InputData(画像、テキスト、音声、動画etc)を何かしらの(固定長)特徴ベクトルに変換する機構のことを言います。
そのまんまですが、InputDataを抽象的なベクトルにエンコードしてるイメージ。

Decoder
Encoderでエンコードされた特徴ベクトルをデコードして何か新しいデータを生む機構のことをいいます。
OutputDataはInputDataと同じデータ形式である必要はなく、画像、テキスト、音声いろいろ

Encoder-Decoderモデル
- 上のEncoderとDecoderをつなげると、Encoder-Decoderモデルの完成
- Encoder-Decoderモデルはいわゆる生成系のモデルであり、画像をテキストにしたり、音声からテキストを生成したり、日本語から英語(テキストから別のテキスト)に変換したりと用途は様々
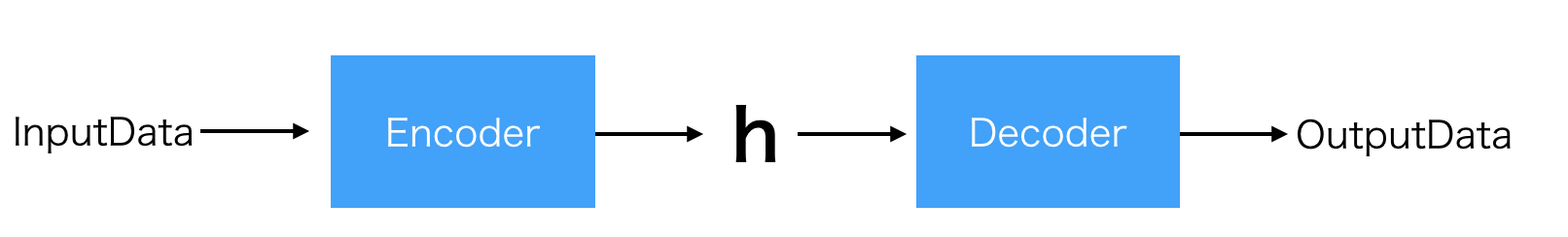
今回はこのSeq2Seqを使って系列データを別の系列データに変換するモデルを実装を通して解説してきます。
問題設定
参考記事に挙げた1.や2.で取り上げられている足し算モデルを扱おうと思ったけど、同じだと面白くないので、少し変更して最大3桁の非負整数同士の引き算をSeq2Seqに学習させてみようと思います。
つまりどういうことかというと、「123-95」をインプットにして「28」をアウトプットに返すようなモデルを作成します。
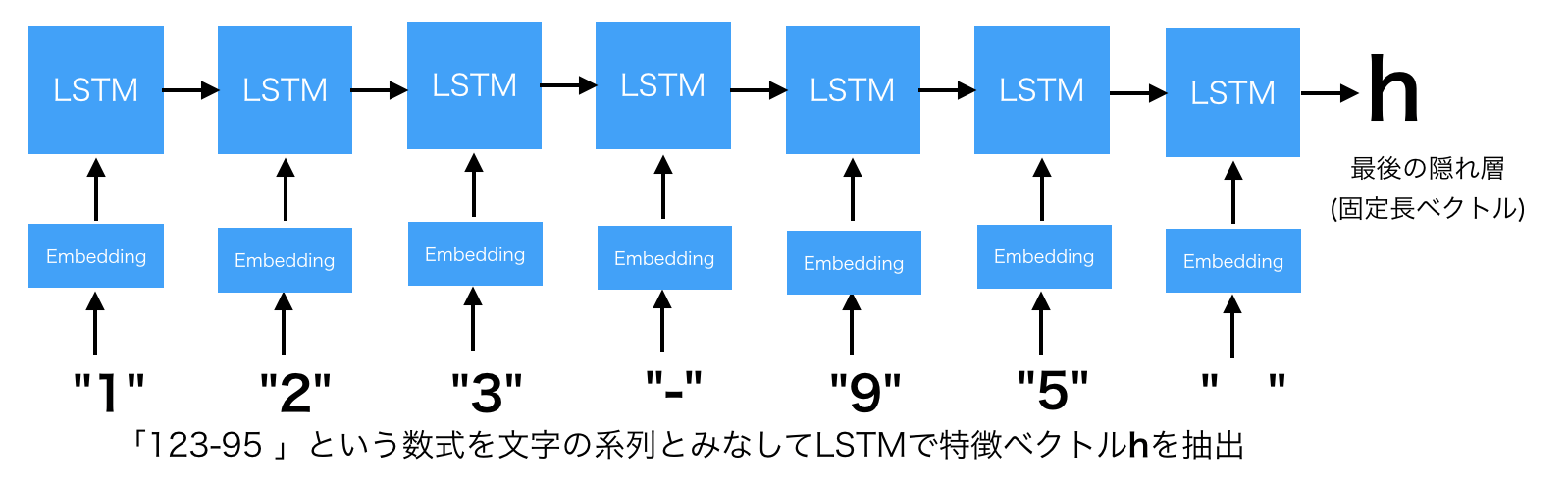
123-95や28を文字の系列データとみなしているわけです。系列データを扱うということはLSTMやGRUのような再帰的ニューラルネットワークが使えそうです。
もちろん今回もバッチ化して学習させたいので系列の長さをすべて揃えます。インプットの最大の長さは「xxx - yyy」で7文字、アウトプットは負の数にもなり得るのでマイナスの記号も含めて最大4文字(ex. -457とか)となりますが、下で説明するように系列生成開始を表す文字列(ここではハイフン"_"とします)を1つ先頭に足す必要があるので最大5文字(_-457とか)になります。
「123-95=28」を例に絵で書くと次のような感じ
Encoder
- Encoder側はいたってシンプルです。以下のようにただLSTMで最後の隠れ層のベクトルを生成すればOK。
- LSTM層の部分はもちろんsimpleなRNNでもGRUでもOK
-
Many to One のモデルです!
Decoder
Decoder側がいろいろややこしいです。推論時と学習時で考え方が異なります。
ここはゼロから作るDeep Learning ❷ ―自然言語処理編にとてもわかりやすく説明があります。下の説明もゼロ作を参考にしているので、わかりにくかったらぜひゼロ作を読んでください!
推論(文字列生成)
- 文字列を生成方法は、以下のようにEncoderの隠れ層と文字生成開始を表す"_"を与えて出力された文字を次のインプットの文字とし、生成された文字を次のインプットに...という操作を生成すべき文字の数だけ繰り返して実行します。

学習
- 上の推論のようなモデルを作成したいわけなので、どのように学習すれば上の推論のようなことが実現できるかを考えます。
- 今回の例は答えが「"28 "」なので、インプットは「"_"」「"2"」「"8"」「" "」の4文字をまとめて与えて、それぞれの層の結果と「"2"」「"8"」「" "」「" "」の損失を計算します。
- Linearの層の値が一番大きいものを予測値とみなせばよいので、softmaxをかます必要はありません。
- Many to Many のモデルです!

実装
- あとは問題設定で説明した内容をひたすら実装するだけ。
- ソースコードはPyTorchによるSeq2seqの実装をがっつり参考にさせていただきました。
データ準備
引き算データセットの準備はどこかから入手する必要もなく、自前で準備すればOK。
from sklearn.model_selection import train_test_split
import random
from sklearn.utils import shuffle
# 数字の文字をID化
char2id = {str(i) : i for i in range(10)}
# 空白(10):系列の長さを揃えるようのパディング文字
# -(11):マイナスの文字
# _(12):系列生成開始を知らせる文字
char2id.update({" ":10, "-":11, "_":12})
# 空白込みの3桁の数字をランダムに生成
def generate_number():
number = [random.choice(list("0123456789")) for _ in range(random.randint(1, 3))]
return int("".join(number))
# 確認
print(generate_number())
# 753
# 系列の長さを揃えるために空白パディング
def add_padding(number, is_input=True):
number = "{: <7}".format(number) if is_input else "{: <5s}".format(number)
return number
# 確認
num = generate_number()
print("\"" + str(add_padding(num)) + "\"")
# "636 "
# 7
# データ準備
input_data = []
output_data = []
# データを50000件準備する
while len(input_data) < 50000:
x = generate_number()
y = generate_number()
z = x - y
input_char = add_padding(str(x) + "-" + str(y))
output_char = add_padding("_" + str(z), is_input=False)
# データをIDに変換
input_data.append([char2id[c] for c in input_char])
output_data.append([char2id[c] for c in output_char])
# 確認
print(input_data[987])
print(output_data[987])
# [1, 5, 11, 2, 6, 6, 10] (←"15-266")
# [12, 11, 2, 5, 1] (←"_-251")
# 7:3にデータをわける
train_x, test_x, train_y, test_y = train_test_split(input_data, output_data, train_size= 0.7)
# データをバッチ化するための関数
def train2batch(input_data, output_data, batch_size=100):
input_batch = []
output_batch = []
input_shuffle, output_shuffle = shuffle(input_data, output_data)
for i in range(0, len(input_data), batch_size):
input_batch.append(input_shuffle[i:i+batch_size])
output_batch.append(output_shuffle[i:i+batch_size])
return input_batch, output_batch
モデル定義
Encoder
- Encoderは簡単。隠れ層を返すだけでOK。
- ちょっと気にしているのが今回はLSTMの第二戻り値 $(h, c)$ をまとめて使っています。 $h$ だけでいいのか $c$ もいるのか、むしろいらないのかは、まだよくわかっていません...
import torch
import torch.nn as nn
import torch.optim as optim
embedding_dim = 200 # 文字の埋め込み次元数
hidden_dim = 128 # LSTMの隠れ層のサイズ
vocab_size = len(char2id) # 扱う文字の数。今回は13文字
# GPU使う用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Encoderクラス
class Encoder(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(Encoder, self).__init__()
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=char2id[" "])
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
def forward(self, sequence):
embedding = self.word_embeddings(sequence)
# Many to Oneなので、第2戻り値を使う
_, state = self.lstm(embedding)
# state = (h, c)
return state
Decoder
Decoderの予測値は最大値をそのまま使えばいいので、softmaxは不要
# Decoderクラス
class Decoder(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(Decoder, self).__init__()
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=char2id[" "])
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
# LSTMの128次元の隠れ層を13次元に変換する全結合層
self.hidden2linear = nn.Linear(hidden_dim, vocab_size)
def forward(self, sequence, encoder_state):
embedding = self.word_embeddings(sequence)
# Many to Manyなので、第1戻り値を使う。
# 第2戻り値は推論時に次の文字を生成するときに使います。
output, state = self.lstm(embedding, encoder_state)
output = self.hidden2linear(output)
return output, state
モデル宣言、損失関数、最適化
# GPU使えるように。
encoder = Encoder(vocab_size, embedding_dim, hidden_dim).to(device)
decoder = Decoder(vocab_size, embedding_dim, hidden_dim).to(device)
# 損失関数
criterion = nn.CrossEntropyLoss()
# 最適化
encoder_optimizer = optim.Adam(encoder.parameters(), lr=0.001)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=0.001)
学習
Decoderの部分が参考にしている記事とちょっと違うけど、PyTorchの仕様的にこれでいいよね?
BATCH_NUM = 100
EPOCH_NUM = 100
all_losses = []
print("training ...")
for epoch in range(1, EPOCH_NUM+1):
epoch_loss = 0 # epoch毎のloss
# データをミニバッチに分ける
input_batch, output_batch = train2batch(train_x, train_y, batch_size=BATCH_NUM)
for i in range(len(input_batch)):
# 勾配の初期化
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# データをテンソルに変換
input_tensor = torch.tensor(input_batch[i], device=device)
output_tensor = torch.tensor(output_batch[i], device=device)
# Encoderの順伝搬
encoder_state = encoder(input_tensor)
# Decoderで使うデータはoutput_tensorを1つずらしたものを使う
# Decoderのインプットとするデータ
source = output_tensor[:, :-1]
# Decoderの教師データ
# 生成開始を表す"_"を削っている
target = output_tensor[:, 1:]
loss = 0
# 学習時はDecoderはこのように1回呼び出すだけでグルっと系列をループしているからこれでOK
# sourceが4文字なので、以下でLSTMが4回再帰的な処理してる
decoder_output, _ = decoder(source, encoder_state)
# decoder_output.size() = (100,4,13)
# 「13」は生成すべき対象の文字が13文字あるから。decoder_outputの3要素目は
# [-14.6240, -3.7612, -11.0775, ..., -5.7391, -15.2419, -8.6547]
# こんな感じの値が入っており、これの最大値に対応するインデックスを予測文字とみなす
for j in range(decoder_output.size()[1]):
# バッチ毎にまとめてloss計算
# 生成する文字は4文字なので、4回ループ
loss += criterion(decoder_output[:, j, :], target[:, j])
epoch_loss += loss.item()
# 誤差逆伝播
loss.backward()
# パラメータ更新
# Encoder、Decoder両方学習
encoder_optimizer.step()
decoder_optimizer.step()
# 損失を表示
print("Epoch %d: %.2f" % (epoch, epoch_loss))
all_losses.append(epoch_loss)
if epoch_loss < 1: break
print("Done")
# training ...
# Epoch 1: 1889.10
# Epoch 2: 1395.36
# Epoch 3: 1194.29
# Epoch 4: 1049.05
# Epoch 5: 931.19
# Epoch 6: 822.30
# 〜略〜
# Epoch 96: 4.47
# Epoch 97: 126.06
# Epoch 98: 32.81
# Epoch 99: 12.69
# Epoch 100: 6.20
# Done
損失可視化
いい感じに損失減ってますが、最後らへんがちょっと迷った感じ?もう少し学習回数増やしたほうが良さそう
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(all_losses)

予測
ここらへんから完全に我流で書いちゃっているので急に読みにくくなるかもです...
# Decoderのアウトプットのテンソルから要素が最大のインデックスを返す。つまり生成文字を意味する
def get_max_index(decoder_output):
results = []
for h in decoder_output:
results.append(torch.argmax(h))
return torch.tensor(results, device=device).view(BATCH_NUM, 1)
# 評価用データ
test_input_batch, test_output_batch = train2batch(test_x, test_y)
input_tensor = torch.tensor(test_input_batch, device=device)
predicts = []
for i in range(len(test_input_batch)):
with torch.no_grad(): # 勾配計算させない
encoder_state = encoder(input_tensor[i])
# Decoderにはまず文字列生成開始を表す"_"をインプットにするので、"_"のtensorをバッチサイズ分作成
start_char_batch = [[char2id["_"]] for _ in range(BATCH_NUM)]
decoder_input_tensor = torch.tensor(start_char_batch, device=device)
# 変数名変換
decoder_hidden = encoder_state
# バッチ毎の結果を結合するための入れ物を定義
batch_tmp = torch.zeros(100,1, dtype=torch.long, device=device)
# print(batch_tmp.size())
# (100,1)
for _ in range(5):
decoder_output, decoder_hidden = decoder(decoder_input_tensor, decoder_hidden)
# 予測文字を取得しつつ、そのまま次のdecoderのインプットとなる
decoder_input_tensor = get_max_index(decoder_output.squeeze())
# バッチ毎の結果を予測順に結合
batch_tmp = torch.cat([batch_tmp, decoder_input_tensor], dim=1)
# 最初のbatch_tmpの0要素が先頭に残ってしまっているのでスライスして削除
predicts.append(batch_tmp[:,1:])
# バッチ毎の予測結果がまとまって格納されてます。
print(len(predicts))
# 150
print(predicts[0].size())
# (100, 5)
- 上でまとめたpredictsをDataFrameにまとめるための処理を以下で実行
- ついでにaccuracyも計算
import pandas as pd
id2char = {str(i) : str(i) for i in range(10)}
id2char.update({"10":"", "11":"-", "12":""})
row = []
for i in range(len(test_input_batch)):
batch_input = test_input_batch[i]
batch_output = test_output_batch[i]
batch_predict = predicts[i]
for inp, output, predict in zip(batch_input, batch_output, batch_predict):
x = [id2char[str(idx)] for idx in inp]
y = [id2char[str(idx)] for idx in output]
p = [id2char[str(idx.item())] for idx in predict]
x_str = "".join(x)
y_str = "".join(y)
p_str = "".join(p)
judge = "O" if y_str == p_str else "X"
row.append([x_str, y_str, p_str, judge])
predict_df = pd.DataFrame(row, columns=["input", "answer", "predict", "judge"])
# 正解率を表示
print(len(predict_df.query('judge == "O"')) / len(predict_df))
# 0.8492
# 間違えたデータを一部見てみる
print(predict_df.query('judge == "X"').head(10))
- input: 予測対象
- answer: 正解
- predict: 予測結果
- judge: 予測が正しければ"O"、間違っていたら"X"
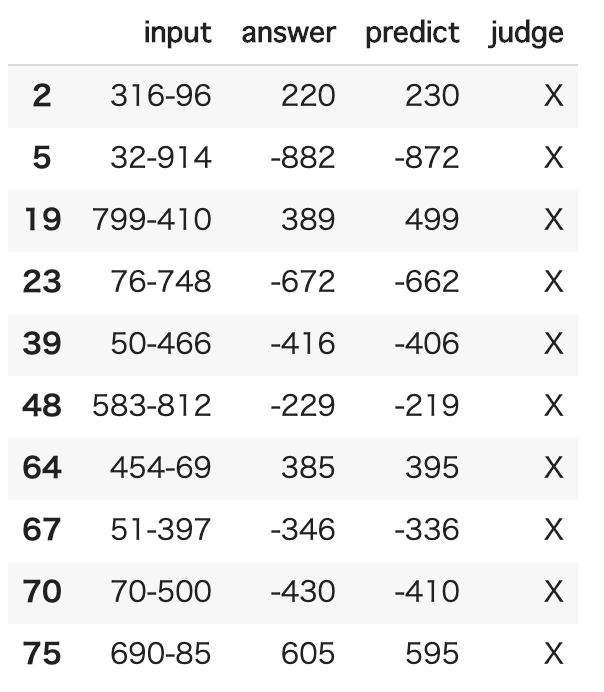
これを見る限り、なんか結果の10の桁が1つずれてしまう傾向がある気がする。人間ではしなさそうな計算ミスをしているような。
おわりに
- もっとepoch数を増やすと90数%くらいの精度まで上がります
- ゼロ作にも書いてますが、精度を更に上げるには覗き見(Peeky)という方法が有効なようです。Encoderの隠れ層をDecoderの最初の層だけに渡すのではなく、各DecoderのLSTM層すべてに渡してしまう、という方法のようです。
- 次はAttentionを扱います! Next→PyTorchでAttention Seq2Seqを実装してみた
おわり