目次
本記事はPyTorchを使って自然言語処理 $\times$ DeepLearningをとりあえず実装してみたい、という方向けの入門講座になっております。以下の順番で読み進めていただくとPyTorchを使った自然言語処理の実装方法がなんとなくわかった気になれるかもしれません。
- PyTorchを使ってLSTMで文章分類を実装してみた
- PyTorchを使ってLSTMで文章分類を実装してみた(バッチ化対応ver)
- PyTorchでSeq2Seqを実装してみた
- PyTorchでAttention Seq2Seqを実装してみた
- PyTorchのBidirectional LSTMのoutputの仕様を確認してみた ←イマココ
- PyTorchでSelf Attentionによる文章分類を実装してみた
- PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた
はじめに
LSTMのリファレンスにあるように、PyTorchでBidirectional LSTMを扱うときはLSTMを宣言する際にbidirectional=Trueを指定するだけでOKと、(KerasならBidrectionalでLSTMを囲むだけでOK)とても簡単に扱うことができます。
が、リファレンスを見てもLSTMをBidirectionalにしたきの出力についてはあまり触れられていないように思います。
ぱっとググってみてもPyTorchにおけるBidirectional LSTMの出力の仕様がいまいちよくわからなかったので、ここに簡単にまとめておきます。
参考
仕様確認
参考1.や2.を見るとわかるように双方向のRNNやLSTMは前方向と後ろ方向のRNNやLSTMが重なっただけと至ってシンプルであることがわかるかと思います。
とりあえず実際に使ってみます。
import torch
import torch.nn as nn
# 各系列の埋め込み次元数を5
# LSTM層の隠れ層のサイズは6
# batch_first=Trueでインプットの形式を(batch_size, vocab_size, embedding_dim)にしてる
# bidrectional=Trueで双方向LSTMを宣言
bilstm = nn.LSTM(5, 6, batch_first=True, bidirectional=True)
# バッチサイズを1
# 系列の長さは4
# 各系列の埋め込み次元数は5
# であるようなtensorを生成する
a = torch.rand(1, 4, 5)
print(a)
# tensor([[[0.1360, 0.4574, 0.4842, 0.6409, 0.1980],
# [0.0364, 0.4133, 0.0836, 0.2871, 0.3542],
# [0.7796, 0.7209, 0.1754, 0.0147, 0.6572],
# [0.1504, 0.1003, 0.6787, 0.1602, 0.6571]]])
# 通常のLSTMと同様に出力は2つあるので両方受け取る
out, hc = bilstm(a)
print(out)
# tensor([[[-0.0611, 0.0054, -0.0828, 0.0416, -0.0570, -0.1117, 0.0902, -0.0747, -0.0215, -0.1434, -0.2318, 0.0783],
# [-0.1194, -0.0127, -0.2058, 0.1152, -0.1627, -0.2206, 0.0747, -0.0210, 0.0307, -0.0708, -0.2458, 0.1627],
# [-0.0163, -0.0568, -0.0266, 0.0878, -0.1461, -0.1745, 0.1097, 0.0230, 0.0353, -0.0739, -0.2186, 0.0818],
# [-0.1145, -0.0460, -0.0732, 0.0950, -0.1765, -0.2599, 0.0063, 0.0143, 0.0124, 0.0089, -0.1188, 0.0996]]],
# grad_fn=<TransposeBackward0>)
print(hc)
# (tensor([[[-0.1145, -0.0460, -0.0732, 0.0950, -0.1765, -0.2599]],
# [[ 0.0902, -0.0747, -0.0215, -0.1434, -0.2318, 0.0783]]],
# grad_fn=<StackBackward>),
# tensor([[[-0.2424, -0.1340, -0.1559, 0.3499, -0.3792, -0.5514]],
# [[ 0.1876, -0.1413, -0.0384, -0.2345, -0.4982, 0.1573]]],
# grad_fn=<StackBackward>))
通常のLSTMと同様に出力はoutとhcと2つあって、hcのほうは通常のLSTMと同様にhc=(h,c)とタプル形式で返ってきます。通常のLSTMの出力と違う点は以下の2つかと思います。
-
outの各要素の次元がLSTMの隠れ層の次元のサイズ(今回は6)ではなく、その倍の値(今回であれば12)になっている -
hcの各要素hやcが2つ返ってきている
これらがどういうことかについて、ずばり図で説明すると以下の通りです。
(cは省略してます。Embedding層も書いちゃったけど、Embedding層はLSTMでやってないです。)
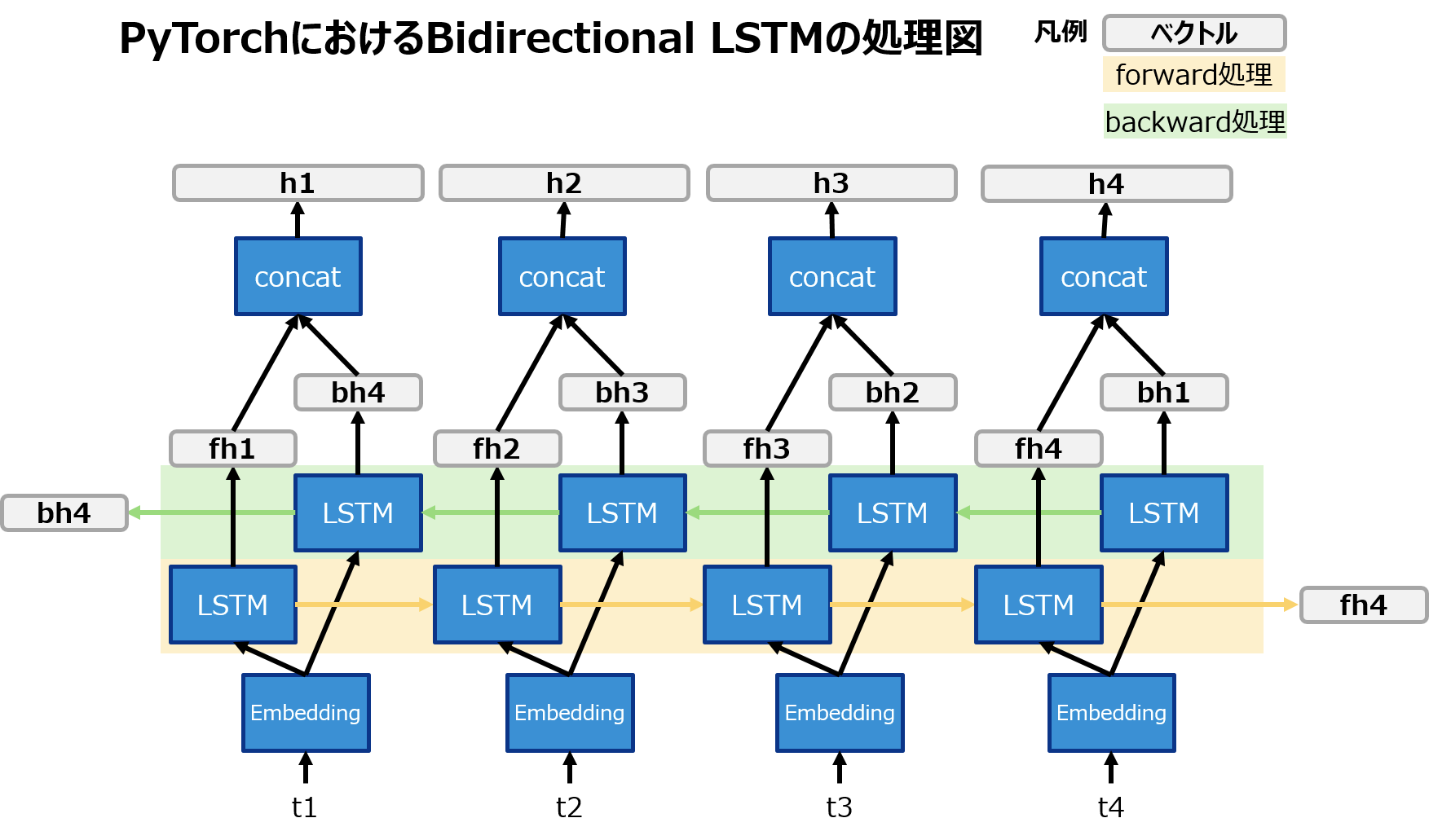
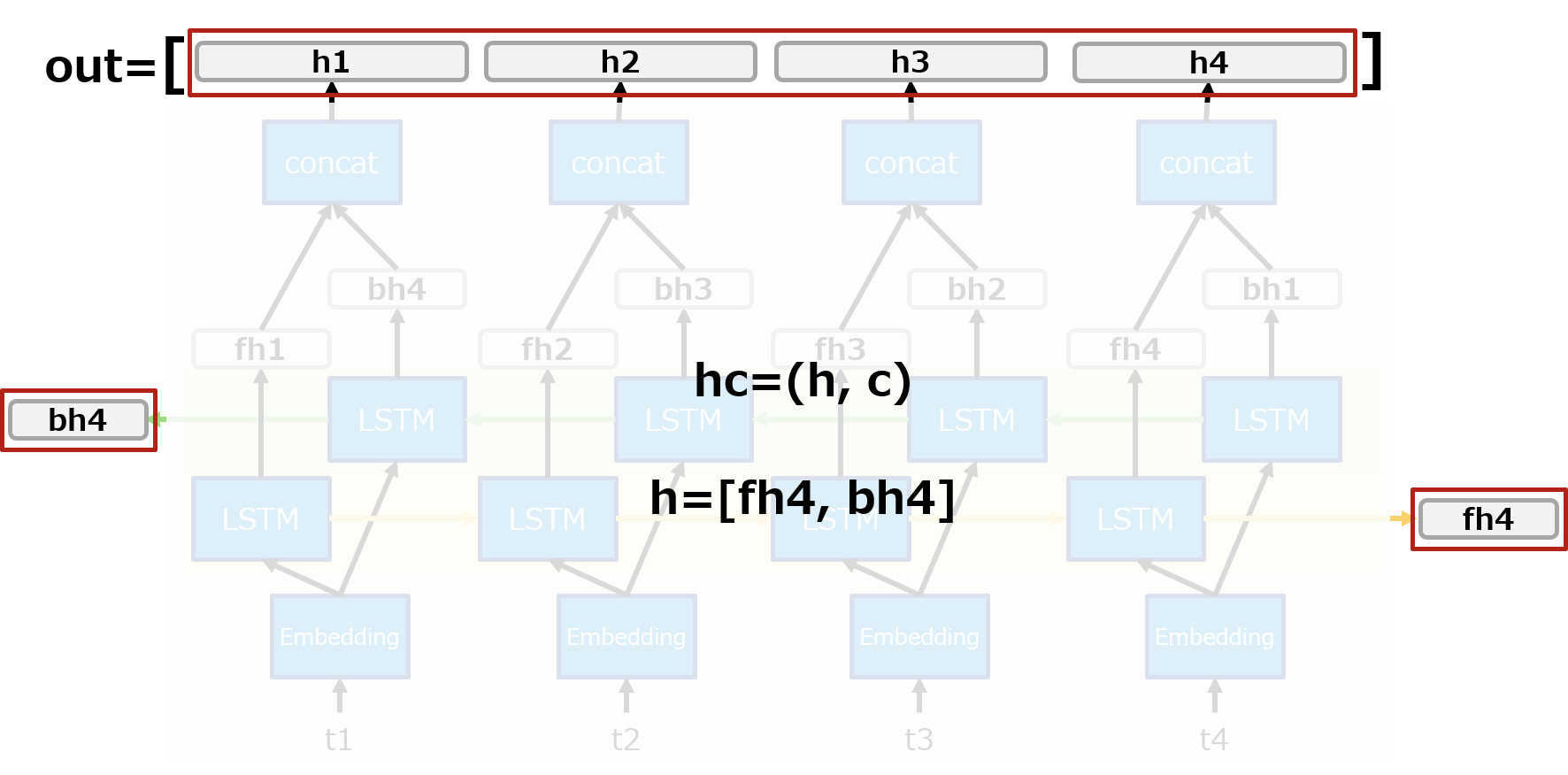
上の図からわかるようにoutの各要素は前方向と後ろ方向の各隠れ層ベクトルを結合しています。(なので各要素の次元が通常の2倍になってる。)
また、hc=(h,c)のhは前方向と後ろ方向のそれぞれの最後の隠れ層ベクトルを返しています。
つまり、
-
outの最後の要素の前半分はhc=(h,c)としたときのh[0]と一致 -
outの最初の要素の後ろ半分はhc=(h,c)としたときのh[1]と一致
することになります。上のサンプルのソースコードの出力からそれが読み取れますが、つまりはこういうこと。
print(out[:,-1][:,:6]) # outの最後の要素の前半分
print(hc[0][0]) # 前方向LSTMの最後の隠れ層の値
# tensor([[-0.1145, -0.0460, -0.0732, 0.0950, -0.1765, -0.2599]], grad_fn=<SliceBackward>)
# tensor([[-0.1145, -0.0460, -0.0732, 0.0950, -0.1765, -0.2599]], grad_fn=<SelectBackward>)
print(out[:,0][:,6:]) # outの最初の要素の後ろ半分
print(hc[0][1]) # 後ろ方向LSTMの最後の隠れ層の値
# tensor([[ 0.0902, -0.0747, -0.0215, -0.1434, -0.2318, 0.0783]], grad_fn=<SliceBackward>)
# tensor([[ 0.0902, -0.0747, -0.0215, -0.1434, -0.2318, 0.0783]], grad_fn=<SelectBackward>)
出力の仕様がわかったらあとはお好きなように料理すればよいですが、
文章分類のようなMany to OneのモデルをBidirectional LSTMにする際はLSTMの第2戻り値を結合したり、平均とったり、要素積をとったりといろいろ方法があるようです。
Kerasの場合なんかは(デフォルトでは)Keras側で結合してくれるようですが、PyTorchの場合はこれらの処理は自前で実装する必要があると思われます。
例えば私が過去に投稿したLSTMによる文章分類をBidirectional LSTMにする場合は以下のような感じになります。
class LSTMClassifier(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size, batch_size=100):
super(LSTMClassifier, self).__init__()
self.batch_size = batch_size
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
self.bilstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True, bidirectional=True)
# 前方向と後ろ方向の最後の隠れ層ベクトルを結合したものを受け取るので、hidden_dimを2倍している
self.hidden2tag = nn.Linear(hidden_dim * 2, tagset_size)
self.softmax = nn.LogSoftmax()
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
_, bilstm_hc = self.bilstm(embeds)
# bilstm_out[0][0]->前方向LSTMの最後の隠れ層ベクトル
# bilstm_out[0][1]->後ろ方向LSTMの最後の隠れ層ベクトル
bilstm_out = torch.cat([bilstm_hc[0][0], bilstm_hc[0][1]], dim=1)
tag_space = self.hidden2tag(bilstm_out)
tag_scores = self.softmax(tag_space.squeeze())
return tag_scores
おわりに
- 世間的にはこんなことすぐにわかりそうな話なのかもしれませんが、自分みたいにPyTorchでBidirectional LSTMを扱うときに一瞬でもあれ?って思った人にこの記事が届いてお調べになるお時間をお助けできれば幸いです。
- ちなみにGRUもLSTMと同様に
bidirectional=TrueでBidirectional GRUになります。出力の形式は上のLSTMの仕様がわかっていれば何の問題もないかと思います。 - 次はこのBidirectional LSTMを使ったSelf Attentionについて扱います! Next → PyTorchでSelf Attentionによる文章分類を実装してみた
おわり