2019/04追記
本記事とほぼ同じ内容をtorchtextと同様なNLPフレームワークであるAllenNLPで書いた記事を公開しました。
0. はじめに
Deep Learning系の技術が流行っていますが、画像認識などの技術に比べて、機械翻訳や文書分類などの自然言語処理系の技術はとっつきにくいと考えられているようです。その原因の大部分を前処理のめんどくささが占めています。どのDeep LearningフレームワークにもLSTMなどのテキストを扱うモデルのチュートリアルがあるのですが、現状
- 簡単すぎるtoyモデルを題材としている
- build in の前処理済みベンチマーク用データセットを題材としている
- データ整備に関する記述が少ない
- ほとんどが英語のデータを扱っており、日本語データを扱うチュートリアルは少ない
という問題点があり、公式のチュートリアルだけでは**「自分で用意した日本語データを使用して、Deep Learningモデルをパッと試してみる」**ことができるようになるまでギャップがある気がします。
そこで、Torchtextというpythonライブラリを中心に、
- 自然言語処理系のDeep Leraningモデル作成時、どの手法やフレームワークでも共通して必要なデータ処理フローの整理
- torchtextを利用してそれらのデータ処理が少ないコーディング量で可能になること
- 英語だけではなく日本語のtextデータも扱える方法
といった内容をまとめようと思います。
この記事ではデータ整備と前処理を中心にコード辺を用いて解説しますが、
- データ整備と前処理
- attentionつき文書分類モデル構築
- attentionの可視化による文書分類の予測理由の提示
も含めたフルのチュートリアルのjupyter notebookを
に上げました。
(宗教上の理由によりpytorchを使って解説しますが、torchtext自体は他のフレームワークとも合わせて使用することができます。)
1. Torchtext とは
torchtext とは自然言語処理関連の前処理を簡単にやってくれる非常に優秀なライブラリです。自分も業務で自然言語処理がからむDeep Learningモデルを構築するときなど大変お世話になっています。torchとついていますが、Pytorchからだけではなく、Tensorflowなどの他のライブラリと一緒に使うこともできます。
torchtextは強力なライブラリなのですが、英語も含めてdocumentは充実していません。既存の記事だと
が参考になります。
2. テキストデータをDeep Learningモデルに入力する際の典型的なデータフロー
自然言語処理のタスクは、文書分類や機械翻訳などたくさんあります。Deep Learningのフレームワークもpytorchやtensorflowなどたくさんあります。しかし、どのタスクをどのフレームワークであつかう場合もtextデータをDeep Neural Networkに入力する際は、たいてい
- センテンスを単語ごとに区切り、
- 単語に番号を振って、
- センテンスを表す番号の列をミニバッチごとにまとめた行列の形
にして渡す必要があります。
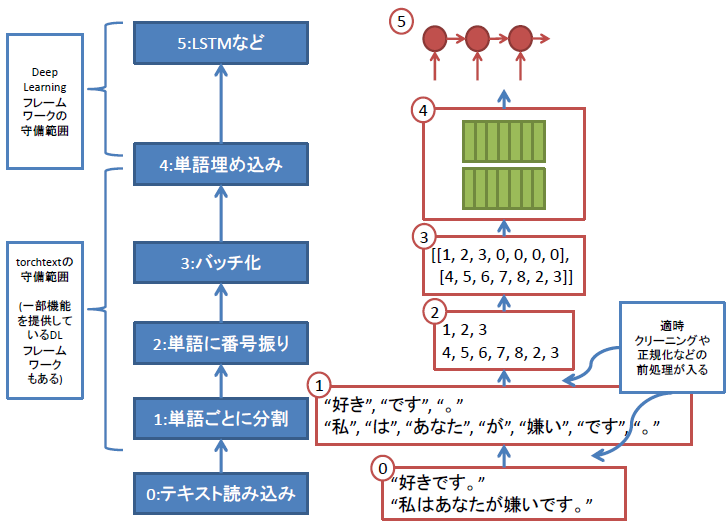
この図の0:テキストデータ読み込み~4:単語埋め込みまでのデータフローの管理をしてくれるのがtorchtextです。
単語埋め込みの部分はDeep learningフレームワークの方で扱う場合が多いですが、学習済み埋め込みベクトルの管理はtorchtextで行えます。
つまり、テキストデータを読み込んで、ミニバッチごとに上図の4の形式の行列を出力するようなiteratorを作成するのがtorchtextの目標です。
以降の章で、上の図の各ステップをtorchtextでどのように記述するのか、説明していきます。
3. 想定データ
今回は文書分類モデル作成を例にtorchtextの機能を説明します。
次のようなサンプルデータ(tsv)を準備します。
I love you. 1
I hate Mike. 0
I like Maki. 1
I don't like you. 0
あなたを愛しています。 1
私はマイクが嫌いです。 0
私はマキがすきです。 1
私はあなたが好きではありません。 0
仮に、日英翻訳モデルを作成するとしたら、
次のようなtsvファイルを用意することになります。
あなたを愛しています。 I love you.
私はマイクが嫌いです。 I hate Mike.
私はマキがすきです。 I like Maki.
私はあなたが好きではありません。 I don't like you.
4. 手順0,1:データの読み込みと単語分割
まず初めにデータを読み込んで、単語に分割(tokenize)する処理に関して説明します。データのtokenizationにかかわってくるのがFieldクラスです。
4.1. Fieldクラス
Fieldクラスは読み込んだデータに施す前処理とその結果を管理するクラスです。
torchtextでは、データを取り込む際、
- 各データソースの各カラムに対して前処理を管理するFieldクラスを指定
- 各カラムごとに、指定されたFieldクラスが管理する前処理が実行される
という流れになります。Fieldクラスが管理する前処理にはテキストのtokenizationも含まれます。
文書分類モデルだと、次のようにtext用のTEXTフィールドとラベル用のLABELフィールドを用意します。
import janome
from janome.tokenizer import Tokenizer
import torchtext
import torch
import spacy
from torchtext import data
from torchtext import datasets
from torchtext.vocab import GloVe
TEXT = data.Field(sequential=True, tokenize=tokenizer, lower=True)
LABEL = data.Field(sequential=False, use_vocab=False)
各引数は次のような意味を持ちます。
- sequential: 対応するデータがtextのように可変長のデータかどうか
- lower: 文字をすべて小文字に変換するかどうか
- tokenize: tokenizeや前処理を記述した関数
tokenizeに使用する関数は文字列を受け取り、前処理+tokenize結果の配列を返す関数です。
ここに記述した処理が、データを読み込んだ時に各カラムの各行に対して適用されます。
例えば、日本語/英語の場合はjanomeやspacyを使用して次のように定義できます。
日本語
from janome.tokenizer import Tokenizer
j_t = Tokenizer()
def tokenizer(text):
return [tok for tok in j_t.tokenize(text, wakati=True)]
>>> print(tokenizer(u'あなたを愛しています。'))
['あなた', 'を', '愛し', 'て', 'い', 'ます', '。']
英語
import spacy
spacy_en = spacy.load('en')
def tokenizer(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
>>> print(tokenizer(u'I love you.'))
['I', 'love', 'you', '.']
ここにhtmlタグ除去などの任意のクリーニング処理を記述することも可能です。
4.1.1. テキストデータのクリーニングに関して
textデータのクリーニングに関しては次の記事が参考になります。
自然言語処理における前処理の種類とその威力
この記事で記述されているクリーニング系の処理のうち、
- 英語の大文字小文字変換
- 出現頻度の低い単語の除去
はtorchtextの機能として実装されています。英語の大文字小文字変換は上のようにFieldのlower引数によって制御します。出現頻度の低い単語の除去は後の章で説明します。
その他のクリーニング処理はあらかじめ入力tsvファイル作成時に行ってもよいですが、htmlタグの除去などは次のようにFieldオブジェクトのtokenizer関数内に記述し、データの読み込みと同時に行うこともできます。
import spacy
from bs4 import BeautifulSoup
spacy_en = spacy.load('en')
def tokenizer(text):
soup = BeautifulSoup(txt)
clean_text = soup.get_text()
return [tok.text for tok in spacy_en.tokenizer(clean_text)]
>>> print(tokenizer(u'<p>I love you.</p>'))
['I', 'love', 'you', '.']
4.2. データの読み込み
データパスと各カラムに対応するFieldを指定してデータを読み込みます。
train, val, test = data.TabularDataset.splits(
path='./', train='train_ja.tsv',
validation='val_ja.tsv', test='test_ja.tsv', format='tsv',
fields=[('Text', TEXT), ('Label', LABEL)])
data.TabularDataset.splitsはデータを読み込んで、datasetオブジェクトを返します。
fields=[('Text', TEXT), ('Label', LABEL)]
という形でfield引数にFieldオブジェクトを渡すと、train_ja.tsvの1列目にTEXT Fieldの、2列目にLABEL Fieldのtokenizerに記述された前処理+単語分割処理が適用されます。そして、それぞれ返り値のdatasetオブジェクトに'Text','Label'という名前で格納されます。
結果は次のように確認できます。
>>> print('len(train)', len(train))
len(train) 4
>>> print('vars(train[0])', vars(train[0]))
vars(train[0]) {'Text': ['i', 'love', 'you', '.'], 'Label': '1'}
5. 手順2:単語へ番号を振る
読み込んだデータに出現した単語のリストを作成し、単語に番号を振ります。Fieldクラスのbuild_vocabメソッドを使用します。
TEXT.build_vocab(train, min_freq=2)
上記のコードでは次のような処理が行われます。
- データ内の各単語の数をカウントし、TEXT.vocab.freqsに格納
- min_freq以上の回数出現した単語に番号を振り、番号から単語への辞書をTEXT.vocab.itosに、単語から番号への辞書をTEXT.vocab.stoiに格納
単語カウントや番号を振った結果は次のように確認できます。
単語カウント結果
>>> TEXT.vocab.freqs
Counter({'.': 4,
'do': 1,
'hate': 1,
'i': 4,
'like': 2,
'love': 1,
'maki': 1,
'mike': 1,
"n't": 1,
'you': 2})
単語-番号辞書
>>> TEXT.vocab.stoi
defaultdict(<function torchtext.vocab._default_unk_index>,
{'.': 2,
'<pad>': 1,
'<unk>': 0,
'do': 0,
'i': 3,
'like': 4,
'maki': 0,
"n't": 0,
'you': 5})
min_freqを2としたので、出現回数が2未満の単語は未知語unk扱いになります。
padはバッチ作成時に使用するダミートークンで、後の章で説明します。
番号-単語
>>> TEXT.vocab.itos
['<unk>', '<pad>', '.', 'i', 'like', 'you']
5.1. 学習済み単語ベクトルについて
build_vocabメソッドのvectors引数を使用すると、単語へ番号を振るのと同時に、学習済みの単語ベクトルを指定し、読み込むことができます。
単語ベクトルは、その言語のすべての単語について保持しておく必要はなく、学習データにおける出現回数がmin_freq以上の単語に対応するベクトルのみメモリ上に保持します。そのため、torchtextでは上記のように単語の出現回数のカウントを行うbuild_vocabメソッドで学習済みの単語ベクトルを読み込んでいます。
独自のベクトル群を指定することもできれば、webで公開されている学習済みベクトルをダウンロードしてくることも可能です。公開されている単語ベクトルの内torchtextが対応しているものはgloveとfasttextとcharngramです。このうち、日本語にも対応しているのはfasttextです。fasttextのベクトルをダウンロードして来て、読み込むには
日本語の場合
from torchtext.vocab import FastText
TEXT.build_vocab(train, vectors=FastText(language="ja"), min_freq=2)
英語の場合
from torchtext.vocab import FastText
TEXT.build_vocab(train, vectors=FastText(language="en"), min_freq=2)
とします。
このように指定すると、単語に番号を振る処理に加えて
- .vector_cache/以下をチェック
- ダウンロード済みでなければ.vector_cache/以下にfasttextで学習したベクトル群をダウンロード
- trainにおける出現回数がmin_freq以上の単語に関して、学習済み単語ベクトルを読み込みTEXT.vocab.vectorsに格納
という処理が走ります。
TEXT.vocab.vectorsは
- 行数:min_freq以上出現した単語数+特殊トークン数(<unk> , <pad>)
- 列数:単語ベクトルの次元。デフォルトだとfasttextは300次元
という行列になります。
>>> TEXT.vocab.vectors.size()
torch.Size([6, 300])
学習済みの単語ベクトルを使用しない場合はvectorsを指定しません。
6. 手順3:バッチ化
data.Iterator.splits はdatasetオブジェクトから、各単語を番号に変換してミニバッチごとにまとめた行列を返すイテレータを作成できます。
train_iter, val_iter, test_iter = data.Iterator.splits(
(train, val, test), batch_sizes=(2, 2, 2), device=-1)
イテレータが返す結果は次のように確認できます。
batch = next(iter(train_iter))
print(batch.Text)
print(batch.Label)
>> Variable containing:
3 3
4 0
0 0
2 4
1 5
1 2
[torch.LongTensor of size 6x2]
Variable containing:
1
0
[torch.LongTensor of size 2]
学習ループでは、このbatch.Textを入力として、Deep Learningモデルによる予測を行い、予測とbatch.Labelを比べて誤差を計算して、学習アルゴリズムを回すことになります。
手順2で作成した番号-単語辞書でbatch.Textを変換すると
i like <unk> . <pad> <pad>
i <unk> <unk> like you .
となります。<pad> トークンはこのようにバッチ化の際、短いtextに追加して、長さをそろえるために使用されます。デフォルトではミニバッチ内で最も長いtextの長さになるまでpaddingされます。
RNNなどの学習でmasked BPTTを使用する際、テキストデータのミニバッチと同時に、ミニバッチ内の各textの長さのデータを渡す必要があります。このtextの長さデータの形式は使用するDeep Learning フレームワークによって異なります。pytorchのRNNモジュールでは各textデータの長さを表す配列を渡せばよいですが、theanoなどでは"mask matrix"を渡す必要があります。(mask matrixはミニバッチと同じサイの行列で、<pad>トークンに対応する部分が0それ以外が1というものです。)
イテレータがテキストの長さデータも返すようにするには、Fieldオブジェクト生成の際include_lengths=Trueとします。
TEXT = data.Field(sequential=True, tokenize=tokenizer, lower=True, include_lengths=True)
このように設定した場合、上記のbatch.Textはテキストデータを表すpadding済みの行列とtextの長さを表す配列のタプルになります。
7. 手順4:単語埋め込みベクトルの使用
手順2で読み込んだ単語埋め込みベクトルは、手順3で作成したイテレータが返す行列内の単語番号をベクトルに変換する際に使用されます。このように単語をベクトル化した結果がLSTMモジュールなどへの直接の入力となります。
単語番号をベクトルに変換するモジュールは各Deep Learningフレームワークに用意されているはずです。(pytorchならnn.Embedding、kerasならlayers.embeddings.Embeddingを使用します。)
例えばpytorchの場合はnn.Embeddingモジュールに次のように埋め込みベクトル(TEXT.vocab.vectors)を渡します。
class EncoderRNN(nn.Module):
def __init__(self, emb_dim, h_dim, v_size, gpu=True, batch_first=True):
super(EncoderRNN, self).__init__()
self.gpu = gpu
self.h_dim = h_dim
self.embed = nn.Embedding(v_size, emb_dim)
self.embed.weight.data.copy_(TEXT.vocab.vectors)
self.lstm = nn.LSTM(emb_dim, h_dim, batch_first=batch_first,
bidirectional=True)
8. 学習の実行
テキストデータを理想的な形に変換して順に出力するイテレータが作成できたので、あとはネットワークを定義して学習を実行するのみです。学習部分のチュートリアルはどのDeep Learningフレームワークにもたくさんあります。学習と結果の可視化などに関しては
torchtextを利用してデータを整備し、attentionつき文書分類モデルを構築して、結果を可視化するjupyter notebookを作成したので、参考になればと思います。
9. 付録:torchtextからベンチマークデータセットを使用する
ここまで自分で用意したデータを使用するための前処理に関して説明してきましたが、torhctextには既存の有名なベンチマークデータセットを簡単に利用するためのモジュール群も用意されています。現状、次のようなデータが使用できます。
- Sentiment analysis: SST and IMDb
- Question classification: TREC
- Entailment: SNLI
- Language modeling: abstract class + WikiText-2
- Machine translation: abstract class + Multi30k, IWSLT, WMT14
- Sequence tagging (e.g. POS/NER): abstract class + UDPOS
このうちIMDBのデータセットを使用してattentionつき文書分類モデルを作成した実験結果を
【 self attention 】簡単に予測理由を可視化できる文書分類モデルを実装する
にのせました。リンク先の実験を行ったコードをgithubにあげてあるのでベンチマークデータセット群の利用方法はそちらを参考にしてください。