0. はじめに
この記事では最新の自然言語処理のフレームワークであるAllenNLPの使い方について紹介します。日本語のデータを使用して、簡単なattentionつき文書分類モデルを作成することを通して、AllenNLPの強力な機能を説明できればと思います。
本記事で使用する、AllenNLPを使用して日本語の文書分類モデルを作成するサンプルはここにあります。
また、本記事を執筆するに際して下記の記事がとても参考になりました。
- 公式チュートリアル
- An In-Depth Tutorial to AllenNLP (From Basics to ELMo and BERT)
- Training a Sentiment Analyzer using AllenNLP (in less than 100 lines of Python code)
1. AllenNLPとは
AllenNLPはPytorchベースの自然言語処理のフレームワークです。さまざまなNLPタスクに対して、Deep Learningモデルの学習/予測を行うための強力な機能群が実装されています。
Deepな自然言語処理といっても、文書分類や機械翻訳などたくさんありますが、学習を行う際はおおむね次のようなパイプラインを組むことになります。
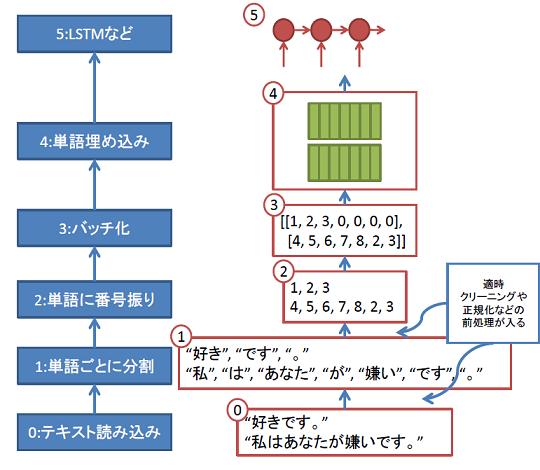
これは、同じく自然言語処理のフレームワークであるtorchtextを解説した記事でものせた図です。(各手順の詳細はそちらを参照してください。)torchtextは0~4が守備範囲ですが、AllenNLPは0~5が守備範囲になります。
AllenNLPの機能面での特徴の一つに、「複雑なモデルを構築する手間を大きく削減する高レイヤーのAPI群の充実」が挙げられますが、今回はどのようなモデルを組む際も必要な、0~4の前処理部分に焦点をあててAllenNLPの使い方を解説します。
2. FieldとInstance
具体的なサンプルに行く前に、AllenNLPでデータをつかさどる2つのクラス(Field, Instance)について説明します。
Field
Fieldはモデルの入力となる各データソースとデータそのものを表します。データソースおのおのにひとずつFieldクラスを定義します。
例:
| タスク | 必要なField |
|---|---|
| テキストのポジネガ分類 | テキストを扱うField, 教師ラベルを扱うField |
| 日英翻訳モデル | 日本語を扱うField, 英語を扱うField |
Fieldクラスは紐づいたデータソースをモデルの入力(テンソル)に変換する方法もつかさどります。Fieldを定義するときに指定するTokenIndexerがそれに当たります。TokenIndexerは単語(文字)の番号付をつかさどるクラスです。(詳しくは後述します。)
Instance
Instanceはモデルの1-inputを表すクラスです。モデルの直接の入力となります。入力Fieldの辞書として表します。
例:
| タスク | Instance |
|---|---|
| テキストのポジネガ分類 | Instance({"tokens":テキストを扱うField, "label":教師ラベルを扱うField}) |
| 日英翻訳モデル | Instance({"jp":日本語を扱うField, "en":英語を扱うField}) |
3. データとタスク
次のようなtsvファイルを読み込んで、テキストのポジネガを判別するモデル学習するサンプルを作成します。
あなたを愛しています。 1
私はマイクが嫌いです。 0
私はマキがすきです。 1
私はあなたが好きではありません。 0
4. 手順0,1:データの読み込みと単語分割
さて、まず初めにデータを読み込んで、単語に分割(tokenize)する処理に関して説明します。データを読み込むパイプラインを扱うDatasetReaderクラスを定義します。DatasetReaderでは、データを読み込み、適切な前処理を行ってモデルの直接の入力となる1つのInstanceを生成する、_readメソッドを実装します。
# coding:utf-8
import janome
from janome.tokenizer import Tokenizer
from pathlib import Path
from typing import *
import torch
import torch.optim as optim
import numpy as np
import pandas as pd
from functools import partial
from overrides import overrides
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from allennlp.data import Instance
from allennlp.data.token_indexers import TokenIndexer
from allennlp.data.tokenizers import Token
from allennlp.data.vocabulary import Vocabulary
from allennlp.data.dataset_readers import DatasetReader
from allennlp.data.fields import TextField, LabelField
from allennlp.data.tokenizers.word_splitter import SpacyWordSplitter
from allennlp.data.token_indexers import SingleIdTokenIndexer
from allennlp.data.iterators import BucketIterator
from allennlp.nn import util as nn_util
from allennlp.models import Model
from allennlp.modules.seq2seq_encoders import Seq2SeqEncoder, PytorchSeq2SeqWrapper
from allennlp.nn.util import get_text_field_mask
from allennlp.modules.text_field_embedders import TextFieldEmbedder
from allennlp.modules.token_embedders import Embedding
from allennlp.modules.text_field_embedders import BasicTextFieldEmbedder
from allennlp.training.trainer import Trainer
from allennlp.predictors.sentence_tagger import SentenceTaggerPredictor
AllenNLPを利用する際はtypingを利用して型の宣言を行います。
class MyReader(DatasetReader):
def __init__(
self,
tokenizer:Callable[[str], List[str]]=lambda x: x.split(),
token_indexers:Dict[str, TokenIndexer]=None,
max_seq_len:Optional[int]=MAX_SEQ_LEN
) -> None:
super().__init__(lazy=False)
self.tokenizer = tokenizer
self.token_indexers = token_indexers or {"tokens":SingleIdTokenIndexer()}
self.max_seq_len = max_seq_len
def text_to_instance(self, tokens:List[Token], label:int=None) -> Instance:
sentence_field = TextField(tokens, self.token_indexers)
fields = {"tokens":sentence_field}
if label is not None:
label_field = LabelField(label, skip_indexing=True)
fields["label"] = label_field
return Instance(fields)
def _read(self, data_path:str) -> Iterator[Instance]:
df = pd.read_csv(data_path, header=None, names=["tokens","label"], sep="\t")
for i, row in df.iterrows():
yield self.text_to_instance(
[Token(x) for x in self.tokenizer(row["tokens"])],
row["label"]
)
上の例ではDatasetReaderの初期化の際、tokenizerを渡しています。これが単語分割を行う関数になります。たとえば日本語の場合、次のように実装します。
from janome.tokenizer import Tokenizer
j_t = Tokenizer()
def tokenizer(text):
return [tok for tok in j_t.tokenize(text, wakati=True)][:MAX_SEQ_LEN]
>>> print(tokenizer(u'あなたを愛しています。'))
['あなた', 'を', '愛し', 'て', 'い', 'ます', '。']
_read関数の
for i, row in df.iterrows():
yield self.text_to_instance(
[Token(x) for x in self.tokenizer(row["tokens"])],
row["label"]
)
の部分で入力tsvファイルの1列目をself.tokenizerにで単語ごとに分割し、self.text_to_instanceでInstanceに変換しています。ラベルを扱うFieldは
label_field = LabelField(label, skip_indexing=True)
と定義していますが、skip_indexing=Trueはtoken_indexerによって番号付を行わない、つまりtsvファイル内の0,1といった値をそのままモデルの入力とすることを意味しています。
実際にtsvファイルを読み込んで_readの結果を確認してみます。
token_indexer = SingleIdTokenIndexer()
reader = MyReader(tokenizer = tokenizer, token_indexers={"tokens":token_indexer})
train_dataset = reader.read(Path(DATA_ROOT) / "train_ja.tsv")
MyReaderにSingleIdTokenIndexer()を渡していますが、これは一つの単語に一つの番号をふるindexerです。このほかに一つの"文字"に一つの番号をふるindexerもあります。このように番号をふる関数を分離しておくことで、単語/文字の埋め込み方のみを変更したいとき、コードの修正が最小限に抑えられます。(SingleIdTokenIndexer以外を使用する例に関しては後程説明します。)
>>> train_dataset
[<allennlp.data.instance.Instance at 0x7f102d4e39e8>,
<allennlp.data.instance.Instance at 0x7f102d4e3d68>,
<allennlp.data.instance.Instance at 0x7f102d4e2080>,
<allennlp.data.instance.Instance at 0x7f102d4e2278>]
>>> vars(train_dataset[0].fields["tokens"])
{'tokens': [あなた, を, が, 好き, です, 。],
'_token_indexers': {'tokens': <allennlp.data.token_indexers.single_id_token_indexer.SingleIdTokenIndexer at 0x7f10bc3044a8>},
'_indexed_tokens': None,
'_indexer_name_to_indexed_token': None}
train_datasetはInstanceの配列となっています。インスタンス中のFieldが、単語分割の結果と、indexerを保持しているのが確認できます。
まだこの時点では単語は番号付されていません。番号ふりは単語と番号の対応表(いわゆるVocabulary)を作成した後行います。
5. 手順2,3:単語への番号ふりとバッチ化
Vocabularyの作成
単語へ番号を振るための対応表(Vocabulary)は次のように作成します。
vocab = Vocabulary.from_instances(train_dataset, max_vocab_size=MAX_VOCAB_SIZE)
get_index_to_token_vocabulary()でVocabularyが確認できます。
>>> vocab.get_index_to_token_vocabulary()
{0: '@@PADDING@@',
1: '@@UNKNOWN@@',
2: 'が',
3: 'です',
4: '。',
5: '好き',
6: '私',
7: 'は',
8: '嫌い',
9: 'あなた',
10: 'を',
11: 'マイク',
12: 'マキ',
13: 'ボブ'}
PADDINGが異なる長さのFieldを一定の長さにそろえるために短い系列に追加されるダミートークンを表します。UNKNOWNは未知語に対応します。
バッチ化
BucketIteratorで各単語を番号に変換してミニバッチごとにまとめた行列を返すイテレータを作成できます。
iterator = BucketIterator(batch_size=BATCH_SIZE, sorting_keys=[("tokens", "num_tokens")])
iterator.index_with(vocab)
次のように番号が振られた結果を確認できます。
>>> batch = next(iter(iterator(train_dataset)))
>>> batch
{'tokens': {'tokens': tensor([[ 6, 7, 11, 2, 8, 3, 4],
[ 6, 7, 12, 2, 5, 3, 4]])}, 'label': tensor([0, 1])}
6. 手順4,5:単語の埋め込みとモデル定義
今回は
【self attention 】簡単に予測理由を可視化できる文書分類モデルを実装する
と同じモデルをAllenNLPを利用して実装してみます。(手順3までのデータの前処理の部分のみAllenNLPを使用し、モデルの記述は生のPytorchを使用する、という実装も可能です。)
モデルの詳細はリンク先を参照してください。
自然言語処理関係の多くのモデルは
- 単語埋め込みモジュール
- "encoder"モジュール(入力テキストを”ベクトル化”するモジュール)
- "decoder"モジュール(例えばseq2seqモデル。今回はなし)
からなります。AllenNLPにもこのそれぞれに対応した高レベルなmoduleが整備されており、それらを組み合わせることで生のpytorchを書くよりも少ない手間で高度なモデルを構築できます。下の実装では単語埋め込みモジュールとencoderモジュールを外部から指定できるようにしています。
モデルクラスはAllenNLPのModelを継承する形で実装します。AllenNLPのModelはtorch.nn.Moduleと同じように扱えます。
class Attn(nn.Module):
def __init__(self, input_sz:int, nch:int=24) -> None:
super(Attn, self).__init__()
self.input_sz = input_sz
self.main = nn.Sequential(
nn.Linear(input_sz, nch),
nn.ReLU(True),
nn.Linear(nch,1)
)
def forward(self,
encoder_outputs:torch.Tensor # (batch_size, seq_len, hidden_sz(=input_sz))
):
b_size = encoder_outputs.size(0)
attn_ene = self.main(encoder_outputs.view(-1, self.input_sz)) # (b, s, h) -> (b*s, 1)
return F.softmax(attn_ene.view(b_size, -1), dim=1).unsqueeze(2) # (b*s, 1) -> (b, s, 1)
class ClassifierWithAttn(Model):
def __init__(
self,
word_embeddings:TextFieldEmbedder,
encoder:Seq2SeqEncoder, # (batch_size, seq_len) -> (batch_size, seq_len. hidden_sz(*2 if bidirectional))
vocab:Vocabulary) -> None:
super().__init__(vocab)
self.word_embeddings = word_embeddings
self.encoder = encoder
self.attn = Attn(self.encoder.get_output_dim()) # encoder.get_output_dim() = hidden_sz(*2 if bidirectional)
self.main = nn.Linear(self.encoder.get_output_dim(), 1)
self.loss = nn.BCEWithLogitsLoss()
def forward(self, tokens:Dict[str, torch.Tensor], label:torch.Tensor = None) -> Dict[str, torch.Tensor]:
mask = get_text_field_mask(tokens)
embeddings = self.word_embeddings(tokens)
encoder_outputs = self.encoder(embeddings, mask) # (batch_size, seq_len, hidden_sz)
attns = self.attn(encoder_outputs) # (batch_size, seq_len, 1)
feats = (encoder_outputs * attns).sum(dim=1) # (batch_size, hidden_sz)
logits = self.main(feats).view(-1) # (batch_size, 1) -> (batch_size, )
output = {"logits":logits, "attns":attns}
if label is not None:
loss = self.loss(logits, label.float())
output["loss"] = loss
return output
注意すべきなのはClassifierWithAttnのforward内で辞書を返しているところです。また、forward内で誤差関数も計算して、返り値の辞書の"loss"として格納しています。このようにすることで後述のTrainerが使用でき、学習のforループの実装を省略できます。
モデルの初期化は次のように行います。
token_embedding = Embedding(num_embeddings=MAX_VOCAB_SIZE + 2, embedding_dim=300, padding_index=0)
word_embeddings: TextFieldEmbedder = BasicTextFieldEmbedder({"tokens":token_embedding})
encoder: Seq2SeqEncoder = PytorchSeq2SeqWrapper(nn.LSTM(word_embeddings.get_output_dim(),
HIDDEN_SZ, bidirectional=True, batch_first=True))
model = ClassifierWithAttn(word_embeddings, encoder, vocab)
Seq2SeqEncoderはテキストをトークンの数だけのベクトルに変換するモジュールを表します。encoderとしてはこのほかにも、テキストを1本のベクトルに変換するSeq2VecEncoderなどがあります。PytorchSeq2SeqWrapperはPytorchのRNNモジュールをAllenNLPのSeq2SeqEncoderに変換する関数です。bidirectional=Trueとすると、順方向のLSTMと逆方向のLSTMの隠れ状態を単語ごとにconcatしたものがencoderの出力として得られます。つまり、上記encoderの出力はコード中のコメントにもあるように、(バッチサイズ、テキストの長さ、隠れ状態の数*2)のテンソルになります。
7. モデルの学習と予測
学習の実行
Trainerクラスを使用すれば、学習のforループの実装を省略することができます。
optimizer = optim.Adam(model.parameters(), lr=LR)
trainer = Trainer(
model = model,
optimizer = optimizer,
iterator = iterator,
train_dataset = train_dataset,
validation_dataset = val_dataset,
cuda_device=0 if USE_GPU else -1,
num_epochs = EPOCHS
)
metrics = trainer.train()
予測
例えば、作成したモデルをwebAPIとして公開するような場合は、前処理を行っていない生のテキスト(json)を入力として、直接モデルの適用結果を出力するクラスが欲しくなります。AllenNLPにはそのような生データからの予測を行う専用のクラスPredictorが実装されています。
Predictorを継承する形で前処理に関するメソッドを実装し、タスクに応じたPredictorを作成します。(今回は使用しませんが、典型的なタスクに関してはそのままつかえる専用のPredictorが準備されています。)
class MyPredictor(Predictor):
def __init__(self, model: Model, dataset_reader: DatasetReader) -> None:
super().__init__(model, dataset_reader)
self._tokenizer = dataset_reader.tokenizer
def predict(self, tokens: str) -> JsonDict:
return self.predict_json({"tokens" : tokens})
@overrides
def _json_to_instance(self, json_dict: JsonDict) -> Instance:
tokens = json_dict["tokens"]
return self._dataset_reader.text_to_instance([Token(x) for x in self._tokenizer(tokens)])
>>> pre = MyPredictor(model, reader)
>>> pre.predict("あなたを愛しています。")
{'logits': 0.13095122575759888,
'attns': [[0.14304891228675842],
[0.14276131987571716],
[0.1426556259393692],
[0.1426471471786499],
[0.14273269474506378],
[0.14290529489517212],
[0.143249049782753]]}
上記MyPredictor内の_json_to_instanceが生の入力をInstanceに変換する関数です。predict_json内でこの関数が呼ばれます。ここで混乱するのですが、_json_to_instanceは単語の分割までしか行っていません。学習時はBucketIteratorが単語への番号ふりを行っていましたが、このMyPredictor内ではいつ行っているのでしょうか。
じつはAllenNLPのModelクラスには、forward_on_instanceという、単語への番号ふりとモデルの予測を両方行う推論時のみ使用できるメソッドがあります。このforward_on_instanceがPredictorではpredict_json内で_json_to_instanceの後に呼ばれています。forward_on_instancでの番号ふりを可能にするため、Modelの初期化の際にVocabularyを渡していました。
class ClassifierWithAttn(Model):
def __init__(
self,
word_embeddings:TextFieldEmbedder,
encoder:Seq2SeqEncoder, # (batch_size, seq_len) -> (batch_size, seq_len. hidden_sz(*2 if bidirectional))
vocab:Vocabulary) -> None:
super().__init__(vocab)
8. ELMoの利用
AllenNLPの大きな特徴として、単語の埋め込みベクトルとして最新の手法であるELMoのpretrainモデルを簡単に使用することが挙げられます。ELMoは文脈を考慮した単語のベクトル化の方法で、簡潔に説明するとテキストをある言語モデルに入力したときの中間層のベクトルを対応する単語の埋め込みベクトルとします。ELMoの詳細に関しては
などが参考になります。
ここまでの章で作成したコードを修正する形でELMoの使用方法を説明します。
token_indexerをSingleIdTokenIndexerからELMoTokenCharactersIndexerに変更
# token_indexer = SingleIdTokenIndexer()
from allennlp.data.token_indexers.elmo_indexer import ELMoTokenCharactersIndexer
token_indexer = ELMoTokenCharactersIndexer()
ELMo自身を計算するNeural Networkは入力としてcharacterレベルのembeddingを受け付けるので、ELMoToken"Characters"Indexerとなっています。
単語/文字に番号をふる関数(token_indexer)をDataReaderやFieldと分離することで、DataReaderに変更を加える必要がなくなっています。
vocabularyの定義を変更
# vocab = Vocabulary.from_instances(train_dataset, max_vocab_size=MAX_VOCAB_SIZE)
vocab = Vocabulary()
pretrainモデルをダウンロード+embedderに指定
※2019/04追記 :現在下記学習済みweight等はリンク切れとなってしまっています。
token_embedding = Embedding(num_embeddings=MAX_VOCAB_SIZE + 2, embedding_dim=300, padding_index=0)
# word_embeddings: TextFieldEmbedder = BasicTextFieldEmbedder({"tokens":token_embedding})
from allennlp.modules.text_field_embedders import BasicTextFieldEmbedder
from allennlp.modules.token_embedders import ElmoTokenEmbedder
options_file = 'https://elmoja.blob.core.windows.net/elmoweights/options.json'
weight_file = 'https://elmoja.blob.core.windows.net/elmoweights/weights.hdf5'
elmo_embedder = ElmoTokenEmbedder(options_file, weight_file)
word_embeddings = BasicTextFieldEmbedder({"tokens": elmo_embedder})
9. 他のNLPフレームワークとの比較
AllenNLPやtorchtextの他にもさまざまなNLPフレームワークが出ています。次の図はそのようなフレームワークの一つPyTextの論文から引用した、各フレームワークの比較表になります。
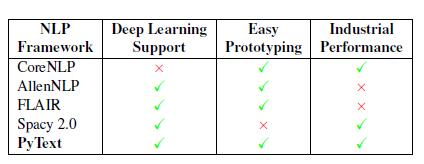
PyTextの論文なのでPyTextびいきな内容となっていますが、AllenNLPは「高度なDLモデルを簡単にプロトタイピングする」ことに利点があるフレームワークといえます。(僕自身は上記の表にあるものはAllenNLP以外は使用した経験がありません)
また、各モジュールがうまく抽象化され分離できており、ELMoの利用の章で説明したように、単語単位のindexer->文字単位のindexerといった大きな変更を行った場合でも、DataReaderクラスやModelクラスには変更が必要ありませんでした。
他のフレームワークとの比較はPyTextを使ってみた話も参考になります。
表にはありませんが、torchtextとの比較でいえば、
- torchtextが前処理に特化した軽量のフレームワークであるのに対し、AllenNLPはモデルの実装学習まで含めたフレームワークであること
- コードのコメントも含めてAllenNLPの方が大幅にドキュメントが充実していること
がAllenNLPの特徴です。この1に関してですが、今回扱ったようなシンプルな文書分類モデルのタスクでは、AllenNLPのモデル実装に関する高度なモジュール群の威力は十分に説明しきれていません。それらを使った実験もいずれ記事にできたらと思います。
10. まとめ
この記事では日本語のデータを利用した文書分類モデルの構築を通して、AllenNLPの主に前処理部分の機能を説明しました。
使用したコードをまとめたものはここに上げてあります。
AllenNLPの特徴は
- 高度なDLモデルを簡単にプロトタイピングできること
- 各モジュールがうまく分離できており、さまざまな修正を手軽に行えること
- ドキュメントがとても充実していること
です。
今回説明しきれなかった、モデル構築部分の高度な機能もいずれ紹介できればと思います。