1. 経緯
最近ツイッターで「素人の俺がAutoMLでデータサイエンス無双な件」みたいなやつをよく見る気がしたので自分も無双してみることにしました。
2. AutoMLとは
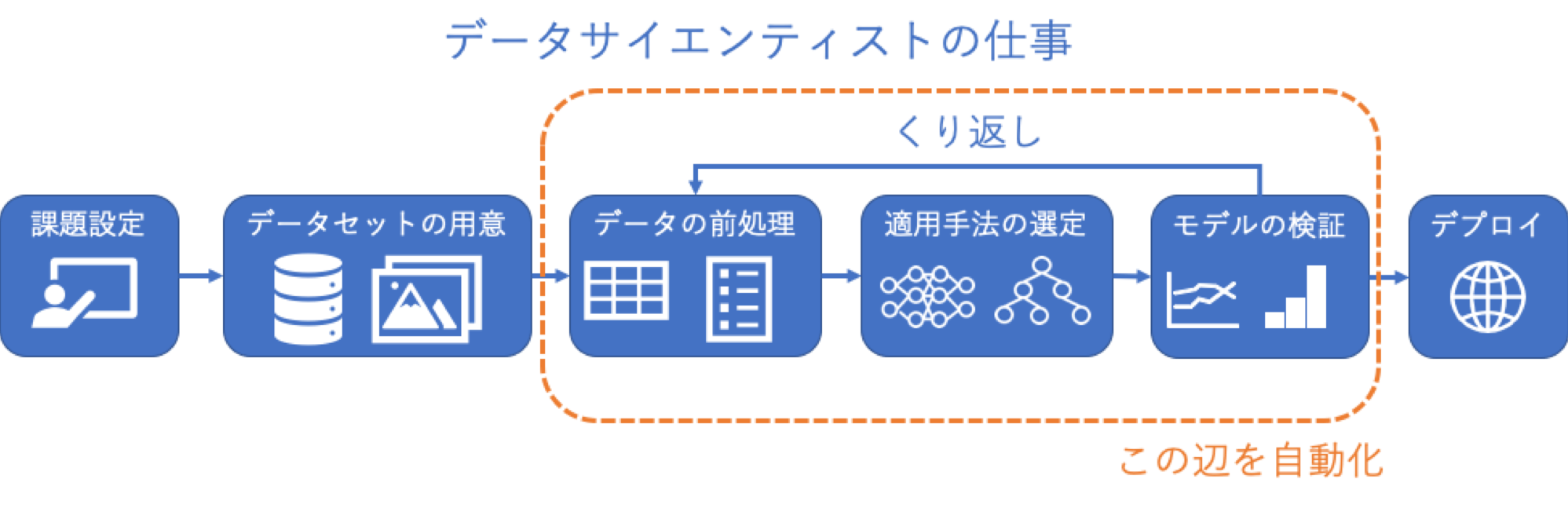
こういう感じで認識してます
もっと詳しい内容はこの辺りを読むと良いと思います。
- その機械学習プロセス、自動化できませんか?
- [自動化された機械学習とは(Microsoft)]
(https://docs.microsoft.com/ja-jp/azure/machine-learning/service/concept-automated-ml)
3. 実施内容
クラウドサービスの提供元を中心に調べたところ
次のようなものが見つかりました。
- Google/AutoML Tables
- IBM/AutoAI
- Microsoft/Automated ML
- Sony/Prediction One (2019/11/13追記)
- H2O Driverless AI (2019/11/15追記)
AutoMLでは画像認識や自然言語処理なども取り扱い範囲に含みますが、
ツイッターで話題になっていたのがGoogle/AutoML Tablesだったことと、IBM/AutoAIを試してみたかったので今回は構造化(表形式)データを対象としました。
テストの種類としてはIBM/AutoAIに従って、2クラス分類、多クラス分類、回帰の三種類を実施することにしました。
4. UX比較
4.1. 機能比較表
- 学習時の機能
| ツール | csv前処理の自動化 | 統計情報の表示 | 特徴量の自動作成 | 交差検証 | DeepLearning | 時系列処理 |
|---|---|---|---|---|---|---|
| Google/AutoML Tables | × | ○ | ▲ | × | ○ | ○ |
| IBM/AutoAI | ○ | △ | ○ | ○ | × | × |
| Microsoft/AutomatedML | △ | ○ | ▲ | ○ | △ | ○ |
| Sony/Prediction One | △ | × | ▲ | ○ | ○ | ○ |
| H2O Driverless AI | ○ | ○ | ○ | ○ | △ | ○ |
- 評価時の機能
| ツール | 特徴量の寄与率表示 | 結果のグラフ化 | 評価指標の説明 | 学習済みモデルのダウンロード | api接続先の作成 |
|---|---|---|---|---|---|
| Google/AutoML Tables | ○ | △ | ○ | × | ○ |
| IBM/AutoAI | ○ | ○ | △ | △ | ○ |
| Microsoft/AutomatedML | ○ | ○ | × | ○ | ○ |
| Sony/Prediction One | ○ | ○ | ○ | × | △ |
| H2O Driverless AI | ○ | ○ | △ | ○ | ○ |
○:良好
▲:実施しているが、表示不能
△:一部可能
×:実装されていない or 良好ではない
4.2. Google/AutoML Tables
統計・機械学習に詳しくない方をターゲットにしていると感じました。
統計情報の表示画面・モデルの評価画面ともに説明が丁寧で、知識が少なくともある程度の結果を出せるように作られていると感じました。
一方、データの読み込みや処理などに癖が強いためこのサービスを含めたgoogle cloud platformへの知識は必要になりそうです
-
良い点
- 統計情報の表示画面が非常に優秀
- ヘルプが充実しているため、モデルの評価が容易
-
悪い点
- データ形式の制約が多い(行数1000行以上、分類ならクラスごとに20以上必要など)
- モデルの内部構造(採用した手法)が分からない
-
分析ページのサンプル画像
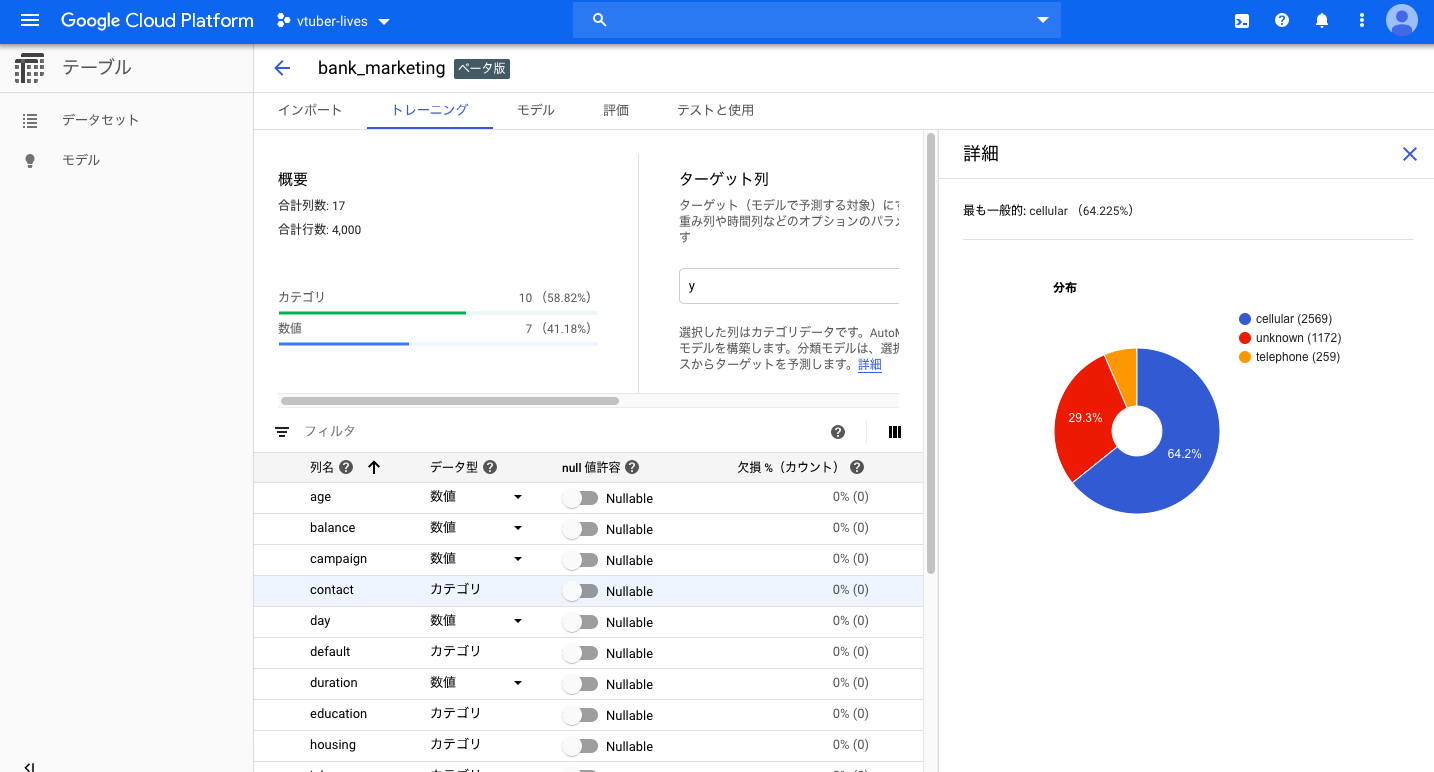
データの種類を自動判別してくれる他、欠損や固有値、各種統計情報を自動計算してくれます。
また、特徴量を選択するとデータの分布もグラフ化してくれます。 -
評価ページのサンプル画像1
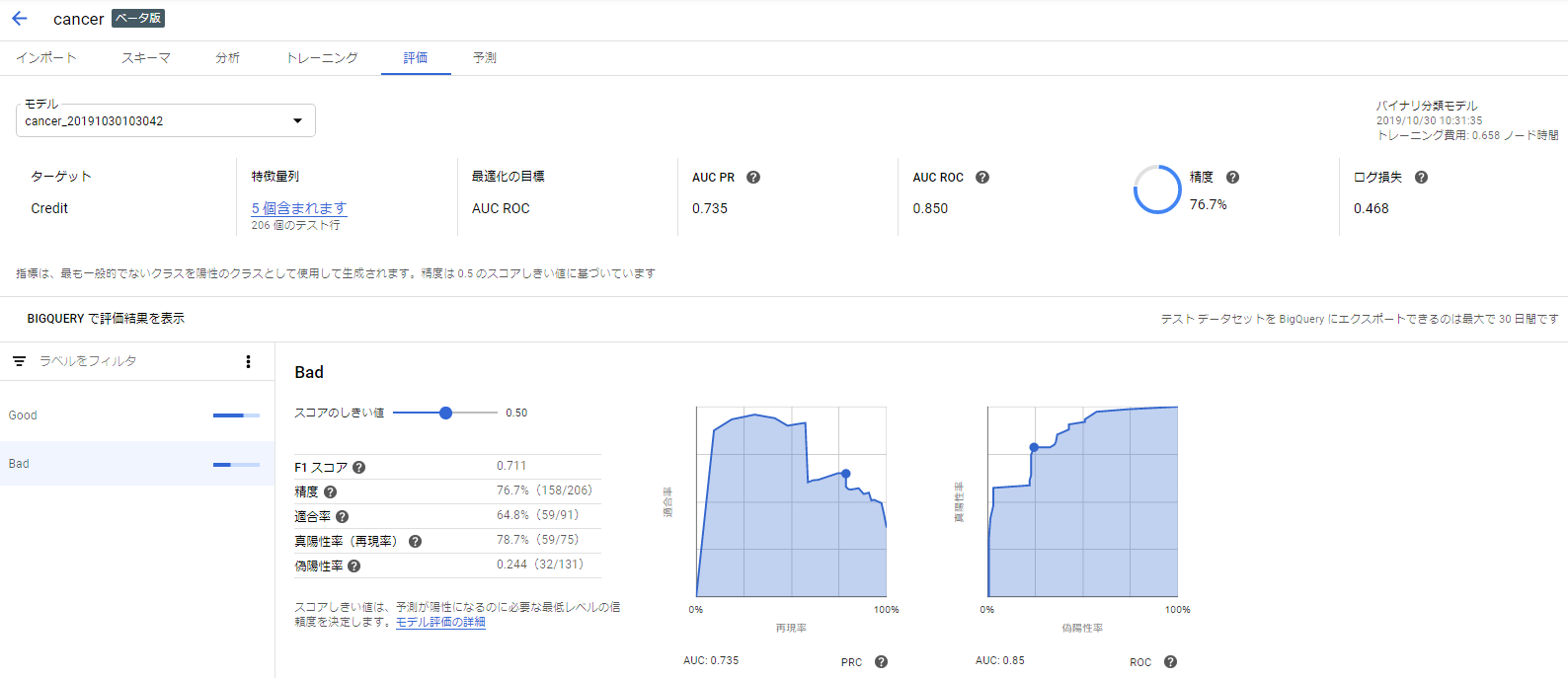
-
評価ページのサンプル画像2
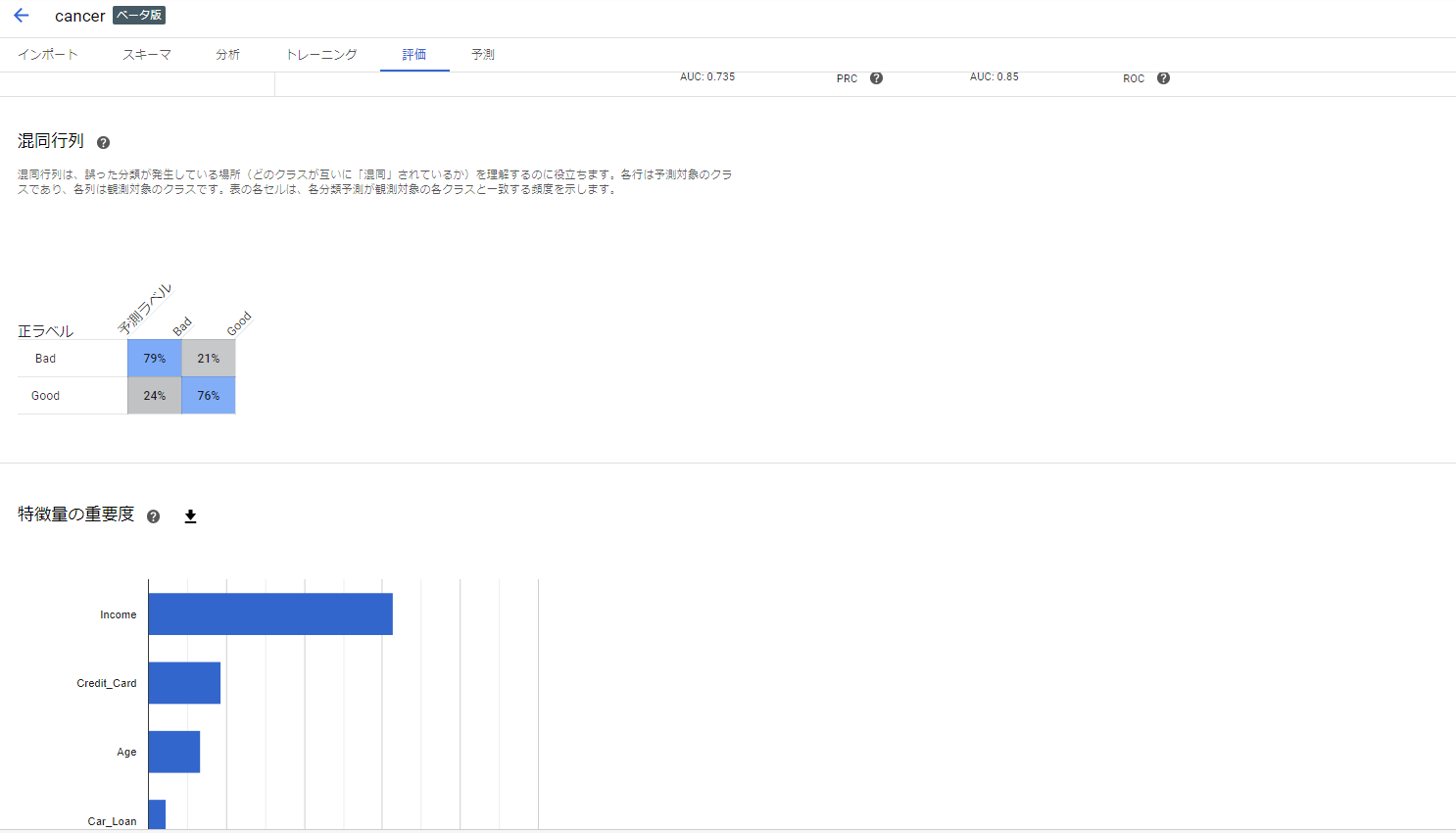
図は2クラス分類の場合。
各種評価指標の他、特徴量の重要度もグラフ化してくれます。また、各指標にヘルプが振られており、容易に参照できます。
-
試用期間における計算性能
4 vCPU and 15 GiB RAM × 92台平行 -
試用期間と同等の性能を確保する場合のトレーニング費用
$19.32/時間
(¥2,123 2019/11/6レート)
参考にした記事
- KaggleのHousePredictionを題材にしてAutoML Tablesがどんなもんか見てみる
- GoogleCloudPlatformの「AutoMLTables」を使ってみた
- AutoML Tablesを使ってみた
公式ドキュメント
4.3. IBM/AutoAI
学習したモデルを他の方に説明する必要がある方をターゲットにしていると感じました。
採用手法や自動で作られた特徴量・どの特徴量がどのモデルで重視されているかなど、
学習済みモデルを説明する情報を多く手に入れることができます。
-
良い点
- モデル作成の過程および作られたモデルの内容が説明しやすい
- 学習済みモデルをnotebook形式で書き出しできる
-
悪い点
- 時系列分析を実施できない
- DeepLearningが別サービスになっている
-
トレーニング開始ページのサンプル画像
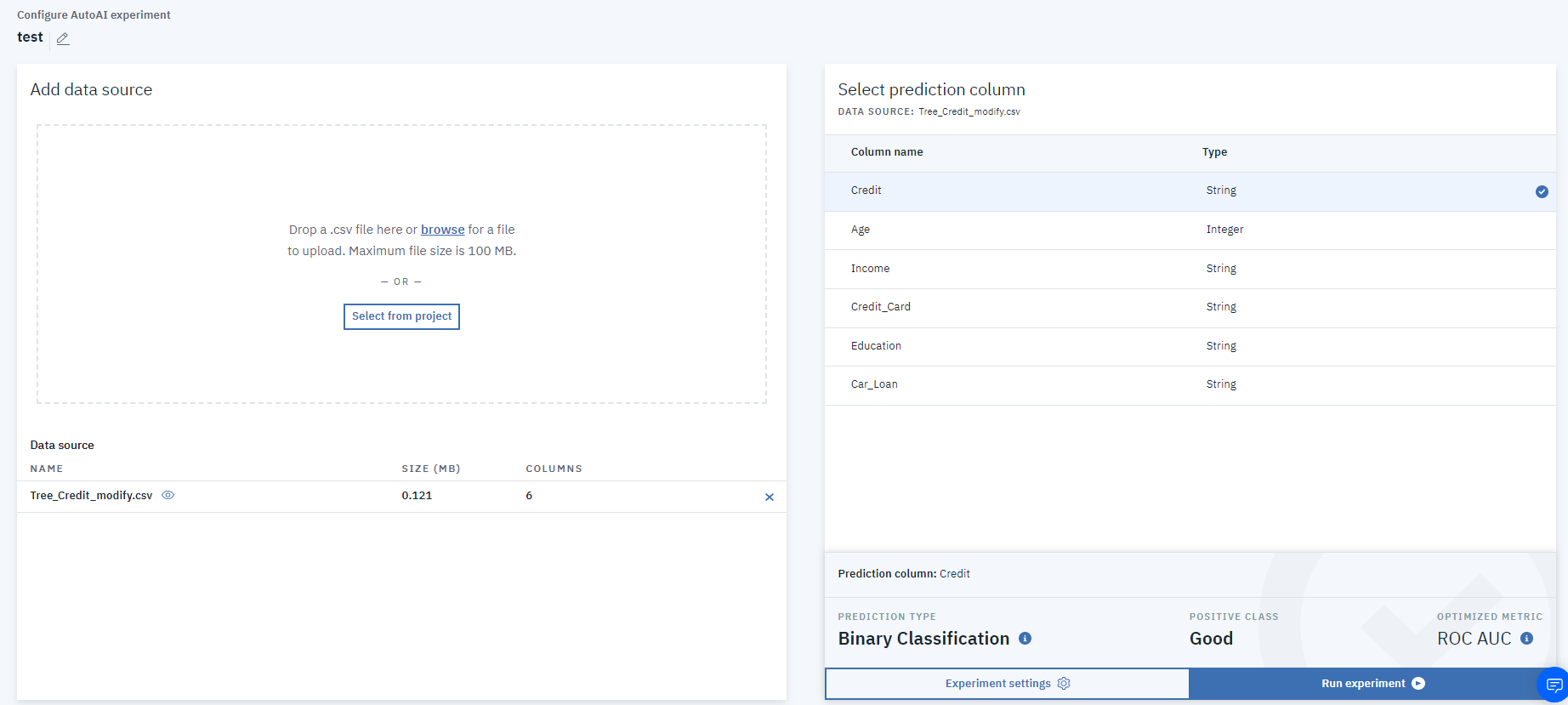
ほとんど設定の必要がなく、データを入れてすぐにはじめることができます。 -
トレーニング中のページのサンプル画像
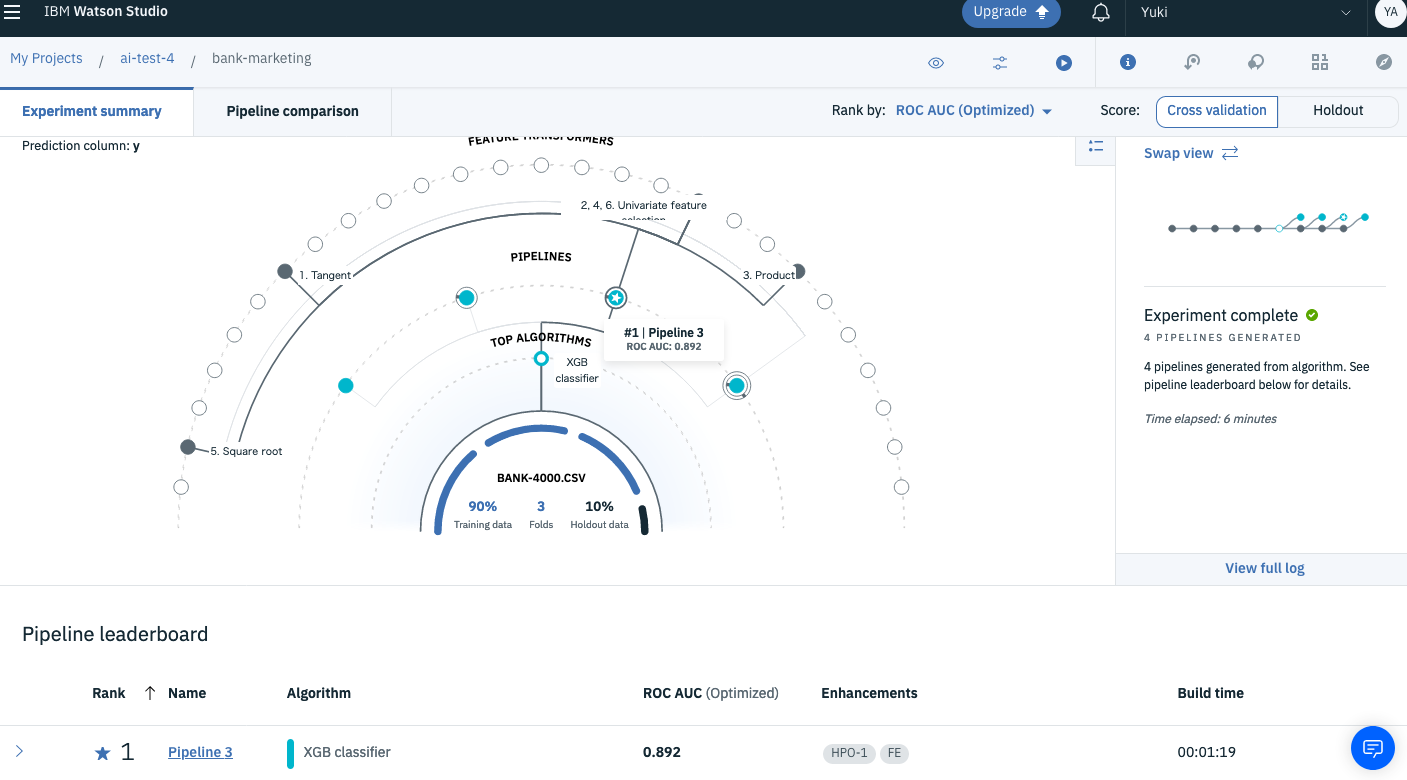
学習モデルや特徴量エンジニアリングの手法がどのモデルに関与しているのかを確認することができます。
また、モデル選択、ハイパーパラメータの最適化、特徴量エンジニアリング、ハイパーパラメータの再調整の各段階でトレーニング結果を確認することができます。 -
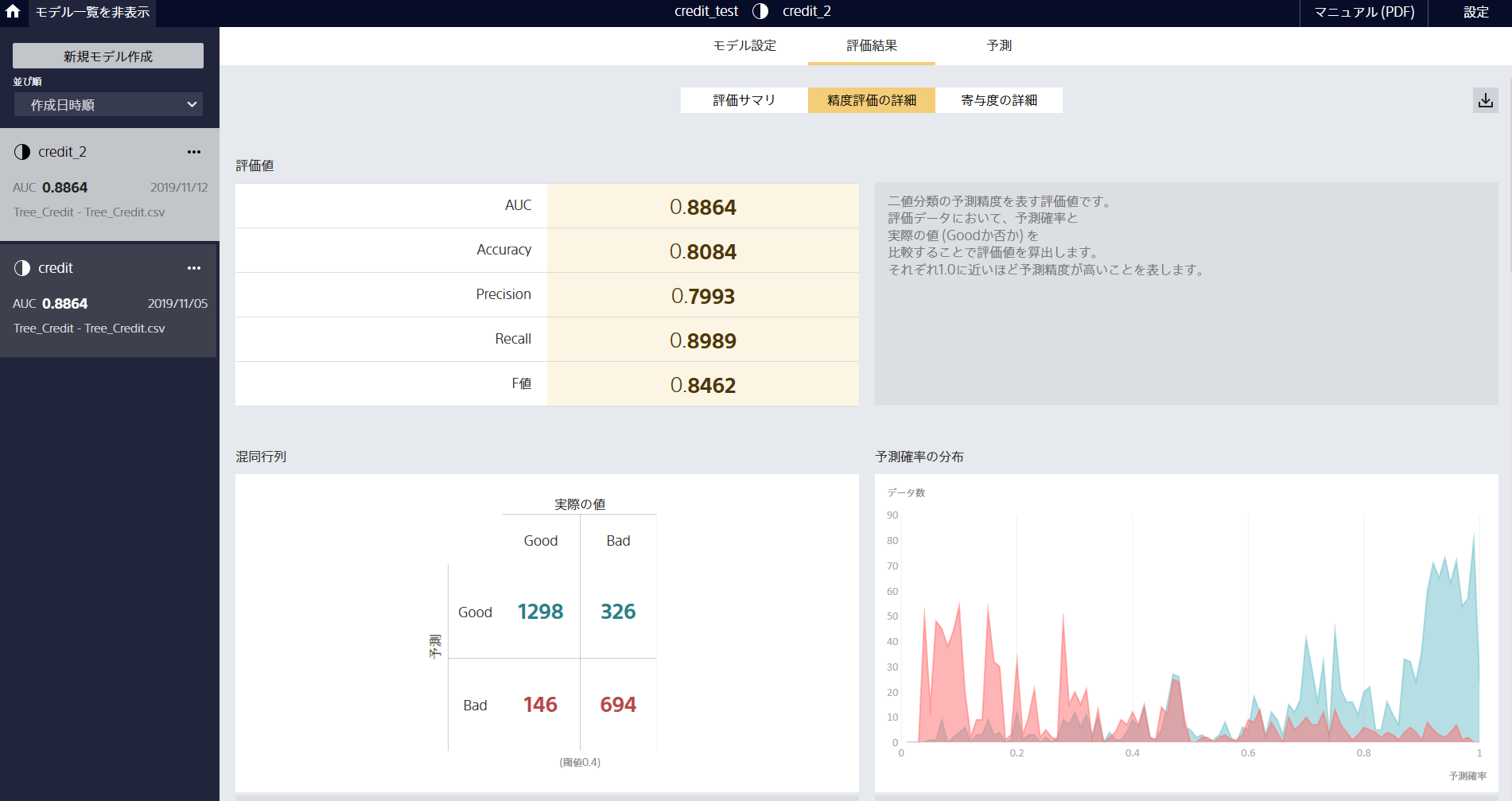
モデル評価ページのサンプル画像
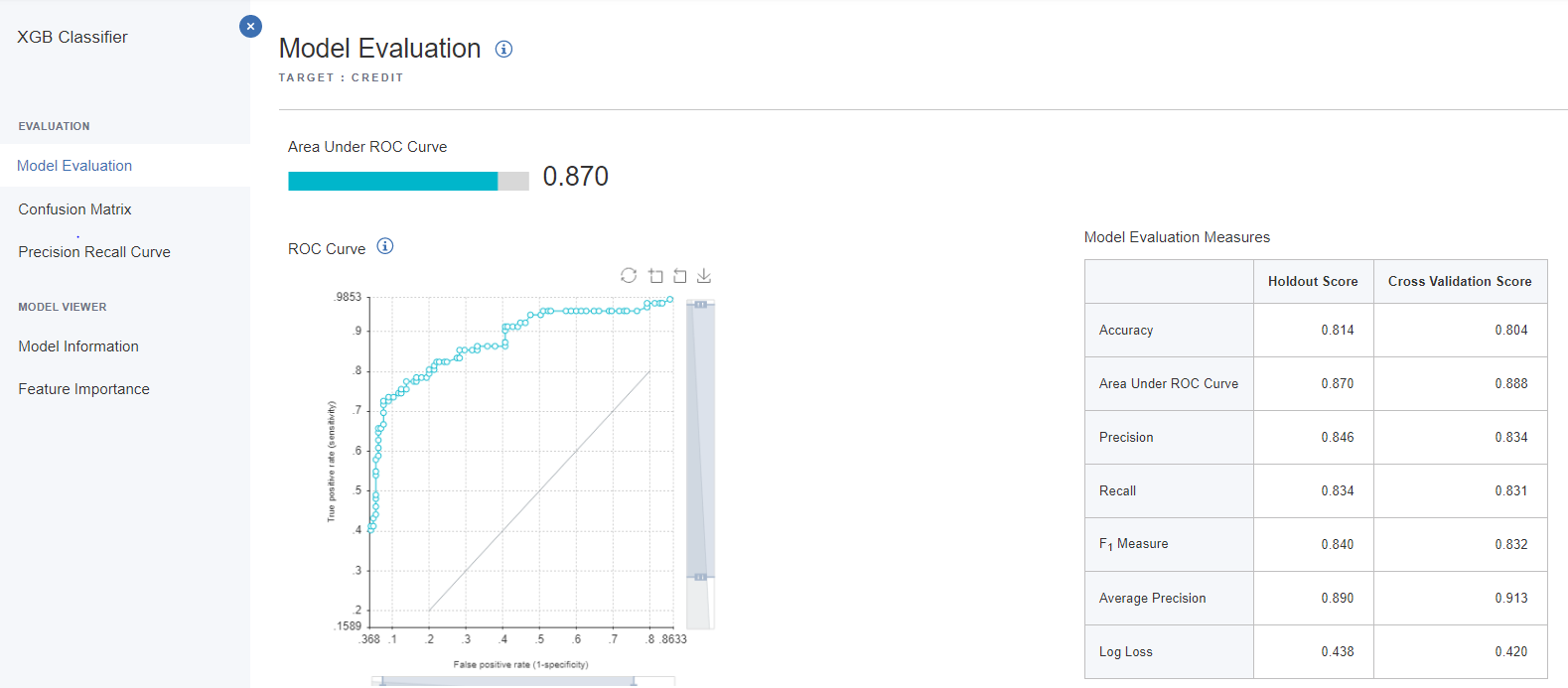
図は2クラス分類の場合。
各種評価指標のグラフ化や混同行列の表示に加え、特徴量エンジニアリングで作られた新しい特徴量を表示してくれます。 -
試用期間における計算性能
8 vCPU and 32 GB RAM -
試用期間と同等の性能を確保する場合のトレーニング費用
¥1,120.0/時間
参考にした記事
- WatsonStudioの「AutoAI」を使ってみた(学習編)
- 誰でもAIモデルが作れる! Watson Studioに新しく搭載された機械学習の自動化機能「AutoAI Experiment」をザクっとご紹介します
- AutoAIでお手軽機械学習(その1) 準備編
公式ドキュメント
4.4. Microsoft/AutomatedML
かなり機械学習の事前知識がある方をターゲットにしていると感じました。
得られる出力は比較的多めですが、説明が無いため、事前知識やマニュアルの読み込みが必須となります。
また、GUIの動作も安定しない事が少なからずありました。
現在はベータ版とのことなので今後の発展によっては良くなる可能性もあると思います。
-
良い点
- 学習済みモデル・実行ファイルなど全ての出力をダウンロードできる
- グラフ作成能力が比較的優秀(多クラス分類・回帰にも対応)
-
悪い点
- 評価指標や仕様の説明が画面上に無い
- firefoxやsafariでの挙動が非常に安定しない
-
タスクタイプ設定ページのサンプル画像
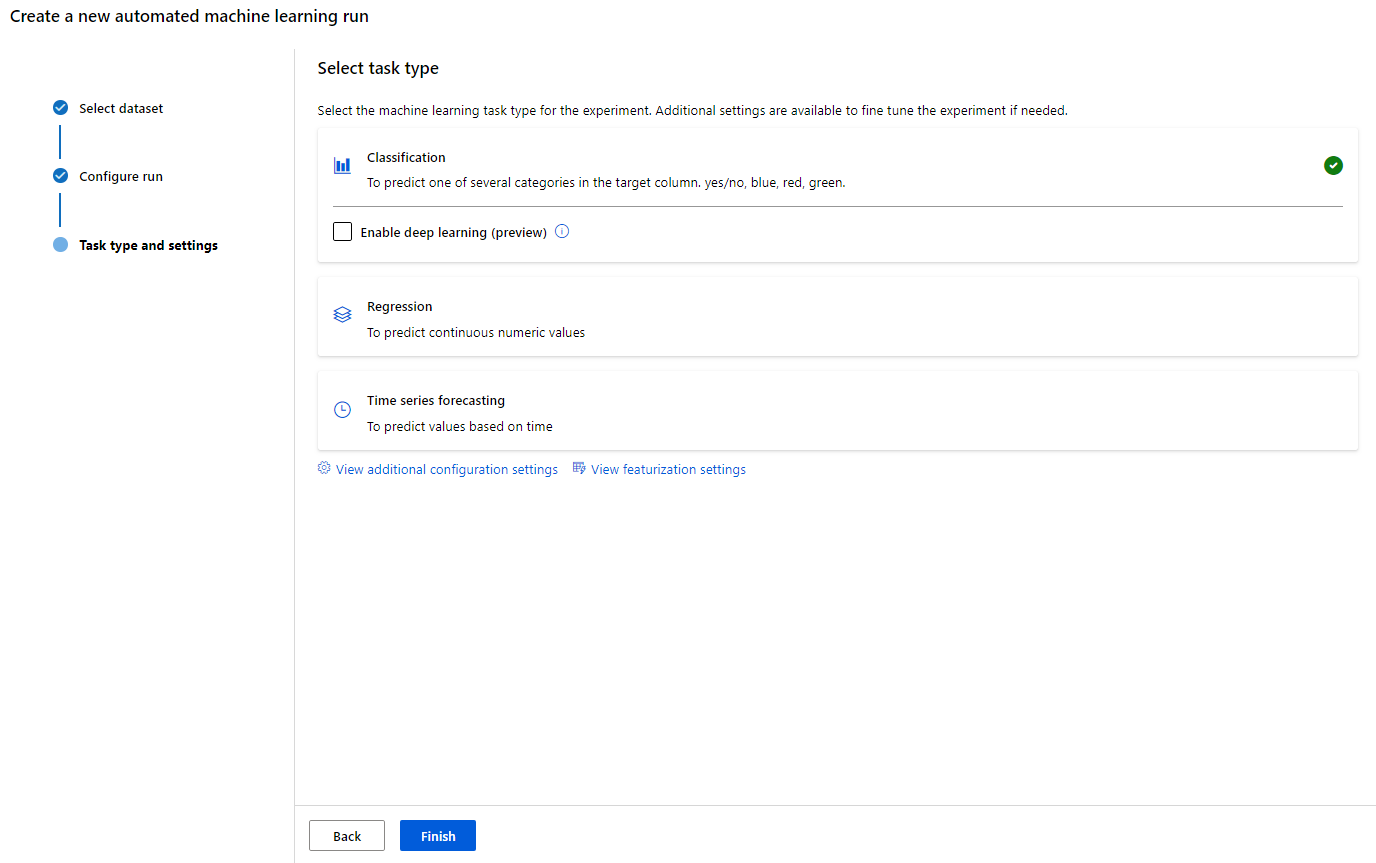
分類・回帰に加えて時系列データを扱うことができます。
また、分類問題ではディープラーニングを扱う事が可能です。
(詳細なドキュメントは見つかりませんでした。
テキストデータが含まれている時に有効ですみたいなヘルプが有ったので、Word2Vec的なことをやってるんでしょうか?) -
多クラス分類でのグラフ化機能のサンプル画像
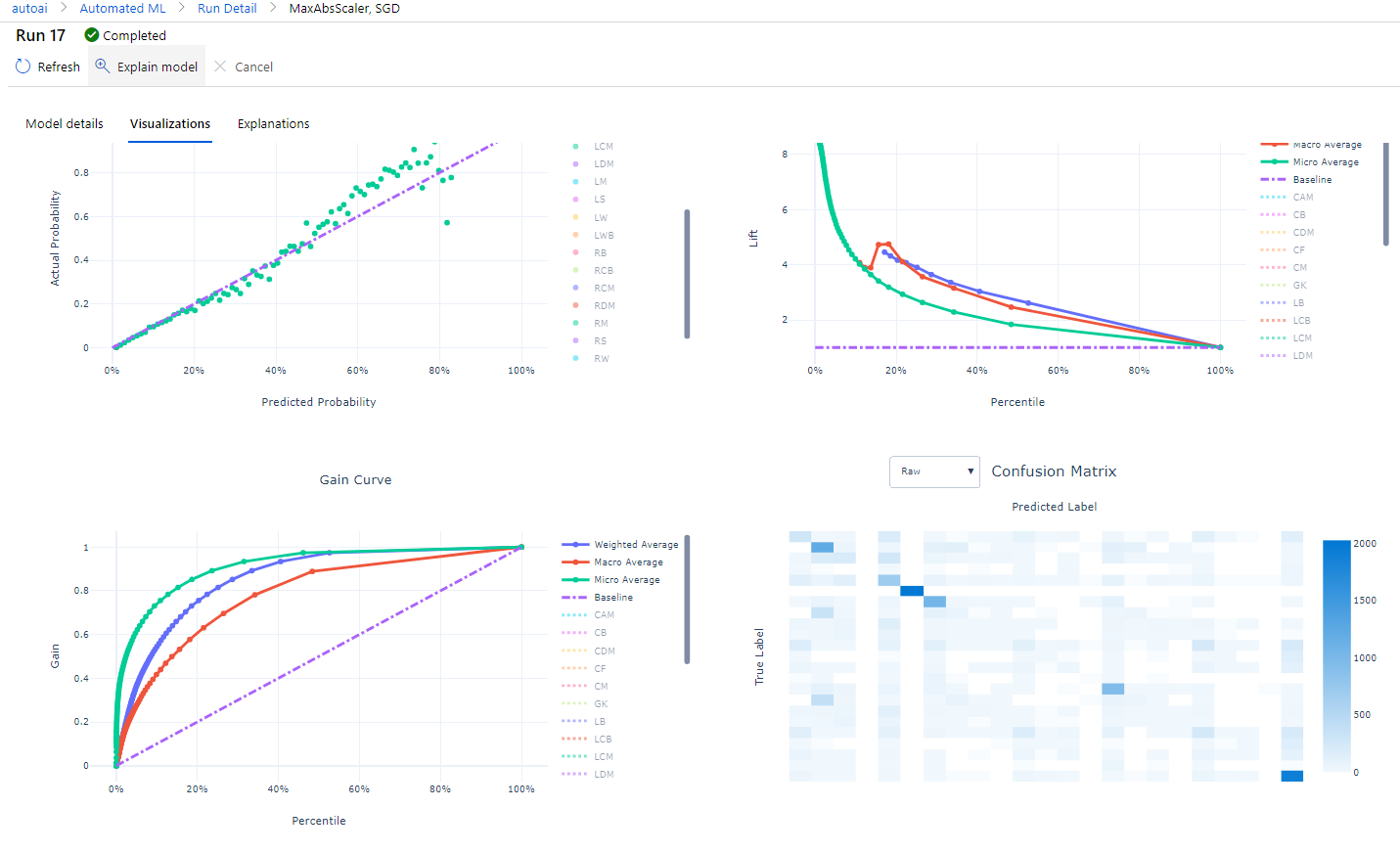
-
回帰分析でのグラフ化機能のサンプル画像2
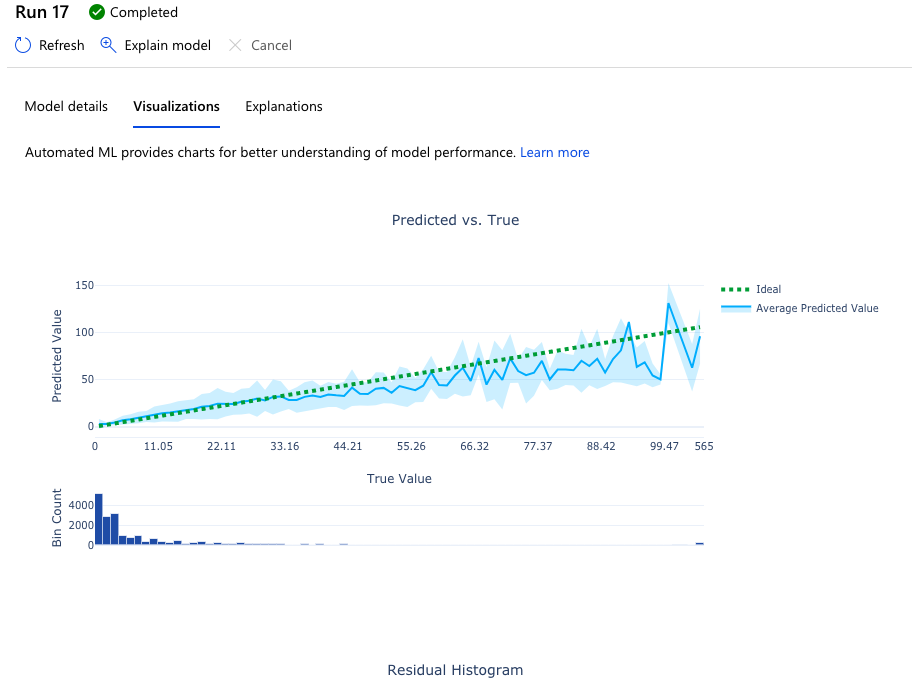
特に設定しなくても自動でグラフを生成してくれます。
また、他ではあまり対応できていなかった多クラス分類や回帰分析のグラフ表示も実施してくれます。
-
試用期間における計算性能
4 vCPU and 28 GiB RAM -
試用期間と同等の性能を確保する場合のトレーニング費用
¥72.9/時間
参考にした記事
公式ドキュメント
4.5. Sony/Prediction One
(2019/11/13追記)
統計、機械学習に詳しくない方をターゲットとしていると感じました。
評価指標などの説明が丁寧でUIも分かりやすい反面、
モデルが何をやっているかについてはほとんど触れられていませんでした。
なお、学習済みモデルの利用はPrediction Oneを通してのみ可能です(CLIで組み込み可能)
-
良い点
- 学習コストが非常に低い(評価指標の説明が丁寧・精度のランク付けなど)
- ローカル環境で動かすことができる
-
悪い点
- モデルの内容を説明できない(採用手法・ランク付けの基準が不明)
- ユニーク数・欠損情報に誤りが起きる(最初の1000行で判断するため)
-
データ読み込み画面のサンプル画像
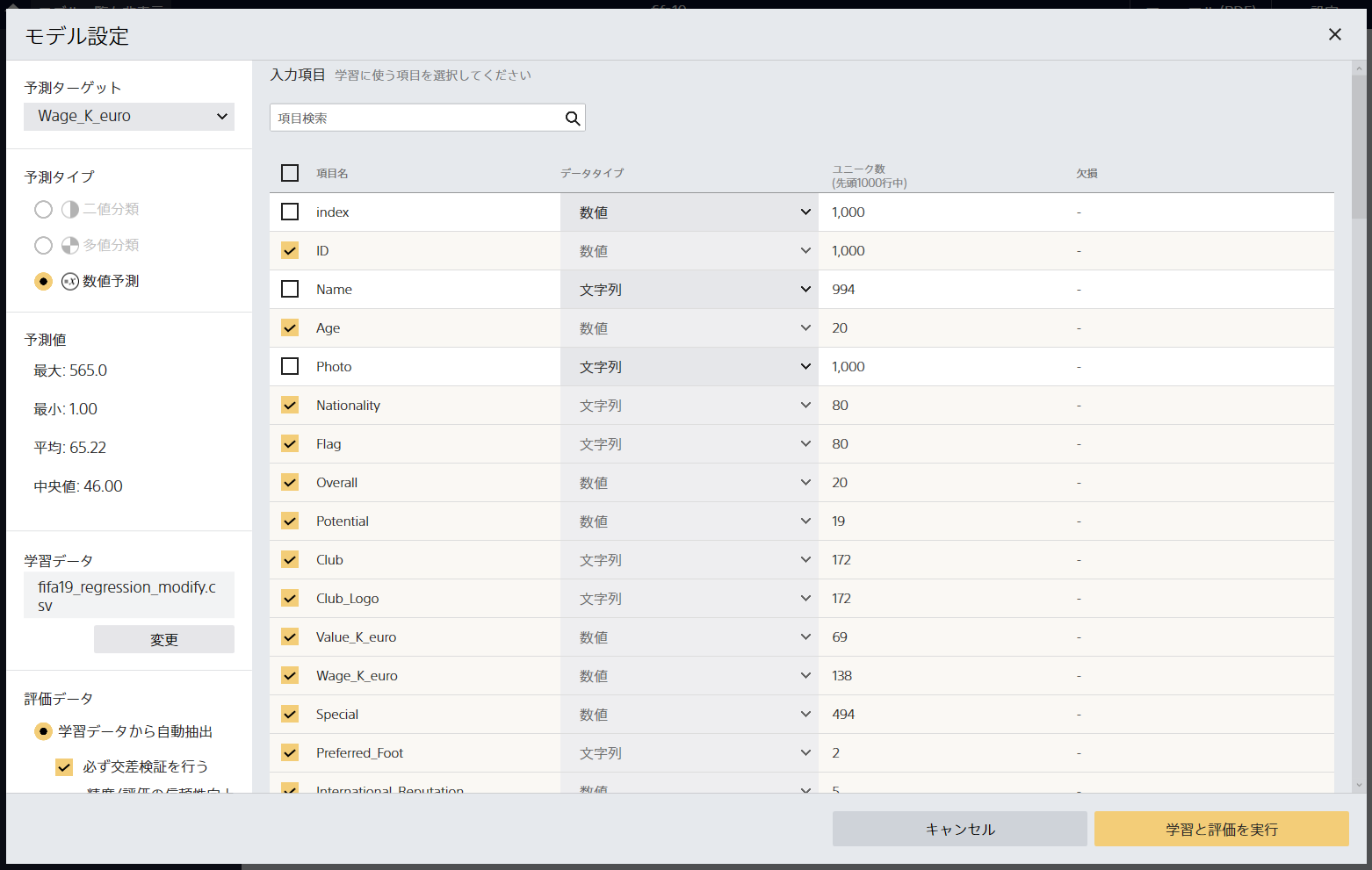
データ読み込み画面。
csvを直接読み込み可能、読み込みは先頭1000行まで。
-
学習中画面のサンプル画像
-
評価画面のサンプル画像1
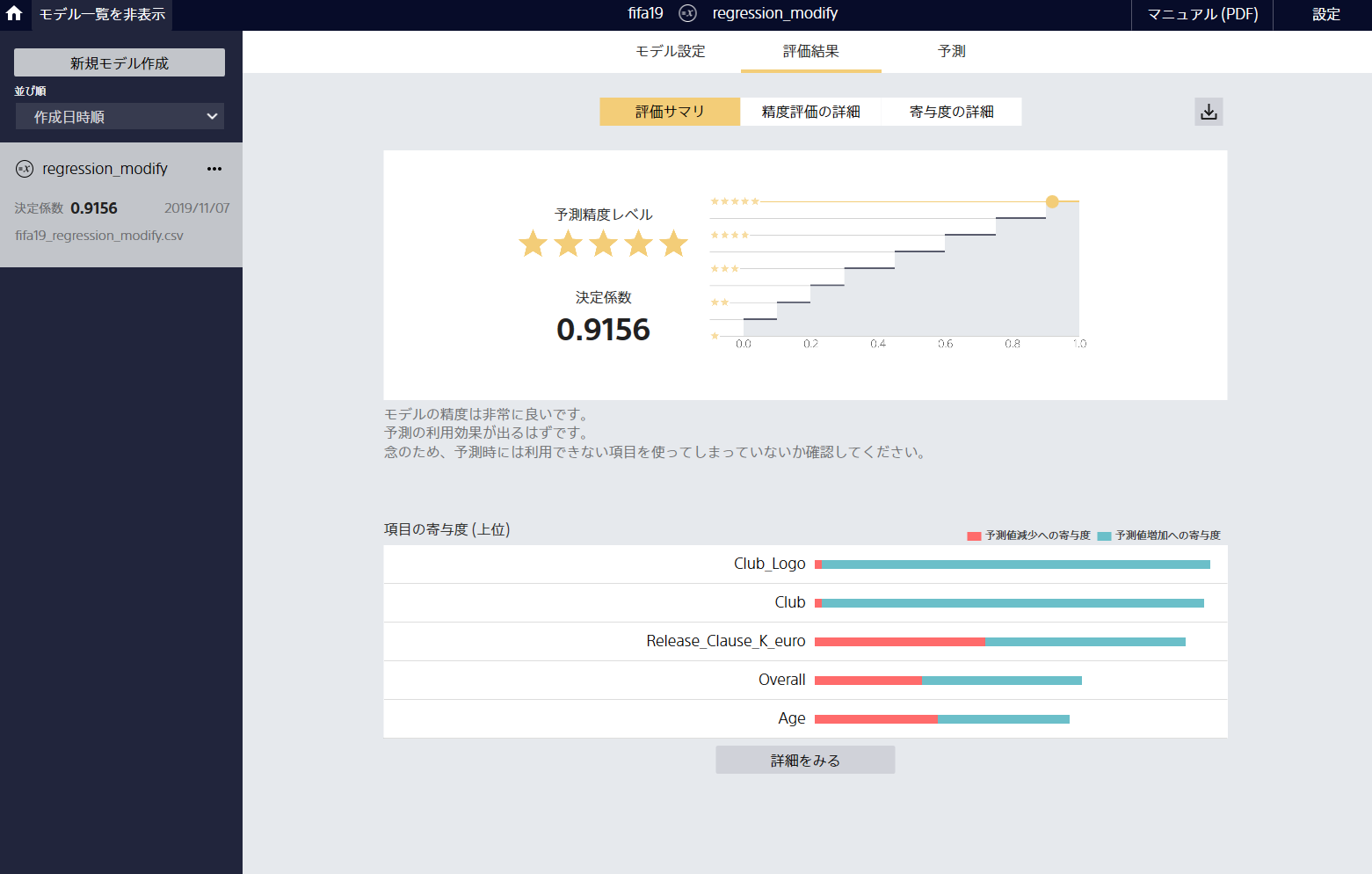
-
評価画面のサンプル画像2
-
実行環境での計算性能
Intel(R) Core(TM) i7-7700K CPU @4.20GHz
参考にした記事
公式ドキュメント
4.6. H2O Driverless AI
(2019/11/15追記)
どちらかといえば作成したモデルを説明する必要がある方をターゲットとしているように感じました。
とはいえ、他のAutoMLサービスと比べて使える機能が多いため、広く適用できると思います。
一方、UIや評価指標に関しては分かりやすいとは言えず。機能の数に対して画面上の説明が少ないため、十全に力を発揮するにはDriverless AIに精通した方が必要になると感じました。
-
良い点
- 機能の数が非常に多い(代理モデル・データの偏りへの対応など他のAutoMLには無い機能も多い)
- データの前処理の手間が非常に少ない
- 学習済みモデルを自由に扱える
-
悪い点
- UIが分かりづらく、よく調べないと間違った結論を下してしまう可能性がある
-
データ可視化画面のサンプル画像
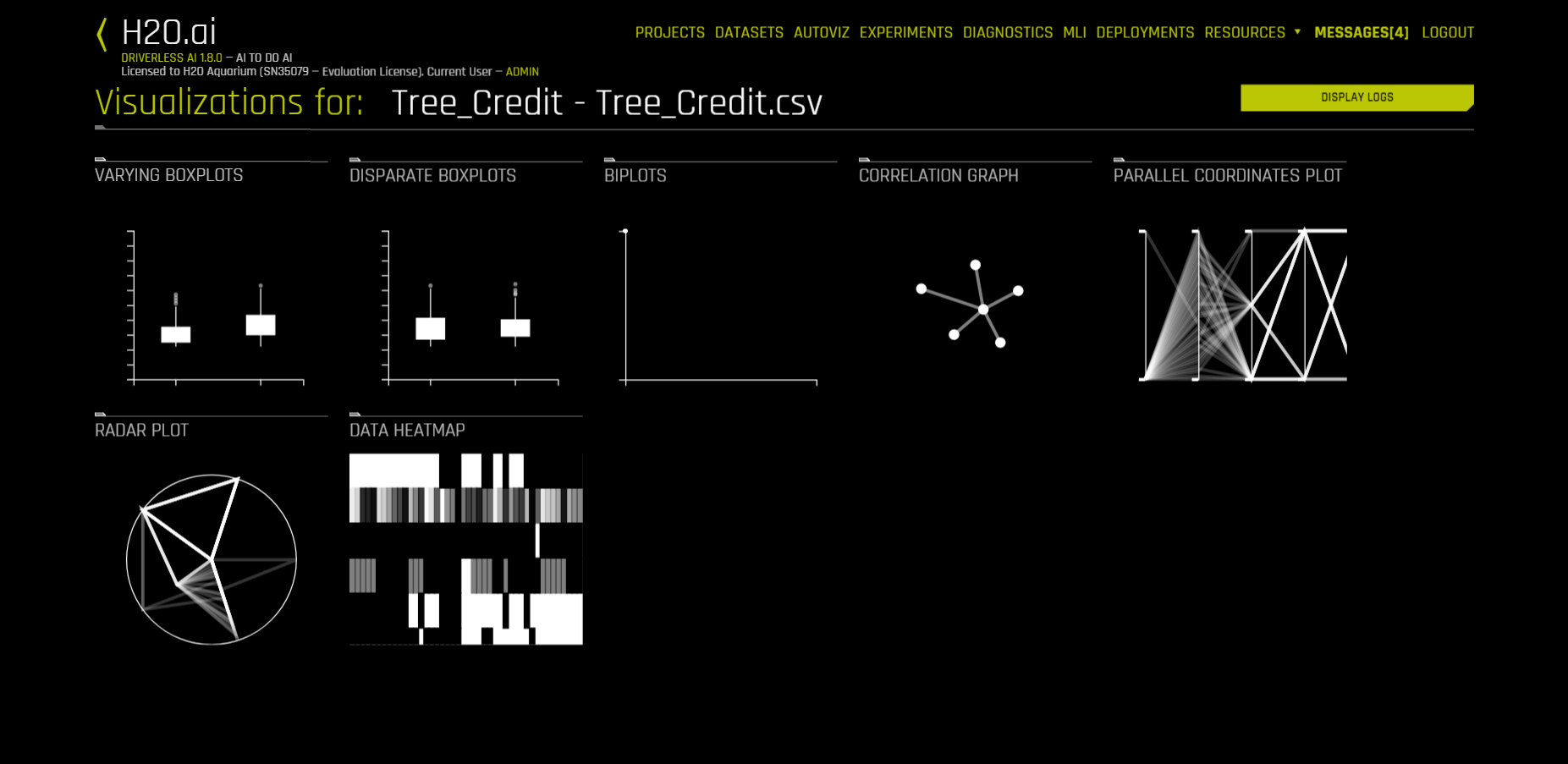
-
学習中画面のサンプル画像
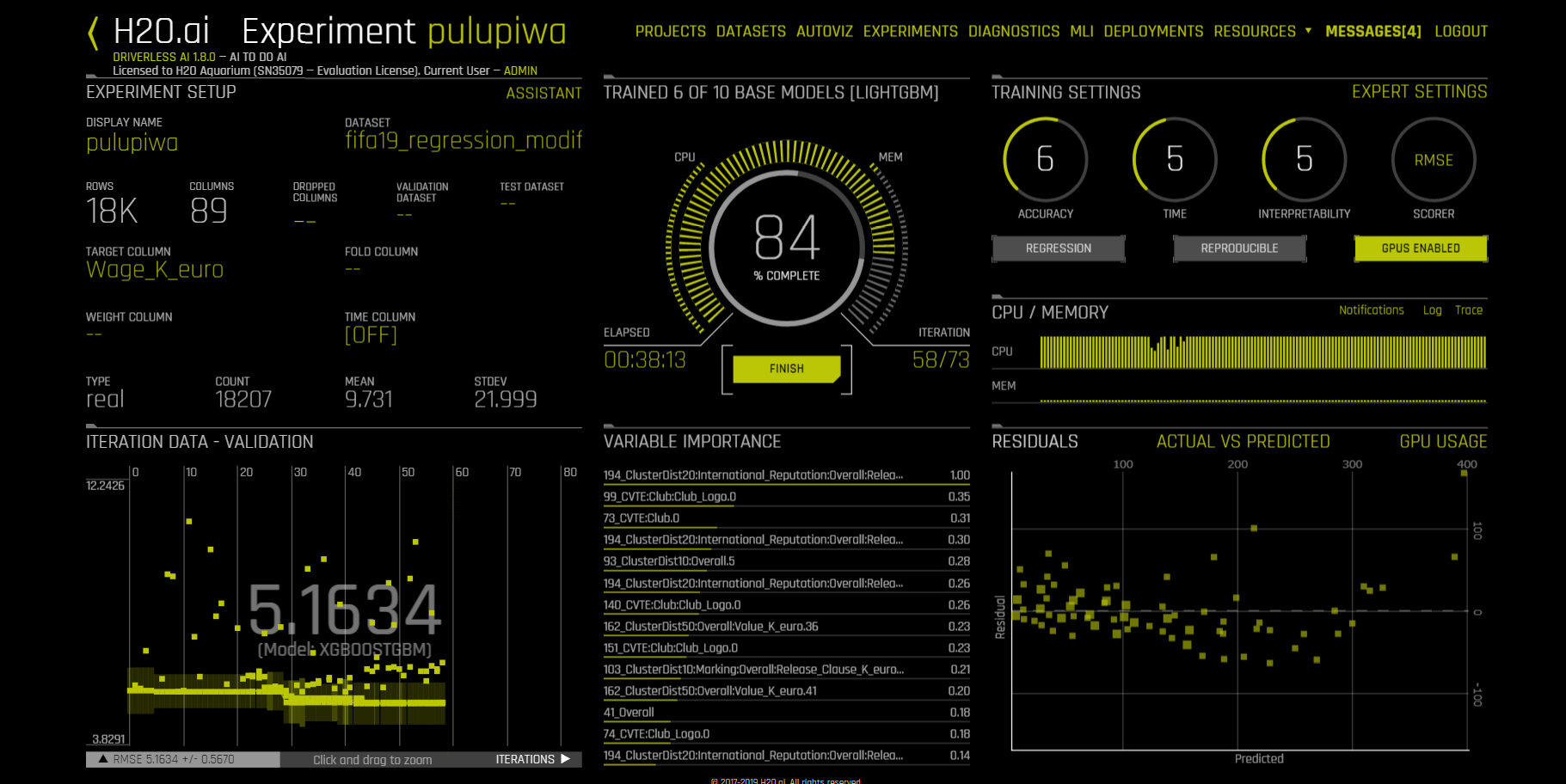
-
代理モデルのサンプル画像
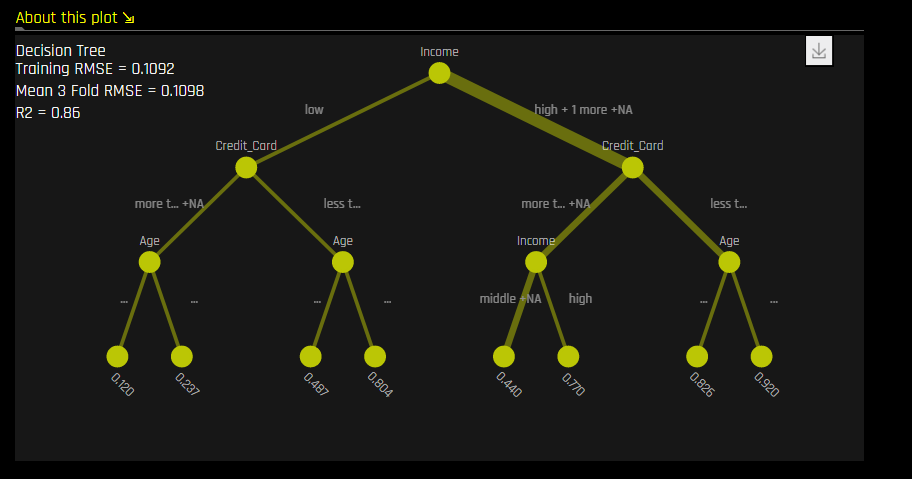
※この記事において"代理モデル"とはDriverless AI本体において"surrogate model"と呼ばれているモデルのことを指します。これは、作成されたモデルを人間が解釈しやすい形に近似して表示するものです。
-
試用期間における計算性能
不明 -
トレーニング費用
契約内容によって大きく異なります(サブスクリプション契約などが一般的)
参考にした記事
公式ドキュメント
5. モデル構築能力比較
今回は比較を行うために全ての手法でhold-out法によるmicroデータを利用しています。
また、トレーニング費用は[時間あたり価格]×[時間]で算出しています。
| ツール | 時間あたり価格(¥/時) |
|---|---|
| Google/AutoML Tables | 2,123 |
| IBM/AutoAI | 1,120 |
| Microsoft/AutomatedML | 73 |
| Sony/Prediction One | 0 |
なお H2O Driverless AIは料金体系が異なるため料金を算出していません
5.1. 既存結果との比較
データサイエンティストの方の手組みによる結果が確認できたデータセットを実施します。
主にAutoML全体のモデル構成能力を見るものです。
5.1.1. 2値分類
AutoAIでお手軽機械学習(その2) モデル構築編
こちらの記事で利用されていたデータセットについて、kaggleのページがありましたのでこれを比較対象とします。
データセット:Bank Marketing Data Set
kaggleページ:Bank Marketing/kaggle
このデータセットでは職業、年齢などを元に商品購入の有無を予測します。
また、比較を行うkernelはこのページの投稿者の方が制作したものとします。
kernel:Bank Marketing + Classification + ROC,F1,RECALL...
制作者:Henrique Yamahata(Competitions Contributor)
| 名前 | F値 | 適合率 | 再現率 | ROC AUC | トレーニング時間(分) | トレーニング費用(¥) |
|---|---|---|---|---|---|---|
| Henrique Yamahata | 0.914 | 0.880 | 0.891 | 0.94 | --- | --- |
| Google/AutoML Tables | 0.410 | 0.615 | 0.308 | 0.897 | 4.29 | 151.8 |
| IBM/AutoAI | 0.626 | 0.585 | 0.674 | 0.939 | 5.5 | 102.7 |
| Microsoft/AutomatedML | 0.316 | 0.664 | 0.207 | --- | 6.61 | 8.0 |
| Sony/Prediction One | 0.548 | 0.439 | 0.729 | 0.883 | 1.4 | 0 |
| H2O Driverless AI | 0.557 | 0.439 | 0.760 | 0.907 | 16.8 | --- |
AutoMLでの適合率と再現率がかなり低めに出る結果となりました。
positive : negative = 1 : 8 程度のスパース気味なデータだったことも影響するのかもしれません。
AutoMLにも向き不向きはあるようです。
5.1.2. 回帰
データセット:House Sales in King County, USA
このデータセットでは家の各種情報から価格を回帰で予測します。
今回選んだ理由は、データセットが1000行以上で、ある程度の知名度がある練習用のデータセットだったためです。
また、今回比較対象としたのは次の2つのkernelです
vote数が最高だったもの
kernel:Predicting House Prices
制作者:Burhan Y. Kiyakoglu(Competitions Contributor)
grandmasterの方が実施されたもの
kernel:Predicting House Prices [XGB/RF/Bagging-Reg Pipe]
制作者:Leonardo Ferreira(Kernels Grandmaster)
| 名前 | RMSE | MAE | R2 | トレーニング時間(時間) | トレーニング費用(¥) |
|---|---|---|---|---|---|
| Burhan Y. Kiyakoglu | 151,200 | --- | 0.813 | --- | --- |
| Leonardo Ferreira | --- | 40,092 | 0.872 | --- | --- |
| Google/AutoML Tables | 109,743 | --- | 0.890 | 2.65 | 5,626 |
| IBM/AutoAI | 119,307 | 42,665 | 0.892 | 1.06 | 1,187 |
| Microsoft/AutomatedML | 131,390 | 40,105 | 0.882 | 0.41 | 30 |
| Sony/Prediction One | 130,661 | --- | 0.873 | 0.31 | 0 |
| H2O Driverless AI | 118,587 | --- | 0.93 | 0.35 | --- |
こちらは予想以上にAutoMLが強くて驚きました。
もちろんデータに向き不向きはあると思いますが、選択肢として一度試してみる価値はあると思います。
5.2. 既存結果のないデータセット
データサイエンティストの方によるお手本がない(見つけられなかった)データセットを実施します。
主にAutoMLサービス同士の性能を比較するためのものです。
5.2.1. 2クラス分類
使用データセット:ローン審査データセット
(誰でもAIモデルが作れる! Watson Studioに新しく搭載された機械学習の自動化機能「AutoAI Experiment」をザクっとご紹介します)
| 行数 | 特徴量数 |
|---|---|
| 2456 | 6 |
AutoAIの紹介をされていた記事からデータをお借りしました。
今回はSPSS Modelerに同梱されているローン審査についてのデータセットを利用したいと思います。
このデータセットは年齢やクレジットカード所持数の高低、収入の高低などからローンの可否を判定するものです。
実施結果は次のようになりました
| ツール | F値 | 適合率 | 再現率 | ROC AUC | トレーニング時間(min) | トレーニング費用(¥) |
|---|---|---|---|---|---|---|
| Google/AutoML Tables | 0.805 | 0.861 | 0.756 | 0.850 | 40 | 1,415.5 |
| IBM/AutoAI | 0.832 | 0.834 | 0.831 | 0.888 | 5 | 92.0 |
| Microsoft/AutomatedML | 0.805 | 0.805 | 0.805 | 0.880 | 20.0 | 24.3 |
| Sony/Prediction One | 0.847 | 0.800 | 0.899 | 0.886 | 0.85 | 0.0 |
| H2O Driverless AI | 0.8513 | 0.809 | 0.898 | 0.851 | 12.3 | --- |
精度に関してはそれほど大きな差は見られませんでした。
しかし、Google/AutoMLでは他に比べて長い時間がかかり、費用も高くなる結果となりました。
5.2.2. 多クラス分類
使用データセット:FIFA 19 complete player dataset
| 行数 | 特徴量数 |
|---|---|
| 18207 | 89 |
| サッカーゲーム、FIFAの選手データです。 | |
| 元々ゲーム用のデータなので、各種能力が数値で表されています。 | |
| カラムの内容としては、身体能力、市場価値、評価、ポジション、AIの行動方針などがあります。 | |
| 多クラス分類と回帰両方がテストできそうだったので選びました。 | |
| 多クラス分類では、23のポジションのうち、選手がどれに割り当てられているかを予測しました。 |
実施結果は次のようになりました
| ツール | F値 | 適合率 | 再現率 | ROC AUC | トレーニング時間(h) | トレーニング費用(¥) |
|---|---|---|---|---|---|---|
| Google/AutoML Tables | 0.574 | 0.774 | 0.456 | 0.972 | 5.53 | 11,655 |
| IBM/AutoAI | 0.585 | 0.585 | 0.585 | --- | 17.0 | 19,040 |
| Microsoft/AutomatedML | 0.493 | 0.493 | 0.493 | 0.918 | 55.8(打ち切り) | 4,068 |
| Sony/Prediction One | 0.437 | 0.526 | 0.374 | --- | 0.78 | 0 |
| H2O Driverless AI | 0.613 | 0.602 | 0.625 | 0.967 | 1.67 | --- |
トレーニング時間に大きな差がある一方、F値にはそれほど大きな差は出ませんでした。
とはいえ、ある程度まではかけた金額が大きい方が性能が高くなるようです。
5.2.3. 回帰
使用データセット:FIFA 19 complete player dataset
回帰では選手の賃金がいくらに設定されているかを予測しました。
| ツール | RMSE | R2 | トレーニング時間(h) | トレーニング費用(¥) |
|---|---|---|---|---|
| Google/AutoML Tables | 2.032 | 0.996 | 3.88 | 8,238 |
| IBM/AutoAI | 8.269 | 0.862 | 2.05 | 2,296 |
| Microsoft/AutomatedML | 13.057 | 0.647 | 12.0 | 874 |
| Sony/Prediction One | 6.39 | 0.916 | 0.49 | 0 |
| H2O Driverless AI | 7.65 | 0.89 | 0.731 | --- |
Google/AutoML Tablesの結果が良い、というか良すぎる気がします。
ドキュメントを見る限りだと交差検証とかはしていない印象を受けるので、過学習気味になってしまっている可能性は考えた方がよさそうです。
5.3. 補足:指標の説明
| 評価指標 | 説明 |
|---|---|
| F値 | 適合率と再現率の調和平均 1に近い程良い |
| 適合率 | 正値を予測したデータの内、標本値でも正値だったデータの割合 1に近いほど良い |
| 再現率 | 標本値が正値になっているデータの内、正値を予測できたデータの割合 1に近いほど良い |
| ROC AUC | 間違いの割合vs正解の割合で書かれたグラフ下の面積 1に近いほど良い |
| RMSE | 予測値と標本値の誤差を二乗して平均を出し、平方根を取ったもの 0に近いほど良い |
| R2 | 予測値と標本値の誤差の二乗和を標本値と平均の差の二乗和で割って1から引いたもの 1に近いほど良い |
6. まとめ
- Google/AutoML Tables
- データがたくさんあるなら効果は高い、そうでなければ過学習に注意が必要
- "誰でも使える感"が高い
- IBM/AutoAI
- 比較的少ないデータでよい結果が得られる
- モデルの内部構造が分かりやすい
- Microsoft/AutomatedML
- 得られる情報の量が多い
- GUIが不安定
- Sony/Prediction One (2019/11/13追記)
- 統計・機械学習が分からない人向け
- ローカル環境なので気楽に扱える
- H2O Driverless AI (2019/11/15追記)
- 利用できる機能が非常に多い
- Driverless AIそのものへの学習が必須
7. 感想
雑にやってこの精度が出るなら単に精度が出せるだけだと今後やってけないんだろうなぁ、と感じました。
とはいえ課題設定とかデータの用意までやってくれるものでもないですし、そういった方向性で勉強していくのが大事なのかなと思います。
8. 今後の更新(2月中を予定)
AWS/Sagemaker Autopilot
ようやく来たので。
時系列分析
Prediction Oneに時系列分析が追加されたため。
おまけ 今回試さなかったツール
Datarobot
個人で使う方法が多分ないので
AWS/MachineLearning
サービス終了してたので(Sagemakerはなんか違う感じだった)