1.はじめに
今日は、**GoogleCloudPlatformの「AutoMLTables」**を使ってみようと思います。いつも通り、KaggleのTitanicのデータを使うと思ったのですが、AutoMLTables は1,000以上のサンプルが必要とのことで、そのままでは使えません(2019/07/07時点)。そこで、あまり良い方法とは言えませんが、いままで試してきたAutoMLと比較したいということもあり、学習時はデータをコピーして2倍にして使ってみることにします。
2.環境とデータ
(1)環境
・Windows10
・GoogleCloudPlatform(AutoMLTables)
※今回は、初回登録時にもらえるサービスクレジットの範囲で実施しているため支払いは発生していませんが、有償の機能となります。
(2)データ
Kaggle Titanicのデータ
https://www.kaggle.com/c/titanic/data
※AutoMLTables の「1,000以上のサンプルが必要」という条件に合わせて、学習データはデータを複製して2倍にしています。
3.事前準備
(1)プロジェクトの作成
①GoogleCloudPlatformの帯のプロジェクトを選択して「新しいプロジェクト」をクリックします。
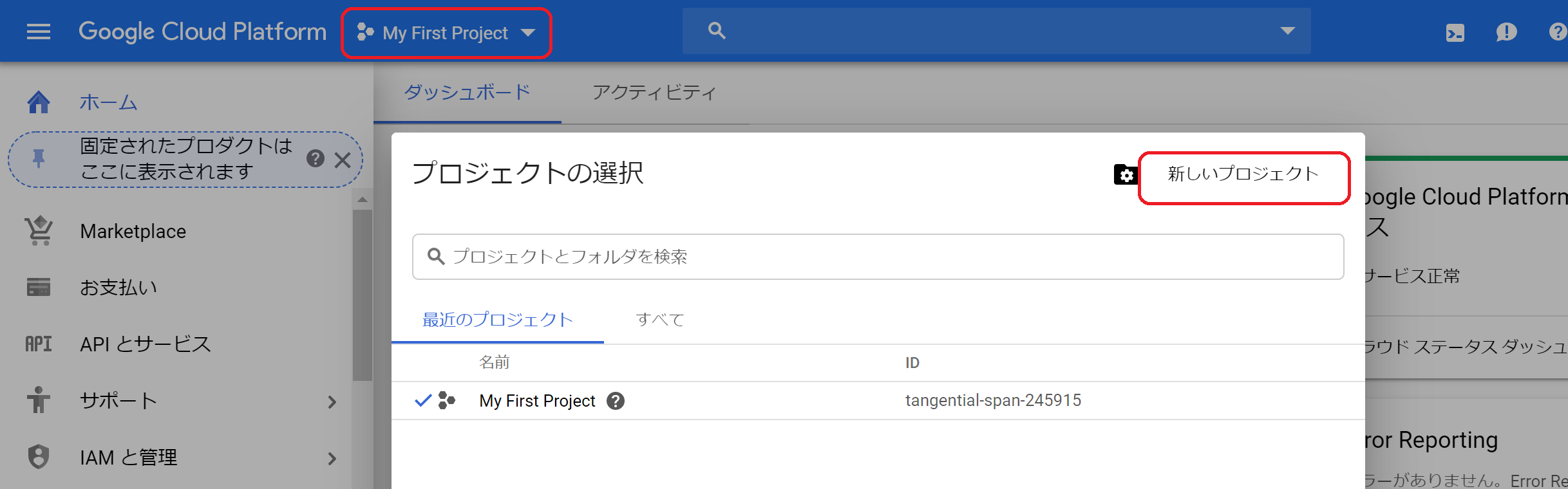
②新しいプロジェクトの作成画面が表示されるのでプロジェクト名「Titanic」、場所「組織内」を入力して「作成」ボタンをクリック。
③プロジェクトの作成が完了したら、もう一度「プロジェクトの選択」から作成した「Titanic」のプロジェクトを開きます。
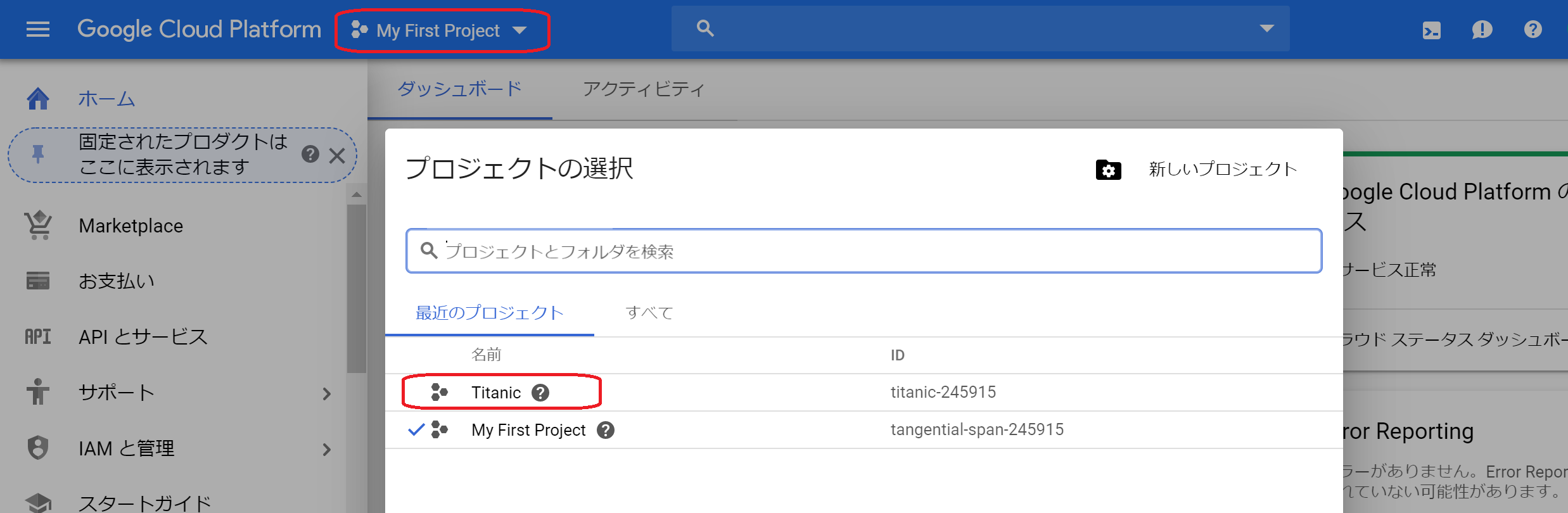
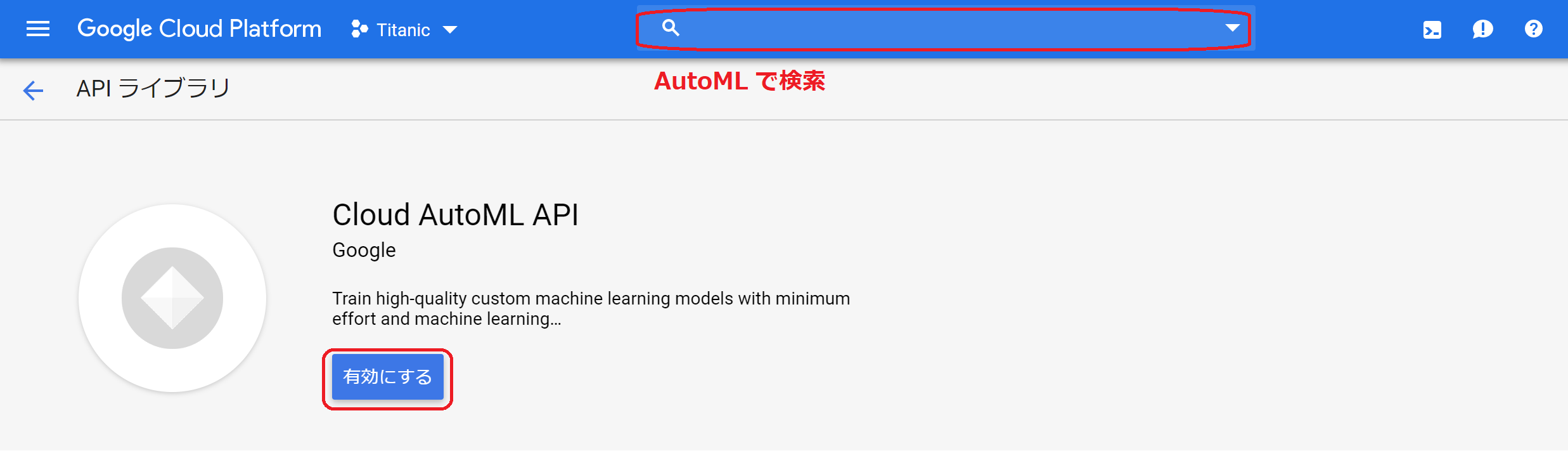
(2)CloudAutoMLAPIの有効化
①上の帯の検索欄に「AutoML」と入力すると、CloudAutoMLAPIが出てくるので選択します。画面が表示されたら、「有効にする」をクリックします。
(3)Storageへデータをアップロード
①サイドメニューの「Storage」-「ブラウザ」をクリック。
②「バケットの作成」をクリック。
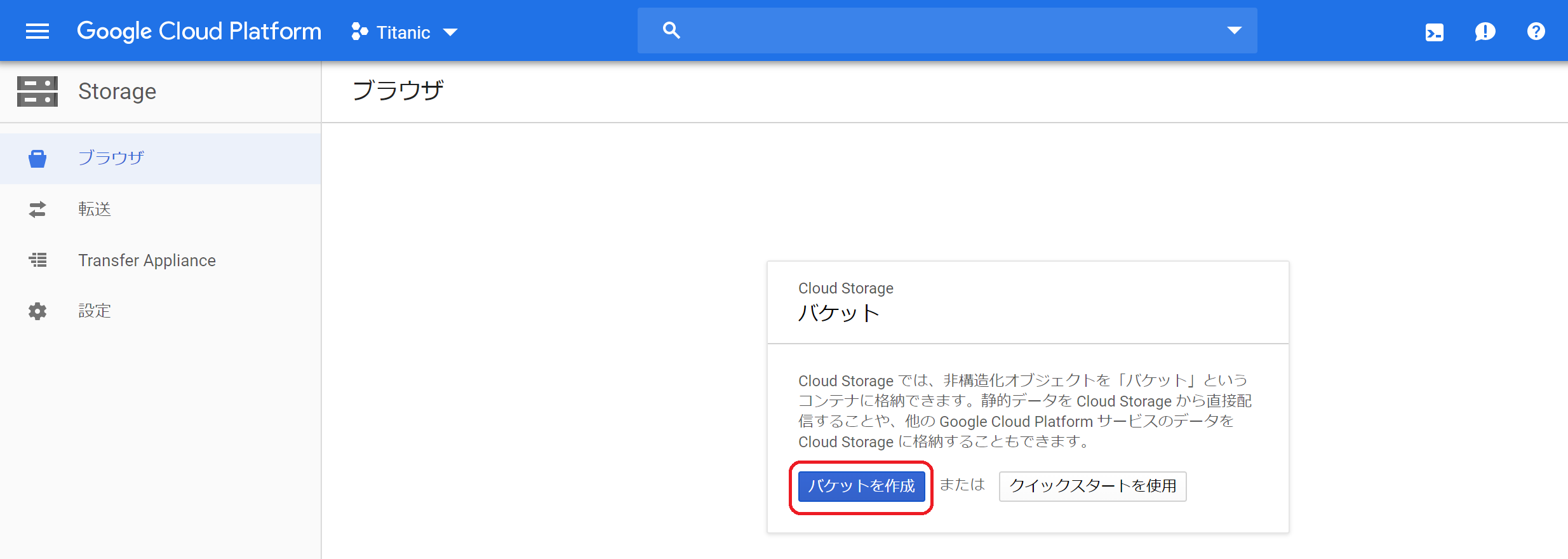
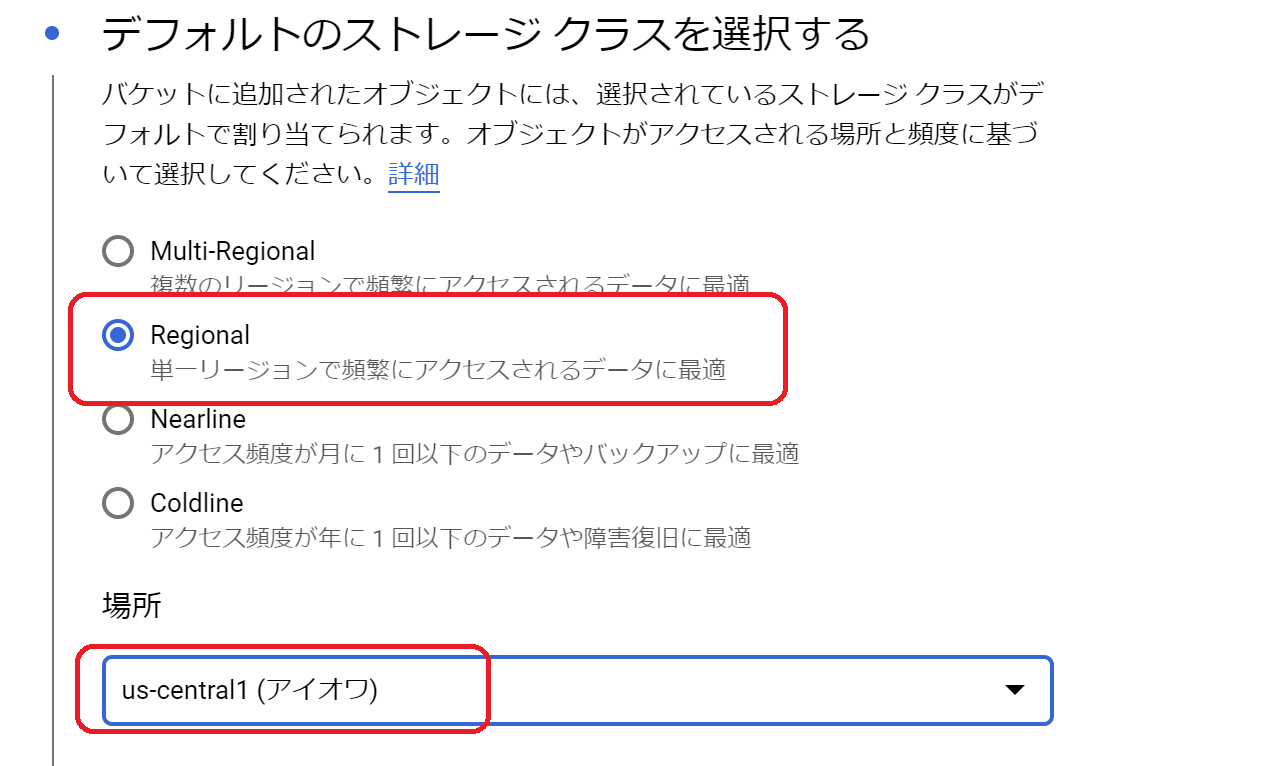
②バケット名(適当に)、ストレージクラスなどを入力し「作成」をクリック。ストレージクラスは、下図のようにクラス「Regional」、場所「us-central」を選択してください。現時点ではus-centralしか対応していないようです。
③バケットの作成ができたら、対象バケットを開き「ファイルをアップロード」から、train.csvとtest.csvをアップロードします。(この時に、1,000件ルールのため、train.csvはデータを2倍にしました。(この手順は今回の実験のための手順です。通常はお勧めしません。)
4.AutoMLTablesを使ってみる
(1)データセットの登録
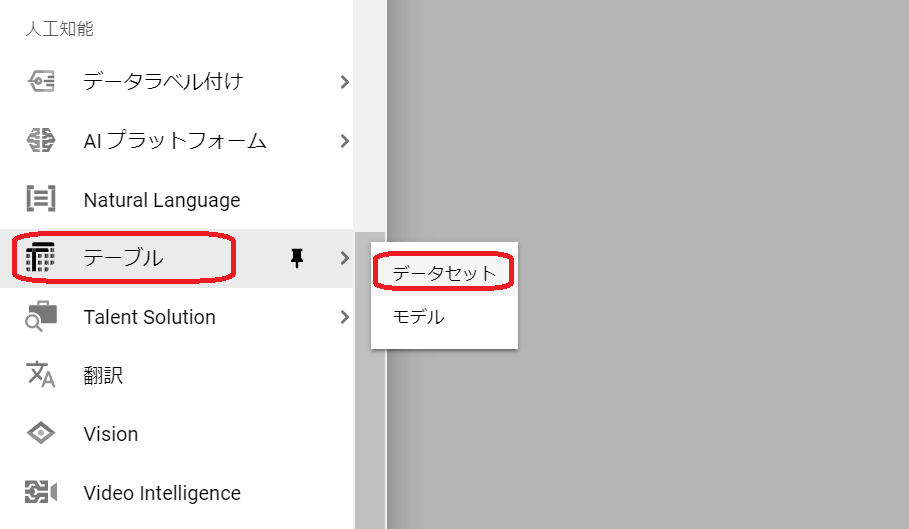
①サイドメニューの人工知能欄(結構下の方)にある「テーブル」-「データセット」をクリック。
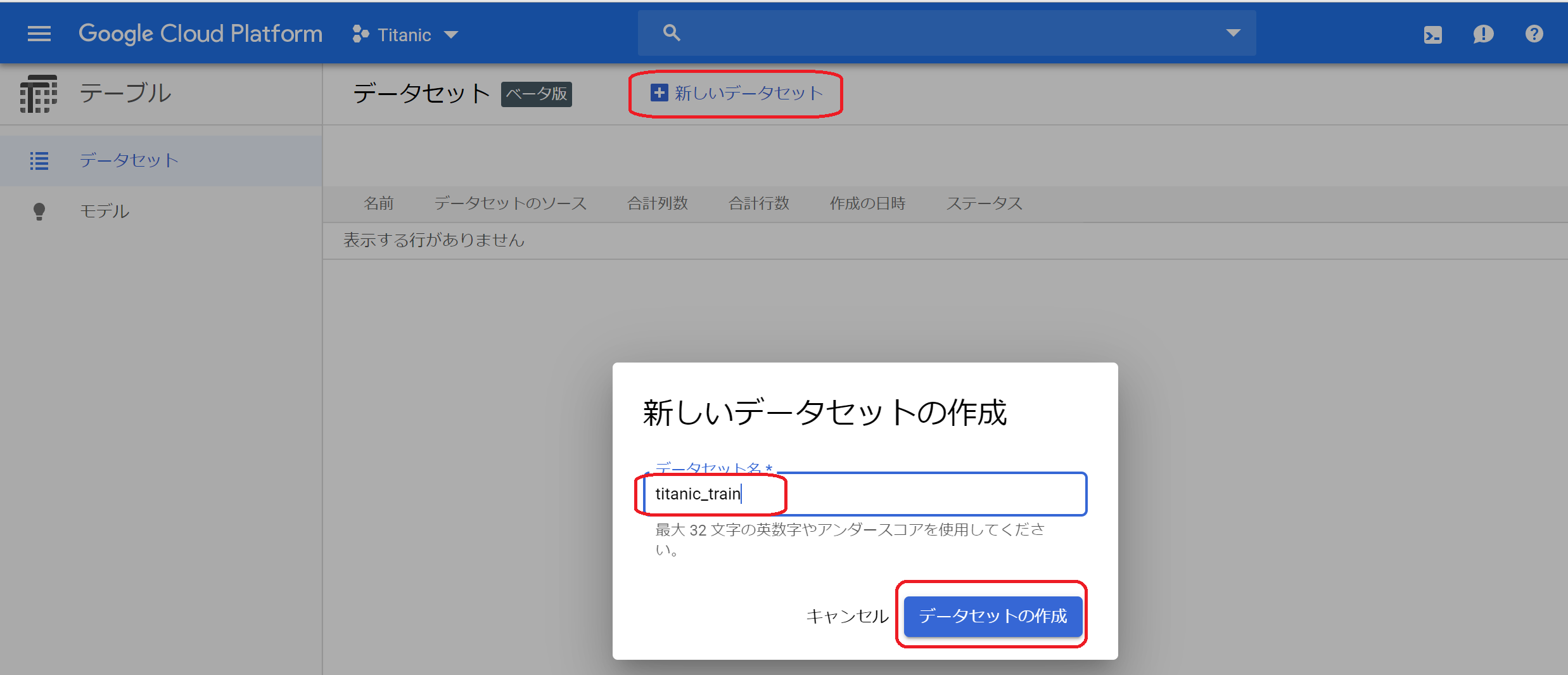
②画面上部の「+新しいデータセット」をクリックすると、入力ダイアログが表示されます。データセット名を入力して、「データセットの作成」をクリック。
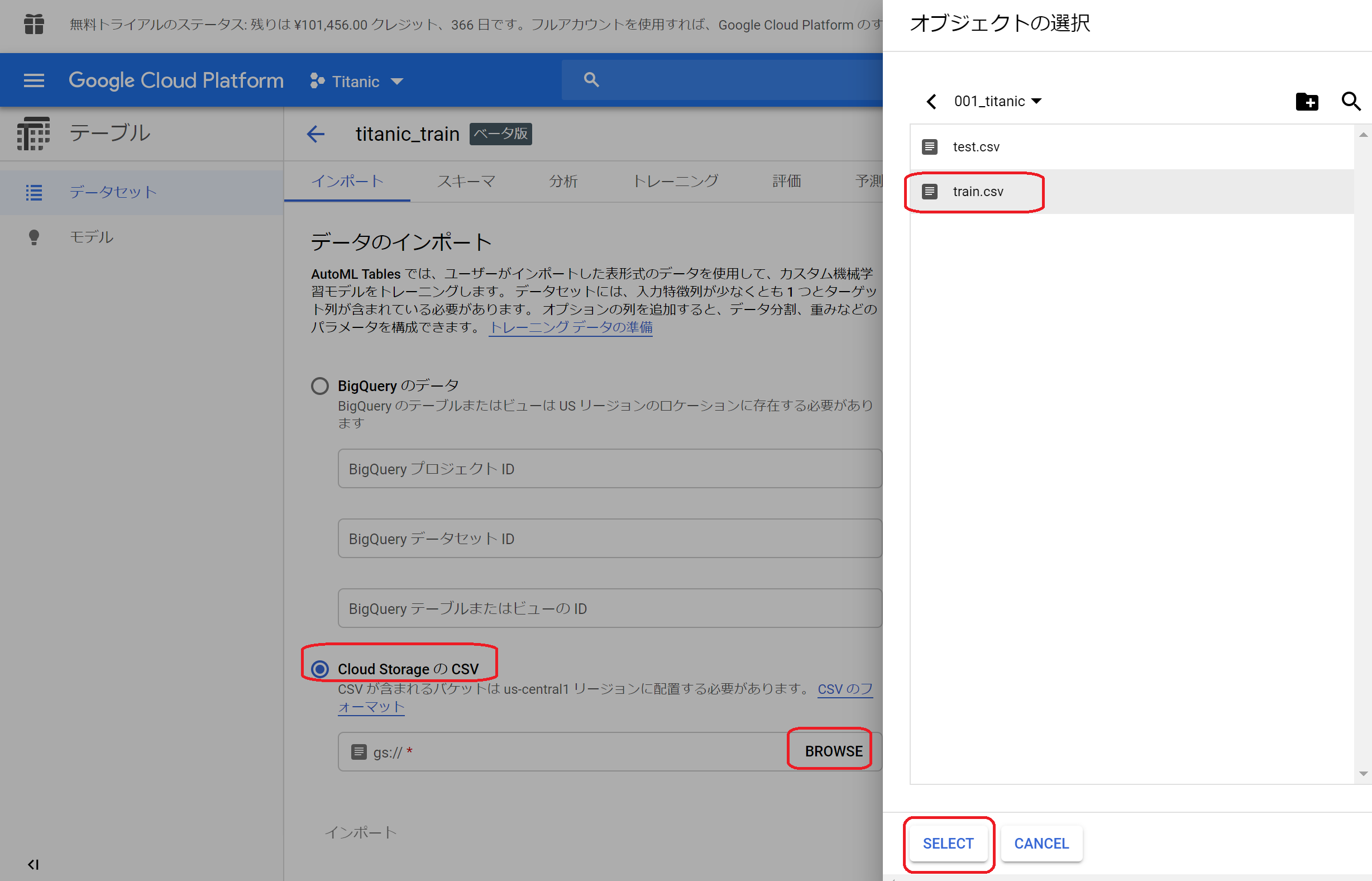
③データのインポート画面が表示されるので、「CloudStrageのCSV」を選択し、BROWSを押して先ほど登録した学習用データを選択して「SELECT」ボタンをクリック。パス欄にデータのありかが反映されたら、画面下部の「インポート」ボタンをクリックします。
(2)ターゲットの選択
①インポートが完了したら、スキーマの設定をします。ターゲットの選択欄で目的変数を選択します。この画面では、Null値を許容するかの設定ができます。読み込んだデータの状況に応じて設定が初期表示されますが、test.csvにはFareがnullのデータが存在するので、FareをNullableに変更します。
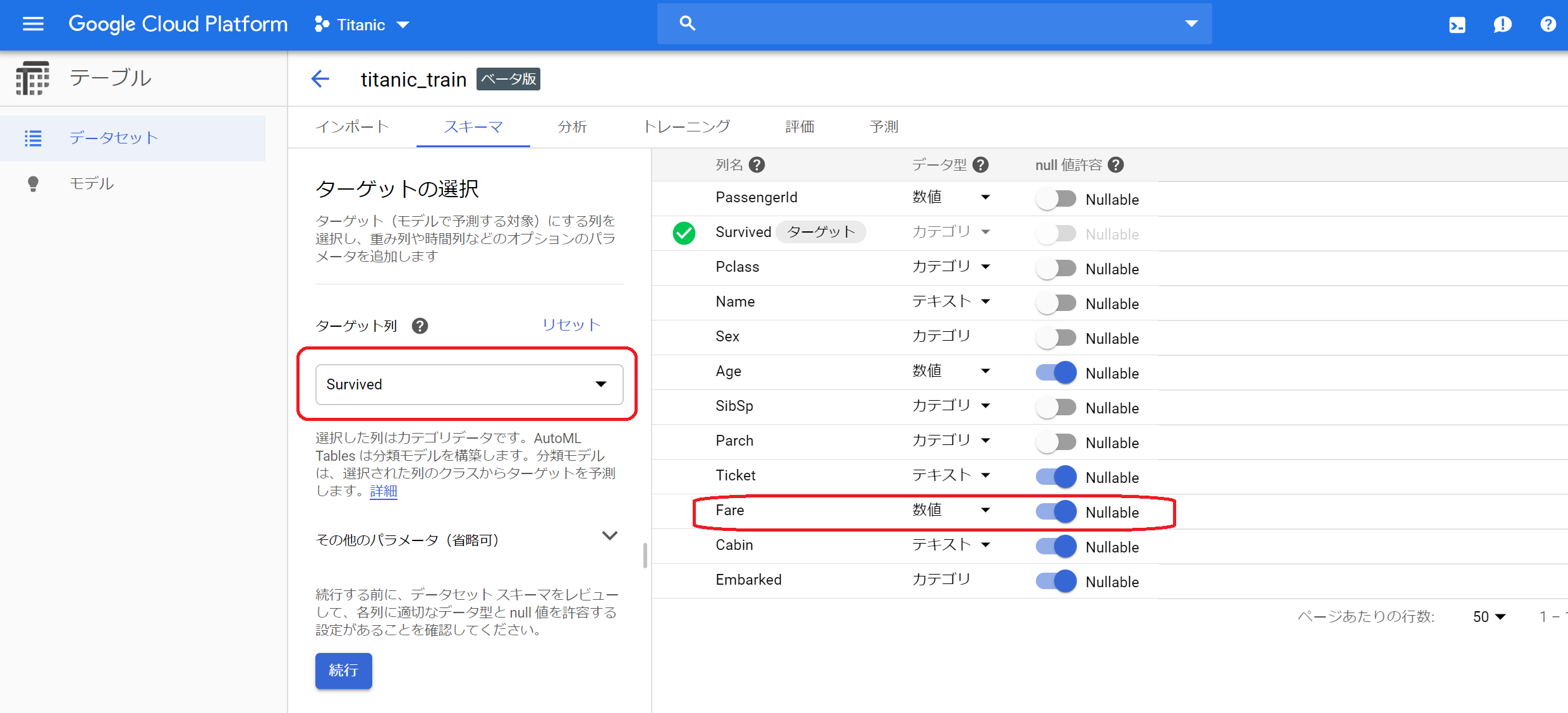
②「続行」をクリックします。
(3)データの概況確認
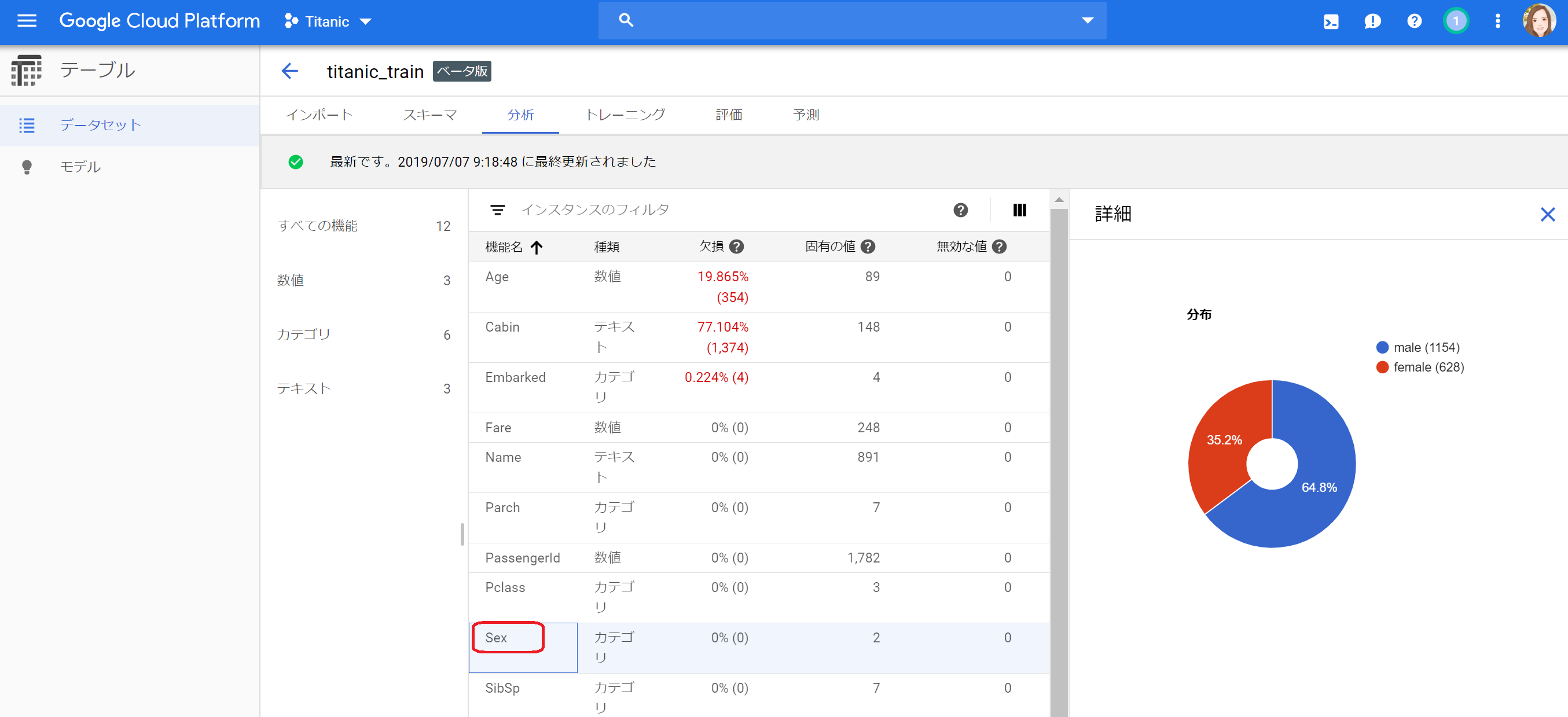
①分析画面が表示されます。この画面がななか便利です!!変数名を選択すると右側に分布が表示されます。これで、簡単にデータの状況が把握できますね!!!!
(4)学習
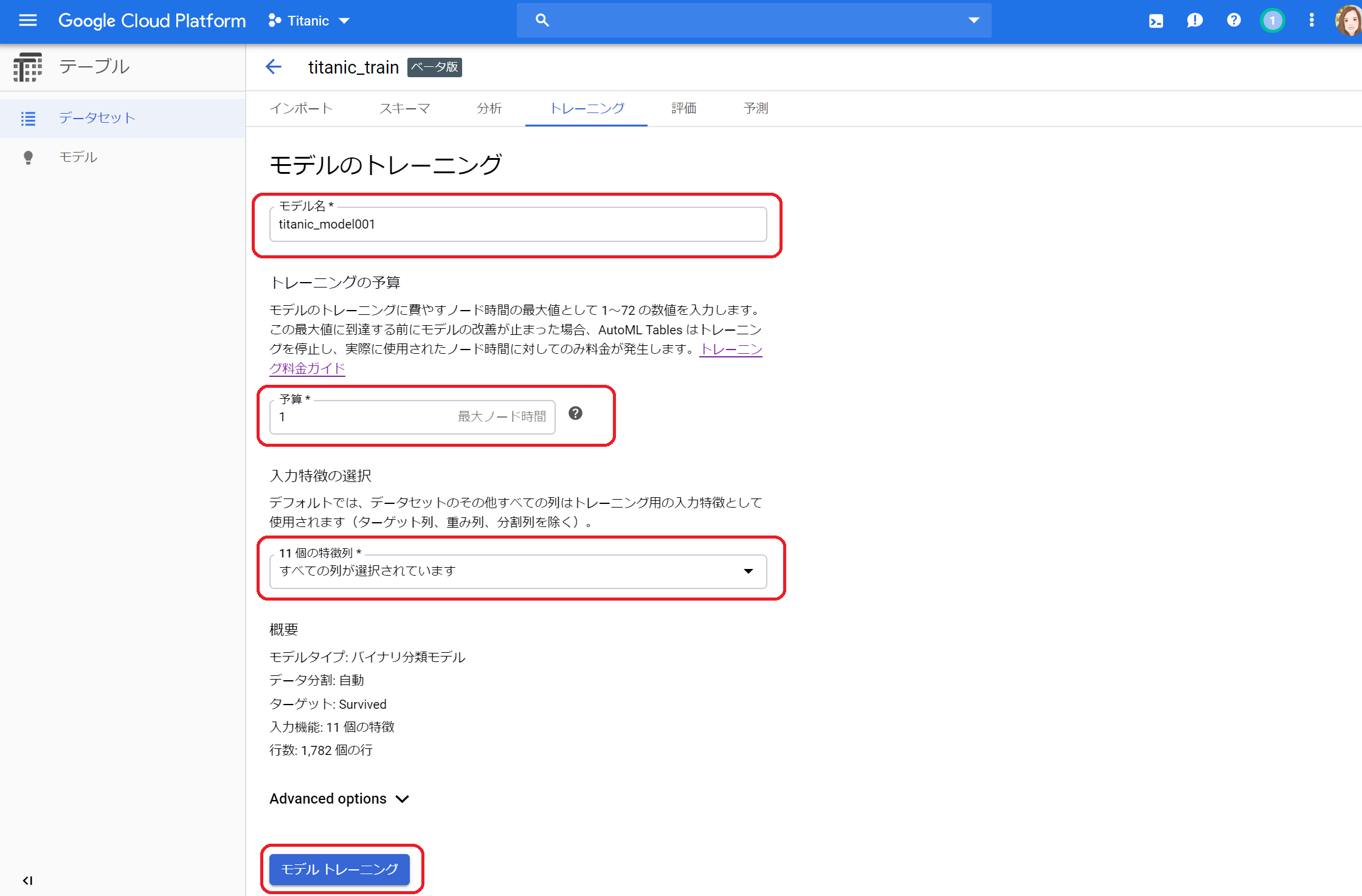
①早速学習してみます。上の「トレーニング」タブを選択します。モデル名(適当)、予算、変数を選択して「モデルトレーニング」をクリックします。予算はヘルプを見ると、以下のように書いてありました。今回は1000件ちょっとですので1時間もあれば十分かな?と思い「1」を設定しました。変数は、とりあえず何も考えず全投入します。
データセットの行数別の推奨されるノード時間:
<100,000 行:1~3 時間
100,000 - 1,000,000 行:1~6 時間
1,000,000 - 10,000,000 行:1~12 時間
>10,000,000 行:3~24 時間
②学習が完了するとこのような画面が表示されます。
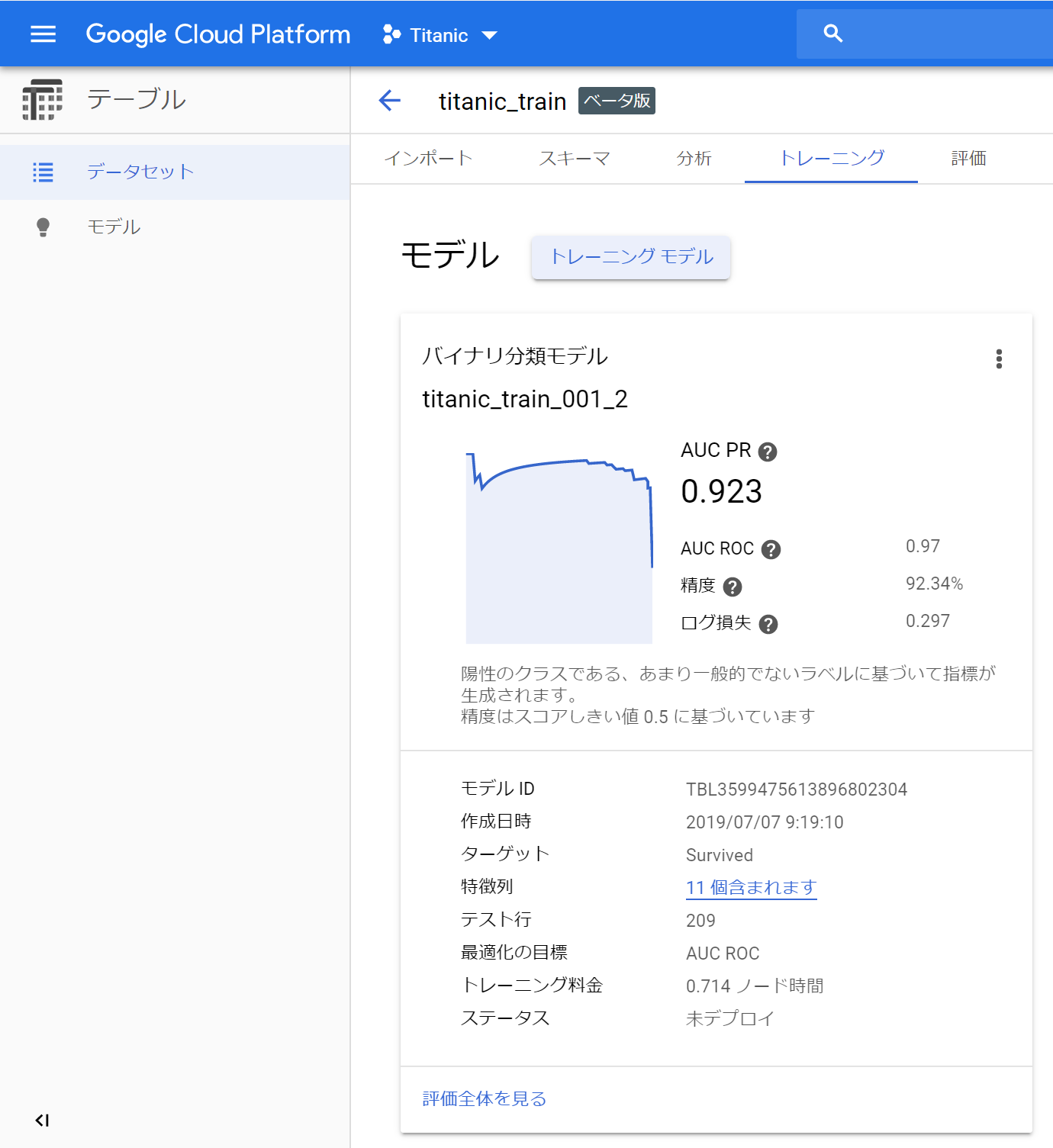
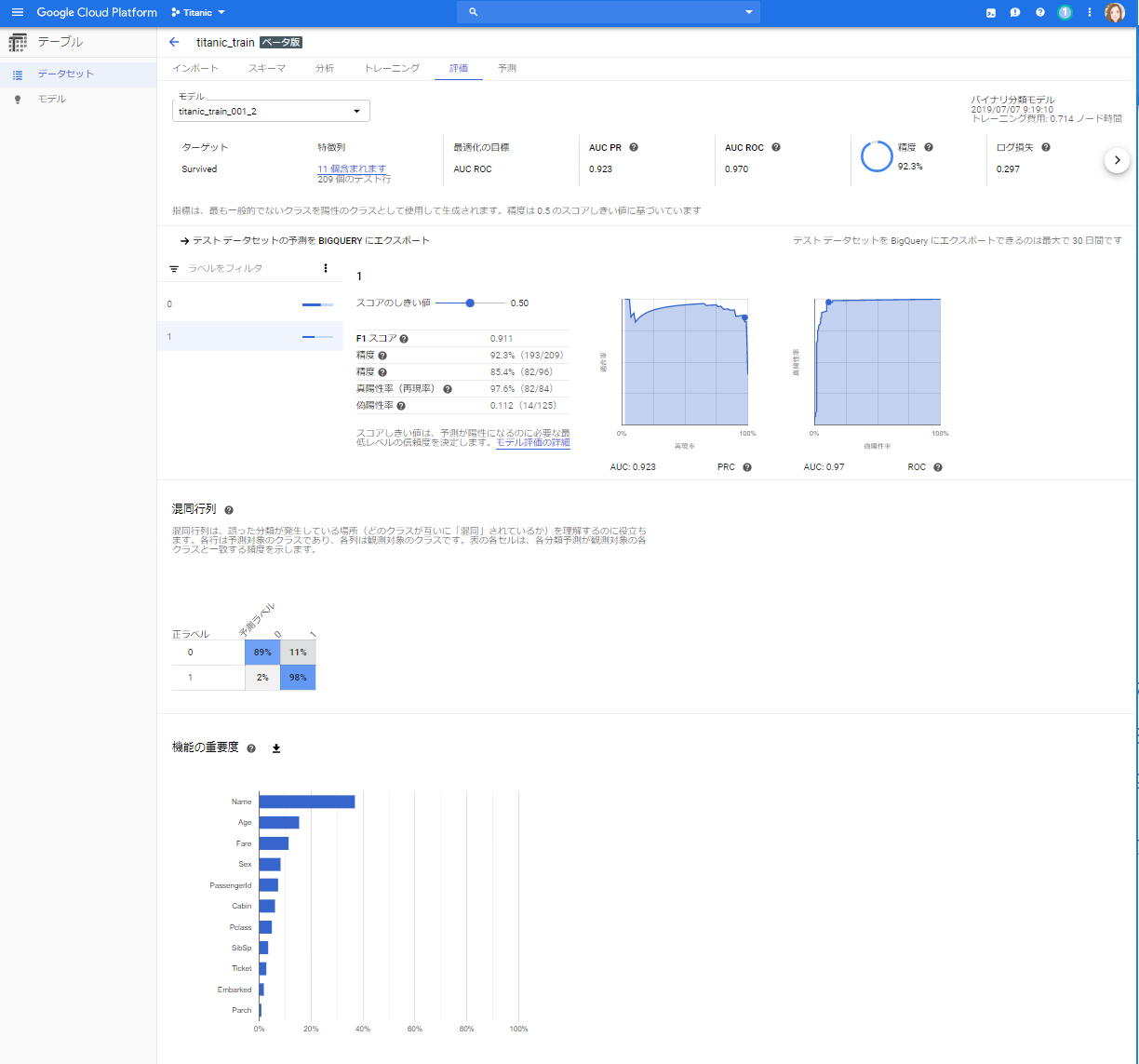
③「評価全体を見る」をクリックするとこのような画面が表示されます。とても親切ですね!!全体的に痒い所に手が届くといった印象です。**「トレーニング費用: 0.714 ノード時間」**と書かれているので、40分くらいかかったということですね。
(5)予測
①それでは、このモデルで評価をしてみましょう。予測タブを開き、入力データセットと結果の出力フォルダを指定して「バッチ予測を送信」をクリックします。
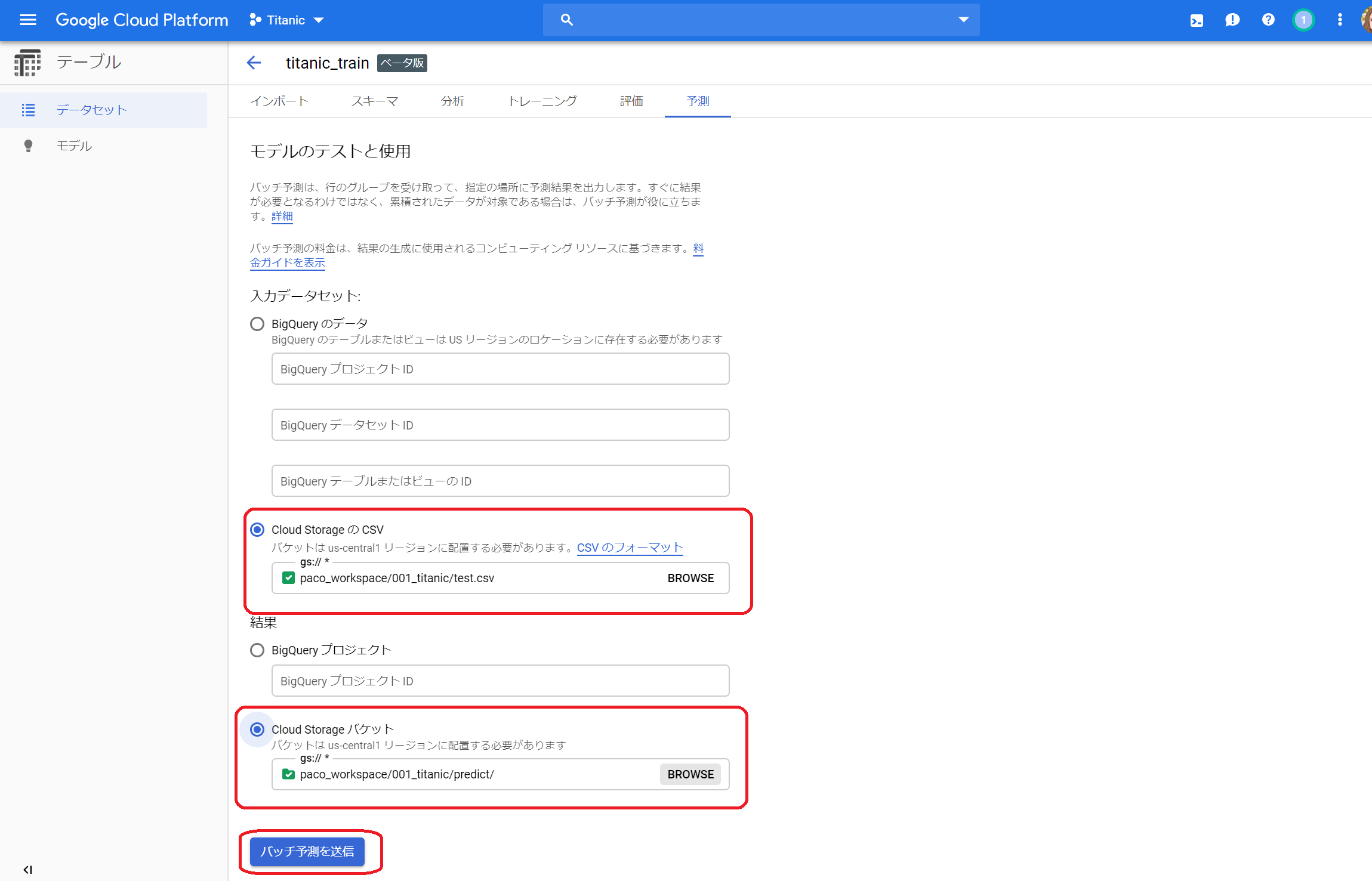
②2分12秒で完了しました。

③では、出力フォルダ(Strage)で結果を見てみましょう。このような形で出力されていますね。早速開いてみます。
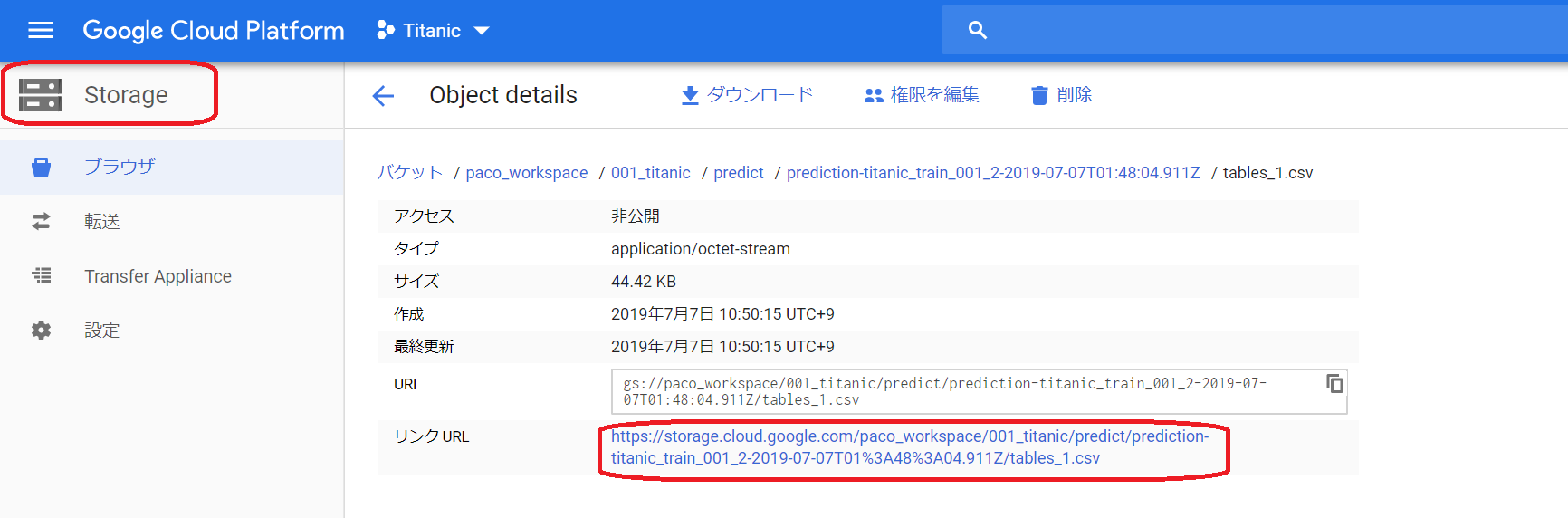
④こんな雰囲気で出力されています。
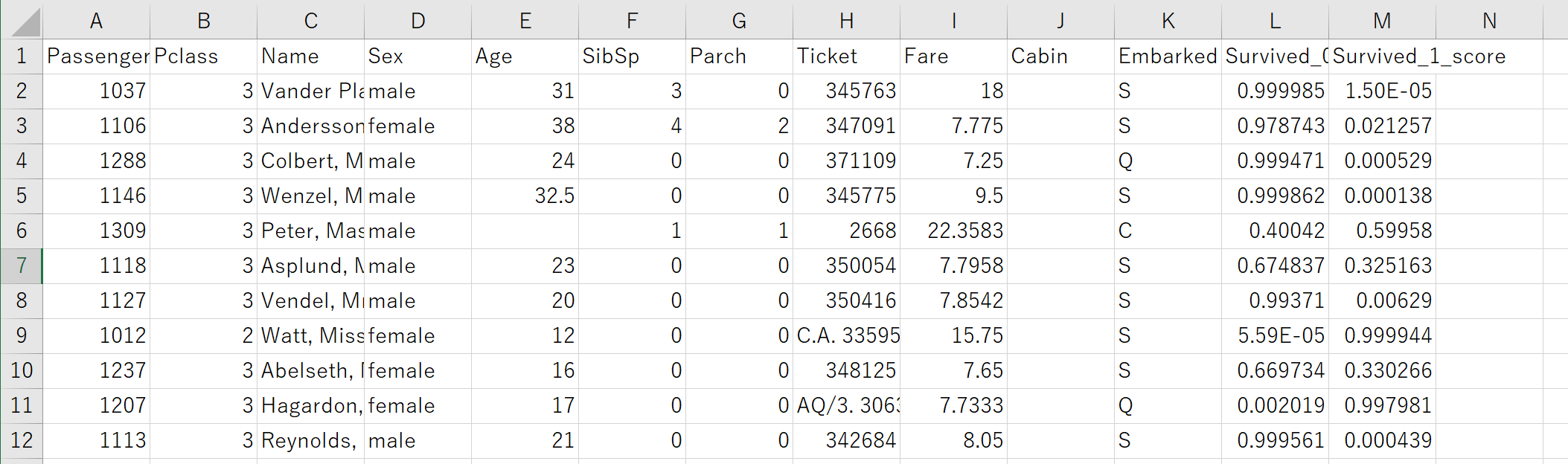
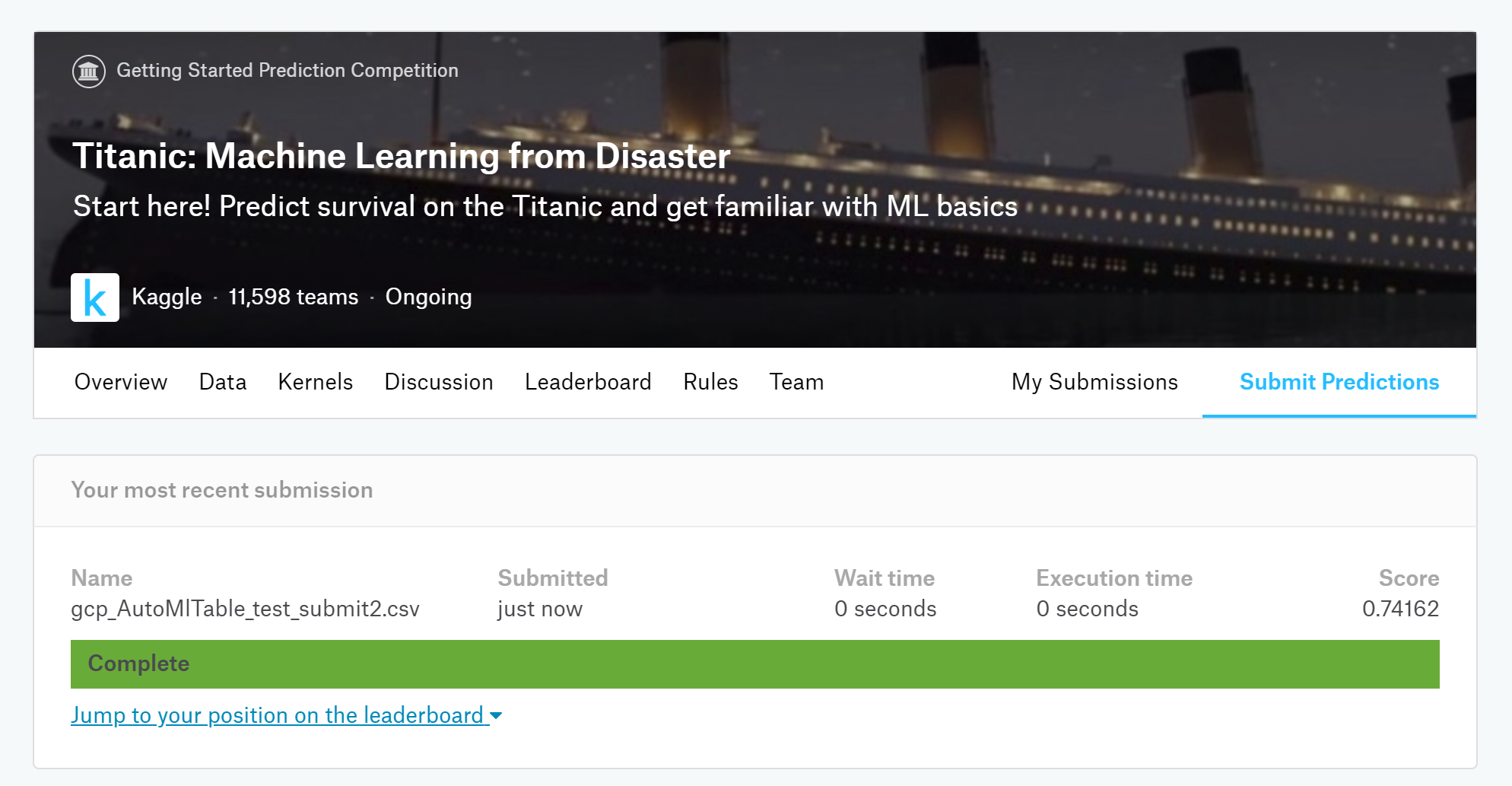
⑤それでは、この結果をKaggle用のフォーマットに直して、KaggleでSubmitしてみます!!
⑥結果は・・0.74162!ベスト更新ならず!
5.感想
(1)操作性
GCPのAutoMLTablesは使い方もそれほど難しくないです。1行もコーディングする必要がありません。また、データを読み込むと分布を可視化してくれるなど、面倒な作業を自動化してくれているのも魅力です。
これまで試してきたツールを、操作の簡単さで並べると、
PredictionOne(Sony)>AutoMLTables(GCP)>>>AutoAI(IBM)
といったところでしょうか。
(2)学習にかかる時間
AutoMLTablesでは学習に30~40分かかりました。AutoAIもPredictionOneも数分で終わっていたことを考えると、ちょっと時間がかかりますね。
(3)精度
一見、AutoMLTables(GCP)の精度がとても良いように見えますが、予測してみると他のツールと比較してもそれほど差がないことを考えると、やや過学習する傾向にあるのかもしれません。AutoMLTablesでも、PassangerID、Name、Ticketの3変数を除外して学習してみましたが、あまり変わりませんでした。
AutoMLの比較
| ツール | 変数 | モデル | AUC(学習) | Accuracy(学習) | Precision(学習) | Recall(学習) | Kaggle(予測) |
|---|---|---|---|---|---|---|---|
| AutoAI(IBM) | 手動3変数削除 | XGBClassifier | 0.88 | 0.84 | 0.80 | 0.77 | 0.775 |
| PredictionOne(SONY) | 自動3変数削除 | 2値分類 | 0.85 | 0.77 | 0.66 | 0.84 | 0.756 |
| AutoMLTables(GCP)※1 | 全変数 | バイナリ分類モデル | 0.97 | - | 0.85 | 0.98 | 0.741 |
| AutoMLTables(GCP)※1 | 手動3変数削除 | バイナリ分類モデル | 0.97 | - | 0.88 | 0.89 | 0.732 |
| AutoAI(IBM) | 全変数 | ExtraTreesClassifier | 0.87 | 0.81 | 0.73 | 0.81 | 0.727 |
※1:学習データのサンプル数が1,000件以上必要なため、データを2倍に複製
🌟Update2019/07/07 16:00(修正)🌟
当初上記の結果をあげていたのですが、データを2倍にするときのIDの振り方が適切でなかったのでやり直した結果を下記に示します。元のやり方では、2倍にするときにPassangerIDを続きの連番で振ってしまっていたのですが、それだと前半の繰り返しなのでID自体に意味が出てきてしまいます。また、test.csvにも同じIDがあるのでよろしくありません。そこで、やり直し版ではPassangerIDの振り直しはせずにもとのIDのままにしました。なお、「4.AutoMLTablesを使ってみる」の章の画像は当初のままになっています。
この結果を見ると、AutoMLTablesは全変数投入してもかなりいい精度が出ています。
AutoMLの比較(修正版)
| ツール | 変数 | モデル | AUC(学習) | Accuracy(学習) | Precision(学習) | Recall(学習) | Kaggle(予測) |
|---|---|---|---|---|---|---|---|
| AutoMLTables(GCP)※1 | 全変数 | バイナリ分類モデル | 0.90 | - | 0.87 | 0.78 | 0.785 |
| AutoAI(IBM) | 手動3変数削除 | XGBClassifier | 0.88 | 0.84 | 0.80 | 0.77 | 0.775 |
| AutoMLTables(GCP)※1 | 手動3変数削除 | バイナリ分類モデル | 0.89 | - | 0.87 | 0.78 | 0.770 |
| PredictionOne(SONY) | 自動3変数削除 | 2値分類 | 0.85 | 0.77 | 0.66 | 0.84 | 0.756 |
| AutoAI(IBM) | 全変数 | ExtraTreesClassifier | 0.87 | 0.81 | 0.73 | 0.81 | 0.727 |
※1:学習データのサンプル数が1,000件以上必要なため、データを2倍に複製
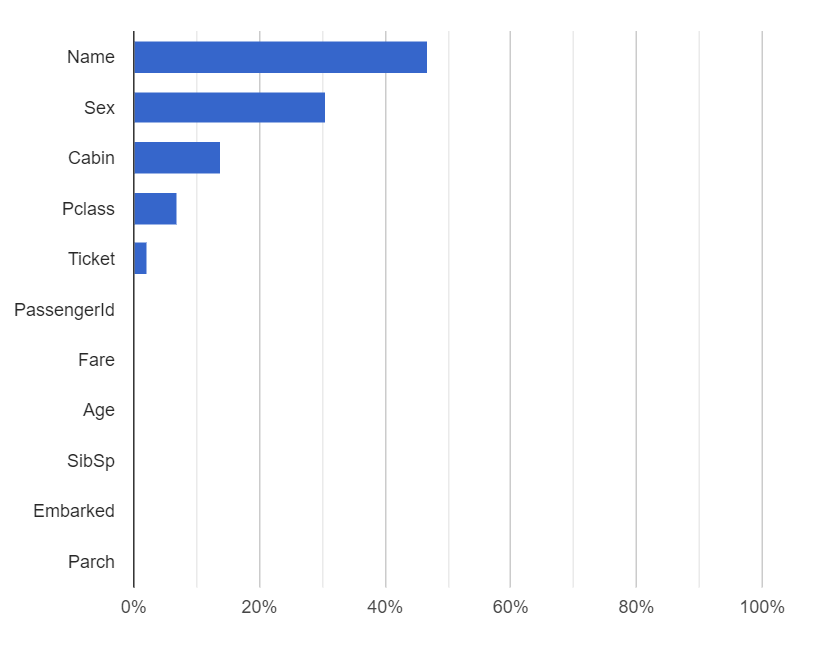
参考までに全変数投入時(修正版)の、変数の重要度は以下のようになっていました。
(4)費用
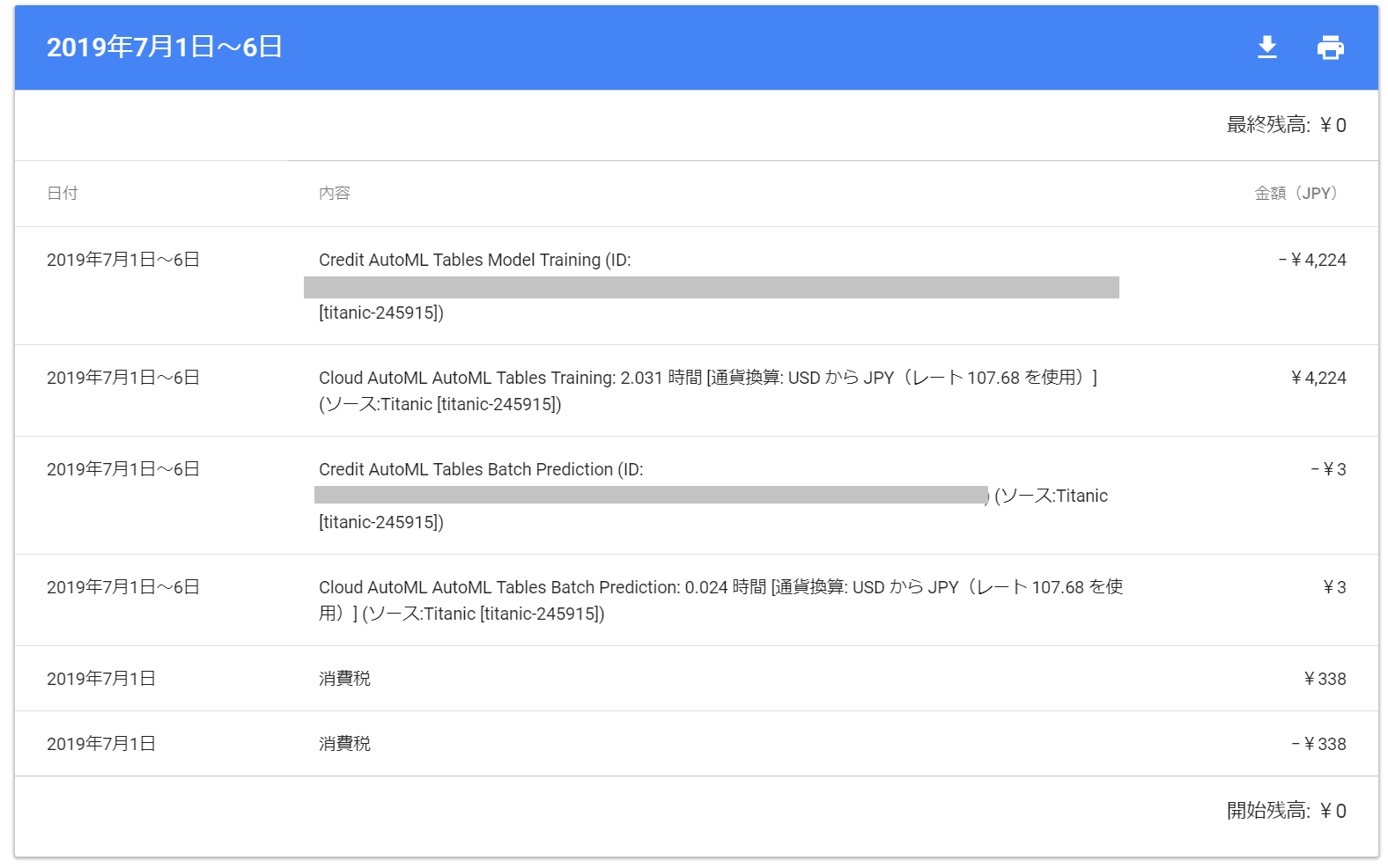
今回、この記事を書くにあたり色々試行錯誤した結果、費用はこれくらいかかっていました。学習に4,224円、予測に3円です。
今回は初回登録時の無償枠(クレジット)の範囲なので実質支払額はゼロですが、正規料金だとお小遣いで払うのにはちょっと大きい金額ですね。1回飲み会をあきらめれば済む金額ではあります🍺
料金については以下に詳細が記載されていました。
AutoML Tablesベータ版
https://cloud.google.com/automl-tables/?hl=ja
トレーニング(学習)にかかる費用は、
6 時間の無料使用 1 回 + $19.32/時間
とのことです。今回1回あたり40分くらいかかっていたので**$12.88/回**、$1.0=¥109 で計算すると約1,400円ということになります。これまでに4回学習の実行をしたので、1回分無料+1,400円×3回=4,200円。大体あっていますね。
6.関連記事
これまでのAutoMLの実験の記事は以下の通りです。よかったら読んでください🌟
SONYのAutoMLサービス「PredictionOne」を使ってみた
https://qiita.com/paco_itengineer/items/7b6f1c62ae7263ac1a43
WatsonStudioの「AutoAI」を使ってみた(学習編)
https://qiita.com/paco_itengineer/items/910b7ee4b6373ff21e4e
WatsonStudioの「AutoAI 」を使ってみた(評価編)
https://qiita.com/paco_itengineer/items/ca1f97f17bb91ac351eb
GoogleCloudPlatformの「AutoMLTables」を使ってみた
https://qiita.com/paco_itengineer/items/4cf064d272f007fcae57