1.はじめに
WatsonStudioの「AutoAI」を使ってみた(学習編)に続きまして、今回は評価編を書こうと思います。今回も、可能なかぎり「マニュアルは読まない!」のポリシーでやっていこうと思います。(が、途中で一部参照してしまいました)
前回、モデルの構築をして保存するところで終わっているので、今回はtest.csvで予測をするためにデプロイするところから始めます。最後の方ではKaggleにsubmitしてみたり、SonyのPredictionOneと比較したりもします。
一応、予測に使ったpythonのコードも公開してありますが、あまりコーディングは得意ではなく、ミスがあったらすみません💦💦
2.環境
・Windows10
・WatsonStudio(IBMCloud)
・python3.6.4(Anaconda) ※ローカル環境
3.手順
(1)デプロイする
①WatsonStudioのAssetのページを開くと、下の方に前回作ったモデルが表示されているので、クリックします。
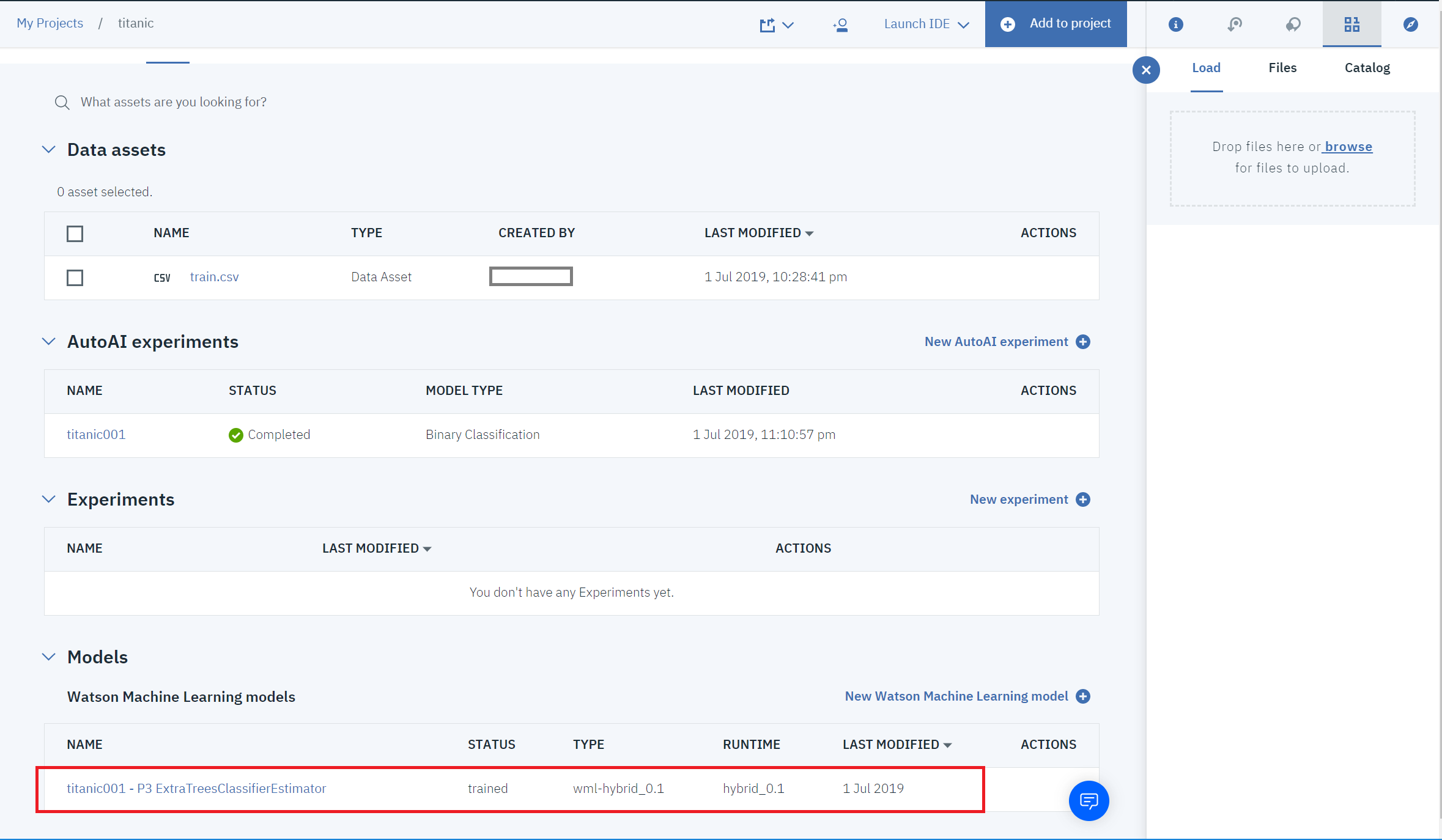
②Deploymentsタブをクリックします。
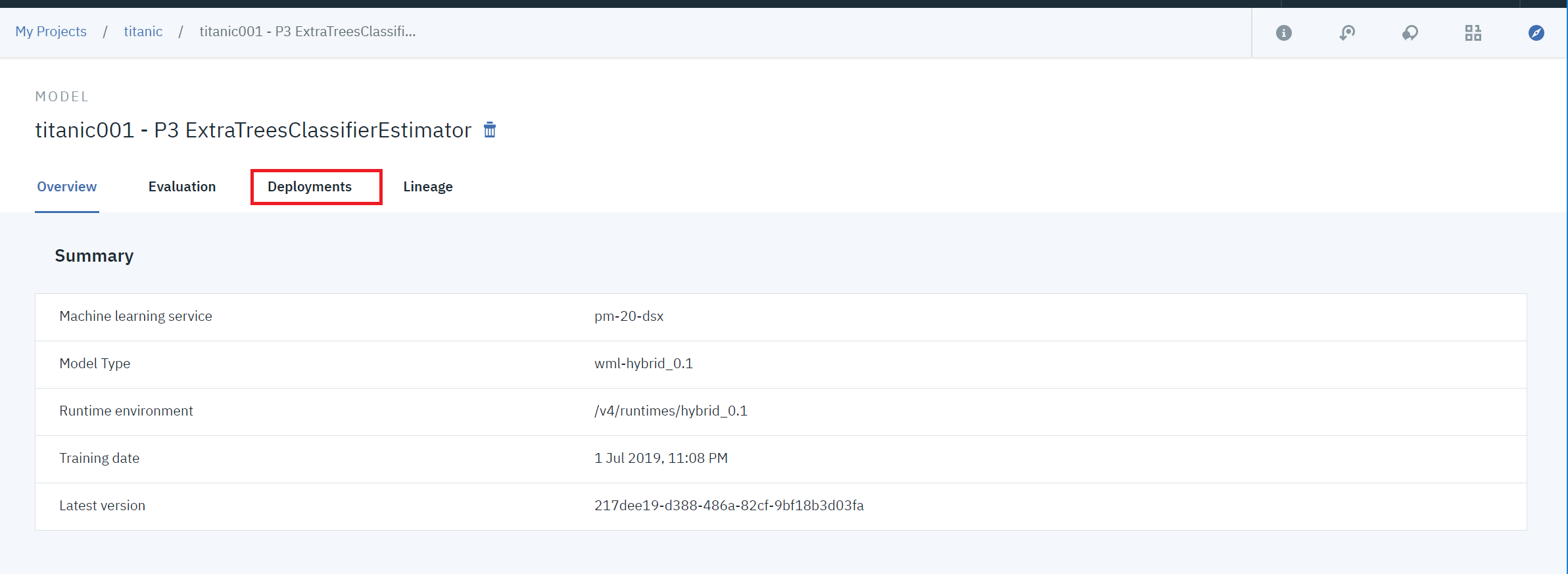
③まだ、デプロイできていないので「Add Deployment」をクリックします。
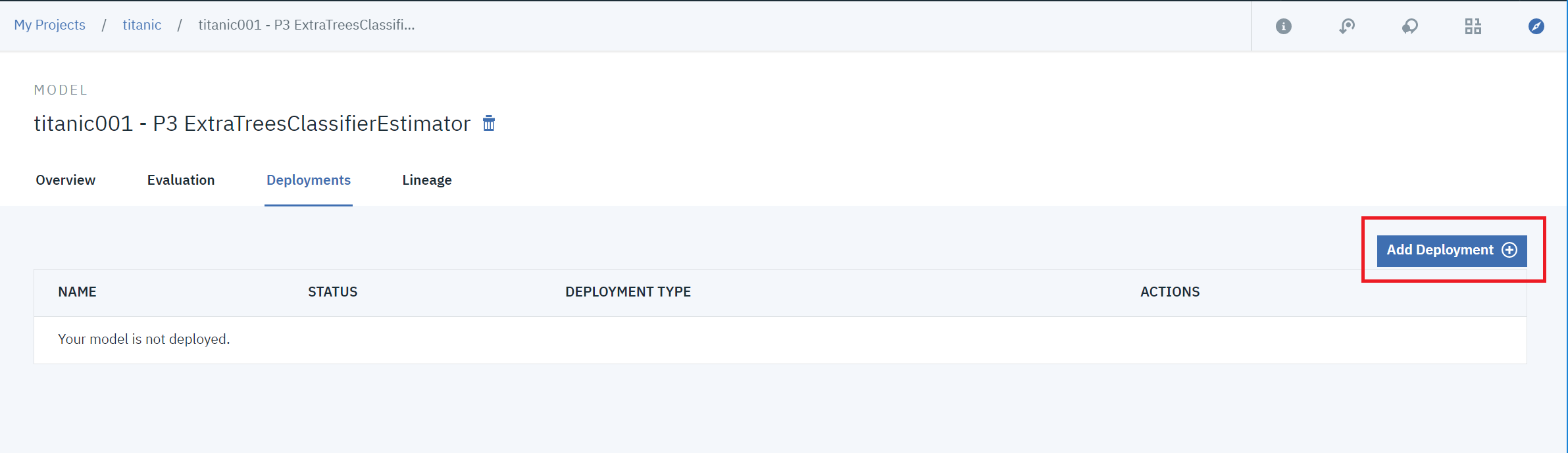
④適当な名前を付けて「Save」をクリックします。
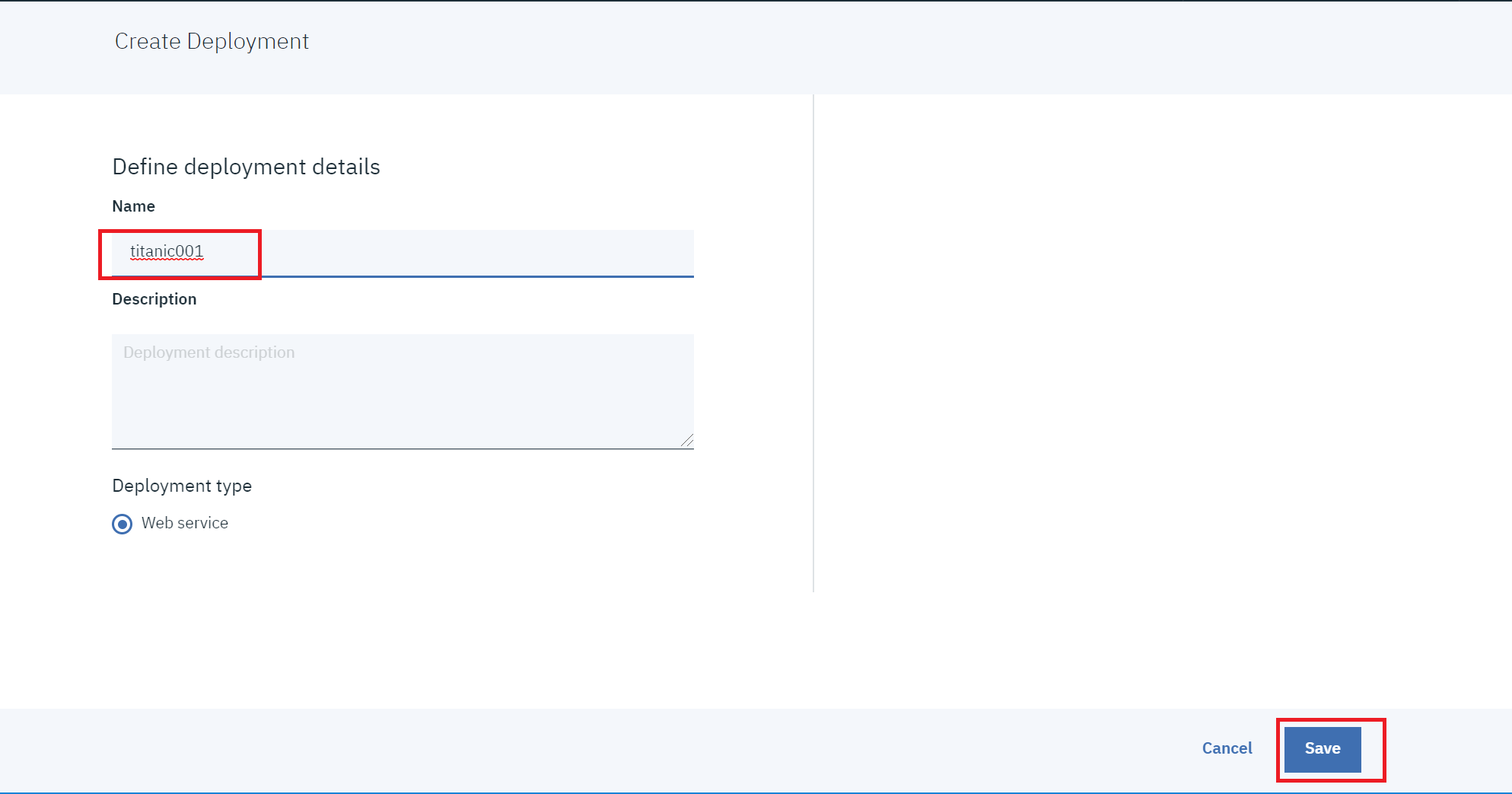
⑤1分くらいでデプロイが完了。Nameをクリックします。
(2)予測を試す
①デプロイやモデルの情報が表示されます。testタブをクリックします。
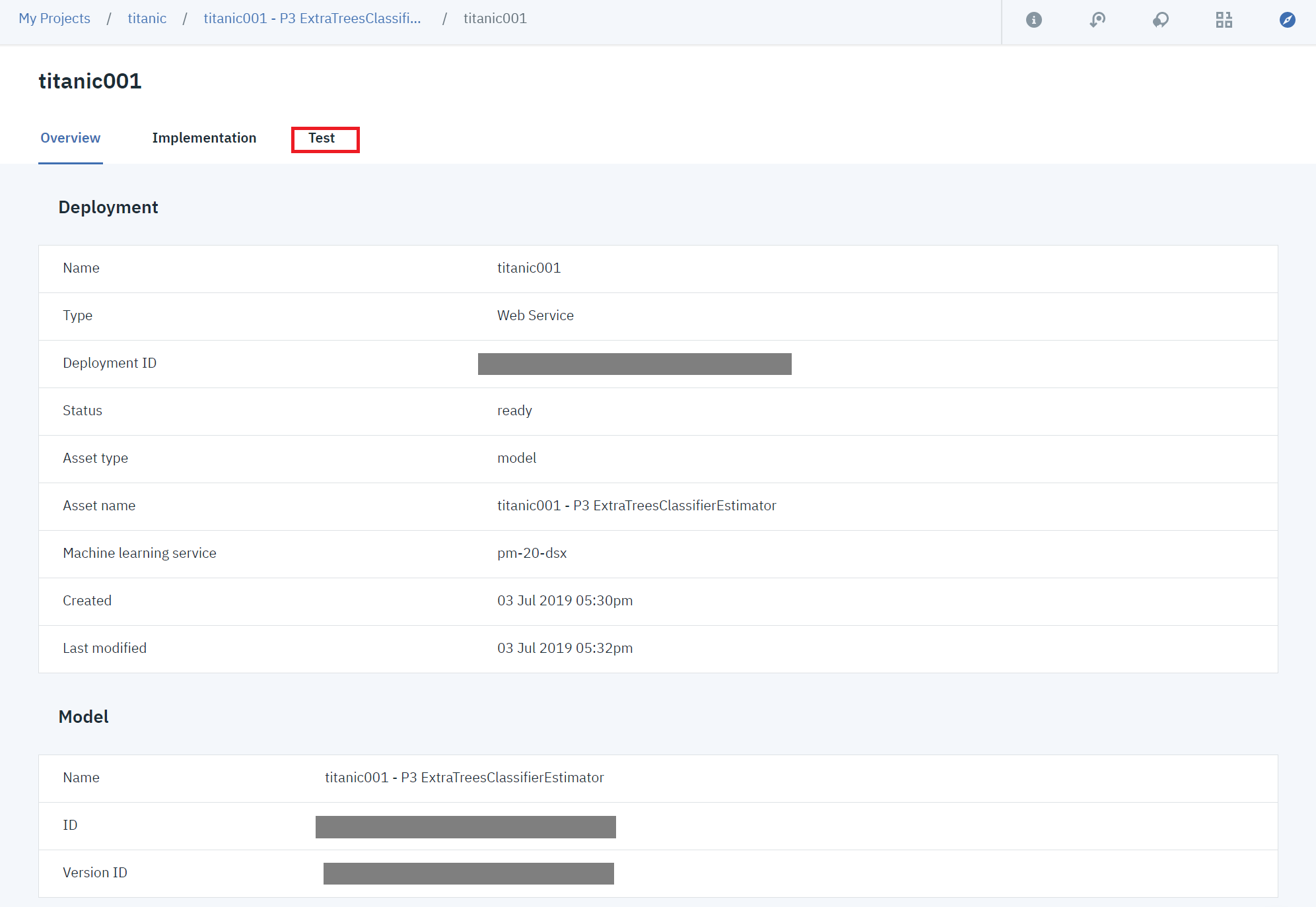
②入力欄に以下のjason(test.csvの1レコード目)を入力して、「Predict」をクリックすると、右側に結果が表示されました![]()
{"input_data":[{
"fields": ["PassengerId","Pclass","Name","Sex","Age","SibSp","Parch","Ticket","Fare","Cabin","Embarked"],
"values": [[892,3,"Kelly, Mr. James","male",34.5,0,0,330911,7.8292,null,"Q"]]
}]}
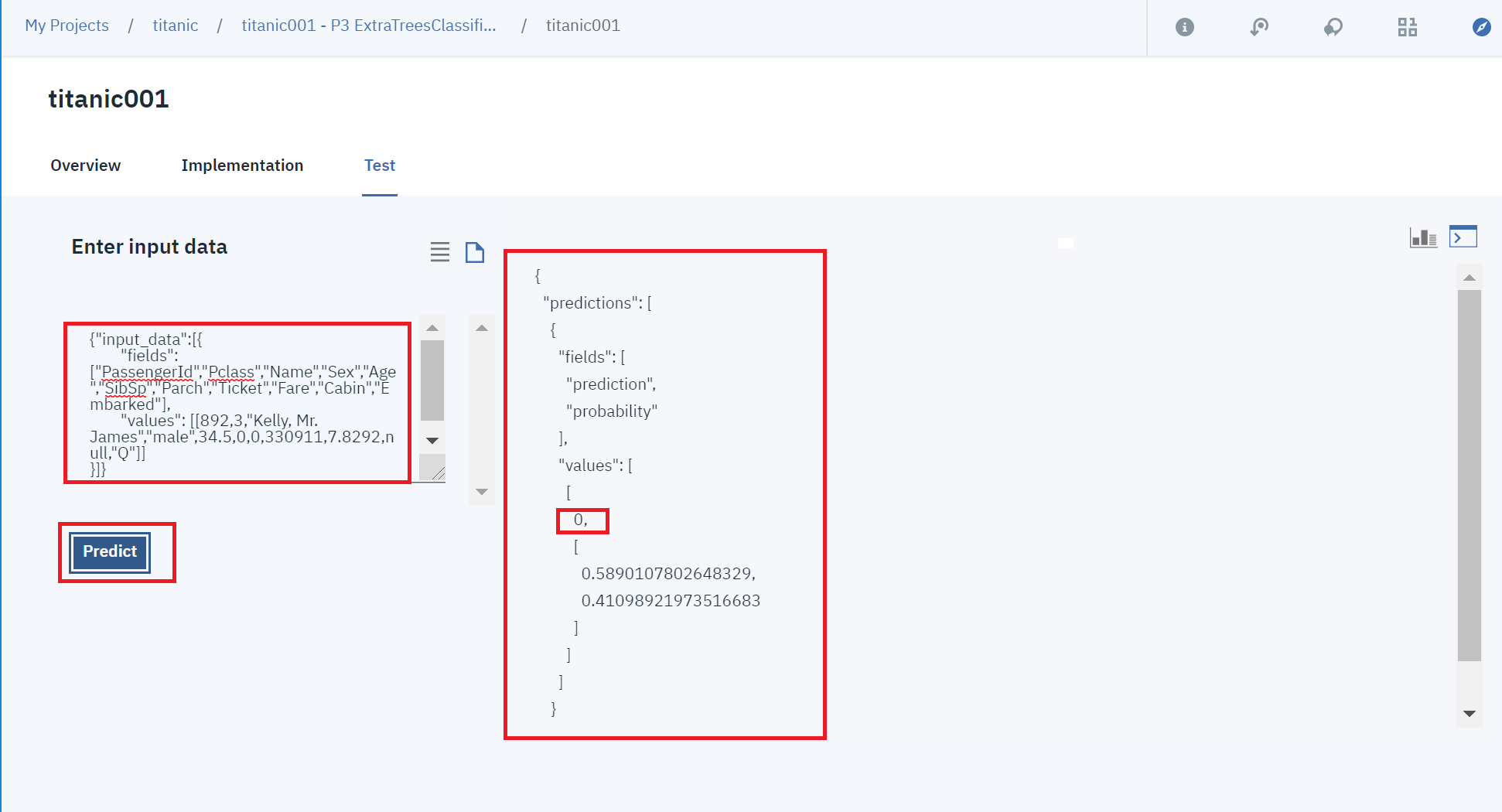
結果は「0」です。正解が分からないのであっているかわかりません💦(意味なし!)
prediction(予測値)=0.589、probability(確信度)=0.411でした。
でも、やりたいのはこれじゃないんですよ。まとまった評価結果が見たいのですよ。どうしたらいいんだ???
(3)一括で予測を実行する(Python)
パラメータの確認
①「Implementation」のタブを選択して、Code Snippetsで「Python」を選択すると、呼び出し方が出てきました!なるほど、Pythonで自分で書けってことか!!!
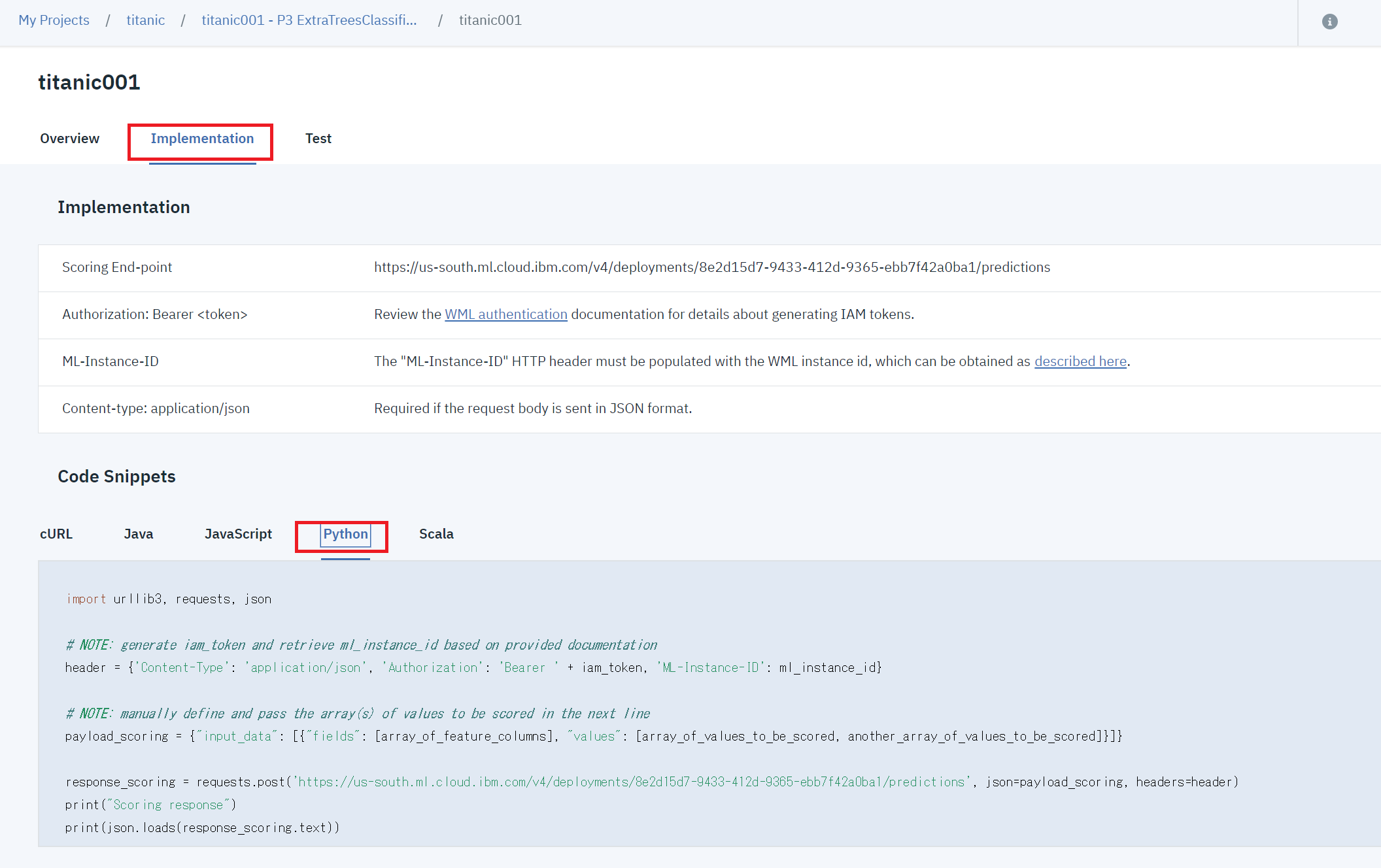
②これを見ても、Authorization: Bearer とか、ML-Instance-IDとかよくわからなない。ここまで**「マニュアルを一切読まない!!」**というポリシーを通してきましたが、あきらめて読むことにしました。
Watson Machine Learning authentication
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/ml-authentication.html
③上記ドキュメントによると以下の5項目を使う必要があるようです。どこにあるんじゃ!
apikey : 123456789
instance_id : ABCDEFG
url : https://HIJKL
username : MNOPQRS
password : TUVWXYZ
④いろいろ探した結果見つかりました。IBMCloudのリソースリストから、「Machine Learning」のサービスをクリックします。
⑤表示された画面の「サービス資格情報」をクリックし、「資格情報の表示」をするとでてきました!5項目とも見つかりました!!!
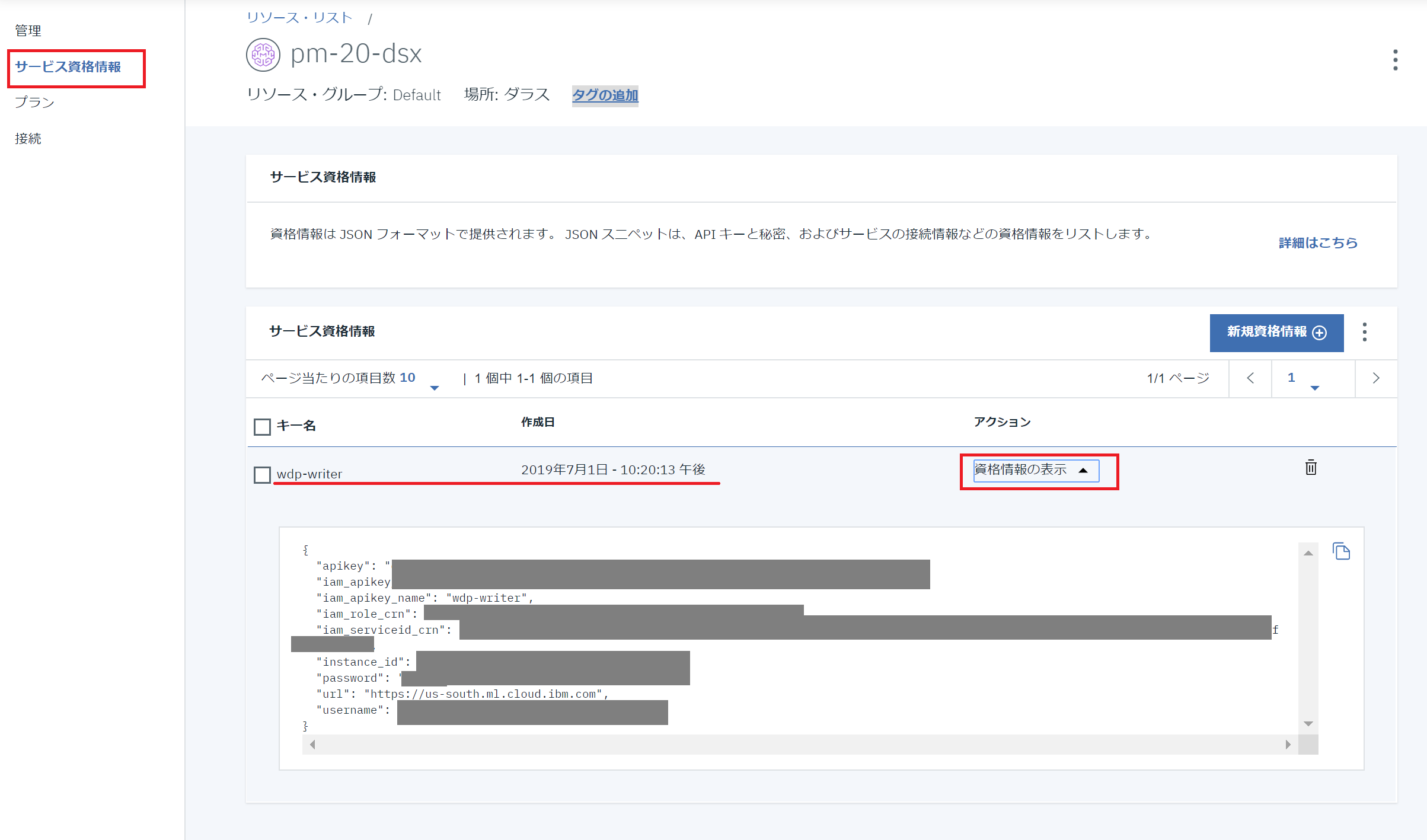
実行
以下のドキュメントを参考に進めていきます。
認証関連
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/ml-authentication.html
デプロイ
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/ml-deploy_new.html?audience=wdp
以下のコードで実行しました。ローカルのJupyterの環境を使っている関係で、細かく区切られていて見づらくなってしまいました。すみません。
import requests
import pandas as pd
import urllib3, requests, json
# IM_tokenの取得
apikey = "XXX" #先ほど調べた値
url = "https://iam.bluemix.net/oidc/token"
headers = { "Content-Type" : "application/x-www-form-urlencoded" }
data = "apikey=" + apikey + "&grant_type=urn:ibm:params:oauth:grant-type:apikey"
IBM_cloud_IAM_uid = "bx"
IBM_cloud_IAM_pwd = "bx"
response = requests.post( url, headers=headers, data=data, auth=( IBM_cloud_IAM_uid, IBM_cloud_IAM_pwd ) )
iam_token = response.json()["access_token"]
# ml_instance_idの設定
ml_instance_id="XXX" #先ほど調べた値
# headerの作成
header = {'Content-Type': 'application/json', 'Authorization': 'Bearer ' + iam_token, 'ML-Instance-ID': ml_instance_id}
# test.csvの読み込み
df_test = pd.read_csv('test.csv')
df_test.head()
# null値をNoneに変換
df_test = df_test.where((pd.notnull(df_test)), None)
df_test.head()
# jsonに設定するカラム名と値をそれぞれリストで取得
array_of_feature_columns = df_test.columns.tolist()
array_of_values = df_test.values.tolist()
# payload変数の組立
payload_scoring = {"input_data": [{
"fields": array_of_feature_columns,
"values": array_of_values
}]}
# 予測の実行(scoring_end_point はImplementationに書いてあった値)
scoring_end_point = "https://us-south.ml.cloud.ibm.com/v4/deployments/xxx/predictions"
response_scoring = requests.post(scoring_end_point, json=payload_scoring, headers=header)
# 結果の取得
response_scoring = json.loads(response_scoring.text)
df_result = pd.DataFrame(response_scoring["predictions"][0]["values"],columns = ["Survived","hoge"])[["Survived"]]
# PassengerId,Survivedのデータフレームを作成(出力用)
df_result['PassengerId'] = df_test["PassengerId"]
df_result=df_result[df_result.columns[::-1]]
# 出力
df_result.to_csv("submission.csv",index=False)
4.KaggleへのSubmit
では、出力されたsubmission.csvをKaggleにSubmitしてみます。
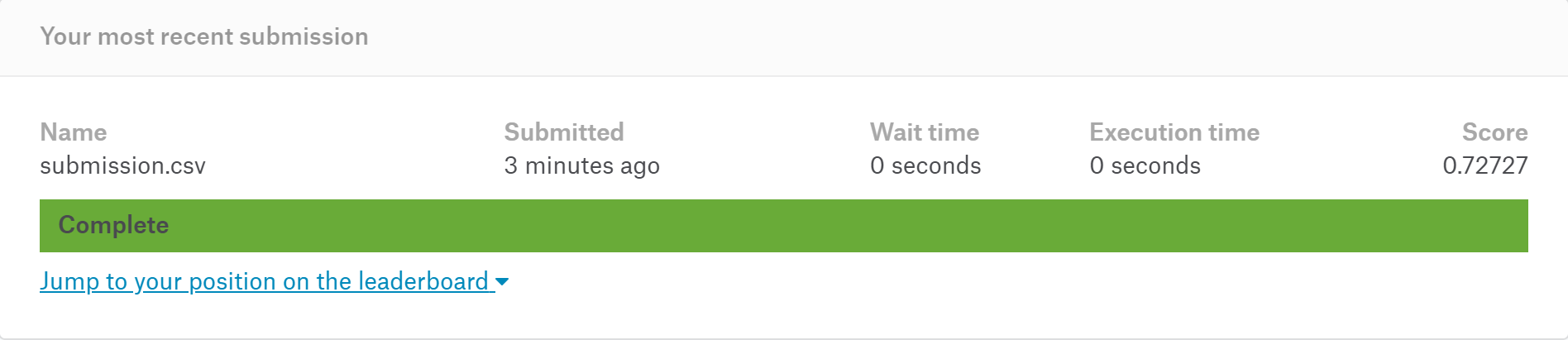
結果は、以下の通り。スコア0.72727。うん、いまいちですね💦まあ、変数全投入していますし、こんなものでしょうか。
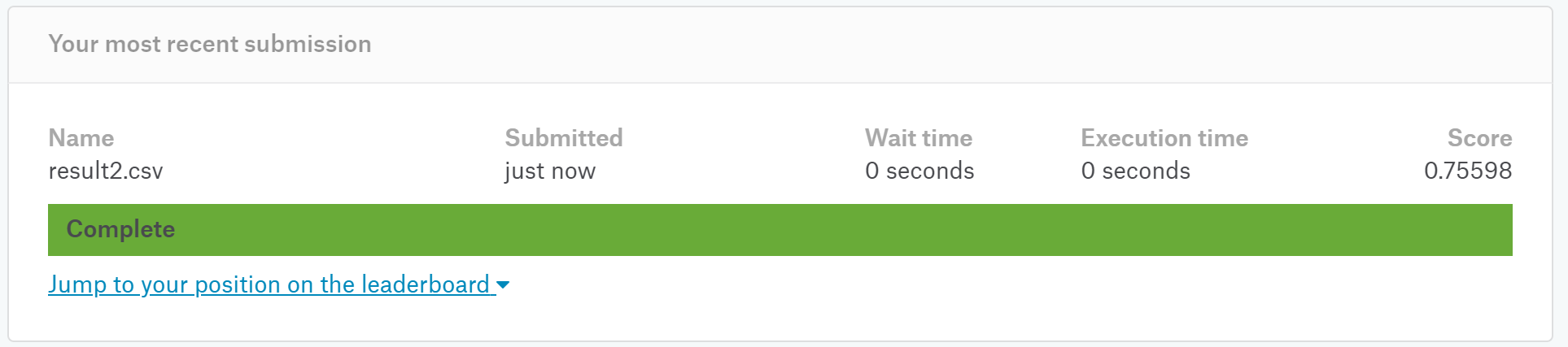
ちなみに、PredictionOneの結果は、スコアが0.75598になりました。
5.感想と考察
(1)感想
精度は・・・いまいちでしたね💦💦
念の為お断りをしておきますと、今回は、何の前処理も変数選択もなしに、そのままデータを突っ込んだのでこのような結果になっています。決してAutoAIの精度が悪いわけではなく、本来の使い方としては、PassengerIDやNameのようなユニーク値は除去するなど、最低限の前処理をしてから実行するものだと思います。
これからは**「ハイパーパラメーターのチューニングはAutoMLにお任せして、人間はデータ収集や前処理を頑張る」**という時代になるのかな~と思いました。
(2)変数選択について
後で確認したところ、PredictionOneは自動的にPassengerId,Name,Ticketを除外して処理していました。なかなかやりますね!!
(3)PredictionOneと同じ変数でのAutoAIのスコア
AutoAIにおいても手動でPassengerId,Name,Ticketの3項目を除去して学習すると、Kaggleのスコアは0.77511になりました。
| ツール | 変数 | モデル | Kaggleスコア |
|---|---|---|---|
| AutoAI | 手動で3変数削除 | XGBClassifier | 0.77511 |
| PredictionOne | 自動で3変数削除 | 2値分類 | 0.75598 |
| AutoAI | 全変数 | ExtraTreesClassifier | 0.72727 |
(4)AutoAIの特性
AutoAIは、データサイエンティストをハイパーパラメータのチューニング作業から解放する可能性があるツールだと思いました。このツールを使うことで、どのようなデータを集めるべきかとか、どのような前処理をするかといった部分を検討することに注力できるようになるのではないかと思います。IBMCloud上でサービスとしてデプロイできるのがとても便利で、より効率的にモデルの構築からサービス化までをつなげることができるようになる便利なツールです。
(5)PredictioOneの特性
PredictioOneは一切コードを書かなくても一連の手順がこなせてしまうところがすごいです。ITの専門ではない事業部門の方が「機械学習したらどうなるのかな?」と思ったときに、さくっと使ってみるのにとてもいいツールだと思いました。このツールで事業部門の方が試行錯誤し、事業としての方向性が見えてきたら、データサイエンティストやITの専門家に委託するという流れが作れるのではないかと思います。
6.関連記事
SONYのAutoMLサービス「PredictionOne」を使ってみた
https://qiita.com/paco_itengineer/items/7b6f1c62ae7263ac1a43
WatsonStudioの「AutoAI」を使ってみた(学習編)
https://qiita.com/paco_itengineer/items/910b7ee4b6373ff21e4e
WatsonStudioの「AutoAI 」を使ってみた(評価編)
https://qiita.com/paco_itengineer/items/ca1f97f17bb91ac351eb
GoogleCloudPlatformの「AutoMLTable」を使ってみた
https://qiita.com/paco_itengineer/items/4cf064d272f007fcae57