
要は(TL;DR;)
- 2019/5/31からWatson Studioに機械学習を自動化する「AutoAI」が搭載されました
- 「AutoAI」はその名前の通り、数値や文字列などの構造化データ(CSV)を入力にして、判定(分類)と数値予測(回帰)のモデルを数クリックで簡単に作れるツールです
- Watson Studioの一機能としてのリリースなので、追加のお金はかかりませんし、無償のライトアカウントでもお試しできます
- (
 要はぶっちゃけ、Data RobotやH2O Driverless AIみたいなもんですわ.. )
要はぶっちゃけ、Data RobotやH2O Driverless AIみたいなもんですわ.. ) - Watson Studioにはディープラーニングの画像分類などをカンタンに自動化するNeuNets1も付いてますよ!
はじめに
こんにちわ、石田です!今日は2019/05/31からWatson Studioで一般利用可能(GA)になった「AutoAI」をご紹介させてください。「AutoAI」を使えば専門家でなくても数クリックで精度の高いAIモデルを簡単に作れますし、モデルの本番環境(WML)へのデプロイも超簡単です!
![]() What's new - May 31, 2019
What's new - May 31, 2019
![]() AutoAI Overview
AutoAI Overview
![]() 約3分半のご紹介ビデオ@YouTube
約3分半のご紹介ビデオ@YouTube
どんな感じ? ざっくりと操作をご紹介
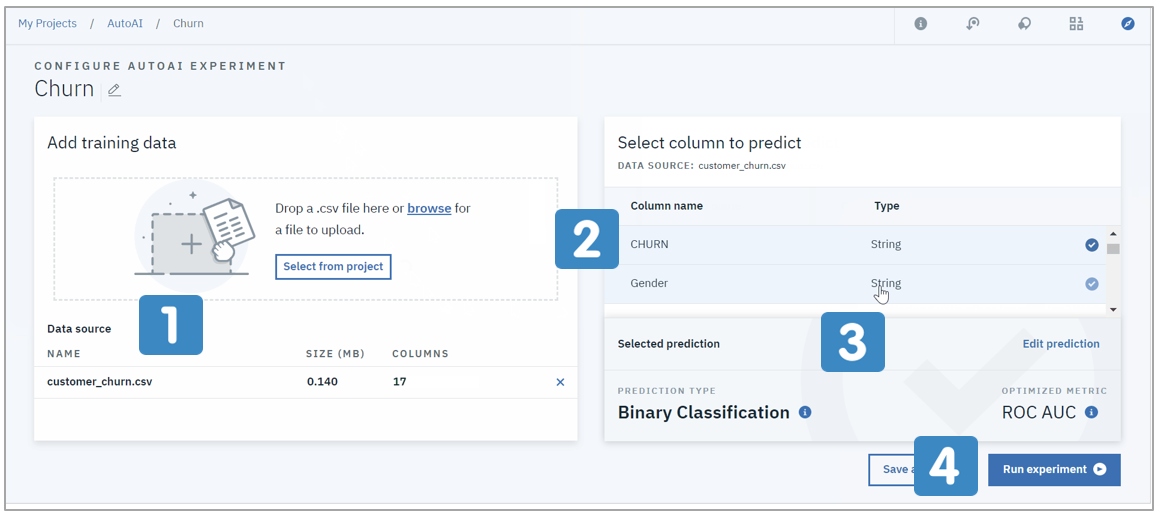
図1. 入力ファイルと予測フィールドの指定
![]() 入力にするCSVファイルを指定します
入力にするCSVファイルを指定します
![]() 予測したいフィールド(ターゲット)を選びます
予測したいフィールド(ターゲット)を選びます
![]() ターゲットの特性により、自動的に手法と評価指標が選択されます(変更できます)
ターゲットの特性により、自動的に手法と評価指標が選択されます(変更できます)
![]() あとは実行するだけ!自動的にトレーニングが起動します。簡単すぎますよね?
あとは実行するだけ!自動的にトレーニングが起動します。簡単すぎますよね?
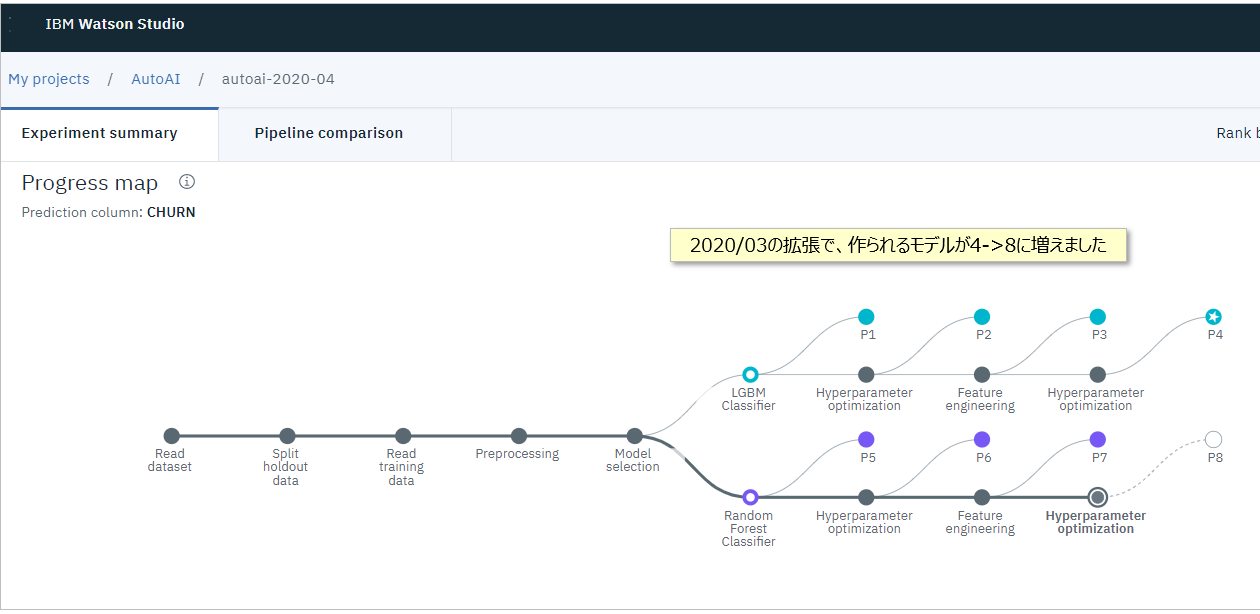
図2. モデル作成中のパネル例
モデル作成では以下のような一連の項目を自動処理しています。(蛇足ですがこの一連の流れを一般的に**機械学習パイプライン(ML Pipeline)**と呼びます)
- 入力データセットの分割(今はTraining:HoldOut=90:10で固定)
- トレーニング・データの読み込み
- データの前処理(欠損値の補完、外れ値の除去など)
- 最適なモデリング手法( estimator ) の選定(分類=30種 回帰=44種より)
- ハイパーパラメーターの最適化( HPO )
- 特徴量の加工(Feature Engeneering)
- アンサンブル(モデルのいいとこ取り)
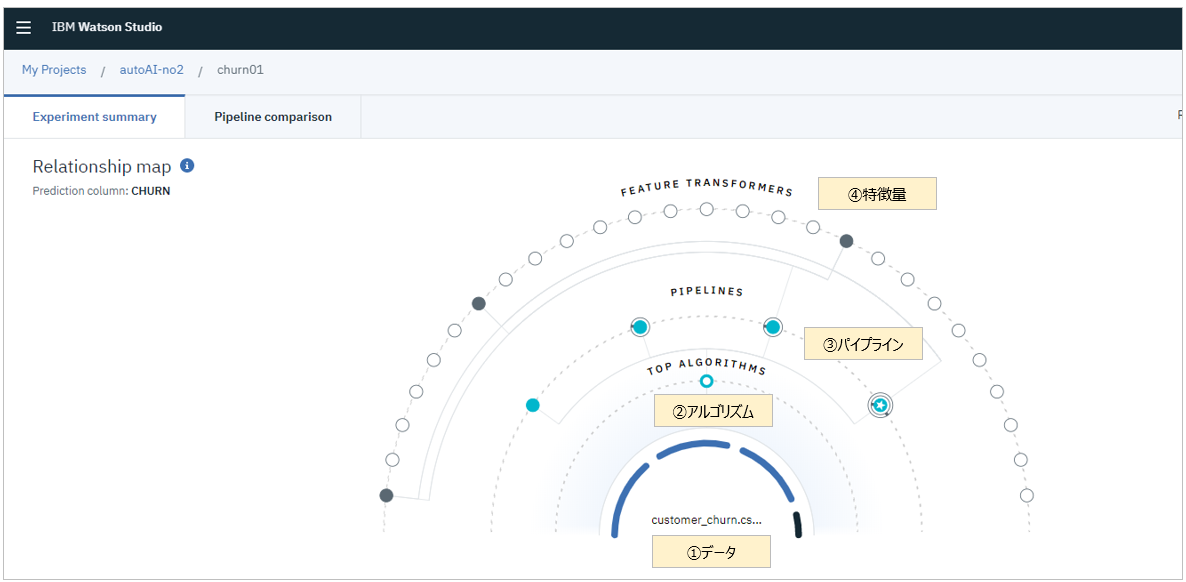
図3. Relationship Mapの例
![]() ( 2019/12追記) Relationship Mapでは以下のような情報をビジュアルに示してくれますので、ともすると「ブラックボックス」になりがちなこの類のツールで、中身の確認や理解促進に有効です。
( 2019/12追記) Relationship Mapでは以下のような情報をビジュアルに示してくれますので、ともすると「ブラックボックス」になりがちなこの類のツールで、中身の確認や理解促進に有効です。
- データをどのように分割したか(基本3分割での交差検証+ホールドアウト)
- どのアルゴリズムを選んだか(少量データにて簡易評価)
- そのアルゴリズムでどのようなパイプラインを試みたか(基本は4パターン)
- 各パイプラインでどのような特徴量生成が有効だったか
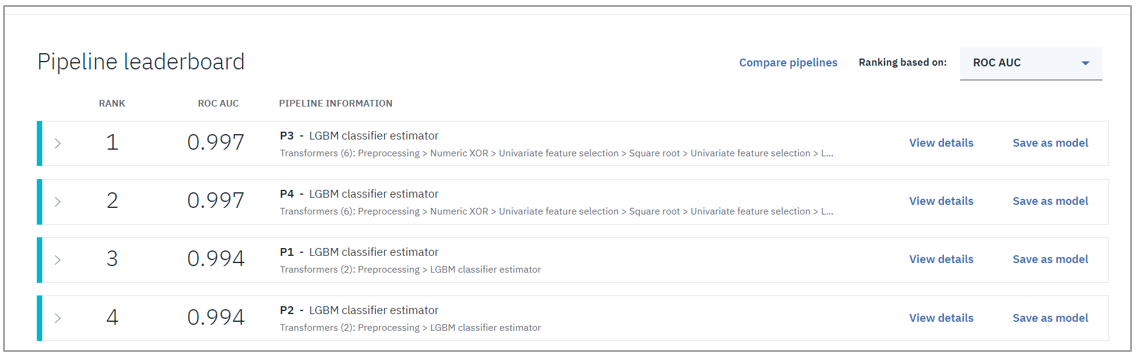
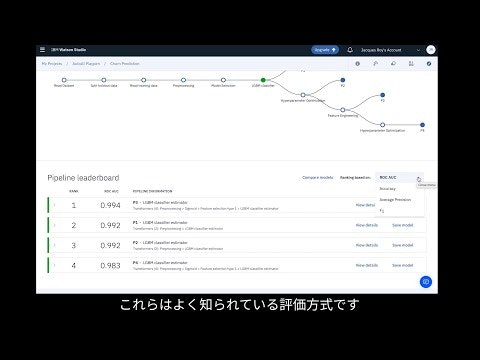
図4. モデル完成時の出力パネル例
トレーニングが完了すると、複数のパイプラインの評価結果を成績の良い順に提示してくれます。
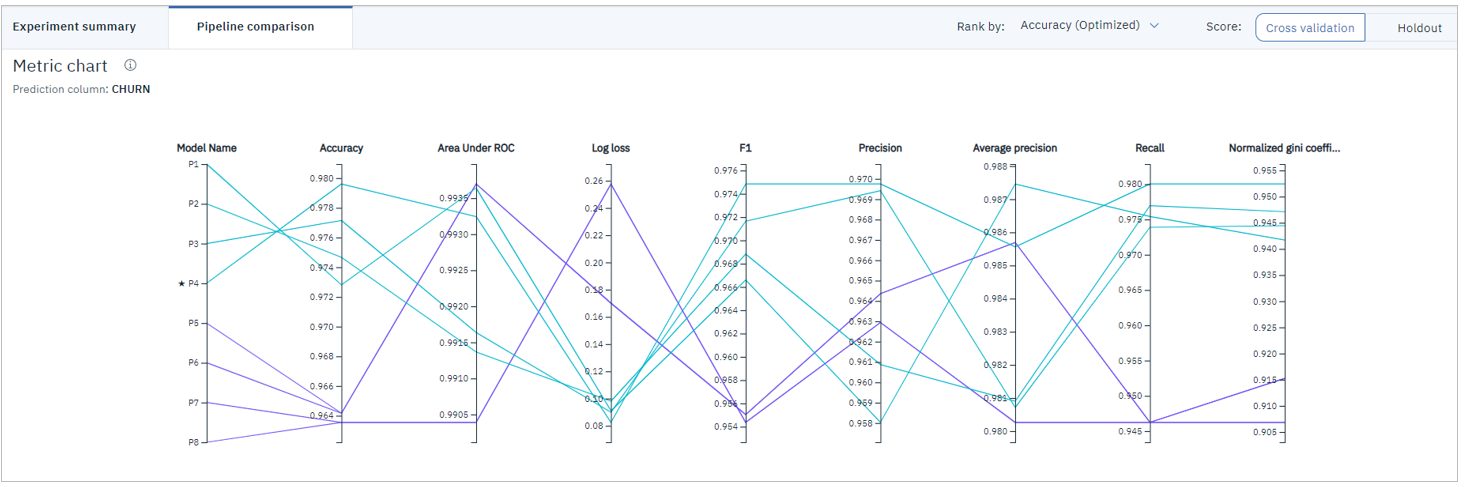
図5. Pipeline Comparisonの例
![]() ( 2019/12追記) 上記のようなPipeline Comparisonも提供されるようになりました。
( 2019/12追記) 上記のようなPipeline Comparisonも提供されるようになりました。
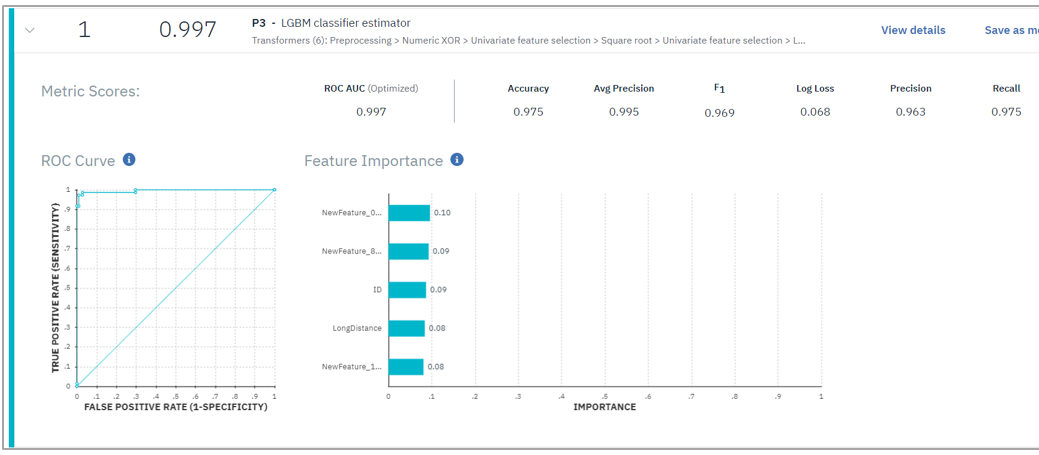
図6. モデルの評価指標の可視化例
それぞれのモデルの評価の明細メタデータもみられますのでデータサイエンティストの方も満足!
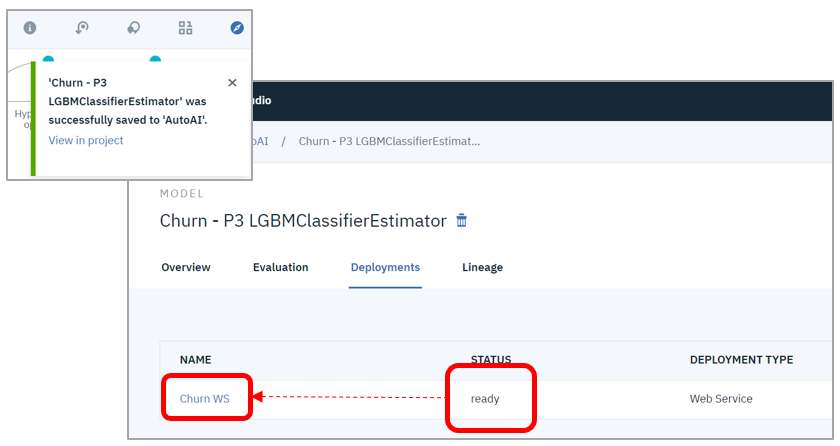
図7. モデルの保管とデプロイ
パネルのUIから簡単にモデルの保管とWML環境(実行ランタイム)へのデプロイができます。あとはREST APIとして任意のクライアントから呼び出すだけ!
「やってみた」記事は長くなったのでこちらに置きました。
機能
![]() (2019-07/22) 英語
(2019-07/22) 英語![]() かつディープな内容ですが、研究所主催のWebinarでAutoAIのFeatute Engineeringの詳細テクニックが説明されていました。参加登録すればどなたでも視聴できるようなので、ご興味ある方はどうぞ。2
かつディープな内容ですが、研究所主催のWebinarでAutoAIのFeatute Engineeringの詳細テクニックが説明されていました。参加登録すればどなたでも視聴できるようなので、ご興味ある方はどうぞ。2
![]() Deep dive on automating feature engineering
Deep dive on automating feature engineering
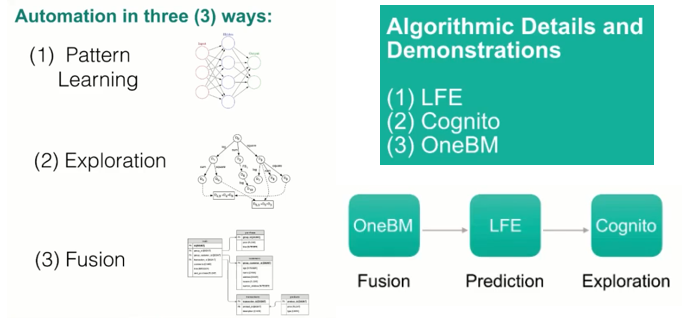
入力
- 現時点ではCSVファイル一択です。データベースは入力にできません
- CSVファイルの最大サイズは
100MB1GB3です - CSVなので、扱えるのは数値や文字などの構造化データのみです。画像やテキストなどの非構造化データを扱いたい場合はAutoAIではなくNeuNetsのほうをご検討ください
解決できる問題
以下の3つの問題に対応しています。いずれも正解データのある「教師あり学習(Supervised Learning)」です。「クラスタリング」などの「教師なし学習(Unsupervised Learning)」は対応していません。
| 問題 | ターゲットの例 | 代表的な評価指標 |
|---|---|---|
| 二値分類( Binary Classification ) | 0/1, Y/N, True/False | ROC AUC |
| 多クラス分類( Multi-Class Classification ) | A/B/C, BRONZE/SILVER/GOLD | Accuracy |
| 回帰(Regression) | 数値(期待売上,身長,予想価格) | RMSE(Root Mean Squered Error) |
(2020/05/26) 更新↓
最新の詳細情報はドキュメント ![]() AutoAI implementation detailsをご参照ください。
AutoAI implementation detailsをご参照ください。
「分類」は下記のアルゴリズムから最適なものを選びます。
- Decision Tree Classifier
- Extra Trees Classifier
- Gradient Boosted Tree Classifier
- LGBM Classifier
- Logistic Regression
- Random Forest Classifier
- XGBoost Classifier
「回帰」は下記のアルゴリズムから最適なものを選びます。
- Decision Tree Regression
- Extra Trees Regression
- Gradient Boosting Regression
- LGBM Regression
- Linear Regression
- Random Forest Regression
- Ridge
- XGBoost Regression
(↑更新ここまで)
ランタイム
使う側からはまったく意識しませんが、内部的なランタイムはPython - scikit-learnらしく、この上にいろいろな自動化/最適化のテクニックを積み上げているらしいです。
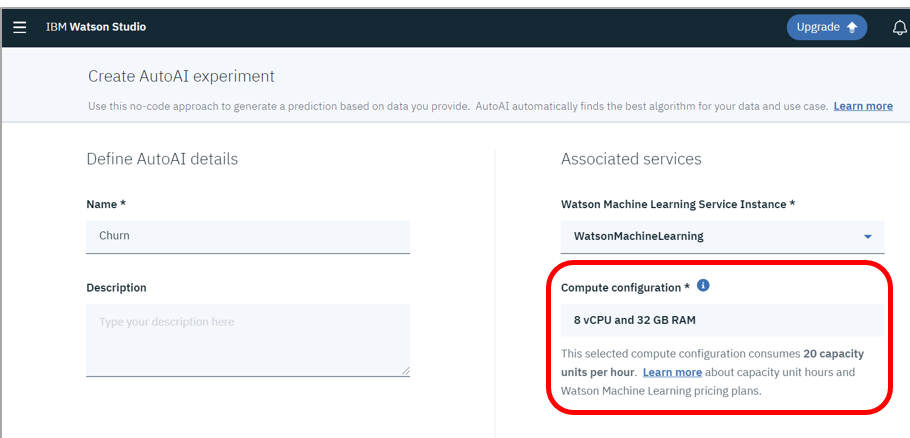
- (あくまで2019/5/31時点では)実行環境は「8 vCPUs and 32 GB RAM」で固定です。先々は他の機能同様に選べるようになるのでしょう。
-
 パネルにも記載ありますが、この構成は20CUH/Hourを消費します。他の機能での同等構成の消費量(4CUH/Hour)より多いので、ご注意ください。
パネルにも記載ありますが、この構成は20CUH/Hourを消費します。他の機能での同等構成の消費量(4CUH/Hour)より多いので、ご注意ください。
Model Builderとの違い
![]() (2019/08/06) What's Newによると 2019/08/02付で、従来からご提供してきた簡単AIモデル作成機能の**Model Builderは無くなりました。今後はAutoAIをご利用ください。
(2019/08/06) What's Newによると 2019/08/02付で、従来からご提供してきた簡単AIモデル作成機能の**Model Builderは無くなりました。今後はAutoAIをご利用ください。
Week ending 02 August 2019
Retirement of Watson Machine Learning Model Builder
Watson Machine Learning Model Builder is no longer available for training machine learning models. Models trained with Model Builder and deployed to Watson Machine Learning will continue to be supported, but no new models can be trained using Model Builder. Instead, use AutoAI for training classification and regression models. Read about the announcement, or learn more about AutoAI.
以前からWatson Studioには似たような機能としてSparkMLベースの「Model Builder」があります。こちらもウイザード形式で超簡単にモデルを作れます。

「専門家不要/自動化」の「効用」だけ見ると同じ、なのですがAutoAIの方が後発な分、機能も多いし深いです。今は並存している過渡期ですが、今後はAutoAIをご利用ください。いちおうModel Builderと比べた時のAutoAIの利点は下記かと思います。
候補となるモデル数が多い自動データ準備(ADP)も、より洗練されている(ハイパーパラメータ最適化など)より洗練された方法でモデルを構築様々な改善により、一般にModel Builderより精度の高いモデルが作れるConfision Matrix始めモデルの評価結果の情報が可視化されており充実している
あと現時点ではModel Builderではバッチ処理もサポートしていますがAutoAIでは未サポートです。
NeuNetSとの違い & (2019/12追記) 両者は2020年にマージされます
冒頭で書いてしまいましたが、要は構造化データはAutoAI, 非構造化データはNeuNetSです。いずれもWatson Studioの機能であり追加料金なしでご利用いただけますし、ライトアカウントでも試せます。構造化データ・非構造化データの両方に対し「機械学習の自動化」の恩恵を低価格(約1万円/月・人)でご提供できているのは、Watson Studioのいいところだと思います。
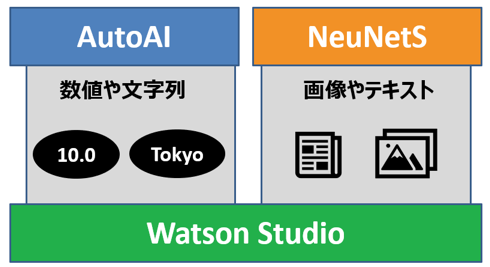
NeuNetSについては以下のQiita記事などご参照ください。
![]() イメージと正解ラベルだけで高精度の画像認識DLモデル作成 - Watsonの最新機能NeuNetSのご紹介
イメージと正解ラベルだけで高精度の画像認識DLモデル作成 - Watsonの最新機能NeuNetSのご紹介
![]() NeuNetSでニューラルネットワークモデルを自動生成してみた
NeuNetSでニューラルネットワークモデルを自動生成してみた
![]() (2019/12月追記) ブログ記事「NeuNetS Merging into AutoAI in Watson Studio」によりますと、2020年にNeuNetsはAutoAIとマージされ一つの機能になるそうです。記事によるとニューラル・ネットワークを用いてテーブル形式のデータ予測や時系列分析、テキストマイニング、イメージ認識などユースケースが拡がるらしいのでお楽しみに!(ベータ募集も書いてありました)
(2019/12月追記) ブログ記事「NeuNetS Merging into AutoAI in Watson Studio」によりますと、2020年にNeuNetsはAutoAIとマージされ一つの機能になるそうです。記事によるとニューラル・ネットワークを用いてテーブル形式のデータ予測や時系列分析、テキストマイニング、イメージ認識などユースケースが拡がるらしいのでお楽しみに!(ベータ募集も書いてありました)
Merging NeuNetS into AutoAI allows for the automation and enhancement of a new suite of neural network models, and it addresses much broader data science use cases, including tabular data prediction and classification, time-series forecasting, text mining, and image recognition.
 (2019/12追記) Pythonノートブックへの保存(beta)
(2019/12追記) Pythonノートブックへの保存(beta)
2019/12月時点では絶賛クローズ・ベータ中ですが、AutoAIで生成したパイプラインをJupyter Notebookに保存できるようになりました。これによりデータサイエンティストの方はブラックボックスになりがちなAutoAIの中の動きをより深く理解できますし、カスタマイズや処理のバッチ化なども実現できるようになります。
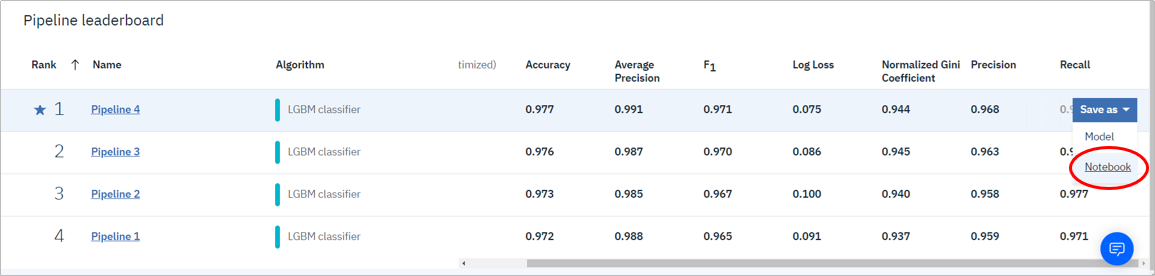
上記のようにパイプラインを選んで右クリックーSave asで簡単にNotebookに処理内容をエクスポートできます。
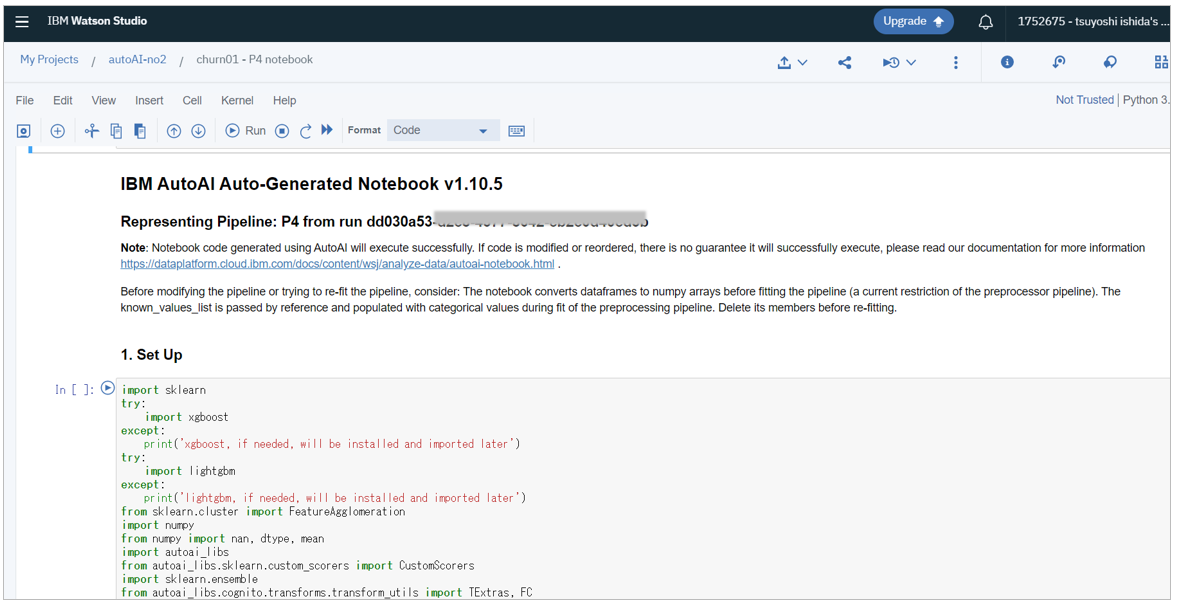
基本的にNotebookはWatson Studio上のJupyter Notebookになりますので、このまま実行も可能です。
![]() Saving an AutoAI generated notebook
Saving an AutoAI generated notebook
[おまけ] 著名データセットで実際にやってみた
小規模なものですが、機械学習でよく出てくる著名データセットにAutoAIを適用してみました。以下が結果ですが、なんもしないのに結構いい線行ってるのがおわかりいただけるかと思います。(使ったファイルはGithubに置いておきますのでご自由にどうぞ~)
ちなみに評価結果の見方は下記になります。
- 2クラス分類=ROC AUCは1に近いほど性能良い
- 複数クラス分類=Accuracyも1に近いほど性能良い
- 回帰=RMSEは0に近いほど性能が良い(&異なるデータ間での比較は無意味)
| # | データの種類 | CSV | 大元 | 行数 | カラム数 | 方式 | 指標 | 実行時間 | 評価結果 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 乳がんデータ | Cancer | sklearn | 569 | 30 | 2クラス分類 | ROC AUC | 2min | 0.992 |
| 2 | ボストン市の住宅価格データ | House | sklearn | 506 | 14 | 回帰 | RMSE | 2min | 2.991 |
| 3 | アヤメの品種データ | Iris | sklearn | 150 | 4 | 複数クラス分類 | Accuracy | 85s | 0.978 |
| 4 | タイタニックの生存者データ | Titanic | kaggle | 891 | 12 | 2クラス分類 | ROC AUC | 115s | 0.86 |
| 5 | ワインの品質データ | Wine | sklearn | 178 | 13 | 複数クラス分類 | Accuracy | 2min | 0.975 |
| 6 | ローン審査のデータ | Credit | SPSS Modeler | 2465 | 6 | 2クラス分類 | ROC AUC | 6min | 0.89 |
| 7 | 顧客離反のデータ | Churn | IBM | 1799 | 19 | 2クラス分類 | ROC AUC | 6min | 0.997 |
最後に
ってことで、専門家でなくても超簡単にモデルが作れてしまうので、皆様もぜひお試しください!なお「やってみた」記事はこちらです。
以上です。
 改定履歴
改定履歴
当記事は今後も気付きがあったら追加しようと思うので改定履歴をつけます。初版から記述を追加/変更した箇所には![]() マークを付けておきますね。
マークを付けておきますね。
| 版 | 日付 | 変更内容 |
|---|---|---|
| 1.0 | 2019-06-05 | 初版公開 |
| 1.1 | 2019-07-22 | AutoAIのWebinarの紹介を追加 |
| 1.2 | 2019-08-06 | Model Builderが無くなった点を追記 |
| 1.3 | 2019-12-02 | Relationship MapやNotebook Exportを追記 |
| 1.4 | 2020-04-09 | CSVデータの最大が100MB->1GBに拡張された点を追記 |
| 1.5 | 2020-05-26 | ドキュメント上、Watson Studioが内部的に使う手法の記述が変わってたので最新を反映 |