2019/11/20追記
NeuNetSは今後別のサービスであるAutoAIに統合するため、2019/12/6をもって段階的に廃止となるようです。今回のNeuNetSベータ版提供で蓄積した知見をAutoAIに反映させるとのことで、来年以降のAutoAIの発展が楽しみです。
詳細は下記をご参照ください。
はじめに
NeuNetS(ニューネッツ)は、IBM Cloud上で提供されるツールでトレーニング用データセットをアップロードすると高精度のディープニューラルネットワークモデルを自動生成してくれます。
2019年4月末現在では、テキスト認識、画像認識用のモデル生成をサポートしています。
NeuNetS提供の背景として、現状高いスキルを持つデータサイエンティストに対する需要が供給を大きく上回っていることから、ニューラルネットワークモデルの自動生成に対するニーズが高いといったことがあるようです。
- NeuNetS: Automating neural network model synthesis for broader adoption of AI
However, while only a small proportion of data scientists have the skills and experience needed to create a high-performance neural network from scratch, at the same time the demand far exceeds the supply.
NeuNetSについてさらに詳細を知りたい方は、@makaishi2さんが下記の記事で詳細を紹介されているのでこちらを参照されるとよいと思います。
- イメージと正解ラベルだけで高精度の画像認識DLモデル作成 - Watsonの最新機能NeuNetSのご紹介 -
私はまだディープラーニング初心者のため、今回MNISTの手書き数字の画像認識モデルを下記NeuNetSのドキュメントに従い生成してみました。
1. トレーニング用データセットの準備
NeuNetSでは画像認識の場合、トレーニング用データセットとして、以下のファイル名の2ファイルを準備します。
- train.zip ・・・ 画像認識対象の画像ファイル(png or jpg形式)をzipで圧縮したもの
- labels.csv ・・・ 上記zip内の画像ファイル名と正解ラベルのcsvデータ
私はMNISTの上記トレーニング用データを下記のコードで作成しました。
画像ファイルは、作成したimageフォルダを手動でzipで圧縮しました。
import os
from keras.datasets import mnist
from PIL import Image
# MNISTデータのロード
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 画像保存ディレクトリ作成
img_dir = 'image'
for i in range(10):
subdir = '%s/%s' % (img_dir, str(i))
os.makedirs(subdir, exist_ok=True)
# ラベル用CSVファイルの定義
csv_file_name = 'labels.csv'
# ラベル用CSVファイル & 画像ファイルの出力
with open(csv_file_name, mode='w') as f:
for i in range(len(x_train)):
# ラベルの定義
label = str(y_train[i])
# 画像ファイルの定義
img_file_name = '%s/%s/train-%s-%05d.png' % (img_dir, label, label, i)
# ラベル用CSVの保存
f.write('%s,%s\n' % (img_file_name, label))
# 画像ファイルの保存
img = Image.fromarray(x_train[i])
with open(img_file_name, mode='wb') as png_out:
img.save(png_out, format='png')
labels.csvの内容は以下の通りで、上記により作成されたトレーニング用データ数は60,000件になります。
image/5/train-5-00000.png,5
image/0/train-0-00001.png,0
image/4/train-4-00002.png,4
<以下省略>
2. Watson Studioプロジェクトの作成
NeuNetSを実行するため、Watson Studioプロジェクトを作成し、Cloud Object StorageとWatson Machine Learningサービスを追加します。
これらは、Liteプランを選択することで無料で作成できます。
作成手順は、@makaishi2さんが下記の記事で紹介されていますのでこちらをご参照ください。
- Watson Studioセットアップガイド(ライトアカウント可)
3. Cloud Object Storage上でトレーニング用データセットと自動生成したモデル保管先を設定
3.1 トレーニング用データセットのアップロード
Watson Stduioプロジェクトに関連付けられたCloud Object Storage設定画面に移動するため、Watson Studio画面左上のメニューから「Data Services」を選択します。

表示されたCloud Object Storageを選択します。

トレーニング用データセットのアップロード先のバケットをこのCloud Object Storage内に作成します。
「バケットの作成」をクリックし、バケット名に固有の名前を入力し作成します。
このとき、回復力には「Cross Region」、ロケーションには「us-geo」を指定します。
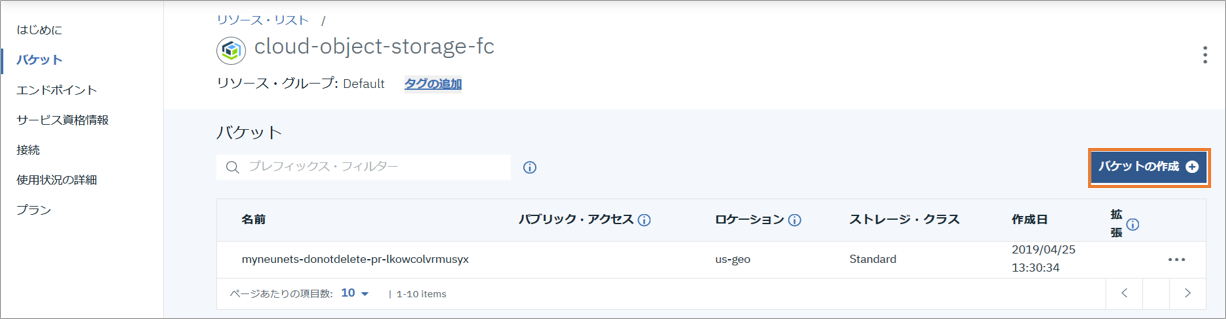

この作成したバケットをクリックし、トレーニング用データセットをアップロードします。

3.2 自動生成したモデル保管先の作成
自動生成したモデルの保管先のバケットを3.1と同様に作成します。

4. NeuNetSの実行
4.1 Watson OpenScaleインスタンスの追加
NueNetSは、Watson OpenScaleを前提としているため、Watson OpenScaleインスタンスを追加します。
IBM Cloudダッシュボード画面(Watson Stduioダッシュボードではなく)から「リソースの作成」をクリックし、「Watson OpenScale」を選択します。

ページ下部でライトプランを選択していることを確認し、「作成」をクリックします。

4.2 NeuNetSの設定
2で作成したWatson Studioプロジェクトを開き、「Add to project」をクリックし、NeuNetSを追加します。

次の画面で「Synthesized neural network」を選択します。

NeuNetSの設定画面で、3で作成したCloud Object Storage上のバケットを関連付けます。
まず、「Training data connection」にトレーニング用データセットのバケットを設定します。

「New connection」タブを選択し、Cloud Object Storageインスタンスとトレーニング用データセットのバケットを指定します。

同様に「Trained model connection」に自動生成したモデル保管先バケットを設定します。
ここでは「Existing connection」タブを選択し、先ほど作成したCloud Object StorageのConnectionとモデル保管先バケットを指定します。

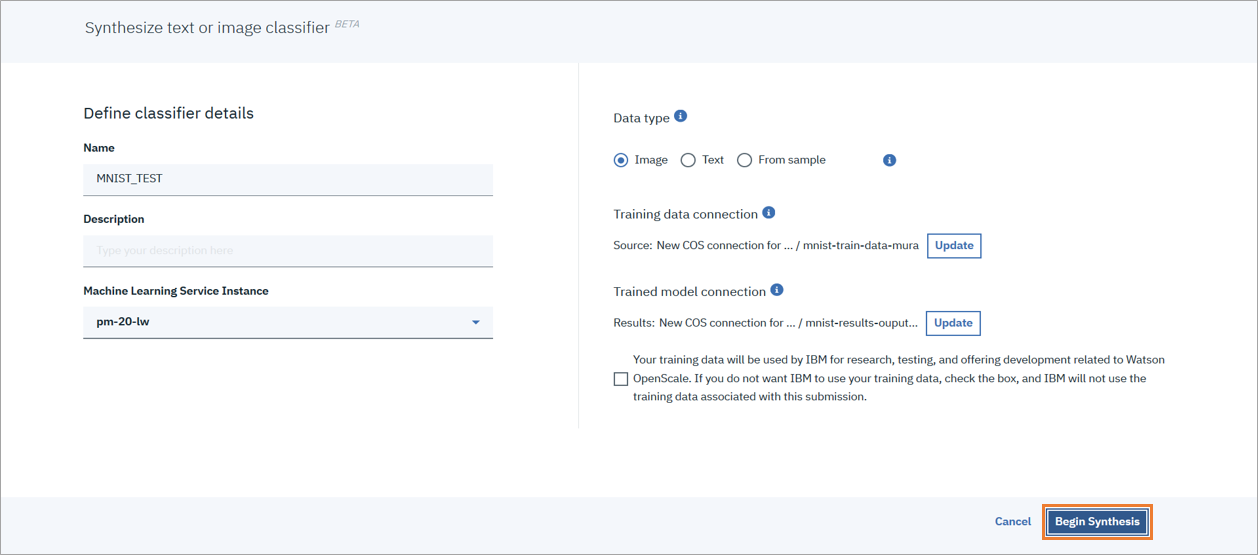
4.3 画像認識モデルの自動生成
「Begin Synthesis」をクリックし、トレーニング用データセットをもとに画像認識モデルの生成をおこないます。
モデル生成中は下記のような画面が表示され、モデル生成にはしばらく時間がかかるのでこのまま放置 or 画面を閉じても大丈夫です。
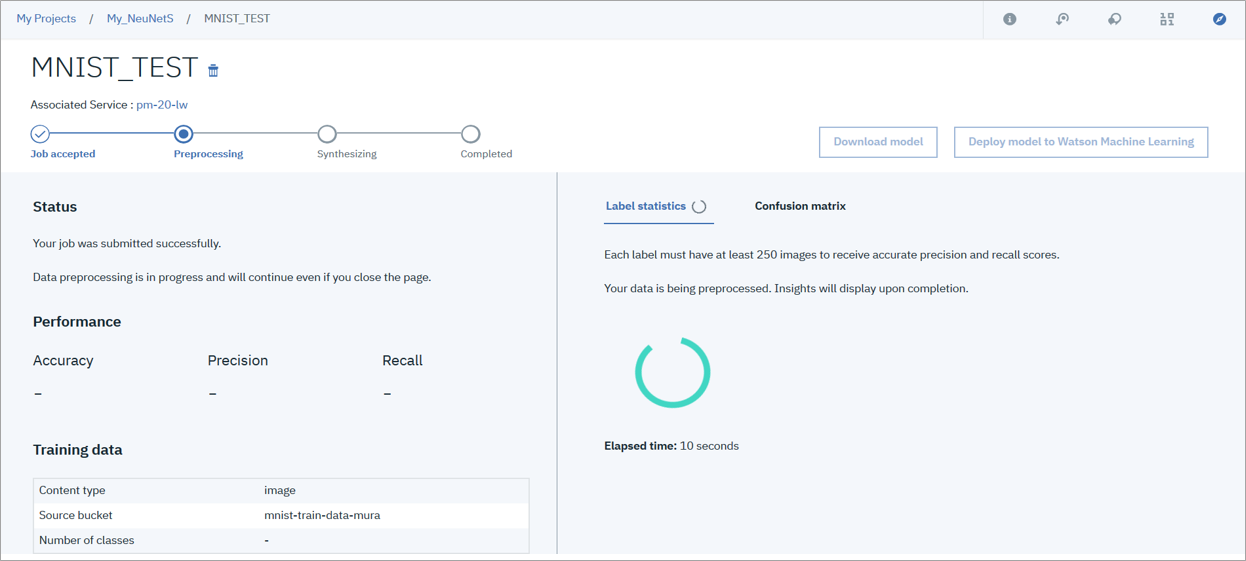
モデルの生成が完了すると下記の画面が表示されます。(だいたい2時間半ほどでこちらの画面が表示されました。)
今回準備したトレーニング用データセットは60,000件に対し、48,000件と表示されているので準備したデータの内80%を学習に利用するようです。
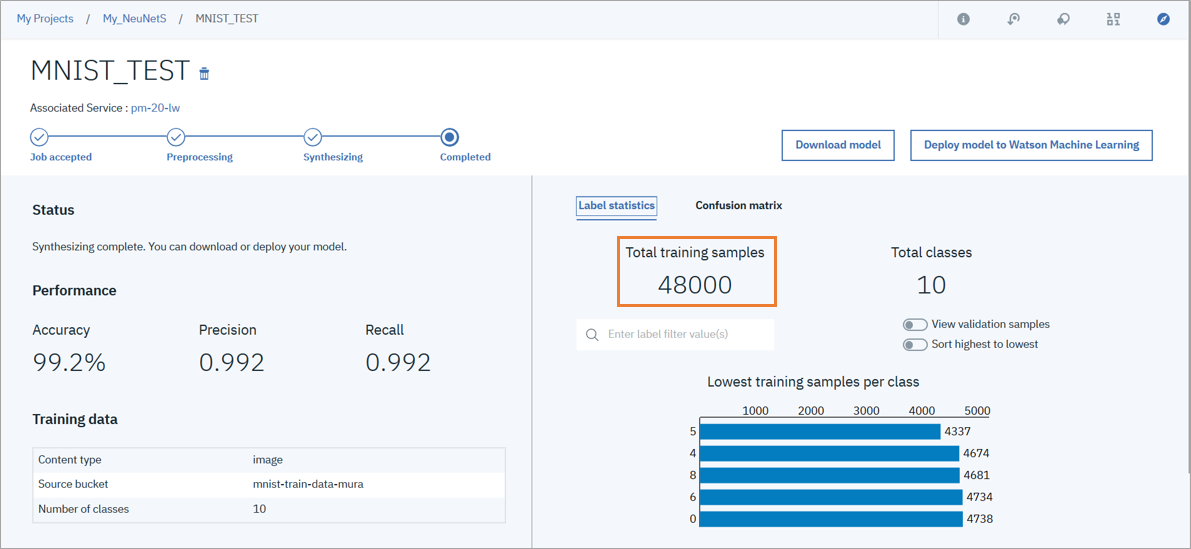
モデル検証結果としてConfusion Matrixも表示可能で、こちらのTotalを見ると12,000件とあるので準備したデータの内20%をモデル検証用に利用するようです。

5 自動生成したモデルの利用
今回自動生成した画像認識モデルをローカル環境で稼働させ、私の手書き数字の認識をおこなってみました。
ローカル環境で稼働させるためには、自動生成したモデルをダウンロードし、NeuNetSライブラリを使ってモデルを利用します。
5.1 NeuNetSライブラリのインストール
まず、Python用のNeuNetSライブラリをインストールします。
下記ドキュメントによると、GitHubから直接インストールできるようですが、私はpipから直接GitHubに接続できなかったため、一度git cloneでローカルにコピーし、ビルド、インストールをおこないました。
- Downloading and using NeuNetS models locally
NeuNetSライブラリのビルド、インストール時のコマンドは以下の通りです。
注意点として、NeuNetSライブラリは、TensorFlow 1.5が前提のようで2019年4月末時点ではPython 3.7.xではTensorFlow 1.5が利用できなかったため、今回Python 3.6.xを使用しています。
C:\GitHub\NeuNetS\neunets_processor>python setup.py build
C:\GitHub\NeuNetS\neunets_processor>python setup.py install
5.2 NeuNetSモデルのダウンロード
下記画面から「Download model」をクリックし、生成したモデルをダウンロードします。

モデルはzip形式で圧縮されており、以下の2つのファイルを含みます。
- keras_model.hdf5 ・・・ Kerasのモデルファイル
- metadata.json ・・・ ラベル名とインデックスのマッピングファイル
5.3 NeuNetSモデルの利用
上記2ファイルを適切なフォルダに配置し、以下のコードで私の手書き数字を認識してみました。
from neunets_processor.image import image_processor
from PIL import Image
# モデルファイルの定義
model_file = "neunets_output\keras_model.hdf5"
metadata_file = "neunets_output\metadata.json"
# 認識対象ファイルの定義
my_file = "9.png"
# モデルのロード
processor = image_processor.ImageProcessor(model_file, metadata_file)
# 認識対象ファイルオープン
test_image = Image.open(my_file).convert('L')
# 画像認識
predicted_class = processor.predict([test_image])
print("予測ラベル値: ", predicted_class)
max_p = max(predicted_class, key=predicted_class.get)
print('画像の予測は{}です。'.format(max_p))
入力画像(ビミョーな"9")と出力結果は下記になり、"9"と認識してくれました。

予測ラベル値: {0: 0.008170195, 1: 6.921888e-09, 2: 5.196157e-06, 3: 3.8861134e-07, 4: 1.0287822e-05, 5: 1.2040587e-08, 6: 2.2019007e-07, 7: 3.83452e-06, 8: 1.7265119e-06, 9: 0.9918081}
画像の予測は9です
おわりに
トレーニング用データセットを用意するだけで、NeuNetSがディープニューラルネットワークモデルを自動生成してくれるのは、確かに高いスキルを必要としないため、便利だなと思いました。
ただ、現時点ではモデル生成時にハイパーパラメーターの変更などのチューニングをおこなう設定画面はないため、期待した精度が出なかった場合の対応や、システム運用フェーズに入った際のモデルの改善をどのようにおこなっていくのかが気になりました。
NeuNetSは、まだまだこれから機能追加や改善がされていくと思われますので、今後も注視したいと思います。