はじめに
IBM Cloud上のサービスOpenScaleでは、イメージデータと正解ラベルをクラウドストレージ上にアップするだけで高精度のDLモデルが作れるNetNetS機能の提供が始まりました。
どれぐらい高精度かというと、Deep Learningのベンチマークデータとして有名なCIFAR-10で大体93%程度の精度が出ています。
[2019-01-30] 派手なデモページができていたので、最後にリンクを紹介しておきます。
どんなことをやっているのか
NeuNetSは「AIによるAI」と呼ばれています。学習用データを見て、どんなニューラルネットを組むのが最適か、調べていくということになります。
要素技術としては、TAPASと呼ばれる、入力データの複雑さから目標とする精度の見積もりを行う仕組みや、NCEvolve(Neuro-Cell-based Evolution)と呼ばれる、より精度の高いネットワークに進化させる仕組みを組み合わせて実装しています。これ以上の内容は、この記事の範囲を超えてしまいますので、関心のある方は以下のリンクの論文などを参考にされて下さい。
・TAPAS: Train-less Accuracy Predictor for Architecture Search
・Deep Learning Architecture Search by Neuro-Cell-based Evolution with Function-Preserving Mutations
以下は、論文のポイントを抜粋したブログ記事などです。
NeuNetS: Automating neural network model synthesis for broader adoption of AI
NeuNetS: Automating Neural Network Model Synthesis for Broader Adoption of AI
Using AI to Design Deep Learning Architectures
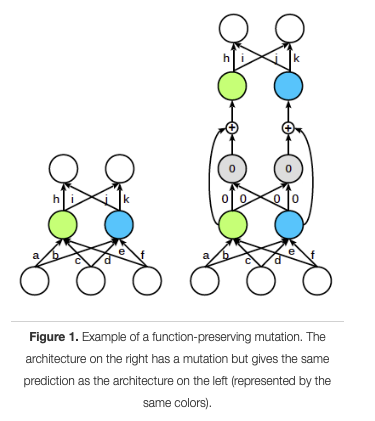
参考までに論文中の図については、いくつか下に添付しておきます。
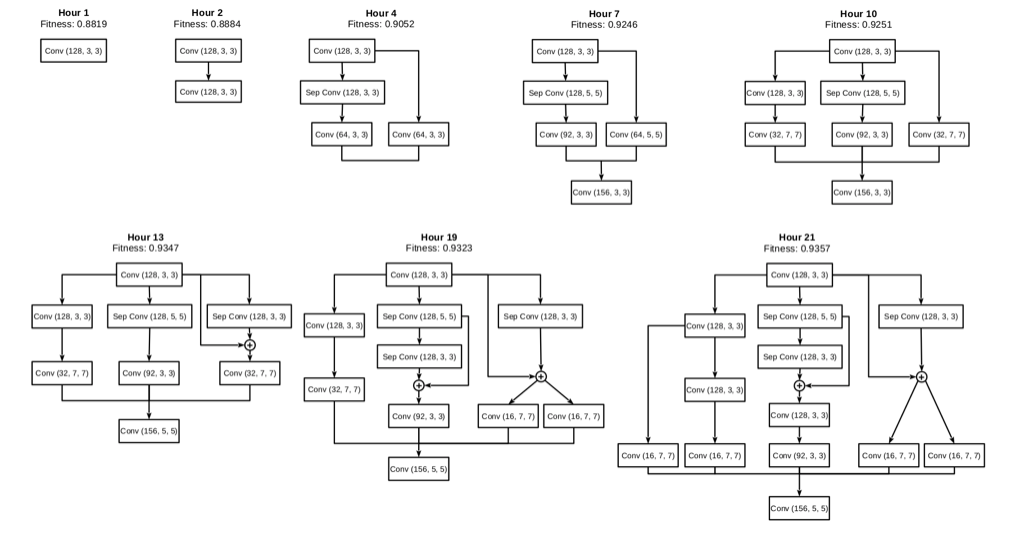
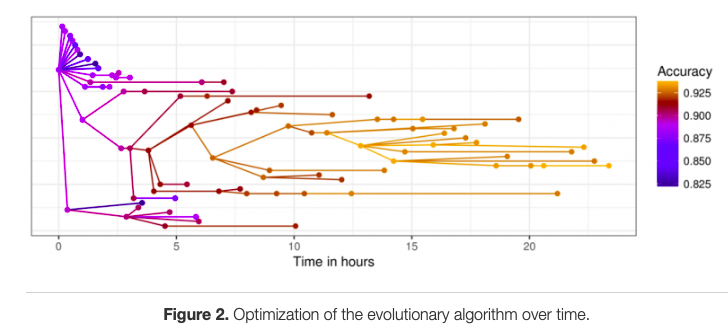
難しい話はさておき、論より証拠なので、まずは実際の動作を試してみましょう。
NetNetSは、IBM Cloudのライトアカウントというクレジットカード登録不要のアカウントで簡単に試してみることができます。以下にその手順を記載しましたので、Deep Learningに関心のある方は是非お試し下さい!
ライトアカウントのサインアップ
最初のステップは、IBM Cloudのライトアカウントのサインアップです。
手順については、こちら最新版IBM Cloud ライトアカウント登録手順を参照して下さい。
Watson Studioのプロジェクト作成
次のステップはWatson Studioでプロジェクトを作成することです。
こちらも手順を記事に書いておきましたので、こちらWatson Studioセットアップガイド(ライトアカウント可)を参照して下さい。
OpenScaleインスタンスの追加
NeuNetsのフロントのUIはWatson Studioなのですが、裏ではOpenScaleが動いています。そのため、OpenScaleのインスタンスを作成します。そのため、[IBM Cloudダッシュボード]
(https://console.bluemix.net/dashboard/apps)から、「リソースの作成」->カテゴリ「AI」->「AI OpenSCale」を選択します。
しばらく待って下の図のように「作成」ボタンが有効になったら、プランが「Lite」であることを確認の上、「作成」をクリックします。
学習用データのダウンロード
まずは最短コースでお試し下さいということで、私が作成した学習用データを連係しておきます。このデータがCIFAR-10の訓練用データ50,000件をNeuNetsの学習用に使えるようにpng形式に変換し、必要なラベルデータもあわせて作成したものです。カスタムの学習用データの作り方については後ほど解説します。
次のBoxリンクから2つのファイル、train.zip と labels.csv をダウンロードします。train.zipは約130MBと大きめのサイズなのでご注意下さい。
学習用入力・出力バケットの作成
モデル作成はクラウド上でバッチ処理として行われるため、作業のストレージが必要です。NueNetsでは、IBM CloudのストレージサービスColoud Object Storage(Amazon S3互換)を利用します。以下の手順でその設定を行います。
まず、先ほど同様に[IBM Cloudダッシュボード]
(https://console.bluemix.net/dashboard/apps)を表示し、リストにあるインスタンスの中からcloud-object-storage-xxとなっているものを選択します。(このインスタンスは、Watson Studioのプロジェクトを作った際に裏で自動的に作られているはずです。)
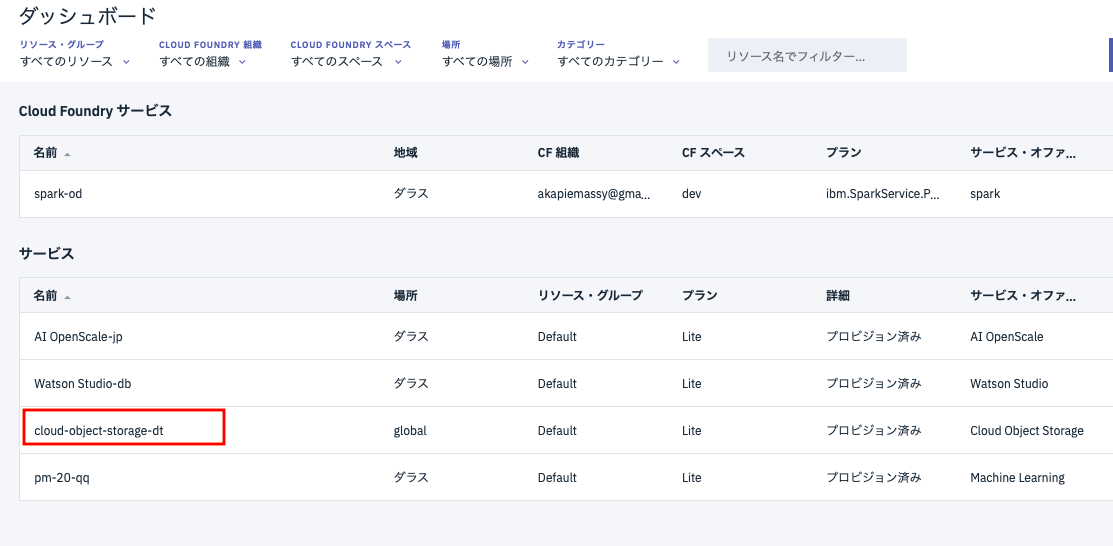
下の画面になったら、「バケットの作成」をクリックします。
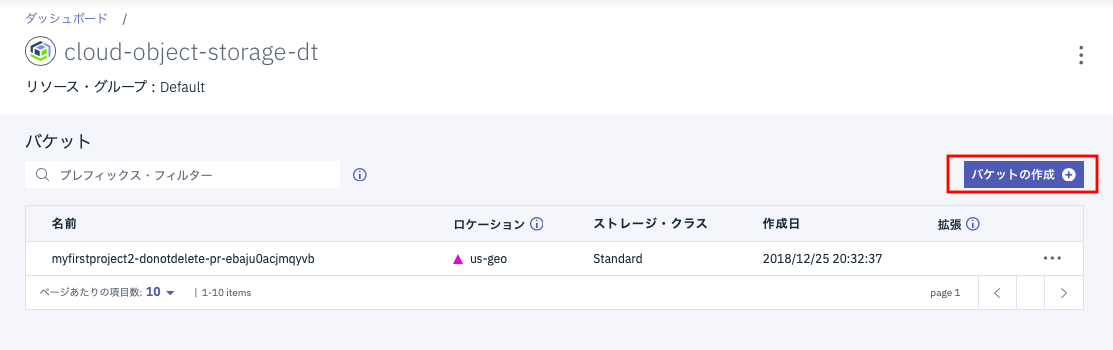
下にバケット作成時の入力画面を示します。デフォルト値から変更が必要なのは、「固有のバケット名」と「回復力」です。
固有のバケット名はなんでもいいのですが、グローバルでユニークな名前を指定します。最初に作るのは出力用バケットなので、図のように出力用とわかるものが望ましいです。「回復力」はデフォルトの「Regional」を図のように「Cross Region」に変更します。ロケーションはデフォルトで「us-geo」のはずですが、違っていたら「us-geo」に変更して下さい。「ストレージクラス」は図のようにデフォルト値のままでいいです。
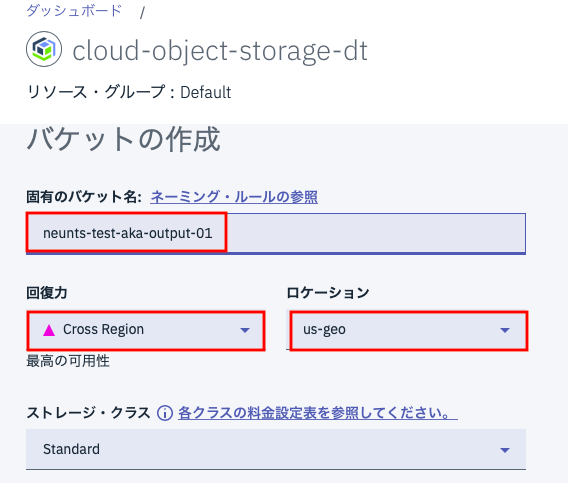
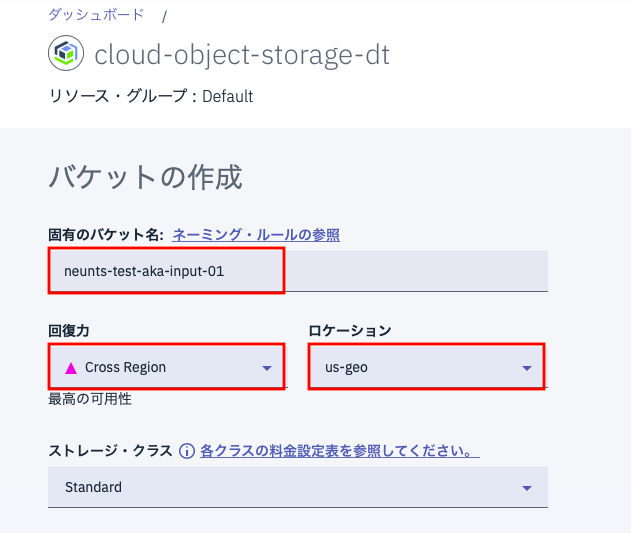
次に同じ要領で入力用バケットを作成します。オプションなどは上とまったく同じ方式です。
学習用ファイルのアップロード
入力用バケットには、先ほど事前準備でダウンロードした2つのファイルをアップロードして下さい。drag & dropでアップロード可能です。最終的には下の図のようになっているはずです。
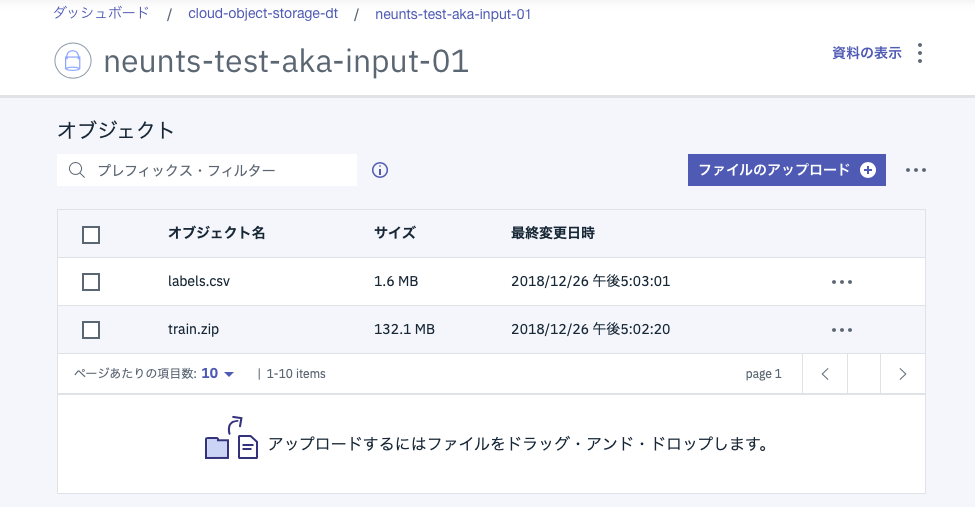
モデル作成
お待たせしました。これで必要な準備作業はすべて完了しました。次にいよいよNeuNetSのモデル作成機能を呼び出します。
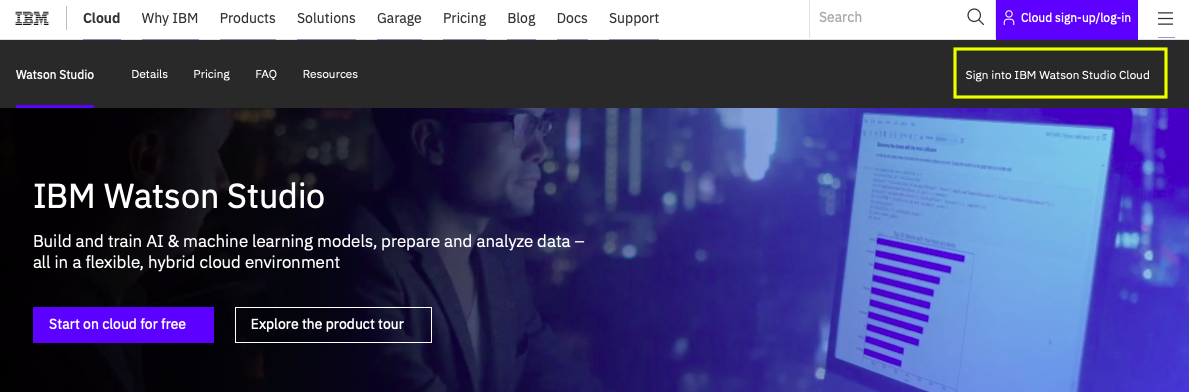
Watson Studio初期画面から右上のリンクをクリックしてWatson Studioにログインします。ログイン後に下の画面になったら、右上の「Sign in ..」のリンクをクリックします。
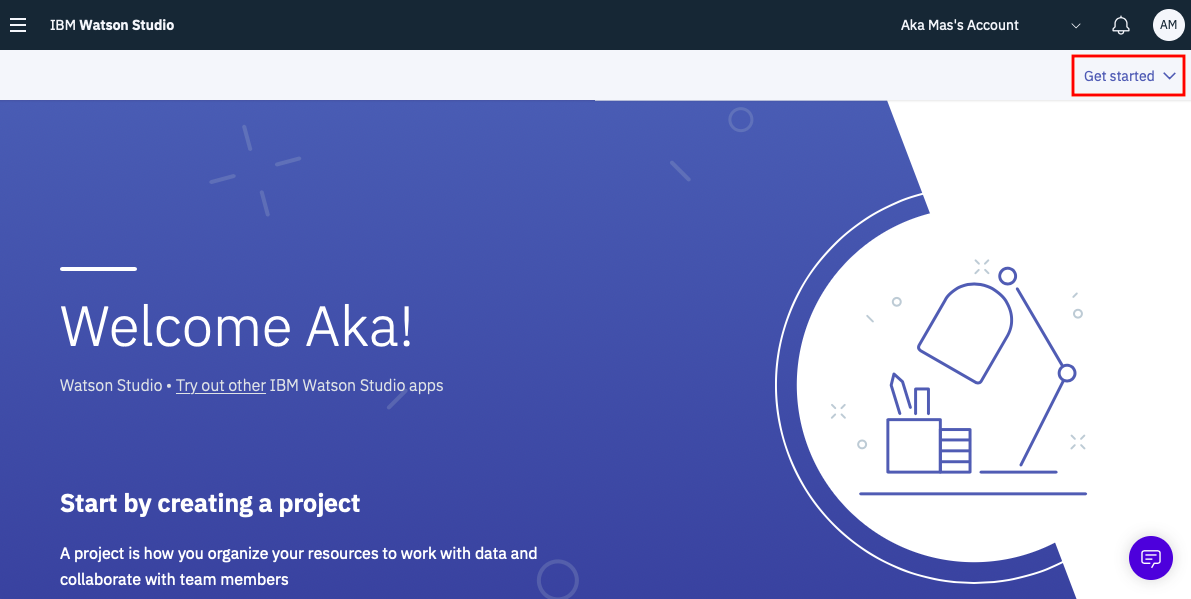
下の画面になったら、右上の「Get started」のリンクをクリック。
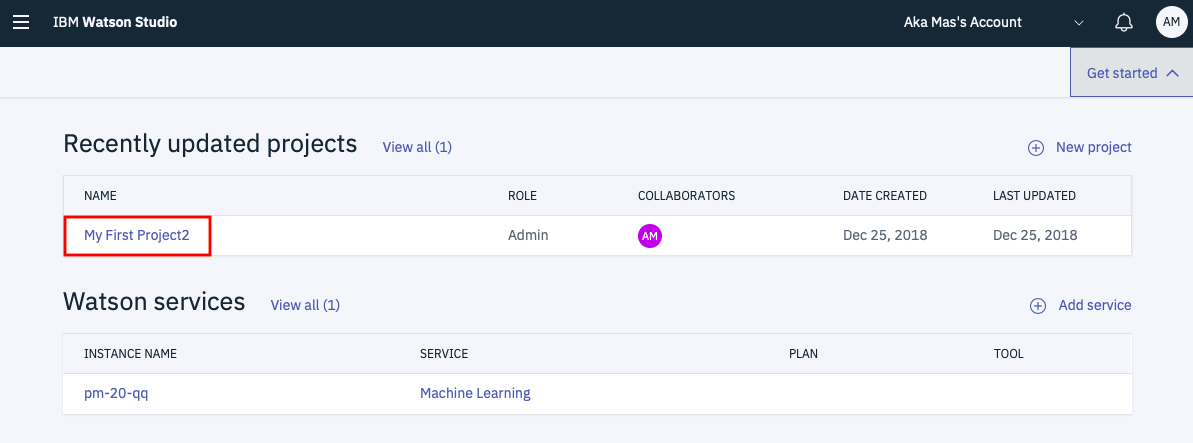
次の画面で先ほど作ったばかりのプロジェクトのリンクをクリックします。
プロジェクトのメイン画面になったら、画面右上の「Add to project」をクリック、引き続きメニューから「SYNTHESIZED NE..」を選択します。
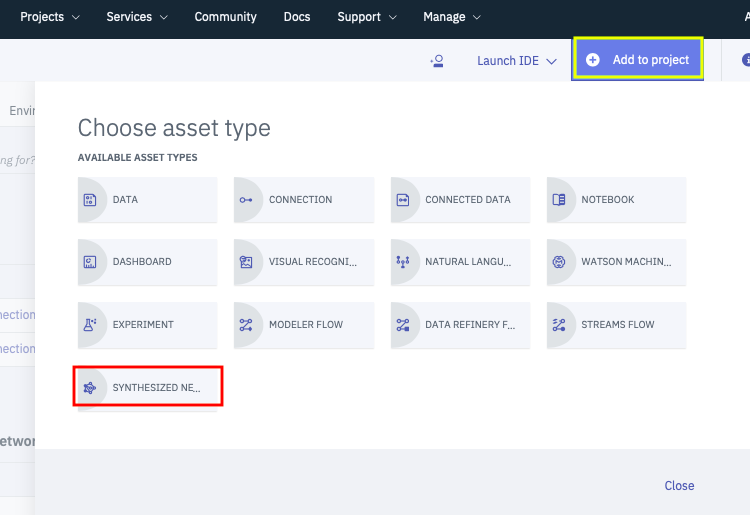
すると下のように「Synthesize text or image classifier」というパネルが表示されます。「CIFAR10 Test」のように名前を適当に設定した後、「Training data connection」の欄の「Select」ボタンをクリックします。
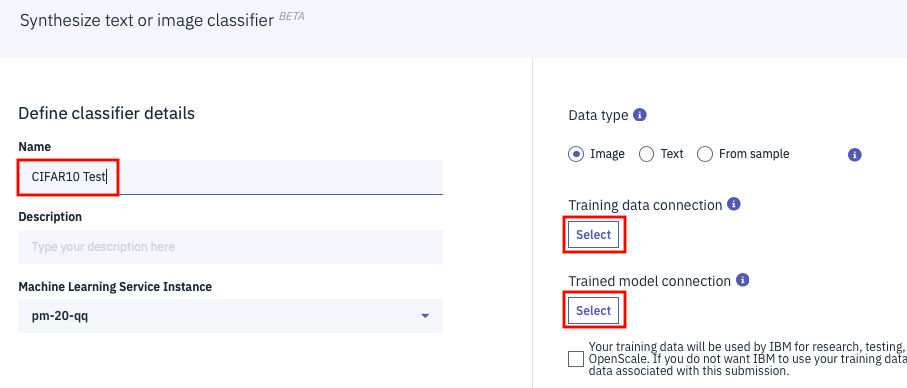
下のような画面になりますので、「New connection」タブをクリック
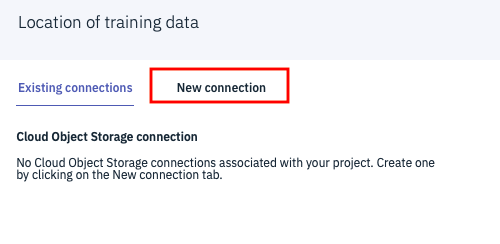
ドロップダウンから先ほど作成したCloud Object Storageのインスタンスと、入力用のバケットを順に選択し、画面右下の「Create」ボタンをクリックします。
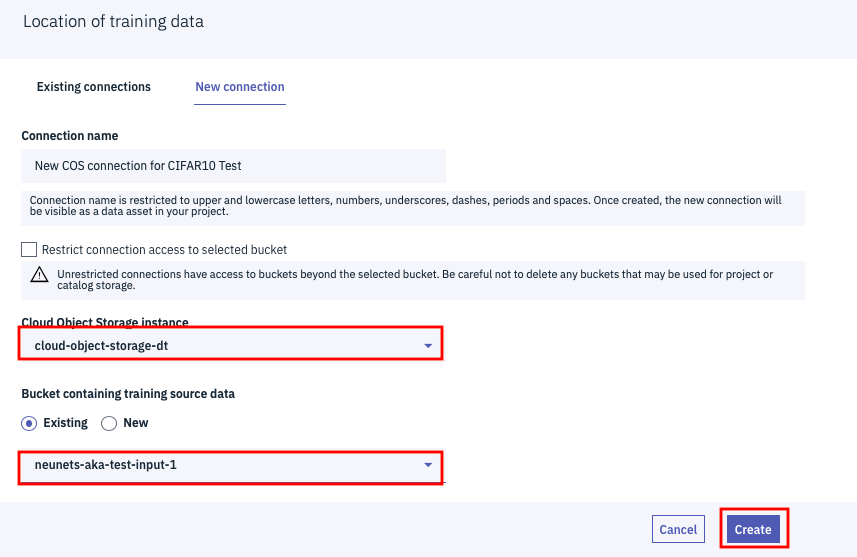
元の画面に戻りますので、次の「Trained model connection」の下のボタンをクリックします。今度は「Existing Connections」のタブから設定可能です。
「Cloud Object Storage connection」のドロップダウンは先ほど自動作成したconnection名、「Bucket containing results data」の欄は、出力用バケットを指定して、画面右下の「Select」をクリックします。

下記が、必要な項目の設定がすべて完了した状態での設定画面です。赤枠で囲んだ設定項目がすべて適切に設定されたことを確認した上で、画面右下の「Begin Synthesis」をクリックします。
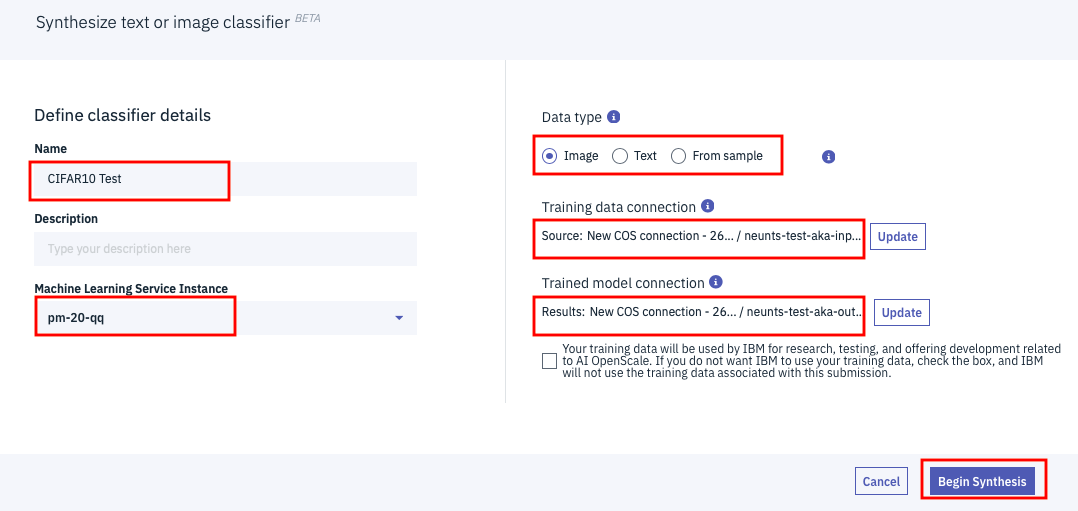
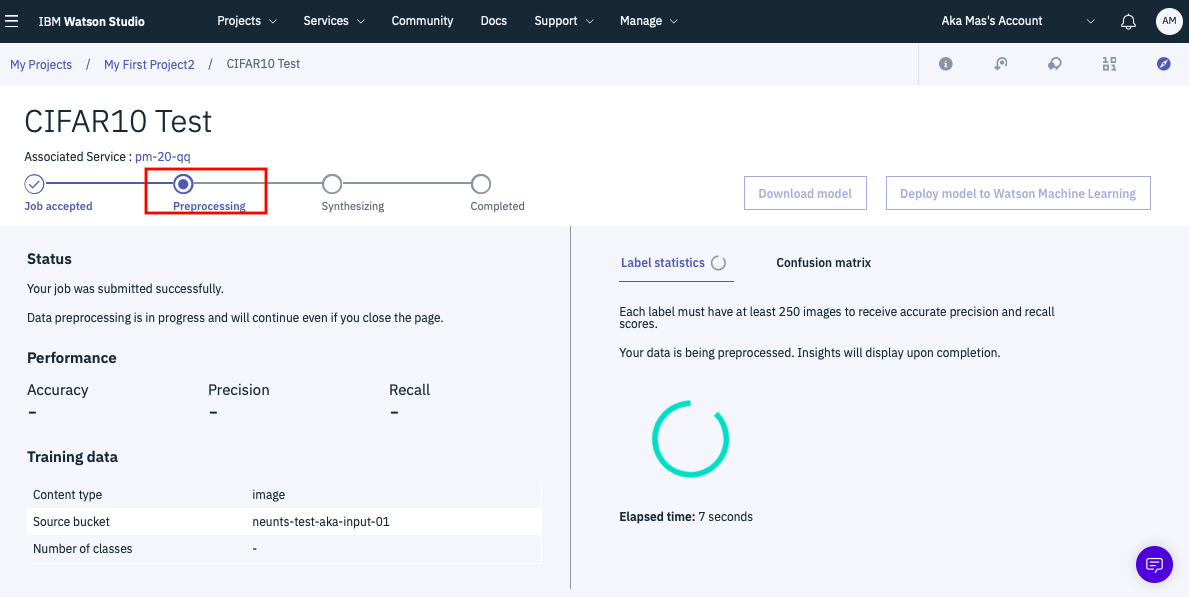
下記がボタンをクリックした直後の画面です。ステータスが「Preprocessing」となっており、学習データの整合性チェックを行っている状態であることを示しています。
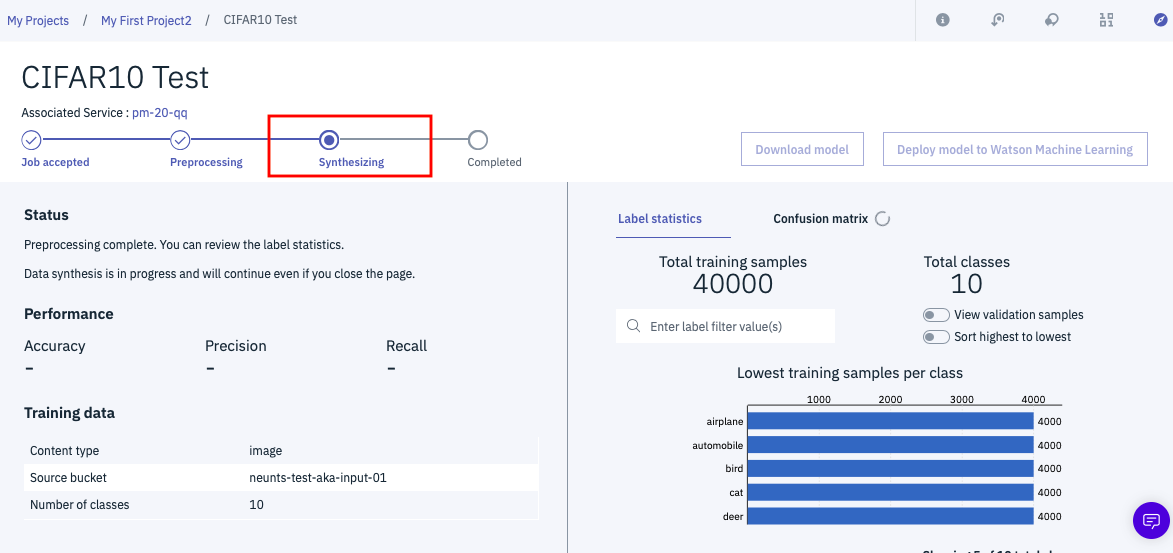
数分間待っていると、下のような画面に遷移します。整合性チェックが完了して最適なモデルを自動作成するフェーズに移行したことを示しています。ここまでくればもう画面を見ている必要はないです。ブラウザをいったん閉じて、後のことはWatsonに任せて下さい。
2、3時間後にWatson Studioの同じ画面を開くと、下の図のように完成したモデルの画面に遷移していることがわかります。
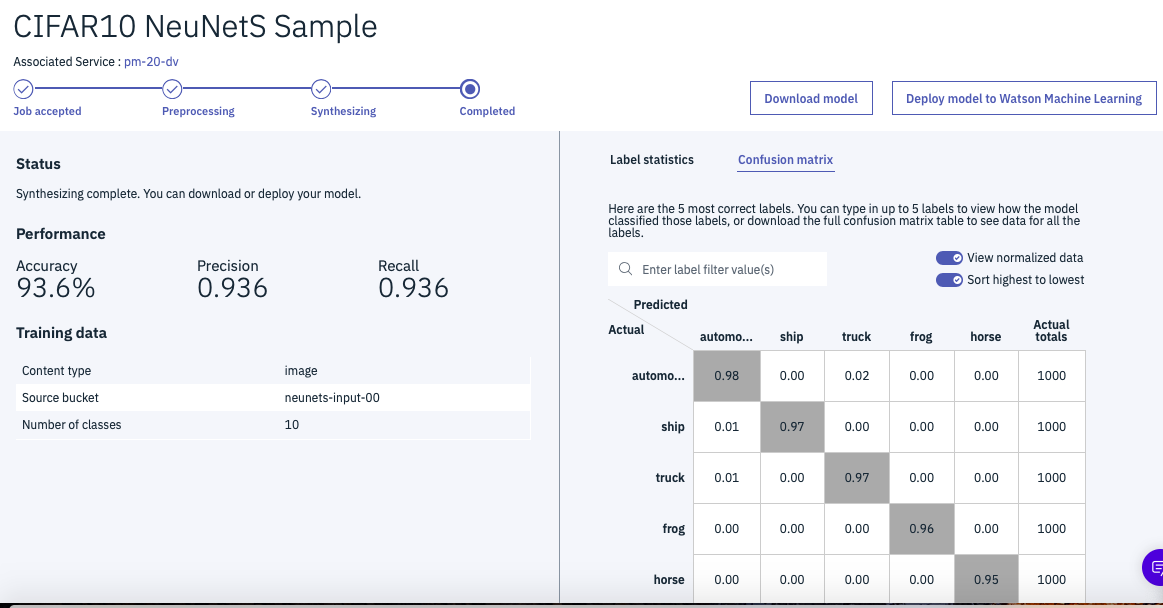
下の図が、完成後の画面例です。(機械学習の通例でいつもこの精度が出るわけではありません)
Accuracyが93.6%となっていることがわかります。クラウドには50000件アップしたのですが、学習に使われたのは40000件で、10000件は検証データとして使われていることもわかります。
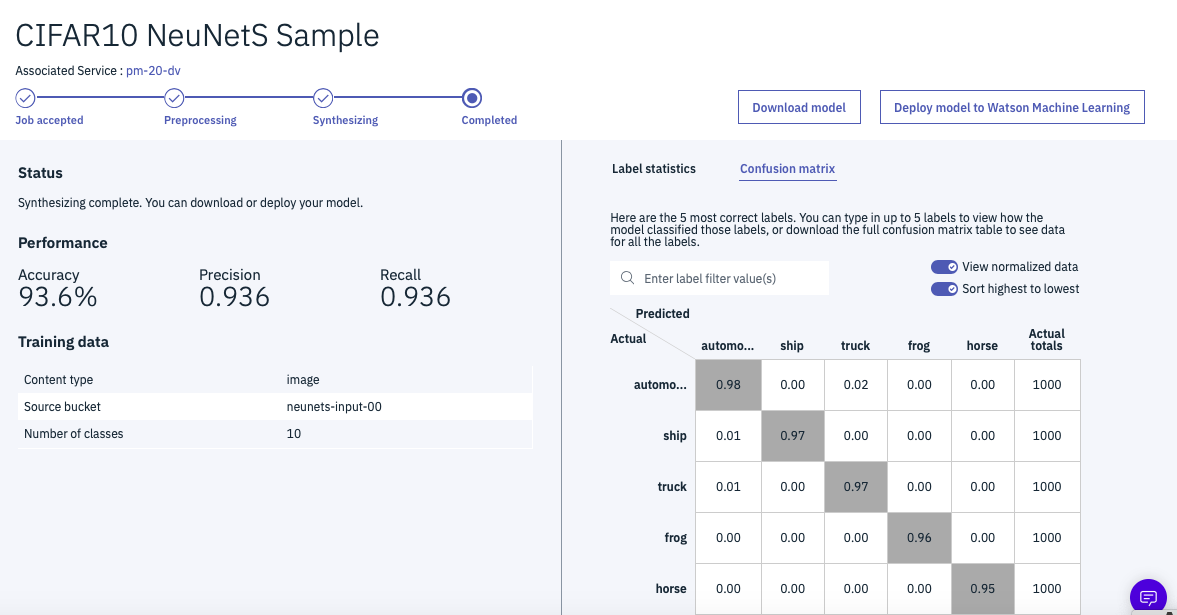
ツールにはConfusion Matrixの表示機能も持っていて、その機能を使って表示した結果です。イヌとネコの区別が難しいことが、この表から読み取れます。
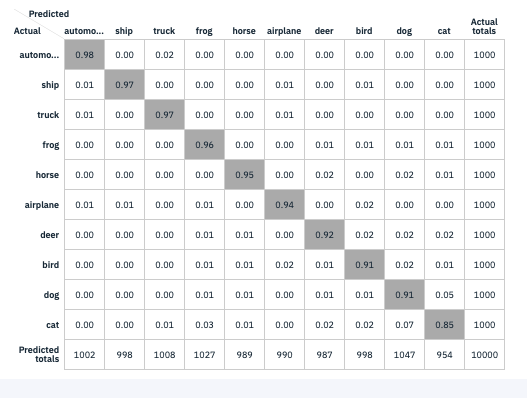
モデルの検証
ツールの画面上はこんな形で高い精度がでているのですが、本当にそうなのか確認してみます。
NeuNetSで作成したモデルの使い方としては次の2つの方法があります。
- モデルファイルをローカルにダウンロードして利用する
- モデルファイルをWatson Studio上のMachine Learningモデルとしてデプロイする
このうち、精度の検証は前者の方法のほうが簡単にできるので、前者の方法で確かめました。
まず、下の画面から「Download model」を選択して、作ったモデルをダウンロードします。
ダウンロードしたファイルは neunets_output.tar.gz という名前になっています。
解凍すると、keras_model.hdf5とmetadata.jsonという二つのファイルになっています。このkeras_model.hdf5というファイルはKerasのライブラリですぐにKerasのModelクラスにすることができます。
以下に、このファイルをModelに戻して、CIFAR-10の検証データ(学習には一切使われていない)を使って精度を検証するサンプルプログラムを記載します。
# Modelのロード
from keras.models import load_model
model = load_model('keras_model.hdf5')
# CIFAR-10データ読み込み
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 入力データの前処理
# 入力データに関しては前処理として標準化を行う必要がある
x = x_test
import numpy as np
mean = np.mean(x)
std = np.std(x)
x = (x - mean)/std
# 正解データを配列に
yt = y_test.ravel()
# テストデータから予測値の取得
predict = model.predict(x)
# 予測値から、予測ラベルを求める
yp = np.argmax(predict, axis=1).ravel()
# 精度(Accuracy)の計算
from sklearn.metrics import accuracy_score
print('accuracy:', accuracy_score(yt, yp))
#
from sklearn.metrics import classification_report
print(classification_report(yt, yp))
# Confusion Matrixの表示
from sklearn.metrics import confusion_matrix
print(confusion_matrix(yt, yp))
結果は次のとおりで、確かに93%強の精度がでていそうなことがわかります。
accuracy: 0.9323
precision recall f1-score support
0 0.95 0.93 0.94 1000
1 0.95 0.97 0.96 1000
2 0.91 0.91 0.91 1000
3 0.88 0.85 0.86 1000
4 0.94 0.94 0.94 1000
5 0.89 0.89 0.89 1000
6 0.91 0.97 0.94 1000
7 0.97 0.95 0.96 1000
8 0.97 0.96 0.96 1000
9 0.96 0.94 0.95 1000
avg / total 0.93 0.93 0.93 10000
[[930 4 23 4 4 1 6 1 23 4]
[ 2 975 1 0 0 2 2 1 1 16]
[ 13 0 909 17 17 13 24 4 1 2]
[ 5 2 19 852 14 62 33 3 3 7]
[ 0 0 13 13 941 11 14 7 0 1]
[ 4 0 12 56 18 891 8 11 0 0]
[ 4 0 11 11 0 3 971 0 0 0]
[ 3 0 6 10 11 15 4 949 0 2]
[ 16 8 2 2 0 2 1 0 960 9]
[ 5 36 3 5 1 0 0 0 5 945]]
次に検証データの先頭50個で、どんな画像を間違えていたのか調べてみました。
# データ内容の確認
import matplotlib.pyplot as plt
N = 50
indexes = range(N)
# x_orgの選択結果表示 (白黒反転)
x_selected = x_test[indexes]
y_selected = yt[indexes]
# 予測値の計算
yp_test = yp[indexes]
# グラフ表示
plt.figure(figsize=(15, 20))
for i in range(N):
ax = plt.subplot(10, 10, i + 1)
plt.imshow(x_selected[i])
ax.set_title('%d:%d' % (y_selected[i], yp_test[i]),fontsize=14 )
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
結果がこちら。
写真のタイトルの文字の左が正解値、右が予測値です。それぞれの数字は、この表で読み替えます。
[['0' 'airplane']
['1' 'automobile']
['2' 'bird']
['3' 'cat']
['4' 'deer']
['5' 'dog']
['6' 'frog']
['7' 'horse']
['8' 'ship']
['9' 'truck']]

50件中3件エラーですが、人間でもわけわからないものばかりです。
相当いい精度のモデルができたことは確かなようです。
最後に、以下のコードでモデルのネットワーク図を作ってみました。
from keras.utils import plot_model
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
plot_model(model, to_file='neunets-model.png', show_shapes=True, show_layer_names=True)
その結果については、Githubにアップしておきました。
ネットワーク図
全部は載せきれないので、冒頭の部分だけアップしておくと、こんな感じです。
結構すごい仕組みができているかなという感想です。皆様も是非お試し下さい!
(参考)学習データの作り方
Training data format required for training models using NeuNetSに解説がありますが、データの作り方は大変簡単です。
train.zipとlabels.csvという2つの名前決め打ちのファイルを作って、COS(Cloud Object Storage)にアップロードするだけです。
イメージデータ以外に正解ラベルを示すファイル(labels.csv)が必要ですが、そのファイルの書式は下記のとおりです。
<filename1>,<labelname1>
<filename2>,<labelname2>
:
例として、サンプルで作ったCIFAR10学習用データの冒頭の部分は次のようになっています。
frog/train-frog-00000.png,frog
truck/train-truck-00001.png,truck
truck/train-truck-00002.png,truck
deer/train-deer-00003.png,deer
automobile/train-automobile-00004.png,automobile
automobile/train-automobile-00005.png,automobile
bird/train-bird-00006.png,bird
horse/train-horse-00007.png,horse
ship/train-ship-00008.png,ship
cat/train-cat-00009.png,cat
deer/train-deer-00010.png,deer
イメージファイルの種類としてはjpegとpngが対応しています。
以下に、kerasライブラリで提供されるCIFAR-10の学習用データから、検証用のtrain.zipとlabels.csvを生成するサンプルコードを添付します。
# 作業用ディレクトリの準備
base_dir = 'Image'
zip_dir = 'ZIP'
import os
import shutil
shutil.rmtree(base_dir)
shutil.rmtree(zip_dir)
os.mkdir(base_dir)
os.mkdir(zip_dir)
# イメージ読み込み
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# ラベル名配列
import numpy as np
cifar10_labels = np.array([
'airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck'])
# サブディレクトリ作成
for i in range(10):
subdir = '%s/%s' % (base_dir, cifar10_labels[i])
print(subdir)
os.mkdir(subdir)
from PIL import Image
label_file = '%s/labels.csv' % zip_dir
f = open(label_file, "w")
# 生成イメージ数(最大50000)
image_num = 100
# image_num = 50000
# イメージファイル生成
for i in range(image_num):
img = Image.fromarray(x_train[i])
label_i = y_train[i][0]
label = cifar10_labels[label_i]
#filename = '%s/%s/train-%s-%05d.png' % (base_dir, label, label, i)
filename1 = '%s/train-%s-%05d.png' % (label, label, i)
filename2 = '%s/%s' % (base_dir, filename1)
#print(filename1)
f.write('%s,%s\n' % (filename1, label))
with open(filename2, mode='wb') as out:
#img.save(out, format='jpeg', quality=100, optimize=True)
img.save(out, format='png')
f.close()
# 圧縮ファイル作成
import tarfile
os.chdir(base_dir)
# 圧縮ファイル名
tar_name = '../%s/train.zip' % zip_dir
# 圧縮処理
archive = tarfile.open(tar_name, mode='w:')
archive.add('.')
archive.close()
os.chdir('..')
(参考)サンプルアプリケーション
上記の方法で作ったModelをWatson Machine Learningにデプロイ、Webサービス化しました。そしてそのWebサービスを呼び出すサンプルアプリを作ってみました。
Watson StudioでCIFAR-10用に作ったサンプルアプリをほんの少し手直ししただけです。
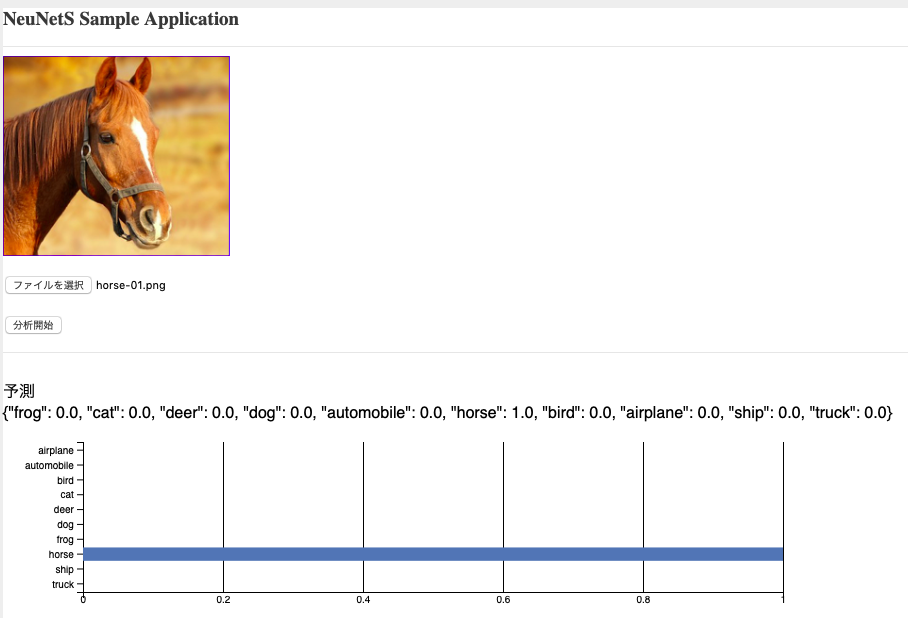
具体的には、イメージを受け取って加工し(イメージを(32,32,3)のNumpy配列に変換、更にListにする)APIを呼び出すところは一切変更していません。
APIの戻り値はデータの表現が若干変わりました。下記の様な形式のJsonデータがやってくるようになっています。
{
"automobile": 1.6959260384918906e-11,
"bird": 1.0,
"dog": 4.241513806846342e-10,
"deer": 3.1998675931177445e-10,
"truck": 8.276909539695065e-12,
"frog": 1.0537125616494336e-09,
"cat": 4.5520576891222575e-11,
"horse": 2.7509487743326844e-11,
"airplane": 2.0071992956616214e-09,
"ship": 1.0772259473323942e-10
}
これに伴い、データを受けて表示するまでのロジックを若干変更しています。今までと比べるとシンプルな形式の戻り値なので、新たにアプリをつくる分にはかえってやりやすくなったと思います。
Githubのリンクはこちら
README.MDに簡単な導入手順もついていますので、こちらもあわせてお試しいただければと思います。このアプリケーションもLiteアカウントの範囲内で利用可能です。
おまけ
デモページ
最後に最近見つけたデモページをご紹介しておきます。なかなか派手なアニメーションで見ていて面白いです。
Automatically build an optimized neural network