![]() 誰でもAIモデルが作れる! Watson Studioに新しく搭載された機械学習の自動化機能「AutoAI」をザクっとご紹介しますの続きです。(長くなるので記事を分割しました)
誰でもAIモデルが作れる! Watson Studioに新しく搭載された機械学習の自動化機能「AutoAI」をザクっとご紹介しますの続きです。(長くなるので記事を分割しました)
![]() (2019/12月) Relationship Mapなど機能強化に伴い一部の画面コピーを取り直しました。
(2019/12月) Relationship Mapなど機能強化に伴い一部の画面コピーを取り直しました。
![]() (2020/04月) モデルの生成数が4->8に増えたのに伴い、一部の画面コピーを取り直しました。
(2020/04月) モデルの生成数が4->8に増えたのに伴い、一部の画面コピーを取り直しました。
やってみた
シナリオ
前述のYoutube動画やCognos Analyticsのデモ等でよく使われる顧客離反の実績データ(customer_churn.csv)を使って予測モデルを作り、顧客のサービス解約の可能性を予測します。


上記のようなデータで、"CHURN"の値(TかFか)を予測する二値予測問題です。
![]() 記事を読むだけでなく実際に実行される場合は、上記のCSVデータをお手元にダウンロードしておいてください。
記事を読むだけでなく実際に実行される場合は、上記のCSVデータをお手元にダウンロードしておいてください。
はじめに
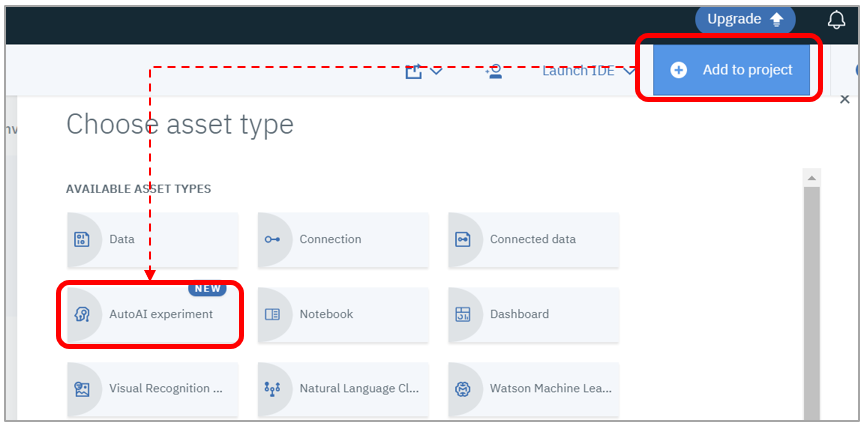
- 任意のプロジェクトで「Add to Project」-「AutoAI Experiment」をクリック
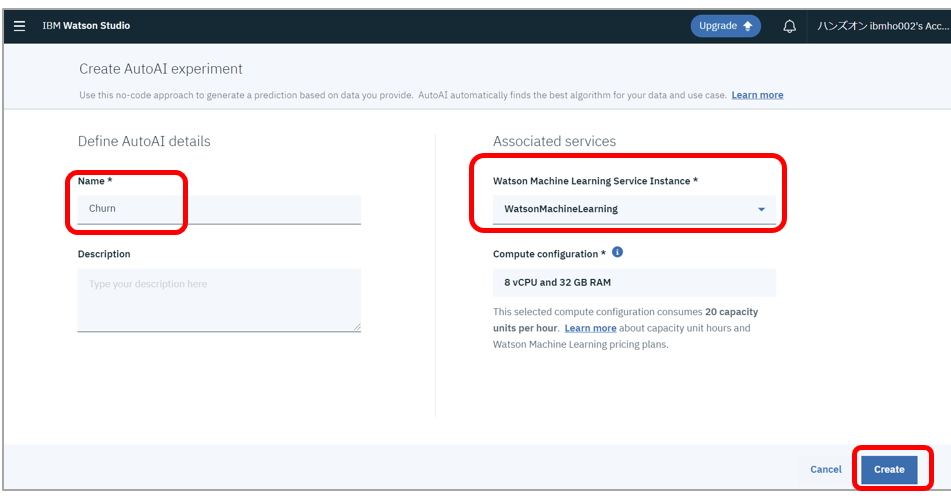
- Nameに任意の名前を入力し、利用するWatson Machine Learningのインスタンスを選択して「Create」ボタン
入力データを指定
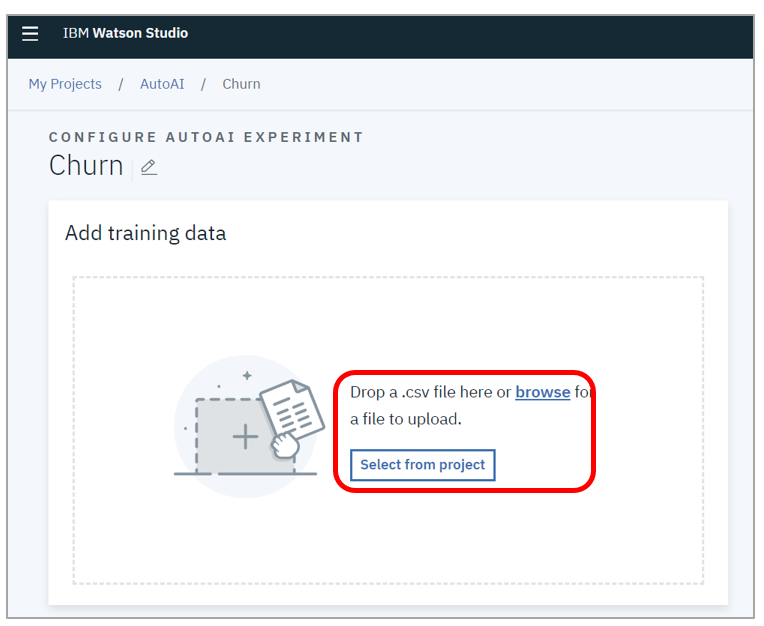
- 「browse」リンクでダウンロード済みのcsvファイルを指定します
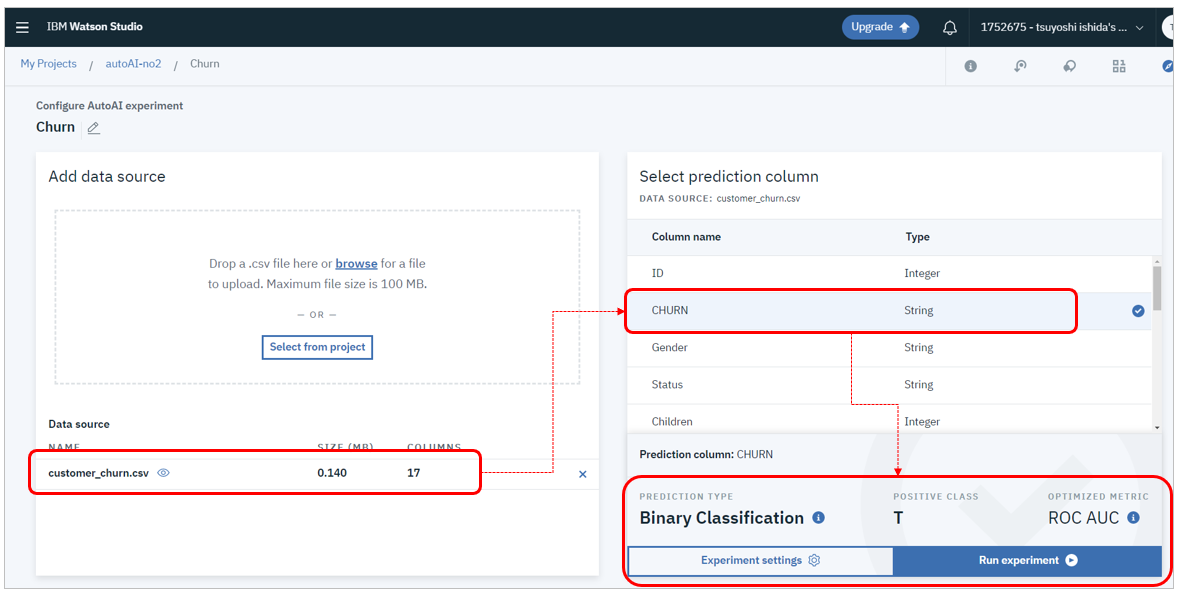
- 「DataSource」欄にCSVファイルの名前が表示されます
- 右側に「Select column to predict(予測したいカラムを選択)」が表示されるので「CHURN」を選択します
- 「CHURN」を選択すると自動的に「PREDICTION TYPE(予測の種類)」は「Binary Classification(二値分類)」がセットされ、「OPTIMIZED METRIC(最適化の指標)」は「ROC AUC(Area under an Curve)」にセットされます
- 「Run experiment」ボタンを押します
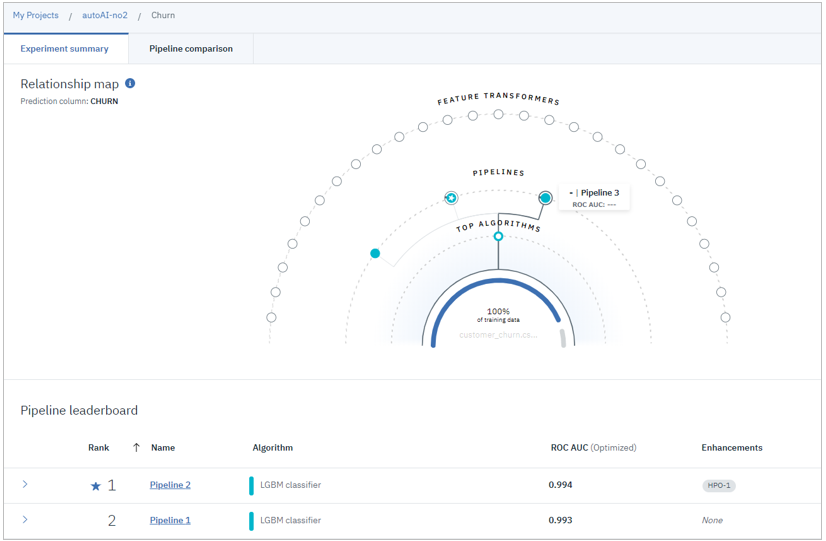
- 処理の進行につれてRelationShip Mapが逐次、ダイナミックに更新されていきます。
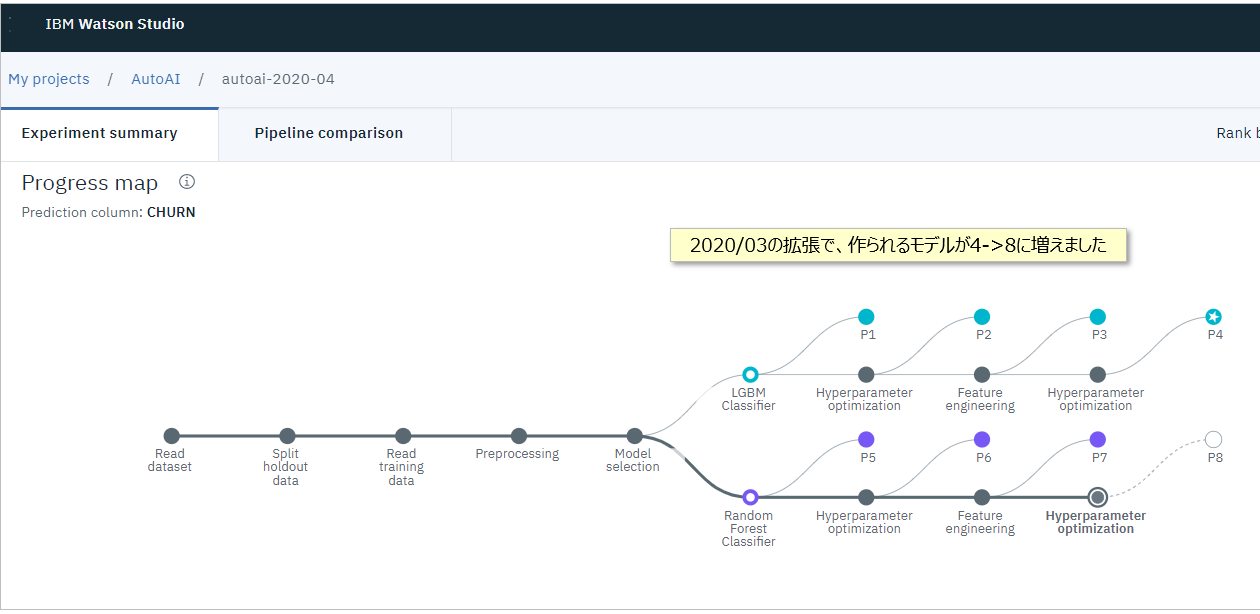
- ビューを切り替えるとProgress Mapもみられます。トレーニングの進行状況を見るのに便利です。
モデルの評価
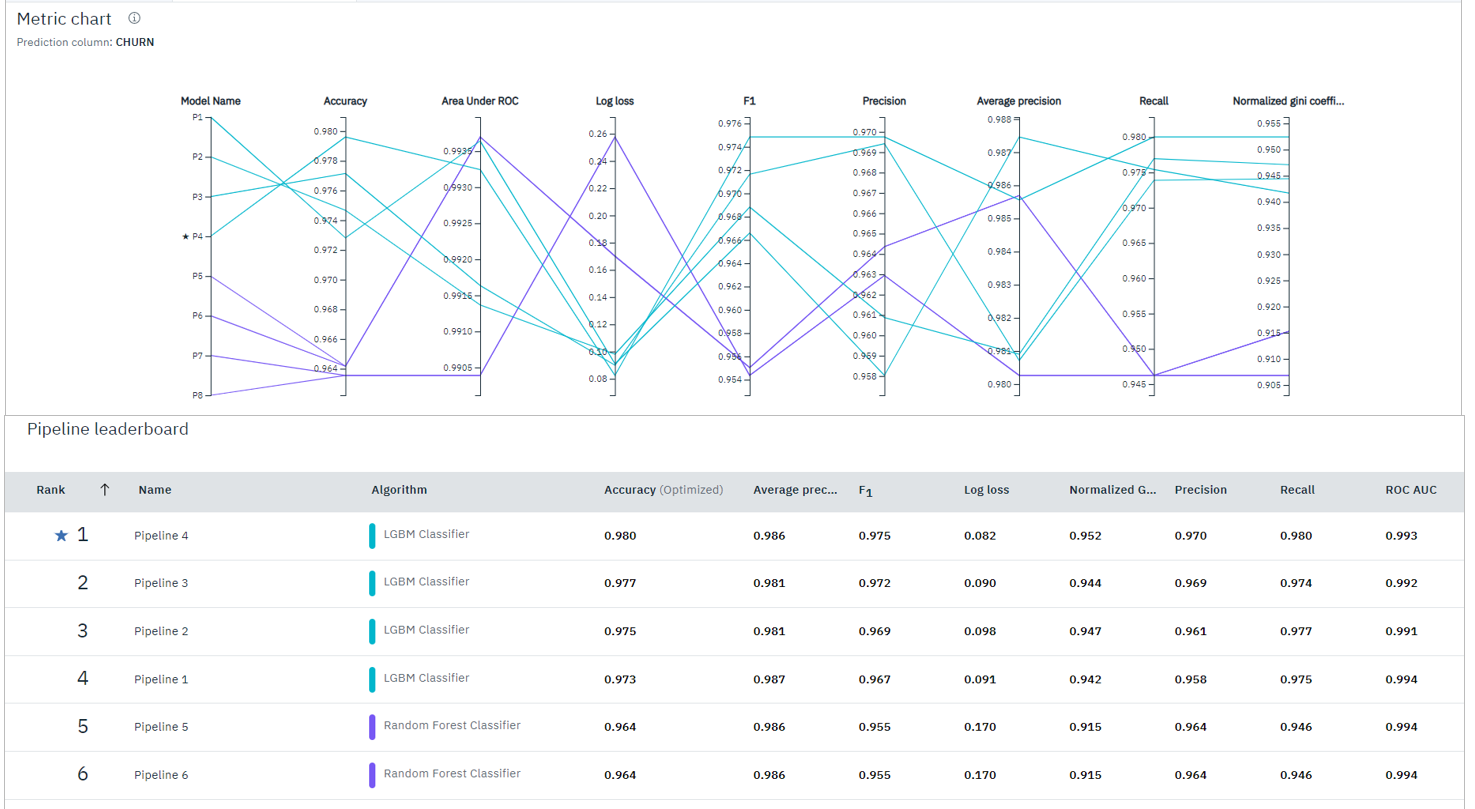
- 完了しました。今回のデータではトレーニングに11分かかりました。
- パネルの下部にモデルの精度が表示されています。
- 「view details」のリンクからモデルの詳細情報を参照できます
View Details
※解く問題の種類により表示される内容は若干違います。当ケースは二値分類の場合の例です。
基礎的な性能指標
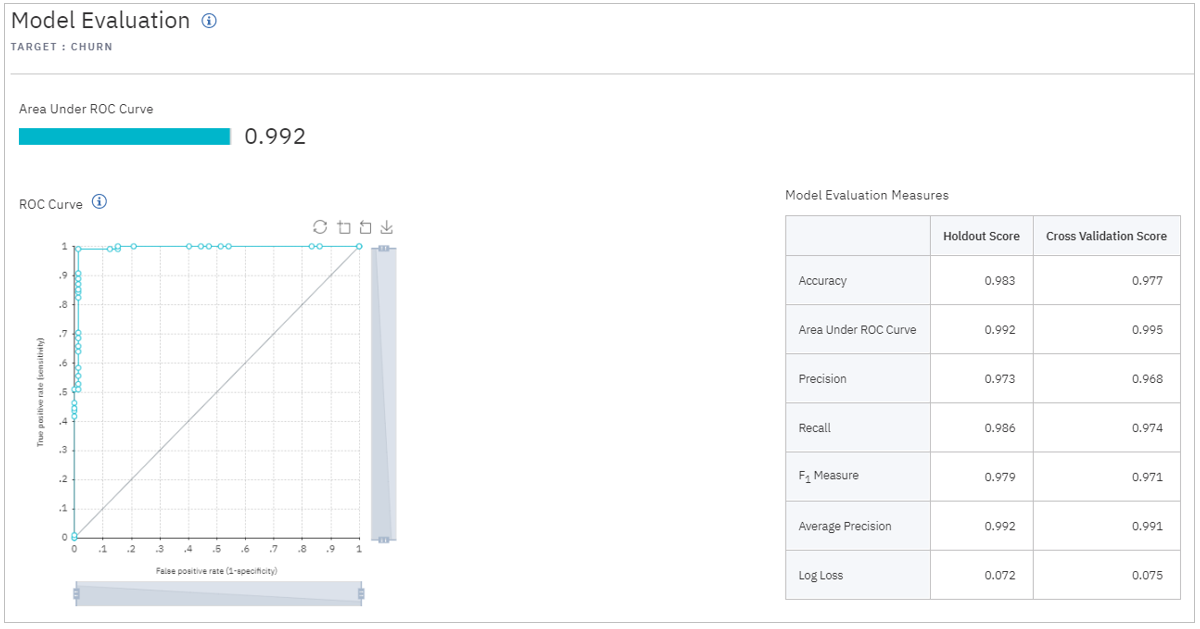
混同行列(二値分類なので)
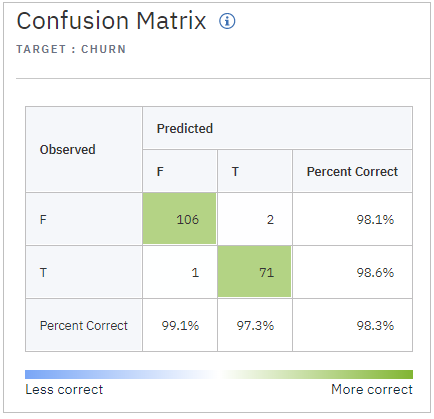
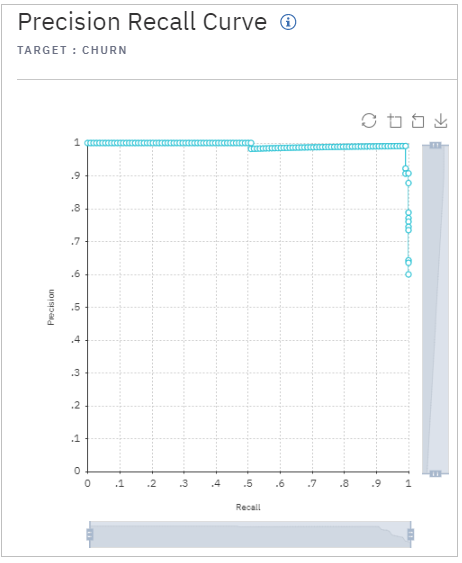
PR曲線
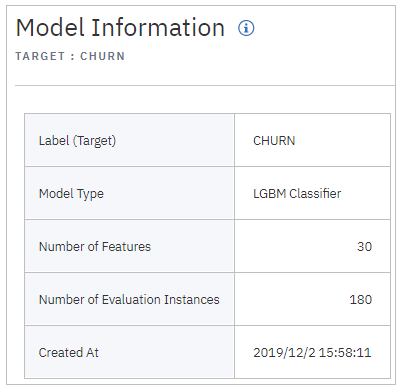
モデルの基本情報
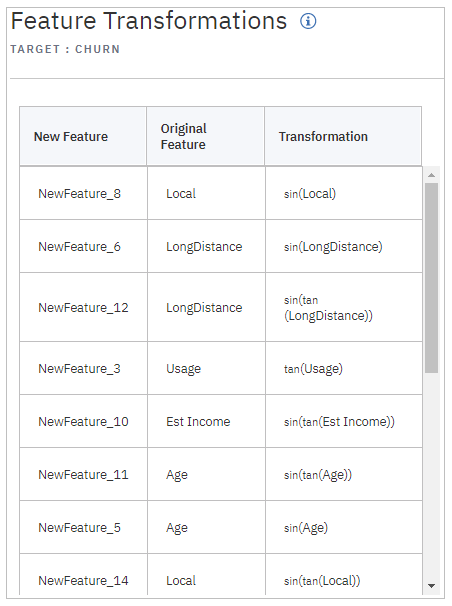
特徴量変換の内訳(こういうのを自動でやってくれるの、楽ですね)
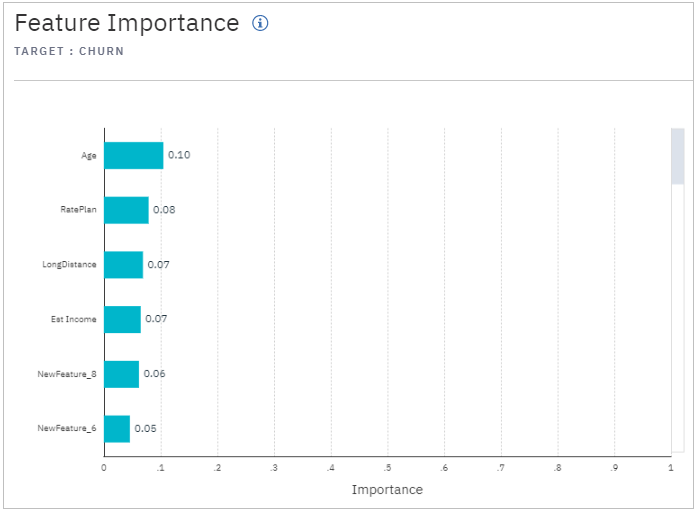
それぞれの特徴量の重要度
モデルの保管とデプロイ
モデルを保管してWMLにデプロイする手順はModel BuilderやSPSS Modelerなどと同じです。

- 「Save as model」でモデルを保管します
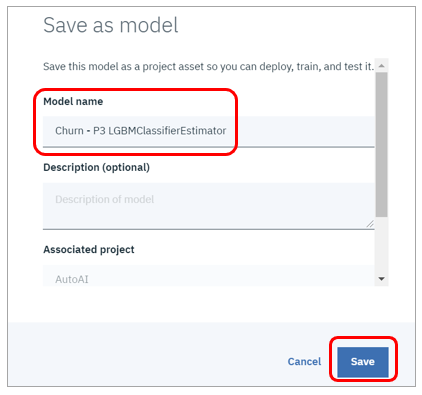
- 任意の名前を指定して「Save]
- saveされました
- 「View in project」のリンクをクリック
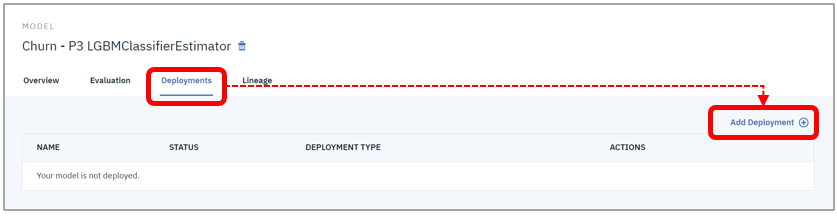
- 「Deployments」タブ-「Add Deployments」をクリック
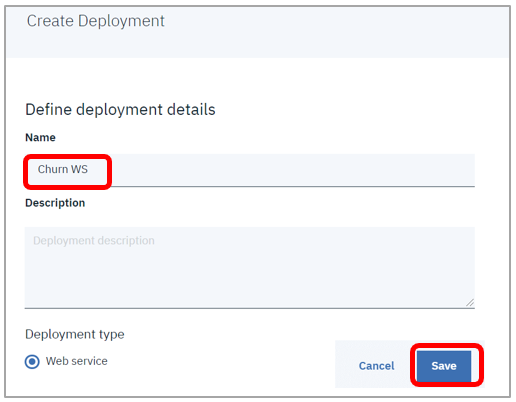
- 任意の名前を入力して「Save」
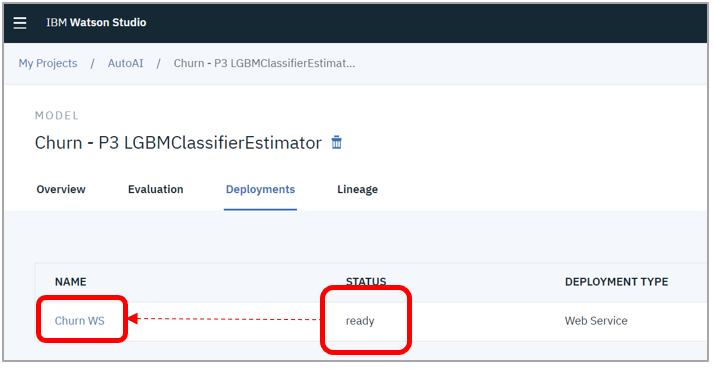
- Statusが「ready」になったらWMLへのデプロイは成功しています
- サービスの名前のリンクをクリック
モデルのテスト
![]() (2019/08/06) What's Newによると2019/07/19付でテストでフォームが使えるようになりました。今まではJSON形式の要求をベタで渡す必要がありましたが、楽になりました。
(2019/08/06) What's Newによると2019/07/19付でテストでフォームが使えるようになりました。今まではJSON形式の要求をベタで渡す必要がありましたが、楽になりました。
以下はJSON形式の場合です。
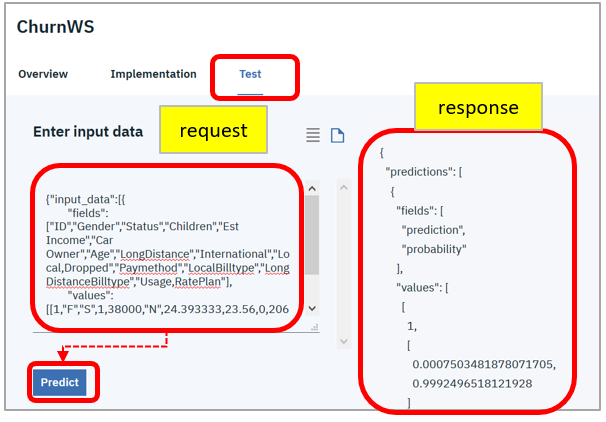
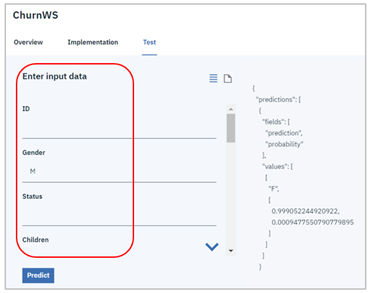
- 「Test」タブ
- 「Enter input data」欄にjsonの形式で要求ぺイロードを記載します
- 「Predict」ボタン
- 右側にレスポンス(判定結果)が返ります
{"input_data":[{
"fields": ["ID","Gender","Status","Children","Est Income","Car Owner","Age","LongDistance","International","Local,Dropped","Paymethod","LocalBilltype","LongDistanceBilltype","Usage,RatePlan"],
"values": [[1,"F","S",1,38000,"N",24.393333,23.56,0,206.08,0,"CC","Budget","Intnl_discount",229.64,3]]
}]}
- 要求のJSONのレイアウトはマニュアルのココに書いてありますが、要は下記の感じです
{"input_data":[{
"fields": ["名前1","名前2",..."名前N"],
"values": [[値1,値2,...値N]]
}]}
- JSON中にターゲット=予測対象=当ケースでは「"CHURN"」のカラムとデータは存在してはいけません。(それを予測するのですから当然ですが)
- ターゲット以外は省略できません。存在しないなら明示的にnullという値を渡す必要があります
{"input_data": [{
"fields":["ID","Gender","Status","Children","Est Income","Car Owner","Age","LongDistance","International","Local","Dropped","Paymethod","LocalBilltype","LongDistanceBilltype","Usage","RatePlan"],
"values":[[null,"F",null,null,null,null,null,null,null,null,null,null,null,null,null,null]]}]
}
{"input_data": [{
"fields":["Gender"],
"values":[["F"]]}]
}
(ご参考) モデル作成時に指定可能なオプション
発表当初はデフォルト決め打ちでしたが、2019/12月現在、デフォルトの設定を変更できるようになってます。
【データソース】
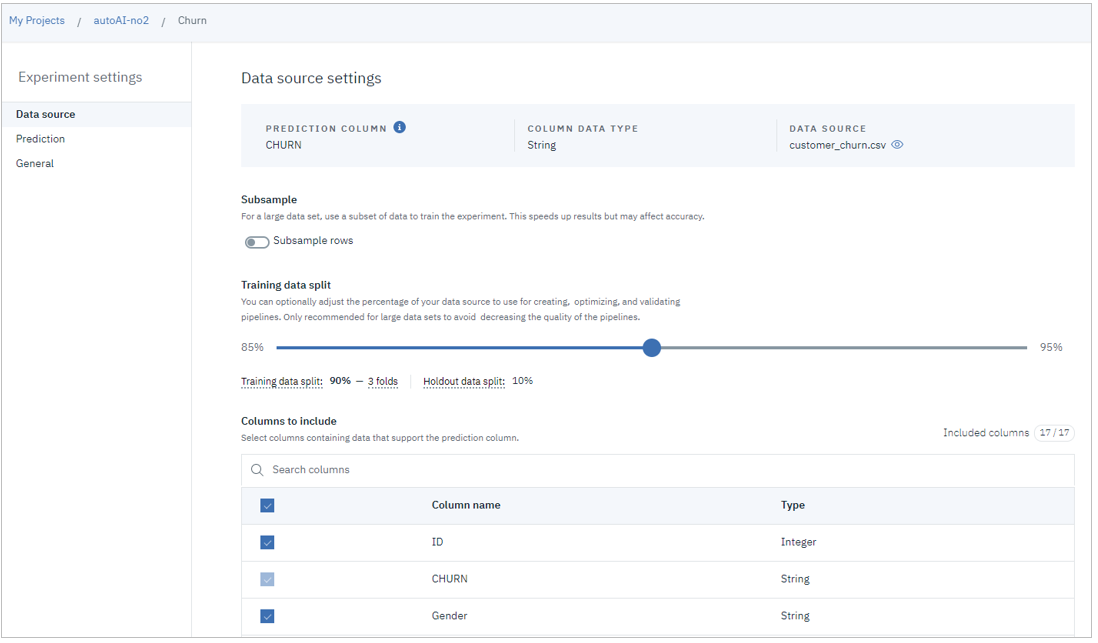
- サンプリング、データのスプリット方法、含めるカラム(デフォルトは全部)
【予測】
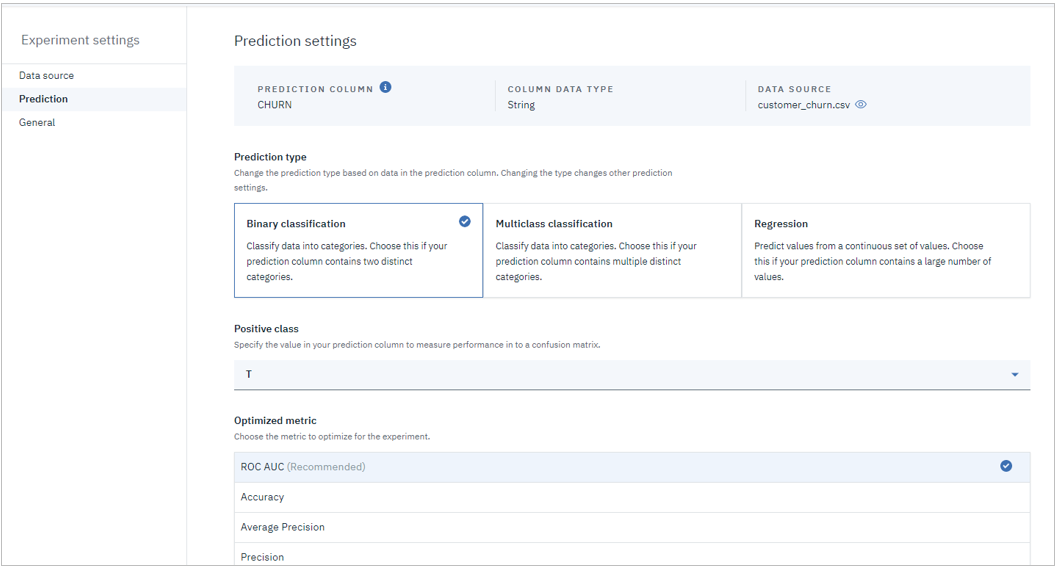
- 予測手法、Trueの値、重視すべき指標
【一般】
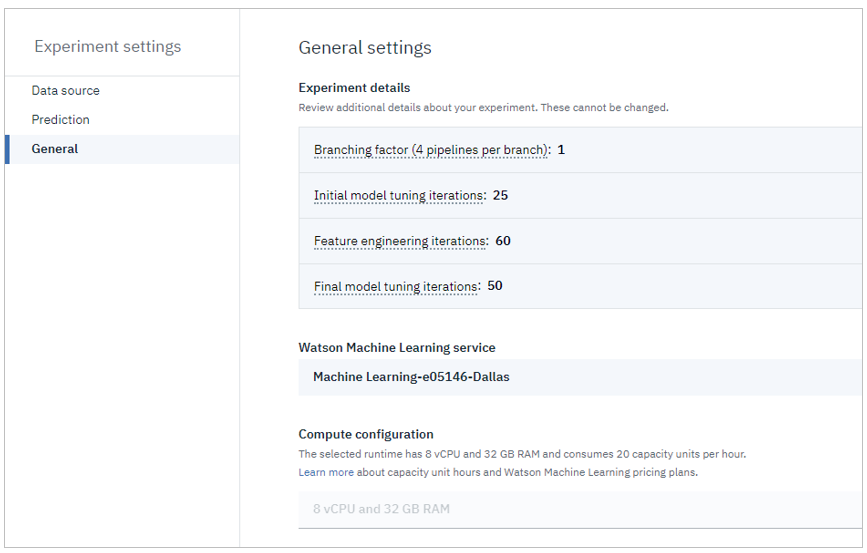
- 手法の明細など。今は参照のみで変更できません。
以上です!(簡単すぎる。。)
 改定履歴
改定履歴
初版から記述を追加/変更した箇所には![]() マークを付けておきますね。
マークを付けておきますね。
| 版 | 日付 | 変更内容 |
|---|---|---|
| 1.0 | 2019-06-05 | 初版公開 |
| 1.1 | 2019-08-06 | テストでFormが使えるようになった点を追記 |
| 1.2 | 2020-04-09 | 一部画面コピーの取り直し |