ここ数年、機械学習を使った研究開発やアプリケーション作成、データ分析がしやすい環境が整ってきました。機械学習フレームワークとしては、scikit-learn や TensorFlow が整備され、各クラウドベンダーからは機械学習用APIや学習/運用用のインフラが提供され、誰でも最先端の機械学習に触れられる時代になりました。
このような環境で自社の競争力を強化するには、機械学習プロセスの最適化による生産性向上が一つの手です。研究開発においては、アルゴリズムの開発をすばやく行わなければ競合に先んじられ、論文を書かれてしまうでしょう。また、アプリケーション作成やデータ分析業務での生産性向上が競争力強化に役立つのは言うまでもありません。
そこで本記事では、機械学習プロセスを自動化する技術であるAutomated Machine Learning(AutoML)の概要について紹介します。具体的には、AutoMLとは何か、なぜ必要か、どんなことができるのか、といった話を説明し、次の行動に繋げられるようにします。記事の構成としては、最初に一般的な機械学習プロセスについて説明し、次にAutoMLについて説明します。最後にAutoMLの将来について述べます。
一般的な機械学習プロセス
本記事をご覧の方はご存知の通り、「機械学習はアルゴリズムにデータを与えるだけで何か良い結果が出る」というものではありません。性能を出すためには多くの作業が必要です。典型的な作業には、データ収集、データクリーニング、特徴エンジニアリング、モデル選択、ハイパーパラメータチューニング、モデルの評価といった作業が含まれます。下のような図を一度は見たことがあるでしょう。

出典: Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science
最近よく使われているディープラーニングでも多くの作業が必要なことには変わりありません。確かに、ディープラーニングではモデルが特徴を学習してくれるため、特徴エンジニアリングの労力は減るかもしれません。しかし、プロセス全体は伝統的な機械学習と同様なので、データの前処理やハイパーパラメータのチューニングが必要なことには変わりません。また、高い性能を出すためには、ニューラルネットワークのアーキテクチャ設計に多くの時間を費やす必要があります。
このように、機械学習には多くの作業が必要で時間がかかることから自動化技術の重要性が増しています。
AutoMLとは?
AutoML(Automated Machine Learning)は、機械学習プロセスの自動化を目的とした技術のことです。機械学習に多くの作業が必要なのは先に述べたとおりですが、AutoMLでは機械学習の各プロセスを自動化してエンジニアの生産性を向上させること、また誰でも機械学習を使えるようになることを目指しています。したがって、究極的な目標は、生データを与えたら、何らかの処理をして、良い結果を出すことだと言えるでしょう。
データサイエンティストの数が急激に増えていることもAutoMLを後押しする背景となっています。以下の図はLinkedInでデータサイエンティストの数を調査した結果です。図を見ると、その数が指数関数的に増えていることがわかります。2010年から2015年の5年間でおよそ2倍、2018年までなら推定で8倍に増えています。
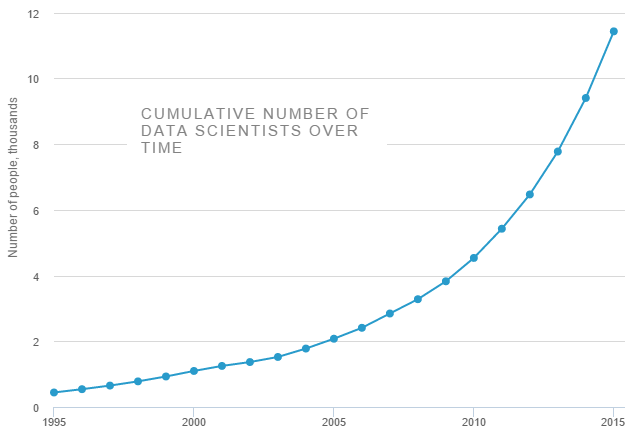
出典: Study Shows That the Number of Data Scientists Has Doubled in 4 Years
データサイエンティストの数が急激に増えたことで、高度な分析をできる人手が足りていないという現状があります。そのような人手不足を補うために、データ分析や機械学習の適応経験が少ないエンジニアを助けるようなツールが必要となってきました。その目的に合致するのがAutoMLというわけです。
ここまでで、AutoMLの重要性が増している理由について述べました。次節からは各プロセスで従来行われている処理とAutoMLによる効率化について見ていきましょう。
AutoMLで行われること
本節では機械学習の各プロセスでAutoMLがどのように生産性向上に寄与するかを説明します。対象とするプロセスは、ハイパーパラメータチューニング、モデル選択、特徴エンジニアリングの3つです。各プロセスについて、何をするプロセスなのか、なぜその処理が必要か、従来どうしていたか、AutoMLではどうしているかの3点から説明します。
出典: Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science
ハイパーパラメータチューニング
ハイパーパラメータチューニングは、ハイパーパラメータを最適な値に調整するプロセスです。各機械学習モデルには様々なハイパーパラメータが存在します。たとえば、ランダムフォレストなら木の深さや数をハイパーパラメータとして持っています。これらのハイパーパラメータはデータから学習するものではなく、モデルを学習させる前に設定しておく必要があります。
ハイパーパラメータチューニングが必要な理由として、機械学習フレームワークのデフォルトのパラメータでは良い性能が出ないことが多いという点を挙げることができます。以下の図は、scikit-learn に含まれる様々な機械学習アルゴリズムについて、ハイパーパラメータをデフォルト値からチューニングしたときに、性能がどれだけ向上したかを表しています。

出典: Data-driven Advice for Applying Machine Learning to Bioinformatics Problems
結果を見ると、アルゴリズムによって改善の度合いは異なりますが、ハイパーパラメータをチューニングすることで性能が向上することがわかります。平均的には正解率で3〜5%程度の改善が見られたという結果になっています。つまり、ハイパーパラメータは明らかにチューニングする価値があり、デフォルトのパラメータを信用し過ぎるべきではないということを示唆しています。
チューニングによって性能向上が見込めるとはいえ、数多くのハイパーパラメータを手動でチューニングするのは骨が折れる作業です。たとえば、ハイパーパラメータ数が5個あり、各ハイパーパラメータに対して平均で3つの値をテストするのだとすれば、組合せは3の5乗(=273)通り存在します。これらすべての組み合わせに対して手動でチューニングをするのは非生産的な行為です。また、以下の図のようにモデルが複雑化すれば、手動でのチューニングは現実的ではなくなります。
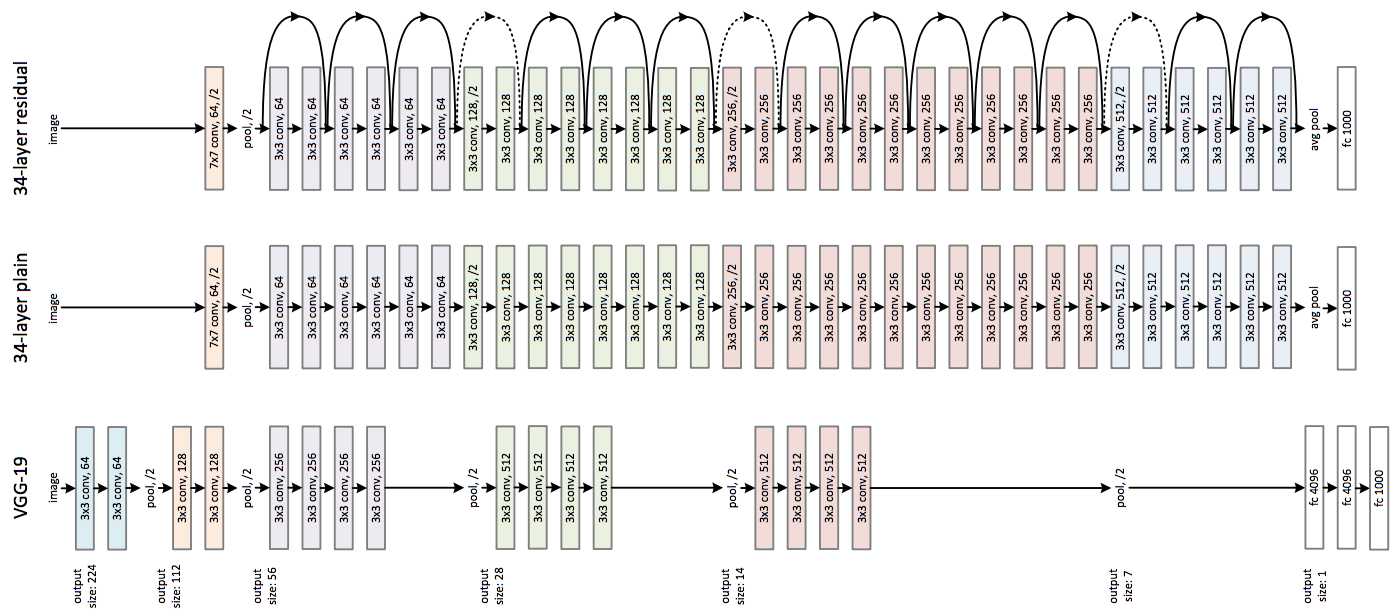
出典: Deep Residual Learning for Image Recognition
そこで、AutoMLでは従来人手で行っていたハイパーパラメータチューニングを自動化することを考えます。自動化により、チューニングの効率が向上するだけでなく、人が直感的に決めたパラメータによるバイアスを取り除くことにも繋がります。具体的には以下のような手法が使われています。
- グリッドサーチ(GridSearch)
- ランダムサーチ(RandomSearch)
- ベイズ最適化(Bayesian Optimization)
このうち、最もよく使われているのはグリッドサーチとランダムサーチでしょう。それらの違いは以下の図のように表されます。

出典: Random Search for Hyper-Parameter Optimization
グリッドサーチは、伝統的によく使われているハイパーパラメータチューニングの手法で、あらかじめ各ハイパーパラメータの候補値を複数設定して、すべての組合せを試すことでチューニングします。たとえば、$C$ と $\gamma$ という2つのパラメータがあり、それぞれ、$C \in$ {10, 100, 1000}, $\gamma \in$ {0.1, 0.2, 0.5, 1.0}という候補値を設定した場合、3x4=12の組み合わせについて試します。
一方、ランダムサーチはパラメータに対する分布を指定し、そこから値をサンプリングしてチューニングする手法です。たとえば、グリッドサーチでは $C$ に対して $C \in$ {10, 100, 1000} のような離散値を与えていたのに対して、ランダムサーチでは、パラメータ $\lambda=100$ の指数分布のような確率分布を与え、そこから値をサンプリングします。少数のハイパーパラメータが性能に大きく影響を与える場合に効果的な手法です。
グリッドサーチやランダムサーチの課題として、見込みのないハイパーパラメータに時間を費やしがちな点を挙げることができます。この原因としては、グリッドサーチやランダムサーチでは以前に得られた結果を利用していない点を挙げられます。
では、以前に得られた結果を利用すると、どのようにハイパーパラメータを選べるのでしょうか? 以下の図を御覧ください。この図はランダムフォレストのハイパーパラメータの一つであるn_estimatorの数を変化させたときの性能を示しています。スコアの値が高い方が性能が良いのだとすれば、n_estimatorが200近辺を探索するより、800近辺を探索した方が効率が良さそうな事がわかると思います。
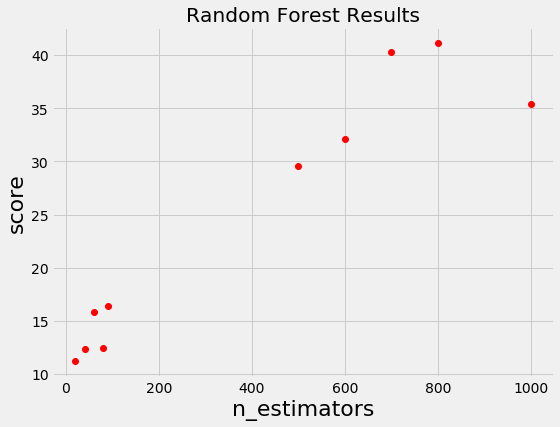
出典: A Conceptual Explanation of Bayesian Hyperparameter Optimization for Machine Learning
最近使われるようになってきたベイズ最適化を用いたハイパーパラメータチューニングは、以前の結果を使って次に探索するハイパーパラメータを選ぶ手法です。これにより、有望そうなところを中心にハイパーパラメータを探索することができます。人間が行う探索に近いことをしているとも言えるでしょう。ディープラーニングを含む機械学習のモデルに対して、比較的良いハイパーパラメータを探索できることが知られています。
ベイズ最適化の仕組みについてこれ以上詳しく解説するとこの記事では終わらないので、最後に最適化に使えるソフトウェアを紹介しましょう。ここでは以下のソフトウェアを挙げました。
GridSearchCVとRandomizedSearchCVはご存知 scikit-learn に組み込まれているクラスです。scikit-learn を使っている場合には一番使いやすいのではないかと思います。 scikit-learn に限らず使いたいなら、ParameterGrid を使うのが選択肢に挙がると思います。ParameterGrid を使うことでハイパーパラメータの組み合わせを生成することができます。
hyperopt はランダムサーチとベイズ最適化によるハイパーパラメータチューニングを行えるPythonパッケージです。ベイズ最適化の方はTPEと呼ばれるアルゴリズムをサポートしています。hyperas はKeras用のhyperoptラッパーです。私のようにKerasをよく使うユーザにはこちらの方が使いやすいと思います。
モデル選択
モデル選択は、データを学習させるのに使う機械学習アルゴリズムを選ぶプロセスです。モデルにはSVMやランダムフォレスト、ニューラルネットワークなど多くの種類があります。その中から、解きたい問題に応じて選びます。たとえば、解釈性が重要な場合は決定木などのモデルが選ばれるでしょうし、とにかく性能を出したいという場合はニューラルネットワークが候補になるでしょう。
モデル選択が必要な理由として、すべての問題に最適な機械学習アルゴリズムは存在しないという点を挙げることができます。以下の図は165個のデータセットについて、モデル間の性能の勝敗について検証した結果を示しています。左側の列はモデルの名前が書かれており、良い結果となったモデルから順に並んでいます。

出典: Data-driven Advice for Applying Machine Learning to Bioinformatics Problems
結果を見ると、Gradient Tree Boosting(GTB)やランダムフォレスト、SVMは良く、逆にNBは悪いことがわかります。また、ほとんどの場合においてGradient Tree Boostingは良い結果なのですが、NBでも1%のデータセットではGTBに勝っているという結果になっています。ちなみに、足しても100%にならないのは、少なくとも正解率で1%以上上回った場合を勝利としているからです。
要するに何が言いたいかというと、確かにGTBやRandomForestは良い結果を出しますが、すべての問題で勝てる最適なアルゴリズムは存在しないということです。これは機械学習を行う上で重要な点で、機械学習を使って問題を解く際には、多くの機械学習アルゴリズムについて考慮する必要があるということをこの実験結果は示唆しています。
ただ、実際のプロジェクトでは多くの機械学習アルゴリズムを考慮できているとはいい難い状況です。その原因の一つには、人間のバイアスが関係しています。たとえば、「GTBは毎回良い結果を出すからこれを使っておけばいいんだ」というのは一つのバイアスです。確かにそれはたいていの場合正しいかもしれません。しかし、上図が示すように、実際には人間のバイアスは悪い方向に働くこともあるのです。
人間のバイアスを軽減させるために有効な手の一つとして、データセットの特徴に応じて選ぶモデルを決定する仕組みを構築しておく手があります。以下は scikit-learn が公開している機械学習アルゴリズムを選択するためのチートシートです。ただ、この方法にもシートを作成した人のバイアスが入っている、多くのアルゴリズムを考慮できていないといった問題があります。
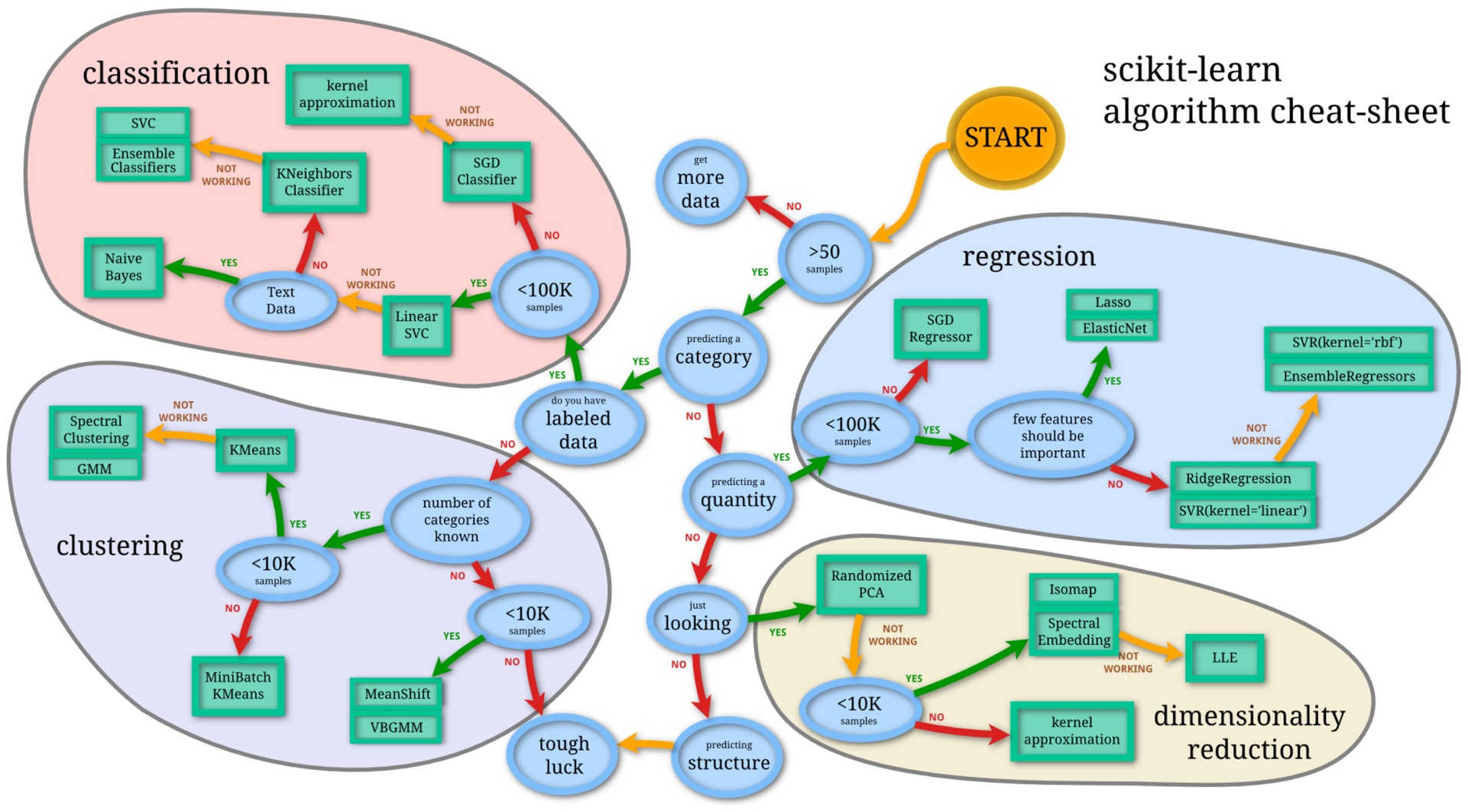
出典: Choosing the right estimator
そういうわけでAutoMLでは機械学習アルゴリズムの選択を自動的に行うことを考えます。モデル選択を自動化することにより、人間のバイアスを排除しつつ、様々なモデルを考慮することができます。モデル選択についてはハイパーパラメータチューニングと切り離せない話なので、話としてはここまでにしておきます。
お話だけだと退屈なので、ここでソフトウェアを紹介しましょう。モデル選択の機能を組み込んだソフトウェアは商用・非商用問わずに数多くありますが、今回はその中から TPOT を紹介します。
TPOT は、scikit-learnライクなAPIで使えるAutoMLのツールです。機能としてはモデル選択とハイパーパラメータチューニングを行ってくれます。また、タスクとしては分類と回帰を解くことができます。
scikit-learnを使ったことがある人であれば、TPOTを使うのは非常に簡単です。たとえば、分類問題を解く場合は、TPOTClassifierをインポートし、データを与えて学習させるだけです。以下ではMNISTを学習させています。
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
学習が終わると以下に示すように最も良かったパイプラインとそのスコアを表示します。今回の場合、入力にPolynomialFeaturesを適用した後、モデルにLogisticRegressionを使うのが最も良い結果になりました。ハイパーパラメータが設定されていることも確認できます。スコア自体はよくありませんでしたが、手軽さは確認できたかと思います。
Generation 1 - Current best internal CV score: 0.9651912264496657
Generation 2 - Current best internal CV score: 0.9822200910854291
Generation 3 - Current best internal CV score: 0.9822200910854291
Generation 4 - Current best internal CV score: 0.9822200910854291
Generation 5 - Current best internal CV score: 0.9822200910854291
Best pipeline: LogisticRegression(PolynomialFeatures(input_matrix, degree=2, include_bias=False, interaction_only=False), C=15.0, dual=True, penalty=l2)
0.9844444444444445
ニューラルアーキテクチャサーチ
モデル選択と関係する話として、最近よく話題になるニューラルアーキテクチャサーチ(Neural Architecture Search: NAS)について述べておきましょう。NASもAutoMLの一部と捉えられます。ニュースでも大きく取り上げられ、New York Timesでは「AIを構築できるAIを構築する」(Building A.I. That Can Build A.I.)というタイトルで記事が書かれています。

ニューラルアーキテクチャサーチとは、ニューラルネットワークの構造設計を自動化する技術です。実際には、ニューラルネットワークを使ってネットワークアーキテクチャを生成し、ハイパーパラメータチューニングをしつつ学習させています。
基本的な枠組みは以下の図のようになっています。まず、コントローラと呼ばれるRNNがアーキテクチャをサンプリングします。次に、サンプリングした結果を使って、ネットワークを構築します。そして、構築したネットワークを学習し、検証用データセットに対して評価を行います。この評価結果を使って、より良いアーキテクチャを設計できるようにコントローラを更新します。以上の操作を繰り返し行うことで良いアーキテクチャを探索しています。
 出典: [Neural Architecture Search with Reinforcement Learning](http://rll.berkeley.edu/deeprlcoursesp17/docs/quoc_barret.pdf)
出典: [Neural Architecture Search with Reinforcement Learning](http://rll.berkeley.edu/deeprlcoursesp17/docs/quoc_barret.pdf)
ニューラルネットワークの設計を自動化したいのにはいくつかの理由があります。その一つとしてニューラルネットワークのアーキテクチャを設計するのは高度な専門知識が必要で非常に難しい点を挙げられます。よいアーキテクチャを作るためには試行錯誤が必要で、これには時間もお金もかかります。これでは活用できるのが少数の研究者やエンジニアだけに限られてしまいます。
このような理由からニューラルアーキテクチャサーチで設計から学習まで自動化しようという話になりました。NASによって、アーキテクチャの設計、ハイパーパラメータチューニング、学習を自動化することができ、誰にでも利用できるようになります。これはつまり、ドメインエキスパートによるニューラルネットワークの活用に道が開かれることを意味しています。
そんなNASの課題としては計算量の多さを挙げられます。たとえば、Neural Architecture Search with Reinforcement Learningでは、アーキテクチャを探索するのに 800 GPUで28日間かかっています。また、NASNetでは、500 GPU を使用して4日間かかっています。これでは一般の研究者や開発者が利用するのは現実的ではありません。
高速化の手段の一つとして使われるのが転移学習です。Efficient Neural Architecture Search via Parameter Sharingではすべての重みをスクラッチで学習させるのではなく、学習済みのモデルから転移学習させて使うことで高速化をしています。その結果、学習時間は 1 GPU で半日までに抑えられています。
最後にNASを提供しているサービスとOSSについて紹介します。
NASを提供するサービスとして最も有名なのはGoogleの Cloud AutoML でしょう。Cloud AutoMLでは画像認識、テキスト分類、翻訳に関して学習させることができます。データさえ用意すれば、誰でも簡単に良いモデルを作って使えるのが特徴です。一方、お金が結構かかるのと、学習したモデルをエクスポートできないのが欠点です。
NASに使えるOSSとしてはAuto-Kerasがあります。Auto-Kerasは、scikit-learnライクなAPIで使えるオープンソースのAutoMLのツールです。こちらは、Texas A&M大学のDATA Labとコミュニティによって開発されました。論文としては、2018年に発表された「Auto-Keras: Efficient Neural Architecture Search with Network Morphism」が基となっています。目標としては、機械学習の知識のないドメインエキスパートでも簡単にディープラーニングを使えるようにすることです。
Auto-Kerasもscikit-learnを触ったことがある人であれば使うのは簡単です。以下のようにして分類器を定義し、fitメソッドを使って学習させるだけです。以下のコードはAuto-KerasにMNISTを学習させるコードです。fitメソッドで学習をして最適なアーキテクチャを探索します。その後、final_fitで探索を終えて得られた最適なアーキテクチャで学習し直します。
import autokeras as ak
from keras.datasets import mnist
if __name__ == '__main__':
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape + (1,))
x_test = x_test.reshape(x_test.shape + (1,))
clf = ak.ImageClassifier(verbose=True)
clf.fit(x_train, y_train, time_limit=12 * 60 * 60)
clf.final_fit(x_train, y_train, x_test, y_test, retrain=True)
print(clf.evaluate(x_test, y_test))
学習を始めると以下のような表示がされます。Father Modelに親モデルのIDが書いてあり、その隣に変更点が書いてあります。そして、学習が終わるとその結果がLossとMetric Valueに表示されます。このモデルの場合は、正解率で0.9952だったことを表しています。
+----------------------------------------------+
| Training model 8 |
+----------------------------------------------+
+--------------------------------------------------------------------------+
| Father Model ID | Added Operation |
+--------------------------------------------------------------------------+
| 6 | to_deeper_model 68 Conv2d(512, 512, 5, 1) |
+--------------------------------------------------------------------------+
Saving model.
+--------------------------------------------------------------------------+
| Model ID | Loss | Metric Value |
+--------------------------------------------------------------------------+
| 8 | 0.07076152432709933 | 0.9952 |
+--------------------------------------------------------------------------+
特徴エンジニアリング
特徴エンジニアリング(Feature Engineering)は、機械学習アルゴリズムがうまく学習できるような特徴を作成するプロセスのことです。特徴エンジニアリングは機械学習を使ったシステムを作る際の基礎であり、ここで良い特徴を得られれば、機械学習アルゴリズムでも良い性能を出すことができます。ただし、良い特徴を得るのは非常に難しく、時間のかかる部分でもあります。
機械学習における特徴(Feature)とは、観察される現象の測定可能な特性のことです。以下の例は、タイタニック号の生存者情報を含むデータセットの一部です。各列は、分析に使用できる測定可能なデータである年齢(Age)、性別(Sex)、料金(Fare)などを含みます。これらがデータセットの特徴量です。

特徴エンジニアリングが重要な理由として、良い特徴を得ることで機械学習アルゴリズムの予測性能が大きく変わる点を挙げることができます。たとえば、タイタニック号のデータセットの例で言うなら、乗客名をそのまま特徴として使っても良い性能は得られないでしょう。しかし、名前から敬称(Mr. Mrs. Sir.など)を抽出して使えば性能向上に役立つでしょう。なぜなら、社会的地位の高さや既婚者か否かといった情報は救命ボートに乗る際に考慮されただろうと考えられるからです。
伝統的に、特徴エンジニアリングは人間によって行われてきましたが、それには2つの問題点がありました。一つは良い特徴を思いつくのは難しいという点です。良い特徴を思いつくためにはドメインの知識が必要な場合もあり、一筋縄ではいきません。もう一つは、時間がかかるという点です。単に思いつくだけではなく、それを検証することも含めると、特徴エンジニアリングは非常に時間のかかる作業です。実際に機械学習のどの部分で時間がかかるかをデータサイエンティストに尋ねると特徴エンジニアリングは上位に位置します。
AutoMLでは、人間によって行われてきた特徴エンジニアリングを自動化します。これにより、先に述べた2つの問題を軽減することができます。以下では実際にAutoMLにおいて特徴エンジニアリングがどのように行われるのかについて説明します。ここでは、AutoMLのサービスである DataRobot での自動化と、特徴エンジニアリングを自動化するためのツールである featuretools を例にとって説明しましょう。
まずはAutoMLのサービスである DataRobot ではどうしているかを紹介しましょう。以下の述べる内容は、DataRobotのブログ記事「Automated Feature Engineering」に基づいています。2018年6月28日の記事ですが内容が古くなっている可能性はありますので、その点はご留意ください。
DataRobotではエキスパートシステムを構築することで特徴エンジニアリングを自動化しています。具体的には以下のようなことをしています。
- 特徴の生成
- 特徴エンジニアリングが必要なモデルを知る
- 各モデルに有効な特徴エンジニアリングの種類を知る
- システマティックにモデルを比較して、特徴エンジニアリングとモデルの最も良い組み合わせを知る
これらの操作をDataRobotでは model blueprint を使って行っています。ここで、model blueprint とは、こちらの記事によると、前処理、特徴エンジニアリング、学習、チューニングといった処理のシーケンスのことのようです。以下が model blueprint の例です。

出典: Automated Feature Engineering
この model blueprint では、DataRobotのシステムはL2正則化を入れたロジスティック回帰に対するデータを用意しています。具体的に行っている特徴エンジニアリングとしては、One-Hotエンコーディング、欠損値の補完、標準化の3つです。
より複雑な例としては以下の Gradient Boosted Greedy Treesに対する model blueprint があります。
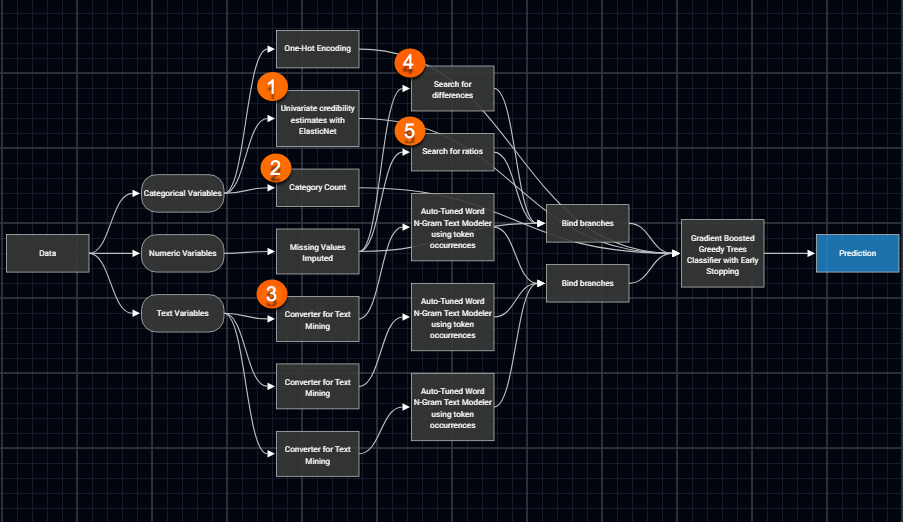
出典: Automated Feature Engineering
これまでのところをまとめましょう。まず、DataRobotでは前処理からチューニングまでのパイプラインを定義したmodel blueprintが多数用意されていいます。それらのmodel blueprintをデータに対して適用し、その結果を比較して最も良いモデルと特徴エンジニアリングの組み合わせを決めているということをしているようです。
DataRobotの方法も良いのですが、作り込みが必要で真似しにくい感じのやり方なので featuretools についても紹介しておきます。featuretools はPython製のオープンソースの特徴エンジニアリング自動化ツールです。featuretools を使うことで特徴を自動的に生成することができます。
featuretools では Deep Feature Synthesis(DFS) と呼ばれる方法で新たな特徴を生成しています。DFSでは primitive と呼ばれる関数を使ってデータの集約と変換を行います。primitive の例としては、列の平均や最大値を取る関数を挙げることができます。また自分で定義した関数を primitive として使うこともできます。
百聞は一見にしかずということで、実際にやってみましょう。まずはデモ用のカスタマートランザクションデータを生成します。
>>> import featuretools as ft
>>> es = ft.demo.load_mock_customer(return_entityset=True)
>>> es
Entityset: transactions
Entities:
transactions [Rows: 500, Columns: 5]
products [Rows: 5, Columns: 2]
sessions [Rows: 35, Columns: 4]
customers [Rows: 5, Columns: 3]
Relationships:
transactions.product_id -> products.product_id
transactions.session_id -> sessions.session_id
sessions.customer_id -> customers.customer_id
生成されたデータには4つのテーブル(transactions, products, sessions, customers)と3つの関係が定義されています。このうち、customersテーブルを対象にprimitiveを適用して特徴を生成します。以下がそのコードです。
>>> feature_matrix, features_defs = ft.dfs(entityset=es, target_entity="customers")
>>> feature_matrix.head(5)
zip_code COUNT(sessions) ... MODE(sessions.MONTH(session_start)) MODE(sessions.WEEKDAY(session_start))
customer_id ...
1 60091 10 ... 1 2
2 02139 8 ... 1 2
3 02139 5 ... 1 2
4 60091 8 ... 1 2
5 02139 4 ... 1 2
features_defsから以下のような特徴を自動的に生成していることがわかります。 ここで、MODEやSUM、STDというのが primitive です。つまり、SUM(transactions.amount)はtransactionsテーブルのamount列の合計を特徴として加えるということを意味しています。
>>> pprint(features_defs)
[<Feature: zip_code>,
<Feature: COUNT(sessions)>,
<Feature: NUM_UNIQUE(sessions.device)>,
<Feature: MODE(sessions.device)>,
<Feature: SUM(transactions.amount)>,
<Feature: STD(transactions.amount)>,
<Feature: MAX(transactions.amount)>,
<Feature: SKEW(transactions.amount)>,
<Feature: MIN(transactions.amount)>,
<Feature: MEAN(transactions.amount)>,
<Feature: COUNT(transactions)>,
...
<Feature: MODE(sessions.WEEKDAY(session_start))>]
featuretoolsではこのように特徴を生成することで、特徴エンジニアリングにかかる時間を軽減することができます。
AutoMLのソフトウェア
AutoMLのための数多くのソフトウェアやサービスがすでに公開されています。ここでは、OSSと非OSSという2つの区分で分けると以下に列挙するソフトウェアがあります。
OSS
非OSS
AutoMLの将来
最後はAutoMLの将来についての私見です。まず、AutoMLは将来的にはデータクリーニングのプロセスも扱えるようになるのではないかと考えています。たとえば、テキストのような非構造化データを分析にすぐに使えるようにテーブルデータに変換するといったことです。次に、大規模データにスケールするような方法が出てくるでしょう。Cloud AutoMLを試してみるとわかるのですが、サンプルの小さなデータに対してでさえ計算時間が結構かかります。将来的にはいわゆるビッグデータに対しても使えるようになるでしょう。最後に、性能が人間を上回るようになるでしょう。現在でも一部のデータセットでは人間に匹敵する性能を出していますが、将来的には人間が考えつかないような特徴であるとかネットワークアーキテクチャを生み出せるようになるでしょう。そういう意味では、Alpha Goに似たところはあるかもしれません。
おわりに
ここ数年で最先端の機械学習に触れやすい環境ができてきました。このような環境で競争力を強化するには、機械学習プロセスの最適化が一つの手です。本記事では、機械学習プロセスを自動化する技術であるAutoMLの概要について紹介しました。本記事で紹介した内容以外にも、環境構築やモデルのデプロイといった部分の効率化も必要ですが、そのへんはまたの機会にしましょう。本記事が皆様のお役に立ったのであれば幸いです。
私のTwitterアカウントでも機械学習や自然言語処理に関する情報をつぶやいています。
@Hironsan
この分野にご興味のある方のフォローをお待ちしています。
参考資料
特徴エンジニアリング
- Why Automated Feature Engineering Will Change the Way You Do Machine Learning
- Deep Feature Synthesis: How Automated Feature Engineering Works
- Automated Feature Engineering
ニューラルアーキテクチャサーチ
- Neural Architecture Search with Reinforcement Learning
- Learning Transferable Architectures for Scalable Image Recognition
- Efficient Neural Architecture Search via Parameter Sharing
- Everything you need to know about AutoML and Neural Architecture Search
- Understanding AutoML and Neural Architecture Search
- An Opinionated Introduction to AutoML and Neural Architecture Search
- What do machine learning practitioners actually do?
ハイパーパラメータチューニング