TL;DR
- AutoML TableがGoogle Cloud Next'19で発表されたよ
- もう触れるみたいなので、KaggleのHousePricePredictionで試してみたよ、手軽だったよ
- 一応LightGBMと比較してみたら、チューニングすれば良い成績を出せたよ
前置き
Google Cloud Next'19でAutoMl Tableが発表されましたね〜

LPがいつもすこ
早速使えるようなので(現在はβ版)、使ってみました。題材はKaggleから取ってきます。
Titanicでやろうとしてみた
Kaggleのいつものやつ、ということでTItanicでやろうとしてみました。→ Kaggle Titanic
csvを取得してきて、BigQueryにテーブルとしてインポートします。GCSにcsv直接置くのでもよいんですが、今回は AutoMl Table なので、テーブルにしていきたいですよね(?)
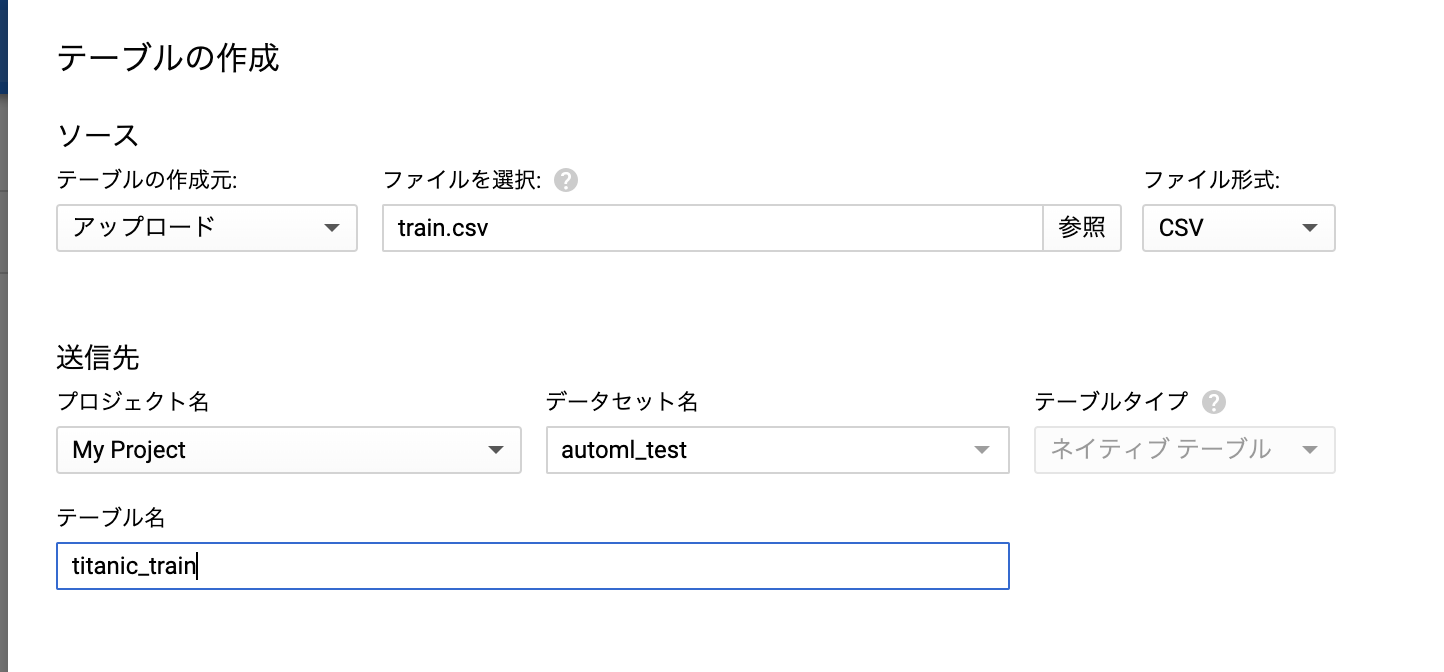
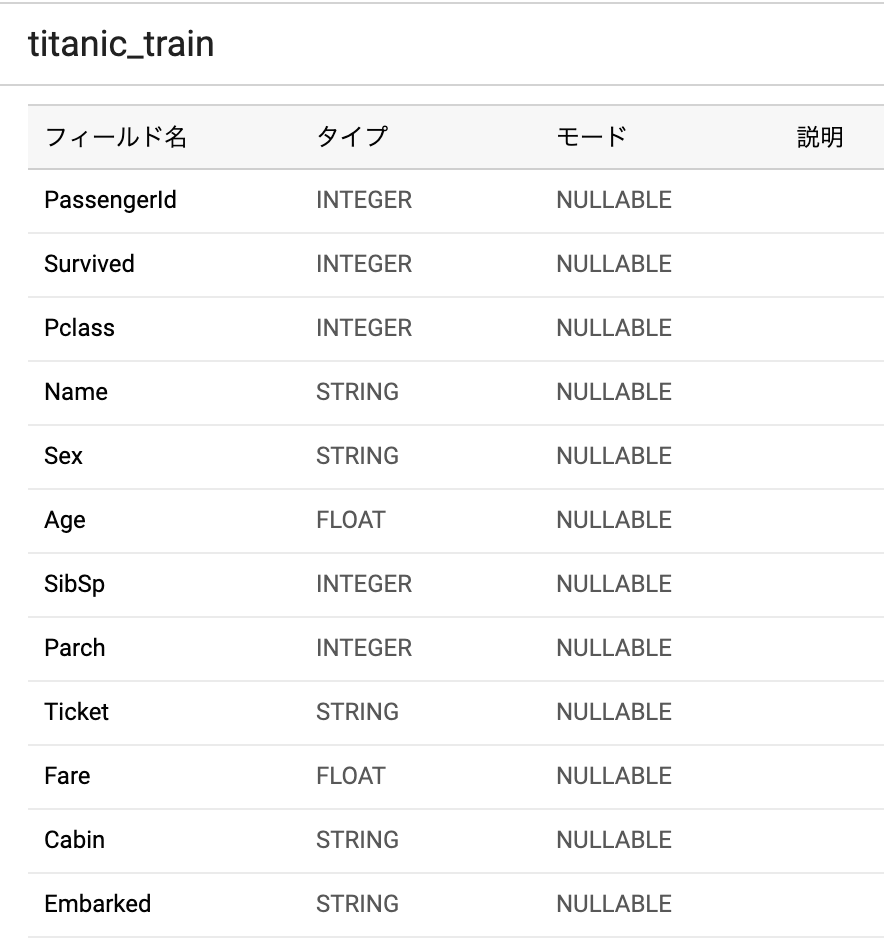
カラムはこんな感じです
automl-tables のリンクからコンソールに飛ぶと以下のような画面になります。
さっそくデータセットを作成していきましょう。
しかしここで新たな事実が発覚。
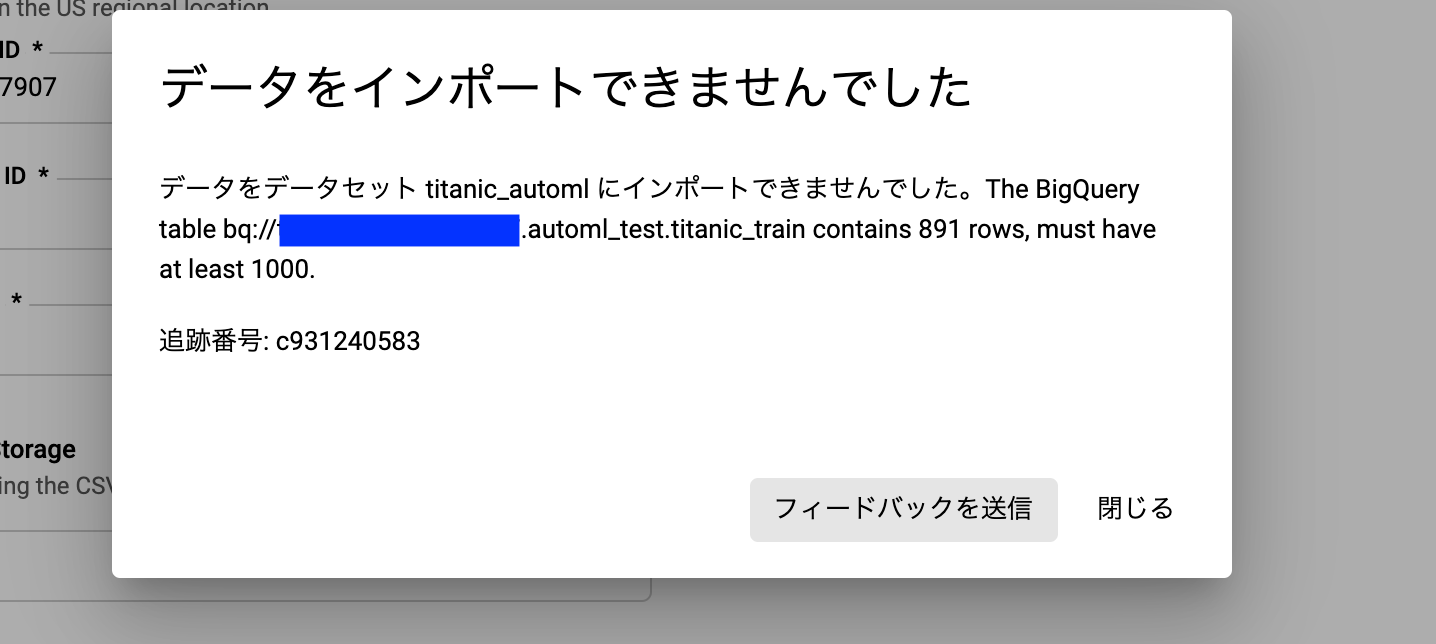
最低1000行ないとトレーニングできない...
違うのにしましょう。
House Price Predictionでやる
Titanicと同じくらい初心者向けで有名なのでこちらのHousePricePredictionです。
House Prices: Advanced Regression Techniques | Kaggle
こっちはデータ数が1400件で制限をクリアしているのでこちらでやっていきます。
データの準備
同じようにcsvをダウンロードしてきてBigQueryに用意します。
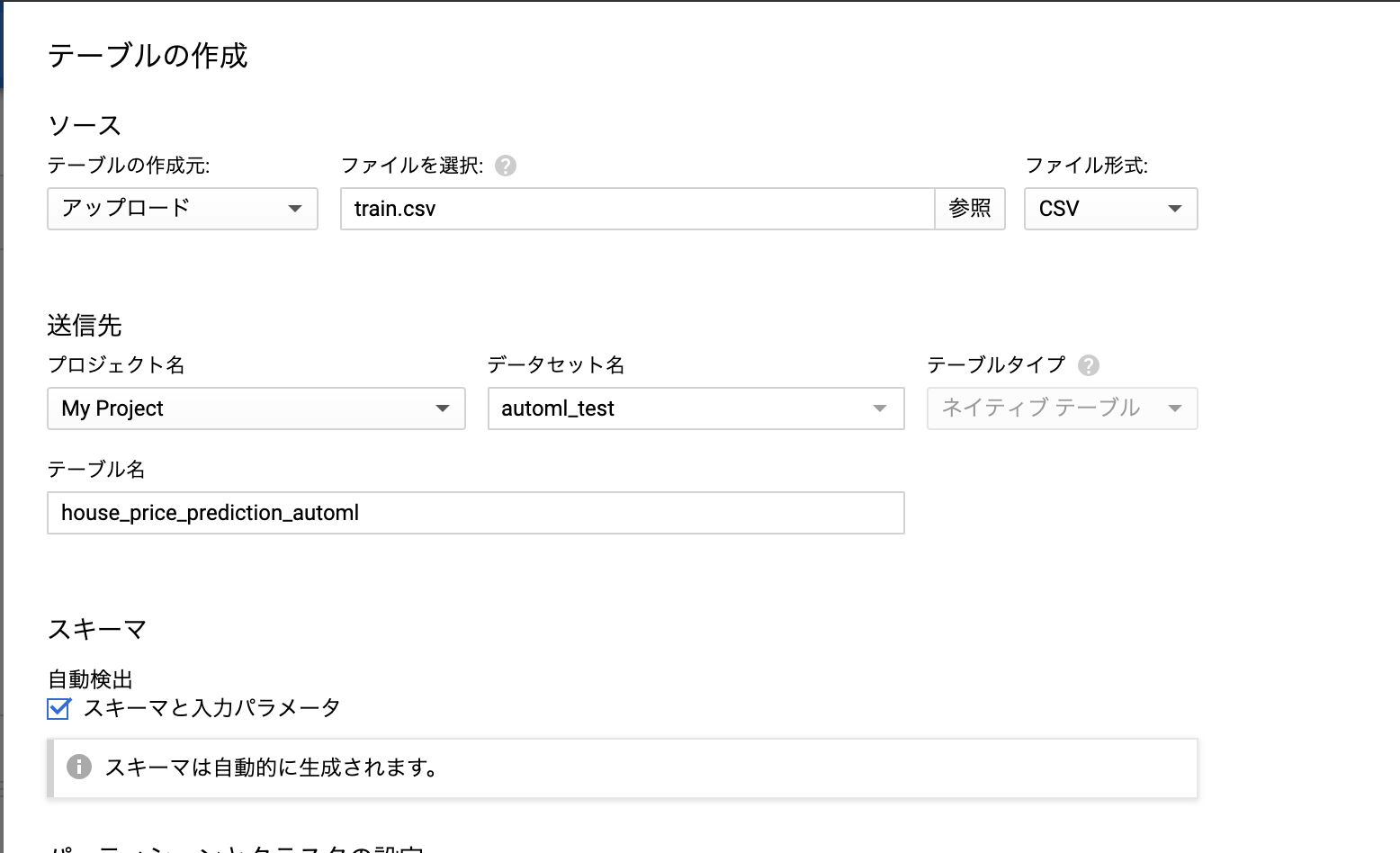
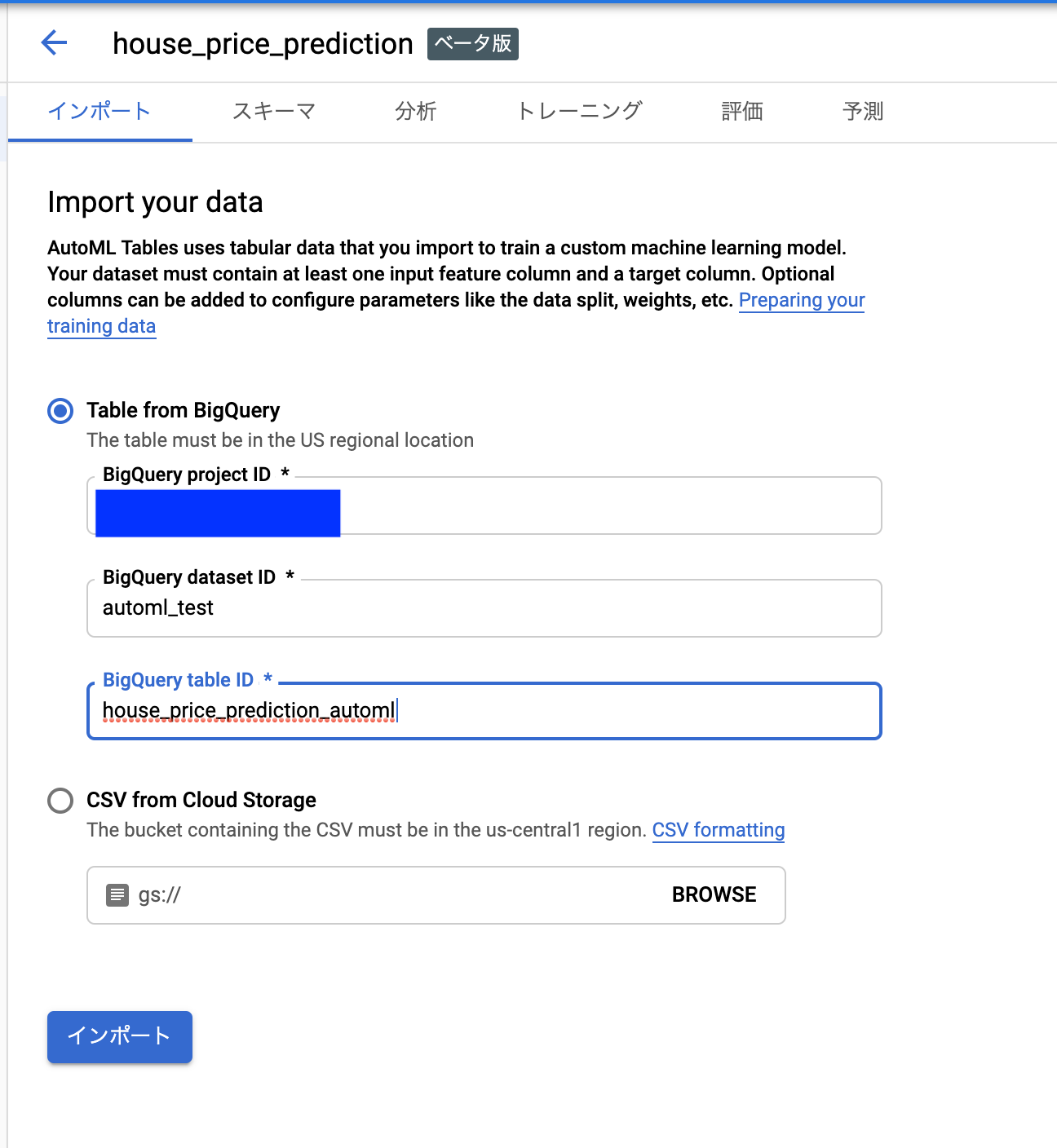
必要な情報を入力していってポチポチしていけばデータセット作成できます。かんたん。
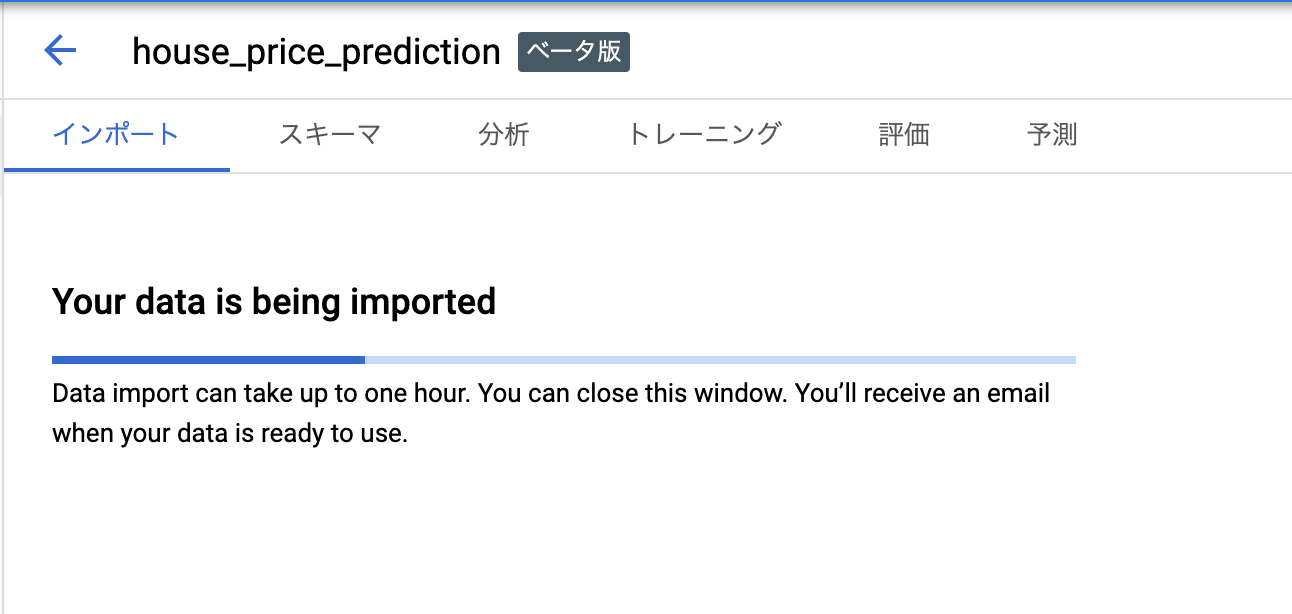
この画面になったら一旦待ちです。と思いきや
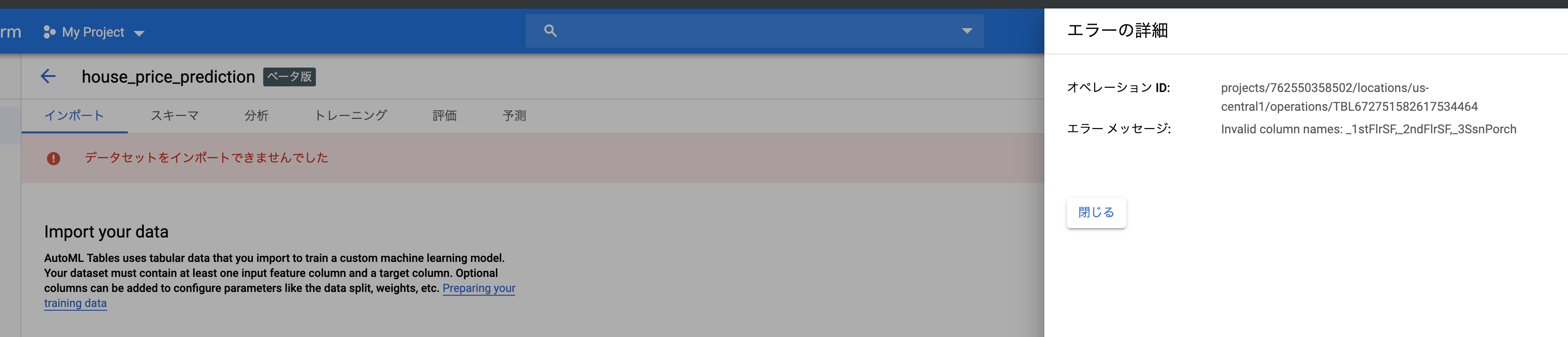
なんかの理由でインポートできない...
数字から始まるカラムがあると悪いみたいなので、 1stとかなってるやつを変えておきます。(1stFlrSF,2ndFlrSF,3SsnPorch→firstFlrSF,secondFlrSF,threeSsnPorch)
さらにnullがある状態を避けておきたいので、あらかじめnaを埋めておいたりします。こちらのkernelを参考にどうぞ。
Easy prediction using lightgbm model | Kaggle
これをやった上で、改めてBigqueryのテーブルをimportしましょう。ここまで何回も読み込むくらいなら、小さいデータならGCSでやるほうがいいのでは...?と思い始めてきましたがめげません。 AutoML Tables なので(?)
スキーマ確認と目的変数決定
で、無事にインポートできると次のような画面になります。ここではスキーマを確認します。
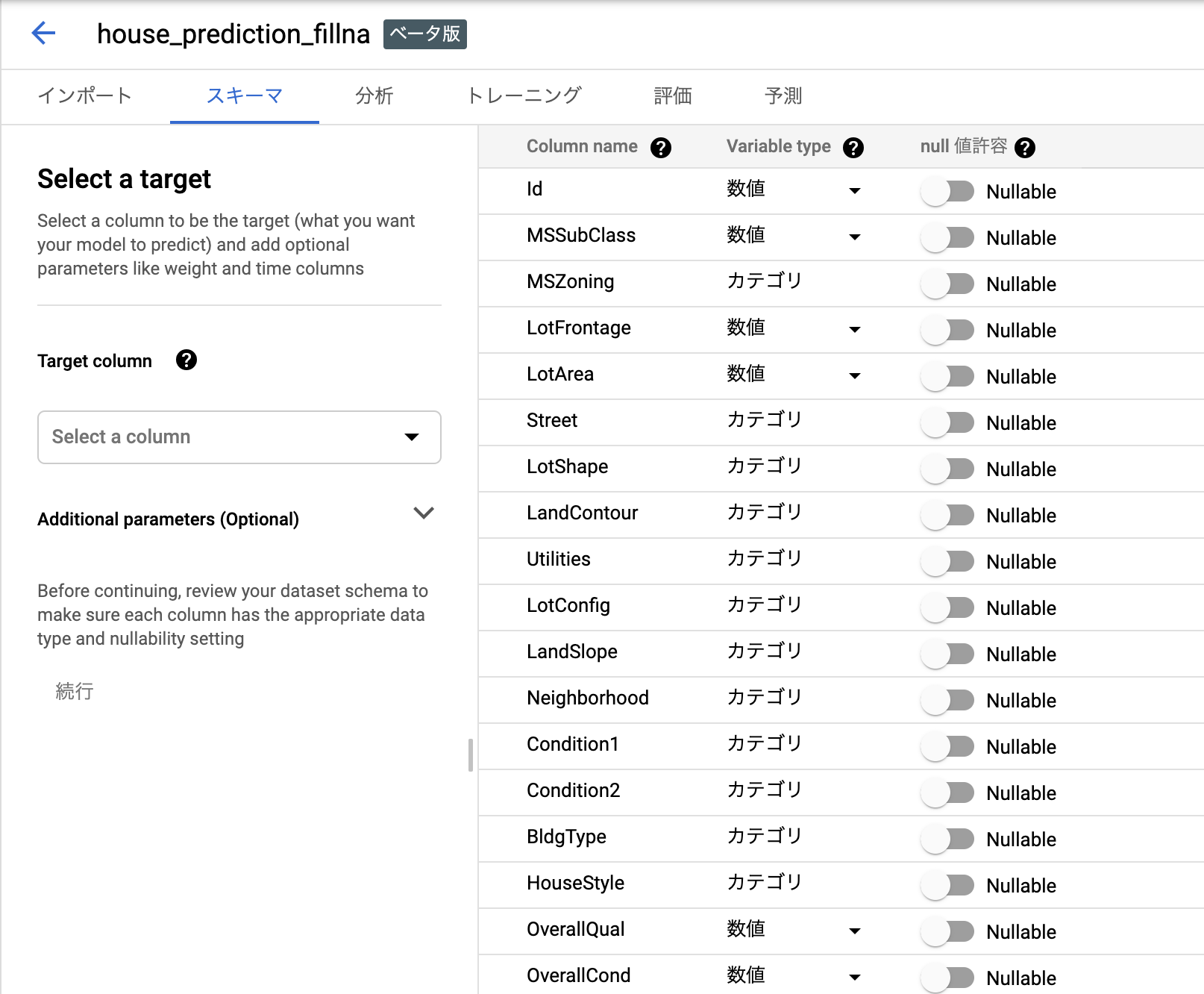
Nullableかどうかはすごく重要です。今回は前もってNAを埋めておりましたので考える必要ないですが、ここが間違ってて実はNULL入るよー入らないよーがあったりすると、予測時にエラーになってしまいます。運用のことを考えるとあやしいやつは全部NULLABLEにするほうがいいのかもですね。
今回は全てnull許容なしで大丈夫。
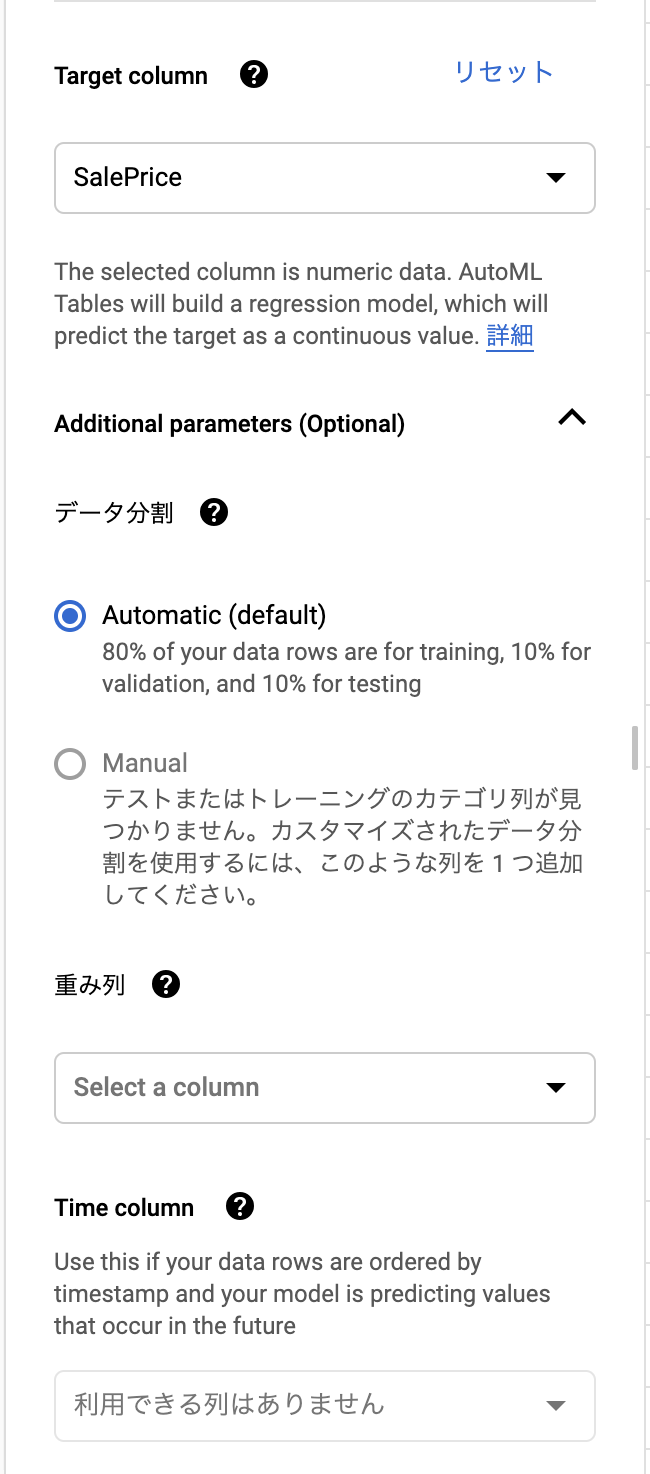
目的変数は横のパネルで決定します。このとき、各レコードごとに重みを決めたいならそのカラムがあれば重みとして加えられるようです。
更に時間に関わるカラムがあればそれを使うことでリークを防ぐようにできるっぽいです。過去のデータで未来を予測するvalidation setにしてくれてそうな気がする。
分析タブ
以上を終えてボタンを押せば分析タブに移行します。各種指標を計算してくれているみたいで、少し時間がかかります。
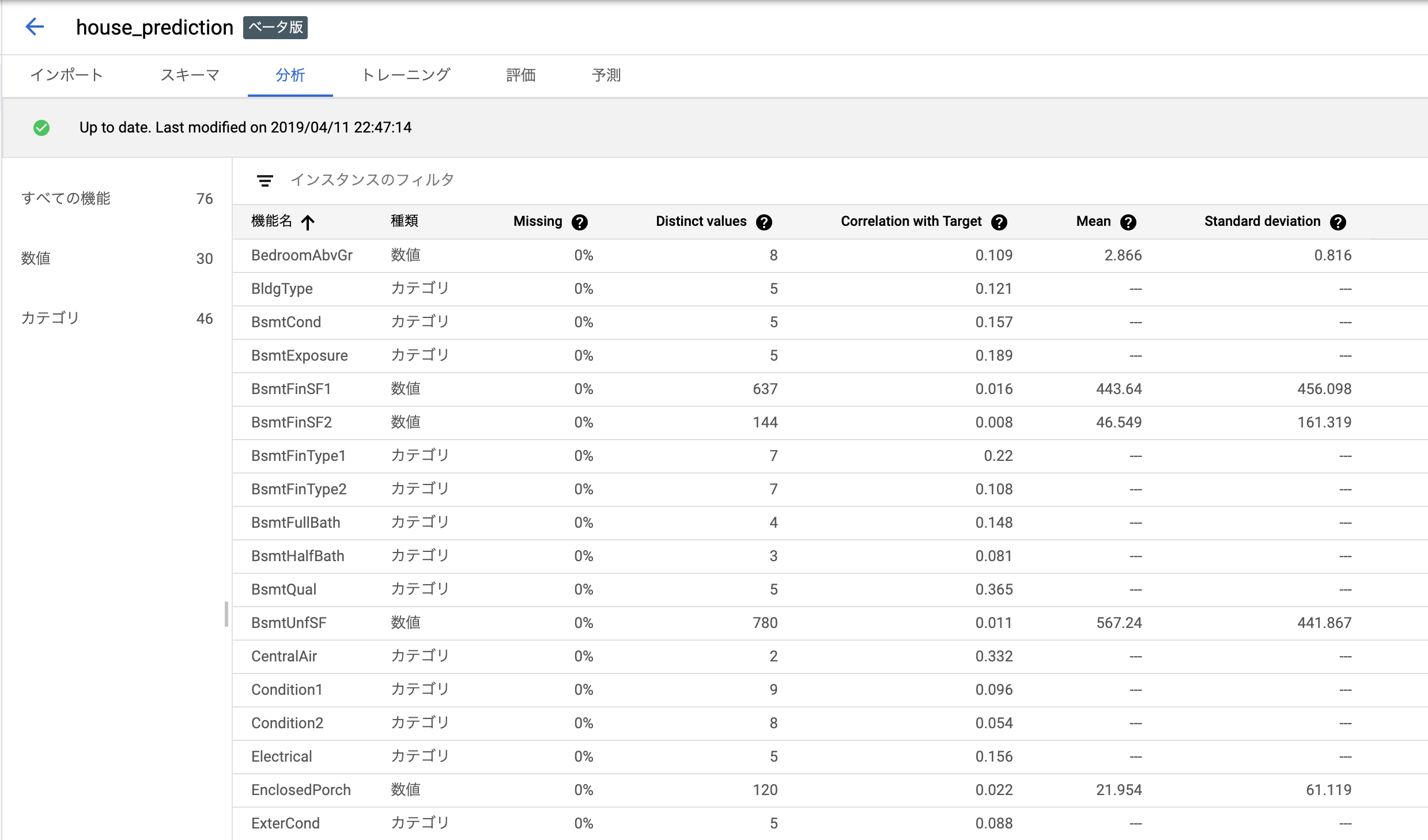
いろんな指標を計算してくれて気分がいいですね。
項目を押すと、横にグラフが出て傾向を確認できます。
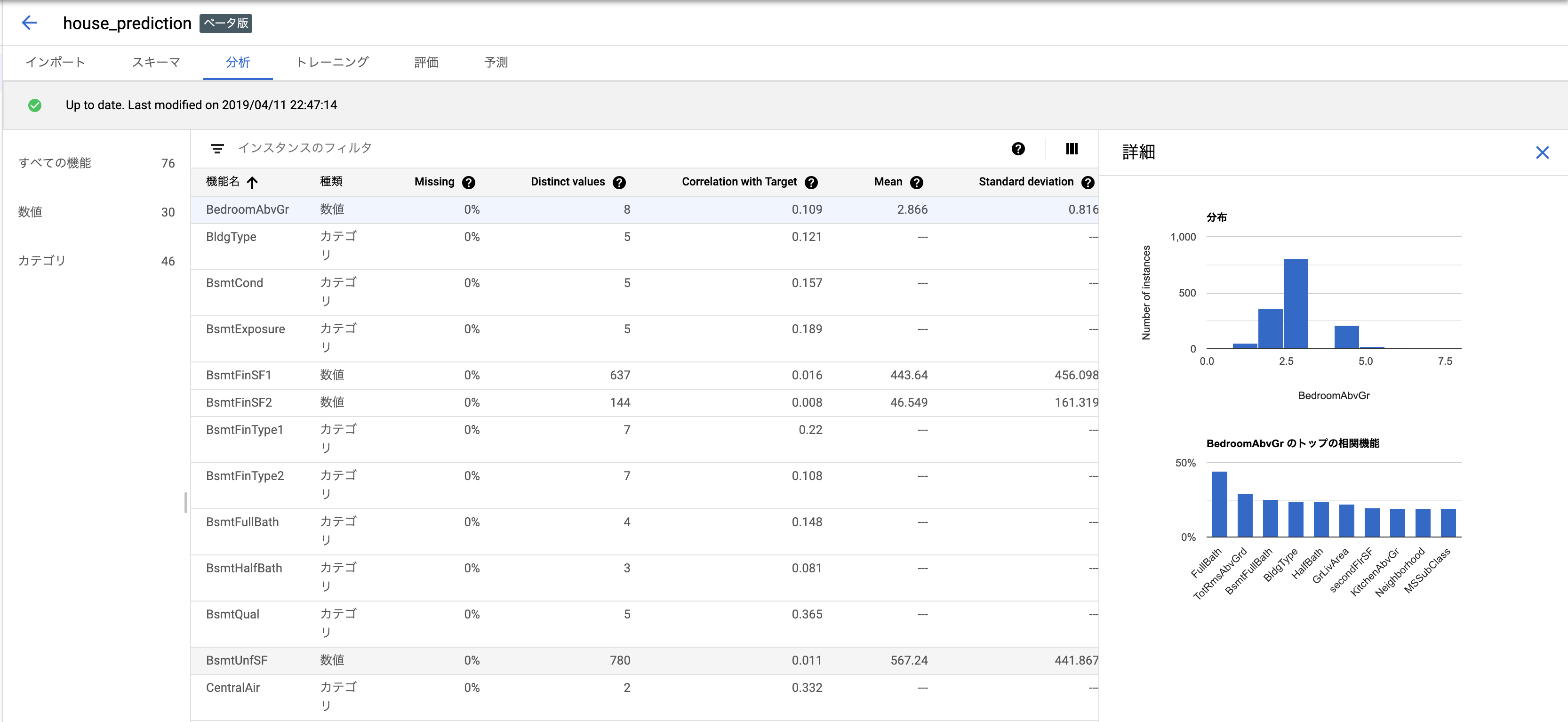
目的変数との相関を計算してくれていて、それでソート・フィルタが可能です。
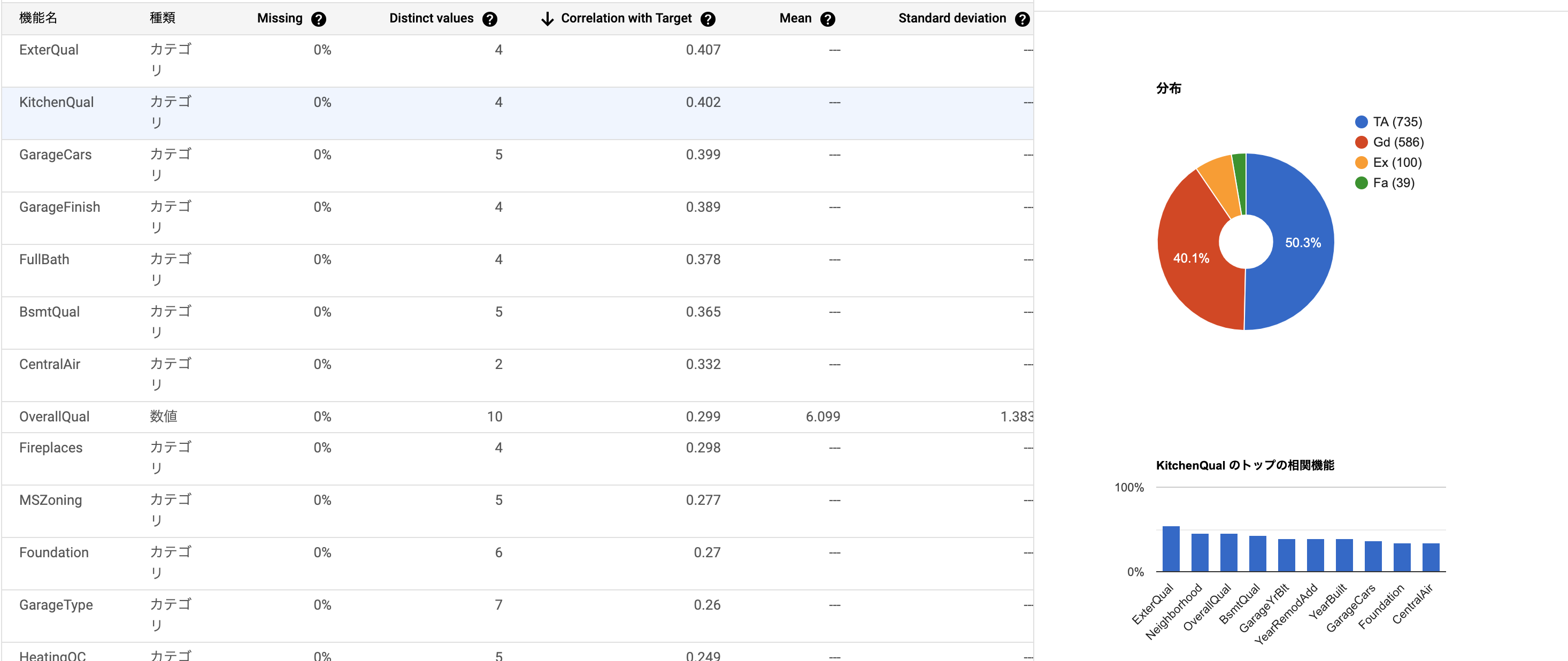
キッチンのクオリティが家賃との相関高めと出てますね。たしかにそれっぽい。
トレーニングタブ
では早速学習してみましょう。
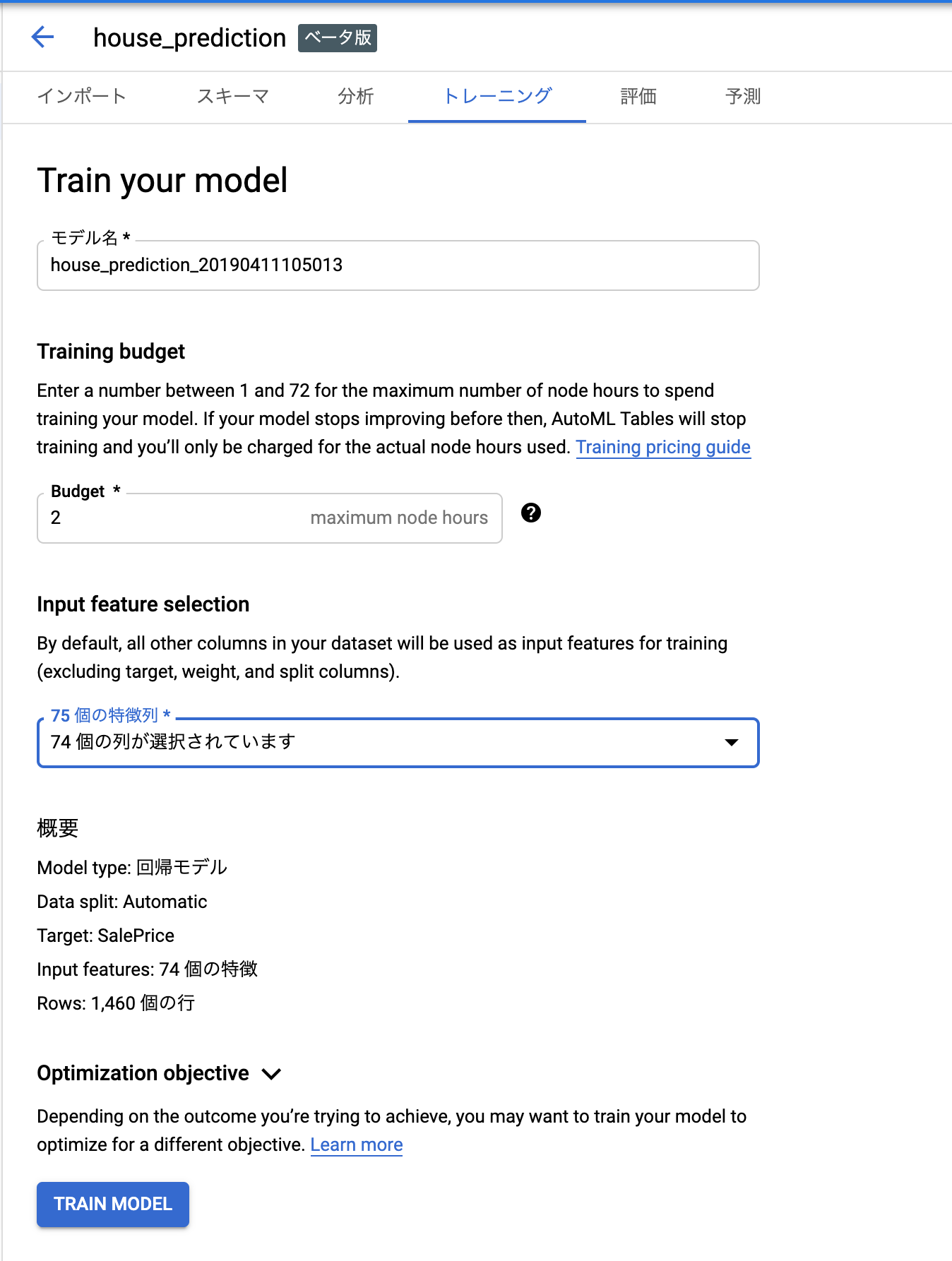
budgetは並列数みたいなものと解釈してます。データ数が多いならここを予算が許す限り増やせば良さそう。ちなみに、割と大きな数にしないと多分あんまり早くならないです。1~3を試したんですが、あまり大差がなかった。
このタブでは特徴量の選択ができます。
ここでIdは弾いておかないと当然リークするので外します。このへんはちゃんと機械学習、というか思考停止でポチポチするだけだと死ぬポイントですね。
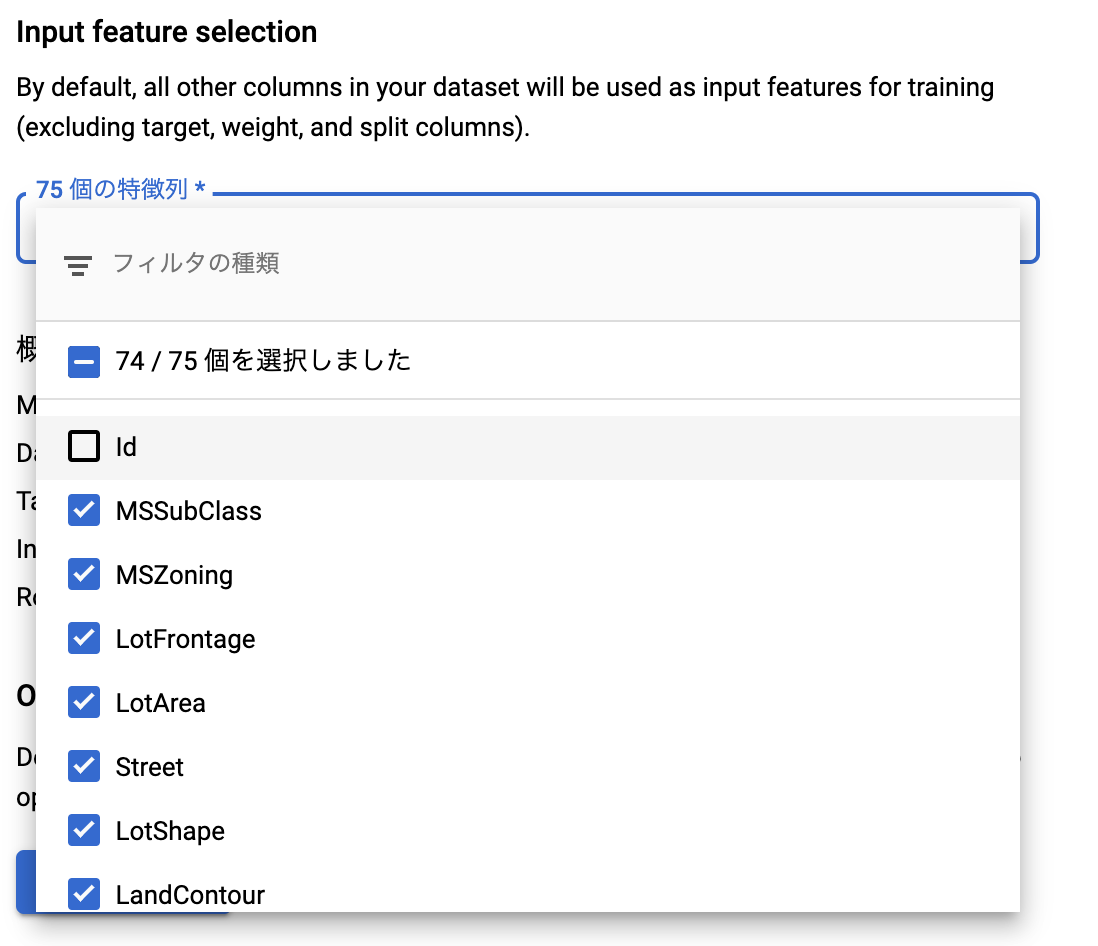
ちゃんと回帰であることを認識してそのモデルになっていますね。安心。
またmetricsもいくつかから選べます。今回のHouse PredictionのmetricsはRMSEなので、それを選択しておきます。
トレーニングしているときはこういう表示。終わるとemailが飛んできます。
評価タブ
しばらくコーヒーブレイク(node数が少ないときはコーヒーブレイクどころでは済まないと思います。僕は3nodeで1時間くらい待ちました。)していれば、メールが届きます。
コンソールを見に行けば、学習終わった風の画面になっていますね。
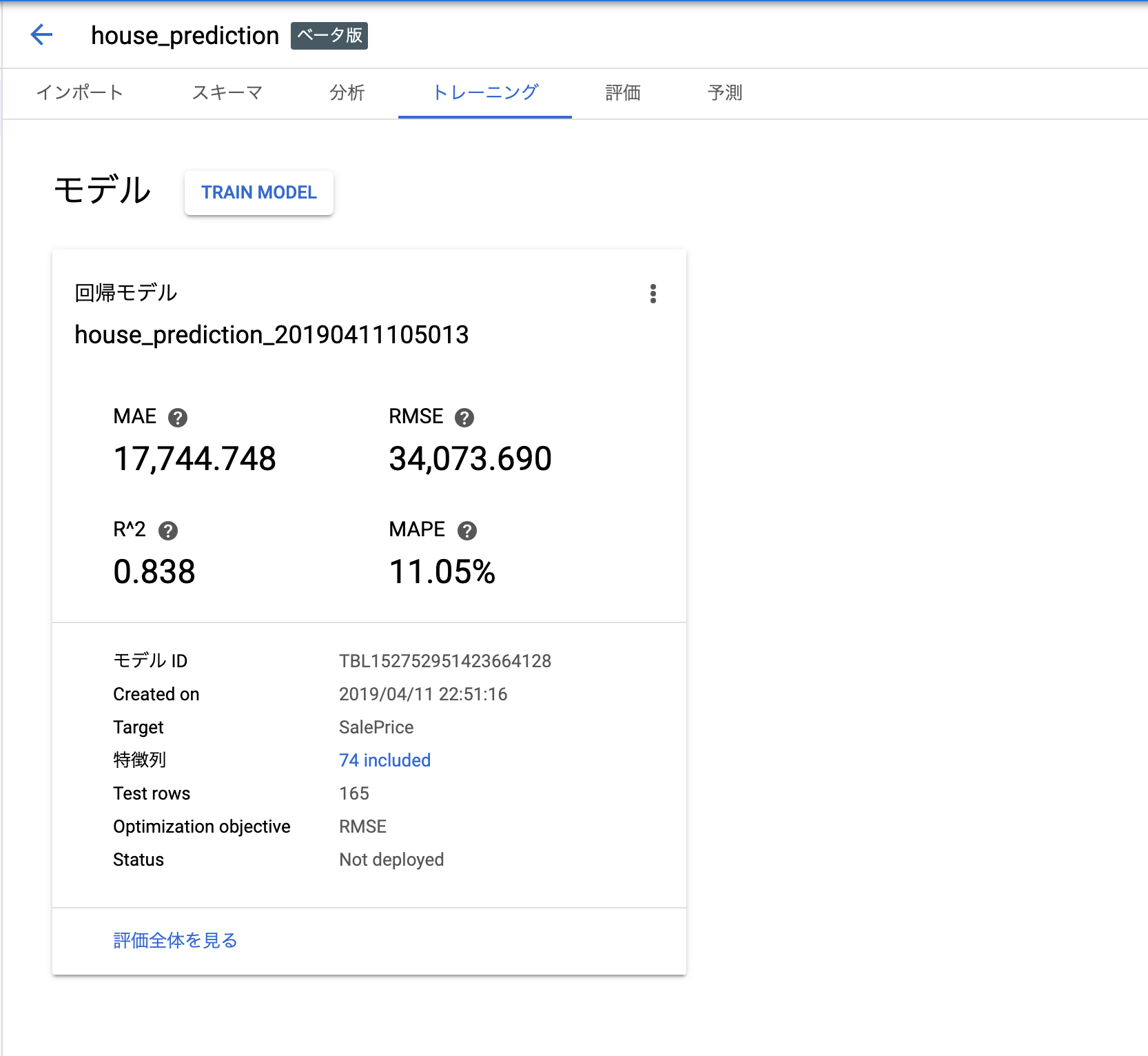
クリックすると評価タブに移行します。いろんな数字が並んでて気持ちいいですね。
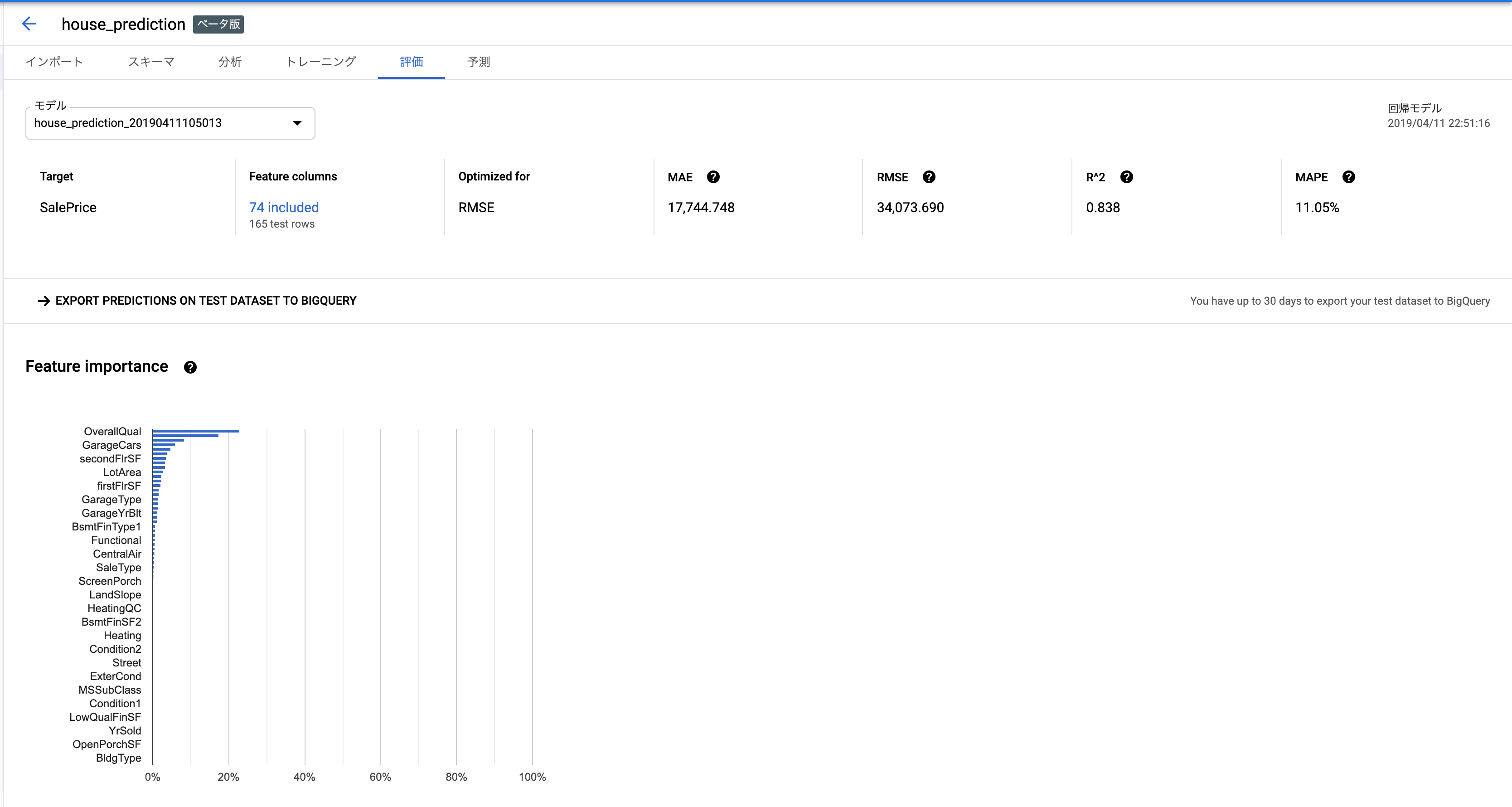
Feature Importanceまで出てます。ってことはやっぱり中身は勾配Boostingなんでしょうか...
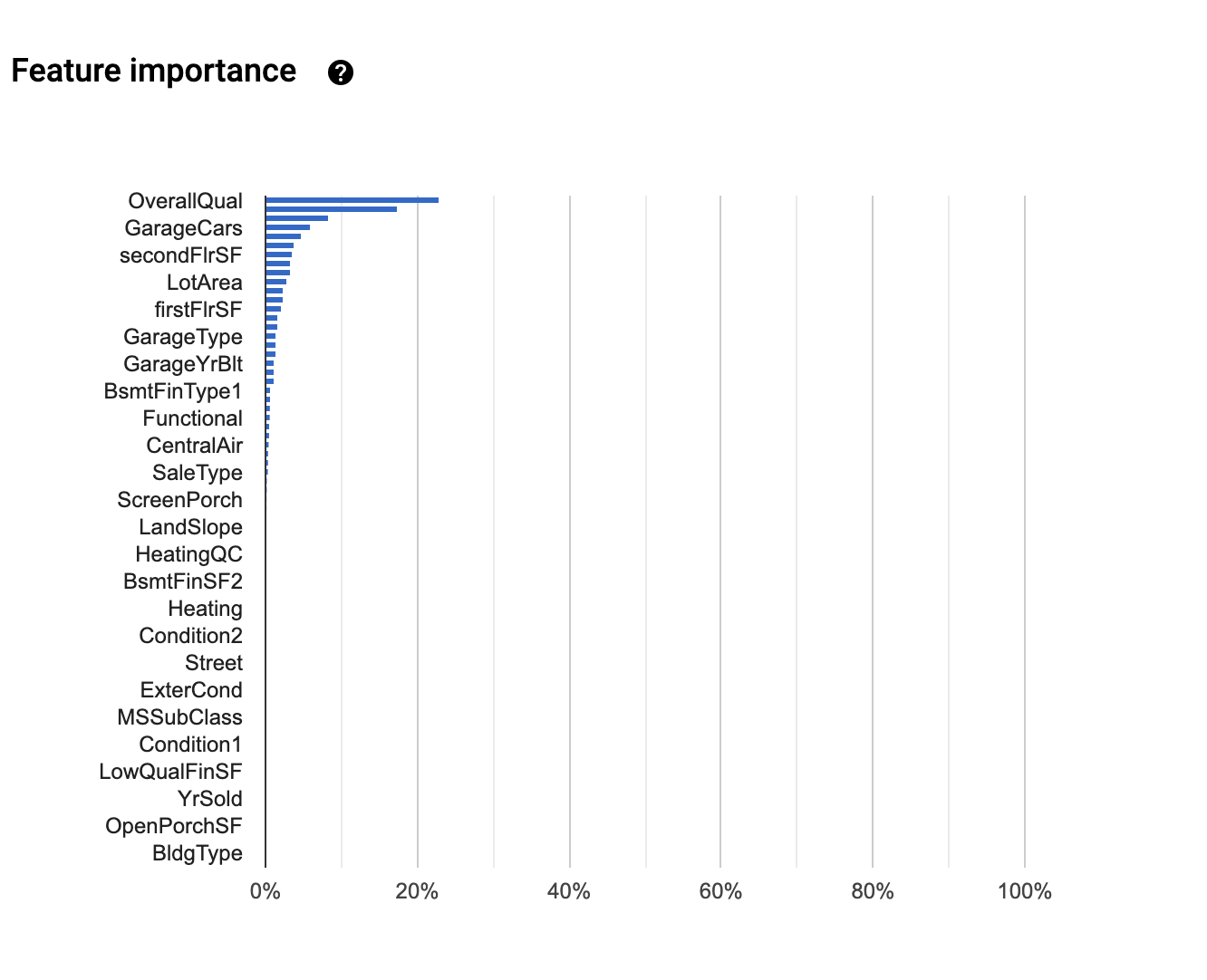
実は評価タブ内で、どのモデルを使っててこのモデルが良かったよ!的なのが見れるんじゃないかと期待していました。それこそデータロボットみたく。まあでもその機能は残念ながらないっぽいっすね。しょうがなし。
予測タブ
ではでは、予測やっていきましょう。今回はバッチ予測をやります。予め前処理しておいたtestデータをBigQueryに突っ込んでおき、最初にデータセットを作成したときと同じようにそのターブルを指し示す情報を入力していきます。
結果を格納したものはBigQueryのデータセットで吐き出されます。指定するのはプロジェクトIDだけで大丈夫です。
では、また再びコーヒーブレイクしましょう。おそらくここでもnode数が効いてきます。
終わると再びメールが届きます。BigQueryを見に行けば、こんな感じで指定したプロジェクト配下にテーブルができてます。
予測結果とエラーがデータセット内には格納されています。エラーテーブルを見て、0件なら安心。そうじゃなかったらnullableなどを確認しましょう。もう一回スキーマの確認からです...
全件予測が完了していることを確認しつつ、中身の値を見てみましょう。今回は最後のvalueだけ見れば良さそうですね。
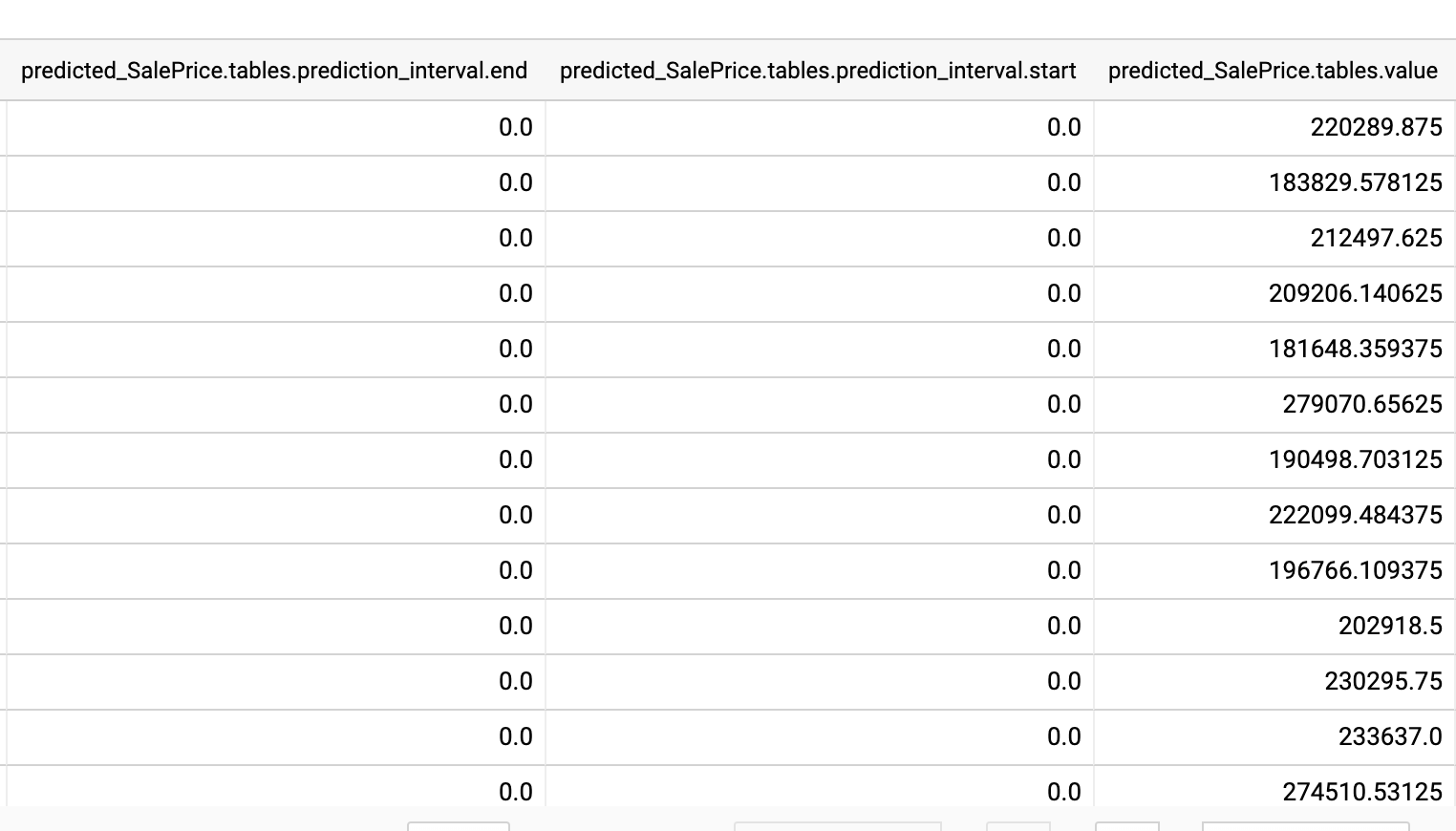
注意すべきことなのですが 予測結果 predicted_{target_name} は RECORD 型で返ってきます。jsonみたいなものなのですが微妙に違います。
普通に select predicted_{target_name}.tables.value from ... でアクセスしようとしてもだめです。 UNNEST を使って配列構造から開放する必要があります。
WITH
tmp AS (
SELECT
*
FROM
`{your_project_id}.prediction_house_prediction_20190411105013_2019_04_11T07_59_52_140Z.predictions`)
SELECT
CAST(Id as int64) as Id,
tables.value AS SalePrice
FROM
tmp,
UNNEST(tmp. predicted_SalePrice)
order by Id
上記のSQLで抽出すれば、あとはもうsubmitするだけです。submit!

0.15ということのようです。LeaderBoard的には、2900位くらい。4500チーム中でということを考えるとそこそこくらいですかね。

自分でコードを書いたLightGBMと比較する
さて、では僕が失職するかどうかを占うために、同じ特徴量でLightGBMにかけてみてチューニングでどれくらい伸ばせるかをやってみます。
コードはこんな感じです。見づらいですがご容赦ください。
# 既にna処理をしたあとで、 train_fillna、test_fillnaというデータが有るところから。
predictors = [v for v in train_fillna.columns if v not in ['Id', 'SalePrice', 'train']]
categorical = ["Utilities", "Street", "SaleType", "SaleCondition", "RoofStyle" ,"RoofMatl"
,"PavedDrive","Neighborhood","MSZoning",'MasVnrType','LotShape',"LotConfig","LandSlope","LandContour","KitchenQual",'KitchenAbvGr',"HouseStyle","HeatingQC","Heating","HalfBath"
,"GarageType","GarageQual","GarageFinish","GarageCond","GarageCars","Functional","FullBath",'Foundation',"Fireplaces","ExterQual","Exterior2nd","Exterior1st","ExterCond","Electrical"
,"Condition2","Condition1","CentralAir","BsmtQual","BsmtHalfBath","BsmtFullBath","BsmtFinType2","BsmtFinType1","BsmtExposure","BsmtCond","BldgType"]
for c in categorical:
train_fillna[c] = train_fillna[c].astype('category')
test_fillna[c] = test_fillna[c].astype('category')
from sklearn.model_selection import train_test_split
dev, _eval = train_test_split(train_fillna)
import lightgbm as lgb
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric':'rmse'
}
xgtrain = lgb.Dataset(dev[predictors], label=dev['SalePrice'].values,
feature_name=predictors
)
xgeval = lgb.Dataset(_eval[predictors], label=_eval['SalePrice'].values,
feature_name=predictors
)
bst = lgb.train(lgb_params,
xgtrain,
valid_sets=[xgtrain, xgeval],
valid_names=['train','valid'],
num_boost_round=2000,
early_stopping_rounds=100,
verbose_eval=1)
# Submission
y_pred = bst.predict(test_fillna[predictors])
submission = pd.DataFrame(test_fillna['Id'])
submission['SalePrice'] = y_pred
submission.to_csv('lightgbm_submission.csv', index=None)
では、まず上記のパラメータ通りにほぼ何もしない状態でLightGBMをやってみて、Submitしてみましょう。どりゃー

な、なるほど。さすがにチューニング無しで勝てるほどあまくはなかったですね...
ではここから、手で頑張ってチューニングしていきます。30分くらいかけて一番良さそうになったのがこちらです。
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric':'l1',
'learning_rate': 0.01,
'feature_fraction': 0.6,
# 'max_bin':10,
'num_leaves': 128,
# 'min_data': 500,
# 'min_hessian': 0.05,
# 'bagging_fraction': 0.85,
# 'bagging_freq': 5
}
で、結果がこちらです!

おー、というわけで無事に AutoMLTables(0.15)よりも良い成績になりました。まだ僕は失職せずに済みそうです。
optuna をつかえばもっと良いパラメータになっていることだと思いますので、もうちょっと差は広げられそうですかね。
両者の結果を比較する
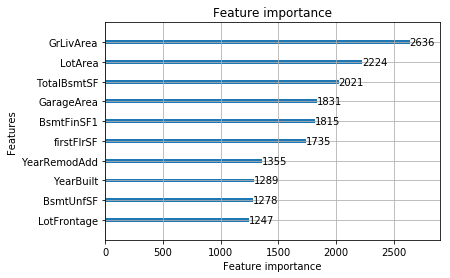
最後に両者の予測結果をいろいろと比較してみたいと思います。まずはFeature Importanceから。
Feature Importance
-
LightGBM
-
AutoML Tables
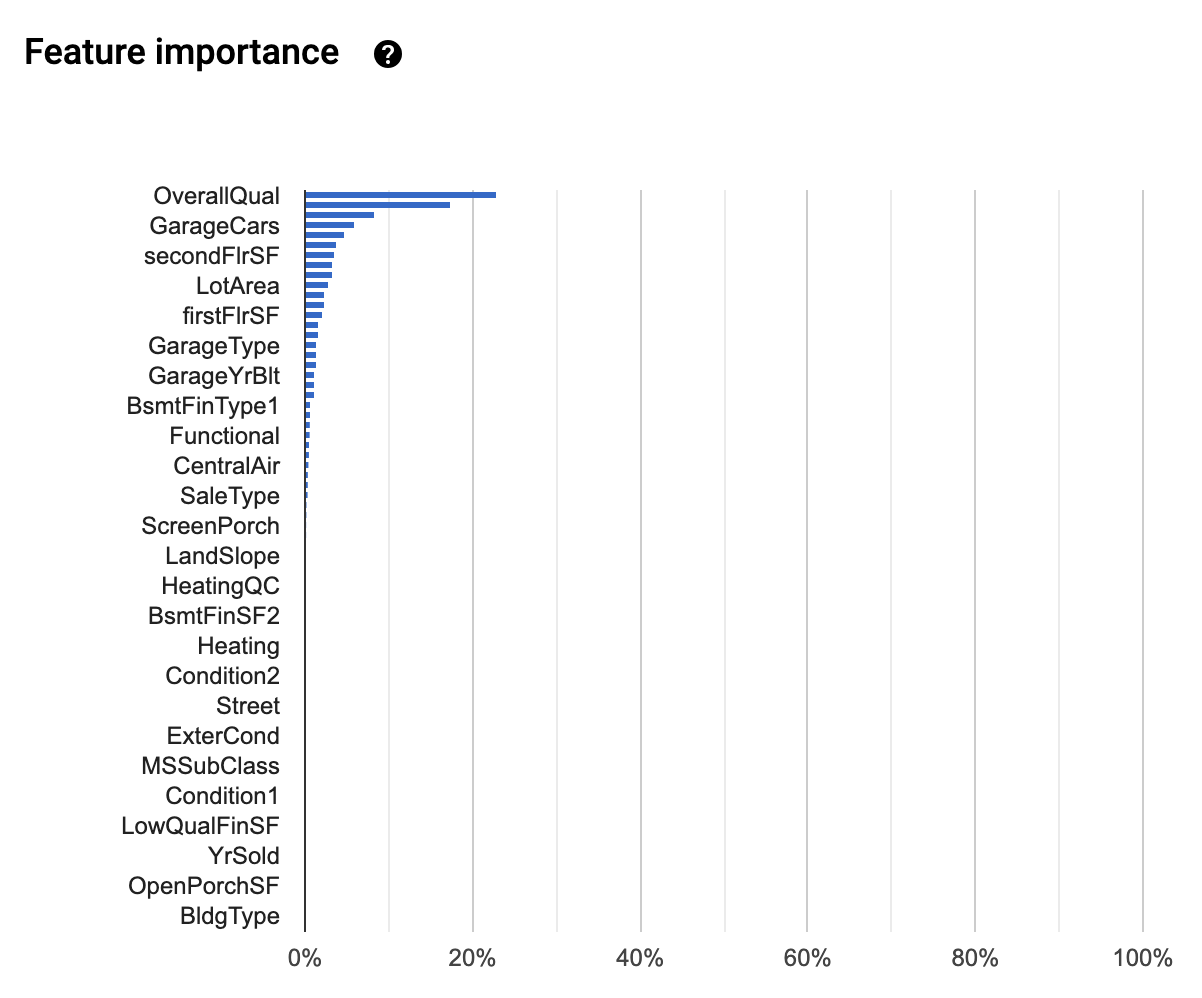
AutoML Tables、細かいところはカーソル当てないとみえない...
GrLivAreaやLotArea・garageAreaが上位という傾向は似てました。
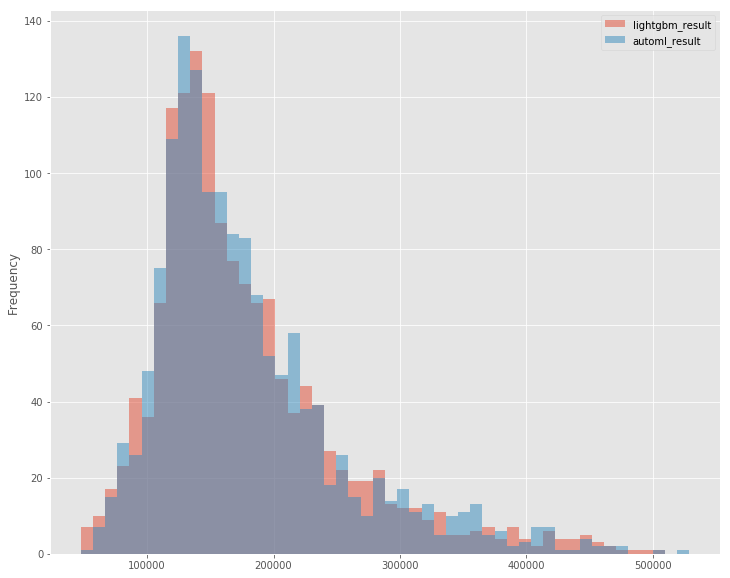
ヒストグラム・基本統計量
ヒストグラムを書いてみると、automlの方が中央によっているようなきがする...
ちょっとoverfit気味なのかもしれないですね。LightGBMチューニング時も結構早くリフトしちゃってたのでなるべくそれを抑えるようにしてました。
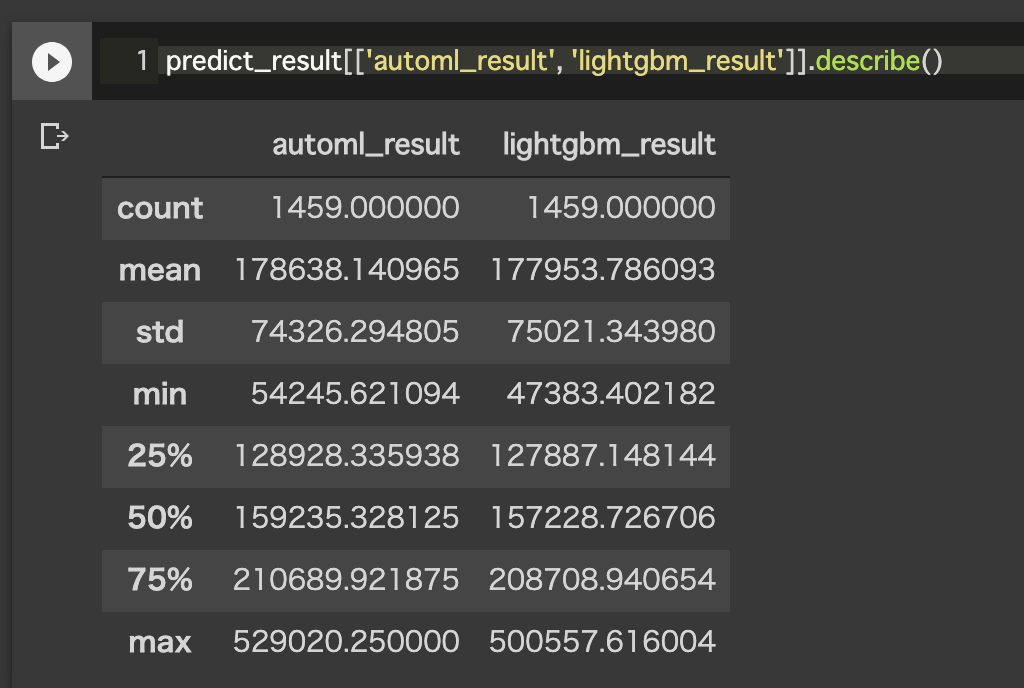
とおもって基本統計量を出してみましたが、そういう感じでもない。stdがlightgbmのほうが大きいってことくらいですかね。
結論と感想
さて、というわけでAutoML Tablesを早速やってみました。
個人的に一番嬉しいのは BigQueryをインプットにできる点ですね。巨大なデータをBigQueryに保有している企業にとって、そのデータをすぐに予測に回せる(csvにわざわざ戻してインスタンスに送ったりする必要がない)のは大きな利点だと思います。
node数を割と大きくしないと時間がかかるってのは何回か回してみて肌感がつかめるところだと思います。お金に気をつけつつ試すとよいのかなと。
そういえば気になるお支払情報ですが、上記のことをいろいろ試行錯誤してみて、だいたい4000円でした。ま、まあこんなもんですかね...

特徴量は依然として人間が頑張って考えたものに依存すること、チューニングはまだ頑張りようがあること、という点などを確認できました。
運用の手間を減らせること、BigQueryからすぐにデータを取り寄せて予測ができるところなど、良い点とうまく付き合いつつもうしばら失職せずに機械学習エンジニアとしてやっていきたいと思います。