はじめに
先日、「サザエさんじゃんけん研究所」1様の「サザエさんじゃんけん白書」が話題になりました。
日曜夕方の代表的なアニメ「サザエさん」の次回予告で行われる「じゃんけん」を記録し、傾向と対策をまとめているという恐ろしい資料です。
1991年11月の開始から現在に至るまで、26年以上のじゃんけんの手が毎週分(執筆時点で1348回!)全て記録されているというから驚きです。2
さらに「サザエさんじゃんけん研究所」様では、傾向と対策を基にサザエさんと毎週じゃんけん勝負をしていて、1996年1月~2018年8月第2週の22年以上で通算勝率70.3%を挙げているのです。3, 4
サザエさんの手に規則性があるとすれば、コンピュータがサザエさんにじゃんけん勝負を挑んでも勝ち越せるのではないでしょうか?
あわよくば、「サザエさんじゃんけん研究所」様の勝率を超えたいところですが、どうなるか。
やはり同じことを考える方がいらっしゃるようで
同じくニューラルネットワークを使ったじゃんけん手の予測ですね。
なおパクリではなく、私も全く独立にプログラムを書いたのでここに投稿させていただきます。
(きれいじゃないけど捨てるのはもったいないので)
また、近々ニューラルネットワーク以外の識別器を使った例も投稿予定です。
また、今回話題になるよりも前から、機械学習による予測手法を試されている方もいらっしゃいますね。
- サザエさんのジャンケンの次の手を決定木で予測+可視化してみた - 唯物是真 @Scaled_Wurm
- サザエさんと本気でじゃんけんしてみた① - アクチュアリーはデータサイエンスの夢を見るか?
- 機械学習.vs.乱数 - 小人さんの妄想
識別器はサポートベクターマシン(SVM)だったり、決定木だったりと様々ですが、だいたい予測的中率(正解率)で50%を少し超える程度、勝率で70%程度に落ち着いているようです。
やはりこのあたりの数値が目標になるでしょうか。
問題設定
過去データを使ってサザエさんとじゃんけん勝負するプログラムを書きます。
「サザエさんじゃんけん研究所」様に合わせて、以下のルールで実施します。
- 1996年1月~2018年8月12日までの1135回で出す手を機械学習で決定する。
- アルゴリズムは自由だが、今回はニューラルネットワークを使用する。
- 各回の手の決定にあたっては、それ以前の回の手の情報だけを使うことができる。
- (※重要)当該回以降の手の情報を使ってはいけない。
- 勝率を「(勝利数)÷(勝利数+敗北数)」で計算し、「サザエさんじゃんけん研究所」様の数値と比較する。
ニューラルネットワークで解いてみる
戦略
安直に
- サザエさんの手を予測
- 1に勝つ手を自分の手として決定する
という方針でいきます。
相手の手を予測するために、どんな特徴量(素性)を使えばよいでしょうか…?
ヒントは「サザエさんじゃんけん白書」にありますので、この中から色々選んでみて良さそうなものを使う、ということになります。
- 各クールの1回目はチョキが出やすい?
- 放送月と放送週(その月の何週目か)が使えるかも
- FNS27時間テレビ内包回はチョキが出やすい?
- 27時間テレビ回かどうかが使えるかも
- 過去2回の手を見れば予測できる?
- 過去数回分の手を特徴量に入れれば良いかも
- 最も長い期間現れていない手を出せば勝てる?
- グー・チョキ・パーのそれぞれが現れていない期間の長さを入れれば良いかも
また、ニューラルネットワークの中間層のユニット数も頑張っていいところを探します。
(データが少ないので、中間層が1つ(全部で3層)のネットワークにします)
いいパラメータが見つかったら、
- 1995年までのデータを使ってパラメータを学習し、1996年の1年間のデータを予測する。
- 1996年までのデータを使ってパラメータを学習し、1997年の1年間のデータを予測する。
- (以下略)
という感じで、1年ごとにパラメータを更新する想定とします。
これならば先のルールに抵触しませんし、仮にじゃんけん予測システムを運用するとしても、比較的簡単にメンテナンスできるはずです。(年またぎ以外は、最新回のサザエさんの手を逐次追加していくだけで良い)
選んだ特徴量
以下の29次元になりました。
数が多いですが、クラスを1-of-K表現にしているためです。
- 放送月(1-of-K表現で12次元)
- 放送週(その月の何回目の放送か。1-of-K表現で5次元)
- 過去3回分のサザエさんの手(9次元:1-of-K表現で3次元×3回分)
- グー・チョキ・パーのそれぞれが現れていない週数(3次元)
- 前の回で現れていれば1、2回前で現れていれば2…
- 初回は便宜上 (1, 1, 1) から始めます。
入力データは、以下の形式のテキストフォーマット(タブ区切り)で与えます。
データのフィルタリングのため、先頭に放送年の列を追加しています。
(先頭行はデータに含めません)

- 最終列はサザエさんの手で、0: グー、1: チョキ、2: パーを表す。
- 1行目は1991年11月第1週(便宜上、開始月は月の途中ですが1週目から始めます)で、サザエさんはチョキを出した。
- 2行目は1991年11月第2週で、前回はチョキ。今回はグー。
- 3行目は1991年11月第3週で、前回はグー、2回前はチョキ。今回はグー。
これが延々1000行以上続きます。
ニューラルネットワークの構造
中間層の数を色々触って、あまり過学習しない程度に調整したところ、以下のようになりました。
- 入力層:29次元(特徴量と同じ)
- 中間層:8次元
- 出力層:3次元(グー・チョキ・パーに対応)
この出力の値を比較して、最もスコアの高いものをサザエさんの手の予測結果とします。
プログラム
numpyとChainer5を使っていますので、事前にインストールしてください。
pipなら以下で入ります(numpyが入っていなければ自動的にインストールされます)。
pip install chainer
なお、今回のプログラムはCPU限定です(別にGPU使うほどの計算量でもないので)。
学習部分
# !/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import os
import random
import numpy as np
import chainer
from chainer.datasets import TransformDataset
from chainer.training import extensions, triggers
import mymodel
import mydata
# 再現性のために乱数シードを固定
# https://qiita.com/mitmul/items/1e35fba085eb07a92560
def reset_seed(seed=0):
random.seed(seed)
np.random.seed(seed)
if chainer.cuda.available:
chainer.cuda.cupy.random.seed(seed)
## Main
gpu_id = -1
max_epoch = 50
## read data
data_orig = mydata.read()
## make output directory
try:
os.makedirs("models")
except OSError:
pass
for year in xrange(1992, 2019):
print "Year: {0}".format(year)
reset_seed(0)
# 前年までのデータで学習
data = data_orig[data_orig[:, 0] < year]
inputs = TransformDataset(data, mymodel.transform)
batchsize = max(len(inputs) / 128, 1)
print "Data size: {0}".format(len(inputs))
print "Batch size: {0}".format(batchsize)
train, valid = chainer.datasets.split_dataset_random(inputs, len(inputs)*9/10, seed=0)
train_iter = chainer.iterators.SerialIterator(train, batchsize)
valid_iter = chainer.iterators.SerialIterator(valid, batchsize, repeat=False, shuffle=False)
# network setup
net = mymodel.create()
# trainer setup
optimizer = chainer.optimizers.Adam().setup(net)
updater = chainer.training.StandardUpdater(train_iter, optimizer, device=gpu_id)
# early stopping
# https://qiita.com/klis/items/7865d9e8e757f16bc39c
stop_trigger = triggers.EarlyStoppingTrigger(monitor='val/main/loss', max_trigger=(max_epoch, 'epoch'))
trainer = chainer.training.Trainer(updater, stop_trigger)
trainer.extend(extensions.Evaluator(valid_iter, net, device=gpu_id), name='val')
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.ExponentialShift("alpha", 0.9999))
## Let's train!
trainer.run()
## save model
chainer.serializers.save_npz("models/{0}.npz".format(year), net)
予測部分
# !/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import numpy as np
import chainer
from chainer.datasets import TransformDataset
import mymodel
import mydata
## read data
data_orig = mydata.read()
win_total = 0
draw_total = 0
lose_total = 0
for year in xrange(1996, 2019):
## network setup
net = mymodel.create()
chainer.serializers.load_npz("models/{0}.npz".format(year), net)
# 前年までのデータで学習したモデルで、1年分のデータを予測
data = data_orig[data_orig[:, 0] == year]
inputs = TransformDataset(data, mymodel.transform)
win = 0
draw = 0
lose = 0
for testcase in inputs:
detected = net.predictor(testcase[0].reshape((1,-1))).data.argmax(axis=1)[0]
# 相手が最も出す確率の高い手に勝つように出す
mychoice = (detected + 2) % 3 # 0: G, 1: C, 2: P
schoice = testcase[1]
if (mychoice + 3 - schoice) % 3 == 0:
draw += 1
elif (mychoice + 3 - schoice) % 3 == 1:
lose += 1
else:
win += 1
win_total += win
draw_total += draw
lose_total += lose
print "{0} Win: {1}, Draw: {2}, Lose: {3} / Avg: {4:.2f}%".format(year, win, draw, lose, float(win)/(win+lose)*100)
print "======"
print "<TOTAL> Win: {0}, Draw: {1}, Lose: {2} / Avg: {3:.2f}%".format(win_total, draw_total, lose_total, float(win_total)/(win_total+lose_total)*100)
共通コード
# -*- coding: utf-8 -*-
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
idx_features = np.r_[1:30]
num_units_inside = 8
## Network definition
class MyJankenNetwork(chainer.Chain):
def __init__(self):
super(MyJankenNetwork, self).__init__(
l1 = L.Linear(idx_features.shape[0], num_units_inside),
l2 = L.Linear(num_units_inside, 3),
)
def __call__(self, x):
h = self.l2(F.relu(self.l1(x)))
return h
def transform(inputs):
r = inputs[idx_features]
label = int(inputs[-1])
return r, label
def create():
net = L.Classifier(MyJankenNetwork())
return net
# -*- coding: utf-8 -*-
import numpy as np
def read():
# read data
with open("input.txt", "r") as fr:
data = [[int(val) for val in l.split(None)] for l in fr]
return np.array(data, dtype=np.float32)
データ
先程説明したフォーマットです。
元データは本家様のサイトからせっせとスクレイピングさせていただきました。m(_ _)m
1991 0 0 ... 1 1 1 1
1991 0 0 ... 2 1 2 0
1991 0 0 ... 1 2 3 0
:
:
結果
以下のように実行します。モデル学習にはしばらく(全部で数分程度)時間が掛かります。
python train.py
python eval.py
実行結果はこちら。
↓(2018/8/20) データの誤りを修正したため、2015年と2016年および合計の値が変わっています。
1996 Win: 24, Draw: 14, Lose: 12 / Avg: 66.67%
1997 Win: 27, Draw: 10, Lose: 14 / Avg: 65.85%
1998 Win: 30, Draw: 12, Lose: 10 / Avg: 75.00%
1999 Win: 27, Draw: 9, Lose: 14 / Avg: 65.85%
2000 Win: 22, Draw: 16, Lose: 13 / Avg: 62.86%
2001 Win: 23, Draw: 15, Lose: 13 / Avg: 63.89%
2002 Win: 33, Draw: 9, Lose: 8 / Avg: 80.49%
2003 Win: 26, Draw: 12, Lose: 12 / Avg: 68.42%
2004 Win: 24, Draw: 13, Lose: 12 / Avg: 66.67%
2005 Win: 22, Draw: 14, Lose: 13 / Avg: 62.86%
2006 Win: 27, Draw: 8, Lose: 15 / Avg: 64.29%
2007 Win: 24, Draw: 13, Lose: 14 / Avg: 63.16%
2008 Win: 30, Draw: 9, Lose: 12 / Avg: 71.43%
2009 Win: 28, Draw: 11, Lose: 11 / Avg: 71.79%
2010 Win: 30, Draw: 12, Lose: 6 / Avg: 83.33%
2011 Win: 33, Draw: 11, Lose: 7 / Avg: 82.50%
2012 Win: 29, Draw: 7, Lose: 13 / Avg: 69.05%
2013 Win: 31, Draw: 12, Lose: 8 / Avg: 79.49%
2014 Win: 33, Draw: 14, Lose: 4 / Avg: 89.19%
2015 Win: 30, Draw: 10, Lose: 10 / Avg: 75.00%
2016 Win: 25, Draw: 12, Lose: 13 / Avg: 65.79%
2017 Win: 32, Draw: 6, Lose: 10 / Avg: 76.19%
2018 Win: 20, Draw: 5, Lose: 7 / Avg: 74.07%
======
<TOTAL> Win: 630, Draw: 254, Lose: 251 / Avg: 71.51%
**おお、勝率71.51%が出たではありませんか…!**恐れ多くもまさかの本家超え(汗)
2014年には9割近く勝てているなど、とてつもなく調子の良い年もあるようです。
最初の方は使えるデータが少ないので、年ごとの勝率は6割台程度にとどまっています。しかし、データが増えるごとに強くなり、2008年以降は2012年を除いて7割を超えてきています。
考察など
結果について
年ごとの予測成績を、本家様3と比較してみました。
勝率の高い方を赤字で示しています。(2018年は8月12日放送分まで。本家様の成績はWebサイトより引用、ただし勝率は小数第4位を四捨五入として再計算)
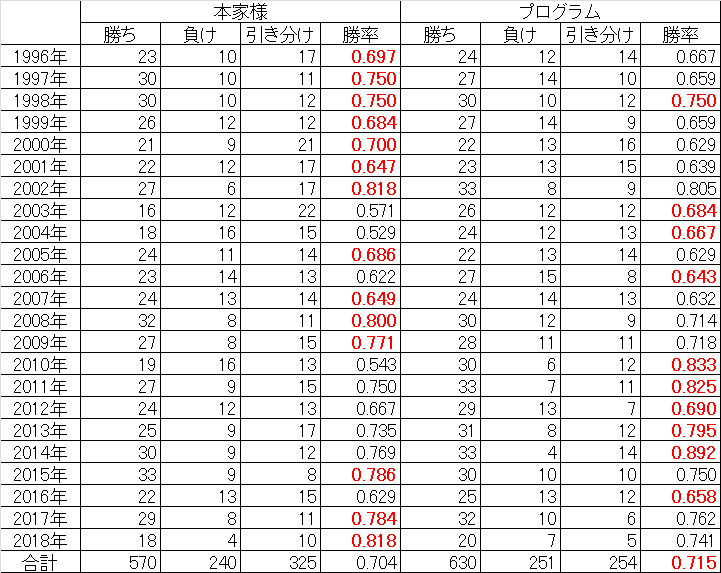
最初の数年間は完全に本家様に負けているのですが、データが蓄積されて徐々に勝負できるようになる様子が見えます。
プログラムの結果は全体として本家様より引き分けが少なくなっています。
後述しますが、ダイレクトに勝ちを狙いに行く戦略になっているのが原因だと思います。
特徴量について
- 3回前までを見るのがどうもよいらしい(4回にすると勝率が落ちる)
- 単に最も長期間出なかった手の情報を入れるより、それぞれの手が何週出ていないかを入れるほうが性能が良かった
- 27時間テレビ回の情報は効果ない様子(回数が少なすぎてうまく学習できず?)
- 本当は、学習されたパラメータを見て、「クール初回はチョキが出やすい」のようなルールが反映されているか調べた方が良いのでしょうが。
戦略について
今回は、サザエさんの出す手を予測し、それに勝つ手を出す戦略を取りました。
例えば、相手の「グー」のスコアが最も高ければ、「パー」を出します。
もう一つの戦略として、「サザエさんが最も出さなそうな手に負ける手を出す」言い換えれば**「最も負ける確率の低い手を出す」**ことも考えられます。
例えば、相手の「グー」のスコアが最も低ければ、「チョキ」を出します。相手が「チョキ」か「パー」を出せば、負けないからです。
ただ、今回は勝率アップになりませんでした。
結局勝率に換算すると70%程度になり、勝ちに行く戦略のほうが良い成績が得られました。
なお、引き分け数が増えて勝ち数は減っているので、的中率(相手の手を当てる)の面でも勝ちに行く戦略が良いという結果になりました。
もっとも、識別問題に「あいこ」の概念を入れるのは、あながち間違っていないと思うのです。
相手が本当は「グー」を出そうとしているときに、「チョキ」と予測するのと「パー」と予測するのでは、損失が異なるはずだと思うからです。
- 「チョキ」と予測した場合、こちらは「グー」を出すのであいこになる(損失が小さい)
- 「パー」と予測した場合、こちらは「チョキ」を出すので負ける(損失が大きい)
サザエさんは前々回と前回にチョキを出しているので、過去の実績から今日はグーまたはパーを出す確率が高いと予想しています。したがって、私の手はパーです。また、次回予告担当の予想はフネです。
— ΗΚΝ@サザエさんじゃんけん研究所 (@jq1hkn) 2018年8月12日
こちらのツイートにもあるように、人間が予測する場合には、「最も負ける確率の低い手を出す」「引き分けでも良し」という戦略を取るのはもっともなことと思います。
しかし、今回のプログラムでは、ただの3クラスの識別問題として解いていますので、上2つの損失は同じと扱っています。つまり「引き分けでも良し」という感覚が現状全く入っていないのです。これが、本家様に比べて引き分けが少ない理由と考えられます。
ここに3すくみの性質を取り入れられれば、より勝率を上げることができませんかね…?(考え中)
今回のプログラムの意義
今回のプログラムが行っているのは、「法則そのものを見つけ出す」ことではなく、「ある程度の法則が分かっているときに、それらをどのように組み合わせて予測するか」のルールを(数式で)表現することといえます。
単にデータだけを与えたときに、「2回前までの結果を見ると良い」といった法則を見つけ出せるようなプログラムではありません。
(そもそも27時間テレビ回が云々というのは周辺知識あってこその話であって、生データだけがあっても思いつくことはできませんよね)
26年間の蓄積として得られた様々な法則は、(単純な内容に落ち着いたとしても)相当な知的作業の成果なのだと感じずにはいられません。
最後に
2017年までのデータを使って学習したニューラルネットワークを使って、2018年8月19日放送予定(執筆時点では放送前)のサザエさんの手を予測すると「グー」になりました。よって私は「パー」を出します。勝てるかな?
→(2018/8/19 20:00追記) サザエさんは予測通り「グー」を出しましたので、勝利です!
**(2018/8/20) SVM(サポートベクターマシン)を使ったじゃんけん予測を実装しました。**よろしければこちらもどうぞ。
機械学習でサザエさんとじゃんけん勝負(SVM編) - Qiita
参考資料
Chainerを使い始めるにあたり色々参考にさせていただきました。
この場を借りて感謝申し上げます。
- Chainerで始めるニューラルネットワーク - Qiita
- Chainer v4 ビギナー向けチュートリアル - Qiita
- chainerにearly stoppingを追加してもらった話
- 勤労感謝の日なのでChainerの勤労(Training)に感謝してextensionsを全部試した話 - EnsekiTT Blog
-
過去の手の分析結果(年別) が毎週更新されています。 ↩
-
サザエさんとの勝負結果(年別) が毎週更新されています。 ↩ ↩2
-
勝率は小数第4位(百分率では小数第2位)を切り捨てた値で表示されているようです。 ↩